Mendeteksi serangan telah menjadi tugas penting dalam keamanan informasi selama beberapa dekade. Contoh-contoh implementasi IDS yang pertama diketahui berasal dari awal 1980-an.
Setelah beberapa dekade, seluruh industri alat deteksi serangan terbentuk. Saat ini, ada berbagai jenis produk, seperti IDS, IPS, WAF, firewall, yang sebagian besar menawarkan deteksi serangan berbasis aturan. Gagasan untuk menggunakan teknik pendeteksian anomali untuk mendeteksi serangan berdasarkan statistik produksi tampaknya tidak realistis seperti di masa lalu. Atau sama saja?
Deteksi Anomali dalam Aplikasi Web
Firewall pertama yang dirancang khusus untuk mendeteksi serangan pada aplikasi web mulai muncul di pasaran pada awal 1990-an. Sejak itu, baik metode serangan dan mekanisme pertahanan telah berubah secara signifikan, dan penyerang bisa selangkah lebih maju setiap saat.
Saat ini, sebagian besar WAF berusaha mendeteksi serangan sebagai berikut: ada beberapa mekanisme berbasis aturan yang dibangun ke dalam server proxy terbalik. Contoh yang paling mencolok adalah mod_security, modul WAF untuk server web Apache, yang dikembangkan pada tahun 2002. Mengidentifikasi serangan menggunakan aturan memiliki beberapa kelemahan; misalnya, aturan tidak dapat mendeteksi serangan zero-day, sedangkan serangan yang sama dapat dengan mudah dideteksi oleh seorang ahli, dan ini tidak mengejutkan, karena otak manusia tidak bekerja seperti serangkaian ekspresi reguler.
Dari sudut pandang WAF, serangan dapat dibagi menjadi serangan yang dapat kami deteksi berdasarkan urutan permintaan, dan serangan yang satu permintaan HTTP (respons) cukup untuk dipecahkan. Penelitian kami berfokus pada mendeteksi tipe serangan yang terakhir - SQL Injection, Cross Site Scripting, XML External Entities Injection, Path Traversal, OS Commanding, Object Injection, dll.
Tapi pertama-tama, mari kita menguji diri kita sendiri.
Apa yang akan dipikirkan oleh ahli ketika dia melihat pertanyaan berikut?
Lihatlah contoh permintaan HTTP untuk aplikasi:
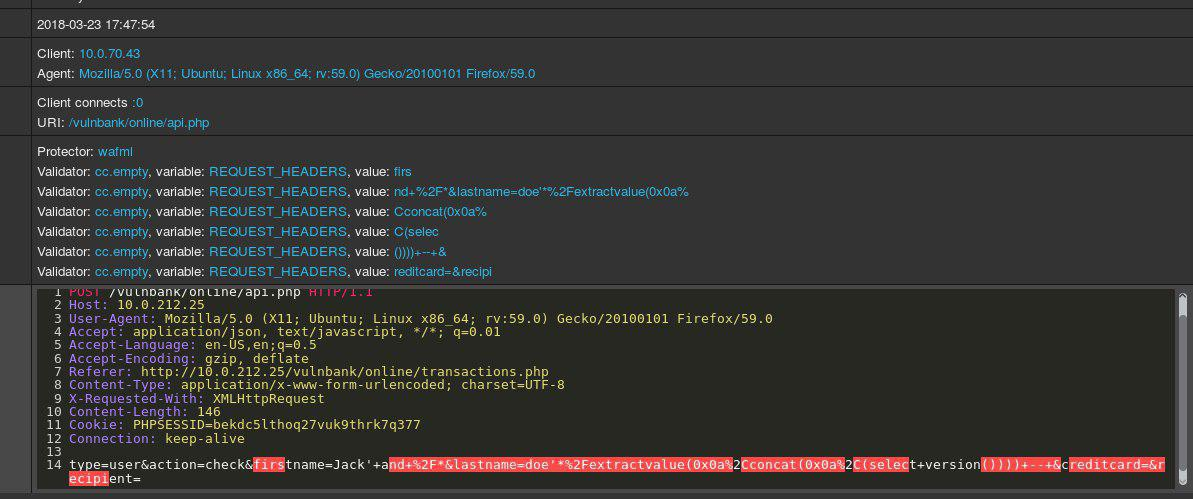
Jika Anda diberi tugas untuk mendeteksi permintaan berbahaya ke suatu aplikasi, kemungkinan besar Anda ingin mengamati perilaku pengguna yang biasa selama beberapa waktu. Dengan memeriksa kueri untuk beberapa titik akhir aplikasi, Anda bisa mendapatkan gambaran umum tentang struktur dan fungsi kueri yang tidak berbahaya.
