Hai Habr!
Banyak pembaca reguler dan penulis situs mungkin berpikir tentang siklus hidup dari artikel yang diterbitkan di sini. Dan meskipun ini secara intuitif lebih atau kurang jelas (jelas, misalnya, bahwa artikel pada halaman pertama memiliki jumlah tampilan maksimum), tetapi seberapa spesifik?
Untuk mengumpulkan statistik, kami akan menggunakan Python, Pandas, Matplotlib dan Raspberry Pi.
Tolong, mereka yang tertarik dengan apa yang terjadi, di bawah kucing.
Pengumpulan data
Pertama, mari kita tentukan metrik - apa yang ingin kita ketahui. Semuanya sederhana di sini, setiap artikel memiliki 4 parameter utama yang ditampilkan pada halaman - ini adalah jumlah tampilan, suka, bookmark dan komentar. Kami akan menganalisisnya.
Mereka yang ingin segera melihat hasilnya, dapat pergi ke bagian ketiga, tetapi untuk sekarang ini adalah tentang pemrograman.
Paket umum: kami akan mengurai data yang diperlukan dari halaman web, menyimpannya dengan CSV, dan melihat apa yang kami dapatkan selama beberapa hari. Pertama, muat teks artikel (penanganan pengecualian dihilangkan untuk kejelasan):
link = "https://habr.com/ru/post/000001/" f = urllib.urlopen(link) data_str = f.read()
Sekarang kita perlu mengekstraksi data dari baris data_str (tentu saja, dalam HTML). Buka kode sumber di browser (elemen yang tidak berprinsip dihapus):
<ul class="post-stats post-stats_post js-user_" id="infopanel_post_438514"> <li class="post-stats__item post-stats__item_voting-wjt"> <span class="voting-wjt__counter voting-wjt__counter_positive js-score" title=" 448: ↑434 ↓14">+420</span> </li> <span class="btn_inner"><svg class="icon-svg_bookmark" width="10" height="16"><use xlink:href="https://habr.com/images/1550155671/common-svg-sprite.svg#book" /></svg><span class="bookmark__counter js-favs_count" title=" , ">320</span></span> <li class="post-stats__item post-stats__item_views"> <div class="post-stats__views" title=" "> <span class="post-stats__views-count">219k</span> </div> </li> <li class="post-stats__item post-stats__item_comments"> <a href="https://habr.com/ru/post/438514/#comments" class="post-stats__comments-link" <span class="post-stats__comments-count" title=" ">577</span> </a> </li> <li class="post-stats__item"> <span class="icon-svg_report"><svg class="icon-svg" width="32" height="32" viewBox="0 0 32 32" aria-hidden="true" version="1.1" role="img"><path d="M0 0h32v32h-32v-32zm14 6v12h4v-12h-4zm0 16v4h4v-4h-4z"/></svg> </span> </li> </ul>
Mudah untuk melihat bahwa teks yang kita butuhkan ada di dalam blok '<ul class = "post-stats post-stats_post js-user_>', dan elemen yang diperlukan ada di blok dengan nama voting-wjt__counter, bookmark__counter, post-stats__views-count dan post- stats__comments-count. Dengan namanya, semuanya cukup jelas.
Kami akan mewarisi kelas str dan menambahkannya metode mengekstraksi substring yang terletak di antara dua tag:
class Str(str): def find_between(self, first, last): try: start = self.index(first) + len(first) end = self.index(last, start) return Str(self[start:end]) except ValueError: return Str("")
Anda dapat melakukannya tanpa warisan, tetapi ini memungkinkan Anda untuk menulis kode yang lebih ringkas. Dengan itu, semua ekstraksi data cocok dalam 4 baris:
votes = data_str.find_between('span class="voting-wjt__counter voting-wjt__counter_positive js-score"', 'span').find_between('>', '<') bookmarks = data_str.find_between('span class="bookmark__counter js-favs_count"', 'span').find_between('>', '<') views = data_str.find_between('span class="post-stats__views-count"', 'span').find_between('>', '<') comments = data_str.find_between('span class="post-stats__comments-count"', 'span').find_between('>', '<')
Tapi itu belum semuanya. Seperti yang Anda lihat, jumlah komentar atau tampilan dapat disimpan sebagai string seperti "12.1k", yang tidak langsung diterjemahkan ke int.
