Pada reli internal terakhir Pyrus, kami berbicara tentang penyimpanan terdistribusi modern, dan Maxim Nalsky, CEO dan pendiri Pyrus, berbagi kesan pertamanya tentang FoundationDB. Pada artikel ini, kita berbicara tentang nuansa teknis yang Anda hadapi ketika memilih teknologi untuk meningkatkan skala penyimpanan data terstruktur.
Ketika layanan tidak tersedia untuk pengguna selama beberapa waktu, itu sangat tidak menyenangkan, tetapi masih tidak mematikan. Tetapi kehilangan data pelanggan sama sekali tidak bisa diterima. Oleh karena itu, kami dengan cermat mengevaluasi teknologi apa pun untuk menyimpan data dengan dua hingga tiga lusin parameter.
Beberapa dari mereka menentukan beban saat ini pada layanan.
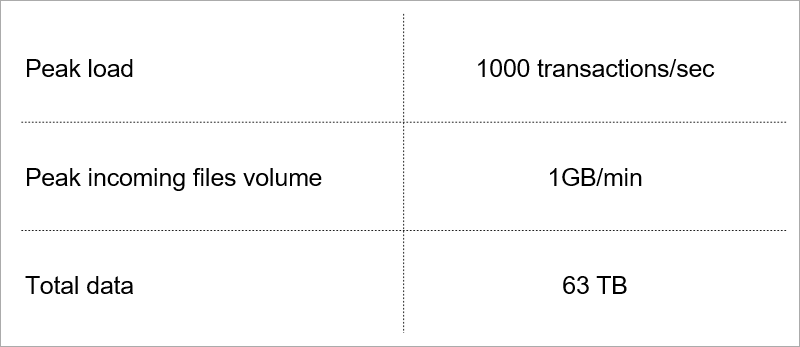 Beban saat ini. Kami memilih teknologi dengan mempertimbangkan pertumbuhan indikator-indikator ini.
Beban saat ini. Kami memilih teknologi dengan mempertimbangkan pertumbuhan indikator-indikator ini.Arsitektur server klien
Model client-server klasik adalah contoh paling sederhana dari sistem terdistribusi. Server adalah titik sinkronisasi, memungkinkan beberapa klien untuk melakukan sesuatu bersama secara terkoordinasi.
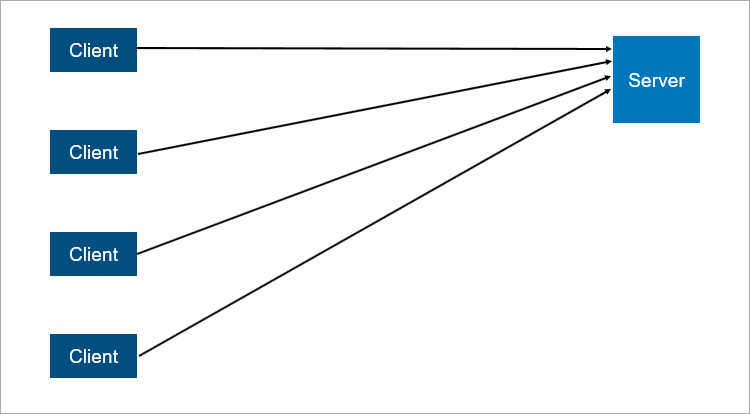 Skema interaksi client-server yang sangat disederhanakan.
Skema interaksi client-server yang sangat disederhanakan.Apa yang tidak dapat diandalkan dalam arsitektur client-server? Jelas, server mungkin macet. Dan ketika server macet, semua klien tidak dapat bekerja. Untuk menghindari hal ini, orang-orang datang dengan koneksi master-slave (yang sekarang secara
politis benar disebut leader-follower ). Intinya adalah ada dua server, semua klien berkomunikasi dengan yang utama, dan pada kedua semua data hanya direplikasi.
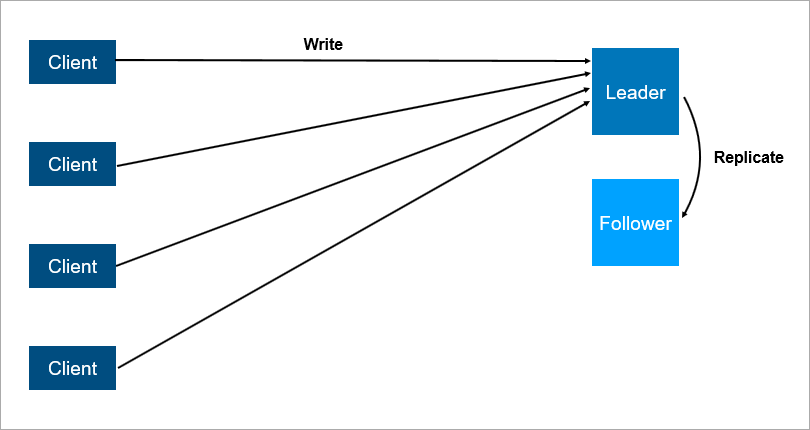 Arsitektur client-server dengan replikasi data ke pengikut.
Arsitektur client-server dengan replikasi data ke pengikut.Jelas bahwa ini adalah sistem yang lebih andal: jika server utama macet, maka salinan semua data ada di pengikut dan dapat dengan cepat dinaikkan.
Penting untuk memahami cara kerja replikasi. Jika sinkron, maka transaksi harus disimpan secara bersamaan pada pemimpin dan pada pengikut, dan ini bisa lambat. Jika replikasi asinkron, Anda bisa kehilangan beberapa data setelah gagal.
Dan apa yang akan terjadi jika pemimpin jatuh pada malam hari ketika semua orang tidur? Ada data tentang pengikut, tetapi tidak ada yang mengatakan kepadanya bahwa ia sekarang adalah seorang pemimpin, dan klien tidak terhubung dengannya. OKE, mari beri para pengikut logika bahwa dia mulai menganggap dirinya hal utama ketika koneksi dengan pemimpin terputus. Kemudian kita dapat dengan mudah mendapatkan otak yang terpecah - konflik ketika hubungan antara pemimpin dan pengikut terputus, dan keduanya berpikir bahwa mereka adalah yang utama. Ini benar-benar terjadi pada banyak sistem,
seperti RabbitMQ , teknologi antrian paling populer saat ini.
Untuk mengatasi masalah ini, atur failover otomatis - tambahkan server ketiga (saksi, saksi). Ini memastikan bahwa kita hanya memiliki satu pemimpin. Dan jika pemimpin jatuh, maka pengikut menyala secara otomatis dengan downtime minimum, yang dapat dikurangi menjadi beberapa detik. Tentu saja, klien dalam skema ini harus mengetahui terlebih dahulu alamat dari pemimpin dan pengikut dan menerapkan logika penyambungan kembali otomatis di antara mereka.
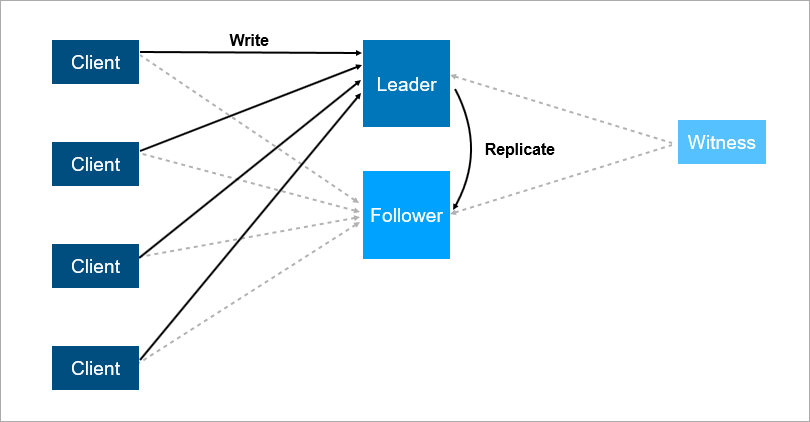 Saksi menjamin bahwa hanya ada satu pemimpin. Jika pemimpin jatuh, maka pengikut menyala secara otomatis.
Saksi menjamin bahwa hanya ada satu pemimpin. Jika pemimpin jatuh, maka pengikut menyala secara otomatis.Sistem seperti itu sekarang bekerja dengan kita. Ada database utama, database cadangan, ada saksi dan ya - kadang-kadang kita datang di pagi hari dan melihat bahwa saklar terjadi di malam hari.
Tetapi skema ini juga memiliki kelemahan. Bayangkan Anda menginstal paket layanan atau memperbarui OS pada server pemimpin. Sebelum itu, Anda secara manual mengaktifkan beban pada pengikut dan kemudian ... jatuh! Bencana, layanan Anda tidak tersedia. Apa yang harus dilakukan untuk melindungi diri dari ini? Tambahkan server cadangan ketiga - pengikut lain. Tiga adalah sejenis angka ajaib. Jika Anda ingin sistem bekerja dengan andal, dua server tidak cukup, Anda perlu tiga. Satu untuk pemeliharaan, yang kedua jatuh, yang ketiga tetap.
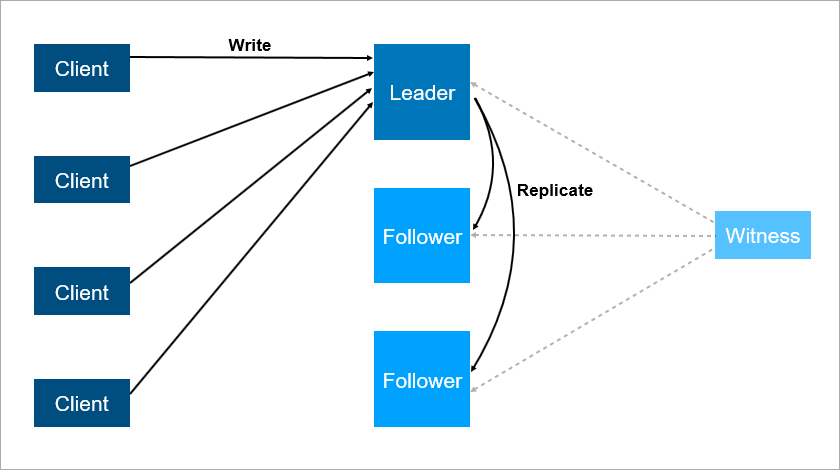 Server ketiga menyediakan operasi yang andal jika dua yang pertama tidak tersedia.
Server ketiga menyediakan operasi yang andal jika dua yang pertama tidak tersedia.Untuk meringkas, redundansi harus sama dengan dua. Redundansi satu saja tidak cukup. Untuk alasan ini, dalam array disk, orang-orang mulai menggunakan skema RAID6 alih-alih RAID5, selamat dari jatuhnya dua disk sekaligus.
Transaksi
Empat persyaratan transaksi dasar yang terkenal: atomicity, konsistensi, isolasi, dan daya tahan (Atomicity, Consistency, Isolasi, Durability - ACID).
Ketika kita berbicara tentang database terdistribusi, kita berarti bahwa data harus diskalakan. Membaca skala sangat baik - ribuan transaksi dapat membaca data secara paralel tanpa masalah. Tetapi ketika transaksi lain menulis data pada saat yang sama dengan membaca, berbagai efek yang tidak diinginkan mungkin terjadi. Sangat mudah untuk mendapatkan situasi di mana satu transaksi akan membaca nilai yang berbeda dari catatan yang sama. Berikut ini beberapa contohnya.
Kotor berbunyi. Dalam transaksi pertama, kami mengirim permintaan yang sama dua kali: mengambil semua pengguna dengan ID = 1. Jika transaksi kedua mengubah baris ini dan kemudian mengembalikan, database tidak akan melihat perubahan di satu sisi, tetapi di sisi lain transaksi pertama akan membaca nilai umur Joe yang berbeda.
 Bacaan tidak dapat diulang.
Bacaan tidak dapat diulang. Kasus lain adalah jika transaksi tulis selesai dengan sukses, dan transaksi baca menerima data yang berbeda selama pelaksanaan permintaan yang sama.

Dalam kasus pertama, klien membaca data yang umumnya tidak ada dalam database. Dalam kasus kedua, klien kedua kali membaca data dari database, tetapi mereka berbeda, meskipun pembacaan terjadi dalam transaksi yang sama.
Phantom reads adalah ketika kita membaca ulang rentang dalam transaksi yang sama dan mendapatkan serangkaian garis yang berbeda. Di suatu tempat di tengah, transaksi lain masuk dan memasukkan atau menghapus catatan.

Untuk menghindari efek yang tidak diinginkan ini, DBMS modern menerapkan mekanisme penguncian (transaksi membatasi akses ke data yang saat ini bekerja dengan transaksi lain) atau kontrol versi multiversion,
MVCC (transaksi tidak pernah mengubah data yang direkam sebelumnya dan selalu membuat versi baru).
Standar ANSI / ISO SQL mendefinisikan 4 level isolasi untuk transaksi yang memengaruhi tingkat saling memblokir mereka. Semakin tinggi tingkat isolasi, semakin sedikit efek yang tidak diinginkan. Harga untuk ini adalah untuk memperlambat aplikasi (karena transaksi lebih sering menunggu untuk membuka kunci data yang mereka butuhkan) dan meningkatkan kemungkinan kebuntuan.
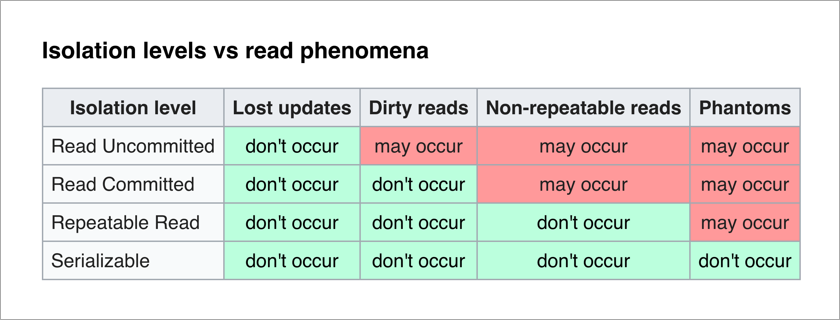
Yang paling menyenangkan bagi seorang programmer aplikasi adalah level Serializable - tidak ada efek yang tidak diinginkan dan seluruh kompleksitas memastikan integritas data dialihkan ke DBMS.
Mari kita pikirkan tentang implementasi naif dari level Serializable - dengan setiap transaksi, kami hanya memblokir semua orang. Setiap transaksi tulis dapat dilakukan secara teoritis dalam 50 μs (waktu satu operasi tulis pada disk SSD modern). Dan kami ingin menyimpan data ke tiga mesin, ingat? Jika mereka berada di pusat data yang sama, maka perekaman akan memakan waktu 1-3 ms. Dan jika mereka, untuk keandalan, ada di kota yang berbeda, maka perekaman dapat dengan mudah mengambil 10-12ms (waktu perjalanan paket jaringan dari Moskow ke St. Petersburg dan sebaliknya). Yaitu, dengan implementasi tingkat Serializable yang naif dengan pencatatan berurutan, kita dapat melakukan tidak lebih dari 100 transaksi per detik. Sementara SSD terpisah memungkinkan Anda melakukan sekitar 20.000 operasi tulis per detik!
Kesimpulan: transaksi tulis harus dilakukan secara paralel, dan untuk menskalakannya, Anda memerlukan mekanisme penyelesaian konflik yang baik.
Sharding
Apa yang harus dilakukan ketika data berhenti masuk pada satu server? Ada dua mekanisme pembesaran standar:
- Tegak ketika kita baru saja menambahkan memori dan disk ke server ini. Ini memiliki batasnya - dalam hal jumlah inti per prosesor, jumlah prosesor, dan jumlah memori.
- Horisontal, ketika kami menggunakan banyak mesin dan mendistribusikan data di antara mereka. Set mesin seperti itu disebut cluster. Untuk memasukkan data ke dalam sebuah cluster, mereka harus di-shard - yaitu, untuk setiap record, tentukan di server mana ia akan berada.
Kunci sharding adalah parameter yang dengannya data didistribusikan di antara server, misalnya, klien atau pengidentifikasi organisasi.
Bayangkan Anda perlu merekam data tentang semua penghuni Bumi dalam sebuah cluster. Sebagai kunci beling, Anda dapat mengambil, misalnya, tahun kelahiran orang tersebut. Maka 116 server akan cukup (dan setiap tahun akan perlu untuk menambah server baru). Atau Anda dapat mengambil sebagai kunci negara tempat orang tersebut tinggal, maka Anda akan membutuhkan sekitar 250 server. Namun, opsi pertama lebih disukai, karena tanggal lahir orang tersebut tidak berubah, dan Anda tidak perlu mentransfer data tentangnya di antara server.
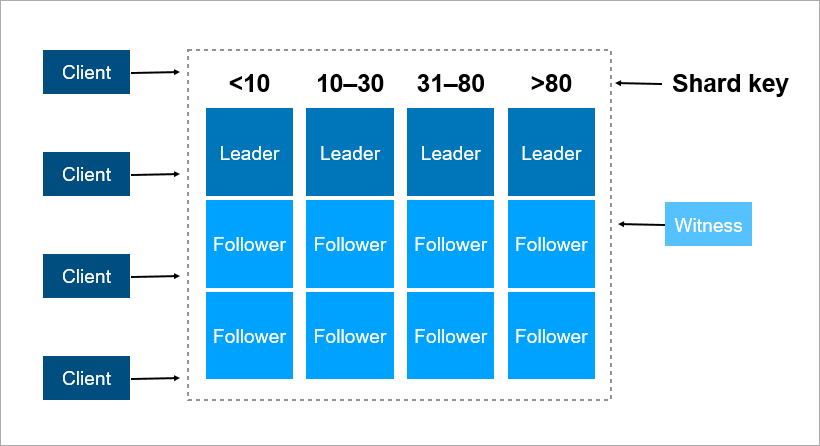
Di Pyrus, Anda dapat mengambil organisasi sebagai kunci sharding. Tetapi mereka sangat berbeda dalam ukuran: ada Sovcombank besar (lebih dari 15 ribu pengguna) dan ribuan perusahaan kecil. Saat Anda menetapkan suatu organisasi server tertentu, Anda tidak tahu sebelumnya bagaimana itu akan tumbuh. Jika organisasi besar dan menggunakan layanan secara aktif, maka cepat atau lambat datanya akan berhenti ditempatkan pada satu server, dan Anda harus melakukan pengulangan. Dan ini tidak mudah jika datanya terabyte. Bayangkan: sistem dimuat, transaksi berjalan setiap detik, dan dalam kondisi ini Anda perlu memindahkan data dari satu tempat ke tempat lain. Anda tidak dapat menghentikan sistem, volume seperti itu dapat dipompa selama beberapa jam, dan pelanggan bisnis tidak akan bertahan selama downtime yang lama.
Sebagai kunci sharding, lebih baik memilih data yang jarang berubah. Namun, jauh dari selalu tugas yang diterapkan membuat ini mudah dilakukan.
Konsensus dalam cluster
Ketika ada banyak mesin di cluster dan beberapa dari mereka kehilangan kontak dengan yang lain, lalu bagaimana memutuskan siapa yang menyimpan versi terbaru dari data? Menugaskan server saksi saja tidak cukup, karena itu juga dapat kehilangan kontak dengan seluruh cluster. Selain itu, dalam situasi otak yang terpecah, beberapa mesin dapat merekam versi berbeda dari data yang sama - dan Anda perlu entah bagaimana menentukan yang mana yang paling relevan. Untuk mengatasi masalah ini, orang-orang datang dengan algoritma konsensus. Mereka memungkinkan beberapa mesin identik untuk mencapai hasil tunggal pada masalah apa pun dengan memilih. Pada tahun 1989, algoritma semacam itu,
Paxos , diterbitkan, dan pada tahun 2014, Stanford datang dengan
Raft yang lebih sederhana untuk diimplementasikan. Sebenarnya, agar sekelompok (2N +1) server untuk mencapai konsensus, cukup bahwa pada saat yang sama memiliki tidak lebih dari kegagalan N. Untuk bertahan dari 2 kegagalan, cluster harus memiliki setidaknya 5 server.
Penskalaan DBMS Relasional
Sebagian besar database yang digunakan pengembang untuk bekerja dengan mendukung aljabar relasional. Data disimpan dalam tabel dan terkadang Anda harus menggabungkan data dari tabel yang berbeda menggunakan operasi JOIN. Pertimbangkan contoh database dan permintaan sederhana untuk itu.
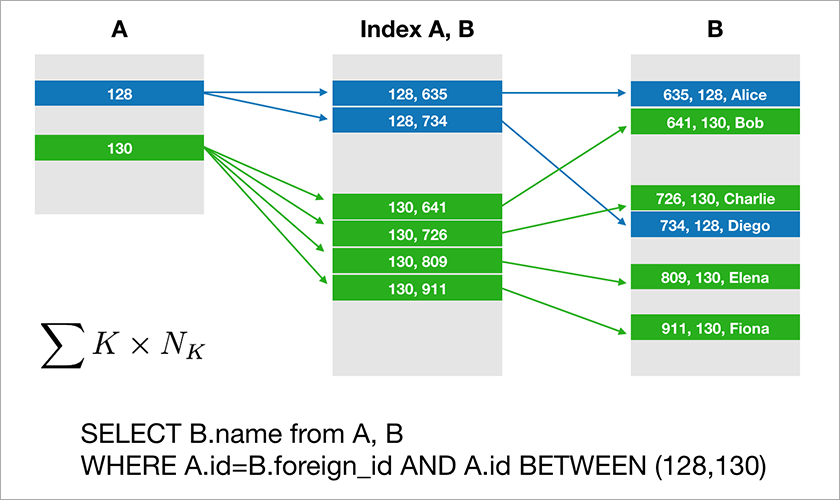
Asumsikan A.id adalah kunci utama dengan indeks berkerumun. Kemudian pengoptimal akan membangun rencana yang kemungkinan besar akan memilih catatan yang diperlukan dari tabel A dan kemudian mengambil tautan yang sesuai ke catatan di tabel B dari indeks yang sesuai (A, B). Waktu pelaksanaan kueri ini tumbuh secara logaritmik dari jumlah catatan dalam tabel.
Sekarang bayangkan bahwa data didistribusikan di empat server di kluster dan Anda perlu menjalankan kueri yang sama:
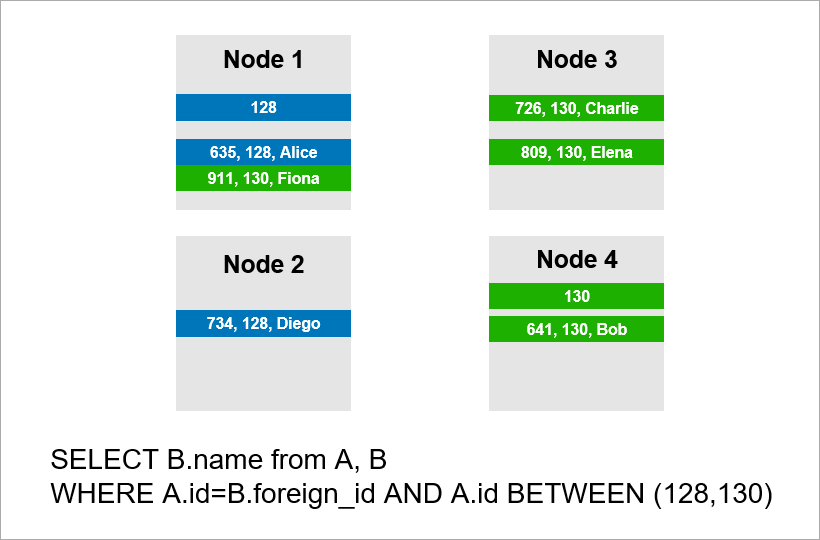
Jika DBMS tidak ingin melihat semua catatan dari seluruh kluster, maka mungkin akan mencoba untuk menemukan catatan dengan A.id sama dengan 128, 129, atau 130 dan menemukan catatan yang sesuai untuk mereka dari tabel B. Tetapi jika A.id bukan kunci beling, maka DBMS di muka tidak dapat mengetahui di server mana data tabel A. aktif. Saya tetap harus menghubungi semua server untuk mengetahui apakah ada catatan A.id yang sesuai dengan kondisi kami. Kemudian setiap server dapat membuat GABUNG di dalam dirinya sendiri, tetapi ini tidak cukup. Anda lihat, kita perlu catatan pada simpul 2 dalam sampel, tetapi tidak ada catatan dengan A.id = 128? Jika node 1 dan 2 akan BERGABUNG secara independen, maka hasil kueri tidak akan lengkap - kami tidak akan menerima bagian dari data.
