Kita semua tahu bagaimana tanah air dimulai, dan pembelajaran mendalam dimulai dengan data. Tanpa mereka, tidak mungkin untuk melatih model, mengevaluasinya, dan memang menggunakannya. Terlibat dalam penelitian, meningkatkan indeks Hirsch dengan artikel tentang arsitektur jaringan saraf baru dan bereksperimen, kami mengandalkan sumber data lokal yang paling sederhana; biasanya file dalam berbagai format. Ini bekerja, tetapi akan menyenangkan untuk mengingat sistem pertempuran yang berisi terabyte data yang terus berubah. Dan ini berarti Anda perlu menyederhanakan dan mempercepat transfer data dalam produksi, serta dapat bekerja dengan data besar. Di sinilah Apache Ignite masuk.
Apache Ignite adalah database sentris-memori terdistribusi, serta platform untuk caching dan pemrosesan operasi yang terkait dengan transaksi, analisis, dan beban streaming. Sistem ini mampu menggiling petabyte data dengan kecepatan RAM. Artikel ini akan fokus pada integrasi antara Apache Ignite dan TensorFlow, yang memungkinkan Anda untuk menggunakan Apache Ignite sebagai sumber data untuk melatih jaringan saraf dan inferensi, serta repositori model terlatih dan sistem manajemen kluster untuk pembelajaran terdistribusi.
Sumber Data RAM Terdistribusi
Apache Ignite memungkinkan Anda untuk menyimpan dan memproses data sebanyak yang Anda butuhkan di cluster terdistribusi. Untuk memanfaatkan Apache Ignite ini saat melatih jaringan saraf di TensorFlow, gunakan
Ignite Dataset .
Catatan: Apache Ignite bukan hanya salah satu tautan dalam pipa ETL antara database atau data warehouse dan TensorFlow. Apache Ignite sendiri adalah
HTAP (sistem hybrid untuk pemrosesan data transaksional / analitik). Memilih Apache Ignite dan TensorFlow, Anda mendapatkan sistem tunggal untuk pemrosesan transaksional dan analitis, dan pada saat yang sama, kemampuan untuk menggunakan data operasional dan historis untuk melatih jaringan saraf dan inferensi.
Tolok ukur berikut menunjukkan bahwa Apache Ignite sangat cocok untuk skenario di mana data disimpan pada satu host. Sistem seperti ini memungkinkan Anda untuk mencapai throughput lebih dari 850 Mb / s, jika data warehouse dan klien berada pada node yang sama. Jika penyimpanan terletak pada host jarak jauh, maka throughputnya sekitar 800 Mb / s.
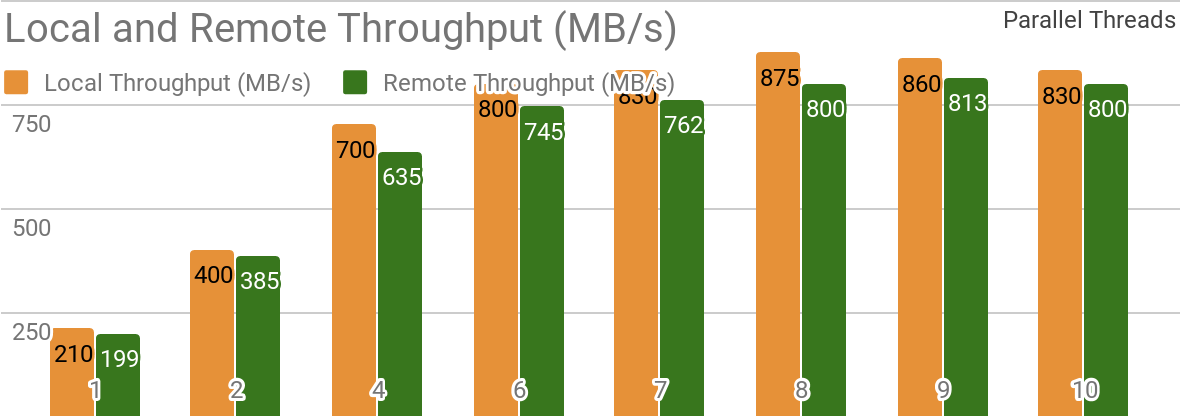
Grafik menunjukkan bandwidth untuk Ignite Dataset untuk node Apache Ignite lokal tunggal. Hasil ini diperoleh pada prosesor 1.7GHz 2x Xeon E5-2609 v4 dengan 16GB RAM dan pada jaringan dengan bandwidth 10GB / s (setiap catatan memiliki ukuran 1MB, ukuran halaman - 20MB).
