Berkat analisis waktu nyata, kami, karyawan Uber, mendapatkan gagasan tentang kondisi hubungan kerja dan efisiensi kerja, dan berdasarkan data kami memutuskan bagaimana meningkatkan kualitas kerja pada platform Uber. Misalnya, tim proyek memantau keadaan pasar dan mengidentifikasi potensi masalah pada platform kami; perangkat lunak yang didasarkan pada model pembelajaran mesin memprediksi penawaran dan permintaan penumpang untuk pengemudi; spesialis pemrosesan data meningkatkan model pembelajaran mesin - pada gilirannya, untuk meningkatkan kualitas perkiraan.

Di masa lalu, untuk analisis waktu nyata, kami menggunakan solusi basis data dari perusahaan lain, tetapi tidak ada yang memenuhi semua kriteria kami untuk fungsionalitas, skalabilitas, efisiensi, biaya, dan persyaratan operasional.
Dirilis pada November 2018, AresDB adalah alat analisis real-time open source. Ini menggunakan catu daya tidak konvensional, prosesor grafis (GPU), yang memungkinkan Anda untuk meningkatkan skala analisis. Teknologi GPU, alat analisis waktu nyata yang menjanjikan, telah meningkat secara signifikan dalam beberapa tahun terakhir, menjadikannya ideal untuk komputasi paralel dan pemrosesan data secara real-time.
Pada bagian berikut, kami menggambarkan struktur AresDB dan bagaimana solusi menarik ini untuk analisis waktu nyata memungkinkan kami untuk lebih efisien dan lebih rasional menyatukan, menyederhanakan, dan meningkatkan solusi basis data Uber untuk analisis waktu nyata. Kami berharap bahwa setelah membaca artikel ini Anda akan mencoba AresDB sebagai bagian dari proyek Anda sendiri dan juga memastikan kegunaannya!
Uber aplikasi analisis real-time
Analisis data sangat penting untuk keberhasilan Uber. Di antara fungsi-fungsi lain, alat analitik digunakan untuk menyelesaikan tugas-tugas berikut:
- Membangun dasbor untuk memantau metrik bisnis.
- Membuat keputusan otomatis (misalnya, menentukan biaya perjalanan dan mengidentifikasi kasus penipuan ) berdasarkan metrik ringkasan yang dikumpulkan.
- Buat kueri acak untuk mendiagnosis, memecahkan masalah, dan memecahkan masalah operasi bisnis.
Kami mengategorikan fungsi-fungsi ini dengan persyaratan yang berbeda sebagai berikut:

Dasbor dan sistem pengambilan keputusan menggunakan sistem analisis waktu-nyata untuk membuat pertanyaan serupa pada subset data yang relatif kecil tetapi sangat penting (dengan tingkat relevansi data tertinggi) dengan QPS tinggi dan latensi rendah.
Perlu modul analitik lain
Masalah paling umum yang Uber gunakan alat analisis real-time untuk menyelesaikan adalah menghitung populasi deret waktu. Perhitungan ini memberikan gambaran interaksi pengguna sehingga kami dapat meningkatkan kualitas layanan yang sesuai. Berdasarkan mereka, kami meminta indikator untuk parameter tertentu (misalnya, hari, jam, pengenal kota dan status perjalanan) untuk jangka waktu tertentu untuk data yang difilter secara acak (atau kadang-kadang digabungkan). Selama bertahun-tahun, Uber telah menggunakan beberapa sistem yang dirancang untuk menyelesaikan masalah ini dengan berbagai cara.
Berikut adalah beberapa solusi pihak ketiga yang kami gunakan untuk menyelesaikan jenis masalah ini:
- Apache Pinot , database analitik open source terdistribusi yang ditulis dalam Java, cocok untuk analisis data skala besar. Pinot menggunakan arsitektur lambda internal untuk meminta data paket dan data waktu-nyata dalam penyimpanan kolom, indeks bit terbalik untuk pemfilteran, dan pohon bintang untuk menyimpan hasil agregat. Namun, itu tidak mendukung deduplikasi berbasis kunci, memperbarui atau menyisipkan, menggabungkan, atau fitur permintaan lanjutan seperti penyaringan geospasial. Selain itu, karena Pinot adalah basis data berbasis JVM, permintaan sangat mahal dalam hal penggunaan memori.
- Elasticsearch digunakan oleh Uber untuk menyelesaikan berbagai tugas analisis streaming. Itu dibangun berdasarkan perpustakaan Apache Lucene , yang menyimpan dokumen, untuk pencarian kata kunci teks lengkap dan indeks terbalik. Sistem tersebar luas dan diperluas untuk mendukung data agregat. Indeks terbalik menyediakan pemfilteran tetapi tidak dioptimalkan untuk menyimpan dan memfilter data berdasarkan rentang waktu. Catatan disimpan dalam bentuk dokumen JSON, yang membebankan biaya tambahan untuk menyediakan akses ke repositori dan permintaan. Seperti Pinot, Elasticsearch adalah basis data berbasis JVM dan, karenanya, tidak mendukung fungsi gabungan, dan eksekusi permintaan menghabiskan banyak memori.
Meskipun teknologi ini memiliki kekuatan mereka, mereka tidak memiliki beberapa fitur yang dibutuhkan untuk kasus penggunaan kami. Kami membutuhkan solusi terpadu, disederhanakan dan dioptimalkan, dan dalam pencariannya kami bekerja ke arah yang tidak standar (lebih tepatnya, di dalam GPU).
