Catatan perev. : Karyawan Tinder baru-baru ini membagikan beberapa detail teknis tentang migrasi infrastruktur mereka ke Kubernetes. Proses ini memakan waktu hampir dua tahun dan menghasilkan peluncuran platform K8 yang sangat besar yang terdiri dari 200 layanan yang di-host di 48 ribu kontainer. Kesulitan apa yang menarik yang dihadapi oleh insinyur Tinder dan hasil apa yang mereka peroleh - baca dalam terjemahan ini.
Mengapa
Hampir dua tahun lalu, Tinder memutuskan untuk beralih platformnya ke Kubernetes. Kubernetes akan memungkinkan tim Tinder untuk kemas dan beralih ke operasi dengan upaya minimal melalui
penyebaran abadi . Dalam hal ini, perakitan aplikasi, penyebarannya, dan infrastrukturnya sendiri akan ditentukan secara unik oleh kode.
Kami juga mencari solusi untuk masalah skalabilitas dan stabilitas. Ketika penskalaan menjadi kritis, kami sering harus menunggu beberapa menit untuk meluncurkan instance EC2 baru. Karenanya, ide untuk meluncurkan kontainer dan mulai melayani lalu lintas dalam hitungan detik, bukan menit, menjadi sangat menarik bagi kami.
Prosesnya tidak mudah. Selama migrasi, pada awal 2019, cluster Kubernetes mencapai massa kritis dan kami mulai menghadapi berbagai masalah karena jumlah lalu lintas, ukuran cluster, dan DNS. Dalam perjalanan ini, kami memecahkan banyak masalah menarik terkait dengan transfer 200 layanan dan pemeliharaan cluster Kubernetes, yang terdiri dari 1000 node, 15.000 pod, dan 48.000 kontainer yang berfungsi.
Bagaimana?
Sejak Januari 2018, kami telah melalui berbagai tahap migrasi. Kami mulai dengan membuat wadah semua layanan kami dan menempatkannya di lingkungan pengujian Kubernetes. Pada bulan Oktober, proses transfer metodis dari semua layanan yang ada ke Kubernetes dimulai. Pada bulan Maret tahun berikutnya, "relokasi" selesai dan sekarang platform Tinder berjalan secara eksklusif di Kubernetes.
Buat gambar untuk Kubernetes
Kami memiliki lebih dari 30 repositori kode sumber untuk layanan microser yang berjalan di kluster Kubernetes. Kode dalam repositori ini ditulis dalam bahasa yang berbeda (misalnya, Node.js, Java, Scala, Go) dengan banyak lingkungan runtime untuk bahasa yang sama.
Sistem build dirancang untuk memberikan "konteks pembangunan" yang sepenuhnya dapat disesuaikan untuk setiap layanan Microsoft. Biasanya terdiri dari Dockerfile dan daftar perintah shell. Konten mereka sepenuhnya dapat disesuaikan, dan pada saat yang sama, semua konteks build ini ditulis sesuai dengan format standar. Standarisasi konteks pembangunan memungkinkan sistem pembangunan tunggal untuk menangani semua layanan microser.
 Gambar 1-1. Proses pembangunan terstandarisasi melalui pembangun-kontainer (Builder)
Gambar 1-1. Proses pembangunan terstandarisasi melalui pembangun-kontainer (Builder)Untuk mencapai konsistensi maksimum antara runtime, proses build yang sama digunakan selama pengembangan dan pengujian. Kami menghadapi masalah yang sangat menarik: kami harus mengembangkan cara untuk menjamin konsistensi lingkungan perakitan di seluruh platform. Untuk melakukan ini, semua proses perakitan dilakukan di dalam wadah
Builder khusus.
Implementasinya membutuhkan teknik-teknik canggih untuk bekerja dengan Docker. Builder mewarisi ID pengguna lokal dan rahasia (seperti kunci SSH, kredensial AWS, dll.) Yang diperlukan untuk mengakses repositori pribadi Tinder. Itu me-mount direktori lokal yang mengandung sumber untuk menyimpan artefak perakitan secara alami. Pendekatan ini meningkatkan kinerja dengan menghilangkan kebutuhan untuk menyalin artefak perakitan antara wadah Builder dan tuan rumah. Artefak rakitan yang disimpan dapat digunakan kembali tanpa konfigurasi tambahan.