Oleh karena itu, untuk memenuhi permintaan ini, setiap server harus beralih ke yang lain. Runtime tumbuh secara kuadratik dengan jumlah server. (Anda beruntung jika Anda dapat shard semua tabel dengan kunci yang sama, maka Anda tidak perlu berkeliling semua server. Namun, dalam praktiknya ini tidak realistis - akan selalu ada pertanyaan di mana pengambilan tidak didasarkan pada kunci shard.)
Dengan demikian, skala operasi BERGABUNG secara fundamental buruk dan ini merupakan masalah mendasar dari pendekatan relasional.
Pendekatan NoSQL
Kesulitan dengan penskalaan DBMS klasik telah membuat orang membuat database NoSQL yang tidak memiliki operasi BERGABUNG. Tidak ada yang bergabung - tidak ada masalah. Tetapi tidak ada properti ACID, tetapi mereka tidak menyebutkan ini dalam materi pemasaran. Dengan cepat
ditemukan pengrajin yang menguji kekuatan berbagai sistem terdistribusi dan
memposting hasilnya secara publik . Ternyata ada skenario ketika
cluster Redis kehilangan 45% dari data yang disimpan, cluster RabbitMQ - 35% dari pesan ,
MongoDB - 9% dari catatan ,
Cassandra - hingga 5% . Dan kita berbicara
tentang kerugian setelah cluster memberi tahu klien tentang save yang berhasil. Biasanya Anda mengharapkan tingkat keandalan yang lebih tinggi dari teknologi yang dipilih.
Google telah mengembangkan basis data
Spanner , yang beroperasi secara global di seluruh dunia. Spanner menjamin properti ACID, Serializability, dan lainnya. Mereka memiliki jam atom di pusat data yang menyediakan waktu yang akurat, dan ini memungkinkan Anda untuk membangun urutan transaksi global tanpa perlu meneruskan paket jaringan antar benua. Gagasan Spanner adalah bahwa lebih baik bagi programmer untuk menangani masalah kinerja yang timbul dengan sejumlah besar transaksi daripada kruk di sekitar kurangnya transaksi. Namun, Spanner adalah teknologi tertutup, itu tidak cocok untuk Anda jika karena alasan tertentu Anda tidak ingin bergantung pada satu vendor.
Penduduk asli Google mengembangkan analog open source dari Spanner dan menamainya CockroachDB ("kecoak" dalam bahasa Inggris "kecoak", yang harus melambangkan keberlangsungan database). Pada Habré
sudah menulis tentang tidak tersedianya produk untuk produksi, karena cluster kehilangan data. Kami memutuskan untuk memeriksa versi 2.0 yang lebih baru, dan sampai pada kesimpulan yang sama. Kami tidak kehilangan data, tetapi beberapa pertanyaan paling sederhana dieksekusi terlalu lama.
Akibatnya, saat ini ada database relasional yang skalanya baik hanya secara vertikal, yang mahal. Dan ada solusi NoSQL tanpa transaksi dan tanpa jaminan ACID (jika Anda ingin ACID, tulis kruk).
Bagaimana membuat aplikasi mission-critical di mana data tidak muat di satu server? Solusi baru muncul di pasar, dan tentang salah satunya -
FoundationDB - kami akan memberi tahu Anda lebih banyak di artikel berikutnya.