
Di antara tanggal Ilmuwan, ada banyak holivar, dan salah satunya menyangkut pembelajaran mesin kompetitif. Apakah kesuksesan Kaggle benar-benar menunjukkan kemampuan spesialis untuk menyelesaikan tugas kerja yang khas? Arseny
arseny_info (Ketua Tim R&D @
WANNABY ,
Kaggle Master , kemudian di
A. ) dan Arthur
n01z3 (Kepala Computer Vision @
X5 Retail Group ,
Kaggle Grandmaster , kemudian di
N. ) meningkatkan holivar ke level baru: alih-alih diskusi lain di mereka mengambil mikrofon di ruang obrolan dan mengadakan
diskusi publik pada pertemuan tersebut , atas dasar mana artikel ini lahir.
Metrik, kernel, leaderboard
A:Saya ingin memulai dengan argumen yang diharapkan bahwa Kaggle tidak mengajarkan hal yang paling penting dalam karya tanggal Scientific yang khas - pernyataan masalahnya. Tugas yang diatur dengan benar sudah mengandung setengah dari solusi, dan seringkali setengah ini adalah yang paling sulit, dan untuk kode beberapa model dan melatihnya jauh lebih mudah. Kaggle menawarkan tugas dari dunia ideal - data siap, metrik siap, ambil, dan latih.
Anehnya, bahkan dengan ini, masalah muncul. Tidaklah sulit untuk menemukan banyak contoh ketika “penipu” bingung ketika mereka melihat metrik yang tidak dikenal / tidak dapat dipahami.
N:Ya, itulah intisari kaggle. Panitia berpikir, meresmikan tugas, mengumpulkan dataset dan menentukan metrik. Tetapi jika seseorang memiliki awal pemikiran kritis, maka hal pertama yang akan dia pikirkan adalah mengapa mereka memutuskan bahwa metrik yang dipilih atau target yang diusulkan adalah optimal.
Peserta yang kuat sering mendefinisikan kembali tugas itu sendiri dan menghasilkan target yang lebih baik.
Dan ketika mereka menemukan metrik, menentukan target, dan mengumpulkan data, maka mengoptimalkan metrik adalah yang terbaik yang dilakukan oleh para pengagum. Setelah setiap kompetisi, pelanggan dapat dengan percaya diri percaya bahwa para peserta menunjukkan "langit-langit" untuk algoritma yang ideal dengan kecepatan tinggi. Dan untuk mencapai ini, para pengagum mencoba berbagai pendekatan dan ide, mengesahkannya dengan iterasi cepat.
Pendekatan ini secara langsung dikonversi menjadi pekerjaan yang sukses pada tugas nyata. Selain itu, kuggler berpengalaman dapat langsung dengan segera secara intuitif atau dari pengalaman masa lalu memilih daftar ide yang pantas untuk dicoba di tempat pertama untuk mendapatkan keuntungan maksimal. Dan di sini seluruh gudang senjata komunitas kaggle datang untuk menyelamatkan: artikel, slack, forum, kernel.
 A:
A:Anda menyebutkan "kernel", dan saya punya keluhan terpisah untuk mereka. Banyak kompetisi telah berubah menjadi pengembangan berbasis kernel. Saya tidak akan fokus pada kasus yang merosot ketika sebuah medali emas bisa didapat karena keberhasilan peluncuran naskah publik. Namun demikian, bahkan dalam kompetisi pembelajaran yang mendalam sekarang Anda bisa mendapatkan semacam medali, hampir tanpa menulis kode. Anda dapat mengambil beberapa keputusan publik, terutama tidak memahami putaran beberapa parameter, menguji diri sendiri di papan peringkat, rata-rata hasilnya dan mendapatkan metrik yang baik.
Sebelumnya, bahkan keberhasilan moderat dalam kompetisi "gambar" (misalnya, medali perunggu, yaitu, masuk ke 10% teratas dari peringkat akhir) menunjukkan bahwa seseorang mampu melakukan sesuatu - Anda harus menulis pipa normal setidaknya dari awal hingga akhir , cegah bug penting. Sekarang keberhasilan ini telah didevaluasi: Kaggle mempromosikan platform intinya dengan kekuatan dan utama, yang menurunkan ambang pintu masuk dan memungkinkan Anda untuk entah bagaimana bereksperimen tanpa menyadari apa itu.
 N:
N:Medali perunggu tidak pernah dikutip. Ini adalah tingkat "Saya meluncurkan sesuatu di sana, dan itu dipelajari." Dan itu tidak terlalu buruk.
