Kami adalah Big Data di MTS dan ini adalah posting pertama kami. Hari ini kita akan berbicara tentang teknologi apa yang memungkinkan kita untuk menyimpan dan memproses data besar sehingga selalu ada sumber daya yang cukup untuk analisis, dan biaya pembelian besi tidak pergi ke jarak yang sangat jauh.
Mereka berpikir tentang menciptakan pusat Data Besar di MTS pada tahun 2014: ada kebutuhan untuk skala penyimpanan analitis klasik dan pelaporan BI atasnya. Pada saat itu, pemrosesan data dan mesin BI adalah SAS - itu terjadi secara historis. Dan meskipun kebutuhan bisnis untuk penyimpanan ditutup, seiring berjalannya waktu, fungsionalitas BI dan analitik ad-hoc di atas penyimpanan analitis tumbuh sangat banyak sehingga perlu untuk menyelesaikan masalah peningkatan produktivitas, mengingat bahwa selama bertahun-tahun jumlah pengguna meningkat sepuluh kali lipat dan terus tumbuh.
Sebagai hasil dari kontes, sistem MPP Teradata muncul di MTS, yang mencakup kebutuhan telekomunikasi pada waktu itu. Ini adalah dorongan untuk mencoba sesuatu yang lebih populer dan open source.
 Dalam foto - tim Big Data MTS di kantor Descartes baru di Moskow
Dalam foto - tim Big Data MTS di kantor Descartes baru di Moskow Cluster pertama terdiri dari 7 node. Ini cukup untuk menguji beberapa hipotesis bisnis dan mengisi benjolan pertama. Upaya tidak sia-sia: Big Data telah ada di MTS selama tiga tahun dan sekarang analisis data terlibat di hampir semua bidang fungsional. Tim tumbuh dari tiga menjadi dua ratus.
Kami ingin memiliki proses pengembangan yang mudah, cepat menguji hipotesis. Untuk melakukan ini, Anda memerlukan tiga hal: tim dengan pemikiran startup, proses pengembangan yang ringan, dan infrastruktur yang dikembangkan. Ada banyak tempat di mana Anda dapat membaca dan mendengarkan tentang yang pertama dan kedua, tetapi ada baiknya menceritakan tentang infrastruktur yang dikembangkan secara terpisah, karena warisan dan sumber data yang ada dalam telekomunikasi penting di sini. Infrastruktur data yang dikembangkan tidak hanya membangun danau data, lapisan data terperinci, dan lapisan etalase. Ini juga termasuk alat dan antarmuka akses data, isolasi sumber daya komputasi untuk produk dan perintah, mekanisme untuk mengirimkan data ke konsumen - baik secara real-time dan dalam mode batch. Dan masih banyak lagi.
Semua pekerjaan ini telah menonjol di area yang terpisah, yang bergerak dalam pengembangan utilitas dan alat data. Area ini disebut platform Big Data IT.
Dari mana Big Data berasal dari MTS
MTS memiliki banyak sumber data. Salah satu yang utama adalah BTS, kami melayani basis pelanggan lebih dari 78 juta pelanggan di Rusia. Kami juga memiliki banyak layanan yang tidak terkait dengan telekomunikasi dan memungkinkan Anda menerima lebih banyak data serbaguna (e-commerce, integrasi sistem, Internet barang, layanan cloud, dll. - semua "non-telekomunikasi" telah menghasilkan sekitar 20% dari seluruh pendapatan).
