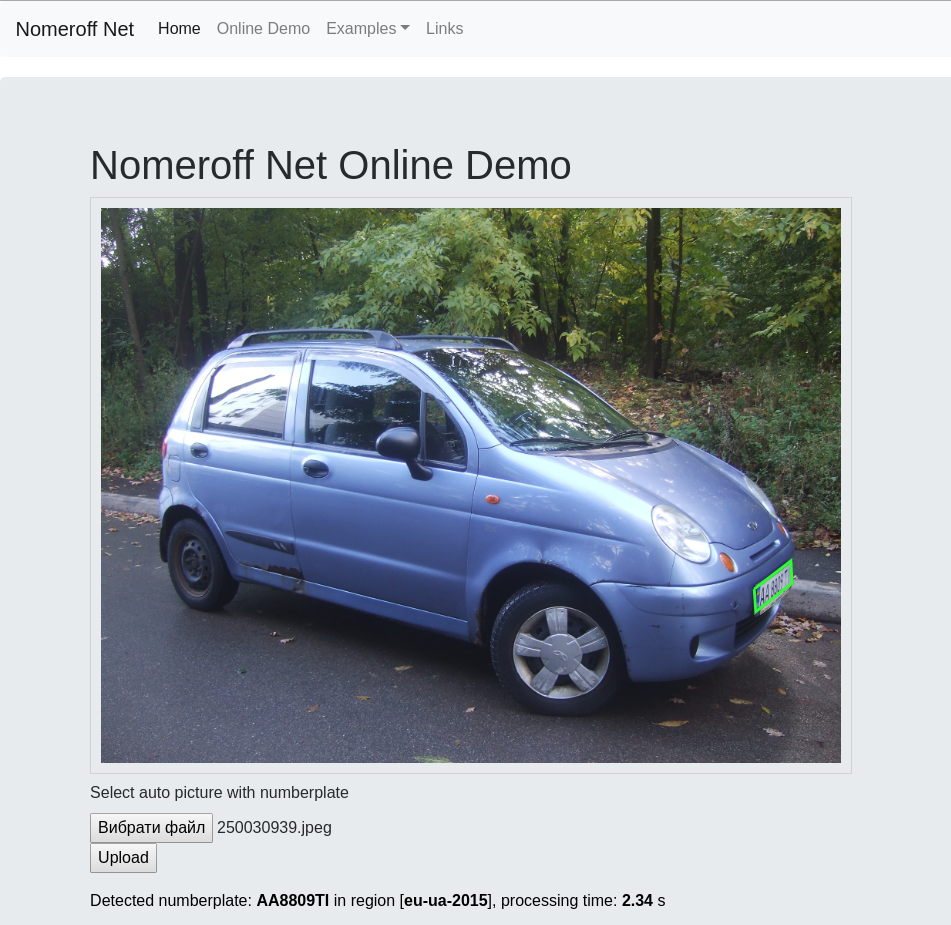
Kami melanjutkan kisah bagaimana mengenali plat nomor untuk mereka yang dapat menulis aplikasi hello world dengan python! Pada bagian ini, kita akan belajar melatih model yang mencari wilayah objek tertentu, serta belajar cara menulis jaringan RNN sederhana yang dapat menangani angka bacaan lebih baik daripada beberapa rekan komersial.
Pada bagian ini saya akan memberi tahu Anda cara melatih Nomeroff Net untuk data Anda, cara mendapatkan kualitas pengakuan tinggi, cara mengonfigurasikan dukungan GPU dan mempercepat semuanya dengan urutan besarnya ...
Kami melatih Mask RCNN untuk menemukan area dengan nomor tersebut
Tentu saja, Anda tidak hanya dapat menemukan angka, tetapi benda lain yang perlu Anda temukan. Misalnya, Anda dapat, dengan analogi, mencari kartu kredit dan membaca detailnya. Secara umum, menemukan topeng di mana objek yang ditorehkan dalam gambar disebut tugas "Segmentasi Instance" (saya sudah menulis tentang ini di bagian pertama).
