Apakah itu terjadi pada Anda bahwa Anda tetap berpegang pada semacam permainan sederhana, berpikir bahwa kecerdasan buatan dapat mengatasinya? Saya dulu, dan saya memutuskan untuk mencoba membuat pemain bot seperti itu. Selain itu, sekarang ada banyak alat untuk visi komputer dan pembelajaran mesin yang memungkinkan Anda untuk membangun model tanpa pemahaman mendalam tentang detail implementasi. Manusia biasa dapat membuat prototipe tanpa membangun jaringan saraf selama berbulan-bulan dari awal.

Di bawah potongan Anda akan menemukan proses menciptakan bot proof-of-concept untuk game Clash Royale, di mana saya menggunakan perpustakaan Scala, Python dan CV. Menggunakan visi komputer dan pembelajaran mesin, saya mencoba membuat bot untuk permainan yang berinteraksi seperti pemain hidup.
Nama saya Sergey Tolmachev, saya Pimpinan Pengembang Scala di Waves Platform dan mengajar
kursus Scala di Distrik Biner, dan di waktu senggang saya mempelajari teknologi lain, seperti AI. Dan saya ingin memperkuat keterampilan yang diperoleh dengan beberapa pengalaman praktis. Tidak seperti kompetisi AI, di mana bot Anda bermain melawan bot pengguna lain, Clash Royale dapat bermain melawan orang-orang, yang terdengar lucu. Bot Anda bisa belajar mengalahkan pemain sungguhan!
Mekanik game di Clash Royale
Mekanik gim ini cukup sederhana. Anda dan lawan Anda memiliki tiga bangunan: benteng dan dua menara. Para pemain sebelum permainan mengumpulkan deck - 8 unit yang tersedia, yang kemudian digunakan dalam pertempuran. Mereka memiliki level yang berbeda, dan mereka dapat dipompa, mengumpulkan lebih banyak kartu dari unit-unit ini dan membeli pembaruan.
Setelah dimulainya permainan, Anda dapat menempatkan unit yang tersedia pada jarak yang aman dari menara musuh, sambil menghabiskan unit mana, yang perlahan-lahan dipulihkan selama permainan. Unit dikirim ke bangunan musuh dan terganggu oleh musuh yang ditemui di sepanjang jalan. Pemain hanya dapat mengontrol posisi awal unit - ia dapat mempengaruhi pergerakan lebih lanjut dan kerusakan hanya dengan mengatur unit lainnya.
Masih ada mantra yang dapat dimainkan di mana saja di lapangan, mereka biasanya menyebabkan kerusakan pada unit dengan cara yang berbeda. Mantra dapat mengkloning, membekukan, atau mempercepat unit di suatu daerah.
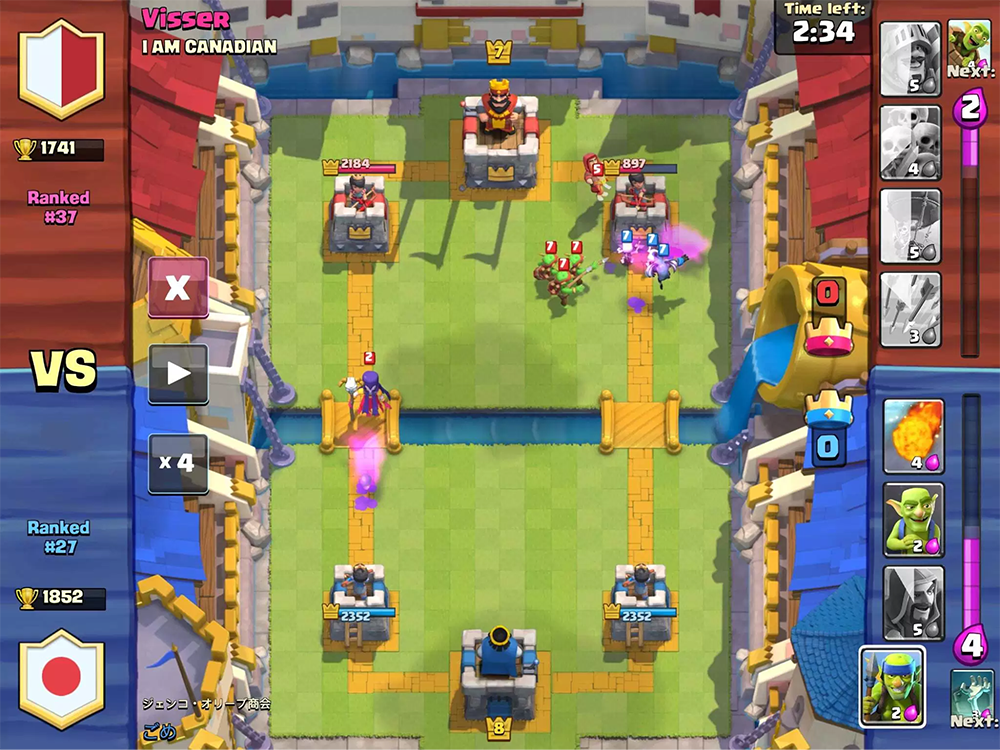
Tujuan permainan ini adalah untuk menghancurkan bangunan musuh. Untuk kemenangan penuh, Anda harus menghancurkan benteng atau setelah dua menit permainan menghancurkan lebih banyak bangunan (aturannya tergantung pada mode permainan, tetapi secara umum mereka terdengar seperti ini).
