
Halo, Habr! Nama saya Stanislav Semenov, saya sedang mengerjakan teknologi untuk mengekstraksi data dari dokumen di R&D ABBYY. Dalam artikel ini, saya akan berbicara tentang pendekatan utama dalam pemrosesan dokumen semi-terstruktur (faktur, penerimaan kas, dll.) Yang kami gunakan baru-baru ini dan yang kami gunakan saat ini. Dan kita akan berbicara tentang bagaimana metode pembelajaran mesin dapat diterapkan untuk menyelesaikan masalah ini.
Kami akan mempertimbangkan faktur sebagai dokumen, karena di dunia mereka sangat luas dan paling dicari dalam hal ekstraksi data. Omong-omong, pemrosesan faktur otomatis adalah salah satu skenario paling populer di antara pelanggan asing kami. Misalnya, dengan ABBYY FlexiCapture, American PepsiCo Imaging Technology
mengurangi waktu pemrosesan faktur dan jumlah kesalahan karena entri manual, sedangkan pengecer Eropa Sportina
mulai memasukkan data dari akun ke dalam sistem akuntansi
2 kali lebih cepat .
Faktur adalah dokumen yang digunakan dalam praktik komersial internasional dan sangat penting untuk bisnis. Sesuatu yang mirip dengan faktur di Rusia, misalnya, adalah waybill. Data dari dokumen-dokumen tersebut termasuk dalam berbagai sistem akuntansi, dan kesalahan di sana, secara sederhana, tidak diterima.
Faktur biasa dapat dianggap cukup terstruktur, berisi dua kelas utama objek:
- berbagai bidang dari header (nomor dokumen, tanggal, pengirim, penerima, total, dll.),
- data tabular adalah daftar barang dan jasa (kuantitas, harga, deskripsi, dll.).
Seperti inilah tampilannya:
Jutaan jam kerja dihabiskan setiap tahun untuk memproses faktur. Dan itu sangat mahal. Menurut berbagai perkiraan, untuk perusahaan pemrosesan satu faktur kertas biaya dari $ 10 hingga $ 40, di mana sebagian besar dari biaya ini adalah tenaga kerja manual untuk memasukkan dan merekonsiliasi data.
Ada perusahaan yang memproses jutaan faktur per bulan. Untuk melakukan ini, mereka berisi seluruh staf yang terdiri dari ratusan, dan kadang-kadang ribuan orang. Mudah untuk memperkirakan bahwa peningkatan akurasi pengakuan atau efisiensi ekstraksi data hanya 1% dapat mengurangi biaya perusahaan besar hingga ratusan ribu dan bahkan jutaan dolar per tahun.
Di sisi lain, ada sejumlah besar dokumen. Pada 2017, Billentis
memperkirakan jumlah total faktur / faktur yang dihasilkan per tahun di dunia sebesar 400 miliar. Dari jumlah tersebut, hanya sekitar 10% yang elektronik, dan sisanya memerlukan entri manual sepenuhnya atau partisipasi manusia yang intensif. Jika Anda mencetak 400 miliar dokumen pada kertas A4 standar, maka itu adalah ribuan truk kertas per hari, atau setumpuk kertas dengan tinggi manusia setiap detik!
Beberapa kata tentang bagaimana teknologi berkembang

Banyak perusahaan sedang mengembangkan perangkat lunak khusus yang dapat mengenali dokumen dan mengekstrak data dari mereka. Namun kualitas pemrosesan faktur masih belum sempurna. "Apa masalahnya?" - kamu bertanya.
Ini semua tentang berbagai macam faktur. Tidak ada standar untuk faktur, dan setiap perusahaan bebas untuk membuat versi dokumennya sendiri: jenis, struktur, dan lokasi bidang.
Temukan bidang dengan kata kunci
Upaya pertama untuk mengekstraksi data dilakukan dengan mencari kata-kata kunci khusus di antara semua kata yang dikenal, seperti, misalnya, Nomor Faktur atau Total, dan kemudian, di lingkungan kecil kata-kata ini, misalnya, ke kanan atau bawah, untuk menemukan artinya sendiri.