Sekarang kita akan mencari cara untuk melatih jaringan untuk menyelesaikan masalah ini. Bahkan, ada sedikit pemrograman di sini, semuanya bermuara pada markup data yang monoton, membosankan, seragam. Ya, ya, setelah Anda menandai seratus pertama Anda, Anda akan mengerti apa yang saya maksud :)
Jadi, algoritma persiapan data adalah sebagai berikut:
- Kami mengambil gambar dengan ukuran setidaknya 300x300, membuang semuanya ke satu folder
- Unduh alat markup VGG Image Annotator (VIA) , Anda dapat menandainya secara online , hasilnya akan berupa direktori dengan foto dan file json yang Anda buat dengan markup. Ada dua folder seperti itu, dalam kereta yang disebut meletakkan bagian utama dari contoh, di val kedua sekitar 20-30% dari jumlah contoh paket pertama (Tentu saja, folder ini tidak boleh memiliki foto yang sama). Anda dapat melihat contoh data yang ditandai untuk proyek Nomeroff Net . Secara kuantitas - semakin banyak semakin baik. Beberapa ahli merekomendasikan 5.000 contoh, kami malas, mengetik sedikit lebih dari 1.000 karena hasilnya cukup baik untuk kami.

- Untuk memulai pelatihan, Anda perlu mengunduh proyek Nomeroff Net dari Github, menginstal Mask RCNN dengan semua dependensi, dan Anda dapat mencoba menjalankan skrip train train / mrcnn.ipynb pada data kami
- Saya segera memperingatkan Anda, ini tidak bekerja cepat. Jika Anda tidak memiliki GPU, ini mungkin memakan waktu berhari-hari. Untuk mempercepat proses pembelajaran secara signifikan, disarankan untuk menginstal tensorflow dengan dukungan GPU .
- Jika pelatihan tentang dataset kami berhasil, Anda sekarang dapat dengan aman beralih ke milik Anda.
Harap dicatat - kami tidak melatih semuanya dari awal, kami melatih model yang dilatih pada data dataset COCO , yang diunduh oleh Mask RCNN saat dijalankan pertama kali
- Anda dapat melatih bukan coco, tetapi mask_rcnn_numberplate_0700.h5 model kami , dan tentukan path ke model ini dalam parameter konfigurasi WEIGHTS (secara default, "WEIGHTS": "coco")
- Parameter yang dapat diperluas adalah: EPOCH, STEPS_PER_EPOCH
- Hasilnya setelah setiap era akan dibuang ke folder ./logs/numberplate<tanggal peluncuran> /
Untuk menguji model terlatih dalam praktik, dalam
contoh proyek, ganti
MASK_RCNN_MODEL_PATH dengan jalur ke model Anda.
Meningkatkan classifier plat nomor untuk kebutuhan Anda
Setelah area dengan plat nomor ditemukan, Anda perlu mencoba menentukan negara / jenis nomor yang kami kenali. Di sini universalisasi bekerja melawan kualitas pengakuan. Oleh karena itu, idealnya, Anda perlu melatih penggolong yang tidak hanya menentukan negara mana nomornya, tetapi juga jenis desain nomor ini (lokasi karakter, opsi simbol untuk jenis nomor tertentu).
Dalam proyek kami, kami menerapkan dukungan untuk mengenali angka Ukraina, Federasi Rusia, dan angka Eropa secara umum. Kualitas pengenalan nomor Eropa sedikit lebih buruk, karena ada angka dengan desain berbeda dan peningkatan jumlah karakter yang ditemukan. Mungkin, seiring waktu, akan ada modul pengenalan terpisah untuk "eu-ee", "eu-pl", "eu-nl", ...