Secara singkat, arsitektur kami dapat direpresentasikan sebagai grafik:
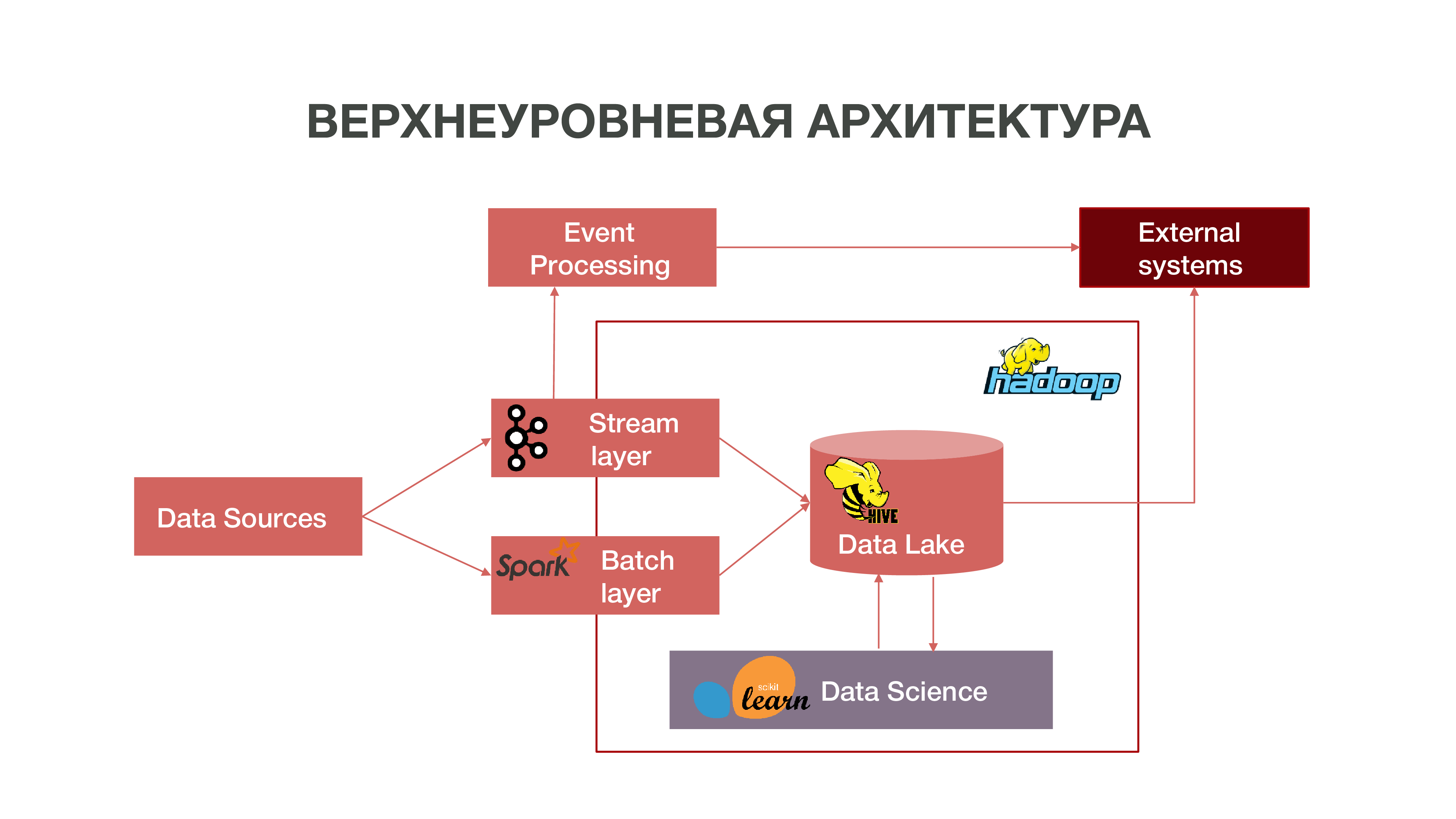
Seperti yang Anda lihat pada grafik, Datasources dapat mengirimkan informasi secara real time. Kami menggunakan layer stream - kami dapat memproses informasi real-time, mengekstrak darinya beberapa peristiwa yang menarik bagi kami, dan membangun analitik atas hal ini. Untuk menyediakan pemrosesan acara semacam itu, kami telah mengembangkan implementasi yang cukup standar (dari sudut pandang arsitektur) menggunakan Apache Kafka, Apache Spark dan kode dalam bahasa Scala. Informasi yang diperoleh sebagai hasil dari analisis tersebut dapat dikonsumsi baik di dalam MTS dan di masa depan di luar: bisnis sering kali tertarik pada fakta tindakan pelanggan tertentu.
Ada juga mode memuat data dalam batch - layer batch. Biasanya, unduhan terjadi sekali dalam satu jam pada jadwal, kami menggunakan Apache Airflow sebagai penjadwal, dan proses unduhan batch sendiri diimplementasikan dalam python. Dalam hal ini, sejumlah besar data secara signifikan dimuat ke Data Lake, yang diperlukan untuk mengisi Big Data dengan data historis, di mana model Ilmu Data kami harus dilatih. Akibatnya, profil pelanggan dibentuk dalam konteks historis berdasarkan data pada aktivitas jaringannya. Ini memungkinkan kami untuk mendapatkan statistik prediksi dan membangun model perilaku manusia, bahkan membuat potret psikologisnya - kami memiliki produk yang terpisah. Informasi ini sangat berguna, misalnya, untuk perusahaan pemasaran.