Untuk beberapa layanan, kami harus membuat wadah lain agar sesuai dengan lingkungan kompilasi dengan runtime (misalnya, selama proses instalasi, perpustakaan bcrypt Node.js menghasilkan artefak biner khusus platform). Selama kompilasi, persyaratan dapat bervariasi untuk berbagai layanan, dan Dockerfile akhir dikompilasi dengan cepat.
Arsitektur dan Migrasi Cluster Kubernetes
Manajemen ukuran cluster
Kami memutuskan untuk menggunakan
kube-aws untuk menyebarkan kluster secara otomatis pada instance Amazon EC2. Pada awalnya, semuanya bekerja dalam satu kumpulan node yang sama. Kami dengan cepat menyadari perlunya memisahkan beban kerja berdasarkan ukuran dan jenis contoh untuk penggunaan sumber daya yang lebih efisien. Logikanya adalah bahwa peluncuran beberapa pod multi-threaded yang dimuat ternyata lebih dapat diprediksi kinerjanya daripada koeksistensi mereka dengan sejumlah besar pod single-threaded.
Sebagai hasilnya, kami memutuskan:
- m5.4xlarge - untuk pemantauan (Prometheus);
- c5.4xlarge - untuk beban kerja Node.js (beban kerja berulir tunggal);
- c5.2xlarge - untuk Java dan Go (beban kerja multi-utas);
- c5.4xlarge - untuk panel kontrol (3 node).
Migrasi
Salah satu langkah persiapan untuk bermigrasi dari infrastruktur lama ke Kubernetes adalah mengarahkan kembali interaksi langsung yang ada antara layanan ke penyeimbang beban baru (ELB, Elastic Load Balancers). Mereka dibuat pada subnet virtual private cloud (VPC) tertentu. Subnet ini terhubung ke Kubernetes VPC. Ini memungkinkan kami untuk memigrasikan modul secara bertahap, tidak dengan mempertimbangkan urutan dependensi layanan tertentu.
Titik akhir ini dibuat menggunakan set data DNS tertimbang dengan CNAME menunjuk ke setiap ELB baru. Untuk beralih, kami menambahkan catatan baru yang menunjuk ke layanan Kubernetes baru ELB dengan bobot 0. Kemudian kami mengatur Time To Live (TTL) dari recordset ke 0. Setelah itu, bobot lama dan baru perlahan-lahan disesuaikan, dan akhirnya 100% beban dikirim. ke server baru. Setelah sakelar selesai, nilai TTL kembali ke level yang lebih memadai.
Modul Java kami yang ada menangani DNS TTL rendah, tetapi aplikasi Node tidak. Salah satu insinyur menulis ulang bagian dari kode kumpulan koneksi, membungkusnya dengan manajer yang memperbarui kumpulan setiap 60 detik. Pendekatan yang dipilih bekerja dengan sangat baik dan tanpa penurunan kinerja yang nyata.
Pelajaran
Pembatasan perangkat jaringan
Pada dini hari 8 Januari 2019, platform Tinder tiba-tiba jatuh. Menanggapi peningkatan latensi platform yang tidak terkait sebelumnya di pagi hari, jumlah pod dan node dalam cluster meningkat. Ini menyebabkan habisnya cache ARP di semua node kami.
Ada tiga opsi Linux yang terkait dengan cache ARP:

(
sumber )
gc_thresh3 adalah batas yang sulit. Penampilan dalam log entri dari bentuk "tetangga tabel melimpah" berarti bahwa bahkan setelah pengumpulan sampah sinkron (GC) dalam cache ARP, tidak ada cukup ruang untuk menyimpan catatan tetangga. Dalam hal ini, kernel hanya menjatuhkan paket sepenuhnya.
