
Saya memasuki Tim Inti Tarantool dan berpartisipasi dalam pengembangan mesin basis data, komunikasi internal komponen server dan replikasi. Dan hari ini saya akan memberi tahu Anda bagaimana replikasi bekerja.
Tentang replikasi
Replikasi adalah proses membuat salinan data dari satu toko ke toko lain. Setiap salinan disebut replika. Replikasi dapat digunakan jika Anda perlu mendapatkan cadangan, menerapkan hot siaga atau skala sistem secara horizontal. Dan untuk ini perlu untuk dapat menggunakan data yang sama pada node yang berbeda dari jaringan komputer cluster.
Kami mengklasifikasikan replikasi dalam dua cara utama:
- Arah: master-master atau master-slave . Replikasi master-slave adalah pilihan termudah. Anda memiliki satu simpul di mana Anda mengubah data. Anda menerjemahkan perubahan ini ke node lain di mana mereka diterapkan. Dengan replikasi master-master, perubahan dilakukan ke beberapa node sekaligus. Dalam hal ini, setiap node mengubah datanya sendiri dan menerapkan perubahan yang dibuat ke node lain untuk dirinya sendiri.
- Mode operasi: asinkron atau sinkron . Replikasi sinkron menyiratkan bahwa data tidak akan dilakukan dan replikasi tidak akan dikonfirmasi kepada pengguna sampai perubahan disebarkan melalui setidaknya jumlah minimum node cluster. Dalam replikasi asinkron, melakukan transaksi (melakukan itu) dan berinteraksi dengan pengguna adalah dua proses independen. Untuk mengkomit data, itu hanya perlu bahwa mereka jatuh ke dalam log lokal, dan hanya kemudian perubahan ini ditransmisikan dalam beberapa cara ke node lain. Jelas, replikasi asinkron memiliki sejumlah efek samping karena ini.
Bagaimana cara replikasi bekerja di Tarantool?
Replikasi di Tarantool memiliki beberapa fitur:
- Itu dibangun dari batu bata dasar, dengan mana Anda dapat membuat sekelompok topologi apa pun. Setiap item konfigurasi dasar tersebut adalah searah, yaitu, Anda selalu memiliki master dan slave. Master melakukan beberapa tindakan dan menghasilkan log operasi, yang digunakan pada replika.
- Replikasi Tarantool tidak sinkron. Yaitu, sistem mengonfirmasi komitmen kepada Anda, terlepas dari berapa banyak replika yang dilihat transaksi ini, berapa banyak itu diterapkan pada dirinya sendiri, dan apakah ternyata dilakukan sama sekali.
- Properti lain dari replikasi di Tarantool adalah bahwa ia berbasis baris. Tarantool menyimpan log operasi (WAL). Operasi sampai di sana baris demi baris, yaitu, ketika beberapa tapla dari ruang berubah, operasi ini ditulis ke log sebagai satu baris. Setelah itu, proses latar belakang membaca baris ini dari log dan mengirimkannya ke replika. Berapa banyak replika yang dimiliki master, begitu banyak proses latar belakang. Artinya, setiap proses replikasi ke node yang berbeda dari cluster dilakukan secara asinkron dari yang lain.
- Setiap node cluster memiliki pengenal uniknya sendiri, yang dihasilkan ketika node dibuat. Selain itu, node juga memiliki pengidentifikasi di cluster (nomor anggota). Ini adalah konstanta numerik yang ditugaskan untuk replika ketika terhubung ke sebuah cluster, dan tetap dengan replika sepanjang hidupnya di cluster.
Karena tidak sinkron, data dikirim ke replika yang tertunda. Artinya, Anda membuat beberapa perubahan, sistem mengkonfirmasi komit, operasi sudah diterapkan pada master, tetapi pada replika itu akan diterapkan dengan beberapa penundaan, yang ditentukan oleh kecepatan proses replikasi latar belakang membaca operasi, mengirimkannya ke replika, dan yang berlaku .
Karena itu, ada kemungkinan data tidak sinkron. Misalkan kita memiliki beberapa master yang mengubah data yang saling berhubungan. Mungkin ternyata operasi yang Anda gunakan adalah non-komutatif dan merujuk ke data yang sama, maka dua anggota cluster yang berbeda akan memiliki versi data yang berbeda.