Sebelum mengklasifikasikan plat nomor, plat harus "dipotong" dari gambar dan dinormalisasi, dengan kata lain, hapus semua distorsi secara maksimal dan dapatkan persegi panjang yang rapi yang akan dianalisis lebih lanjut. Tugas ini ternyata sangat tidak sepele, saya bahkan harus mengingat matematika sekolah dan menulis implementasi khusus dari algoritma k-means :) clustering :). Modul yang memproses ini disebut RectDetector, beginilah tampilan angka yang dinormalisasi, yang selanjutnya akan kita klasifikasikan dan kenali.

Untuk mengotomatiskan proses pembuatan dataset untuk mengklasifikasikan angka, kami mengembangkan
panel admin kecil di nodejs . Dengan menggunakan panel admin ini, Anda dapat menandai prasasti pada plat nomor dan kelas tempatnya.
Mungkin ada beberapa pengklasifikasi. Dalam kasus kami, berdasarkan jenis nomor dan berdasarkan apakah sketsa / dilukis di foto.
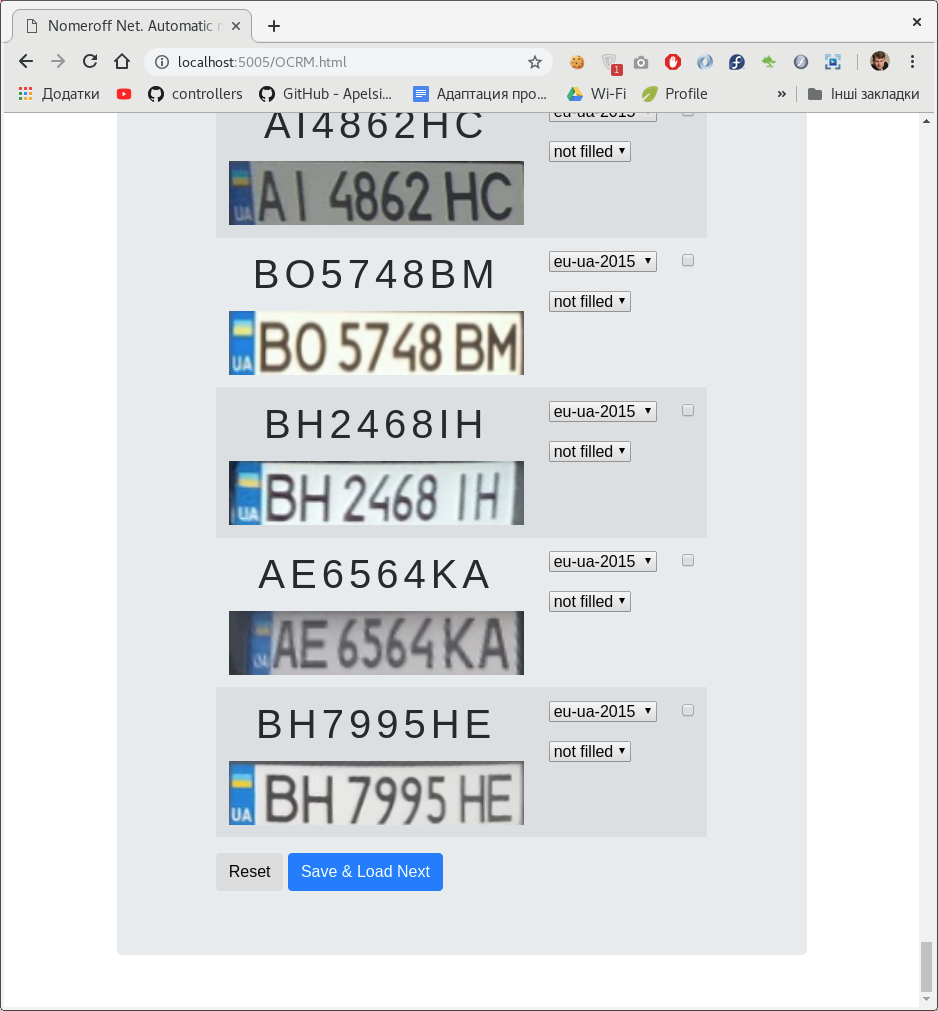
Setelah kami menandai dataset, kami membaginya menjadi pelatihan, validasi, dan sampel uji. Sebagai contoh, unduh
dataset autoriaNumberplateOptions3Dataset-2019-05-20.zip kami untuk melihat cara
kerja semuanya di sana.
