Ketika kami memilih alat untuk memproses data besar, kami mempertimbangkan opsi yang berbeda - baik milik maupun sumber terbuka. Kami mengevaluasi kemungkinan adaptasi yang cepat, aksesibilitas dan fleksibilitas teknologi. Termasuk migrasi antar versi. Akibatnya, kami memilih solusi open source Greenplum, yang terbaik dari semua memenuhi persyaratan kami, tetapi membutuhkan solusi dari satu masalah penting.

Faktanya adalah bahwa file database Greenplum versi 4 dan 5 tidak kompatibel satu sama lain, dan oleh karena itu upgrade sederhana dari satu versi ke versi lain tidak mungkin. Migrasi data hanya dapat dilakukan melalui mengunggah dan mengunduh data. Dalam posting ini saya akan berbicara tentang opsi yang memungkinkan untuk migrasi ini.
Mengevaluasi opsi migrasi
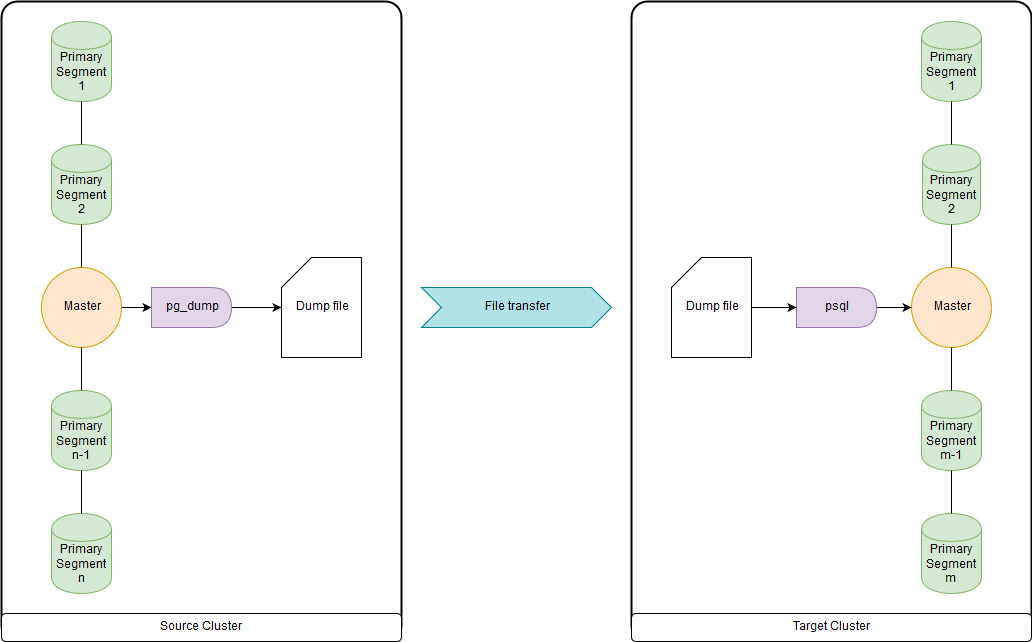
pg_dump & psql (atau pg_restore)
Ini terlalu lambat untuk puluhan terabyte, karena semua data diunggah dan diunduh melalui master node. Tetapi cukup cepat untuk memigrasi DDL dan tabel kecil. Anda dapat mengunggah keduanya ke file dan menjalankan pg_dump dan psql secara bersamaan melalui pipa pada kluster sumber dan kluster tujuan. pg_dump cukup mengunggah ke satu file yang berisi perintah DDL dan perintah data COPY. Data yang diperoleh dapat dengan mudah diproses, yang akan ditampilkan di bawah ini.
gptransfer
Membutuhkan versi Greenplum 4.2 atau yang lebih baru. Adalah penting bahwa kedua cluster sumber dan cluster tujuan bekerja secara bersamaan. Cara tercepat untuk memigrasi tabel data besar untuk versi open source. Tetapi metode ini sangat lambat untuk mentransfer tabel kosong dan kecil karena overhead yang tinggi.
gptransfer menggunakan pg_dump untuk mentransfer DDL dan gpfdist untuk mentransfer data. Jumlah segmen utama pada gugus tujuan harus tidak kurang dari segmen host pada gugus sumber. Ini penting untuk dipertimbangkan ketika membuat kluster "kotak pasir", jika data dari kluster utama akan ditransfer ke mereka, dan penggunaan utilitas gptransfer direncanakan. Sekalipun host segmen sedikit, Anda dapat menggunakan jumlah segmen yang diperlukan pada masing-masing segmen. Jumlah segmen pada gugus tujuan mungkin kurang dari pada gugus sumber, namun, ini
akan mempengaruhi kecepatan transfer data. Di antara kluster, otentikasi ssh pada sertifikat harus dikonfigurasi.
