Halo semuanya! Saya mempersembahkan untuk Anda terjemahan artikel Vidhya Analytics dengan ikhtisar acara AI / ML pada tren 2018 dan 2019. Bahannya cukup besar, sehingga dibagi menjadi 2 bagian. Saya harap artikel ini akan menarik minat tidak hanya spesialis spesialis, tetapi juga mereka yang tertarik dengan topik AI. Selamat membaca!
Pendahuluan
Beberapa tahun terakhir untuk penggemar AI dan profesional pembelajaran mesin telah berlalu dalam mengejar mimpi. Teknologi ini telah berhenti menjadi ceruk, telah menjadi arus utama dan sudah mempengaruhi kehidupan jutaan orang saat ini. Kementerian AI dibuat di berbagai negara [
lebih detail di sini - kira-kira. per.] dan anggaran dialokasikan untuk mengikuti lomba ini.
Hal yang sama berlaku untuk para profesional ilmu data. Beberapa tahun yang lalu, Anda bisa merasa nyaman mengetahui beberapa alat dan trik, tetapi kali ini telah berlalu. Jumlah peristiwa terkini dalam ilmu data dan jumlah pengetahuan yang diperlukan untuk mengikuti perkembangan di bidang ini luar biasa.
Saya memutuskan untuk mengambil langkah mundur dan melihat perkembangan di beberapa bidang utama di bidang kecerdasan buatan dari sudut pandang para pakar ilmu data. Berjerawat apa yang telah terjadi? Apa yang terjadi pada 2018 dan apa yang diharapkan pada 2019? Baca artikel ini untuk mendapat jawaban!
NB Seperti dalam ramalan apa pun, di bawah ini adalah kesimpulan pribadi saya yang didasarkan pada upaya untuk menggabungkan setiap fragmen ke dalam keseluruhan gambar. Jika sudut pandang Anda berbeda dari saya, saya akan senang mengetahui pendapat Anda tentang apa lagi yang mungkin berubah dalam ilmu data pada tahun 2019.
Area yang akan kita bahas dalam artikel ini adalah:
- Proses Bahasa Alami (NLP)
- Visi komputer
- Alat dan perpustakaan
- Pembelajaran Penguatan
- Masalah etika dalam AI
Pemrosesan Bahasa Alami (NLP)
Memaksa mesin untuk menguraikan kata dan kalimat selalu tampak seperti mimpi pipa. Ada banyak nuansa dan fitur dalam bahasa yang terkadang sulit dipahami bahkan untuk orang-orang, tetapi 2018 adalah titik balik nyata bagi NLP.
Kami menyaksikan satu terobosan luar biasa: ULMFiT, ELMO, OpenAl Transformer, Google BERT, dan ini bukan daftar lengkap. Aplikasi pembelajaran transfer yang berhasil (seni menerapkan model pra-terlatih untuk data) telah membuka pintu bagi NLP dalam berbagai tugas.
Transfer pembelajaran - memungkinkan Anda untuk mengadaptasi model / sistem yang sudah dilatih sebelumnya untuk tugas spesifik Anda menggunakan jumlah data yang relatif kecil.
Mari kita lihat beberapa perkembangan penting ini secara lebih rinci.
ULMFiT
Dikembangkan oleh Sebastian Ruder dan Jeremy Howard (fast.ai), ULMFiT adalah kerangka kerja pertama yang menerima pembelajaran transfer tahun ini. Untuk yang belum tahu, singkatan ULMFiT adalah singkatan dari “Universal Language Model Fine-Tuning”. Jeremy dan Sebastian secara sah menambahkan kata "universal" ke ULMFiT - kerangka kerja ini dapat diterapkan untuk hampir semua tugas NLP!
Hal terbaik tentang ULMFiT adalah Anda tidak perlu melatih model dari awal! Para peneliti telah melakukan yang paling sulit bagi Anda - ambil dan terapkan dalam proyek Anda. ULMFiT mengungguli metode lain dalam enam tugas klasifikasi teks.
Anda dapat
membaca tutorial oleh Pratek Joshi [Pateek Joshi - kira-kira. trans.] tentang cara mulai menggunakan ULMFiT untuk tugas klasifikasi teks apa pun.
ELMo
Coba tebak apa arti singkatan ELMo? Akronim untuk Embeddings dari Model Bahasa [lampiran dari model bahasa - kira-kira. trans.]. Dan ELMo menarik perhatian komunitas ML setelah rilis.