Kami menggunakan
Flannel sebagai
fabric jaringan di Kubernetes. Paket dikirimkan melalui VXLAN. VXLAN adalah terowongan L2, terangkat melalui jaringan L3. Teknologi ini menggunakan enkapsulasi MAC-in-UDP (Alamat MAC-di-Pengguna Protokol) dan memungkinkan Anda untuk memperluas segmen jaringan tingkat 2. Protokol transport dalam jaringan fisik pusat data adalah IP plus UDP.
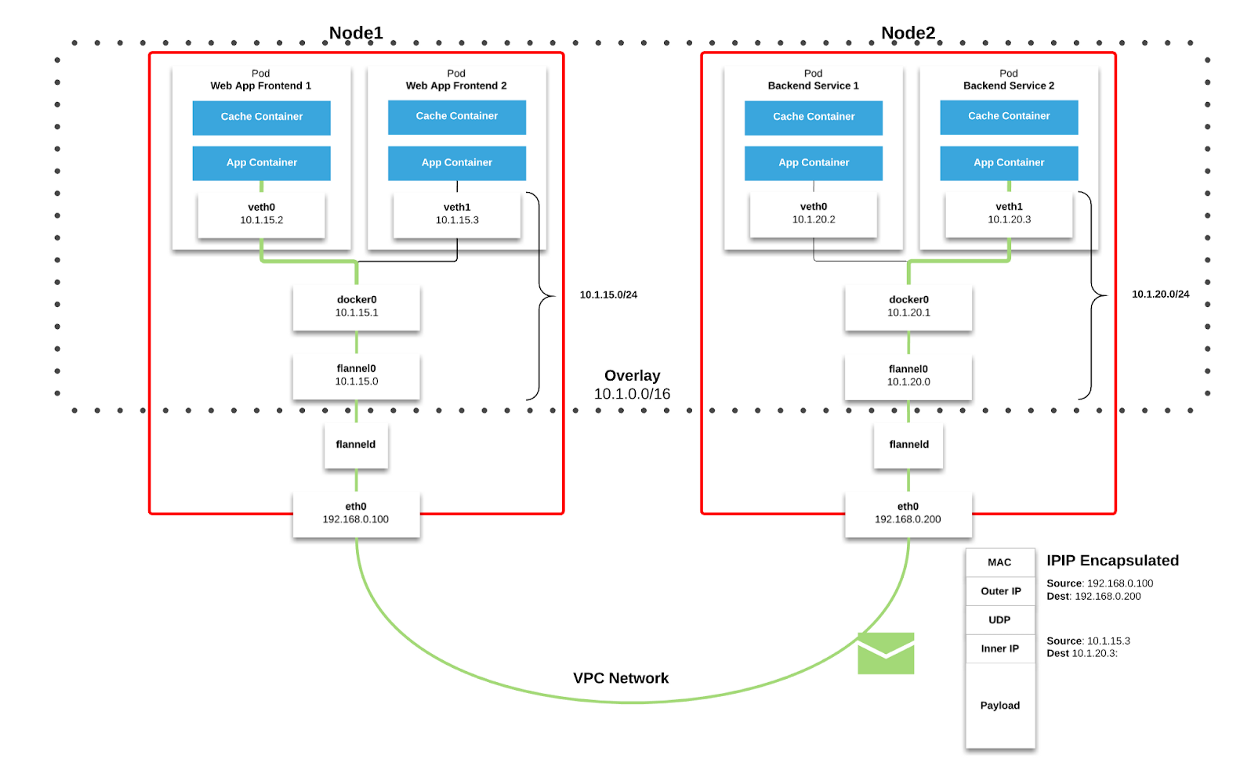 Gambar 2–1. Bagan Flanel ( sumber )
Gambar 2–1. Bagan Flanel ( sumber ) Gambar 2–2. Paket VXLAN ( sumber )
Gambar 2–2. Paket VXLAN ( sumber )Setiap simpul kerja Kubernet mengalokasikan ruang alamat virtual dengan mask / 24 dari blok yang lebih besar / 9. Untuk setiap node, ini
berarti satu entri dalam tabel routing, satu entri dalam tabel ARP (pada antarmuka
flannel.1 ) dan satu entri dalam tabel switching (FDB). Mereka ditambahkan ketika simpul kerja pertama kali dimulai atau ketika setiap simpul baru terdeteksi.