Menggunakan GPU untuk analisis waktu-nyata
Untuk rendering gambar yang realistis dengan frame rate tinggi, GPU secara bersamaan memproses sejumlah besar bentuk dan piksel dengan kecepatan tinggi. Meskipun kecenderungan untuk meningkatkan frekuensi clock unit pemrosesan data selama beberapa tahun terakhir telah mulai menurun, jumlah transistor dalam chip telah meningkat hanya menurut hukum Moore . Akibatnya, kecepatan komputasi GPU, diukur dalam gigaflops per detik (Gflops / s), meningkat pesat. Gambar 1 di bawah ini menunjukkan perbandingan tren kecepatan teoritis (Gflops / s) dari NVIDIA GPU dan Intel CPU selama bertahun-tahun:
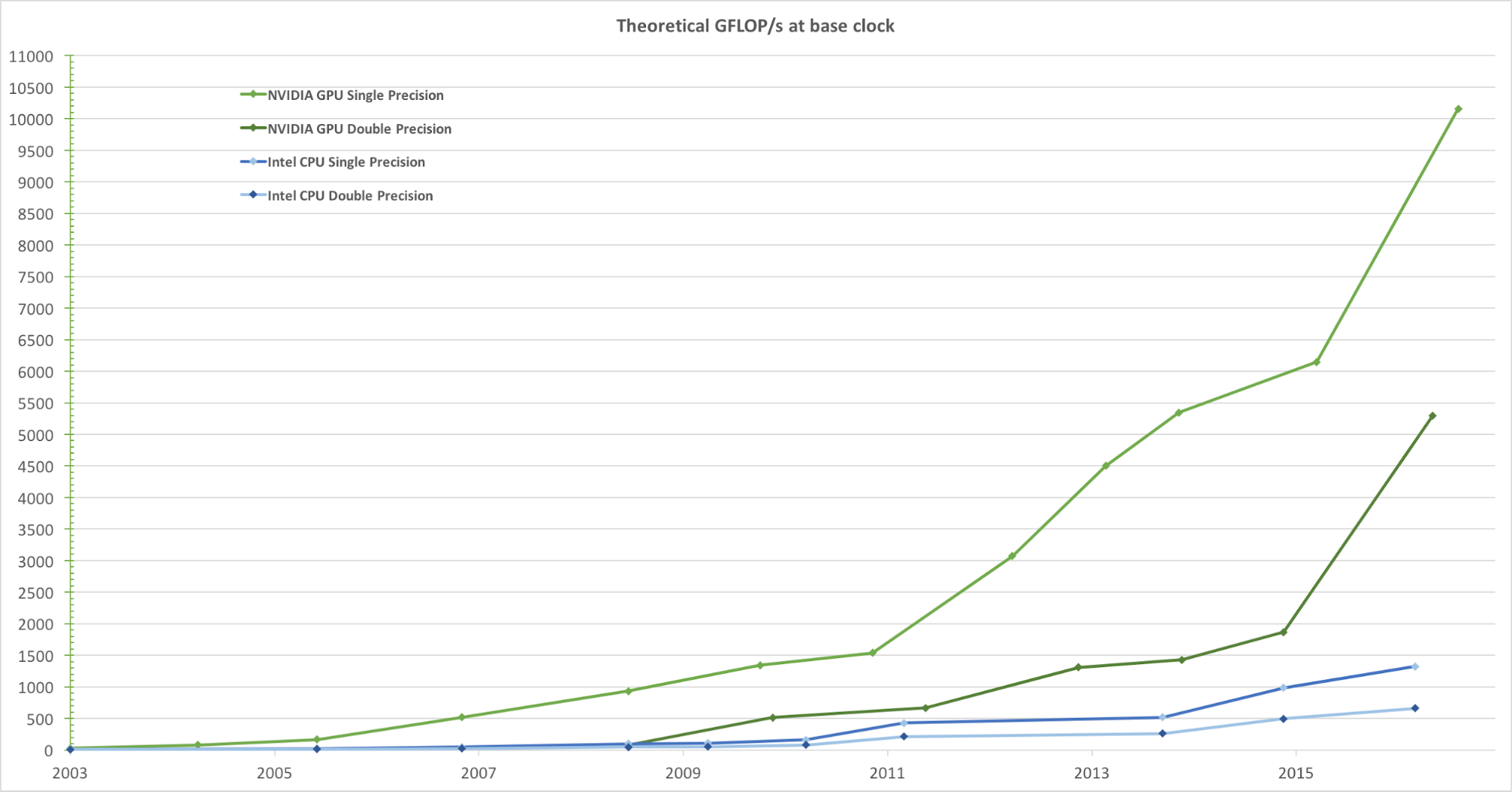
Gambar 1. Perbandingan kinerja floating-point CPU dan GPU presisi tunggal selama beberapa tahun. Gambar diambil dari Panduan Pemrograman CUDA C Nvidia.
Dalam mengembangkan mekanisme permintaan analisis waktu nyata, keputusan untuk mengintegrasikan GPU adalah wajar. Di Uber, permintaan analisis waktu-nyata yang khas membutuhkan pemrosesan data dalam beberapa hari dengan jutaan atau bahkan milyaran catatan, kemudian difilter dan diringkas dalam waktu singkat. Tugas komputasi ini sangat cocok dengan model pemrosesan paralel paralel GPU untuk keperluan umum, karena mereka:
- Mereka memproses data secara paralel dengan kecepatan yang sangat tinggi.
- Mereka memberikan kecepatan komputasi yang lebih tinggi (Gflops / s), yang membuatnya sangat baik untuk melakukan tugas komputasi yang kompleks (lebih dari blok data) yang dapat diparalelkan.
- Mereka memberikan kinerja yang lebih tinggi (tanpa penundaan) dalam pertukaran data antara unit komputasi dan penyimpanan (ALU dan memori global GPU) dibandingkan dengan unit pemrosesan pusat (CPU), menjadikannya ideal untuk memproses tugas I / O memori paralel, yang membutuhkan sejumlah besar data.
Berfokus pada penggunaan basis data analitik berbasis GPU, kami - dari sudut pandang kebutuhan kami - mengevaluasi beberapa solusi analitis yang ada yang menggunakan GPU:
- Kinetica , alat analitik berbasis GPU, memasuki pasar pada tahun 2009, awalnya untuk digunakan di Angkatan Darat AS dan agen intelijen. Meskipun menunjukkan potensi tinggi dari teknologi GPU dalam analitik, kami menemukan bahwa untuk kondisi penggunaan kami, banyak fungsi utama yang hilang, termasuk mengubah skema, memasukkan atau memperbarui sebagian, kompresi data, konfigurasi disk dan memori pada tingkat kolom, dan koneksi dengan hubungan geospasial.
- OmniSci , modul kueri SQL sumber terbuka, tampak seperti opsi yang menjanjikan, tetapi ketika mengevaluasi produk, kami menyadari bahwa ia tidak memiliki beberapa fitur penting untuk digunakan di Uber, seperti deduplikasi. Meskipun OminiSci memperkenalkan kode sumber terbuka proyeknya pada tahun 2017, setelah menganalisis solusi mereka berdasarkan C ++, kami sampai pada kesimpulan bahwa tidak mengubah atau bercabang basis kode mereka secara praktis layak.
- Alat analisis real-time berbasis GPU, termasuk GPUQP , CoGaDB , GPUDB , Ocelot , OmniDB , dan Virgin , sering digunakan dalam lembaga penelitian dan pendidikan. Namun, mengingat tujuan akademis mereka, keputusan ini fokus pada pengembangan algoritma dan konsep pengujian, daripada menyelesaikan masalah dunia nyata. Karena alasan ini, kami tidak memperhitungkannya - dalam kondisi volume dan skala kami.
Secara keseluruhan, sistem ini menunjukkan keuntungan besar dan potensi pemrosesan data menggunakan teknologi GPU, dan mereka mengilhami kami untuk membuat solusi analisis real-time GPU kami sendiri yang disesuaikan dengan kebutuhan Uber. Berdasarkan konsep-konsep ini, kami mengembangkan dan membuka kode sumber untuk AresDB.
Tinjauan Arsitektur AresDB
Pada tingkat tinggi, AresDB menyimpan sebagian besar data dalam memori host (RAM, yang terhubung ke CPU), menggunakan CPU untuk memproses data yang diterima dan disk untuk memulihkan data. Selama periode permintaan, AresDB mentransfer data dari memori host ke memori GPU untuk pemrosesan paralel dalam GPU. Seperti yang ditunjukkan pada Gambar 2 di bawah, AresDB termasuk penyimpanan memori, penyimpanan metadata, dan disk:

Gambar 2. Arsitektur unik AresDB termasuk penyimpanan memori, disk, dan penyimpanan metadata.
Tabel
Tidak seperti kebanyakan sistem manajemen basis data relasional (RDBMS), AresDB tidak memiliki basis data atau skema. Semua tabel milik lingkup yang sama dalam satu cluster / instance dari AresDB, yang memungkinkan pengguna untuk mengaksesnya secara langsung. Pengguna menyimpan data mereka dalam bentuk tabel fakta dan tabel dimensi.