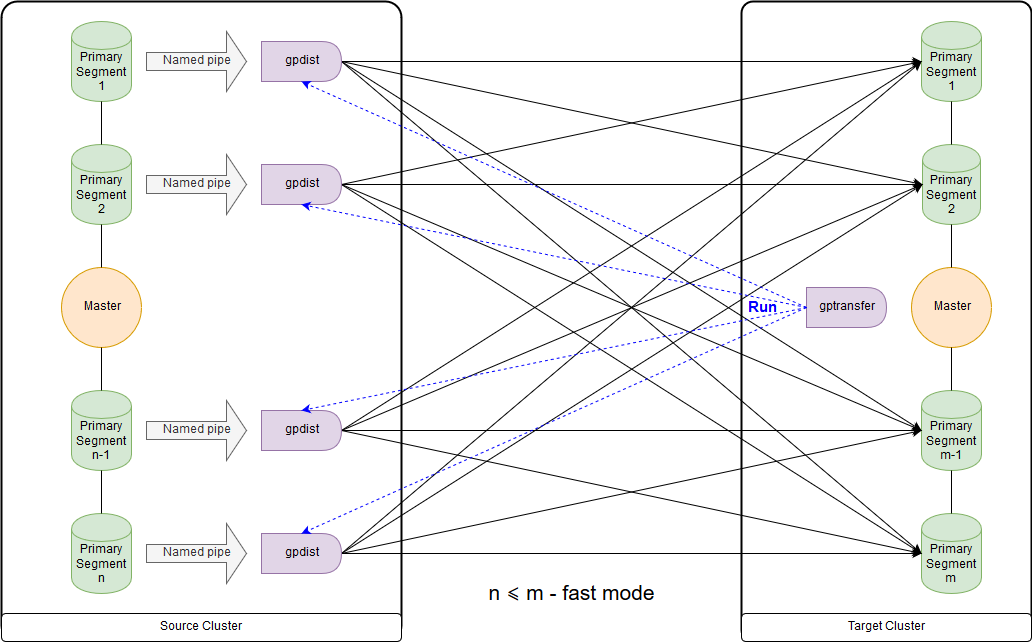
Ini adalah skema untuk mode cepat ketika jumlah segmen pada gugus tujuan lebih besar atau sama dengan jumlah pada gugus sumber. Peluncuran utilitas itu sendiri ditunjukkan pada diagram di node master cluster penerima. Dalam mode ini, tabel tulis eksternal dibuat pada cluster sumber, yang menulis data pada setiap segmen ke pipa bernama. Perintah INSERT INTO writable_external_table SELECT * FROM source_table dieksekusi. Data dari pipa bernama dibaca oleh gpfdist. Tabel eksternal juga dibuat pada gugus tujuan, hanya untuk membaca. Tabel menunjukkan data yang disediakan gpfdist melalui
protokol dengan nama yang sama . INSERT INTO target_table SELECT * FROM external_gpfdist_table perintah dieksekusi. Data secara otomatis didistribusikan kembali di antara segmen-segmen dari cluster tujuan.