Jika replikasi di Tarantool adalah master-slave searah, lalu bagaimana membuat master-master? Sangat sederhana: buat saluran replikasi lain tetapi ke arah lain. Anda perlu memahami bahwa di Tarantool, replikasi master-master hanyalah kombinasi dari dua aliran data yang independen satu sama lain.
Dengan menggunakan prinsip yang sama, kita dapat menghubungkan master ketiga, dan sebagai hasilnya membangun jaringan mesh penuh di mana setiap replika adalah master dan slave untuk semua replika lainnya.
Harap dicatat bahwa tidak hanya operasi yang diprakarsai secara lokal pada master ini direplikasi, tetapi juga operasi yang ia terima secara eksternal melalui protokol replikasi. Dalam hal ini, perubahan yang dibuat pada replika No. 1 akan menjadi replika No. 3 dua kali: secara langsung dan melalui replika No. 2. Properti ini memungkinkan kita untuk membangun topologi yang lebih kompleks tanpa menggunakan mesh penuh. Katakanlah yang ini.
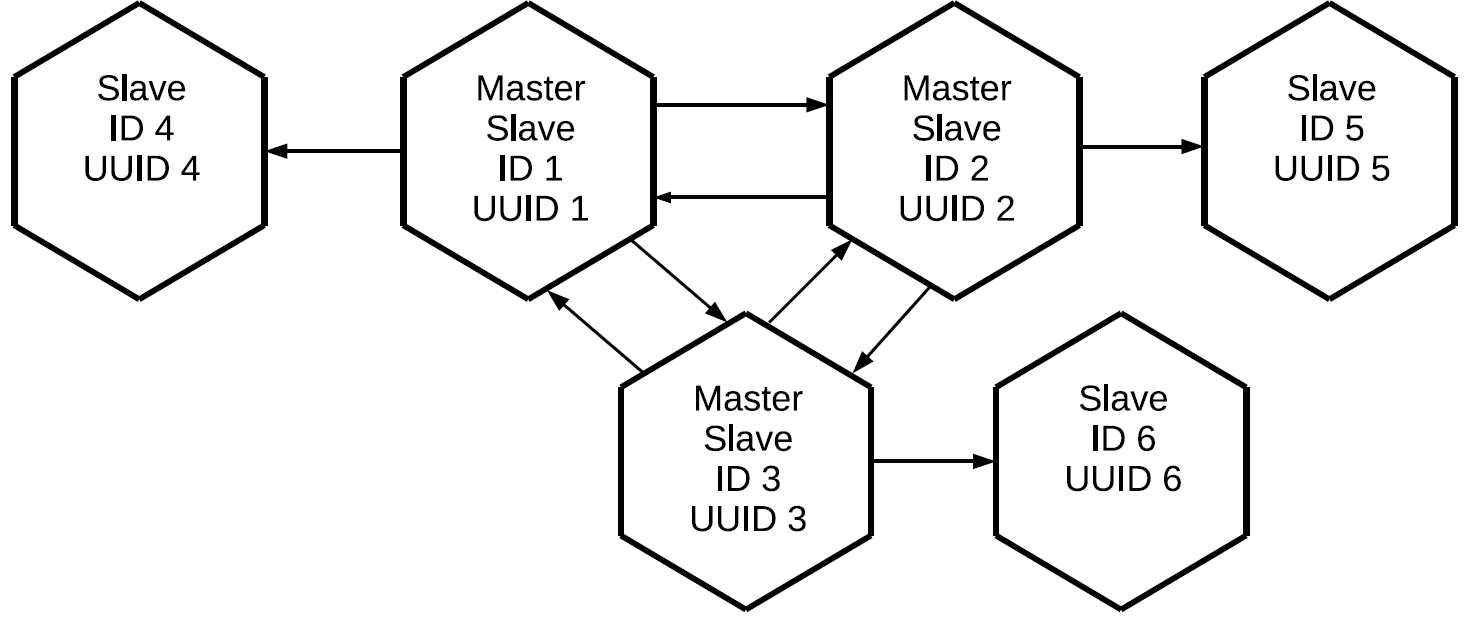
Ketiga master, yang bersama-sama membentuk inti mesh penuh dari cluster, memiliki replika individu. Karena proksi log dilakukan pada masing-masing master, ketiga "bersih" budak akan berisi semua operasi yang dilakukan pada salah satu node cluster.