Tabel fakta
Tabel fakta menyimpan aliran deret waktu yang tak ada habisnya. Pengguna menggunakan tabel fakta untuk menyimpan acara / fakta yang terjadi dalam waktu nyata, dan setiap acara dikaitkan dengan waktu acara, dan tabel tersebut sering ditanyakan pada waktu acara. Sebagai contoh dari jenis informasi yang disimpan dalam tabel fakta, kita dapat memberi nama perjalanan, di mana setiap perjalanan adalah acara, dan waktu permintaan perjalanan sering disebut sebagai waktu acara. Jika beberapa stempel waktu dikaitkan dengan suatu peristiwa, hanya satu stempel waktu diindikasikan sebagai waktu acara dan ditampilkan dalam tabel fakta.
Tabel pengukuran
Tabel pengukuran menyimpan karakteristik fasilitas saat ini (termasuk kota, pelanggan, dan pengemudi). Misalnya, pengguna dapat menyimpan informasi tentang kota, khususnya nama kota, zona waktu dan negara, dalam tabel pengukuran. Tidak seperti tabel fakta, yang terus tumbuh, tabel dimensi selalu terbatas dalam ukuran (misalnya, untuk Uber, tabel kota dibatasi oleh jumlah kota aktual di dunia). Tabel pengukuran tidak memerlukan kolom waktu khusus.
Tipe data
Tabel di bawah ini menunjukkan tipe data saat ini yang didukung oleh AresDB:
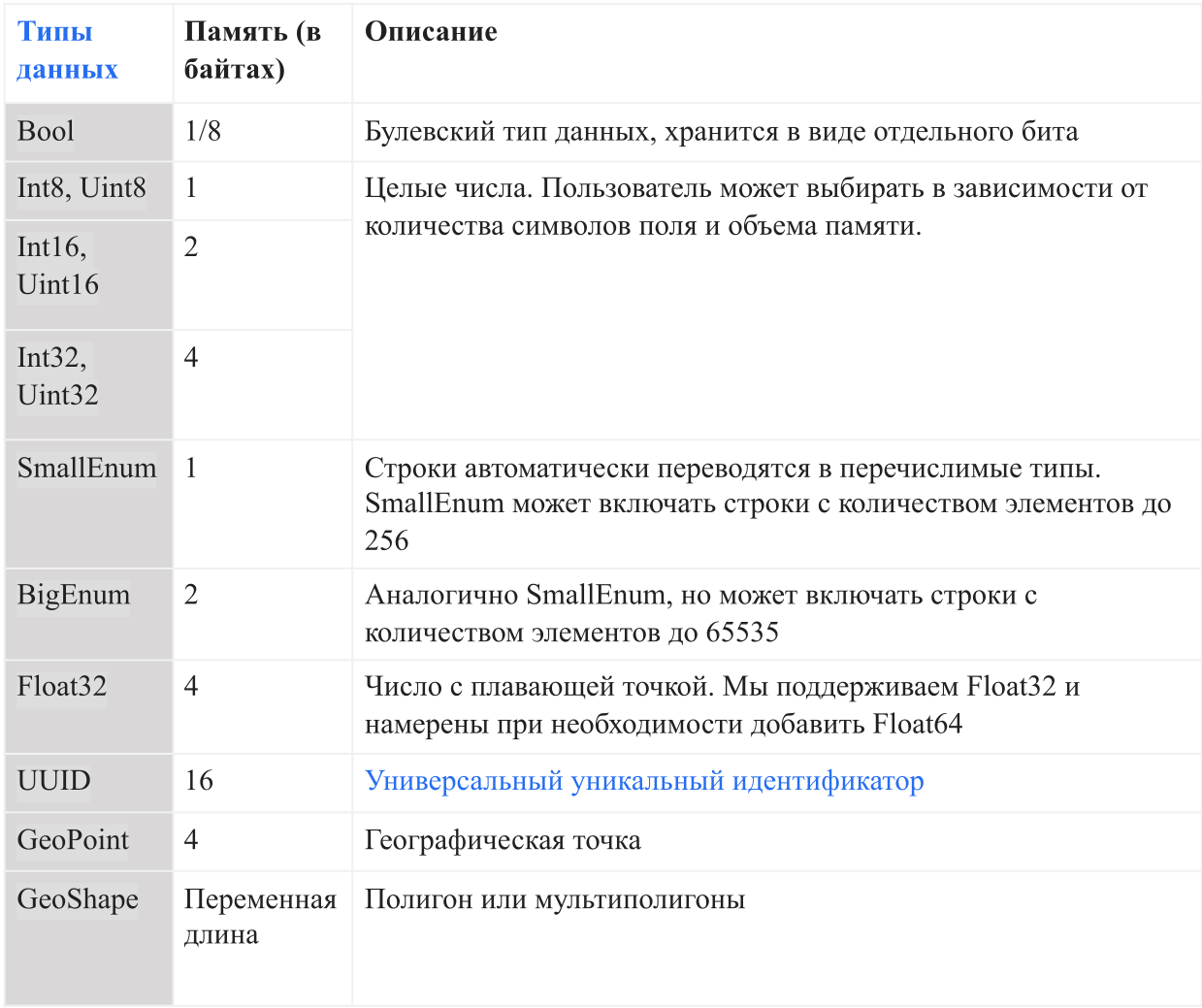
Di AresDB, string dikonversi ke enum secara otomatis sebelum mereka memasuki database untuk meningkatkan kenyamanan penyimpanan dan efisiensi permintaan. Ini memungkinkan pemeriksaan kesetaraan peka huruf besar-kecil, tetapi tidak mendukung operasi lanjutan seperti penggabungan, substring, topeng, dan pencocokan ekspresi reguler. Di masa mendatang, kami bermaksud menambahkan opsi dukungan garis penuh.
Fungsi utama
Arsitektur AresDB mendukung fitur-fitur berikut:
- Penyimpanan berbasis kolom dengan kompresi untuk meningkatkan efisiensi penyimpanan (lebih sedikit memori dalam byte untuk penyimpanan data) dan efisiensi kueri (pertukaran data lebih sedikit antara memori CPU dan memori GPU saat memproses permintaan)
- Pembaruan waktu-nyata atau masukkan dengan deduplikasi kunci utama untuk meningkatkan akurasi data dan memperbarui data waktu-nyata dalam beberapa detik
- Pemrosesan permintaan GPU untuk pemrosesan data GPU yang sangat paralel dengan latensi permintaan rendah (dari sepersekian detik hingga beberapa detik)
Penyimpanan kolom
Vektor
AresDB menyimpan semua data dalam format kolom. Nilai setiap kolom disimpan sebagai vektor nilai kolom. Marker nilai keyakinan / ketidakpastian pada setiap kolom disimpan dalam vektor nol yang terpisah, sedangkan nilai marka nilai keyakinan masing-masing disajikan sebagai satu bit.