Kami juga memiliki sejumlah besar data yang membentuk repositori klasik. Artinya, kami mengumpulkan informasi tentang berbagai peristiwa - baik pengguna dan jaringan. Semua data yang dianonimkan ini juga membantu untuk secara lebih akurat memprediksi minat dan peristiwa pengguna yang penting bagi perusahaan - misalnya, untuk memperkirakan kemungkinan kegagalan peralatan dan pemecahan masalah pada waktunya.
Hadoop
Jika Anda melihat ke masa lalu dan mengingat bagaimana data besar muncul secara umum, harus dicatat bahwa pada dasarnya akumulasi data dilakukan untuk tujuan pemasaran. Tidak ada definisi yang jelas tentang apa itu big data - itu gigabyte, terabytes, petabytes. Tidak mungkin menggambar garis. Untuk beberapa, data besar adalah puluhan gigabyte, untuk yang lain, petabytes.
Kebetulan dari waktu ke waktu banyak data telah terakumulasi di seluruh dunia. Dan untuk melakukan beberapa jenis analisis yang kurang lebih signifikan dari data ini, repositori biasa yang telah berkembang sejak tahun 70-an abad terakhir tidak lagi cukup. Ketika poros informasi dimulai pada tahun 2000-an, 10-an dan ketika ada banyak perangkat yang memiliki akses Internet, ketika Internet hal-hal muncul, repositori ini tidak bisa menangani secara konseptual. Dasar dari repositori ini adalah teori relasional. Artinya, ada hubungan berbagai bentuk yang saling berinteraksi. Ada sistem untuk menggambarkan bagaimana membangun dan merancang repositori.
Ketika teknologi lama gagal, yang baru muncul. Di dunia modern, masalah analitik data besar diselesaikan dengan dua cara:
Membuat kerangka kerja Anda sendiri yang memungkinkan Anda memproses informasi dalam jumlah besar. Biasanya ini adalah aplikasi terdistribusi dari ratusan ribu server - seperti Google, Yandex, yang telah membuat database terdistribusi sendiri yang memungkinkan Anda untuk bekerja dengan volume informasi yang sedemikian besar.
Pengembangan teknologi Hadoop adalah kerangka komputasi terdistribusi, sistem file terdistribusi yang dapat menyimpan dan memproses informasi yang sangat besar. Perangkat Ilmu Data terutama kompatibel dengan Hadoop dan kompatibilitas ini membuka banyak kemungkinan untuk analisis data lanjutan. Banyak perusahaan, termasuk kita, bergerak menuju ekosistem Hadoop open source.
Cluster Hadoop pusat terletak di Nizhny Novgorod. Ini mengumpulkan informasi dari hampir semua wilayah negara. Dari segi volume, sekitar 8,5 petabyte data sekarang dapat diunduh di sana. Juga di Moskow, kami memiliki kelompok RND terpisah tempat kami melakukan eksperimen.
Karena kami memiliki sekitar seribu server di berbagai wilayah, tempat kami melakukan analisis, serta perluasan direncanakan, muncul pertanyaan tentang pilihan peralatan yang tepat untuk sistem analitik terdistribusi. Anda dapat membeli peralatan yang cukup untuk penyimpanan data, tetapi yang ternyata tidak sesuai untuk analitik - hanya karena tidak akan ada sumber daya yang cukup, jumlah core CPU dan RAM gratis pada node. Penting untuk menemukan keseimbangan untuk mendapatkan peluang analitik yang baik dan biaya peralatan yang tidak terlalu tinggi.
Intel menawarkan kepada kami berbagai opsi tentang cara mengoptimalkan kerja dengan sistem terdistribusi sehingga analitik dalam volume data kami dapat diperoleh dengan uang yang masuk akal. Intel Memajukan Teknologi NAND SSD Solid State Drive Ini ratusan kali lebih cepat daripada HDD biasa. Daripada itu baik untuk kita: SSD, terutama dengan antarmuka NVMe, menyediakan akses cepat ke data.
Plus, Intel telah merilis SSD server Intel Optane SSD berdasarkan tipe baru dari memori non-volatile Intel 3D XPoint. Mereka mengatasi beban campuran intensif pada sistem penyimpanan, dan memiliki sumber daya yang lebih lama daripada NAND SSD biasa. Mengapa ini baik bagi kami: Intel Optane SSD memungkinkan Anda untuk bekerja secara stabil di bawah beban berat dengan latensi rendah. Kami awalnya melihat NAND SSD sebagai pengganti hard drive tradisional, karena kami memiliki sejumlah besar data yang bergerak antara hard drive dan RAM - dan kami perlu mengoptimalkan proses ini.