Konfigurasi ini dapat digunakan untuk berbagai tugas. Anda tidak dapat membuat tautan mubazir di antara semua node cluster, dan jika replika ditempatkan di dekatnya, mereka akan memiliki salinan master yang tepat dengan penundaan minimal. Dan semua ini dilakukan dengan menggunakan elemen replikasi master-slave dasar.
Pelabelan Operasi Cluster
Timbul pertanyaan:
jika operasi diproksikan antara semua anggota cluster dan datang ke setiap replika beberapa kali, bagaimana kita memahami operasi yang perlu dilakukan dan yang tidak? Ini membutuhkan mekanisme penyaringan. Setiap operasi yang dibaca dari log diberikan dua atribut:
- Pengidentifikasi server tempat operasi ini dimulai.
- Nomor urut operasi di server, lsn, yang merupakan penggagasnya. Setiap server, ketika melakukan operasi, memberikan angka yang meningkat untuk setiap baris log yang diterima: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ... Jadi, jika kita tahu bahwa untuk server dengan pengidentifikasi tertentu, kami menerapkan operasi dengan NSN 10, maka operasi dengan NSN 9, 8, 7, 10 yang datang melalui saluran replikasi lainnya tidak diperlukan. Sebagai gantinya, kami menerapkan yang berikut: 11, 12, dan seterusnya.
Status Replika
Dan bagaimana Tarantool menyimpan informasi tentang operasi yang telah diterapkan? Untuk melakukan ini, ada jam Vclock - ini adalah vektor dari lsn terakhir yang diterapkan ke setiap node di cluster.
[lsn 1 , lsn 2 , lsn n ]di mana
lsn i adalah nomor dari operasi terakhir yang diketahui dari server dengan identifier i.
Vclock juga bisa disebut snapshot tertentu dari seluruh negara cluster yang diketahui replika ini. Mengetahui ID server dari operasi yang telah tiba, kami mengisolasi komponen Vclock lokal yang kami butuhkan, membandingkan lsn yang diterima dengan operasi lsn, dan memutuskan apakah akan menggunakan operasi ini. Akibatnya, operasi yang diprakarsai oleh master tertentu akan dikirim dan diterapkan secara berurutan. Pada saat yang sama, alur kerja yang dibuat pada master yang berbeda dapat dicampur satu sama lain karena replikasi asinkron.
Penciptaan Cluster
Misalkan kita memiliki sebuah cluster yang terdiri dari dua elemen master dan slave, dan kita ingin menghubungkan instance ketiga ke dalamnya. Ini memiliki UUID yang unik, tetapi belum ada pengidentifikasi kluster. Jika Tarantool belum diinisialisasi, ingin bergabung dengan klaster, ia harus mengirim operasi GABUNG ke salah satu master yang dapat melakukan itu, yaitu, berada dalam mode baca-tulis. Menanggapi BERGABUNG, master mengirimkan snapshot lokalnya ke replika penghubung. Replika menggulungnya di rumah, sementara itu masih tidak memiliki pengenal. Sekarang replika dengan sedikit lag disinkronkan dengan cluster. Setelah itu, master tempat JOIN dijalankan menjalankan pengidentifikasi untuk replika ini, yang dicatat dan dikirim ke replika. Ketika pengidentifikasi ditugaskan untuk replika, itu menjadi simpul penuh dan setelah itu dapat memulai replikasi log ke sisinya.
Baris dari jurnal dikirim mulai dari keadaan replika ini pada saat meminta log replikasi dari master - yaitu, dari jam yang diterima selama proses GABUNG, atau dari tempat replika berhenti sebelumnya. Jika replika telah jatuh karena suatu alasan, maka saat berikutnya terhubung ke cluster, itu tidak lagi BERGABUNG, karena sudah memiliki snapshot lokal. Dia hanya meminta semua operasi yang terjadi selama ketidakhadirannya di cluster.