Karena pemilihan telah ditandai (dimoderasi), maka Anda perlu mengubah "isModerated": 1 menjadi "isModerated" di file json acak: 0 dan kemudian mulai panel admin .
Kami melatih penggolong:
Train script
train / options.ipynb akan membantu Anda mendapatkan versi model. Contoh kami menunjukkan bahwa untuk klasifikasi daerah / jenis plat, kami mendapatkan akurasi
98,8% , untuk klasifikasi "Apakah nomornya dicat?"
99,4% pada dataset kami. Setuju, ternyata baik-baik saja.
Latih OCR Anda (pengenalan teks)
Kami menemukan area dengan nomor dan menormalkannya menjadi persegi panjang yang berisi tulisan dengan nomor tersebut. Bagaimana cara kita membaca teks? Cara termudah adalah dengan menjalankannya melalui FineReader atau Tesseract. Kualitasnya akan “tidak terlalu”, tetapi dengan resolusi area yang baik dengan angka Anda bisa mendapatkan akurasi 80%. Sebenarnya, ini bukan akurasi yang buruk, tetapi jika saya memberi tahu Anda bahwa Anda bisa mendapatkan
97% dan pada saat yang sama menghabiskan sumber daya komputer yang jauh lebih sedikit? Kedengarannya bagus - mari kita coba. Arsitektur yang sedikit tidak biasa cocok untuk tujuan ini, di mana lapisan konvolusional dan berulang digunakan. Arsitektur jaringan ini terlihat seperti ini:
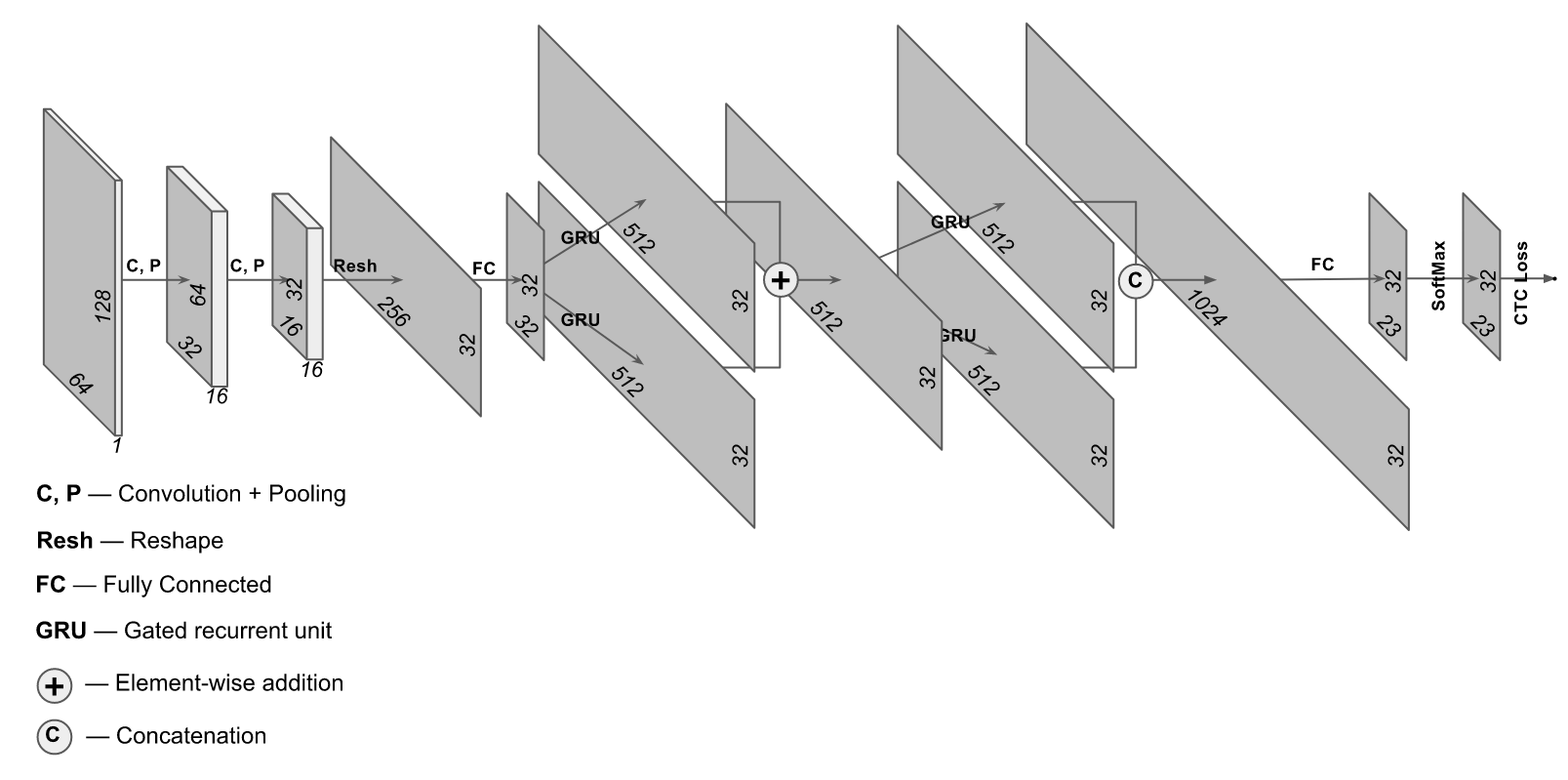
Implementasinya diambil dari situs
https://supervise.ly/ , kami memodifikasinya sedikit untuk pelatihan foto nyata (di situs web yang diawasi, sebuah pilihan dibuat untuk pengambilan sampel sintetis)