Penyimpanan aktif
AresDB menyimpan data kolom yang tidak dikompresi dan tidak disortir (vektor aktif) dalam penyimpanan aktif. Catatan data dalam penyimpanan aktif dibagi menjadi paket (aktif) dari volume yang diberikan. Paket baru dibuat ketika data diterima, sementara paket lama dihapus setelah pengarsipan catatan. Indeks kunci utama digunakan untuk menemukan deduplikasi dan memperbarui catatan. Gambar 3 di bawah ini menunjukkan bagaimana kami mengatur catatan aktif dan menggunakan nilai kunci utama untuk menentukan lokasi mereka:
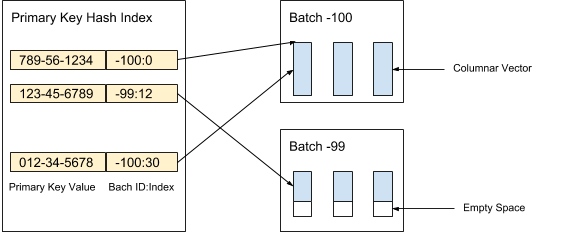
Gambar 3. Kami menggunakan nilai kunci utama untuk menentukan lokasi paket dan posisi setiap catatan dalam paket.
Nilai dari setiap kolom dalam paket disimpan sebagai vektor kolom. Marker reliabilitas / ketidakpastian nilai dalam setiap vektor nilai disimpan sebagai vektor nol yang terpisah, dan marker reliabilitas setiap nilai disajikan sebagai satu bit. Pada Gambar 4 di bawah ini, kami menawarkan contoh dengan lima nilai untuk kolom city_id :
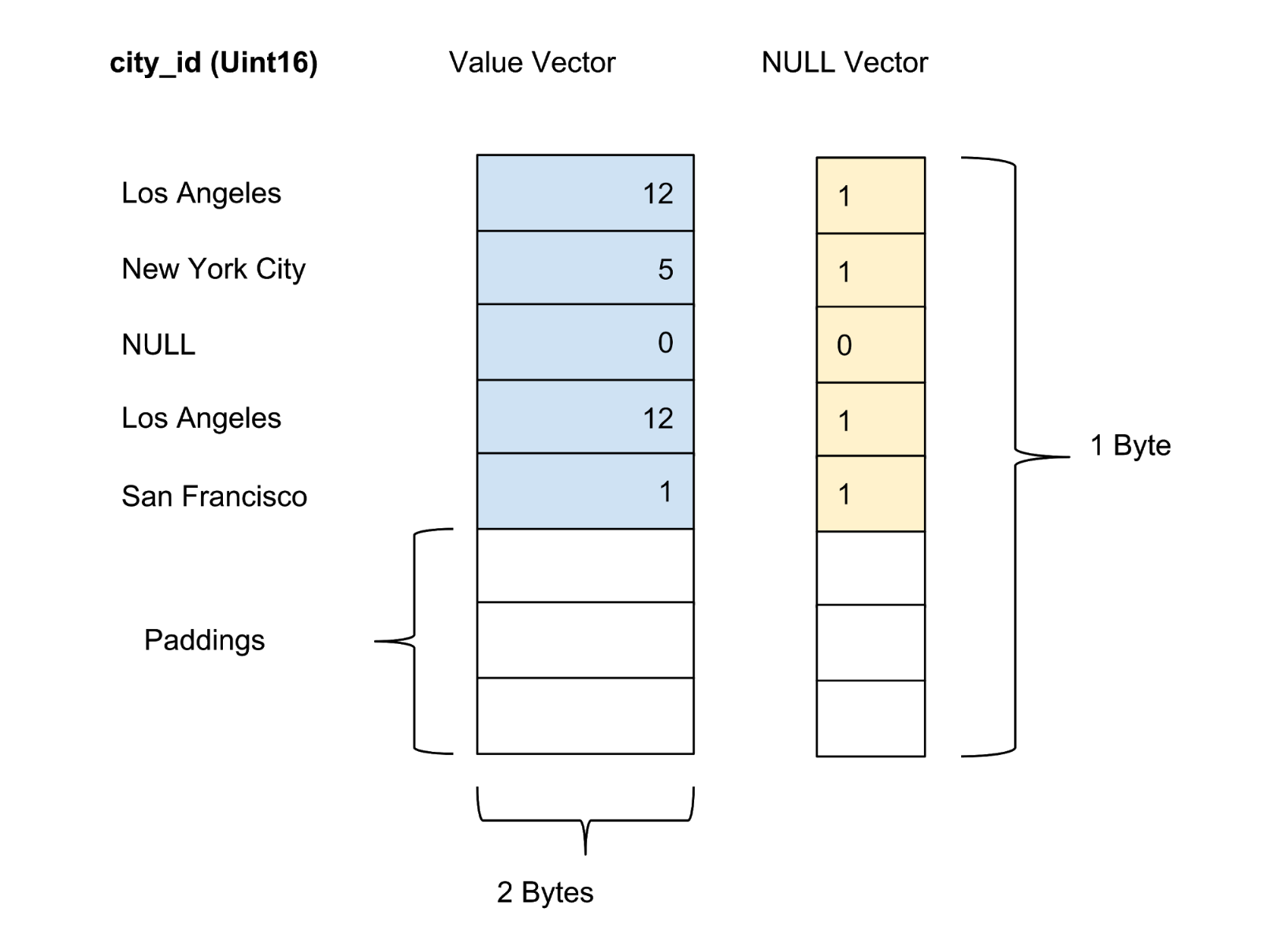
Gambar 4. Kami menyimpan nilai (nilai aktual) dan vektor nol (penanda kepercayaan) kolom terkompresi dalam tabel data.
Penyimpanan arsip
AresDB juga menyimpan data kolom yang telah diisi, disortir, dan dikompresi (arsip vektor) dalam penyimpanan arsip melalui tabel fakta. Catatan dalam penyimpanan arsip juga didistribusikan secara batch. Tidak seperti paket aktif, paket arsip menyimpan catatan per hari sesuai dengan Waktu Universal Terkoordinasi (UTC). Paket arsip telah menggunakan jumlah hari sebagai pengidentifikasi paket sejak Unix Epoch.
