Seberapa kompleks topik pembelajaran mesin? Jika Anda pandai matematika, tetapi jumlah pengetahuan tentang pembelajaran mesin cenderung nol, seberapa jauh Anda bisa bersaing ketat di platform
Kaggle ?

Tentang situs dan kompetisi
Kaggle adalah komunitas orang yang tertarik pada ML (dari pemula hingga pro keren) dan tempat untuk kompetisi (seringkali dengan kumpulan hadiah yang mengesankan).
Untuk segera terjun ke semua pesona ML, saya memutuskan untuk segera memilih kompetisi yang serius. Tersebut hanya tersedia:
Two Sigma: Menggunakan Berita untuk Memprediksi Pergerakan Saham . Inti dari kontes singkatnya adalah untuk memprediksi harga saham berbagai perusahaan berdasarkan status aset dan berita terkait dengan aset ini. Dana hadiah kontes adalah $ 100.000, yang akan didistribusikan di antara para peserta yang memenangkan 7 tempat pertama.
Kompetisi ini istimewa karena dua alasan:
- ini adalah kontes Kernels-only: Anda hanya bisa melatih model di cloud Kaggle Kernels;
- distribusi akhir kursi hanya akan diketahui enam bulan setelah selesainya pengambilan keputusan; selama ini, keputusan akan memprediksi harga pada tanggal saat ini.
Tentang tugas
Dengan syarat, kita harus memprediksi kepercayaan diri
dalam hal pengembalian atas aset akan meningkat. Pengembalian aset dianggap relatif terhadap pengembalian pasar secara keseluruhan. Metrik target adalah khusus - ini bukan
RMSE atau
MAE yang lebih akrab, tetapi
rasio Sharpe , yang dalam hal ini dianggap sebagai berikut:
dimana
,
- pengembalian aset i relatif terhadap pasar untuk hari t pada cakrawala 10 hari,
- variabel Boolean yang menunjukkan apakah aset engan dimasukkan dalam penilaian untuk hari t,
- nilai rata-rata
,
- standar deviasi
.
Rasio Sharpe adalah pengembalian yang disesuaikan dengan risiko, nilai-nilai koefisien menunjukkan efektivitas pedagang:
- kurang dari 1: kinerja buruk
- 1 - 2: efisiensi sedang, normal,
- 2 - 3: kinerja luar biasa,
- lebih dari 3: sempurna.
Data Pergerakan Pasar- waktu (datetime64 [ns, UTC]) - waktu saat ini (dalam data pergerakan pasar di semua lini pada pukul 22:00 UTC)
- assetCode (objek) - pengidentifikasi aset
- assetName (kategori) - pengidentifikasi kelompok aset untuk komunikasi dengan data berita
- universe (float64) - nilai boolean yang menunjukkan apakah aset ini akan diperhitungkan dalam penghitungan skor
- volume (float64) - volume perdagangan harian
- close (float64) - harga penutupan untuk hari ini
- open (float64) - harga terbuka untuk hari ini
- returnsClosePrevRaw1 (float64) - hasil dari penutupan ke penutupan untuk hari sebelumnya
- returnsOpenPrevRaw1 (float64) - profitabilitas dari pembukaan hingga pembukaan untuk hari sebelumnya
- returnsClosePrevMktres1 (float64) - profitabilitas dari penutupan hingga penutupan untuk hari sebelumnya, disesuaikan relatif terhadap pergerakan pasar secara keseluruhan
- returnsOpenPrevMktres1 (float64) - profitabilitas dari pembukaan ke pembukaan untuk hari sebelumnya, disesuaikan relatif terhadap pergerakan pasar secara keseluruhan
- returnsClosePrevRaw10 (float64) - hasil dari dekat ke tutup selama 10 hari sebelumnya
- returnsOpenPrevRaw10 (float64) - profitabilitas dari pembukaan hingga pembukaan selama 10 hari sebelumnya
- returnsClosePrevMktres10 (float64) - hasil dari dekat ke penutupan selama 10 hari sebelumnya, disesuaikan relatif terhadap pergerakan pasar secara keseluruhan
- returnsOpenPrevMktres10 (float64) - hasil dari pembukaan hingga pembukaan selama 10 hari sebelumnya, disesuaikan relatif terhadap pergerakan pasar secara keseluruhan
- returnsOpenNextMktres10 (float64) - hasil dari pembukaan ke pembukaan selama 10 hari ke depan, disesuaikan dengan pergerakan pasar secara keseluruhan. Kami akan memprediksi nilai ini.
Data berita- waktu (datetime64 [ns, UTC]) - waktu dalam ketersediaan data UTC
- sourceTimestamp (datetime64 [ns, UTC]) - waktu dalam berita publikasi UTC
- firstCreated (datetime64 [ns, UTC]) - waktu dalam UTC dari versi pertama data
- sourceId (objek) - pengidentifikasi rekaman
- informasi utama (objek) - judul
- urgency (int8) - jenis berita (1: waspada, 3: artikel)
- takeSequence (int16) - parameter tidak cukup jelas, angka dalam beberapa urutan
- provider (kategori) - pengidentifikasi penyedia berita
- subyek (kategori) - daftar kode topik berita (dapat berupa tanda geografis, acara, sektor industri, dll.)