Tolok ukur lain menunjukkan bagaimana Ignite Dataset bekerja dengan kluster Apache Ignite yang didistribusikan. Konfigurasi ini yang dipilih secara default saat menggunakan Apache Ignite sebagai sistem HTAP dan memungkinkan Anda untuk mencapai bandwidth untuk satu klien lebih dari 1 GB / s pada sebuah cluster dengan bandwidth 10 Gb / s.
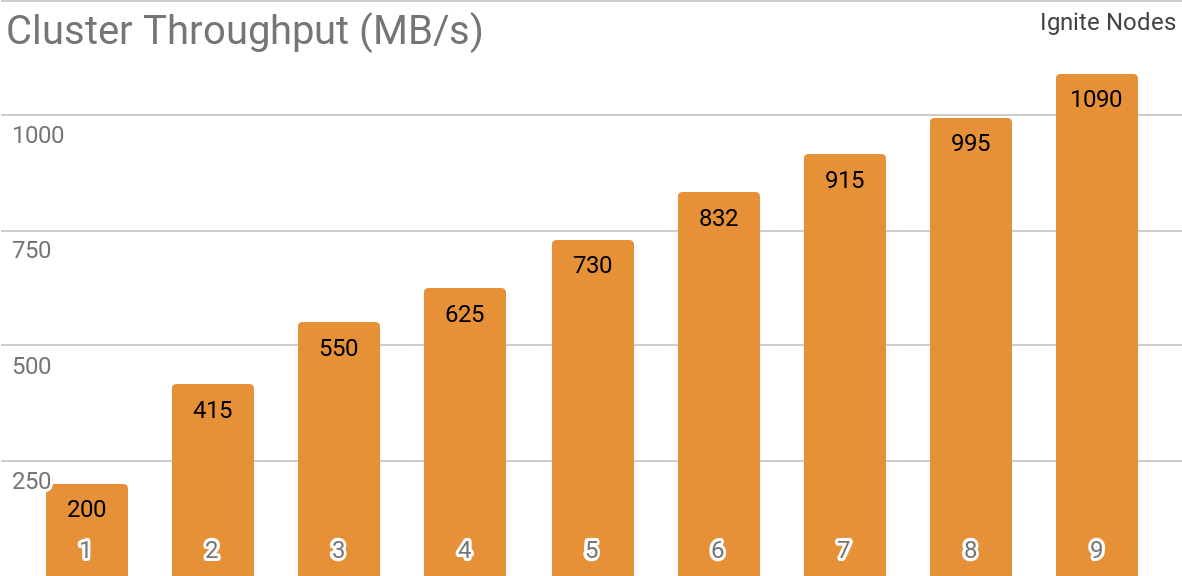
Grafik menunjukkan throughput Ignite Dataset untuk cluster Apache Ignite terdistribusi dengan jumlah node yang berbeda (dari 1 hingga 9). Hasil ini diperoleh pada prosesor 1.7GHz 2x Xeon E5-2609 v4 dengan 16GB RAM dan pada jaringan dengan bandwidth 10GB / s (setiap catatan memiliki ukuran 1MB, ukuran halaman - 20MB).
Skenario berikut diuji: Cache Apache Ignite (dengan sejumlah variabel partisi di set pertama pengujian dan dengan 2048 partisi di yang kedua) diisi dengan 10K baris masing-masing 1 MB, setelah itu klien TensorFlow membaca data menggunakan Ignite Dataset. Cluster dibangun dari mesin dengan 2x Xeon E5-2609 v4 1,7 GHz, memori 16 GB dan terhubung melalui jaringan yang beroperasi pada kecepatan 10 GB / s. Pada setiap node, Apache Ignite bekerja dalam
konfigurasi standar .
Apache Ignite mudah digunakan sebagai database klasik dengan antarmuka SQL dan pada saat yang sama sebagai sumber data untuk TensorFlow.
$ apache-ignite/bin/ignite.sh $ apache-ignite/bin/sqlline.sh -u "jdbc:ignite:thin://localhost:10800/"
CREATE TABLE KITTEN_CACHE (ID LONG PRIMARY KEY, NAME VARCHAR); INSERT INTO KITTEN_CACHE VALUES (1, 'WARM KITTY'); INSERT INTO KITTEN_CACHE VALUES (2, 'SOFT KITTY'); INSERT INTO KITTEN_CACHE VALUES (3, 'LITTLE BALL OF FUR');
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="SQL_PUBLIC_KITTEN_CACHE") for element in dataset: print(element)
{'key': 1, 'val': {'NAME': b'WARM KITTY'}} {'key': 2, 'val': {'NAME': b'SOFT KITTY'}} {'key': 3, 'val': {'NAME': b'LITTLE BALL OF FUR'}}
Benda terstruktur
Apache Ignite memungkinkan Anda untuk menyimpan objek jenis apa pun yang dapat dibangun dalam hierarki apa pun. Anda dapat bekerja dengannya melalui Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES") for element in dataset.take(1): print(element)
{ 'key': 'kitten.png', 'val': { 'metadata': { 'file_name': b'kitten.png', 'label': b'little ball of fur', 'width': 800, 'height': 600 }, 'pixels': [0, 0, 0, 0, ..., 0] } }
Pelatihan jaringan saraf dan perhitungan lainnya memerlukan pra-pemrosesan, yang dapat dilakukan sebagai bagian dari pipa
tf.data jika Anda menggunakan Ignite Dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES").map(lambda obj: obj['val']['pixels']) for element in dataset: print(element)
[0, 0, 0, 0, ..., 0]
Pelatihan yang didistribusikan
TensorFlow adalah kerangka pembelajaran mesin yang
mendukung pembelajaran jaringan saraf terdistribusi, inferensi, dan komputasi lainnya. Seperti yang Anda tahu, pelatihan jaringan saraf didasarkan pada perhitungan gradien dari fungsi kerugian. Dalam hal pelatihan terdistribusi, kita dapat menghitung gradien ini di setiap partisi, lalu mengagregasinya. Ini adalah metode ini yang memungkinkan Anda untuk menghitung gradien untuk masing-masing node tempat data disimpan, merangkumnya dan, akhirnya, memperbarui parameter model. Dan, karena kita menyingkirkan transmisi data sampel pelatihan antara node, jaringan tidak menjadi "bottleneck" dari sistem.
Apache Ignite menggunakan partisi horizontal (sharding) untuk menyimpan data dalam cluster terdistribusi. Dengan membuat cache Ignite Apache (atau tabel, dalam hal SQL), Anda dapat menentukan jumlah partisi di mana data akan didistribusikan. Misalnya, jika kluster Apache Ignite terdiri dari 100 mesin, dan kami membuat cache dengan 1000 partisi, maka setiap mesin akan bertanggung jawab atas sekitar 10 partisi dengan data.