Selain itu, koneksi node-pod (atau pod-pod) akhirnya melewati antarmuka
eth0 (seperti yang ditunjukkan pada diagram Flannel di atas). Ini menghasilkan entri tambahan dalam tabel ARP untuk setiap sumber dan tujuan node yang sesuai.
Di lingkungan kita, jenis komunikasi ini sangat umum. Untuk objek jenis layanan di Kubernetes, sebuah ELB dibuat dan Kubernet mendaftar setiap node di ELB. ELB tidak tahu apa-apa tentang polong dan simpul yang dipilih mungkin bukan tujuan akhir dari paket. Faktanya adalah bahwa ketika sebuah node menerima paket dari ELB, ia menganggapnya mempertimbangkan aturan
iptables akun untuk layanan tertentu dan secara acak memilih pod pada node lain.
Pada saat kegagalan, cluster memiliki 605 node. Untuk alasan yang disebutkan di atas, ini sudah cukup untuk mengatasi nilai
gc_thresh3 default . Ketika ini terjadi, tidak hanya paket-paket yang mulai dibuang, tetapi seluruh ruang alamat virtual Flannel dengan mask / 24 menghilang dari tabel ARP. Komunikasi node-pod dan kueri DNS terputus (DNS dihosting di sebuah cluster; lihat bagian lain artikel ini untuk detailnya).
Untuk mengatasi masalah ini, tingkatkan nilai
gc_thresh1 ,
gc_thresh2 dan
gc_thresh3 dan restart Flannel untuk mendaftar ulang jaringan yang hilang.
Penskalaan DNS yang Tidak Terduga
Selama proses migrasi, kami secara aktif menggunakan DNS untuk mengelola lalu lintas dan secara bertahap mentransfer layanan dari infrastruktur lama ke Kubernetes. Kami menetapkan nilai TTL yang relatif rendah untuk Recordset terkait di Route53. Ketika infrastruktur lama berjalan pada instance EC2, konfigurasi resolver kami menunjuk ke Amazon DNS. Kami menerima begitu saja dan dampak TTL rendah pada layanan Amazon kami (seperti DynamoDB) hampir tanpa disadari.
Karena layanan dimigrasikan ke Kubernetes, kami menemukan bahwa DNS menangani 250.000 kueri per detik. Akibatnya, aplikasi mulai mengalami waktu tunggu yang konstan dan serius untuk permintaan DNS. Ini terjadi meskipun ada upaya luar biasa untuk mengoptimalkan dan mengalihkan penyedia DNS ke CoreDNS (yang mencapai 1000 pod berjalan pada 120 core pada beban puncak).
Menjelajahi penyebab dan solusi lain yang mungkin, kami menemukan
sebuah artikel yang menggambarkan kondisi ras yang memengaruhi kerangka penyaringan paket
netfilter di Linux. Timeout yang kami amati, bersama dengan peningkatan
insert_failed counter di antarmuka Flannel, sesuai dengan kesimpulan artikel.
Masalahnya muncul pada tahap Terjemahan Sumber dan Tujuan Alamat Jaringan (SNAT dan DNAT) dan entri selanjutnya ke tabel
conntrack . Salah satu solusi yang dibahas dalam perusahaan dan diusulkan oleh komunitas adalah transfer DNS ke node kerja itu sendiri. Dalam hal ini:
- SNAT tidak diperlukan karena lalu lintas tetap berada di dalam node. Tidak perlu dialihkan melalui antarmuka eth0 .
- DNAT tidak diperlukan, karena IP tujuan adalah lokal untuk host, dan bukan pod yang dipilih secara acak sesuai dengan aturan iptables .