Daftarkan replika di sebuah cluster
Untuk menyimpan keadaan tentang struktur cluster, ruang khusus digunakan - cluster. Ini berisi pengidentifikasi server di cluster, nomor seri dan pengidentifikasi unik.
[1, 'c35b285c-c5b1-4bbe-83b1-b825eb594aa4']
[2, '37b12cb7-d324-4d75-b428-cde92c18e708']
[3, 'b72b1aa6-42a0-4d73-a611-900e44cdd465']Pengidentifikasi tidak diharuskan untuk masuk, karena node dapat dihapus dan ditambahkan.
Inilah jebakan pertama. Sebagai aturan, cluster tidak dikumpulkan oleh satu node: Anda menjalankan aplikasi tertentu dan menyebarkan seluruh cluster sekaligus. Tetapi replikasi di Tarantool tidak sinkron. Bagaimana jika dua master secara bersamaan menghubungkan node baru dan menetapkan pengidentifikasi identik untuk mereka? Akan ada konflik.
Berikut adalah contoh GABUNG yang salah dan benar:

Kami memiliki dua master dan dua replika yang ingin terhubung. Mereka membuat GABUNG pada master yang berbeda. Misalkan replika mendapatkan pengidentifikasi yang sama. Kemudian replikasi antara master dan mereka yang berhasil mereplikasi log mereka akan berantakan, gugus akan berantakan.
Untuk mencegah hal ini terjadi, Anda harus memulai replika dengan ketat pada satu master setiap saat. Untuk tujuan ini, Tarantool memperkenalkan konsep seperti itu sebagai pemimpin inisialisasi, dan menerapkan algoritma untuk memilih pemimpin ini. Replika yang ingin terhubung ke cluster pertama kali membuat koneksi dengan semua master yang dikenal dari konfigurasi yang ditransfer. Kemudian replika memilih orang-orang yang telah diinisiasi (ketika menggunakan cluster, tidak semua node berhasil menghasilkan uang penuh). Dan dari mereka para master yang tersedia untuk rekaman dipilih. Di Tarantool, ada read-write dan read only, kita tidak bisa mendaftar pada node read only. Setelah itu, dari daftar node yang difilter, kami memilih salah satu yang memiliki UUID terendah.
Jika kita menggunakan konfigurasi yang sama dan daftar server yang sama pada instance yang tidak diinisialisasi yang terhubung ke cluster, maka mereka akan memilih master yang sama, yang berarti GABUNG kemungkinan besar akan berhasil.
Dari sini kita memperoleh aturan: saat menghubungkan replika ke sebuah cluster secara paralel, semua replika ini harus memiliki konfigurasi replikasi yang sama. Jika kita menghilangkan sesuatu di suatu tempat, maka ada kemungkinan instance dengan konfigurasi yang berbeda akan dimulai pada master yang berbeda dan cluster tidak akan dapat berkumpul.
Misalkan kita salah, atau admin lupa untuk memperbaiki konfigurasi, atau Ansible rusak, dan gugus masih berantakan. Apa yang bisa membuktikan hal ini? Pertama, replika pluggable tidak akan dapat membuat snapshot lokal mereka: replika tidak memulai dan melaporkan kesalahan. Kedua, pada master dalam log, kita akan melihat kesalahan terkait dengan konflik di cluster ruang.
Bagaimana kita mengatasi situasi ini? Sederhana:
- Pertama-tama, kita perlu memvalidasi konfigurasi yang kita atur untuk replika penghubung, karena jika kita tidak memperbaikinya, maka semua yang lain akan menjadi tidak berguna.
- Setelah itu, kami membersihkan konflik di cluster dan mengambil gambar.
Sekarang Anda dapat mencoba menginisialisasi replika lagi.
Resolusi Konflik
Jadi, kami membuat cluster dan terhubung. Semua node bekerja dalam mode berlangganan, yaitu, mereka menerima perubahan yang dihasilkan oleh master yang berbeda. Karena replikasi asinkron, konflik mungkin terjadi. Ketika Anda secara bersamaan mengubah data pada master yang berbeda, replika yang berbeda mendapatkan salinan data yang berbeda, karena operasi dapat diterapkan dalam urutan yang berbeda.