Sekarang bagian yang menyenangkan dimulai, tandai setidaknya 5.000 angka :). Kami menandai sekitar
~ 100.000 Ukraina ,
~ 50.000 Ukraina dengan desain "lama" ,
~ 6.500 Eropa ,
~ 10.000 RF . Ini adalah bagian paling sulit dari pengembangan. Anda bahkan tidak dapat membayangkan berapa kali saya tertidur di kursi komputer yang dimoderasi beberapa jam sehari untuk porsi angka selanjutnya. Tetapi pahlawan sebenarnya dari markup adalah
dimabendera - ia menandai 2/3 dari semua konten, (berikan nilai tambah jika Anda mengerti betapa membosankannya melakukan semua pekerjaan ini :))
Anda dapat mencoba untuk mengotomatiskan proses ini, misalnya, setelah sebelumnya mengenali setiap gambar dengan Tesseract, dan kemudian memperbaiki kesalahan menggunakan
panel admin kami .
Harap dicatat: panel admin yang sama digunakan untuk menandai classifier dan OCR pada nomor tersebut. Anda dapat memuat data yang sama di sana dan di sana, kecuali untuk nomor sketsa, tentu saja.
Jika Anda menandai setidaknya 5.000 angka dan dapat melatih OCR Anda - jangan ragu untuk mengatur hadiah untuk diri Anda sendiri dengan atasan Anda, saya yakin tes ini bukan untuk para pengecut!
Pelatihan memulai
Skrip train / ocr-ru.ipynb melatih model untuk nomor Rusia, ada contoh untuk
Ukraina dan
Eropa .
Harap dicatat bahwa dalam pengaturan pelatihan hanya ada satu era (satu pass).