Sekarang Anda mendapatkan permintaan untuk analisis:

Segera terbukti bahwa ada sesuatu yang salah di sini. Butuh beberapa waktu untuk memahami seperti apa sebenarnya di sini, dan begitu Anda mengidentifikasi bagian dari permintaan yang tampaknya tidak normal, Anda dapat mulai memikirkan jenis serangan apa itu. Intinya, tujuan kami adalah membuat "kecerdasan buatan untuk mendeteksi serangan" bekerja dengan cara yang sama - menyerupai pemikiran manusia.
Yang jelas adalah bahwa beberapa lalu lintas, yang sekilas tampak berbahaya, mungkin normal untuk situs web tertentu.
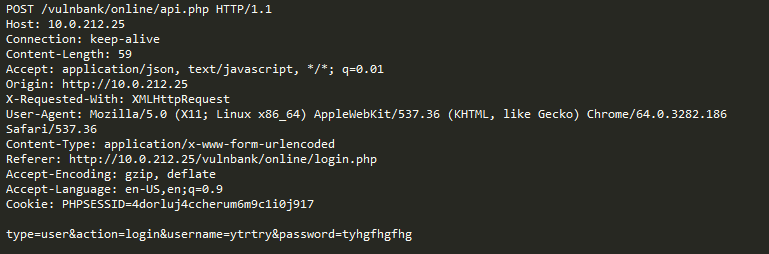
Misalnya, mari pertimbangkan pertanyaan berikut:
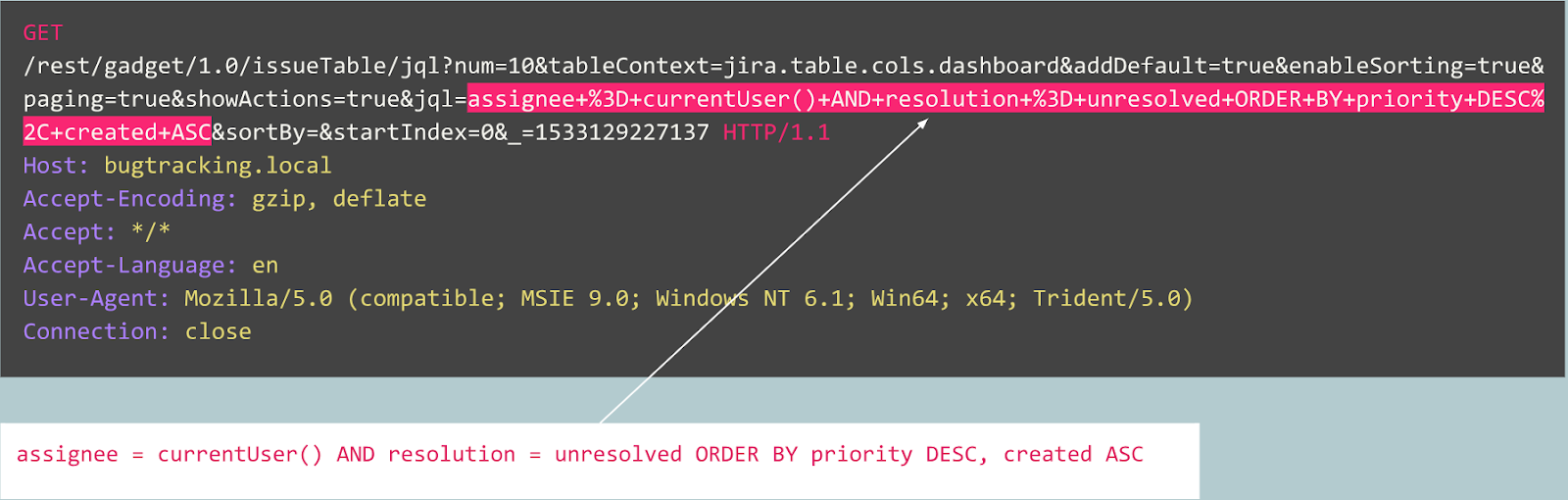
Apakah kueri ini tidak normal?
Bahkan, permintaan ini adalah publikasi bug di pelacak Jira dan merupakan khas dari layanan ini, yang berarti bahwa permintaan tersebut diharapkan dan normal.