Menurunkan level input karena kernel dan kehadiran GPU di dalamnya menciptakan persaingan dan meningkatkan tingkat pengetahuan umum yang lebih tinggi. Jika setahun yang lalu dimungkinkan untuk mendapatkan emas menggunakan vanilla Unet, sekarang Anda tidak dapat melakukannya tanpa 5+ modifikasi dan trik. Dan trik ini bekerja tidak hanya pada Kaggle, tetapi juga di luarnya. Sebagai contoh, di
aerial-Inria, dudes kami dari ods.ai turun dari kakinya dan menunjukkan seni dengan hanya menggunakan pipa segmentasi kuat yang dikembangkan oleh Kaggle. Ini menunjukkan penerapan pendekatan tersebut dalam pekerjaan nyata.
 A:
A:Masalahnya adalah bahwa
dalam tugas nyata tidak ada papan peringkat . Biasanya tidak ada angka tunggal yang menunjukkan bahwa semuanya salah atau, sebaliknya, semuanya baik-baik saja. Seringkali ada beberapa angka, mereka saling bertentangan, menghubungkan mereka ke dalam satu sistem adalah tantangan lain.
N:Tetapi metrik entah bagaimana penting. Mereka menunjukkan kinerja objektif dari algoritma. Tanpa algoritma dengan metrik di atas beberapa ambang yang dapat digunakan, tidak mungkin untuk membuat layanan berbasis ML.
A:Tetapi hanya jika mereka jujur mencerminkan keadaan produk, yang tidak selalu terjadi. Kebetulan Anda perlu menyeret metrik ke tingkat minimum yang higienis, dan
peningkatan lebih lanjut dari metrik "teknis" tidak lagi sesuai dengan peningkatan produk (pengguna tidak melihat ini +0,01 IoU), korelasi antara metrik dan sensasi pengguna hilang.
Selain itu, metode kaggle klasik untuk meningkatkan metrik tidak berlaku dalam pekerjaan normal. Tidak perlu mencari "wajah", tidak perlu mereproduksi markup dan menemukan jawaban yang benar dengan hash file.

Validasi yang dapat diandalkan dan ansambel model yang berani
N:Kaggle mengajarkan Anda untuk memvalidasi dengan benar, termasuk karena kehadiran wajah. Anda harus sangat jelas tentang bagaimana kecepatan di leaderboard telah meningkat. Penting juga
untuk membangun validasi lokal yang representatif yang mencerminkan bagian pribadi dari papan peringkat atau distribusi data dalam produksi, jika kita berbicara tentang pekerjaan nyata.
Hal lain yang sering disalahkan Kagglers adalah ansambel. Solusi Kaggle biasanya terdiri dari banyak model, dan tidak mungkin untuk menariknya. Namun, mereka lupa bahwa tidak mungkin membuat solusi yang kuat tanpa model tunggal yang kuat. Dan untuk menang, Anda tidak hanya membutuhkan ansambel, tetapi ansambel model tunggal yang beragam dan kuat.
Pendekatan “mencampur semuanya dalam satu baris” tidak pernah memberikan hasil yang layak. A:
A:Konsep "model tunggal sederhana" di kumpul-kumpul Kaggle dan untuk lingkungan produksi bisa sangat berbeda. Dalam kerangka kompetisi, ini akan menjadi salah satu arsitektur yang dilatih pada 5/10 lipatan, dengan spread encoder, pada saatnya Anda dapat mengharapkan augmentasi waktu pengujian. Dengan standar kompetisi, ini adalah solusi yang sangat sederhana.
Tetapi produksi seringkali
membutuhkan solusi beberapa urutan lebih mudah , terutama ketika datang ke aplikasi mobile atau IOT. Sebagai contoh, dalam kasus saya, model Kaggle biasanya menempati 100+ megabita, dan dalam pekerjaan model lebih dari beberapa megabita bahkan sering tidak dipertimbangkan; Ada kesenjangan serupa dalam persyaratan untuk tingkat inferensi.
N:Namun, jika tanggal itu para ilmuwan tahu cara melatih grid yang berat, maka semua teknik yang sama juga cocok untuk melatih model-model ringan. Dalam perkiraan pertama, Anda bisa menggunakan mesh yang lebih mudah atau versi mobile dari arsitektur yang sama. Kuantisasi timbangan dan pemangkasan di luar kompetensi Kagglers - tidak diragukan lagi di sini. Tetapi ini sudah keterampilan yang sangat spesifik, yang jauh dari selalu sangat dibutuhkan dalam prod.
Tetapi situasi yang jauh lebih sering dalam masalah nyata adalah bahwa ada dataset berlabel kecil
(seperti celana Anda) dan sebagian besar data yang tidak terisi atau aliran data baru yang berkelanjutan. Dan di sini kemampuan untuk mengelas ansambel yang besar dan akurat sangat cocok. Dengan itu, Anda dapat melakukan pseudo-peredupan atau distilasi untuk melatih model yang ringan. Meningkatkan dataset dengan cara ini dijamin untuk meningkatkan kinerja model apa pun.