Kami memutuskan untuk tetap berpegang pada pendekatan ini. CoreDNS digunakan sebagai DaemonSet di Kubernetes dan kami mengimplementasikan server DNS lokal host di
resolv.conf dari setiap pod dengan mengkonfigurasi
flag --cluster-dns dari perintah
kubelet . Solusi ini terbukti efektif untuk batas waktu DNS.
Namun, kami masih mengamati hilangnya paket dan peningkatan penghitung
insert_failed di antarmuka Flannel. Situasi ini berlanjut setelah pengenalan solusinya, karena kami dapat mengecualikan SNAT dan / atau DNAT hanya untuk lalu lintas DNS. Kondisi balapan bertahan untuk jenis lalu lintas lainnya. Untungnya, sebagian besar paket kami adalah TCP, dan ketika masalah terjadi, mereka hanya dikirim ulang. Kami masih berusaha menemukan solusi yang cocok untuk semua jenis lalu lintas.
Menggunakan Utusan untuk Penyeimbangan Beban yang Lebih Baik
Ketika kami memigrasi layanan backend ke Kubernetes, kami mulai menderita dari beban yang tidak seimbang antara pod. Kami menemukan bahwa karena HTTP Keepalive, koneksi ELB tergantung pada pod siap pakai pertama dari setiap penyebaran peluncuran. Dengan demikian, sebagian besar lalu lintas melewati sebagian kecil dari pod yang tersedia. Solusi pertama yang kami uji adalah mengatur parameter MaxSurge ke 100% pada penerapan baru untuk kasus terburuk. Efeknya tidak signifikan dan tidak menjanjikan dalam hal penyebaran yang lebih besar.
Solusi lain yang kami gunakan adalah meningkatkan permintaan sumber daya secara artifisial untuk layanan misi-kritis. Dalam hal ini, pod yang berdekatan akan memiliki lebih banyak ruang untuk bermanuver daripada pod berat lainnya. Dalam jangka panjang, itu juga tidak akan berhasil karena pemborosan sumber daya. Selain itu, aplikasi Node kami adalah single-threaded dan, karenanya, hanya dapat menggunakan satu inti. Satu-satunya solusi nyata adalah menggunakan load balancing yang lebih baik.
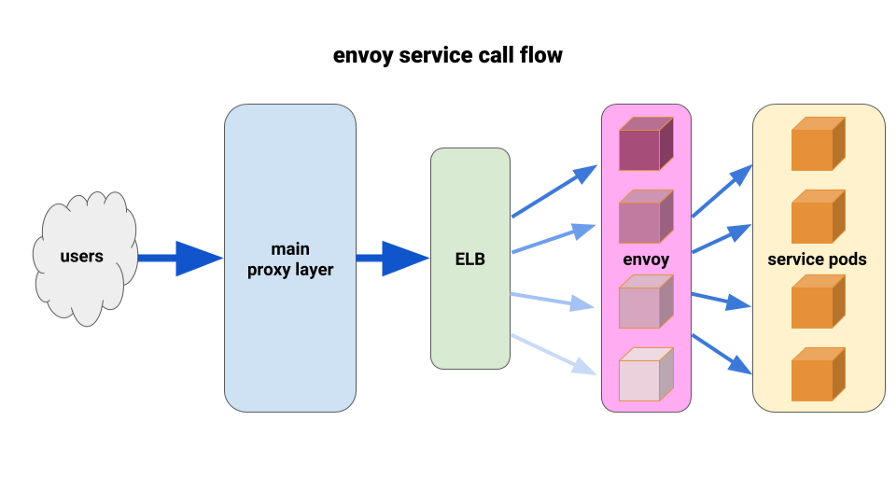
Kami sudah lama ingin sepenuhnya menghargai
Utusan . Situasi saat ini memungkinkan kami untuk menyebarkannya dengan cara yang sangat terbatas dan mendapatkan hasil langsung. Utusan adalah sumber terbuka, proksi tingkat tujuh kinerja tinggi yang dirancang untuk aplikasi SOA besar. Ia mampu menerapkan teknik penyeimbangan beban tingkat lanjut, termasuk percobaan ulang otomatis, pemutus sirkuit, dan batas kecepatan global.