Catatan disimpan dalam bentuk diurutkan sesuai dengan urutan pengurutan kolom yang ditentukan pengguna. Seperti yang ditunjukkan pada Gambar 5 di bawah, kami mengurutkannya terlebih dahulu dengan kolom city_id , dan kemudian oleh kolom status:
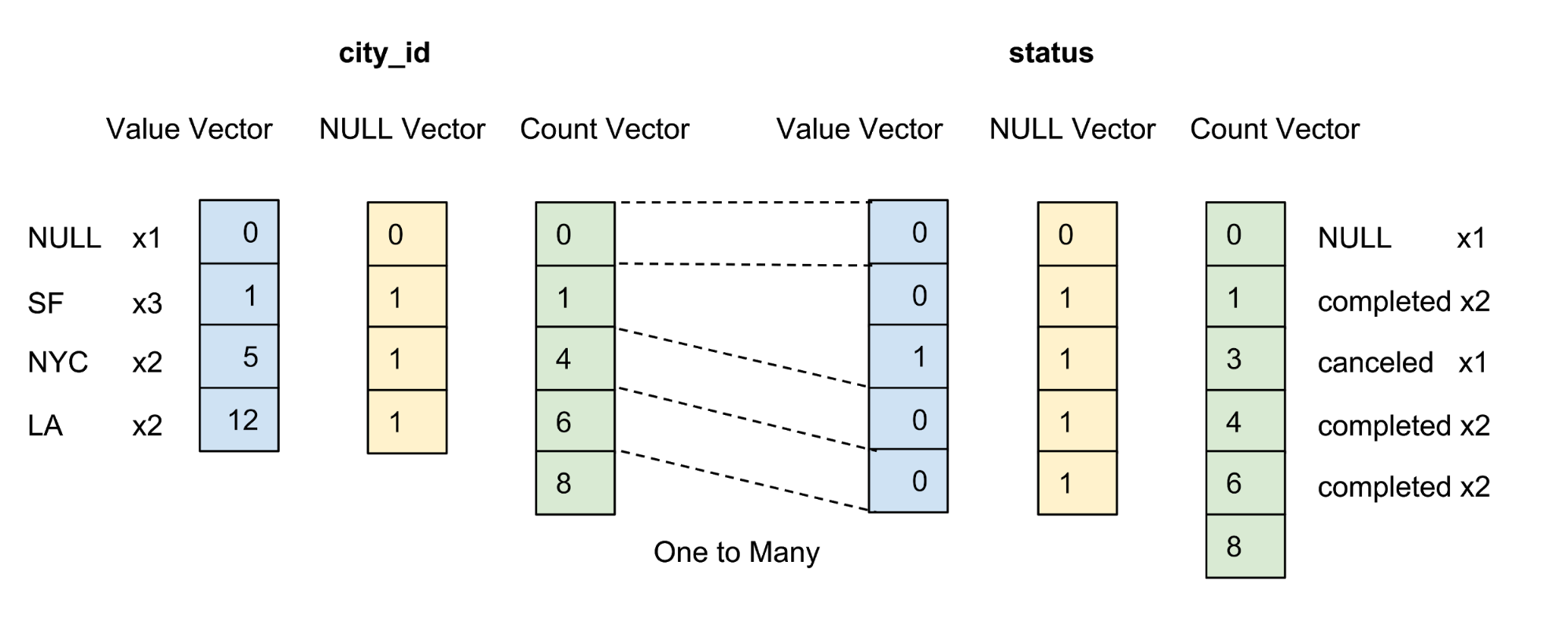
Gambar 5. Kami mengurutkan semua baris dengan city_id, lalu dengan negara, dan kemudian kompres setiap kolom dengan pengkodean grup. Setelah penyortiran dan kompresi, setiap kolom akan menerima vektor akuntansi.
Tujuan pengaturan urutan pengurutan pengguna untuk kolom adalah sebagai berikut:
- Memaksimalkan efek kompresi dengan menyortir kolom dengan sejumlah kecil elemen di tempat pertama. Kompresi maksimum meningkatkan efisiensi penyimpanan (lebih sedikit byte diperlukan untuk menyimpan data) dan efisiensi kueri (lebih sedikit byte yang ditransfer antara memori CPU dan memori GPU).
- Menyediakan pra-penyaringan berdasarkan rentang yang nyaman untuk filter setara umum, mis. City_id = 12. Pra-filtering meminimalkan jumlah byte yang diperlukan untuk mentransfer data antara memori CPU dan memori GPU, yang memaksimalkan efisiensi permintaan.
Kolom dikompresi hanya jika ada dalam urutan pengurutan yang ditentukan oleh pengguna. Kami tidak mencoba mengompres kolom dengan sejumlah besar elemen, karena ini menghemat sedikit memori.
Setelah mengurutkan, data untuk setiap kolom yang memenuhi syarat dikompres menggunakan opsi pengkodean grup tertentu. Selain vektor nilai dan vektor nol, kami memperkenalkan vektor akuntansi untuk mewakili kembali nilai yang sama.
Penerimaan data real-time dengan dukungan untuk fungsi pembaruan dan penyisipan
Klien menerima data melalui API HTTP dengan menerbitkan paket layanan. Paket layanan adalah format biner dipesan khusus yang meminimalkan penggunaan ruang sambil mempertahankan akses acak ke data.
Ketika AresDB menerima paket layanan, itu pertama menulis paket layanan ke log operasi pemulihan. Ketika paket layanan ditambahkan ke akhir log peristiwa, AresDB mengidentifikasi dan melompati entri yang terlambat di tabel fakta untuk digunakan dalam penyimpanan aktif. Catatan dianggap "terlambat" jika waktu acara lebih awal dari waktu yang diarsipkan dari acara putuskan. Untuk catatan yang tidak dianggap "terlambat," AresDB menggunakan indeks kunci utama untuk menemukan paket di dalam toko aktif di mana Anda ingin memasukkan mereka. Seperti yang ditunjukkan pada Gambar 6 di bawah ini, catatan baru (yang sebelumnya tidak ditemui berdasarkan nilai kunci utama) dimasukkan ke ruang kosong, dan catatan yang ada diperbarui secara langsung:
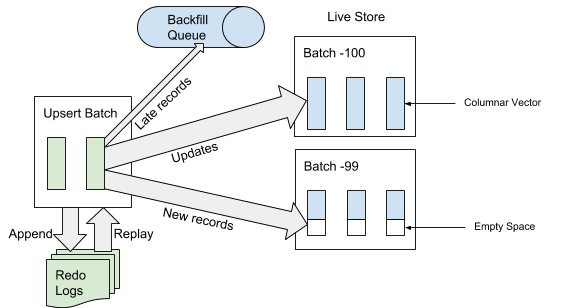
Gambar 6. Ketika data diterima, setelah menambahkan paket layanan ke log peristiwa, entri "terlambat" ditambahkan ke antrian terbalik, dan entri lainnya ke penyimpanan aktif.
Pengarsipan
Ketika data diterima, catatan ditambahkan / diperbarui di penyimpanan aktif, atau ditambahkan ke antrian terbalik, menunggu penempatan di penyimpanan arsip.
Kami secara berkala memulai proses terjadwal, disebut sebagai pengarsipan, sehubungan dengan catatan penyimpanan aktif untuk melampirkan catatan baru (catatan yang belum pernah diarsipkan sebelumnya) ke penyimpanan arsip. Proses pengarsipan hanya memproses catatan dalam penyimpanan aktif dengan waktu acara dalam kisaran antara waktu shutdown lama (waktu shutdown dari proses pengarsipan terakhir) dan waktu shutdown baru (waktu shutdown baru berdasarkan parameter keterlambatan pengarsipan dalam tata letak tabel).
Catatan waktu acara digunakan untuk menentukan di mana paket arsip catatan harus dikombinasikan saat mengemas data arsip ke dalam paket harian. Pengarsipan tidak memerlukan deduplikasi indeks dari nilai kunci utama selama penggabungan, karena hanya catatan dalam rentang antara waktu shutdown yang lama dan yang baru yang diarsipkan.
Gambar 7 di bawah ini menunjukkan grafik sesuai dengan waktu acara catatan tertentu.