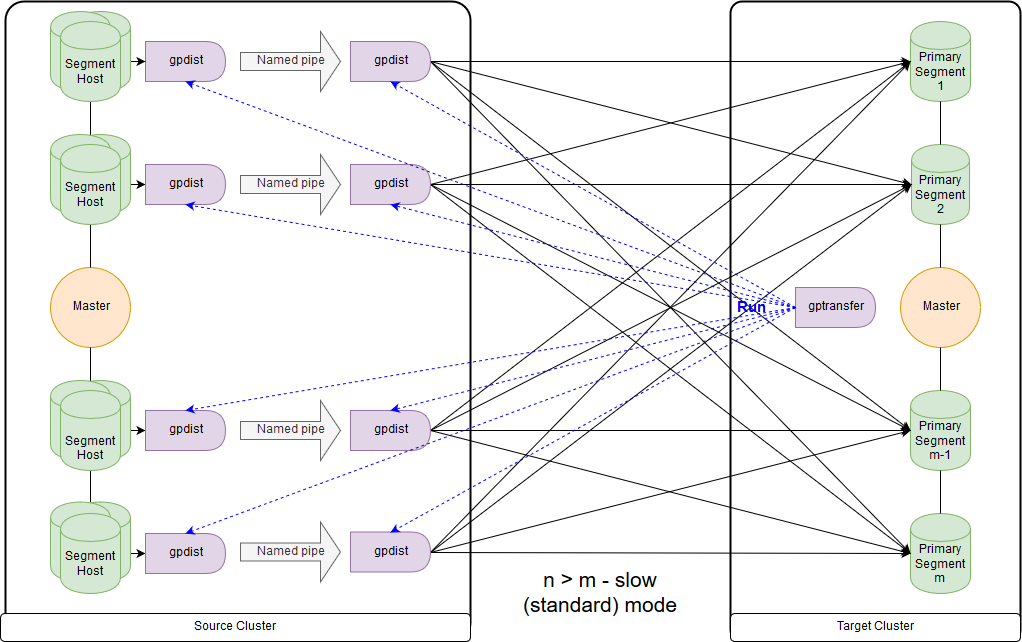
Dan ini adalah skema untuk mode lambat, atau, sebagaimana gptransfer sendiri berikan, mode standar. Perbedaan utama adalah bahwa pada setiap host segmen dari cluster sumber, pasangan gpfdist diluncurkan untuk semua segmen host segmen ini. Tabel catatan eksternal mengacu pada gpfdist yang bertindak sebagai penerima data. Selain itu, jika beberapa nilai diindikasikan untuk ditulis dalam parameter LOCATION pada tabel eksternal, maka segmen didistribusikan secara merata oleh gpfdist saat menulis data. Data antara gpfdist pada segmen host dilewatkan melalui pipa bernama. Karena itu, kecepatan transfer data lebih rendah, tetapi masih ternyata lebih cepat daripada saat mentransfer data hanya melalui master node.
Saat memigrasikan data dari Greenplum 4 ke Greenplum 5, gptransfer harus dijalankan pada master node dari cluster tujuan. Jika kami menjalankan gptransfer pada cluster sumber, kami mendapatkan kesalahan tentang tidak adanya bidang
san_mounts di tabel
pg_catalog.gp_segment_configuration :
gptransfer -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --dest-host=gpdb-target-master.local --dest-database=big_db --source-map-file=/data/master/gpseg-1/host_and_IP_segments --batch-size=10 --sub-batch-size=50 --truncate 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Validating options... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190109:12:46:13:010893 gptransfer:gpdb-source-master.local:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190109:12:46:14:010893 gptransfer:gpdb-source-master.local:gpadmin-[CRITICAL]:-gptransfer failed. (Reason='error 'ERROR: column "san_mounts" does not exist LINE 2: ... SELECT dbid, content, status, unnest(san_mounts... ^ ' in ' SELECT dbid, content, status, unnest(san_mounts) FROM pg_catalog.gp_segment_configuration WHERE content >= 0 ORDER BY content, dbid '') exiting...
Anda juga perlu memeriksa variabel GPHOME sehingga mereka cocok antara kluster sumber dan kluster tujuan. Kalau tidak, kami mendapatkan
kesalahan yang agak aneh (utilitas gptransfer gagal ketika sumber dan target memiliki jalur GPHOME yang berbeda).
gptransfer -t big_db.public.test_table --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -t big_db.public.test_table --source-host=gpdb-spurce-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments --b atch-size=10 --sub-batch-size=50 --truncate 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190109:14:12:07:031438 gptransfer:mdw:gpadmin-[ERROR]:-gptransfer: error: GPHOME directory does not exist on gpdb-source-master.local
Anda cukup membuat symlink yang sesuai dan mengganti variabel GPHOME di sesi di mana gptransfer dimulai.
Ketika gptransfer dimulai pada kluster tujuan, opsi "--source-map-file" harus mengarah ke file yang berisi daftar host dan alamat IP mereka dengan segmen utama dari kluster sumber. Sebagai contoh:
sdw1,192.0.2.1 sdw2,192.0.2.2 sdw3,192.0.2.3 sdw4,192.0.2.4
Dengan opsi "--full" dimungkinkan untuk mentransfer tidak hanya tabel, tetapi seluruh basis data, namun, basis data pengguna tidak boleh dibuat pada gugus tujuan. Anda juga harus ingat bahwa ada masalah karena perubahan sintaks saat memindahkan tabel eksternal.
Mari kita evaluasi overhead tambahan, misalnya, dengan menyalin 10 tabel kosong (tabel dari big_db.public.test_table_2 ke big_db.public.test_table_11) menggunakan gptarnsfer:
gptransfer -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-ba tch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting gptransfer with args: -f temp_filelist.txt --source-host=gpdb-source-master.local --dest-database=big_db --source-map-file=/data1/master/gpseg-1/source_host_and_IP_segments_dev --batch-size=10 --sub-batch-size=50 --truncate 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating options... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of source Greenplum Database... 20190118:06:14:08:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving configuration of destination Greenplum Database... 20190118:06:14:09:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving source tables... 20190118:06:14:12:031521 gptransfer:mdw:gpadmin-[INFO]:-Checking for gptransfer schemas... 20190118:06:14:22:031521 gptransfer:mdw:gpadmin-[INFO]:-Retrieving list of destination tables... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Reading source host map file... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Building list of source tables to transfer... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Number of tables to transfer: 10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-gptransfer will use "standard" mode for transfer. 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating source host map... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-Validating transfer table set... 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:-The following tables on the destination system will be truncated: 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_2 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_3 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_4 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_5 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_6 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_7 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_8 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_9 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_10 20190118:06:14:25:031521 gptransfer:mdw:gpadmin-[INFO]:- big_db.public.test_table_11 … 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using batch size of 10 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Using sub-batch size of 16 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating work directory '/home/gpadmin/gptransfer_31521' 20190118:06:14:34:031521 gptransfer:mdw:gpadmin-[INFO]:-Creating schema public in database edw_prod... 20190118:06:14:40:031521 gptransfer:mdw:gpadmin-[INFO]:-Starting transfer of big_db.public.test_table_5 to big_db.public.test_table_5... … 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Validation of big_db.public.test_table_4 successful 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Removing work directories... 20190118:06:15:02:031521 gptransfer:mdw:gpadmin-[INFO]:-Finished.
Akibatnya, transfer 10 tabel kosong membutuhkan waktu sekitar 16 detik (14: 40-15: 02), yaitu, satu meja - 1,6 detik. Selama ini, dalam kasus kami, sekitar 100 MB data dapat diunduh menggunakan pg_dump & psql.
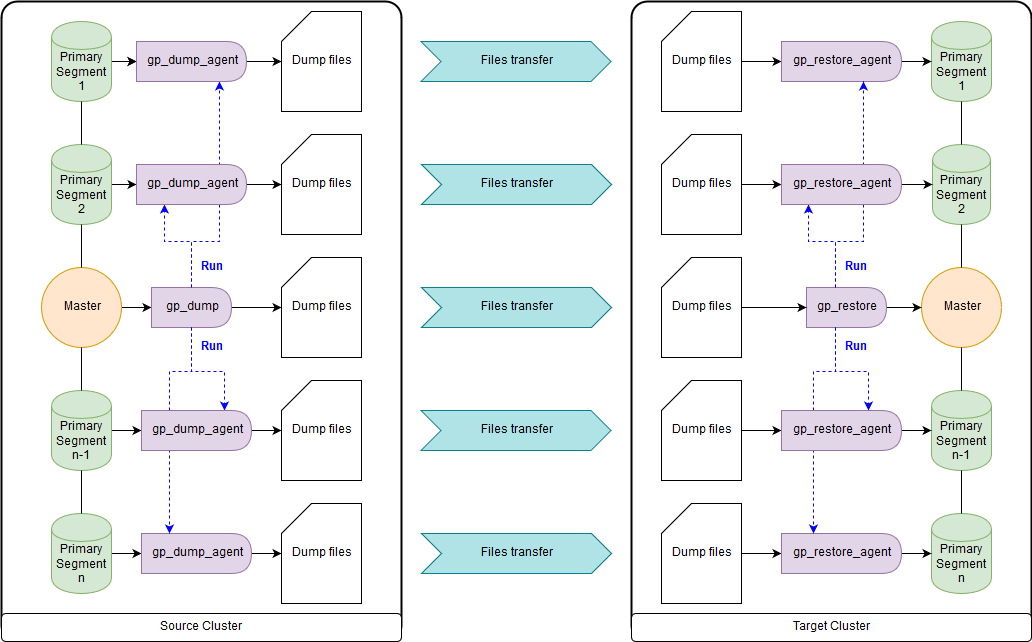
gp_dump & gp_restore
Sebagai opsi: gunakan add-on di atasnya, gpcrondump & gpdbrestore, karena gp_dump & gp_restore dinyatakan usang. Meskipun gpcrondump & gpdbrestore sendiri menggunakan gp_dump & gp_restore dalam prosesnya. Ini adalah cara yang paling universal, tetapi bukan yang tercepat. File cadangan yang dibuat dengan gp_dump mewakili seperangkat perintah DDL pada master node, dan pada segmen primer, terutama set perintah dan data COPY. Cocok untuk kasus-kasus ketika tidak mungkin untuk memberikan operasi simultan dari cluster tujuan dan cluster sumber. Ada keduanya di Greenplum versi lama, dan di yang baru:
gp_dump ,
gp_restore .
Utilitas Gpbackup & gprestore
Dibuat sebagai pengganti gp_dump & gp_restore. Untuk pekerjaan mereka, versi Greenplum minimum 4.3.17 diperlukan (
const MINIMUM_GPDB4_VERSION = "4.3.17" ). Skema kerjanya mirip dengan gpbackup & gprestore, sementara kecepatan kerjanya jauh lebih cepat. Cara tercepat untuk mendapatkan perintah DDL untuk basis data besar. Secara default, ini mentransfer objek global, untuk pemulihan Anda perlu menentukan "gprestore --with-global". Parameter opsional “--jobs” dapat mengatur jumlah pekerjaan (dan sesi ke basis data) saat membuat cadangan. Karena beberapa sesi dibuat, penting untuk memastikan konsistensi data sampai semua kunci diterima. Ada juga opsi yang berguna "--with-stats", yang memungkinkan Anda untuk mentransfer statistik pada objek yang digunakan untuk membangun rencana eksekusi. Informasi lebih lanjut di
sini .
Utilitas gpcopy
Untuk menyalin basis data ada gpcopy utilitas - pengganti gptansfer. Tetapi itu hanya termasuk dalam versi eksklusif Greenplum dari Pivotal, mulai dari 4.3.26 - dalam versi open source
, utilitas ini tidak . Dalam operasi, gugus sumber mengeksekusi perintah COPY source_table TO PROGRAM 'gpcopy_helper ...' ON SEGMENT CSV MENGGABUNGKAN PARTISI EKSTERNAL. Di sisi gugus penerima, tabel eksternal sementara MENCIPTAKAN TEMPAT TEMPAT WEB EKSTERNAL external_temp_table (LIKE target_table) EXECUTE '... gpcopy_helper –listen ...' dibuat dan INSERT INTO target_table SELECT * DARI perintah external_temp_table dieksekusi. Akibatnya, gpcopy_helper dengan parameter –listen diluncurkan pada setiap segmen dari cluster tujuan, yang menerima data dari gpcopy_helper dari segmen-segmen dari cluster sumber. Karena skema transmisi data, serta kompresi, kecepatan transmisi jauh lebih tinggi. Antar cluster, otentikasi ssh pada sertifikat juga harus dikonfigurasi. Saya juga ingin mencatat bahwa gpcopy memiliki opsi yang nyaman "--truncate-source-after" (dan "--validate") untuk kasus-kasus di mana cluster sumber dan tujuan berada di server yang sama.
Strategi Transfer Data
Untuk menentukan strategi transfer, kita perlu menentukan apa yang lebih penting bagi kita: mentransfer data dengan cepat, tetapi dengan lebih banyak tenaga kerja dan mungkin kurang andal (gpbackup, gptransfer atau kombinasinya) atau dengan sedikit tenaga kerja, tetapi lebih lambat (gpbackup atau gptransfer tanpa menggabungkan).
Cara tercepat untuk mentransfer data - ketika ada klaster sumber dan kluster tujuan - berikut ini:
- Dapatkan DDL menggunakan gpbackup --metadata-only, konversi dan muat melalui pipa menggunakan psql
- Hapus indeks
- Transfer tabel dengan ukuran 100 MB atau lebih menggunakan gptransfer
- Transfer tabel dengan ukuran kurang dari 100 MB menggunakan pg_dump | psql seperti pada paragraf pertama
- Buat kembali indeks yang dihapus
Metode ini ternyata berada di pengukuran kami setidaknya 2 kali lebih cepat daripada gp_dump & gp_restore. Metode alternatif: mentransfer semua basis data menggunakan gptransfer –full, gpbackup & gprestore, atau gp_dump & gp_restore.
Ukuran tabel dapat diperoleh dengan kueri berikut:
SELECT nspname AS "schema", coalesce(tablename, relname) AS "name", SUM(pg_total_relation_size(class.oid)) AS "size" FROM pg_class class JOIN pg_namespace namespace ON namespace.oid = class.relnamespace LEFT JOIN pg_partitions parts ON class.relname = parts.partitiontablename AND namespace.nspname = parts.schemaname WHERE nspname NOT IN ('pg_catalog', 'information_schema', 'pg_toast', 'pg_bitmapindex', 'pg_aoseg', 'gp_toolkit') GROUP BY nspname, relkind, coalesce(tablename, relname), pg_get_userbyid(class.relowner) ORDER BY 1,2;
Konversi yang diperlukan
File cadangan dalam versi Greenplum 4 dan 5 juga tidak sepenuhnya kompatibel. Jadi, di Greenplum 5, karena perubahan sintaksis, perintah CREATE EXTERNAL TABLE dan COPY tidak memiliki parameter INTO ERROR TABLE, dan Anda perlu mengatur parameter SET gp_ignore_error_table menjadi true sehingga pemulihan cadangan tidak gagal karena kesalahan. Dengan set parameter, kita hanya mendapat peringatan.
Selain itu, versi kelima memperkenalkan protokol berbeda untuk berinteraksi dengan tabel pxf eksternal, dan untuk menggunakannya, Anda perlu mengubah parameter LOCATION dan mengkonfigurasi layanan pxf.
Perlu dicatat juga bahwa dalam file cadangan gp_dump & gp_restore baik pada master node dan pada setiap segmen primer, parameter SET gp_strict_xml_parse disetel ke false. Tidak ada parameter seperti itu di Greenplum 5, dan sebagai hasilnya, kami mendapatkan pesan kesalahan.
Jika protokol gphdfs digunakan untuk tabel eksternal, Anda perlu memeriksa dalam file cadangan daftar sumber dalam parameter LOCATION untuk tabel eksternal pada baris 'gphdfs: //'. Sebagai contoh, seharusnya hanya ada 'gphdfs: //hadoop.local: 8020'. Jika ada baris lain, mereka perlu ditambahkan ke skrip pengganti pada master node dengan analogi.
grep -o gphdfs\:\/\/.*\/ /data1/master/gpseg-1/db_dumps/20181206/gp_dump_-1_1_20181206122002.gz | cut -d/ -f1-3 | sort | uniq gphdfs://hadoop.local:8020
Kami membuat penggantian pada node master (menggunakan file data gp_dump sebagai contoh):
mv /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz gunzip -c /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.old.gz | sed "s#'gphdfs://hadoop.local:8020#'pxf:/#g" | sed "s/\(^.*pxf\:\/\/.*'\)/\1\\&\&\?PROFILE=HdfsTextSimple'/" |sed "s#'&#g" | sed 's/SET gp_strict_xml_parse = false;/SET gp_ignore_error_table = true;/g' | gzip -1 > /data1/master/gpseg-1/db_dumps/20181206/big_db_gp_dump_1_1_20181206080001.gz nets
Dalam versi terbaru, nama profil HdfsTextSimple
dinyatakan usang , nama baru adalah hdfs: teks.
Ringkasan
Di luar artikel, kebutuhan tetap untuk konversi eksplisit ke teks (
Pengecoran Teks Implisit ), mekanisme manajemen sumber daya klaster
Kelompok Sumber Daya baru yang menggantikan Antrian Sumber Daya, pengoptimal
GPORCA , yang disertakan secara default di Greenplum 5, masalah kecil dengan klien.
Saya menantikan rilis versi keenam dari Greenplum, yang dijadwalkan untuk musim semi 2019: tingkat kompatibilitas dengan PostgreSQL 9.4, Pencarian Teks Lengkap, Dukungan Indeks GIN, Jenis Rentang, JSONB, Kompresi zStd. Juga, rencana awal untuk Greenplum 7 menjadi dikenal: tingkat kompatibilitas dengan PostgreSQL minimum 9,6, Keamanan Tingkat Baris, Failover Master Otomatis. Pengembang juga menjanjikan ketersediaan utilitas pemutakhiran basis data untuk memperbarui antara versi utama, sehingga akan lebih mudah untuk digunakan.
Artikel ini disiapkan oleh tim manajemen data Rostelecom