ELMo menggunakan model bahasa untuk menerima lampiran untuk setiap kata, dan juga memperhitungkan konteks di mana kata tersebut cocok dengan kalimat atau paragraf. Konteks adalah aspek kritis NLP, di mana sebagian besar pengembang sebelumnya gagal. ELMo menggunakan LSTM dua arah untuk membuat lampiran.
Memori jangka pendek (LSTM) adalah jenis arsitektur jaringan saraf berulang yang diusulkan pada tahun 1997 oleh Sepp Hochreiter dan Jürgen Schmidhuber. Seperti kebanyakan jaringan saraf berulang, jaringan LSTM bersifat universal dalam arti bahwa, dengan jumlah elemen jaringan yang cukup, dapat melakukan perhitungan apa pun yang dapat dilakukan oleh komputer biasa, yang membutuhkan matriks bobot yang sesuai yang dapat dianggap sebagai program. Tidak seperti jaringan saraf berulang tradisional, jaringan LSTM sangat cocok untuk pelatihan tentang masalah mengklasifikasikan, memproses, dan memprediksi deret waktu dalam kasus-kasus di mana peristiwa-peristiwa penting dipisahkan oleh jeda waktu dengan durasi dan batas yang tidak terbatas.
- sumber. Wikipedia
Seperti ULMFiT, ELMo secara signifikan meningkatkan produktivitas dalam menyelesaikan sejumlah besar tugas NLP, seperti menganalisis suasana teks atau menjawab pertanyaan.
BERT dari Google
Cukup banyak ahli mencatat bahwa rilis BERT menandai awal era baru di NLP. Mengikuti ULMFiT dan ELMo, BERT memimpin, menunjukkan kinerja tinggi. Seperti yang dinyatakan oleh pengumuman aslinya: "BERT secara konseptual sederhana dan kuat secara empiris."
BERT telah menunjukkan hasil luar biasa dalam 11 tugas NLP! Lihat hasil dalam tes SQuAD:
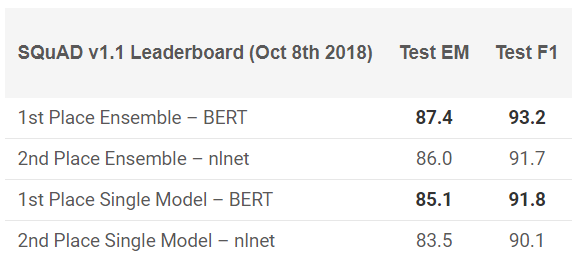
Mau mencobanya? Anda dapat menggunakan implementasi ulang di PyTorch, atau kode TensorFlow dari Google dan mencoba mengulang hasilnya di mesin Anda.
Facebook PyText
Bagaimana Facebook bisa menjauh dari balapan ini? Perusahaan ini menawarkan kerangka kerja NLP open-source miliknya yang disebut PyText. Menurut sebuah penelitian yang diterbitkan oleh Facebook, PyText meningkatkan keakuratan model percakapan sebesar 10% dan mengurangi waktu pelatihan.
PyText sebenarnya di belakang beberapa produk Facebook sendiri, seperti Messenger. Jadi bekerja dengannya akan menambah poin bagus untuk portofolio Anda dan pengetahuan yang tak ternilai yang pasti akan Anda dapatkan.
Anda dapat mencobanya sendiri,
unduh kode dari GitHub .
Google duplex
Sulit dipercaya bahwa Anda belum pernah mendengar tentang Google Duplex. Berikut ini adalah demo yang telah lama dimuat dalam berita utama:
Karena ini adalah produk Google, ada sedikit kemungkinan bahwa cepat atau lambat kode akan dipublikasikan kepada semua orang. Tentu saja, demonstrasi ini menimbulkan banyak pertanyaan: dari masalah etika hingga privasi, tetapi kita akan membicarakannya nanti. Untuk saat ini, nikmati saja sejauh mana kami telah mencapai ML dalam beberapa tahun terakhir.
Tren NLP 2019
Siapa yang lebih baik dari Sebastian Ruder sendiri yang bisa memberikan gambaran tentang ke mana NLP menuju 2019? Berikut ini adalah temuannya:
- Penggunaan model investasi bahasa pra-terlatih akan semakin meluas; model canggih tanpa dukungan akan sangat jarang.
- Tampilan pra-terlatih akan muncul yang dapat menyandikan informasi khusus yang melengkapi lampiran model bahasa. Kami akan dapat mengelompokkan berbagai jenis presentasi pra-terlatih tergantung pada persyaratan tugas.