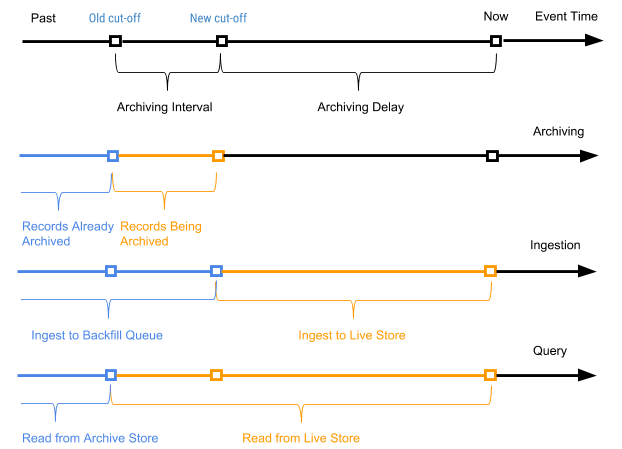
Gambar 7. Kami menggunakan waktu acara dan waktu perjalanan untuk mendefinisikan catatan sebagai baru (aktif) dan lama (waktu acara lebih awal dari waktu yang diarsipkan dari acara perjalanan).
Dalam hal ini, interval pengarsipan adalah interval waktu antara dua proses pengarsipan, dan penundaan pengarsipan adalah periode setelah waktu acara, tetapi sampai acara diarsipkan. Kedua parameter didefinisikan dalam pengaturan skema tabel AresDB.
Isi ulang
Seperti yang ditunjukkan pada Gambar 7 di atas, catatan lama (waktu acara lebih awal dari waktu yang diarsipkan dari acara pematian) untuk tabel fakta ditambahkan ke antrian terbalik dan akhirnya diproses sebagai bagian dari proses pengurukan. Pemicu proses ini juga waktu atau ukuran antrian terbalik, jika mencapai tingkat ambang batas. Dibandingkan dengan proses penambahan data ke penyimpanan aktif, pengisian ulang tidak sinkron dan relatif lebih mahal dalam hal CPU dan sumber daya memori. Pengisian digunakan dalam skenario berikut:
- Memproses data acak yang sangat terlambat
- Pengambilan manual data historis dari aliran data hulu
- Memasukkan data historis di kolom yang baru ditambahkan
Tidak seperti pengarsipan, proses pengisian ulang idempoten dan membutuhkan deduplikasi berdasarkan nilai kunci utama. Data yang dapat diisi pada akhirnya akan terlihat oleh kueri.
Antrian terbalik dipertahankan dalam memori dengan ukuran yang telah ditentukan, dan dengan banyak pengisian isi ulang, proses akan diblokir untuk klien sampai antrian dihapus dengan memulai proses pengisian ulang.
Meminta pemrosesan
Dalam implementasi saat ini, pengguna perlu menggunakan Ares Query Language (AQL) yang dibuat oleh Uber untuk menjalankan kueri di AresDB. AQL adalah bahasa yang efektif untuk kueri analitik runtun waktu dan tidak mengikuti sintaks SQL standar seperti "SELECT FROM WHERE GROUP BY" seperti bahasa lain yang mirip dengan SQL. Sebagai gantinya, AQL digunakan dalam bidang terstruktur dan dapat dimasukkan dalam objek JSON, YAML, dan Go. Misalnya, alih-alih /SELECT (*) /FROM /GROUP BY city_id, /WHERE = «» /AND request_at >= 1512000000 , varian AQL yang setara di JSON ditulis sebagai berikut:
{ “table”: “trips”, “dimensions”: [ {“sqlExpression”: “city_id”} ], “measures”: [ {“sqlExpression”: “count(*)”} ], ;”> “rowFilters”: [ “status = 'completed'” ], “timeFilter”: { “column”: “request_at”, “from”: “2 days ago” } }
Dalam format JSON, AQL menawarkan pengembang dashboard dan sistem pengambilan keputusan algoritma kueri program yang lebih nyaman daripada SQL, memungkinkan mereka untuk dengan mudah menyusun kueri dan memanipulasi mereka menggunakan kode tanpa khawatir tentang hal-hal seperti injeksi SQL. Ini bertindak sebagai format permintaan universal untuk arsitektur khas browser web, server eksternal dan internal hingga database (AresDB). Selain itu, AQL menyediakan sintaks yang nyaman untuk memfilter berdasarkan waktu dan batching dengan dukungan untuk zona waktunya sendiri. Selain itu, bahasa mendukung sejumlah fungsi, seperti subqueries implisit, untuk mencegah kesalahan umum dalam kueri dan memfasilitasi proses menganalisis dan menulis ulang kueri untuk pengembang antarmuka internal.
Terlepas dari banyak manfaat yang ditawarkan AQL, kami sangat menyadari bahwa sebagian besar insinyur lebih terbiasa dengan SQL. Menyediakan antarmuka SQL untuk mengeksekusi kueri adalah salah satu langkah selanjutnya yang akan kita lihat sebagai bagian dari upaya kami untuk meningkatkan interaksi dengan pengguna AresDB.
Diagram alur eksekusi permintaan AQL ditunjukkan pada Gambar 8 di bawah ini:
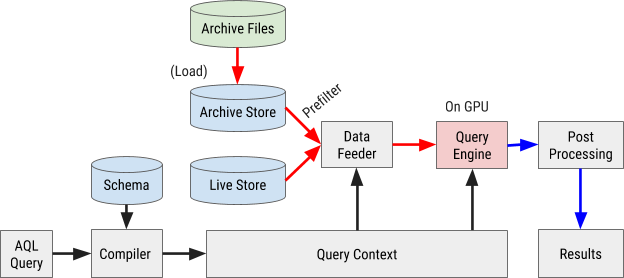
Gambar 8. Diagram alir kueri AresDB menggunakan bahasa kueri AQL kami sendiri untuk memproses dan mengambil data dengan cepat dan efisien.
Kompilasi permintaan
Kueri AQL dikompilasi ke dalam konteks kueri internal. Ekspresi dalam filter, pengukuran, dan parameter dianalisis dalam pohon sintaksis abstrak (AST) untuk diproses lebih lanjut melalui prosesor grafis (GPU).
Pemuatan data
AresDB menggunakan pra-filter untuk memfilter data arsip dengan murah sebelum mengirimnya ke GPU untuk pemrosesan paralel. Karena data yang diarsipkan diurutkan berdasarkan urutan kolom yang dikonfigurasi, beberapa filter dapat menggunakan urutan ini dan metode pencarian biner untuk menentukan rentang pencocokan yang sesuai. Secara khusus, filter yang setara untuk semua kolom X yang awalnya diurutkan dan filter rentang opsional untuk kolom yang diurutkan X + 1 dapat digunakan sebagai filter awal, seperti yang ditunjukkan pada Gambar 9 di bawah ini.

Gambar 9. AresDB melakukan pra-filter data kolom sebelum mengirimnya ke GPU untuk diproses.
Setelah pra-pemfilteran, hanya nilai hijau (memenuhi kondisi filter) yang harus dikirim ke GPU untuk pemrosesan paralel. Input data dimasukkan ke dalam GPU dan diproses satu paket sekaligus. Ini termasuk paket aktif dan paket arsip.
AresDB menggunakan stream CUDA untuk pipelining dan pemrosesan data. Untuk setiap permintaan, dua aliran diterapkan secara bergantian untuk diproses dalam dua tahap yang tumpang tindih. Pada Gambar 10 di bawah ini, kami menawarkan grafik yang menggambarkan proses ini.
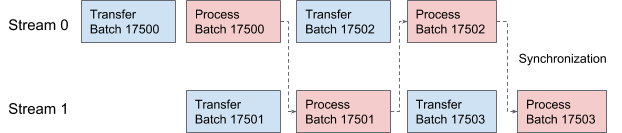
Gambar 10. Dalam AresDB, dua utas CUDA mengirimkan dan memproses data secara bergantian.
Eksekusi query
Untuk kesederhanaan, AresDB menggunakan perpustakaan Thrust untuk mengimplementasikan prosedur eksekusi kueri, yang menawarkan blok algoritma paralel yang disetel dengan halus untuk implementasi cepat kueri dalam alat saat ini.
Dalam Thrust, input dan output data vektor dievaluasi menggunakan iterator akses acak. Setiap thread GPU mencari iterator input di posisi kerjanya, membaca nilai-nilai dan melakukan perhitungan, dan kemudian menulis hasilnya ke posisi yang sesuai di iterator output.
Untuk mengevaluasi ekspresi AresDB, model “satu operator per inti” (OOPK) mengikuti.
Pada Gambar 11 di bawah ini, prosedur ini ditunjukkan dengan menggunakan contoh AST yang dihasilkan dari ekspresi dimensi request_at – request_at % 86400 pada tahap kompilasi permintaan:
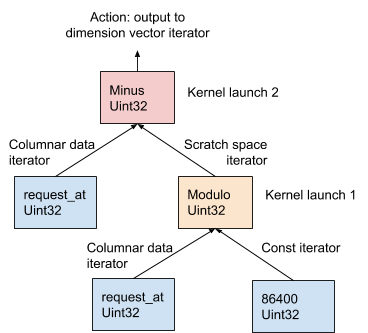
Gambar 11. AresDB menggunakan model OOPK untuk mengevaluasi ekspresi.
Dalam model OOPK, mesin kueri AresDB memotong setiap simpul daun pohon AST dan mengembalikan iterator untuk simpul sumber. Jika simpul root juga terbatas, tindakan root dilakukan langsung pada input iterator.
Untuk setiap simpul non-ujung non-root ( operasi modulo dalam contoh ini), vektor ruang kerja sementara dialokasikan untuk menyimpan hasil antara yang diperoleh dari request_at% 86400 ekspresi. Menggunakan Thrust, fungsi kernel diluncurkan untuk menghitung hasil pernyataan ini di GPU. Hasil disimpan di iterator ruang kerja.
Untuk simpul root, fungsi kernel berjalan dengan cara yang sama seperti untuk simpul non-root, tidak terbatas. Berbagai tindakan keluaran dilakukan berdasarkan jenis ekspresi, yang dijelaskan secara rinci di bawah ini:
- Penyaringan untuk mengurangi jumlah elemen vektor input
- Merekam data hasil pengukuran dalam vektor pengukuran untuk penggabungan data selanjutnya
- Rekam output parameter dalam vektor parameter untuk penggabungan data selanjutnya
Setelah mengevaluasi ekspresi, penyortiran dan transformasi dilakukan untuk akhirnya menggabungkan data. Dalam operasi penyortiran dan transformasi, kami menggunakan nilai-nilai vektor dimensi sebagai nilai kunci untuk penyortiran dan transformasi, dan nilai-nilai vektor parameter sebagai nilai untuk menggabungkan data. Dengan demikian, baris dengan nilai dimensi yang sama dikelompokkan dan dikombinasikan. Gambar 12 di bawah ini menunjukkan proses penyortiran dan konversi ini.
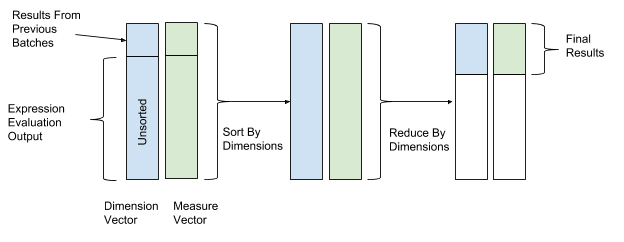
Gambar 12. Setelah mengevaluasi ekspresi, AresDB mengurutkan dan mengonversi data sesuai dengan nilai-nilai kunci dari vektor pengukuran (nilai kunci) dan parameter (nilai).
AresDB juga mendukung fungsi kueri lanjutan berikut:
- Bergabung : AresDB saat ini mendukung opsi gabung hash antara tabel fakta dan tabel dimensi
- Memperkirakan jumlah item Hyperloglog: AresDB menggunakan algoritma Hyperloglog
- Geo Intersect : AresDB saat ini hanya mendukung operasi yang saling berhubungan antara GeoPoint dan GeoShape
Manajemen sumber daya
Sebagai basis data berdasarkan memori internal, AresDB harus mengelola jenis penggunaan memori berikut:
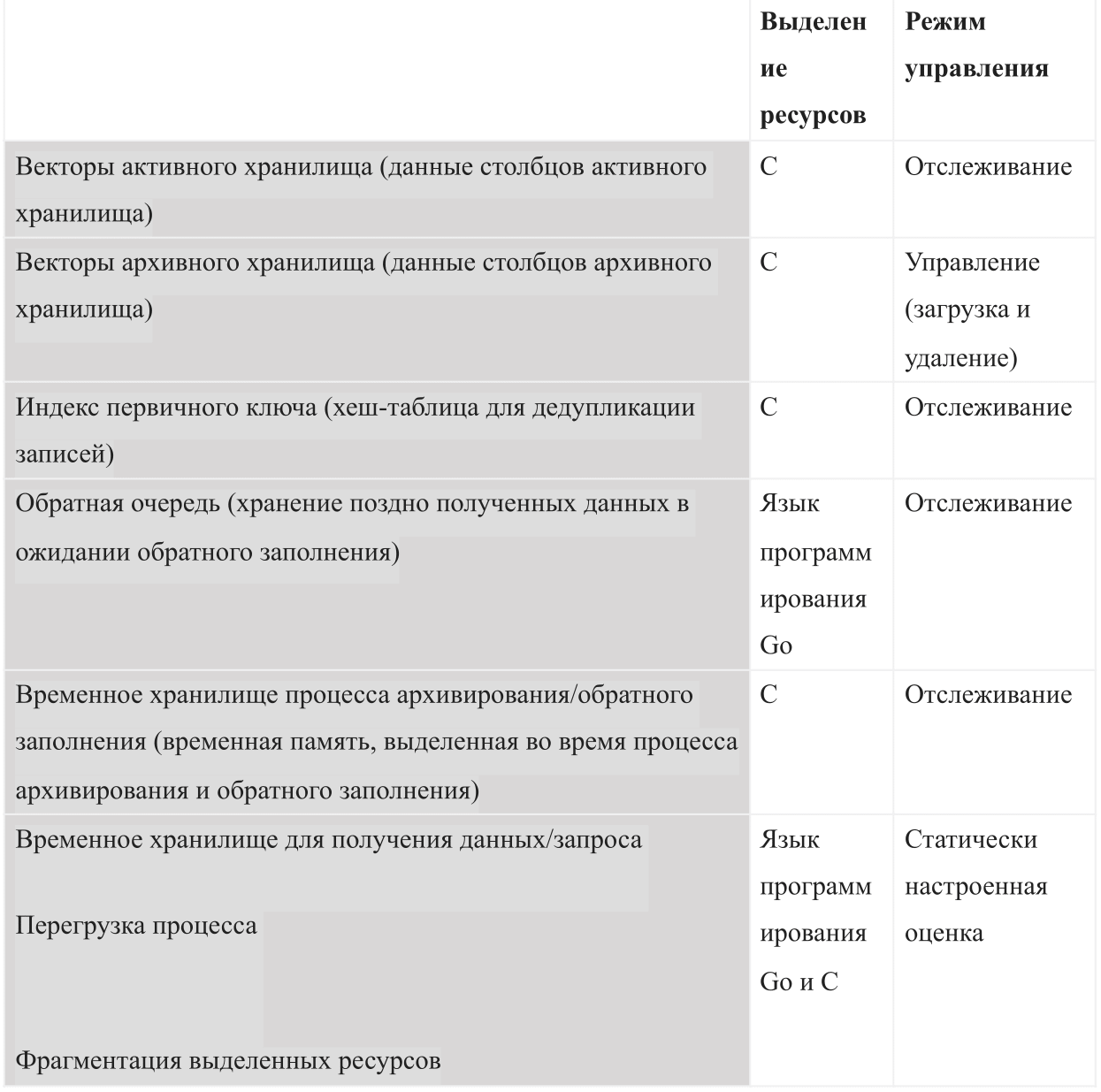
Ketika AresDB mulai, ia menggunakan anggaran memori bersama yang dikonfigurasi. Anggaran dibagi menjadi enam jenis memori dan juga harus menyisakan ruang yang cukup untuk sistem operasi dan proses lainnya. Anggaran ini juga mencakup perkiraan kemacetan yang dikonfigurasi secara statis, penyimpanan data aktif yang dipantau oleh server, dan data yang diarsipkan yang dapat diputuskan oleh server untuk diunduh dan dihapus tergantung pada sisa anggaran memori.