Tes pertama
Tes pertama yang kami lakukan pada tahun 2016. Kami baru saja mengambil dan mencoba mengganti HDD dengan NAND SSD yang cepat. Untuk melakukan ini, kami memesan sampel drive Intel baru - pada waktu itu adalah DC P3700. Dan mereka menjalankan tes standar Hadoop - sebuah ekosistem yang memungkinkan Anda mengevaluasi bagaimana kinerja berubah dalam kondisi yang berbeda. Ini adalah tes standar TeraGen, TeraSort, TeraValidate.

TeraGen memungkinkan Anda untuk "menghasilkan" data buatan volume tertentu. Misalnya, kami mengambil 1 GB dan 1 TB. Dengan TeraSort, kami mengurutkan jumlah data ini di Hadoop. Ini adalah operasi yang cukup intensif sumber daya. Dan tes terakhir - TeraValidate - memungkinkan Anda untuk memastikan bahwa data diurutkan dalam urutan yang benar. Artinya, kita melewati mereka untuk kedua kalinya.

Sebagai percobaan, kami hanya mengambil mobil dengan SSD - yaitu, Hadoop dipasang hanya pada SSD tanpa menggunakan hard drive. Dalam versi kedua, kami menggunakan SSD untuk menyimpan file sementara, HDD - untuk menyimpan data dasar. Dan di versi ketiga, hard drive digunakan untuk keduanya.
Hasil percobaan ini tidak terlalu menyenangkan bagi kami, karena perbedaan dalam indikator kinerja tidak melebihi 10-20%. Artinya, kami menyadari bahwa Hadoop tidak terlalu ramah dengan SSD dalam hal penyimpanan, karena pada awalnya sistem ini dibuat untuk menyimpan data besar pada HDD, dan tidak ada yang mengoptimalkannya terutama untuk SSD yang cepat dan mahal. Dan karena biaya SSD pada saat itu cukup tinggi, kami memutuskan sejauh ini untuk tidak masuk ke cerita ini dan bertahan dengan hard drive.
Tes kedua
Kemudian, Intel memperkenalkan Intel Optane SSD sisi server baru berbasis memori 3D XPoint. Mereka dirilis pada akhir 2017, tetapi sampel tersedia untuk kami sebelumnya. Fitur memori 3D XPoint memungkinkan untuk menggunakan Intel Optane SSD sebagai ekstensi RAM di server. Karena kami sudah menyadari bahwa tidak mudah untuk menyelesaikan masalah kinerja IO Hadoop di tingkat perangkat penyimpanan blok, kami memutuskan untuk mencoba opsi baru - memperluas RAM menggunakan Intel Memory Drive Technology (IMDT). Dan pada awal tahun ini, kami adalah salah satu yang pertama di dunia yang mengujinya.
Ini lebih baik bagi kami: lebih murah daripada RAM, yang memungkinkan Anda mengumpulkan server yang memiliki terabyte RAM. Dan karena RAM cukup cepat, Anda dapat memuat set data besar ke dalamnya dan menganalisisnya. Biarkan saya mengingatkan Anda bahwa kekhasan proses analitik kami adalah bahwa kami mengakses data beberapa kali. Untuk melakukan beberapa jenis analisis, kita perlu memuat sebanyak mungkin data ke dalam memori dan "menggulir" beberapa jenis analisis data ini beberapa kali.
Laboratorium Intel English di Swindon mengalokasikan kami satu cluster yang terdiri dari tiga server, yang selama pengujian kami membandingkannya dengan cluster pengujian kami yang berlokasi di MTS.

Seperti yang bisa dilihat dari grafik, berdasarkan hasil tes, kami mendapat hasil yang cukup baik.