Tambahkan fungsi untuk mengonversi string semacam itu ke angka:
def to_int(self): s = self.lower().replace(",", ".") if s[-1:] == "k":
Tinggal menambahkan cap waktu saja, dan Anda dapat menyimpan data dalam csv:
timestamp = strftime("%Y-%m-%dT%H:%M:%S.000", gmtime()) str_out = "{},votes:{},bookmarks:{},views:{},comments:{};".format(timestamp, votes.to_int(), bookmarks.to_int(), views.to_int(), comments.to_int())
Karena kami tertarik menganalisis beberapa artikel, kami menambahkan kemampuan untuk menentukan tautan melalui baris perintah. Kami juga akan menghasilkan nama file log dengan ID artikel:
link = sys.argv[1]
Dan langkah terakhir. Kami mengambil kode dalam fungsi, dalam loop kami polling data, dan menulis hasilnya ke log.
delay_s = 5*60 while True:
Seperti yang Anda lihat, data diperbarui setiap 5 menit agar tidak membuat beban di server. Saya menyimpan file program dengan nama habr_parse.py, ketika dimulai, itu akan menyimpan data sampai program ditutup.
Selanjutnya, disarankan untuk menyimpan data, setidaknya selama beberapa hari. Karena Kami enggan menghidupkan komputer selama beberapa hari, kami menggunakan Raspberry Pi - ia akan memiliki daya yang cukup untuk tugas seperti itu, dan tidak seperti PC, Raspberry Pi tidak membuat suara dan hampir tidak menggunakan listrik. Kami membahas SSH dan menjalankan skrip kami:
nohup python habr_parse.py https://habr.com/ru/post/0000001/ &
Perintah nohup meninggalkan skrip di latar belakang setelah menutup konsol.
Sebagai bonus, Anda dapat menjalankan server http di latar belakang dengan memasukkan perintah "nuhup python -m SimpleHTTPServer 8000 &". Ini akan memungkinkan Anda untuk menonton hasilnya secara langsung di browser kapan saja, membuka tautan dari formulir
http://192.168.1.101:8000 (alamatnya, tentu saja, mungkin berbeda).
Sekarang Anda dapat membiarkan Raspberry Pi dihidupkan dan kembali ke proyek dalam beberapa hari.
Analisis data
Jika semuanya dilakukan dengan benar, maka outputnya harus seperti log ini:
2019-02-12T22:26:28.000,votes:12,bookmarks:0,views:448,comments:1; 2019-02-12T22:31:29.000,votes:12,bookmarks:0,views:467,comments:1; 2019-02-12T22:36:30.000,votes:14,bookmarks:1,views:482,comments:1; 2019-02-12T22:41:30.000,votes:14,bookmarks:2,views:497,comments:1; 2019-02-12T22:46:31.000,votes:14,bookmarks:2,views:513,comments:1; 2019-02-12T22:51:32.000,votes:14,bookmarks:2,views:527,comments:1; 2019-02-12T22:56:32.000,votes:14,bookmarks:2,views:543,comments:1; 2019-02-12T23:01:33.000,votes:14,bookmarks:2,views:557,comments:2; 2019-02-12T23:06:34.000,votes:14,bookmarks:2,views:567,comments:3; 2019-02-12T23:11:35.000,votes:13,bookmarks:2,views:590,comments:4; ... 2019-02-13T02:47:03.000,votes:15,bookmarks:3,views:1100,comments:20; 2019-02-13T02:52:04.000,votes:15,bookmarks:3,views:1200,comments:20;
Mari kita lihat bagaimana prosesnya. Untuk memulai, muat csv ke dalam kerangka data panda:
import pandas as pd import numpy as np import datetime log_path = "habr_data.txt" df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments'])
Tambahkan fungsi untuk konversi dan rata-rata, dan ekstrak data yang diperlukan:
def to_float(s):
Rata-rata diperlukan karena jumlah tampilan di situs ditampilkan dalam peningkatan 100, yang mengarah ke jadwal "sobek". Pada prinsipnya, ini tidak perlu, tetapi dengan rata-rata terlihat lebih baik. Zona waktu Moskow juga ditambahkan dalam kode (waktu pada Raspberry Pi ternyata menjadi GMT).
Akhirnya, Anda dapat menampilkan grafik dan melihat apa yang terjadi.
import matplotlib.pyplot as plt
Hasil
Pada awal setiap grafik ada ruang kosong, yang dijelaskan secara sederhana - ketika skrip diluncurkan, artikel sudah diterbitkan, sehingga data tidak dikumpulkan dari awal. Titik "nol" ditambahkan secara manual dari deskripsi waktu publikasi artikel.
Semua grafik yang dibuat dihasilkan oleh matplotlib dan kode di atas.
Menurut hasil, saya membagi artikel yang diselidiki menjadi 3 kelompok. Pembagian ini bersyarat, meskipun masih memiliki beberapa pengertian.
Artikel Populer
Artikel ini adalah tentang beberapa topik populer dan relevan, dengan judul seperti "Bagaimana MTS mengurangi uang" atau "Roskomnadzor memblokir pusat
porno git".
Artikel semacam itu memiliki banyak pandangan dan komentar, tetapi "hype" berlangsung maksimal beberapa hari. Anda juga dapat melihat sedikit perbedaan dalam pertumbuhan jumlah tampilan pada siang dan malam hari (tetapi tidak sepenting yang diharapkan - tampaknya, Habr dibaca dari hampir semua zona waktu).
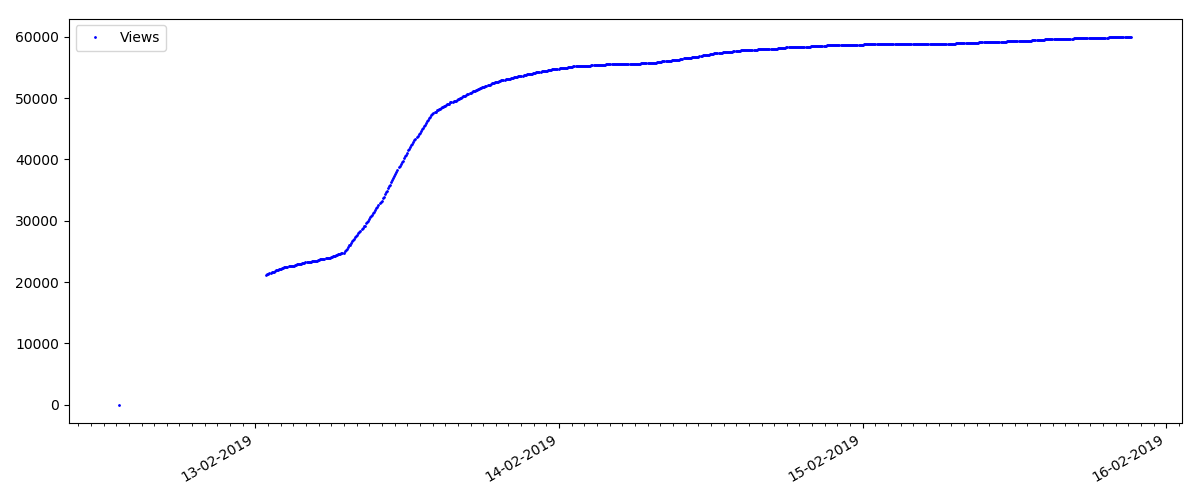
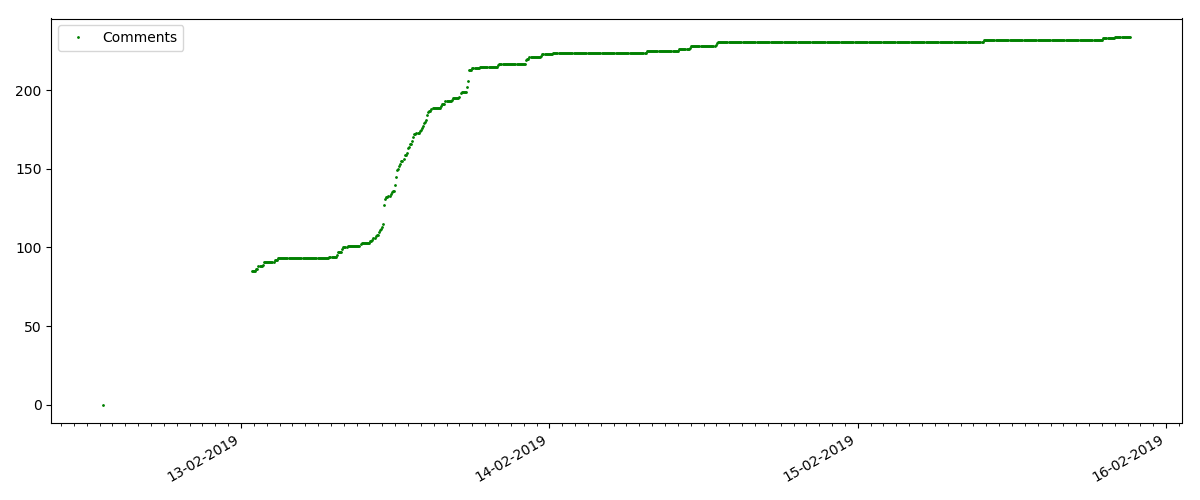
Jumlah "suka" tumbuh cukup signifikan, sementara jumlah bookmark tumbuh lebih lambat. Ini logis, karena Seseorang mungkin menyukai artikel itu, tetapi kekhususan teksnya sedemikian rupa sehingga tidak diperlukan untuk menandainya.
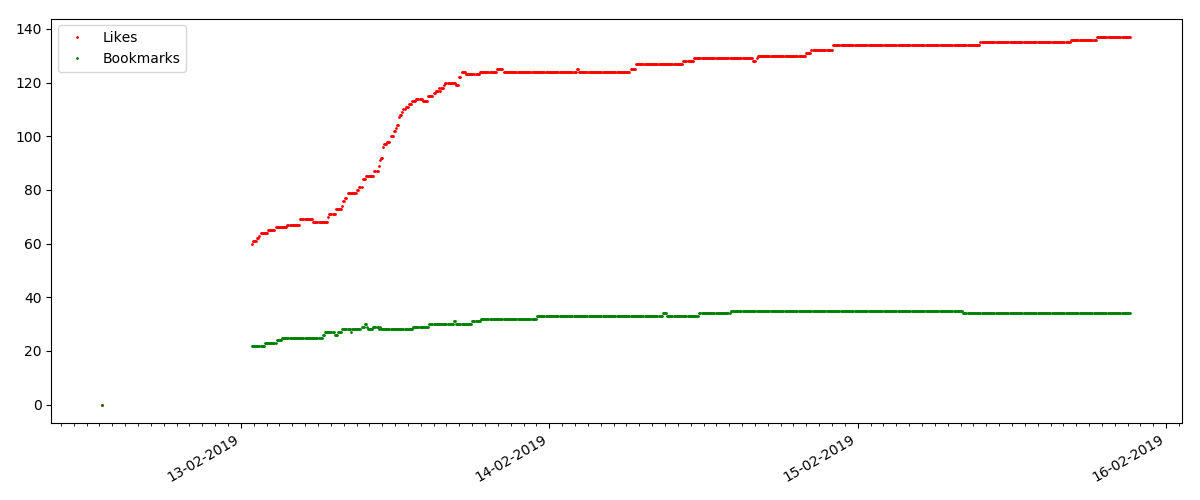
Rasio tampilan dan suka kurang lebih sama dan kira-kira 400: 1:
Artikel "Teknis"
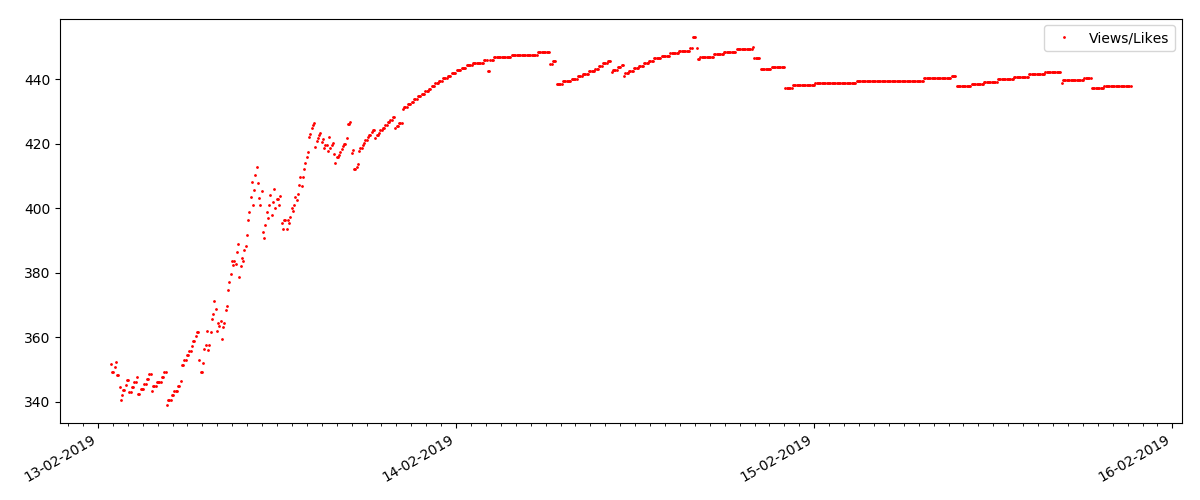
Ini adalah artikel yang lebih khusus, seperti "Menyiapkan Script untuk Node JS". Artikel seperti itu, tentu saja, mendapatkan pandangan yang jauh lebih sedikit daripada yang “panas”, jumlah komentar juga terasa lebih kecil (dalam hal ini hanya ada 4).
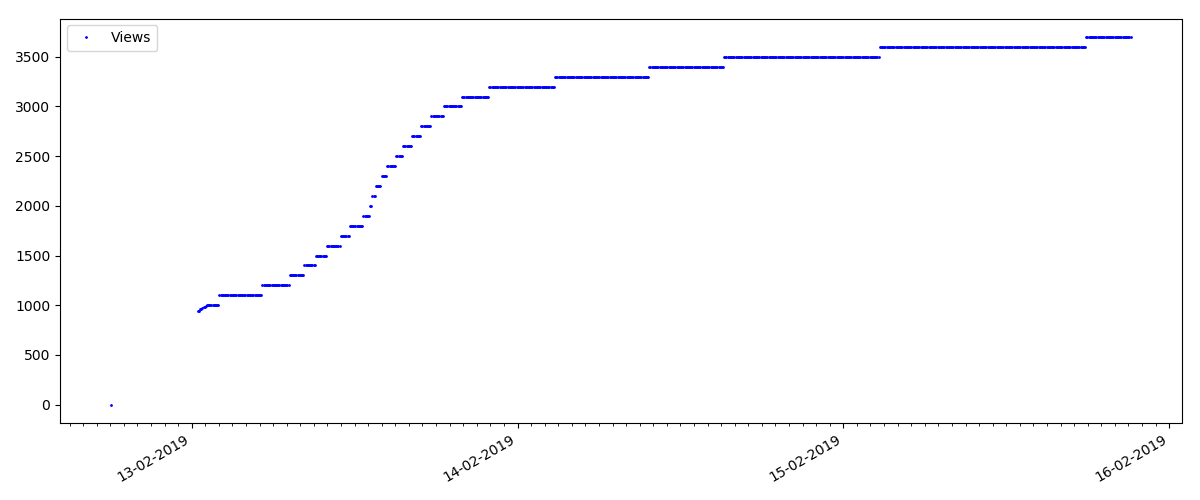
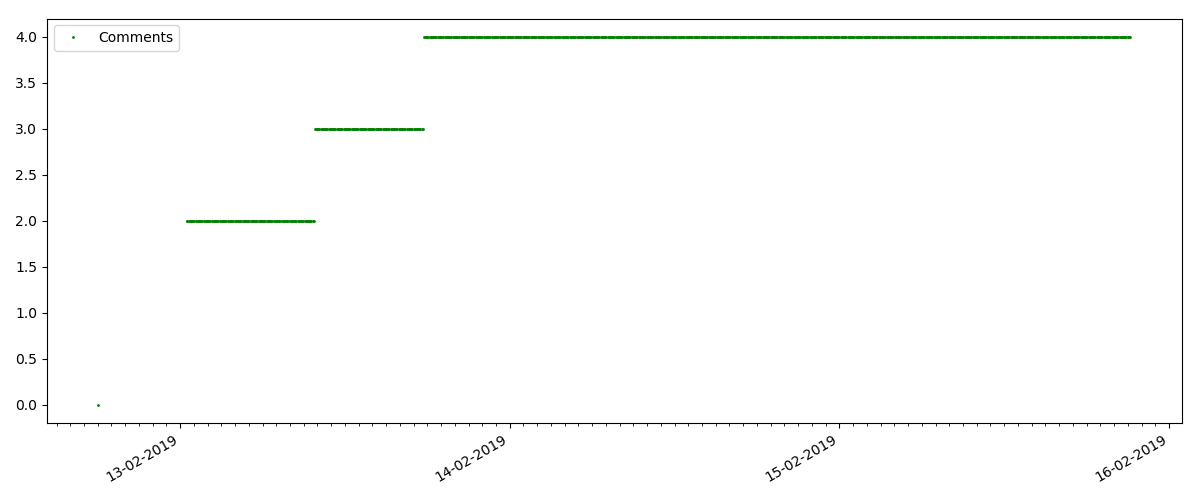
Tetapi poin berikutnya lebih menarik: jumlah "suka" untuk artikel tersebut tumbuh lebih lambat dari jumlah "bookmark". Ini dia sebaliknya dibandingkan dengan versi sebelumnya - banyak yang menemukan artikel yang berguna untuk disimpan untuk masa depan, tetapi pembaca tidak harus mengklik "suka" sama sekali.
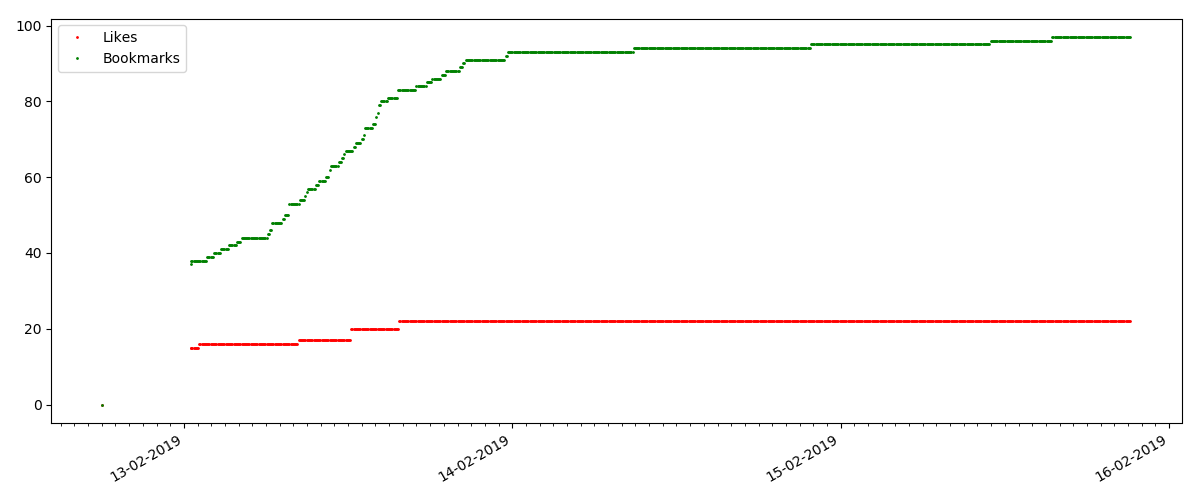
Ngomong-ngomong, pada titik ini saya ingin menarik perhatian administrator situs - saat menghitung peringkat artikel, Anda harus menghitung bookmark secara paralel dengan suka (misalnya, menggabungkan set oleh OR). Kalau tidak, ini mengarah ke bias dalam peringkat, ketika sebuah artikel terkenal memiliki banyak bookmark (yaitu, pembaca pasti menyukainya), tetapi orang-orang ini lupa atau terlalu malas untuk mengklik "suka".
Dan akhirnya, rasio pandangan dan suka: Anda dapat melihat bahwa itu terasa lebih tinggi daripada dalam perwujudan pertama dan kira-kira 150: 1, yaitu. kualitas konten juga dapat secara tidak langsung dianggap lebih tinggi.
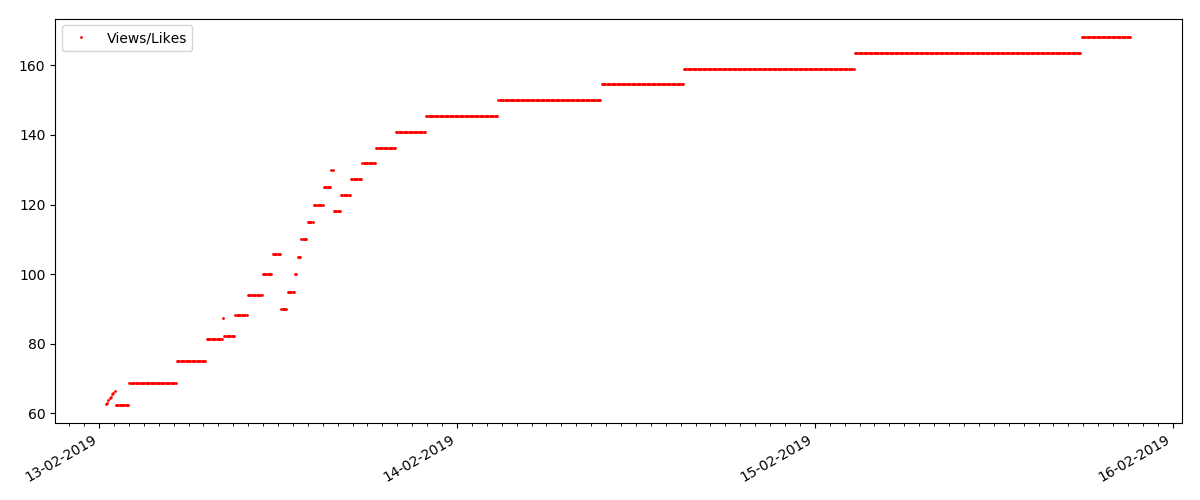
Artikel “Mencurigakan” (tapi ini tidak akurat)
Untuk artikel berikutnya yang diperiksa, jumlah "suka" meningkat sepertiga dalam interval 5 menit (segera dengan 10 dengan total 30 skor untuk semua beberapa hari).
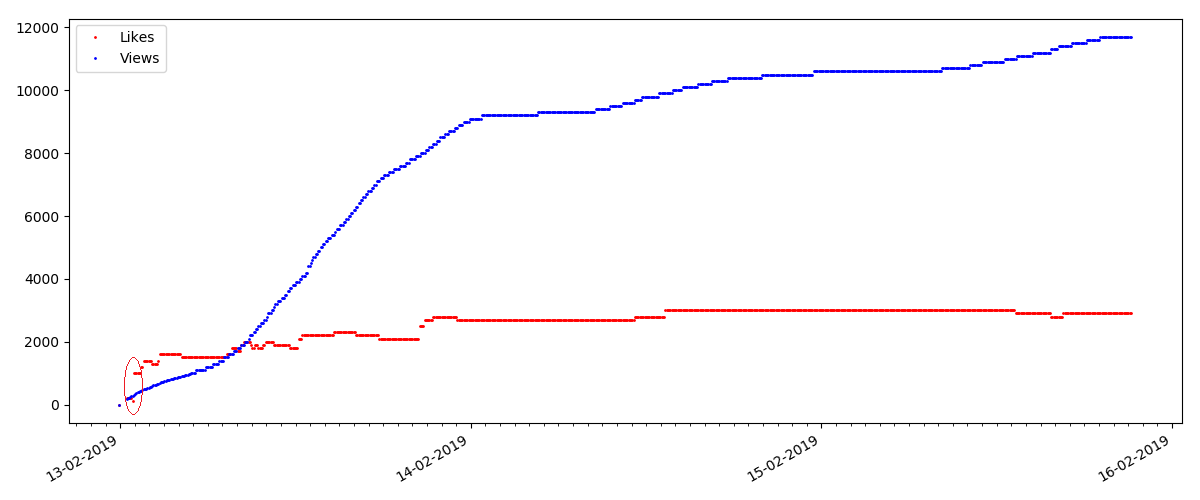
Orang bisa menduga adanya kecurangan, tetapi "teori antrian" pada prinsipnya memungkinkan terjadinya lonjakan semacam itu. Atau mungkin penulis hanya mengirim tautan ke 10 temannya, yang, tentu saja, tidak dilarang oleh aturan.
Kesimpulan
Kesimpulan utama adalah bahwa semuanya adalah pembusukan dan maya. Bahkan materi yang paling populer, memperoleh ribuan tampilan, akan masuk "di masa lalu" hanya dalam 3-4 hari. Begitulah, sayangnya, kekhasan Internet modern, dan mungkin seluruh industri media modern secara keseluruhan. Dan saya yakin bahwa angka-angka yang ditampilkan tidak hanya khusus untuk Habr, tetapi juga untuk sumber daya Internet serupa.
Kalau tidak, analisis ini lebih cenderung bersifat "Jumat", dan, tentu saja, tidak berpura-pura menjadi studi serius. Saya juga berharap seseorang menemukan sesuatu yang baru dalam menggunakan Pandas dan Matplotlib.
Terima kasih atas perhatian anda