- Lebih banyak pekerjaan akan muncul di bidang aplikasi multibahasa dan model multibahasa. Secara khusus, dengan bergantung pada penyisipan kata dalam bahasa antarbahasa, kita akan melihat kemunculan representasi antar bahasa dalam pra-terlatih.
Visi komputer

Saat ini, visi komputer adalah bidang yang paling populer di bidang pembelajaran yang mendalam. Tampaknya buah pertama dari teknologi telah diperoleh dan kami berada pada tahap pengembangan aktif. Terlepas dari apakah ini gambar atau video, kami melihat munculnya banyak kerangka kerja dan perpustakaan yang dengan mudah memecahkan masalah penglihatan komputer.
Berikut adalah daftar solusi terbaik yang dapat dilihat tahun ini.
BigGANs Out
Ian Goodfellow merancang GAN pada tahun 2014, dan konsep ini melahirkan berbagai macam aplikasi. Tahun demi tahun, kami mengamati bagaimana konsep asli diselesaikan untuk digunakan pada kasus nyata. Tapi satu hal tetap tidak berubah sampai tahun ini - gambar yang dihasilkan komputer terlalu mudah dibedakan. Inkonsistensi tertentu selalu muncul dalam bingkai, yang membuat perbedaannya sangat jelas.
Dalam beberapa bulan terakhir, pergeseran telah muncul ke arah ini, dan, dengan
penciptaan BigGAN , masalah seperti itu dapat diselesaikan sekali dan untuk semua. Lihatlah gambar yang dihasilkan oleh metode ini:

Tanpa mikroskop, sulit untuk mengatakan apa yang salah dengan gambar-gambar ini. Tentu saja, semua orang akan memutuskan sendiri, tetapi tidak ada keraguan bahwa GAN mengubah cara kita memandang gambar digital (dan video).
Untuk referensi: model ini pertama kali dilatih pada dataset ImageNet, dan kemudian pada JFT-300M untuk menunjukkan bahwa model ini ditransfer dengan baik dari satu dataset ke yang lain. Berikut ini
tautan ke halaman dari milis GAN yang menjelaskan cara memvisualisasikan dan memahami GAN.
Model Fast.ai dilatih di ImageNet dalam 18 menit
Ini adalah implementasi yang sangat keren. Ada kepercayaan luas bahwa, untuk melakukan tugas-tugas pembelajaran yang mendalam, Anda akan membutuhkan terabyte data dan sumber daya komputasi yang besar. Hal yang sama berlaku untuk melatih model dari awal pada data ImageNet. Sebagian besar dari kita berpikir dengan cara yang sama sebelum beberapa orang berpuasa.
Model mereka memberikan akurasi 93% dengan 18 menit mengesankan. Perangkat keras yang mereka gunakan,
dijelaskan secara rinci
di blog mereka , terdiri dari 16 instance cloud AWS publik, masing-masing dengan 8 GPU NVIDIA V100. Mereka membangun sebuah algoritma menggunakan perpustakaan fast.ai dan PyTorch.
Total biaya perakitan hanya $ 40! Jeremy menggambarkan
pendekatan dan metode mereka secara lebih rinci di
sini . Ini adalah kemenangan bersama!
vid2vid dari NVIDIA
Selama 5 tahun terakhir, pemrosesan gambar telah membuat langkah besar, tetapi bagaimana dengan video? Metode untuk mengkonversi dari bingkai statis ke yang dinamis ternyata sedikit lebih rumit dari yang diharapkan. Bisakah Anda mengambil urutan frame dari video dan memprediksi apa yang akan terjadi di frame berikutnya? Studi semacam itu telah dilakukan sebelumnya, tetapi publikasi tidak jelas.

NVIDIA memutuskan untuk membuat keputusannya untuk publik awal tahun ini [2018 - kira-kira. per.], yang secara positif dievaluasi oleh masyarakat. Tujuan vid2vid adalah untuk memperoleh fungsi tampilan dari video input yang diberikan untuk membuat video output yang mentransmisikan konten video input dengan akurasi luar biasa.
Anda dapat mencoba implementasinya di PyTorch, bawa
ke GitHub di sini .