- audiences (kategori) - daftar kode audiensi berita
- bodySize (int32) - jumlah karakter di badan berita
- companyCount (int8) - jumlah perusahaan yang disebutkan secara eksplisit dalam berita
- headlineTag (objek) - tag judul tertentu dari Thomson Reuters
- marketCommentary (bool) - tanda bahwa berita tersebut berkaitan dengan kondisi pasar secara umum
- kalimatCount (int16) - jumlah penawaran dalam berita
- wordCount (int32) - jumlah kata dan tanda baca dalam berita
- assetCodes (kategori) - daftar aset yang disebutkan dalam berita
- assetName (kategori) - kode grup aset
- firstMentionSentence (int16) - kalimat yang pertama kali menyebutkan aset:
- relevance (float32) - angka dari 0 hingga 1, menunjukkan relevansi berita terkait aset tersebut
- sentimentClass (int8) - kelas nada suara berita
- sentimentNegative (float32) - probabilitas bahwa nada suara negatif
- sentimentNeutral (float32) - probabilitas bahwa warnanya netral
- sentimentPositive (float32) - probabilitas bahwa kuncinya adalah positif
- sentimentWordCount (int32) - jumlah kata dalam teks yang terkait dengan aset
- noveltyCount12H (int16) - berita "kebaruan" dalam 12 jam, dihitung relatif terhadap berita sebelumnya tentang aset ini
- noveltyCount24H (int16) - sama, dalam 24 jam
- noveltyCount3D (int16) - sama, dalam 3 hari
- noveltyCount5D (int16) - sama, dalam 5 hari
- noveltyCount7D (int16) - sama, dalam 7 hari
- volumeCounts12H (int16) - jumlah berita tentang aset ini dalam 12 jam
- volumeCounts24H (int16) - sama, dalam 24 jam
- volumeCounts3D (int16) - sama, dalam 3 hari
- volumeCounts5D (int16) - sama, selama 5 hari
- volumeCounts7D (int16) - sama, dalam 7 hari
Tugas dasarnya adalah tugas klasifikasi biner, yaitu, kami memprediksi tanda biner, akan menghasilkan kenaikan (1 kelas) atau menurun (kelas 0).
Tentang Alat
Kernel Kaggle adalah platform komputasi awan yang mendukung kolaborasi. Jenis kernel berikut ini didukung:
- Skrip python
- Script R.
- Notebook Jupyter
- RMarkdown
Setiap kernel berjalan dalam wadah buruh pelabuhan. Sejumlah besar paket dipasang di wadah, daftar untuk python dapat ditemukan di
sini . Spesifikasi teknis adalah sebagai berikut:
- CPU: 4 core,
- RAM: 17 GB,
- drive: 5 GB permanen dan 16 GB sementara,
- waktu menjalankan skrip maksimum: 9 jam (pada awal kompetisi 6 jam).
GPU juga tersedia di kernel, namun GPU dilarang dalam kontes ini.
Keras adalah kerangka kerja jaringan saraf tingkat tinggi yang berjalan di atas
TensorFlow ,
CNTK, atau
Theano . Ini adalah API yang sangat mudah dan mudah dipahami, dan dimungkinkan untuk menambahkan topologi jaringan Anda, fungsi kehilangan, dan lainnya menggunakan API backend.
Scikit-belajar adalah perpustakaan besar algoritma pembelajaran mesin. Sumber yang berguna untuk preprocessing data dan algoritma analisis data untuk digunakan dengan kerangka kerja yang lebih khusus.
Validasi model
Sebelum mengirimkan model untuk evaluasi, Anda perlu memeriksa secara lokal seberapa baik kerjanya - yaitu, datang dengan cara untuk validasi lokal. Saya mencoba pendekatan berikut:
- validasi silang vs pembagian proporsional sederhana ke dalam set pelatihan / tes;
- perhitungan lokal rasio Sharpe vs ROC AUC .
Akibatnya, hasil yang paling dekat dengan penilaian kompetitif, anehnya, menunjukkan kombinasi partisi proporsional (secara empiris memilih partisi 0,85 / 0,15) dan AUC. Validasi silang mungkin tidak terlalu cocok, karena perilaku pasar sangat berbeda pada tahap awal data pelatihan dan pada periode evaluasi. Mengapa AUC bekerja lebih baik daripada rasio Sharpe - Saya tidak bisa mengatakannya sama sekali.
Upaya pertama
Karena tugasnya adalah untuk memprediksi deret waktu, yang pertama diuji solusi klasik - jaringan saraf berulang (
RNN ), atau lebih tepatnya, variannya
LSTM dan
GRU .