( Catatan terjemahan : Untuk lebih jelasnya, lihat artikel terbaru tentang Istio - service mesh, yang didasarkan pada Utusan.)Kami datang dengan konfigurasi berikut: minta sespan utusan untuk setiap pod dan satu rute, dan cluster - sambungkan ke kontainer secara lokal dengan port. Untuk meminimalkan potensi cascading dan menjaga radius kecil "kerusakan", kami menggunakan taman pod proxy-depan Utusan, satu untuk setiap Zona Ketersediaan (AZ) untuk setiap layanan. Mereka beralih ke mekanisme penemuan layanan sederhana yang ditulis oleh salah satu insinyur kami, yang hanya mengembalikan daftar pod di setiap AZ untuk layanan yang diberikan.
Kemudian bagian depan layanan Utusan menggunakan mekanisme penemuan layanan ini dengan satu cluster hulu dan rute. Kami menetapkan batas waktu yang memadai, meningkatkan semua pengaturan pemutus sirkuit, dan menambahkan konfigurasi coba ulang minimal untuk membantu dengan kegagalan tunggal dan memastikan penyebaran yang mulus. Sebelum masing-masing utusan depan layanan ini, kami menempatkan TCP ELB. Bahkan jika keepalive dari lapisan proxy utama kami tergantung pada beberapa pod Utusan, mereka masih dapat menangani beban lebih baik dan diatur untuk menyeimbangkan melalui setidaknya_meminta di backend.
Untuk penyebaran, kami menggunakan kait preStop pada pod aplikasi dan pod sespan. Kait memulai kesalahan dalam memeriksa status titik akhir admin yang terletak di wadah sespan, dan "tidur" untuk sementara waktu untuk memungkinkan koneksi aktif untuk menyelesaikan.
Salah satu alasan mengapa kami dapat maju dengan cepat dalam menyelesaikan masalah adalah terkait dengan metrik terperinci yang kami dapat dengan mudah diintegrasikan ke dalam instalasi standar Prometheus. Dengan mereka menjadi mungkin untuk melihat apa yang terjadi ketika kami memilih parameter konfigurasi dan mendistribusikan kembali traffic.