Sekarang perhatikan contoh berikut:

Sekilas, permintaan tersebut tampak seperti pendaftaran pengguna normal pada situs web berdasarkan Joomla CMS. Namun, operasi yang diminta adalah user.register bukan registrasi.register yang biasa. Opsi pertama sudah usang dan mengandung kerentanan yang memungkinkan siapa pun untuk mendaftar sebagai administrator. Eksploitasi untuk kerentanan ini dikenal sebagai Joomla <3.6.4 Pembuatan Akun / Peningkatan Privilege (CVE-2016-8869, CVE-2016-8870).

Di mana kita mulai
Tentu saja, pertama kami memeriksa solusi yang ada untuk masalah tersebut. Berbagai upaya untuk membuat algoritma deteksi serangan berdasarkan statistik atau pembelajaran mesin telah dilakukan selama beberapa dekade. Salah satu pendekatan yang paling populer adalah untuk memecahkan masalah klasifikasi, ketika kelas adalah sesuatu seperti "query yang diharapkan", "injeksi SQL", XSS, CSRF, dll. Dengan cara ini, Anda dapat mencapai beberapa akurasi yang baik untuk kumpulan data menggunakan classifier. Namun, pendekatan ini tidak menyelesaikan masalah yang sangat penting dari sudut pandang kami:
- Seleksi kelas terbatas dan ditentukan sebelumnya . Bagaimana jika model Anda dalam proses pembelajaran diwakili oleh tiga kelas, katakan “queries normal”, SQLi dan XSS, dan selama operasi sistem ia menghadapi CSRF atau serangan zero-day?
- Arti dari kelas-kelas ini . Misalkan Anda perlu melindungi sepuluh klien, yang masing-masing menjalankan aplikasi web yang sangat berbeda. Untuk sebagian besar dari mereka, Anda tidak tahu seperti apa sebenarnya injeksi SQL untuk aplikasi mereka. Ini berarti Anda harus membuat set data pelatihan secara artifisial. Pendekatan ini tidak optimal, karena pada akhirnya Anda akan belajar dari data yang berbeda dalam distribusi dari data nyata.
- Interpretabilitas hasil model . Nah, model menghasilkan hasil SQL Injection, dan sekarang apa? Anda dan, yang lebih penting, klien Anda, yang pertama kali melihat peringatan dan biasanya bukan pakar serangan web, harus menebak bagian mana dari permintaan yang dianggap berbahaya oleh model Anda.
Dengan mengingat semua masalah ini, kami memutuskan untuk mencoba melatih model pengklasifikasi.
Karena protokol HTTP adalah protokol teks, jelas bahwa kami perlu melihat pada pengklasifikasi teks modern. Salah satu contoh yang terkenal adalah analisis sentimen dalam dataset ulasan film IMDB. Beberapa solusi menggunakan RNN untuk mengklasifikasikan ulasan. Kami memutuskan untuk mencoba model serupa dengan arsitektur RNN dengan beberapa perbedaan kecil. Misalnya, arsitektur bahasa alami RNN menggunakan representasi vektor kata-kata, tetapi tidak jelas kata-kata mana yang muncul dalam bahasa yang tidak alami seperti HTTP. Oleh karena itu, kami memutuskan untuk menggunakan representasi vektor simbol untuk tugas kami.
Representasi siap pakai tidak menyelesaikan masalah kami, jadi kami menggunakan pemetaan karakter sederhana ke dalam kode numerik dengan beberapa penanda internal, seperti
GO dan
EOS .
Setelah pengembangan dan pengujian model selesai, semua masalah yang diprediksi sebelumnya menjadi jelas, tetapi setidaknya tim kami beralih dari asumsi yang tidak berguna ke beberapa hasil.
Apa selanjutnya
Selanjutnya, kami memutuskan untuk mengambil beberapa langkah menuju interpretabilitas hasil model. Pada titik tertentu, kami menemukan mekanisme perhatian "Perhatian" dan mulai menerapkannya dalam model kami. Dan itu memberikan hasil yang menjanjikan. Sekarang model kami mulai menampilkan tidak hanya label kelas, tetapi juga faktor perhatian untuk setiap karakter yang kami berikan kepada model.
Sekarang kita bisa memvisualisasikan dan menunjukkan di antarmuka web tempat yang tepat di mana serangan injeksi SQL terdeteksi. Ini adalah hasil yang baik, tetapi masalah lain dari daftar masih belum terselesaikan.