A:Pseudo-dabbing berguna, tetapi dalam kompetisi itu tidak digunakan untuk kehidupan yang baik - hanya karena tidak mungkin untuk kembali ukuran data. Data yang diperoleh dengan menggunakan peredupan semu, meskipun meningkatkan metrik, tidak berguna seperti menandai ulang data yang hilang secara manual.
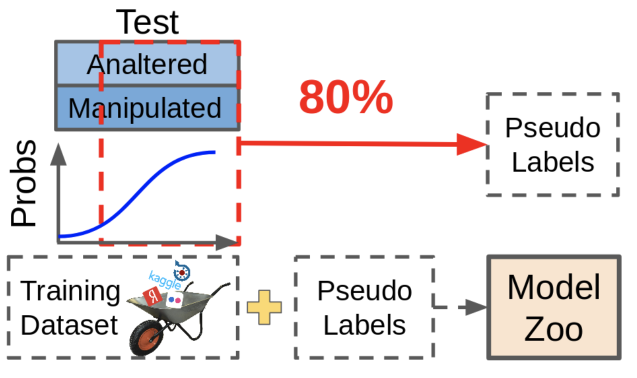
Apa itu pseudo-dabbing? Kami mengambil model yang ada, lihat di mana mereka memberikan prediksi yang andal, kami membuang sampel ini bersama-sama dengan prediksi ke dalam dataset kami. Dalam hal ini, sampel yang sulit untuk model tetap tidak berlabel, karena prediksi ini tidak cukup baik sekarang. Lingkaran jahat!
Dalam praktiknya, jauh lebih berguna untuk menemukan sampel-sampel yang menyebabkan jaringan menghasilkan prediksi yang tidak pasti, dan mengubah ukurannya. Ini membutuhkan banyak kerja manual, tetapi efeknya sepadan.
Tentang keindahan kode dan kerja tim
A:Masalah lainnya adalah kualitas kode dan budaya pengembangan. Kaggle tidak hanya mengajarkan Anda cara menulis kode, tetapi juga memberikan banyak contoh buruk. Kebanyakan kernel adalah kode yang tidak terstruktur, tidak dapat dibaca, dan tidak efisien yang disalin tanpa berpikir. Beberapa kepribadian Kaggle yang populer bahkan berlatih mengunggah kode mereka di Google Drive alih-alih repositori.

Orang pandai belajar tanpa pengawasan. Jika Anda sering melihat kode yang buruk, Anda bisa terbiasa dengan gagasan bahwa memang seharusnya begitu. Ini sangat berbahaya bagi pemula, yang cukup banyak di Kaggle.
N:Kualitas kode adalah titik diperdebatkan pada cuggle, saya setuju. Namun, saya juga bertemu orang-orang yang menulis saluran pipa yang sangat layak yang dapat digunakan kembali untuk tugas-tugas lain. Tapi ini agak pengecualian: dalam panasnya pertarungan, kualitas kode dikorbankan demi pemeriksaan cepat ide-ide baru, terutama menjelang akhir kompetisi.
Tapi Kaggle mengajarkan kerja tim. Dan tidak ada yang menyatukan orang-orang seperti tujuan bersama, tujuan bersama yang bisa dipahami. Anda dapat mencoba bersaing dengan sekelompok orang yang berbeda, terlibat dan mengembangkan keterampilan lunak.
 A:
A:Tim gaya kaggle juga sangat berbeda. Baik jika memang ada semacam pemisahan tugas berdasarkan peran, interaksi yang konstruktif, dan semua orang memberikan kontribusi. Namun demikian, tim di mana setiap orang membuat bola lumpurnya sendiri, dan pada hari-hari terakhir kompetisi semua ini dicampur dengan panik, juga cukup, dan ini juga tidak mengajarkan sesuatu yang baik - pengembangan perangkat lunak yang nyata (termasuk ilmu data) tidak dilakukan untuk waktu yang sangat lama.
Ringkasan
Mari kita simpulkan.
Tidak diragukan lagi, partisipasi dalam kompetisi memberikan bonusnya yang berguna dalam pekerjaan sehari-hari: pertama-tama, itu adalah kemampuan untuk dengan cepat beralih, memeras segala sesuatu dari data dalam kerangka metrik dan tidak ragu untuk menggunakan pendekatan canggih.
Di sisi lain, penyalahgunaan pendekatan Kaggle sering mengarah pada kode tidak terbaca yang tidak optimal, prioritas kerja yang meragukan, dan sedikit bling.
Namun, setiap tanggal ilmuwan tahu bahwa untuk berhasil membuat ansambel, Anda harus menggabungkan berbagai model. Jadi dalam sebuah tim
, ada baiknya menggabungkan orang-orang dengan keahlian yang berbeda , dan satu atau dua Kagglers berpengalaman akan berguna bagi hampir semua tim.