Berikut adalah contoh kluster setelah menjalankan GABUNG:
Kami memiliki tiga master-slave, log ditransmisikan di antara mereka, yang diproksikan dalam arah yang berbeda dan diterapkan pada slave. Data tidak sinkron berarti bahwa setiap replika akan memiliki riwayat perubahan vclock sendiri, karena aliran dari master yang berbeda dapat dicampur bersama. Tetapi kemudian urutan operasi pada instance dapat bervariasi. Jika operasi kami tidak komutatif, seperti operasi REPLACE, maka data yang kami terima pada replika ini akan berbeda.
Contoh kecil. Misalkan kita memiliki dua tuan dengan vclock = {0,0}. Dan keduanya akan melakukan dua operasi, yang ditunjuk sebagai op1, 1, op1, 2, op2, 1. Ini adalah irisan kedua kalinya ketika masing-masing master melakukan satu operasi lokal:

Hijau menunjukkan perubahan pada komponen vclock yang sesuai. Pertama, kedua tuan mengubah jam mereka, dan kemudian tuan kedua melakukan operasi lokal lain dan sekali lagi meningkatkan jam. Master pertama menerima operasi replikasi dari master kedua, ini ditunjukkan dengan angka merah 1 pada jam node cluster pertama.

Kemudian master kedua menerima operasi dari yang pertama, dan yang pertama - operasi kedua dari yang kedua. Dan pada akhirnya, master pertama melakukan operasi terakhirnya, dan master kedua menerimanya.

Vclock dalam nol waktu kuantum kita memiliki yang sama - {0,0}. Pada kuantum terakhir waktu, kita juga memiliki jam yang sama {2,2}, akan terlihat bahwa data harus sama. Tetapi urutan operasi yang dilakukan pada masing-masing master berbeda. Dan jika ini adalah operasi REPLACE dengan nilai yang berbeda untuk kunci yang sama? Kemudian, meskipun pada jam yang sama pada akhirnya, kami akan mendapatkan versi data yang berbeda pada kedua replika.
Kami juga dapat menyelesaikan situasi ini.
- Catatan serpihan . Pertama, kita dapat melakukan operasi penulisan bukan pada replika yang dipilih secara acak, tetapi entah bagaimana membuangnya. Mereka baru saja memecahkan operasi penulisan di berbagai master dan akhirnya mendapatkan sistem konsistensi. Misalnya, kunci telah berubah dari 1 menjadi 10 pada satu master dan dari 11 menjadi 20 pada master lainnya - node akan bertukar log mereka dan mendapatkan data yang persis sama.
Sharding menyiratkan bahwa kita memiliki router tertentu. Tidak harus menjadi entitas yang terpisah sama sekali, router dapat menjadi bagian dari aplikasi. Ini bisa berupa beling yang menerapkan operasi tulis untuk dirinya sendiri atau mentransfernya ke master lain dengan satu atau lain cara. Tapi itu berlalu sedemikian rupa sehingga perubahan dalam nilai yang terkait pergi ke beberapa master tertentu: satu blok nilai pergi ke satu master, blok lain ke master lain. Dalam hal ini, operasi baca dapat dikirim ke sembarang simpul dalam gugus. Dan jangan lupa tentang replikasi asinkron: jika Anda merekam pada master yang sama, maka Anda mungkin juga perlu membacanya.
- Urutan operasi yang logis . Misalkan sesuai dengan kondisi masalah, Anda entah bagaimana dapat menentukan prioritas operasi. Katakan, letakkan stempel waktu, atau versi, atau label lain yang memungkinkan kita untuk memahami operasi mana yang terjadi secara fisik sebelumnya. Artinya, kita berbicara tentang sumber pemesanan eksternal.