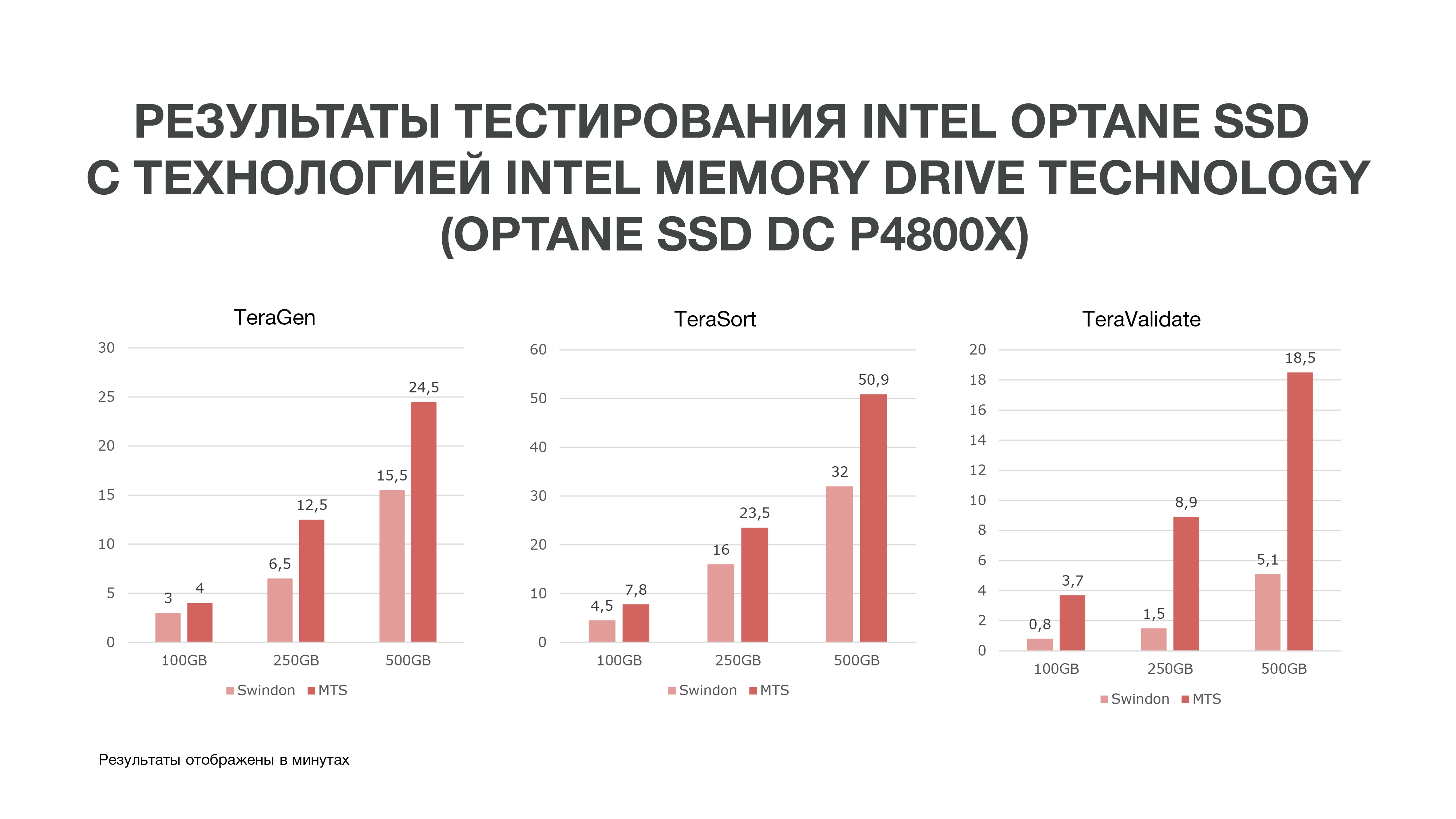
TeraGen yang sama menunjukkan peningkatan hampir dua kali lipat dalam produktivitas, TeraValidate - sebesar 75%. Ini sangat baik bagi kami, karena, seperti yang saya katakan, kami mengakses data yang kami miliki di memori kami beberapa kali. Dengan demikian, jika kita mendapatkan peningkatan kinerja seperti itu, itu akan sangat membantu kita dalam analisis data, terutama dalam waktu nyata.
Kami melakukan tiga tes dalam kondisi yang berbeda. 100 GB, 250 GB, dan 500 GB. Dan semakin banyak kami menggunakan memori, Intel Optane SSD dengan Intel Memory Drive Technology tampil lebih baik. Artinya, semakin banyak data yang kami analisis, semakin banyak kami mendapatkan efisiensi. Analisis yang terjadi pada lebih banyak node dapat terjadi pada lebih sedikit. Dan kami juga mendapatkan jumlah memori yang cukup besar pada mesin kami, yang sangat bagus untuk tugas-tugas Ilmu Data. Berdasarkan hasil pengujian, kami memutuskan untuk membeli drive ini untuk bekerja di MTS.
Jika Anda juga harus memilih dan menguji perangkat keras untuk menyimpan dan memproses sejumlah besar data, kami akan tertarik untuk membaca kesulitan apa yang Anda temui dan hasil apa yang Anda dapatkan: tulis di komentar.
Penulis:
Grigory Koval, kepala Pusat Kompetensi Arsitektur Terapan Departemen Data Besar MTS, grigory_koval
Kepala suku manajemen data Big Data Departemen MTS Dmitry Shostko zloi_diman