Ignite Dataset memungkinkan Anda untuk menggunakan dua aspek ini untuk pelatihan jaringan saraf terdistribusi. Ignite Dataset adalah simpul
grafik komputasi yang membentuk dasar arsitektur TensorFlow. Dan, seperti simpul apa pun dalam grafik, ia dapat berjalan pada simpul jarak jauh di dalam kluster. Node jarak jauh seperti itu dapat menimpa Ignite Dataset parameter (misalnya,
host ,
port atau
part ), mengatur variabel lingkungan yang sesuai untuk alur kerja (misalnya,
IGNITE_DATASET_HOST ,
IGNITE_DATASET_PORT atau
IGNITE_DATASET_PART ). Dengan menggunakan override tersebut, Anda dapat menetapkan partisi tertentu untuk setiap node cluster. Kemudian satu node bertanggung jawab untuk satu partisi dan pada saat yang sama pengguna menerima satu fasad pekerjaan dengan dataset.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset dataset = IgniteDataset("IMAGES")
Apache Ignite juga memungkinkan untuk pembelajaran terdistribusi menggunakan pustaka
API Estimator tingkat tinggi TensorFlow. Fungsionalitas ini didasarkan pada apa yang disebut
mode pembelajaran
mandiri klien yang didistribusikan di TensorFlow, di mana Apache Ignite bertindak sebagai sumber data dan sistem manajemen cluster. Artikel selanjutnya akan sepenuhnya dikhususkan untuk topik ini.
Belajar Penyimpanan Titik Kontrol
Selain kemampuan basis data, Apache Ignite juga memiliki sistem file
IGFS terdistribusi. Secara fungsional, ini menyerupai sistem file Hadoop HDFS, tetapi hanya dalam RAM. Bersamaan dengan APInya sendiri, sistem file IGFS mengimplementasikan Hadoop FileSystem API dan secara transparan dapat terhubung ke Hadoop atau Spark yang digunakan. Pustaka TensorFlow di Apache Ignite menyediakan integrasi antara IGFS dan TensorFlow. Integrasi didasarkan pada plugin
sistem file milik
TensorFlow dan API IGFS asli Apache Ignite. Ada berbagai skenario untuk penggunaannya, misalnya:
- Pos pemeriksaan status disimpan di IGFS untuk keandalan dan toleransi kesalahan.
- Proses pembelajaran berinteraksi dengan TensorBoard dengan menulis file acara ke direktori yang dipantau oleh TensorBoard. IGFS memastikan bahwa komunikasi tersebut operasional bahkan ketika TensorBoard sedang berjalan di proses lain atau di mesin lain.
Fungsionalitas tersebut muncul dalam rilis TensorFlow 1.13.0.rc0, dan juga akan menjadi bagian dari
tensorflow / io dalam rilis TensorFlow 2.0.
Koneksi SSL
Apache Ignite memungkinkan Anda untuk mengamankan saluran data menggunakan
SSL dan otentikasi. Ignite Dataset mendukung koneksi SSL dengan dan tanpa otentikasi. Lihat dokumentasi
Apache Ignite SSL / TLS untuk lebih jelasnya.
import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() dataset = IgniteDataset(cache_name="IMAGES", certfile="client.pem", cert_password="password", username="ignite", password="ignite")
Dukungan Windows
Ignite Dataset sepenuhnya kompatibel dengan Windows. Ini dapat digunakan sebagai bagian dari TensorFlow pada workstation Windows, serta pada sistem Linux / MacOS.
Coba sendiri
Contoh di bawah ini akan membantu Anda memulai dengan modul.
Menyalakan dataset
Cara termudah untuk memulai dengan Ignite Dataset adalah memulai wadah
Docker dengan Apache Ignite dan mengunduh data
MNIST , dan kemudian bekerja dengannya menggunakan Ignite Dataset. Wadah semacam itu tersedia di Docker Hub:
dmitrievanthony / ignite-with-mnist . Anda perlu menjalankan wadah di mesin Anda:
docker run -it -p 10800:10800 dmitrievanthony/ignite-with-mnist
Setelah itu, Anda dapat bekerja dengannya sebagai berikut:
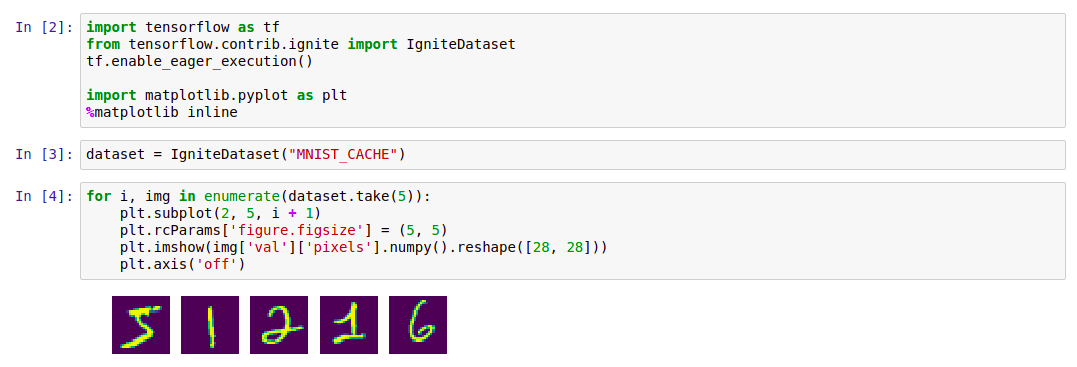
Kode import tensorflow as tf from tensorflow.contrib.ignite import IgniteDataset tf.enable_eager_execution() import matplotlib.pyplot as plt %matplotlib inline dataset = IgniteDataset("MNIST_CACHE") for i, img in enumerate(dataset.take(5)): plt.subplot(2, 5, i + 1) plt.rcParams['figure.figsize'] = (5, 5) plt.imshow(img['val']['pixels'].numpy().reshape([28, 28])) plt.axis('off')
IGFS
Dukungan TensorFlow IGFS muncul dalam rilis TensorFlow 1.13.0rc0 dan juga akan menjadi bagian dari rilis
tensorflow / io di TensorFlow 2.0. Untuk mencoba IGFS dengan TensorFlow, cara termudah untuk memulai wadah
Docker adalah dengan Apache Ignite + IGFS, dan kemudian bekerja dengannya menggunakan TensorFlow
tf.gfile . Wadah semacam itu tersedia di Docker Hub:
dmitrievanthony / ignite-with-igfs . Wadah ini dapat dijalankan di mesin Anda:
docker run -it -p 10500:10500 dmitrievanthony/ignite-with-igfs
Maka Anda dapat bekerja dengannya seperti ini:
import tensorflow as tf import tensorflow.contrib.ignite.python.ops.igfs_ops with tf.gfile.Open("igfs:///hello.txt", mode='w') as w: w.write("Hello, world!") with tf.gfile.Open("igfs:///hello.txt", mode='r') as r: print(r.read())
Hello, world!
Keterbatasan
Saat ini, ketika bekerja dengan Ignite Dataset, diasumsikan bahwa semua objek dalam cache memiliki struktur yang sama (objek homogen), dan bahwa cache berisi setidaknya satu objek yang diperlukan untuk mengambil skema. Keterbatasan lain menyangkut objek terstruktur: Ignite Dataset tidak mendukung UUID, Maps, dan array Obyek, yang dapat menjadi bagian dari objek. Menghapus batasan-batasan ini, serta menstabilkan dan menyinkronkan versi TensorFlow dan Apache Ignite, adalah salah satu tugas pengembangan yang sedang berlangsung.
Versi TensorFlow 2.0 yang diharapkan
Perubahan yang akan datang ke TensorFlow 2.0 akan menyoroti fitur-fitur ini dalam modul
tensorflow / io . Setelah itu, bekerja bersama mereka dapat dibangun lebih fleksibel. Contoh-contoh akan sedikit berubah, dan ini akan tercermin dalam gihab dan dalam dokumentasi.