Tarantool memiliki pemicu before_replace yang dapat dieksekusi selama replikasi. Dalam hal ini, kami tidak dibatasi oleh kebutuhan untuk merutekan permintaan, kami dapat mengirimkannya ke mana pun kami inginkan. Tetapi ketika melakukan replikasi pada input aliran data, kami memiliki pemicu. Dia membaca baris yang dikirim, membandingkannya dengan baris yang sudah disimpan, dan memutuskan baris mana yang memiliki prioritas lebih tinggi. Yaitu, pemicu mengabaikan permintaan replikasi, atau menerapkannya, mungkin dengan modifikasi yang diperlukan. Kami sudah menerapkan pendekatan ini, meskipun juga memiliki kelemahan. Pertama, Anda memerlukan sumber jam eksternal. Misalkan seorang operator di salon telepon seluler membuat perubahan pada pelanggan. Untuk operasi seperti itu, Anda dapat menggunakan waktu di komputer operator, karena tidak mungkin beberapa operator akan melakukan perubahan pada satu pelanggan pada saat yang sama. Operasi dapat dilakukan dengan cara yang berbeda, tetapi jika masing-masing dapat diberikan versi tertentu, maka ketika melewati pemicu hanya yang relevan yang akan tetap ada.
Kelemahan kedua metode ini: karena pemicu diterapkan ke setiap delta yang datang dengan replikasi untuk setiap permintaan, ini menciptakan beban komputasi ekstra. Tapi kemudian kita akan memiliki salinan data yang konsisten pada skala cluster.
Sinkronkan
Replikasi kami asinkron, yaitu, dengan melakukan eksekusi Anda tidak tahu apakah data ini sudah ada di beberapa node cluster lainnya. Jika Anda membuat komit pada master, itu dikonfirmasi kepada Anda, dan master untuk beberapa alasan segera berhenti bekerja, maka Anda tidak dapat memastikan bahwa data telah disimpan di tempat lain. Untuk mengatasi masalah ini, protokol replikasi Tarantool memiliki ACK. Setiap master memiliki pengetahuan tentang ACK terakhir yang berasal dari masing-masing budak.
Apa itu ACK? Ketika slave menerima delta, yang ditandai dengan master lsn dan pengenalnya, maka sebagai responsnya ia mengirim paket ACK khusus, di mana ia mengemas jam lokalnya setelah menerapkan operasi ini. Mari kita lihat bagaimana ini bisa bekerja.
Kami memiliki master yang melakukan 4 operasi dalam dirinya sendiri. Misalkan pada suatu waktu slave slave menerima tiga baris pertama dan jamnya meningkat menjadi {3.0}.
ACK belum tiba. Setelah menerima tiga baris ini, slave mengirimkan paket ACK yang telah dijahit jamnya pada saat paket itu dikirim. Biarkan master-budak mengirim baris lain dalam slot waktu yang sama, yaitu, jam kerja budak telah meningkat. Berdasarkan hal ini, master No. 1 tahu pasti bahwa tiga operasi pertama yang dia lakukan telah diterapkan pada budak ini. Status ini disimpan untuk semua budak yang bekerja sama dengan master, mereka sepenuhnya independen.
Dan pada akhirnya, budak merespons dengan paket ACK keempat. Setelah itu, master tahu bahwa budak disinkronkan dengannya.
Mekanisme ini dapat digunakan dalam kode aplikasi. Ketika Anda melakukan operasi, Anda tidak segera mengakui pengguna, tetapi pertama-tama memanggil fungsi khusus. Itu menunggu budak lsn yang dikenal oleh master sama dengan lsn tuanmu pada saat komit selesai. Jadi Anda tidak perlu menunggu sinkronisasi penuh, tunggu saja momen yang disebutkan.
Misalkan panggilan pertama kita telah berubah tiga baris, dan panggilan kedua telah berubah satu. Setelah panggilan pertama, Anda ingin memastikan bahwa data disinkronkan. Keadaan yang ditunjukkan di atas sudah berarti bahwa panggilan pertama disinkronkan pada setidaknya satu budak.
Di mana tepatnya mencari informasi tentang ini, kami akan mempertimbangkan di bagian selanjutnya.
Pemantauan
Ketika replikasi sinkron, pemantauan sangat sederhana: jika berantakan, kesalahan dikeluarkan untuk operasi Anda. Dan jika replikasi asinkron, maka situasinya menjadi membingungkan. Guru menjawab Anda bahwa semuanya baik-baik saja, berfungsi, diterima, dituliskan. Tetapi pada saat yang sama, semua replika mati, data tidak memiliki redundansi, dan jika Anda kehilangan master, Anda akan kehilangan data. Oleh karena itu, saya benar-benar ingin memantau cluster, memahami apa yang terjadi dengan replikasi asinkron, di mana replika berada, dalam keadaan apa mereka berada.
Untuk pemantauan dasar, Tarantool memiliki entitas box.info. Layak menyebutnya di konsol, karena Anda akan melihat data menarik.
id: 1 uuid: c35b285c-c5b1-4bbe-83b1-b825eb594aa4 lsn : 5 vclock : {2: 1, 1: 5} replication : 1: id: 1 uuid : c35b285c -c5b1 -4 bbe -83b1 - b825eb594aa4 lsn : 5 2: id: 2 uuid : 37 b12cb7 -d324 -4 d75 -b428 - cde92c18e708 lsn : 1 upstream : status : follow idle : 0.30358312401222 peer : lag: 3.6001205444336 e -05 downstream : vclock : {2: 1, 1: 5}
Metrik yang paling penting adalah id
id . Dalam hal ini, 1 berarti bahwa lsn dari master ini akan disimpan pada posisi pertama dalam semua jam. Suatu hal yang sangat berguna. Jika Anda memiliki konflik dengan GABUNG, maka Anda dapat membedakan satu master dari yang lain hanya dengan pengidentifikasi unik. Juga, jumlah lokal termasuk jumlah seperti lsn. Ini adalah jumlah baris terakhir yang dieksekusi dan ditulis oleh master ini ke log-nya. Dalam contoh kami, master pertama melakukan lima operasi. Vclock adalah keadaan operasi yang dia tahu dia terapkan pada dirinya sendiri. Dan akhirnya, untuk master nomor 2, ia melakukan salah satu operasi replikasi.
Setelah indikator negara bagian, Anda dapat melihat apa yang diketahui oleh instance ini tentang keadaan replikasi cluster, karena ini, ada bagian
replication . Ini daftar semua node cluster yang dikenal untuk instance, termasuk dirinya sendiri. Node pertama memiliki pengidentifikasi 1, id terkait dengan instance saat ini. Node kedua memiliki pengidentifikasi 2, lsn 1 yang sesuai dengan lsn yang ditulis untuk vclock. Dalam hal ini, kami mempertimbangkan replikasi master-master, ketika master No. 1 adalah master untuk simpul kedua dari cluster dan slave-nya, yaitu, ia mengikutinya.
- Inti dari
upstream . Atribut status follow berarti bahwa master 1 mengikuti master 2. Idle adalah waktu yang telah dilewati secara lokal sejak interaksi terakhir dengan master ini. Kami tidak mengirim aliran secara terus menerus, master hanya mengirim delta ketika terjadi perubahan. Ketika kami mengirim semacam ACK, kami juga berkomunikasi. Jelas, jika idle menjadi besar (detik, menit, jam), maka ada sesuatu yang salah. - Atribut
lag . Kami berbicara tentang lag. Selain lsn dan server id setiap operasi dalam log juga ditandai dengan stempel waktu - waktu lokal di mana operasi ini direkam dalam jam pada master yang melakukan itu. Pada saat yang sama, Slave membandingkan stempel waktu lokalnya dengan stempel waktu delta yang ia terima. Stempel waktu terakhir saat ini diterima untuk baris terakhir, tampilan budak dalam pemantauan. - Atribut
downstream . Itu menunjukkan apa yang diketahui tuan tentang budak khususnya. Ini adalah ACK yang dikirim budak kepadanya. downstream disajikan di atas berarti bahwa terakhir kali budaknya, alias tuan di nomor 2, mengirimnya jam kerjanya, yaitu 5,1. Master ini tahu bahwa kelima barisnya, yang dia selesaikan di tempatnya, berangkat ke simpul lain.