Gambar 13 di bawah ini menunjukkan model memori host AresDB.
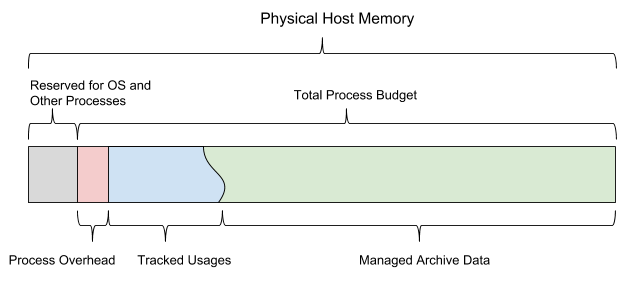
Gambar 13. AresDB mengelola penggunaan memorinya sendiri sehingga tidak melebihi anggaran total proses yang dikonfigurasi.
AresDB memungkinkan pengguna untuk mengatur hari preload dan prioritas tingkat kolom untuk tabel fakta dan preload data yang diarsipkan hanya pada hari preload. Data yang belum diunduh sebelumnya dimuat ke dalam memori dari disk sesuai permintaan. Ketika diisi, AresDB juga menghapus data yang diarsipkan dari memori host. Prinsip-prinsip penghapusan AresDB didasarkan pada parameter berikut: jumlah hari preloading, prioritas kolom, hari penyusunan paket, dan ukuran kolom.
AresDB juga mengelola beberapa perangkat GPU dan mensimulasikan sumber daya perangkat sebagai utas GPU dan memori perangkat, melacak penggunaan memori GPU untuk memproses permintaan. AresDB mengelola perangkat GPU melalui manajer perangkat yang memodelkan sumber daya perangkat GPU dalam dua dimensi (utas GPU dan memori perangkat) dan melacak penggunaan memori saat memproses permintaan. Setelah mengkompilasi permintaan, AresDB memungkinkan pengguna untuk memperkirakan jumlah sumber daya yang dibutuhkan untuk menyelesaikan permintaan. Persyaratan memori perangkat harus dipenuhi sebelum permintaan diselesaikan; jika saat ini tidak ada cukup memori pada perangkat apa pun, permintaan tersebut harus menunggu. Saat ini, AresDB dapat menjalankan satu atau lebih permintaan pada perangkat GPU yang sama secara bersamaan jika perangkat tersebut memenuhi semua persyaratan sumber daya.
Dalam implementasi saat ini, AresDB tidak men-cache input di memori perangkat untuk digunakan kembali dalam beberapa permintaan. AresDB bertujuan untuk mendukung permintaan terhadap dataset yang terus diperbarui secara real time dan di-cache dengan benar. Dalam versi AresDB yang akan datang, kami bermaksud mengimplementasikan fungsi untuk menyimpan data dalam memori GPU, yang akan membantu mengoptimalkan kinerja kueri.
Di Uber, kami menggunakan AresDB untuk membuat dasbor untuk mendapatkan informasi bisnis waktu-nyata. AresDB bertanggung jawab untuk menyimpan acara utama dengan pembaruan konstan dan menghitung metrik kritis untuk mereka dalam sepersekian detik berkat sumber daya GPU dengan biaya rendah, sehingga pengguna dapat menggunakan dasbor secara interaktif. Misalnya, data perjalanan anonim yang memiliki masa berlaku lama di gudang data diperbarui oleh beberapa layanan, termasuk sistem pengiriman, pembayaran, dan sistem penetapan harga kami. Untuk memanfaatkan data perjalanan secara efisien, pengguna membagi dan memecah data menjadi dimensi yang berbeda untuk mendapatkan wawasan tentang solusi waktu nyata.
Saat menggunakan AresDB, dasbor Uber adalah dasbor analisis luas yang digunakan oleh tim dalam perusahaan untuk menghasilkan metrik yang relevan dan respons waktu nyata untuk meningkatkan pengalaman pengguna.
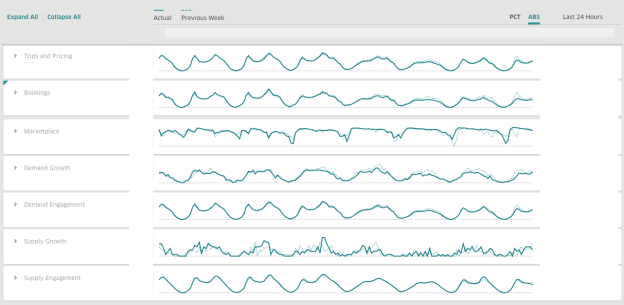
14. Uber AresDB .
, , :
( )

( )

AresDB
, , AresDB :

, , , , , .
AresDB , Apache Kafka , , Apache Flink Apache Spark .
AresDB
, « » « ». , -. 24 AQL:

:
, , .

, AresDB , , . AresDB , , .
AresDB Uber , . , , AresDB .
:
- : AresDB, , , .
- : AresDB 2018 , , AresDB .
- : , , , .
- : , (LLVM) GPU.
AresDB Apache. AresDB .
, .
Ucapan Terima Kasih
(Kate Zhang), (Jennifer Anderson), (Nikhil Joshi), (Abhi Khune), (Shengyue Ji), (Chinmay Soman), (Xiang Fu), (David Chen) (Li Ning) , !