Lokasi Nomor Faktur di berbagai faktur (dapat diklik):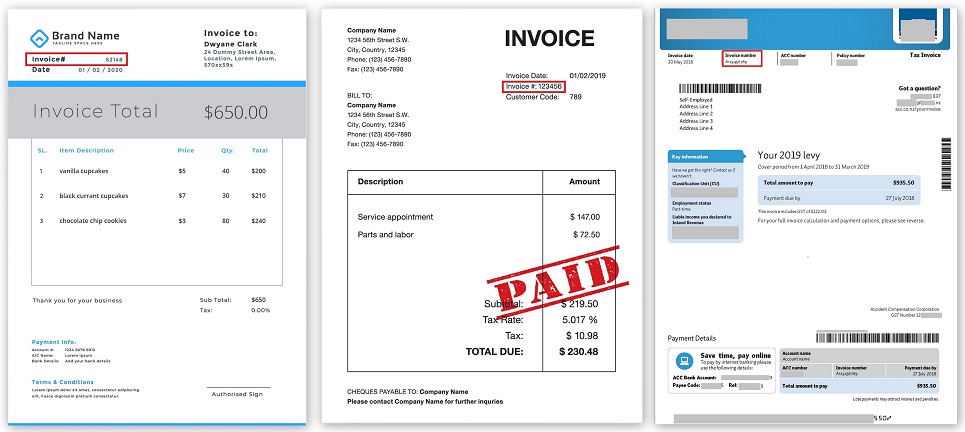
Seluruh logika diprogram, bahwa ada bidang ini dan itu, mereka berada di tempat dokumen ini dan itu, di sekitar mereka ada bidang lain di beberapa jarak. Dan ini entah bagaimana berhasil sampai beberapa perusahaan lain muncul, yang mulai mengirim dokumen-dokumennya dalam bentuk yang sama sekali berbeda. Atau perusahaan sebelumnya tiba-tiba mengubah formatnya, dan semuanya berhenti berfungsi.
Pola
Memerangi ini, setiap kali memprogram ulang sesuatu, itu tidak rasional. Oleh karena itu, paradigma baru datang untuk menyelamatkan - penggunaan templat.
Templat adalah seperangkat bidang yang perlu ditemukan dalam dokumen, dan seperangkat aturan tentang cara menemukan bidang ini. Keuntungan utama di sini adalah bahwa template dibuat secara visual. Misalnya, kami ingin mencari Nomor Faktur dan Total, pilih bidang ini dan konfigurasikan parameter bahwa bidang ini dan itu muncul segera setelah kata kunci ini dan itu, terletak di bagian atas dokumen dan berisi angka serta tanda baca.
Alat khusus dikembangkan, yang disebut editor template, di mana pengguna yang sudah mahir tanpa bantuan programmer dapat dengan cepat mengatur semacam logika secara manual. Segera setelah dokumen formulir baru tiba, templat dibuat untuk itu dan semuanya mulai bekerja kurang lebih.
Contoh template (dapat diklik):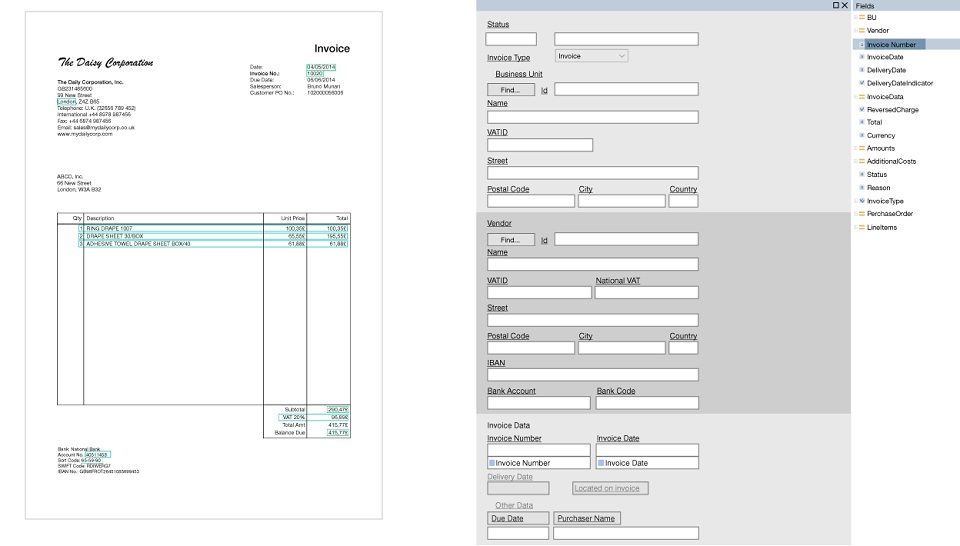
Tetapi untuk membuat satu templat saja tidak cukup, perlu dibuat ratusan bahkan ribuan. Oleh karena itu, menyiapkan produk untuk setiap klien terkadang dapat menghabiskan banyak waktu. Tidak mungkin membuat template "universal" sebelumnya, yang akan mencakup seluruh jenis faktur.
Menggunakan templat, Anda dapat secara signifikan meningkatkan kualitas pengambilan tabel. Tetapi seringkali struktur tabel yang kompleks ditemukan, dengan representasi data non-standar, beberapa tingkat bersarang, dan templat dalam kasus ini tidak selalu berjalan dengan baik. Jadi sekali lagi, Anda harus menulis beberapa skrip yang berisi banyak parameter, kondisi, pengecualian yang dipilih secara manual, dll.
Menggunakan Machine Learning
Teknologi saat ini tidak berdiri diam, dan dengan perkembangan pembelajaran mesin, menjadi mungkin untuk mentransfer tugas penggalian data dari dokumen ke jaringan saraf.
Saat ini, ada beberapa pendekatan dasar yang digunakan dalam praktik:
- Pendekatan pertama adalah bekerja secara langsung dengan gambar input dokumen. Yaitu, gambar (gambar) atau fragmen dimasukkan ke input jaringan, dan jaringan belajar untuk menemukan area kecil di mana bidang yang diperlukan berada, dan kemudian teks di area ini dikenali menggunakan teknologi OCR (Pengenalan Karakter Optik) klasik. Ini adalah solusi ujung ke ujung yang dapat diimplementasikan dengan cepat. Anda dapat mengambil jaringan yang sudah jadi untuk mencari objek dalam gambar, misalnya, YOLO atau Faster R-CNN dan melatihnya dalam gambar dokumen yang ditandai.
Kerugian dari pendekatan ini bukanlah kualitas terbaik dari data yang diekstraksi dan kesulitan dalam mengekstraksi tabel. Sebenarnya, pendekatan ini dalam beberapa cara mirip dengan tugas menemukan kata yang tepat dalam gambar (word spotting), masalah mendasar dari bidang visi komputer, hanya di sini kita mencari bukan kata-kata, tetapi bidang yang diperlukan. - Pendekatan kedua adalah memproses teks yang diekstrak dari dokumen. Ini bisa berupa teks dari PDF, atau dokumen OCR satu halaman penuh. Ini menggunakan teknologi Natural Language Processing (NLP) . Garis dikumpulkan dari kata-kata individual, berbagai fragmen teks, paragraf atau kolom dibentuk dari garis, dan di dalamnya jaringan sudah belajar membedakan berbagai entitas bernama NER (Named-Entity Recognition).
Berbagai cara membentuk fragmen teks dimungkinkan. Anda dapat menggabungkan pendekatan pertama dan kedua, melatih satu jaringan untuk menemukan blok besar dengan informasi tertentu dalam gambar, misalnya, data tentang pengirim atau data tentang penerima, yang segera berisi nama, alamat, perincian, dll., Dan kemudian mentransfer teks dari setiap blok tersebut ke jaringan NER kedua.
Kualitas pendekatan ini mungkin lebih tinggi daripada hanya pada pendekatan pertama, tetapi agak sulit untuk membangun model yang efektif. Saat ini, ada beberapa model yang cukup canggih, misalnya, LSTM-CRF untuk NER, yang dapat menandai kata-kata dalam teks dan mendefinisikan entitas. - Pendekatan ketiga adalah membangun representasi semantik dokumen tanpa merujuk pada jenis dokumen, mis. ketika kami tidak tahu dokumen apa yang ada di depan kami, tetapi kami mencoba memahaminya selama pemrosesan. Seperangkat kata-kata dokumen dengan berbagai atributnya (misalnya, apakah kata itu hanya berisi huruf atau angka), susunan kata-kata geometris (koordinat, indentasi) dan dengan berbagai pembatas dan koneksi yang diidentifikasi selama analisis gambar, diumpankan ke input jaringan dan output diperoleh untuk Setiap kata memiliki serangkaian karakteristik spesifiknya sendiri. Berdasarkan karakteristik yang diperoleh, berbagai set hipotesis bidang yang mungkin atau tabel dibentuk, yang selanjutnya diurutkan dan dievaluasi oleh penggolong tambahan. Kemudian hipotesis yang paling dapat diandalkan dari struktur dan isi dokumen dipilih.
Secara teknis ini sudah merupakan solusi yang paling sulit, tetapi Anda dapat memecahkan masalah penggalian data dari dokumen secara umum.
Bagaimana kita menggunakan jaringan saraf
Kami di ABBYY tidak hanya memonitor secara dekat pencapaian ilmu pengetahuan dan teknologi, tetapi juga menciptakan teknologi canggih kami sendiri dan menerapkannya dalam berbagai produk.
Gambar di bawah ini menunjukkan arsitektur umum dari solusi kami menggunakan jaringan saraf.
Gambar yang dapat diklik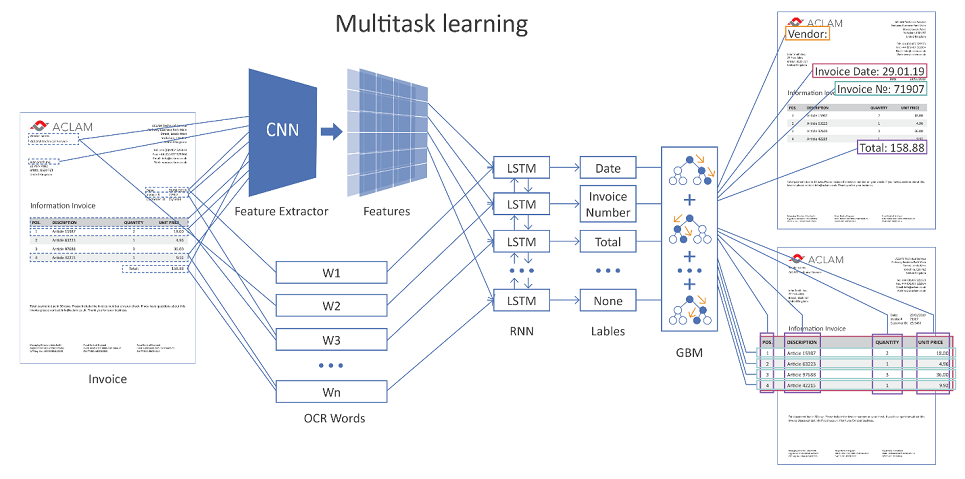
Seluruh halaman dokumen dimasukkan ke input jaringan. Menggunakan lapisan konvolusional (CNN), berbagai fitur geometris terbentuk, misalnya, posisi relatif kata-kata relatif satu sama lain. Selanjutnya, tanda-tanda ini dikombinasikan dengan representasi vektor dari kata-kata yang dikenali (embeddings kata) dan disajikan pada berulang (LSTM) dan lapisan yang terhubung sepenuhnya. Ada beberapa lapisan keluaran yang berbeda (pembelajaran multi-tugas), setiap keluaran menyelesaikan masalahnya sendiri:
- penentuan jenis bidang yang sesuai dengan kata tersebut,
- hipotesis batas-batas tabel,
- hipotesis baris tabel, batas kolom, dll.
Jika dokumen multi-halaman, maka jaringan membuat prediksi untuk setiap halaman individu, maka hasilnya digabungkan.
Selanjutnya, hipotesis dibentuk dari kemungkinan pengaturan bidang dan tabel, dengan bantuan fungsi regresi yang dilatih secara terpisah, mereka dievaluasi, dan hipotesis yang paling percaya diri menang.
Untuk meningkatkan keakuratan ekstraksi data, selain memisahkan dokumen berdasarkan jenis (periksa, faktur, kontrak, dll.), Pengelompokan tambahan terjadi di dalam jenisnya sesuai dengan karakteristik tambahan.
Misalnya, untuk faktur dapat berupa vendor atau hanya penampilan (sesuai dengan tingkat kesamaan lokasi bidang). Dan kemudian, tergantung pada kelompok tertentu (cluster), pengaturan algoritma spesifik diterapkan. Secara teknis, memiliki contoh faktur yang ditandai dengan benar untuk kelompok yang berbeda, dimungkinkan di sisi pengguna untuk melatih kembali mekanisme untuk mengevaluasi dan memilih hipotesis yang tepat.
Untuk mengonfigurasi semua jenis parameter algoritma dan jaringan saraf kami, kami menggunakan metode evolusi diferensial, yang telah terbukti dengan sangat baik dalam praktiknya.
Hasil Pembelajaran Mesin Kami

- Metode yang dikembangkan untuk mengekstraksi data dari dokumen terstruktur menggunakan pembelajaran mesin dalam banyak kasus menunjukkan hasil yang lebih baik daripada solusi yang diprogram berdasarkan heuristik. Peningkatan kualitas dalam berbagai metrik berkisar dari beberapa unit hingga puluhan persen pada berbagai entitas yang dapat diekstraksi.
- Ada keuntungan yang tidak dapat disangkal atas pendekatan klasik - kemampuan untuk melatih ulang jaringan pada data baru. Dalam hal berbagai bentuk dokumen, sekarang ini bukan masalah, melainkan suatu kebutuhan. Semakin banyak dari mereka, semakin baik; semakin kuat kemampuan jaringan untuk menggeneralisasi dan semakin tinggi kualitasnya.
- Ada peluang untuk merilis solusi yang disebut "out of the box", ketika pengguna hanya menginstal produk (pada kenyataannya, jaringan terlatih), dan semuanya segera mulai bekerja dengan hasil yang dapat diterima. Tidak perlu memprogram apa pun, menyesuaikan template dengan panjang dan menyakitkan, pilih semua jenis parameter.
Detail penting yang juga ingin saya sebutkan adalah data. Tidak ada pembelajaran mesin yang dapat terjadi tanpa data berkualitas. Pembelajaran mesin memberikan hasil yang lebih baik daripada rekayasa pengetahuan, hanya jika ada cukup banyak data yang ditandai. Dalam hal faktur, ini adalah puluhan ribu dokumen berlabel manual, dan angka ini terus bertambah.
Selain itu, kami menggunakan mekanisme augmentasi data canggih, mengubah nama organisasi, alamat, daftar barang dan jenis layanan dalam tabel, tanggal, berbagai karakteristik kuantitatif, seperti harga, jumlah, biaya, dll. Kami juga mengubah urutan berbagai entitas dalam dokumen, yang memungkinkan kami untuk akhirnya menghasilkan jutaan dokumen yang sangat berbeda untuk pelatihan.
Alih-alih sebuah kesimpulan
Sebagai kesimpulan, kita dapat mengatakan bahwa pemrograman, tentu saja, tidak menghilang, tetapi secara bertahap mengubah perannya. Dengan setiap hari baru, pembelajaran mesin mulai mengatasi tugas-tugas yang diberikan dengan lebih baik dan lebih baik di berbagai industri, mengalahkan pendekatan klasik. Keuntungan yang tidak dapat dipungkiri dari pembelajaran mesin dalam efisiensi: puluhan tahun kerja intelektual sekarang menghabiskan puluhan jam belajar mesin. Oleh karena itu, dalam waktu dekat kami melihat perkembangan yang lebih besar dan penerapan jaringan di semua perkembangan kami. Dan jika Anda tertarik, kami selalu terbuka untuk saran dan
kerja sama .