Selama permainan, Anda harus memperhitungkan pergerakan unit, jumlah mana yang mungkin dan kartu musuh saat ini. Anda juga perlu mempertimbangkan bagaimana pemasangan unit memengaruhi lapangan bermain.
Membangun solusi
Clash Royale adalah game mobile, jadi saya memutuskan untuk menjalankannya di Android dan berinteraksi dengannya melalui ADB. Ini akan mendukung pekerjaan dengan simulator atau dengan perangkat nyata.
Saya memutuskan bahwa bot, seperti banyak AI game lainnya, harus bekerja pada algoritma Persepsi-Analisis-Tindakan. Seluruh lingkungan dalam permainan ditampilkan di layar, dan interaksi dengannya terjadi dengan mengeklik layar. Oleh karena itu, bot harus berupa program, input yang menggambarkan kondisi permainan saat ini: lokasi dan karakteristik unit dan bangunan, kemungkinan kartu saat ini, dan jumlah mana. Pada output, bot harus memberikan array koordinat di mana unit harus direkam.
Tetapi sebelum membuat bot itu sendiri, perlu untuk menyelesaikan masalah mengekstraksi informasi tentang kondisi saat ini permainan dari tangkapan layar. Pada umumnya, isi artikel selanjutnya dikhususkan untuk tugas ini.
Untuk mengatasi masalah ini, saya memutuskan untuk menggunakan Computer Vision. Mungkin ini bukan solusi terbaik: CV tanpa banyak pengalaman dan sumber daya jelas memiliki keterbatasan dan tidak dapat mengenali semuanya di tingkat manusia.
Akan lebih akurat untuk mengambil data dari memori, tetapi saya tidak memiliki pengalaman seperti itu. Root diperlukan dan secara keseluruhan solusi ini terlihat lebih rumit. Juga tidak jelas apakah kecepatan sekitar waktu nyata dapat dicapai di sini jika Anda mencari objek dengan tumpukan JVM di dalam perangkat. Selain itu, saya ingin menyelesaikan masalah CV lebih dari ini.
Secara teori, seseorang dapat membuat server proxy dan mengambil informasi dari sana. Tetapi protokol jaringan permainan sering berubah, proksi di Internet datang, tetapi dengan cepat menjadi usang dan tidak didukung.
Sumber Daya Game yang tersedia
Untuk mulai dengan, saya memutuskan untuk berkenalan dengan materi yang tersedia dari permainan. Saya menemukan sebuah
klub pengrajin menarik keluar sumber daya permainan dikemas
[1] [2] . Pertama-tama, saya tertarik pada gambar unit, tetapi dalam paket game yang tidak dibungkus, mereka disajikan dalam bentuk peta petak (bagian-bagiannya terdiri dari unit).
Saya juga menemukan skrip frame animasi unit terpaku (meskipun tidak sempurna) - mereka berguna untuk melatih model pengenalan.

Selain itu, dalam sumber daya Anda dapat menemukan csv dengan berbagai data permainan - jumlah HP, kerusakan unit dari berbagai tingkat, dll. Ini berguna saat membuat logika bot. Misalnya, dari data menjadi jelas bahwa bidang itu dibagi menjadi 18 x 29 sel, dan unit hanya dapat ditempatkan pada mereka. Ada juga semua gambar peta unit, yang akan berguna bagi kita nanti.
Visi Komputer untuk Malas
Setelah mencari solusi-CV yang tersedia, menjadi jelas bahwa dalam kasus apa pun, mereka harus dilatih tentang dataset berlabel. Saya mengambil tangkapan layar dan sudah siap untuk menandai sejumlah tangkapan layar dengan tangan saya. Ini ternyata menjadi tantangan.
Menemukan program pengenalan yang tersedia membutuhkan waktu. Saya memilih
labelImg . Semua aplikasi anotasi yang saya temukan cukup primitif: banyak yang tidak mendukung pintasan keyboard, pemilihan objek dan tipenya dibuat jauh lebih tidak nyaman daripada di labelImg.
Saat markup, ternyata bermanfaat untuk memiliki kode sumber aplikasi. Saya mengambil screenshot setiap beberapa detik dari pertandingan. Ada banyak objek di tangkapan layar (misalnya, sepasukan kerangka), dan saya membuat modifikasi pada labelImg - secara default, saat menandai gambar berikutnya, label dari yang sebelumnya diambil. Seringkali, mereka hanya harus dipindahkan ke posisi baru unit, menghapus unit yang mati dan menambahkan beberapa muncul, dan tidak menandai dari awal.

Prosesnya ternyata memakan banyak sumber daya - dalam dua hari dalam mode senyap, saya memposting sekitar 200 tangkapan layar. Sampel terlihat sangat kecil, tetapi saya memutuskan untuk mulai bereksperimen. Anda selalu dapat menambahkan lebih banyak contoh dan meningkatkan kualitas model.
Pada saat markup, saya tidak tahu alat pelatihan apa yang akan saya gunakan, jadi saya memutuskan untuk menyimpan hasil markup dalam format VOC - salah satu yang konservatif dan tampaknya universal.
Pertanyaannya mungkin timbul: mengapa tidak mencari gambar unit demi piksel secara kebetulan saja? Masalahnya adalah bahwa untuk yang satu ini harus mencari sejumlah besar frame animasi yang berbeda dari unit yang berbeda. Itu tidak akan berhasil. Saya ingin membuat solusi universal yang mendukung berbagai izin. Selain itu, unit dapat memiliki warna yang berbeda tergantung pada efek yang diterapkan padanya - pembekuan, akselerasi.
Mengapa saya memilih YOLO
Saya mulai mengeksplorasi kemungkinan solusi pengenalan gambar. Saya melihat penerapan berbagai algoritma: OpenCV, TensorFlow, Torch. Saya ingin membuat pengakuan secepat mungkin, bahkan mengorbankan akurasi, dan mendapatkan POC sesegera mungkin.
Setelah membaca
artikel , saya menyadari bahwa tugas saya tidak sesuai dengan pengklasifikasi HOG / LBP / SVM / HAAR / .... Meskipun mereka cepat, mereka harus diterapkan berkali-kali - sesuai dengan pengklasifikasi untuk setiap unit - dan kemudian satu per satu untuk menerapkannya pada gambar untuk pencarian. Selain itu, prinsip operasi mereka dalam teori akan memberikan hasil yang buruk: unit dapat memiliki bentuk yang berbeda, misalnya, ketika bergerak ke kiri dan ke atas.
Secara teoritis, menggunakan jaringan saraf, Anda dapat menerapkannya sekali untuk gambar dan mendapatkan semua unit dari jenis yang berbeda dengan posisi mereka, jadi saya mulai menggali ke arah jaringan saraf. TensorFlow telah menemukan dukungan untuk Convolutional Neural Networks (CNN). Ternyata tidak perlu melatih jaringan saraf dari awal - Anda dapat
melatih kembali jaringan kuat yang ada .
Kemudian saya menemukan algoritma YOLO yang lebih praktis, yang menjanjikan kompleksitas lebih sedikit dan, oleh karena itu, harus menyediakan algoritma pencarian berkecepatan tinggi tanpa mengorbankan banyak akurasi (dan dalam beberapa kasus, melampaui model lain).
Situs web YOLO menjanjikan perbedaan kecepatan yang sangat besar dengan menggunakan model mungil dan jaringan yang lebih kecil dan dioptimalkan. YOLO juga memungkinkan Anda untuk melatih ulang jaringan saraf yang telah selesai untuk tugas Anda, dan
darknet - kerangka kerja
open source untuk menggunakan berbagai neuron yang pembuatnya dikembangkan YOLO - adalah aplikasi C asli yang sederhana, dan semua pekerjaan dengannya terjadi melalui pemanggilan parameternya.
TensorFlow, yang ditulis dengan Python, sebenarnya adalah sebuah pustaka Python dan digunakan dengan menggunakan skrip yang ditulis sendiri yang harus Anda pahami atau sempurnakan sesuai kebutuhan Anda. Mungkin, bagi sebagian orang, fleksibilitas TensorFlow merupakan nilai tambah, tetapi tanpa merinci, hampir tidak mungkin untuk dengan cepat mengambil dan menggunakannya. Karena itu, dalam proyek saya, pilihan jatuh pada YOLO.
Bangunan model
Untuk mengerjakan pelatihan model, saya menginstal Ubuntu 18.10, mengirimkan paket perakitan, paket OpenCL NVIDIA dan dependensi lainnya, dan membangun darknet.
Github memiliki
bagian dengan langkah-langkah sederhana untuk melatih ulang model YOLO : Anda perlu mengunduh model dan mengonfigurasi, mengubahnya dan mulai melatih kembali.
Pertama saya ingin mencoba melatih kembali model YOLO sederhana, lalu Tiny dan membandingkannya. Namun, ternyata untuk melatih model-model sederhana, Anda memerlukan 4 GB memori kartu video, dan saya hanya punya kartu grafis NVIDIA GeForce GTX 1060 3 GB yang dibeli untuk permainan. Karena itu, saya hanya bisa segera melatih model Tiny.
Markup unit pada gambar yang saya miliki adalah dalam format VOC, dan YOLO bekerja dengan formatnya sendiri, jadi saya menggunakan utilitas
convert2Yolo untuk mengonversi file anotasi.
Setelah satu malam pelatihan di 200 tangkapan layar saya, saya mendapatkan hasil pertama, dan mereka mengejutkan saya - model itu benar-benar mampu mengenali sesuatu dengan benar! Saya menyadari bahwa saya bergerak ke arah yang benar, dan memutuskan untuk melakukan lebih banyak contoh pengajaran.

Saya tidak ingin terus meletakkan tangkapan layar, dan saya ingat tentang bingkai dari animasi unit. Saya menandai semua gambar kecil dengan kelas mereka dan mencoba untuk melatih jaringan pada set ini. Hasilnya sangat buruk. Saya berasumsi bahwa model tidak dapat memilih pola yang benar dari gambar kecil untuk digunakan dalam gambar besar.
Setelah itu, saya memutuskan untuk menempatkan mereka di latar belakang arena pertempuran yang sudah jadi dan secara terprogram membuat file markup VOC. Ternyata screenshot sintetis seperti itu dengan tata letak otomatis 100% akurat.
Saya menulis sebuah skrip di Scala yang membagi tangkapan layar menjadi 16 kotak 4x4 dan mengatur unit di tengah mereka sehingga mereka tidak saling berpotongan. Skrip juga memungkinkan saya untuk menyesuaikan pembuatan contoh pelatihan - saat menerima kerusakan, unit dicat dengan warna tim mereka (merah / biru), dan selama klasifikasi saya secara terpisah mengenali unit warna yang berbeda. Selain pewarnaan, unit tim yang berbeda yang menerima kerusakan memiliki sedikit perbedaan dalam pakaian. Juga, saya secara acak menambah dan mengurangi unit sedikit, sehingga model belajar untuk tidak terlalu bergantung pada ukuran unit. Hasilnya, saya belajar cara membuat puluhan ribu contoh pelatihan yang kira-kira mirip dengan tangkapan layar nyata.
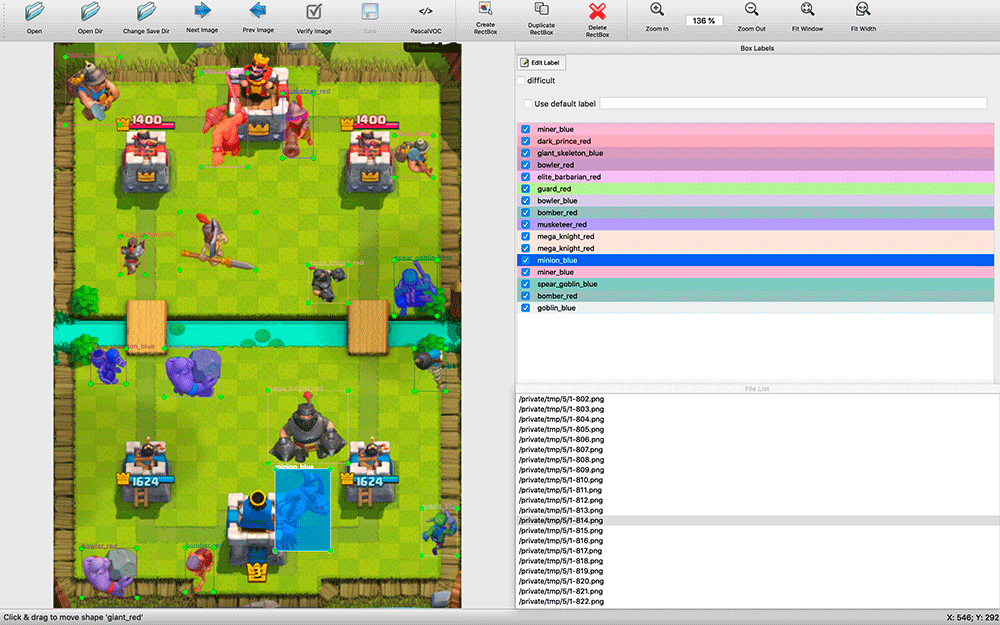
Generasi itu tidak sempurna. Seringkali unit ditempatkan di atas bangunan, meskipun dalam permainan mereka akan berada di belakang mereka; tidak ada contoh tumpang tindih bagian unit, meskipun ini bukan situasi yang jarang terjadi dalam permainan. Tapi sejauh ini saya memutuskan untuk mengabaikannya.

Model yang diperoleh setelah beberapa malam pelatihan tentang campuran 200 tangkapan layar nyata dan 5000 gambar yang dihasilkan yang diciptakan kembali selama proses pelatihan sekali sehari, ketika diuji pada tangkapan layar ini, memberikan hasil yang buruk. Tidak mengherankan, karena gambar yang dihasilkan memiliki banyak perbedaan dari yang asli.
Oleh karena itu, saya meletakkan model yang dihasilkan untuk melatih ulang pada sampel rata-rata, di mana hanya ada 200 tangkapan layar saya. Setelah itu, dia mulai bekerja jauh lebih baik.
Sayang sekaliSaya minta maaf karena menangani tindakan tidak ilmiah seperti itu "jauh lebih baik", tetapi saya tidak tahu cara cepat memvalidasi gambar, jadi saya mencoba beberapa tangkapan layar dari perangkat non-pelatihan dan mencari apakah hasilnya memuaskan saya. Ini adalah hal yang paling penting. Kami malas dan kami membuat prototipe, kan?
Langkah-langkah selanjutnya untuk meningkatkan model dapat dipahami - tandai dengan tangan Anda tangkapan layar yang lebih nyata dan latihlah pada model tersebut, pra-latih pada tangkapan layar yang dihasilkan.
Mari kita turun ke bot
Saya memutuskan untuk menulis bot dengan Python - ia memiliki banyak alat yang tersedia untuk ML. Saya memutuskan untuk menggunakan model saya dengan OpenCV, yang dari
3,5 belajar menggunakan model jaringan saraf , dan saya bahkan menemukan
contoh sederhana . Setelah mencoba beberapa perpustakaan untuk bekerja dengan ADB, saya memilih
pure-python-adb - semua yang saya butuhkan hanya diterapkan di sana: fungsi tangkapan layar dan operasi pada perangkat shell; Saya ketuk menggunakan 'input ketuk'.
Jadi, setelah menerima tangkapan layar dari gim tersebut, mengenali unit-unit di dalamnya dan menyodoknya di layar, saya terus berupaya mengenali keadaan gim. Selain unit, saya perlu membuat pengakuan tingkat mana saat ini dan kartu yang tersedia untuk pemain.
Level mana dalam game ditampilkan sebagai bilah kemajuan dan angka. Tanpa berpikir dua kali, saya mulai memotong nomornya, membalikkan dan mengenali menggunakan
pytesseract .
Untuk menentukan kartu yang tersedia dan posisinya, saya menggunakan
detektor keypoint KAZE dari OpenCV . Sejauh ini saya tidak ingin kembali mempelajari jaringan saraf lagi, dan saya memilih metode yang lebih cepat dan lebih mudah, meskipun pada akhirnya ternyata memiliki akurasi minimum yang cukup dalam kasus ketika Anda perlu mencari banyak objek.
Saat memulai bot, saya menghitung titik kunci untuk semua gambar kartu (totalnya ada beberapa lusin), dan selama permainan saya mencari kecocokan semua kartu dengan area kartu pemain untuk mengurangi jumlah kesalahan dan meningkatkan kecepatan. Mereka disortir berdasarkan akurasi dan koordinat
x untuk mendapatkan urutan peta - informasi tentang bagaimana mereka berada di layar.
Setelah bermain sedikit dengan parameter, dalam praktiknya saya mendapatkan banyak kesalahan, meskipun beberapa gambar kartu yang kompleks, yang kadang-kadang keliru untuk orang lain oleh algoritma, diakui dengan sangat akurat. Saya harus menambahkan buffer tiga elemen: jika tiga pengenalan berturut-turut kita mendapatkan nilai yang sama, maka kita secara kondisional percaya bahwa kita dapat mempercayai mereka.

Setelah menerima semua informasi yang diperlukan (unit dan perkiraan posisi mereka, mana dan kartu yang tersedia), Anda dapat membuat beberapa keputusan.
Sebagai permulaan, saya memutuskan untuk mengambil sesuatu yang sederhana: misalnya, jika ada cukup mana pada kartu yang dapat diakses, mainkan di lapangan. Tetapi bot masih tidak tahu bagaimana cara "bermain" kartu - ia tahu kartu apa yang kita miliki, di mana lapangan, Anda perlu mengklik kartu yang diinginkan, dan kemudian pada sel yang diinginkan di lapangan.
Mengetahui resolusi tangkapan layar, Anda dapat memahami koordinat peta dan sel bidang yang diinginkan. Sekarang saya sudah terikat dengan resolusi layar yang tepat, tetapi jika perlu, saya bisa mengabaikan ini. Fungsi keputusan akan mengembalikan array keran yang perlu dilakukan dalam waktu dekat. Secara umum, bot kami akan menjadi loop tak terbatas (disederhanakan):
: = : ( ) : = () = () = () += (, , , )
Sejauh ini, bot hanya dapat menempatkan unit pada satu titik, tetapi sudah memiliki informasi yang cukup untuk membangun strategi yang lebih kompleks.
Masalah pertama
Pada kenyataannya, saya mengalami masalah yang tidak terduga dan sangat tidak menyenangkan. Membuat tangkapan layar melalui ADB membutuhkan waktu sekitar 100 ms, yang memperkenalkan penundaan yang signifikan - Saya mengandalkan penundaan yang sedemikian besar, dengan mempertimbangkan semua perhitungan dan pilihan tindakan, tetapi tidak pada satu langkah membuat tangkapan layar. Solusi sederhana dan cepat tidak dapat ditemukan. Secara teori, menggunakan emulator Android, Anda dapat mengambil tangkapan layar langsung dari jendela aplikasi, atau Anda dapat membuat utilitas untuk streaming gambar dari ponsel dengan kompresi melalui UDP dan menghubungkan bot ke sana, tetapi saya juga tidak menemukan solusi cepat di sini.
Jadi
Setelah dengan tenang menilai keadaan proyek saya, saya memutuskan untuk berhenti pada model ini untuk saat ini. Saya menghabiskan beberapa minggu waktu luang saya melakukan ini, dan pengenalan unit hanya bagian dari gameplay.
Saya memutuskan untuk mengembangkan bagian-bagian bot secara bertahap - untuk membuat logika dasar persepsi, kemudian logika sederhana dari permainan dan interaksi dengan permainan, dan kemudian akan mungkin untuk meningkatkan bagian-bagian bot yang mereda secara individu. Ketika tingkat model pengenalan unit menjadi cukup, menambahkan informasi tentang HP dan tingkat unit dapat membawa pengembangan bot game ke tahap yang sama sekali baru. Mungkin ini akan menjadi tujuan berikutnya, tetapi saat ini jelas tidak layak untuk fokus pada tugas ini.
Repositori proyek GithubSaya menghabiskan banyak waktu di proyek dan, terus terang, saya bosan, tapi saya tidak menyesal sedikit - saya mendapat pengalaman baru di ML / CV.
Mungkin saya akan kembali kepadanya nanti - saya akan senang jika seseorang bergabung dengan saya. Jika Anda tertarik, bergabunglah dengan grup di
Telegram , dan datang juga ke
kursus Scala saya.