Kerugian XLOG
Pertimbangkan situasi dengan jatuhnya master.
lsn : 0 id: 3 replication : 1: <...> upstream : status: disconnected peer : lag: 3.9100646972656 e -05 idle: 1602.836148153 message: connect, called on fd 13, aka [::1]:37960 2: <...> upstream : status : follow idle : 0.65611373598222 peer : lag: 1.9550323486328 e -05 3: <...> vclock : {2: 2, 1: 5}
Pertama-tama, statusnya akan berubah.
Lag tidak berubah karena garis yang kami terapkan tetap sama, kami tidak mendapatkan yang baru. Pada saat yang sama,
idle tumbuh, dalam hal ini sudah sama dengan 1602 detik, sehingga master waktu banyak yang mati. Dan kami melihat beberapa pesan kesalahan: tidak ada koneksi jaringan.
Apa yang harus dilakukan dalam situasi yang sama? Kami mencari tahu apa yang terjadi dengan master kami, menarik administrator, restart server, meningkatkan node. Replikasi berulang dilakukan, dan ketika master memasuki sistem, kami terhubung dengannya, berlangganan XLOG-nya, dapatkan sendiri dan kluster stabil.
Tapi ada satu masalah kecil. Bayangkan kita memiliki seorang budak, yang karena alasan tertentu dimatikan dan tidak ada untuk waktu yang lama. Selama waktu ini, master, yang menyajikannya, menghapus XLOG. Misalnya, disk penuh, pengumpul sampah telah mengumpulkan log. Bagaimana seorang budak yang kembali dapat melanjutkan? Tidak mungkin. Karena log yang dia perlu terapkan untuk disinkronkan dengan cluster hilang dan tidak ada tempat untuk mengambilnya. Dalam hal ini, kita akan melihat kesalahan yang menarik: status tidak lagi
disconnected , tetapi
stopped . Dan pesan tertentu: tidak ada file log yang cocok dengan lsn tersebut.
id: 3 replication : 1: <...> upstream : peer : status: stopped lag : 0.0001683235168457 idle : 9.4331328970147 message: 'Missing .xlog file between LSN 7 1: 5, 2: 2 and 8 1: 6, 2: 2' 2: <...> 3: <...> vclock : {2: 2, 1: 5}
Padahal, situasinya tidak selalu berakibat fatal. Misalkan kita memiliki lebih dari dua tuan, dan pada beberapa dari mereka log ini masih dipertahankan. Kami menuangkannya ke semua tuan sekaligus, dan tidak menyimpannya hanya pada satu. Kemudian ternyata replika ini, menghubungkan ke semua master yang dia kenal, pada beberapa dari mereka akan menemukan log yang dia butuhkan. Dia akan melakukan semua operasi ini di rumah, jam nya akan meningkat, dan dia akan mencapai kondisi saat ini dari cluster. Setelah itu, Anda dapat mencoba menyambung kembali.
Jika tidak ada log sama sekali, kami tidak dapat melanjutkan replika. Tetap hanya menginisialisasi ulang. Ingat pengenal uniknya, Anda dapat menuliskannya di selembar kertas atau dalam file. Kemudian kami membersihkan replika secara lokal: menghapus gambar, log, dan sebagainya. Setelah itu, hubungkan kembali replika dengan UUID yang sama seperti yang dimilikinya.
box.cfg{instance_uuid = uuid} cluster atau gunakan kembali UUID untuk replika baru:
box.cfg{instance_uuid = uuid} .
, . UUID space cluster, . , . UUID, master, JOIN, , UUID, , .
, UUID , space cluster , . . , , .
, - . , . , , .
Tarantool .
replication_connect_quorum: 2
replication_connect_timeout: 30
replication_sync_lag: 0.1, , , , , , master' 0,1 . 30 . , . 0,1 . , .
Keep alive
, ip tables drop. , - 30 30 , , . , keep alive-.
keep alive- :
box.cfg.replication_timeout .
master' , keep alive-, , . 4 master slave keep alive- , . master'.
, . 6 , 5 . 10 , 9 . .
, , . , master', . - . .
6 , 3. , . , 5 , 3 .
, :
, Telegram-, . , GitHub, .