Prinsip utama dari jaringan berulang adalah bahwa untuk setiap nilai output, tidak satu sampel adalah input, tetapi seluruh rangkaian. Dari sini berikut bahwa:
- kita membutuhkan beberapa pemrosesan awal data awal - pembuatan sekuens panjang t hari ini untuk setiap aset;
- model berdasarkan jaringan berulang tidak dapat memprediksi nilai output jika tidak ada data untuk t hari sebelumnya.
Saya menghasilkan urutan untuk setiap hari, dimulai dengan t, jadi untuk t yang cukup besar (dari 20) set lengkap sampel pelatihan tidak lagi sesuai dengan memori. Masalahnya diselesaikan menggunakan generator, karena Keras dapat menggunakan generator sebagai input dan output set data untuk pelatihan dan prediksi.
Persiapan awal data sedapat mungkin naif: kami mengambil seluruh data pasar ditambah menambahkan beberapa fitur (hari dalam seminggu, bulan, jumlah minggu dalam setahun), dan kami tidak menyentuh data berita sama sekali.
Model pertama menggunakan t = 10 dan terlihat seperti ini:
model = Sequential() model.add(LSTM(256, activation=act.tanh, return_sequences=True, input_shape=(data.timesteps, data.features))) model.add(LSTM(256, activation=act.relu)) model.add(Dense(data.assets, activation=act.relu)) model.add(Dense(data.assets))
Tidak ada yang memadai diperas dari model ini, skornya mendekati nol (bahkan sedikit minus).
Jaringan Konvolusional Temporal
Solusi jaringan saraf yang lebih modern untuk prediksi deret waktu adalah TCN. Inti dari topologi ini sangat sederhana: kami mengambil jaringan konvolusional satu dimensi dan menerapkannya pada urutan panjang t kami. Opsi yang lebih maju menggunakan beberapa lapisan konvolusional dengan pelebaran yang berbeda. Implementasi TCN sebagian disalin (kadang-kadang pada tingkat ide)
dari sini (visualisasi tumpukan TCN diambil dari
artikel Wavenet ).
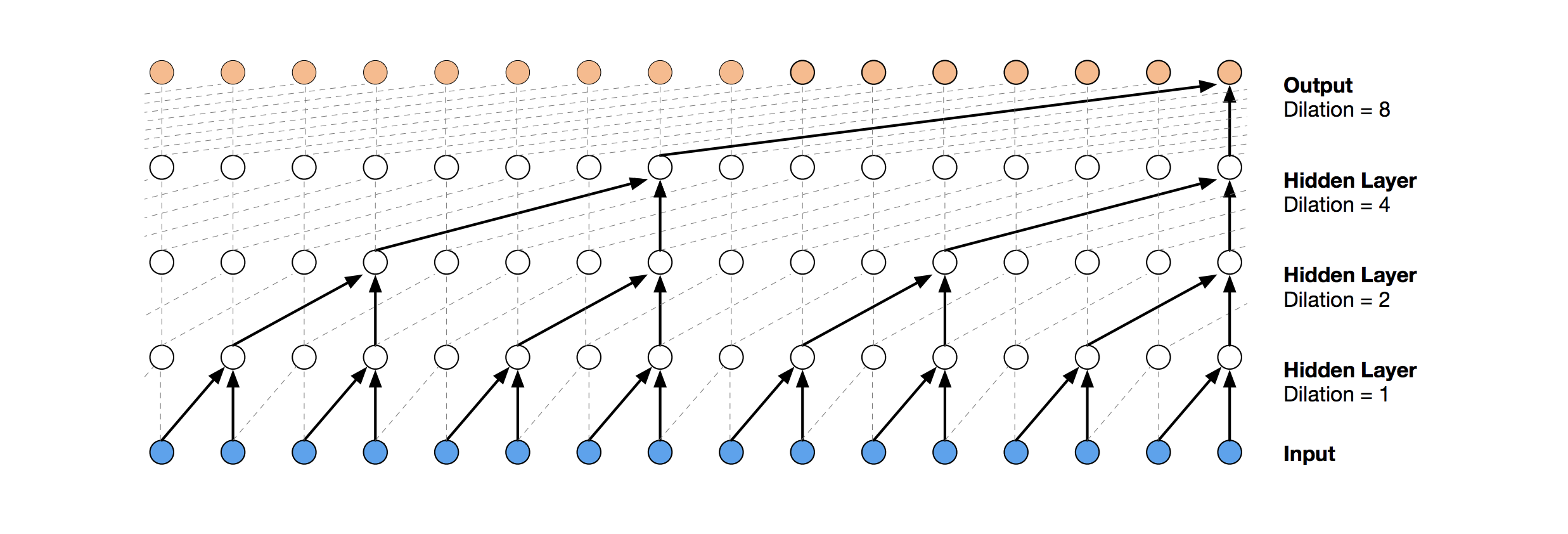
Solusi yang relatif sukses pertama adalah model ini, yang mencakup lapisan GRU di atas TCN:
model = Sequential() model.add(Conv1D(512,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(100,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(256)) model.add(Dense(data.assets, activation=act.relu))
Model seperti itu menghasilkan skor = 0,27668. Dengan sedikit penyetelan (jumlah filter TCN, ukuran batch) dan peningkatan t hingga 100, kami sudah mendapatkan 0,41092:
batch_size = 512 model = Sequential() model.add(Conv1D(8,3, activation=act.relu, padding='causal', input_shape=(data.timesteps, data.features))) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=2)) model.add(Conv1D(4,3, activation=act.relu, padding='causal', dilation_rate=4)) model.add(GRU(16)) model.add(Dense(1, activation=act.sigmoid))
Selanjutnya kita tambahkan normalisasi dan dropout:
Kode batch_size = 512 dropout_rate = 0.05 def channel_normalization(x): max_values = K.max(K.abs(x), 2, keepdims=True) + 1e-5 out = x / max_values return out model = Sequential() if(data.timesteps > 1): model.add(Conv1D(16,2, activation=act.relu, padding='valid', input_shape=(data.timesteps, data.features))) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) for i in range(1, 6): model.add(Conv1D(16,2, activation=act.relu, padding='valid', dilation_rate=2**i)) model.add(Lambda(channel_normalization)) model.add(SpatialDropout1D(dropout_rate)) model.add(Conv1D(16,1, padding='valid')) model.add(Flatten()) else: model.add(Flatten(input_shape=(data.timesteps, data.features))) model.add(Dense(256, activation=act.relu)) model.add(Dense(1, activation=act.sigmoid))
Menerapkan model ini, termasuk pada langkah awal (dengan t = 1), kita mendapatkan skor = 0,53578.
Mesin Peningkat Gradien
Pada tahap ini, ide-ide berakhir, dan saya memutuskan untuk melakukan apa yang perlu dilakukan di awal: untuk melihat keputusan publik dari peserta lain. Sebagian besar solusi yang baik tidak menggunakan jaringan saraf sama sekali, lebih memilih GBM.
Gradient Boosting adalah metode ML, yang hasilnya kami dapatkan ansambel model sederhana (paling sering pohon keputusan). Karena sejumlah besar model sederhana seperti itu, fungsi kerugian dioptimalkan. Anda dapat membaca lebih lanjut tentang Peningkatan Gradien, misalnya, di
sini .
Sebagai implementasi GBM digunakan
lightgbm - kerangka kerja yang cukup terkenal dari Microsoft.
Model dan preprocessing data yang diambil
dari sini segera memberikan skor sekitar 0,64:
Kode def prepare_data(marketdf, newsdf):
Pra-pemrosesan di sini sudah termasuk data berita, menggabungkannya dengan data pasar (namun, melakukannya dengan naif, hanya satu kode aset dari semua yang disebutkan dalam berita yang diperhitungkan). Saya mengambil opsi pra-pemrosesan ini sebagai dasar untuk semua keputusan selanjutnya.
Dengan menambahkan sedikit fitur (firstMentionSentence, marketCommentary, sentimentClass), dan juga mengganti metrik dengan
ROC AUC , kami mendapatkan skor 0,65389.
Ensemble
Keputusan sukses berikutnya adalah menggunakan ensemble yang terdiri dari model jaringan saraf dan GBM (meskipun "ensemble" adalah nama besar untuk dua model). Prediksi yang dihasilkan diperoleh dengan rata-rata prediksi kedua model, sehingga menerapkan mekanisme voting lunak. Keputusan ini diizinkan untuk mendapatkan skor 0,66879.
Analisis Data Eksplorasi dan Rekayasa Fitur
Hal lain untuk memulai adalah EDA. Setelah membaca bahwa penting untuk memahami korelasi antara fitur, kami membuat gambar seperti itu (gambar di bagian ini dapat diklik):
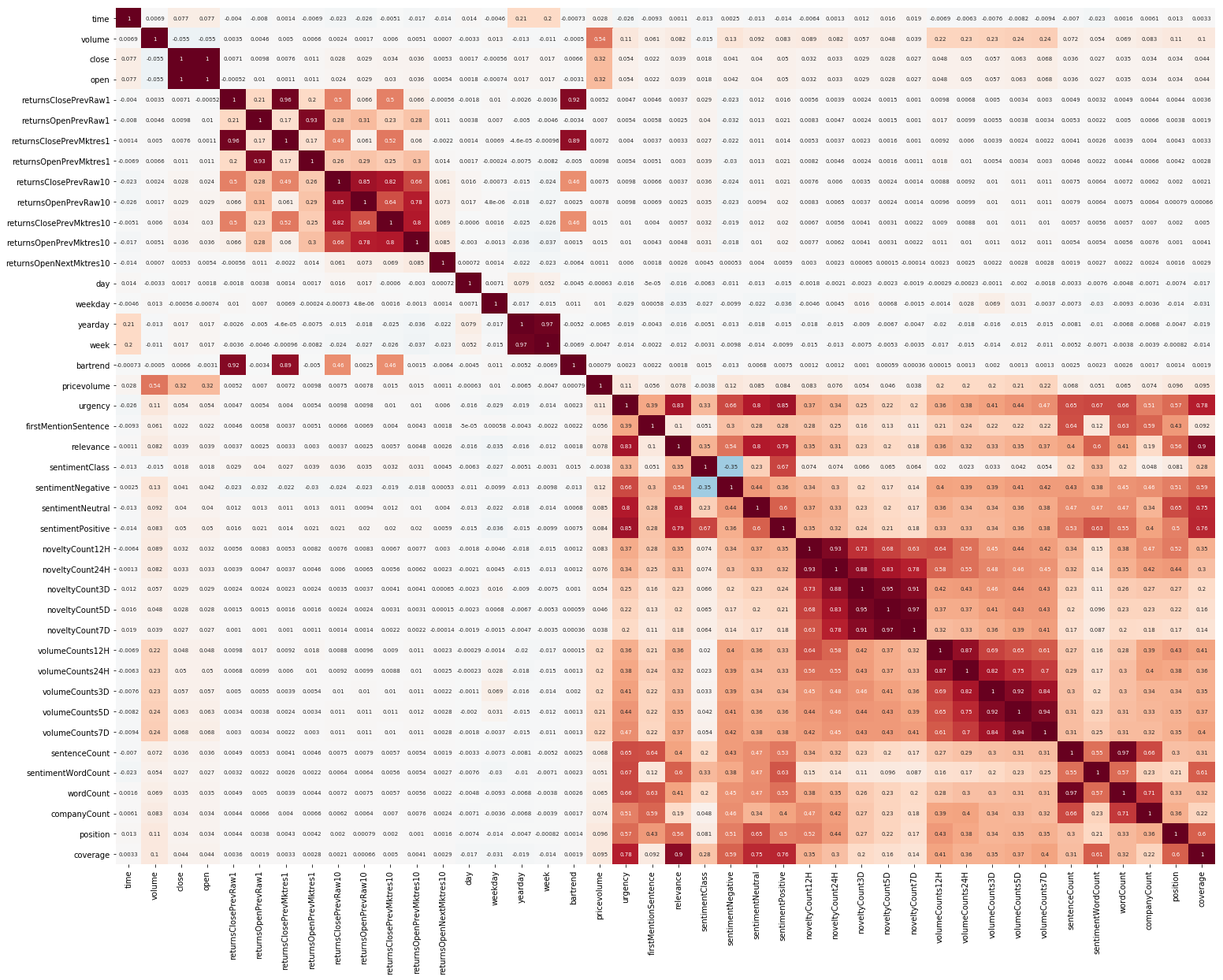
Jelas terlihat di sini bahwa korelasi secara terpisah di dalam pasar dan data berita cukup tinggi, namun, hanya nilai-nilai pengembalian berkorelasi dengan nilai target setidaknya entah bagaimana. Karena data mewakili deret waktu, masuk akal juga untuk melihat autokorelasi nilai target:
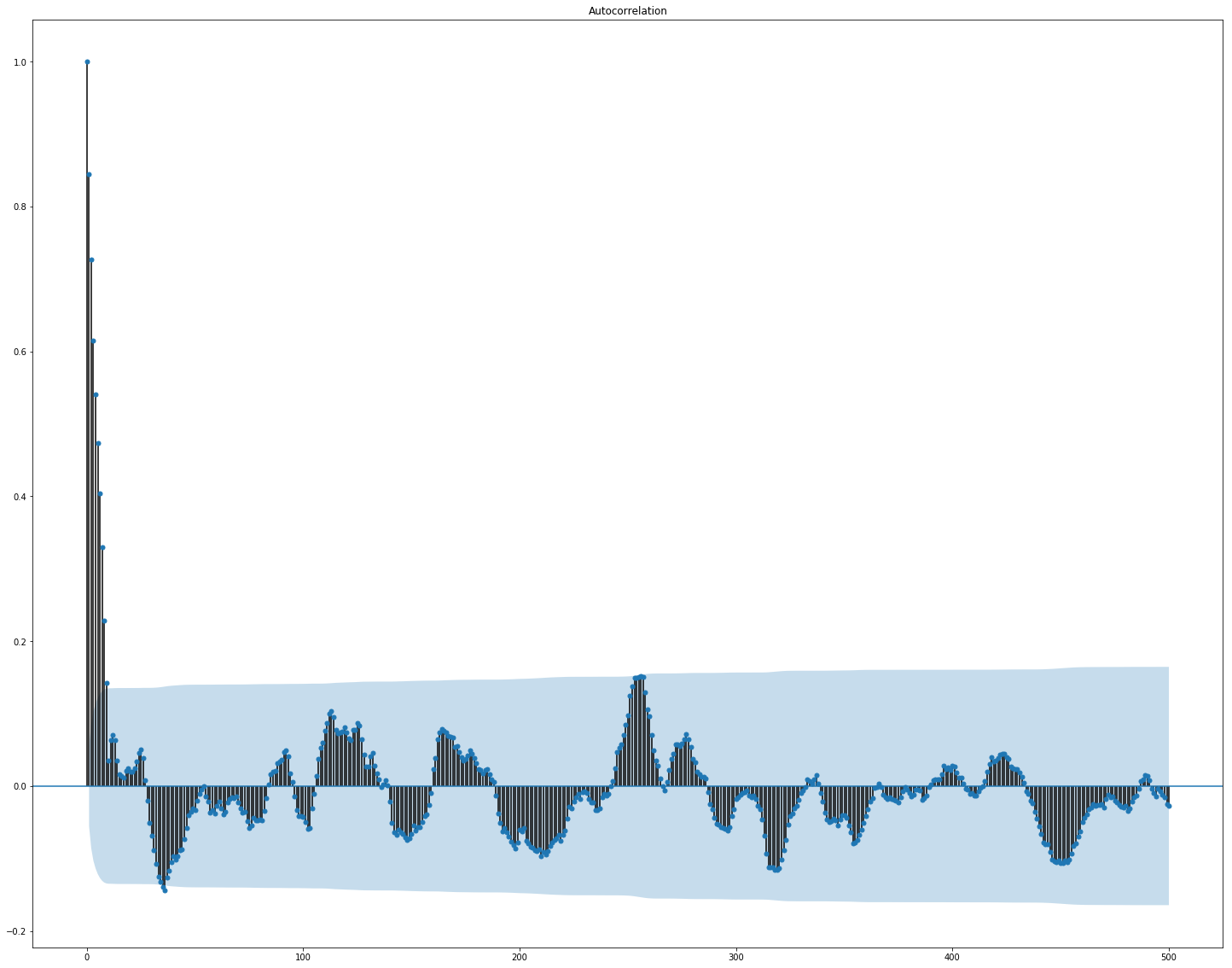
Dapat dilihat bahwa setelah periode 10 hari, ketergantungan menurun secara signifikan. Ini mungkin yang menyebabkan GBM bekerja dengan baik, dengan mempertimbangkan hanya fitur akun dengan penundaan 10 hari (yang sudah ada dalam kumpulan data asli).
Pemilihan fitur dan preprocessing sangat penting untuk semua algoritma ML. Mari kita coba menggunakan cara otomatis untuk mengekstrak fitur, yaitu,
analisis komponen utama (
PCA ):
from sklearn.decomposition import PCA from sklearn.preprocessing import StandardScaler market_x = market_data.loc[:,features] scaler = StandardScaler() scaler.fit(market_x) market_x = scaler.transform(market_x) pca = PCA(.95) pca.fit(market_x) market_pca = pca.transform(market_x)
Mari kita lihat fitur apa yang dihasilkan PCA:

Kami melihat bahwa metode ini tidak bekerja dengan baik pada data kami, karena korelasi akhir dari fitur baru dengan nilai target kecil.
Penalaan yang bagus dan apakah perlu
Banyak model ML memiliki jumlah hyperparameter yang cukup besar, yaitu, "pengaturan" dari algoritma itu sendiri. Mereka dapat dipilih secara manual, tetapi ada juga mekanisme seleksi otomatis. Untuk yang terakhir, ada pustaka
hyperopt yang mengimplementasikan dua algoritma pencocokan - pencarian acak dan
Penaksir Parzen Tree-structured (TPE) . Saya mencoba mengoptimalkan:
- parameter lightgbm (jenis algoritme, jumlah daun, laju pembelajaran, dan lainnya),
- parameter model jaringan saraf (jumlah filter TCN , jumlah blok memori GRU , tingkat putus sekolah, tingkat pembelajaran, jenis solver).
Hasilnya, semua solusi yang ditemukan menggunakan optimasi ini memberikan skor yang lebih rendah, meskipun mereka bekerja lebih baik pada data uji. Mungkin, alasannya terletak pada fakta bahwa data yang skornya dinilai tidak sangat mirip dengan data validasi yang dipilih dari pelatihan. Jadi, untuk tugas ini, fine tuning sangat tidak cocok, karena mengarah ke pelatihan ulang model.
Keputusan akhir
Menurut aturan kompetisi, peserta dapat memilih dua solusi untuk tahap akhir. Keputusan akhir saya hampir sama dan berisi ansambel dua model -
GBM dan
GRU multilayer. Satu-satunya perbedaan adalah bahwa satu solusi tidak menggunakan data berita sama sekali, dan yang lainnya menggunakannya, tetapi hanya untuk model jaringan saraf.
Solusi Data Berita:
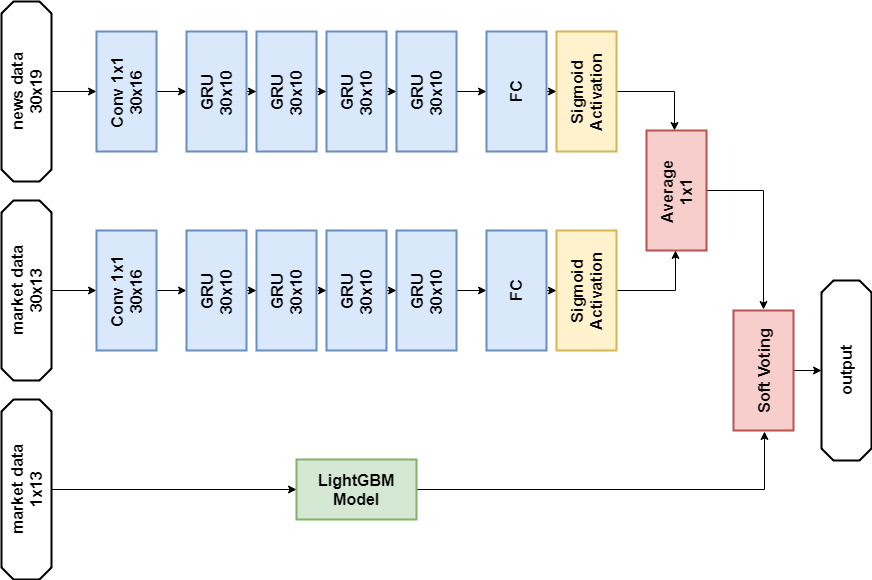
Impor import numpy as np import pandas as p import itertools import functools from kaggle.competitions import twosigmanews from sklearn.preprocessing import StandardScaler, LabelEncoder import tensorflow as tf from keras.models import Sequential, Model from keras.layers import Dense, GRU, LSTM, Conv1D, Reshape, Flatten, SpatialDropout1D, Lambda, Input, Average from keras.optimizers import Adam, SGD, RMSprop from keras import losses as ls from keras import activations as act import keras.backend as K import lightgbm as lgb
Model jaringan saraf def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) x2 = Lambda(lambda x: x[:,:,13:])(i) x2 = Conv1D(16,1, padding='valid')(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10, return_sequences=True)(x2) x2 = GRU(10)(x2) x2 = Dense(1, activation=act.sigmoid)(x2) x = Average()([x1, x2]) model = Model(inputs=i, outputs=x) return model def train_model_time_series(model, data, val_data=None): print('Building model...') batch_size = 4096 optimizer = RMSprop()
Model GBM def train_model(data, val_data=None): print('Building model...') params = { "objective" : "binary", "metric" : "auc", "num_leaves" : 60, "max_depth": -1, "learning_rate" : 0.01, "bagging_fraction" : 0.9,
Pelatihan n_timesteps = 30 market_data, news_data = cleanData(market_train_df, news_train_df) dates = market_data['time'].unique() train = range(len(dates))[:int(0.85*len(dates))] val = range(len(dates))[int(0.85*len(dates)):] train_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[train])], news_data.loc[news_data['time'] <= max(dates[train])]) val_data_prepared = prepareData(market_data.loc[market_data['time'].isin(dates[val])], news_data.loc[news_data['time'] > max(dates[train])], scaler=train_data_prepared.scaler) model_gbm = train_model(train_data_prepared, val_data_prepared) train_data_ts = generateTimeSeries(train_data_prepared, n_timesteps=n_timesteps) val_data_ts = generateTimeSeries(val_data_prepared, n_timesteps=n_timesteps) rnn = buildRNN(train_data_ts.timesteps, train_data_ts.features) model_rnn = train_model_time_series(rnn, train_data_ts, val_data_ts)
Prediksi def make_predictions(data, template, model): if(hasattr(data, 'gen')): prediction = (model.predict(data.gen(data.samples)) * 2 - 1)[:,-1] else: prediction = model.predict(data.x) * 2 - 1 predsdf = p.DataFrame({'ast':data.assets,'conf':prediction}) template['confidenceValue'][template['assetCode'].isin(predsdf.ast)] = predsdf['conf'].values return template day = 1 days_data = p.DataFrame({}) days_data_len = [] days_data_n = p.DataFrame({}) days_data_n_len = [] for (market_obs_df, news_obs_df, predictions_template_df) in env.get_prediction_days(): print(f'Predicting day {day}') days_data = p.concat([days_data, market_obs_df], ignore_index=True, copy=False, sort=False) days_data_len.append(len(market_obs_df)) days_data_n = p.concat([days_data_n, news_obs_df], ignore_index=True, copy=False, sort=False) days_data_n_len.append(len(news_obs_df)) data = prepareData(market_obs_df, news_obs_df, scaler=train_data_prepared.scaler) predictions_df = make_predictions(data, predictions_template_df.copy(), model_gbm) if(day >= n_timesteps): data = prepareData(days_data, days_data_n, scaler=train_data_prepared.scaler) data = generateTimeSeries(data, n_timesteps=n_timesteps) predictions_df_s = make_predictions(data, predictions_template_df.copy(), model_rnn) predictions_df['confidenceValue'] = (predictions_df['confidenceValue'] + predictions_df_s['confidenceValue']) / 2 days_data = days_data[days_data_len[0]:] days_data_n = days_data_n[days_data_n_len[0]:] days_data_len = days_data_len[1:] days_data_n_len = days_data_n_len[1:] env.predict(predictions_df) day += 1 env.write_submission_file()
Solusi tanpa data berita:

Kode (hanya metode yang berbeda) def buildRNN(timesteps, features): i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
Kedua keputusan memberikan hasil yang sama (sekitar 0,69) pada tahap pertama kompetisi, yang sesuai dengan 566 dari 2.927 tempat. Setelah bulan pertama data baru, posisi dalam daftar peserta dicampur-aduk, dan solusi dengan data berita berada di tempat ke-65 dari 697 tim yang tersisa dengan hasil 3,19251, dan apa yang akan terjadi selama lima bulan ke depan, tidak ada yang tahu.
Apa lagi yang saya coba
Metrik khusus
Karena keputusan dievaluasi menggunakan rasio Sharpe, logis untuk mencoba menggunakannya sebagai metrik untuk penghentian awal pelatihan.
Metrik untuk lightgbm:
def sharpe_metric(y_pred, train_data): y_true = train_data.get_label() * 2 - 1 std = np.std(y_true * y_pred) mean = np.mean(y_true * y_pred) sharpe = np.divide(mean, std, out=np.zeros_like(mean), where=std!=0) return "sharpe", sharpe, True
Verifikasi menunjukkan bahwa metrik seperti itu bekerja lebih buruk dalam masalah ini daripada AUC.
Mekanisme perhatian
Mekanisme perhatian memungkinkan jaringan saraf untuk fokus pada fitur "paling penting" dalam sumber data. Secara teknis, perhatian diwakili oleh vektor bobot (paling sering diperoleh dengan menggunakan lapisan yang sepenuhnya terhubung dengan aktivasi
softmax ), yang dikalikan dengan output dari lapisan lain. Saya menggunakan implementasi di mana perhatian diterapkan pada sumbu waktu:
def buildRNN(timesteps, features): def attention_3d_block(inputs): a = Permute((2, 1))(inputs) a = Dense(timesteps, activation=act.softmax)(a) a = Permute((2, 1))(a) mul = Multiply()([inputs, a]) return mul i = Input(shape=(timesteps, features)) x1 = Lambda(lambda x: x[:,:,:13])(i) x1 = Conv1D(16,1, padding='valid')(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10, return_sequences=True)(x1) x1 = attention_3d_block(x1) x1 = GRU(10)(x1) x1 = Dense(1, activation=act.sigmoid)(x1) model = Model(inputs=i, outputs=x1) return model
Model ini terlihat cukup cantik, tetapi pendekatan ini tidak memberikan peningkatan skor, ternyata sekitar 0,67.
Apa yang tidak punya waktu untuk dilakukan
Beberapa area yang terlihat menjanjikan:
Kesimpulan
Petualangan kami telah berakhir, Anda dapat mencoba untuk meringkas. Persaingan ternyata sulit, tetapi kami tidak bisa menghadapi tanah. Ini mengisyaratkan bahwa ambang batas untuk memasuki ML tidak terlalu tinggi, tetapi, seperti dalam bisnis apa pun, sihir nyata (dan ada banyak hal dalam pembelajaran mesin) sudah tersedia bagi para profesional.
Hasil dalam angka:
- Skor maksimum di tahap pertama: ~ 0,69 melawan ~ 1,5 di tempat pertama. Sesuatu seperti rata-rata untuk rumah sakit, nilai 0,7 diatasi oleh beberapa, skor maksimum dari keputusan publik juga ~ 0,69, sedikit lebih dari milikku.
- Tempatkan di tahap pertama: 566 dari 2927.
- Skor di tahap kedua: 3.19251 setelah bulan pertama.
- Tempatkan di tahap kedua: 65 dari 697 setelah bulan pertama.
Saya menarik perhatian Anda pada fakta bahwa angka-angka pada tahap kedua tidak secara khusus berbicara tentang apa pun, karena masih sangat sedikit data untuk penilaian kualitatif terhadap keputusan.
Referensi
Solusi terakhir menggunakan beritaTwo Sigma: Menggunakan Berita untuk Memprediksi Pergerakan Saham - Halaman Kontes
Keras - Neural
Network FrameworkLightGBM - kerangka kerja GBM
Scikit-learn - perpustakaan algoritma pembelajaran mesin
Hyperopt - perpustakaan untuk mengoptimalkan hiperparameter
Artikel tentang WaveNet