Tren Visi Mesin untuk 2019
Seperti yang saya sebutkan sebelumnya, pada 2019 kita lebih cenderung melihat perkembangan tren 2018, daripada terobosan baru: mobil self-driving, algoritma pengenalan wajah, realitas virtual dan banyak lagi. Bisakah Anda tidak setuju dengan saya jika Anda memiliki sudut pandang atau penambahan yang berbeda, berbagi dengan kami, apa lagi yang bisa kami harapkan di tahun 2019?
Masalah drone, sambil menunggu persetujuan politisi dan pemerintah, akhirnya mungkin mendapatkan lampu hijau di Amerika Serikat (India jauh tertinggal dalam hal ini). Secara pribadi, saya ingin lebih banyak penelitian dilakukan dalam skenario dunia nyata. Konferensi seperti
CVPR dan
ICML memberikan cakupan yang baik dari pencapaian terbaru di bidang ini, tetapi seberapa dekat proyek dengan kenyataan tidak terlalu jelas.
"Menjawab pertanyaan visual" dan "sistem dialog visual" akhirnya mungkin muncul dengan debut yang telah lama ditunggu-tunggu. Sistem ini tidak memiliki kemampuan untuk menggeneralisasi, tetapi diharapkan bahwa kita akan segera melihat pendekatan multimodal yang terintegrasi.
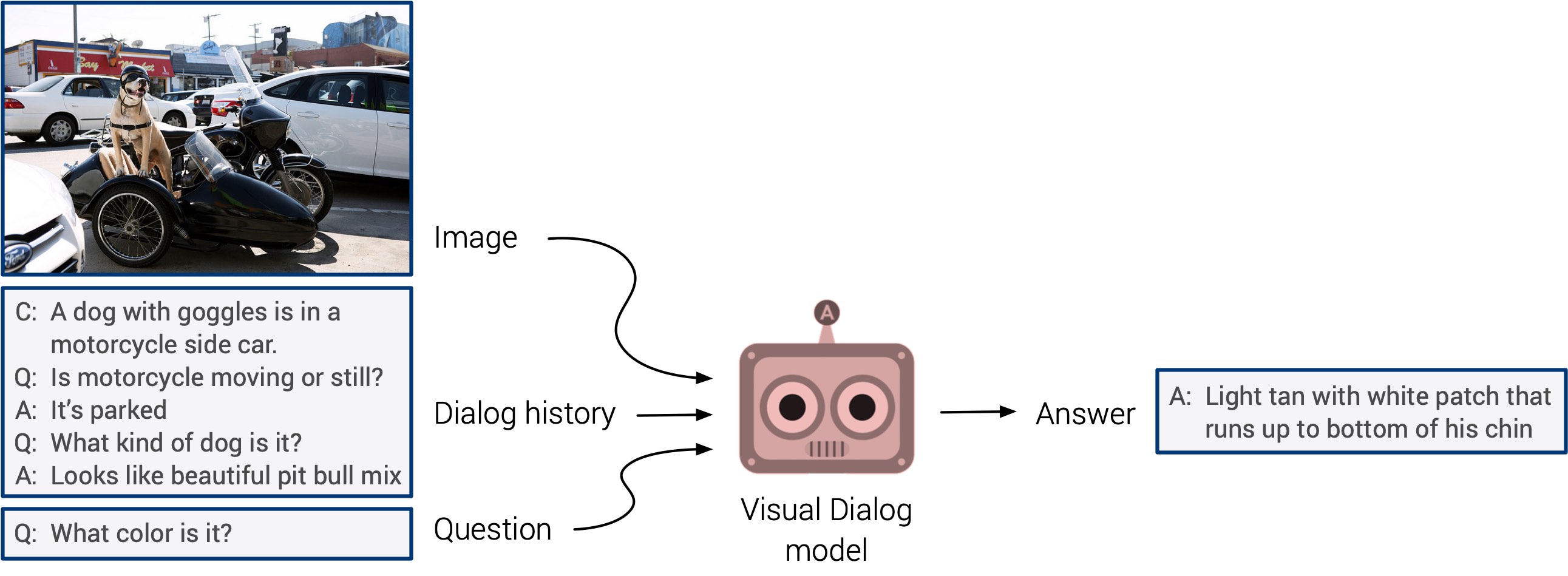
Latihan mandiri datang ke permukaan tahun ini. Saya bertaruh bahwa tahun depan ia akan menemukan aplikasi dalam jumlah studi yang jauh lebih besar. Ini adalah arah yang sangat keren: tanda ditentukan langsung dari input data, daripada membuang waktu secara manual menandai gambar. Mari jaga agar jari kita saling bersilang!