Fitur pelatihan dataset seperti itu akan menjadi hasil yang sangat berbeda untuk setiap upaya, sebelum setiap sesi pelatihan, data dicampur dalam urutan acak, kadang-kadang lebih “tidak terlalu baik” untuk pelatihan. Saya sarankan Anda mencoba setidaknya 5 kali, sambil mengontrol akurasi data uji. Dengan berbagai upaya peluncuran, akurasi kami dapat "melompat" dari
87% menjadi 97% .
Beberapa rekomendasi :
- Tidak perlu menginisialisasi semuanya dengan cara baru, cukup restart model baris = ocrTextDetector.train (mode = MODE) hingga kami mendapatkan hasil yang diharapkan
- Salah satu alasan keakuratan yang buruk adalah data yang tidak memadai. Jika Anda tidak menyukainya, kami menandainya berulang-ulang, pada titik tertentu kualitasnya berhenti bertambah, untuk setiap dataset berbeda, Anda dapat fokus pada jumlah 10.000 contoh berlabel
- Pelatihan akan lebih cepat jika Anda menginstal driver NVIDIA CuDNN , mengubah nilai MODE = "gpu" dalam skrip pelatihan dan CuDNNGRU akan terhubung sebagai pengganti lapisan GRU, yang akan mengarah pada akselerasi tiga kali lipat.
Sedikit tentang pengaturan tensorflow untuk GPU NVIDIA
Jika Anda adalah pemilik yang bahagia dari GPU dari NVIDIA, maka Anda dapat mempercepat semuanya: nomor model pelatihan dan nomor inferensi (mode pengenalan). Masalahnya adalah menginstal dan mengkompilasi semuanya dengan benar.
Kami menggunakan Fedora Linux di server ML kami (ini terjadi secara historis).
Perkiraan urutan tindakan untuk mereka yang menggunakan OS ini adalah sebagai berikut:
- Kami menempatkan driver GPU untuk versi OS Anda, di sini untuk Fedora
- Kami menghubungkan repositori NVIDIA dan menginstal paket CUDA dari sana, di sini untuk CentOS / Fedora
- Kami menaruh bazel, dan kami mengumpulkan tensorflow dari sumber di dermaga ini
- Juga disarankan untuk menginstal versi lama dari kompiler gcc, yang disebut cuda-gcc, semuanya berjalan baik bagi saya di cuda-gcc 6.4. Saat mengkonfigurasi rakitan, tentukan path ke cuda-gcc
Jika Anda tidak dapat membangun tensorflow dengan dukungan gpu, Anda dapat menjalankan semuanya melalui buruh pelabuhan, dan selain buruh pelabuhan, Anda perlu menginstal paket nvidia-docker2. Di dalam wadah buruh pelabuhan, Anda dapat menjalankan notebook jupyter, dan kemudian menjalankan semua yang ada di sana.
jupyter notebook --ip=0.0.0.0 --port=8888 --allow-root
Tautan yang bermanfaat
Saya juga ingin mengucapkan terima kasih kepada 2 expres,
habrausers glassofkvass untuk memberikan foto dengan angka dan
dimabendera untuk menulis sebagian besar kode dan menandai sebagian besar data dari proyek Nomeroff Net.
UPD1: Karena I dan Dmitri dikirim ke pertanyaan standar PM tentang pengenalan angka, kombinasi tensorflow dengan gpu, dll. dan Dmitry dan saya memberikan jawaban yang sama, saya ingin mengoptimalkan proses ini.
Kami menyarankan agar korespondensi dalam komentar lebih terstruktur, dibagi berdasarkan topik. Ada fungsionalitas yang nyaman di GitHub untuk ini. Di masa depan, silakan ajukan pertanyaan tidak di komentar, tetapi dalam
masalah tematik di github Nomeroff NetUPD2: Seiring waktu, dataset juga muncul:
angka Kazakh ,
angka Georgia