Jelas bahwa kita harus terus bergerak ke arah manfaat dari mekanisme perhatian dan menjauh dari tugas klasifikasi. Setelah membaca sejumlah besar studi terkait pada model urutan (pada mekanisme perhatian [2], [3], [4], pada representasi vektor, pada arsitektur autoencoder) dan percobaan dengan data kami, kami dapat membuat model pendeteksian anomali yang pada akhirnya akan bekerja kurang lebih seperti yang dilakukan seorang ahli.
Pengkode Otomatis
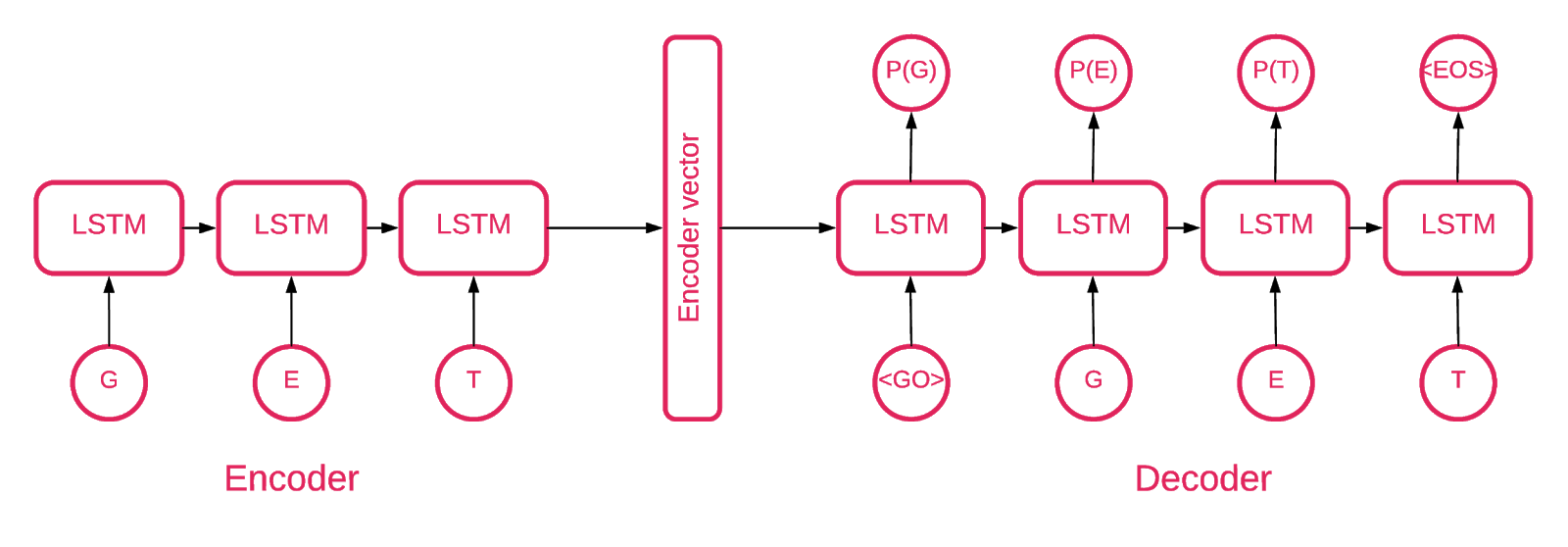
Pada titik tertentu, menjadi jelas bahwa arsitektur Seq2Seq [5] paling cocok untuk tugas kita.
Model Seq2Seq [7] terdiri dari dua LSTM multilayer - sebuah encoder dan sebuah decoder. Encoder memetakan urutan input ke vektor dengan panjang tetap. Dekoder menerjemahkan vektor target menggunakan output encoder. Dalam pelatihan, pembuat enkode otomatis adalah model yang nilai targetnya ditetapkan sama dengan nilai input.
Idenya adalah untuk mengajarkan jaringan untuk memecahkan kode hal-hal yang dilihatnya, atau, dengan kata lain, mendekatkan identitas. Jika autoencoder terlatih diberi pola abnormal, itu mungkin membuatnya kembali dengan tingkat kesalahan yang tinggi, hanya karena tidak pernah terlihat.
Solusi
Solusi kami terdiri dari beberapa bagian: inisialisasi model, pelatihan, perkiraan dan verifikasi. Sebagian besar kode yang terletak di repositori, kami harap, tidak memerlukan penjelasan, jadi kami hanya akan fokus pada bagian-bagian penting.
Model ini dibuat sebagai turunan dari kelas Seq2Seq, yang memiliki argumen konstruktor berikut:
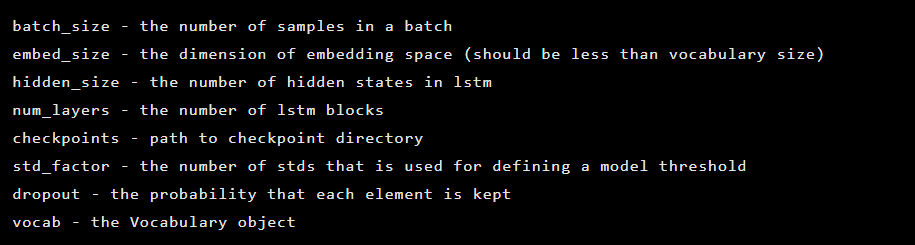
Selanjutnya, lapisan auto-encoder diinisialisasi. Encoder pertama:
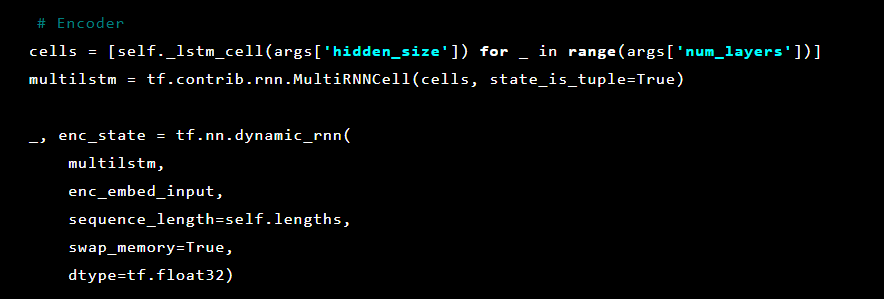
Kemudian dekoder:
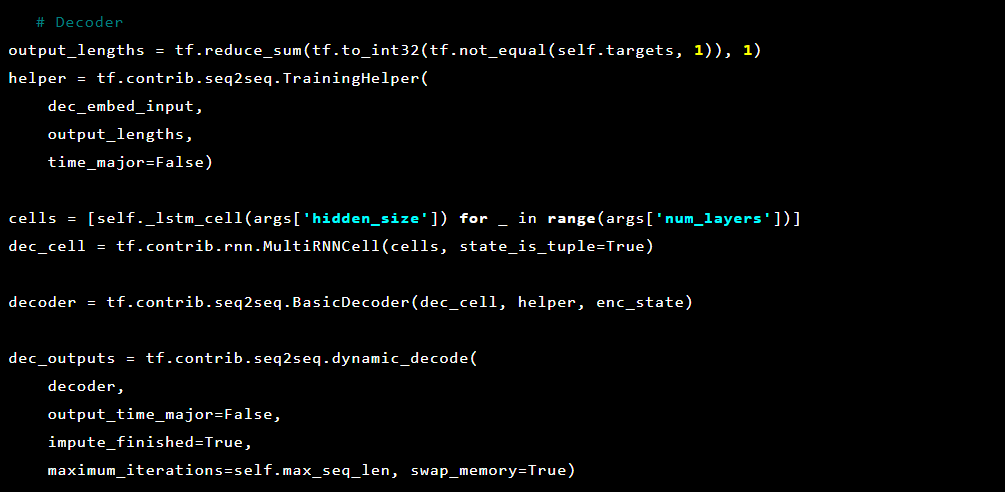
Karena masalah yang kami selesaikan adalah mendeteksi anomali, nilai target dan inputnya sama. Jadi feed_dict kami terlihat seperti ini:
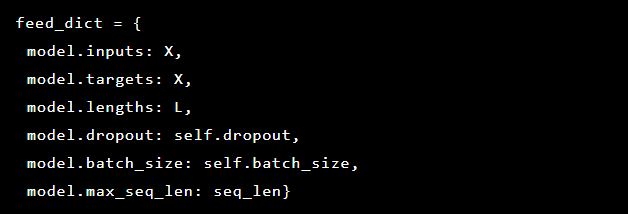
Setelah setiap era, model terbaik disimpan sebagai titik referensi, yang kemudian dapat diunduh. Untuk tujuan pengujian, aplikasi web dibuat yang kami pertahankan dengan model untuk memeriksa apakah serangan nyata berhasil.
Terinspirasi oleh mekanisme perhatian, kami mencoba menerapkannya pada model auto-encoder untuk menandai bagian abnormal dari permintaan ini, tetapi memperhatikan bahwa probabilitas yang berasal dari lapisan terakhir bekerja lebih baik.

Pada tahap pengujian pada sampel kami yang tertunda, kami mendapatkan hasil yang sangat baik: presisi dan daya ingat mendekati 0,99. Dan kurva ROC cenderung ke 1. Kelihatannya luar biasa, bukan?
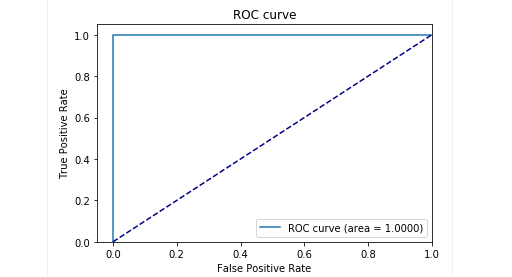
Hasil
Model yang diusulkan dari auto-encoder Seq2Seq mampu mendeteksi anomali dalam permintaan HTTP dengan akurasi yang sangat tinggi.
Model ini bertindak seperti orang: hanya mempelajari permintaan pengguna "normal" untuk aplikasi web. Dan ketika mendeteksi anomali dalam permintaan, ia memilih lokasi yang tepat dari permintaan, yang dianggap anomali.
Kami menguji model ini pada beberapa serangan pada aplikasi uji dan hasilnya menjanjikan. Misalnya, gambar di atas menunjukkan bagaimana model kami mendeteksi injeksi SQL dibagi menjadi dua parameter dalam formulir web. Suntikan SQL semacam itu disebut terfragmentasi: bagian dari muatan serangan dikirim dalam beberapa parameter HTTP, yang membuatnya sulit dideteksi untuk WAF berbasis aturan, karena mereka biasanya menguji setiap parameter secara individual.
Kode model dan data pelatihan dan pengujian diterbitkan sebagai laptop Jupyter sehingga semua orang dapat mereproduksi hasil kami dan menyarankan perbaikan.
Kesimpulannya
Kami percaya bahwa tugas kami agak tidak penting. Kami ingin, dengan upaya minimal (pertama-tama, untuk menghindari kesalahan karena kompleksitas solusi), untuk menemukan cara untuk mendeteksi serangan yang, seolah-olah dengan sihir, telah belajar untuk memutuskan apa yang baik dan apa yang buruk. Kedua, saya ingin menghindari masalah dengan faktor manusia, ketika tepatnya seorang ahli memutuskan apa tanda serangan dan apa yang bukan. Kesimpulannya, saya ingin mencatat bahwa auto-encoder dengan arsitektur Seq2Seq untuk masalah mencari anomali, menurut pendapat kami dan untuk masalah kami, melakukan pekerjaan yang sangat baik.
Kami juga ingin menyelesaikan masalah dengan interpretabilitas data. Menggunakan arsitektur jaringan saraf yang kompleks biasanya sangat sulit. Dalam serangkaian transformasi, pada akhirnya sudah sulit untuk mengatakan apa sebenarnya bagian data yang paling mempengaruhi keputusan. Namun, setelah memikirkan kembali pendekatan interpretasi data oleh model, ternyata cukup bagi kita untuk mendapatkan probabilitas untuk setiap simbol dari lapisan terakhir.
Perlu dicatat bahwa ini bukan versi produksi. Kami tidak dapat mengungkapkan rincian penerapan pendekatan ini dalam produk nyata, dan kami ingin memperingatkan bahwa hanya dengan mengambil dan menyematkan solusi ini di beberapa produk tidak akan berfungsi.
Repositori GitHub:
goo.gl/aNwq9UPenulis : Alexandra Murzina (
murzina_a ), Irina Stepanyuk (
GitHub ), Fedor Sakharov (
GitHub ), Arseniy Reutov (
Raz0r )
Referensi:
- Memahami Jaringan LSTM
- Perhatian dan Augmented Neural Networks
- Perhatian adalah yang Anda butuhkan
- Perhatian Yang Anda Butuhkan (beranotasi)
- Tutorial Terjemahan Mesin Saraf (seq2seq)
- Autoencoder
- Sequence to Sequence Learning dengan Neural Networks
- Membangun Autoencoder di Keras