Hasilnya langsung dan jelas. Kami mulai dengan layanan yang paling tidak seimbang, dan saat ini sudah berfungsi sebelum 12 layanan paling penting di cluster. Tahun ini kami berencana untuk pindah ke jala servis penuh dengan penemuan layanan yang lebih canggih, pemutus sirkuit, deteksi outlier, pembatasan kecepatan dan pelacakan.
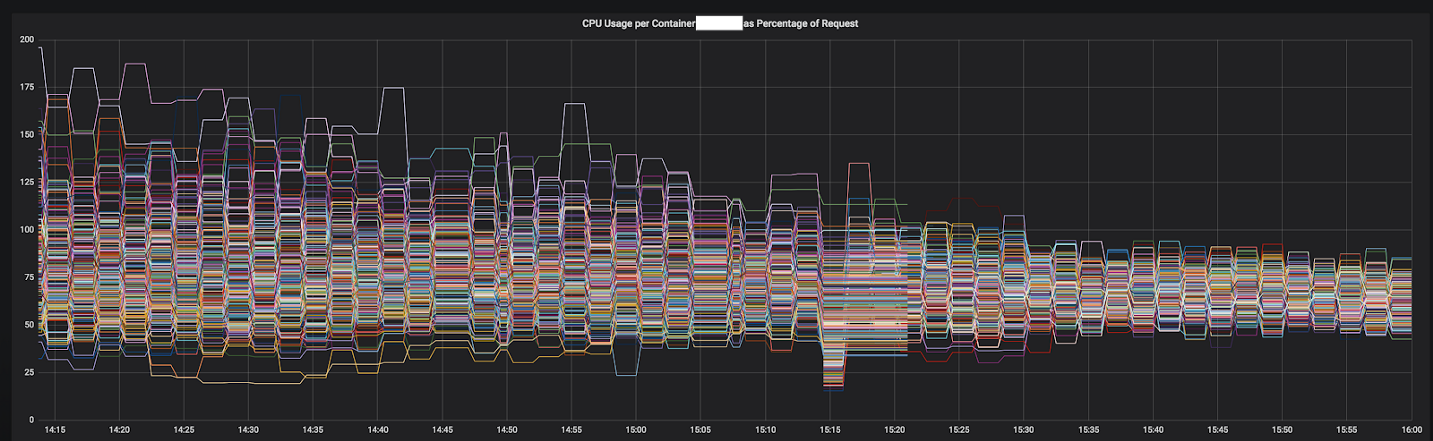 Gambar 3–1. Konvergensi CPU dari satu layanan selama transisi ke Utusan
Gambar 3–1. Konvergensi CPU dari satu layanan selama transisi ke Utusan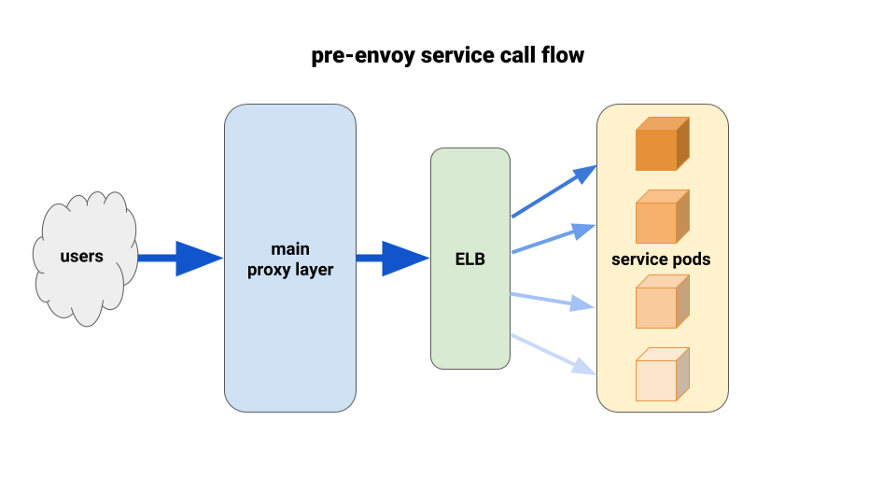
Hasil akhir
Berkat pengalaman dan penelitian tambahan kami, kami telah membangun tim infrastruktur yang kuat dengan keterampilan yang baik dalam mendesain, menyebarkan dan mengoperasikan kluster Kubernet besar. Sekarang semua insinyur Tinder memiliki pengetahuan dan pengalaman tentang cara mengemas kontainer dan menyebarkan aplikasi di Kubernetes.
Ketika kebutuhan untuk kapasitas tambahan muncul pada infrastruktur lama, kami harus menunggu beberapa menit untuk meluncurkan instance EC2 baru. Sekarang wadah mulai dan mulai memproses lalu lintas selama beberapa detik, bukan menit. Menjadwalkan banyak wadah pada satu instance EC2 juga memberikan peningkatan konsentrasi horisontal. Akibatnya, pada tahun 2019, kami memperkirakan penurunan biaya EC2 yang signifikan dibandingkan tahun lalu.
Butuh waktu hampir dua tahun untuk bermigrasi, tetapi kami menyelesaikannya pada Maret 2019. Saat ini, platform Tinder berjalan secara eksklusif pada kluster Kubernetes, yang terdiri dari 200 layanan, 1000 node, 15.000 pod, dan 48.000 container yang berjalan. Infrastruktur tidak lagi menjadi tanggung jawab tim operasi. Semua teknisi kami berbagi tanggung jawab ini dan mengendalikan proses membangun dan menggunakan aplikasi mereka hanya menggunakan kode.
PS dari penerjemah
Baca juga seri artikel kami di blog kami: