Perangkat keras dan kompiler modern siap untuk membalikkan kode kita, jika itu bekerja lebih cepat. Dan produsen mereka dengan hati-hati menyembunyikan dapur bagian dalam mereka. Dan semuanya baik-baik saja asalkan kode dieksekusi dalam satu utas.
Di lingkungan multi-utas, Anda bisa mengamati hal-hal menarik. Misalnya, menjalankan instruksi program tidak sesuai urutan yang tertulis dalam kode sumber. Setuju, tidak menyenangkan untuk menyadari bahwa mengeksekusi kode sumber baris demi baris hanyalah imajinasi kita.
Tetapi semua orang sudah menyadari, karena bagaimanapun Anda harus hidup dengannya. Dan programmer Java bahkan hidup dengan baik. Karena Java memiliki model memori - Java Memory Model (JMM), yang menyediakan aturan yang cukup sederhana untuk menulis kode multi-utas yang benar.
Dan aturan ini cukup untuk sebagian besar program. Jika Anda tidak mengetahuinya, tetapi menulis atau ingin menulis program multi-utas di Jawa, maka yang terbaik adalah membiasakan diri dengan
mereka sesegera mungkin. Dan jika Anda tahu, tetapi Anda tidak memiliki konteks yang cukup atau menarik untuk mengetahui dari mana kaki JMM tumbuh, maka artikel ini dapat membantu Anda.
Dan mengejar abstraksi
Menurut pendapat saya, ada kue, atau, lebih cocok, gunung es. JMM adalah puncak gunung es. Gunung es itu sendiri adalah teori pemrograman multi-threaded di bawah air. Di bawah gunung es adalah Neraka.

Gunung es adalah abstraksi, jika bocor, kita pasti akan melihat Neraka. Meskipun banyak hal menarik terjadi di sana, di artikel ulasan kami tidak akan membahasnya.
Dalam artikel ini, saya lebih tertarik dengan topik berikut:
- Teori dan Terminologi
- Bagaimana teori pemrograman multithreaded tercermin dalam JMM
- Model Pemrograman yang Kompetitif
Teori pemrograman multi-utas memungkinkan Anda untuk keluar dari kerumitan prosesor dan kompiler modern, ini memungkinkan Anda untuk mensimulasikan pelaksanaan program multi-utas dan mempelajari sifat-sifatnya. Roman Elizarov membuat
laporan yang sangat bagus, yang tujuannya adalah untuk memberikan dasar teoretis untuk memahami JMM. Saya merekomendasikan laporan ini kepada semua orang yang tertarik dengan topik ini.
Mengapa penting untuk mengetahui teorinya? Menurut pendapat saya, saya hanya berharap untuk saya, beberapa programmer berpendapat bahwa JMM adalah komplikasi dari bahasa dan menambal beberapa masalah platform dengan multithreading. Teori ini menunjukkan bahwa Java tidak menyulitkan, tetapi disederhanakan dan membuat pemrograman multithreaded sangat kompleks.
Persaingan dan Konkurensi
Pertama, mari kita lihat terminologinya. Sayangnya, tidak ada konsensus dalam terminologi - ketika mempelajari materi yang berbeda, Anda mungkin menemukan definisi yang berbeda tentang kompetisi dan konkurensi.
Masalahnya adalah bahwa bahkan jika kita sampai pada dasar kebenaran dan menemukan definisi yang tepat dari konsep-konsep ini, masih tidak sebanding dengan harapan bahwa setiap orang akan memiliki makna yang sama dengan konsep-konsep ini. Anda tidak
akan menemukan ujungnya di sini.
Roman Elizarov, dalam sebuah laporan, teori pemrograman paralel untuk praktisi menyarankan bahwa kadang-kadang konsep-konsep ini dicampur. Pemrograman paralel kadang-kadang dibedakan sebagai konsep umum yang dibagi menjadi kompetitif dan didistribusikan.
Tampak bagi saya bahwa dalam konteks JMM Anda masih perlu memisahkan persaingan dan paralelisme, atau lebih tepatnya memahami bahwa ada dua paradigma yang berbeda, tidak peduli bagaimana mereka disebut.
Sering dikutip oleh Rob Pike, yang membedakan antara konsep sebagai berikut:
- Persaingan adalah cara untuk secara bersamaan menyelesaikan banyak masalah
- Concurrency adalah cara untuk melakukan berbagai bagian dari satu tugas.
Pendapat Rob Pike bukanlah standar, tetapi menurut pendapat saya, mudah untuk membangunnya untuk mempelajari lebih lanjut masalah ini. Baca lebih lanjut tentang perbedaannya di
sini .
Kemungkinan besar, pemahaman yang lebih besar tentang masalah ini akan muncul jika kami menyoroti fitur utama dari program yang kompetitif dan paralel. Ada banyak tanda, pertimbangkan yang paling signifikan.
Tanda-tanda kompetisi.
- Adanya beberapa aliran kontrol (mis. Thread di Jawa, coroutine di Kotlin), jika hanya ada satu aliran kontrol, maka tidak ada eksekusi kompetitif
- Hasil non-deterministik. Hasilnya tergantung pada peristiwa acak, implementasi, dan bagaimana sinkronisasi dilakukan. Sekalipun setiap aliran sepenuhnya deterministik, hasil akhirnya akan menjadi non-deterministik
Program paralel akan memiliki serangkaian fitur yang berbeda.
- Opsional memiliki banyak aliran kontrol
- Ini dapat menyebabkan hasil deterministik, misalnya, hasil dari mengalikan setiap elemen array dengan angka tidak akan berubah jika Anda mengalikannya dalam bagian-bagian secara paralel
Anehnya, eksekusi paralel dimungkinkan pada aliran kontrol tunggal, dan bahkan pada arsitektur inti tunggal. Faktanya adalah bahwa paralelisme di tingkat tugas (atau aliran kontrol) yang kita terbiasa bukanlah satu-satunya cara untuk melakukan perhitungan secara paralel.
Konkurensi dimungkinkan pada tingkat:
- bit (misalnya, pada mesin 32-bit, penambahan terjadi dalam satu tindakan, memproses semua 4 byte dari nomor 32-bit secara paralel)
- instruksi (pada satu inti, dalam satu utas, prosesor dapat menjalankan instruksi secara paralel, terlepas dari kenyataan bahwa kode tersebut berurutan)
- data (ada arsitektur dengan pemrosesan data paralel (Single Instruction Multiple Data) yang dapat mengeksekusi satu instruksi pada set data yang besar)
- tugas (menyiratkan adanya beberapa prosesor atau inti)
Konkurensi pada level instruksi adalah salah satu contoh optimisasi yang terjadi dengan eksekusi kode yang disembunyikan dari programmer.
Dijamin bahwa kode yang dioptimalkan akan setara dengan yang asli dalam kerangka satu utas, karena tidak mungkin untuk menulis kode yang memadai dan dapat diprediksi jika tidak melakukan apa yang diinginkan oleh programmer.
Tidak semua yang berjalan secara paralel penting bagi JMM. Eksekusi bersamaan pada tingkat instruksi dalam satu utas tidak dipertimbangkan dalam JMM.
Terminologi ini sangat goyah, dengan presentasi oleh Roman Elizarov yang disebut "Teori pemrograman
paralel untuk praktisi," meskipun ada lebih banyak tentang pemrograman kompetitif, jika Anda tetap berpegang pada hal di atas.
Dalam konteks JMM, dalam artikel saya akan tetap berpegang pada istilah kompetisi, karena kompetisi sering tentang keadaan umum. Tetapi di sini Anda perlu berhati-hati untuk tidak berpegang pada persyaratan, tetapi pahamilah bahwa ada paradigma yang berbeda.
Model dengan kondisi umum: "rotasi operasi" dan "terjadi sebelumnya"
Dalam
artikelnya, Maurice Herlichi (penulis pemrograman The Art Of Multiprocessor) menulis bahwa sistem kompetitif berisi kumpulan proses sekuensial (dalam karya teoretis artinya sama dengan utas) yang berkomunikasi melalui memori bersama.
Model keadaan umum mencakup perhitungan dengan olahpesan, di mana keadaan bersama adalah antrian pesan dan perhitungan dengan memori bersama, di mana kondisi umum adalah struktur dalam memori.
Setiap perhitungan dapat disimulasikan.
Model ini didasarkan pada mesin negara yang terbatas. Model ini memfokuskan secara eksklusif pada status bersama dan data lokal dari masing-masing aliran diabaikan sepenuhnya. Setiap tindakan aliran di atas status bersama adalah fungsi transisi ke kondisi baru.
Jadi misalnya, jika 4 utas menulis data ke variabel bersama, maka akan ada 4 fungsi untuk beralih ke status baru. Manakah dari fungsi-fungsi ini yang akan diterapkan tergantung pada kronologi peristiwa dalam sistem.
Perhitungan lewat pesan dimodelkan dengan cara yang sama, hanya fungsi keadaan dan transisi tergantung pada pengiriman atau penerimaan pesan.
Jika model tampak rumit bagi Anda, maka dalam contoh ini kami akan memperbaikinya. Ini sangat sederhana dan intuitif. Sedemikian rupa sehingga tanpa mengetahui tentang keberadaan model ini, kebanyakan orang masih akan menganalisis program seperti yang disarankan oleh model tersebut.
Model seperti ini disebut model
kinerja melalui pergantian operasi (nama itu terdengar dalam laporan oleh Roman Elizarov).
Ke intuisi dan kealamian, Anda dapat dengan aman menuliskan keunggulan model. Anda dapat pergi ke alam liar dengan
konsistensi kata kunci
Sequential dan
karya Leslie Lamport.
Namun, ada klarifikasi penting tentang model ini. Model memiliki batasan bahwa semua tindakan pada keadaan bersama harus instan dan pada saat yang sama, tindakan tidak dapat terjadi secara bersamaan. Mereka mengatakan bahwa sistem seperti itu memiliki
urutan linier - semua tindakan dalam sistem dipesan.
Dalam praktiknya, ini tidak terjadi. Operasi tidak terjadi secara instan, tetapi dilakukan dalam suatu interval, pada sistem multi-core, interval ini dapat berpotongan. Tentu saja, ini tidak berarti bahwa model tersebut tidak berguna dalam praktiknya, Anda hanya perlu membuat kondisi tertentu untuk penggunaannya.
Sementara itu, pertimbangkan
model lain
- "terjadi sebelumnya," yang tidak berfokus pada negara, tetapi pada set sel memori baca dan tulis selama eksekusi (sejarah) dan hubungan mereka.
Model mengatakan bahwa peristiwa dalam aliran yang berbeda tidak instan dan atom, tetapi secara paralel, dan tidak mungkin untuk membangun keteraturan di antara mereka. Peristiwa (menulis dan membaca data bersama) di aliran pada arsitektur multiprosesor atau multi-core benar-benar terjadi secara paralel. Tidak ada konsep waktu global dalam sistem, kami tidak dapat memahami kapan satu operasi berakhir dan yang lainnya dimulai.
Dalam praktiknya, ini berarti bahwa kita dapat menulis nilai ke variabel di satu utas dan melakukannya, katakan di pagi hari, dan baca nilai dari variabel ini di utas lain di malam hari, dan kita tidak bisa mengatakan bahwa kita akan membaca nilai yang ditulis di pagi hari pasti. Secara teori, operasi ini dilakukan secara paralel dan tidak jelas kapan satu akan berakhir dan operasi lain akan dimulai.
Sulit membayangkan bagaimana ternyata operasi baca-tulis sederhana yang dilakukan pada waktu yang berbeda dalam satu hari terjadi secara bersamaan. Tetapi jika Anda memikirkannya, itu tidak masalah bagi kami ketika peristiwa menulis dan membaca terjadi, jika kami tidak dapat menjamin bahwa kami akan melihat hasil rekaman.
Dan kita benar-benar tidak dapat melihat hasil rekaman, mis. ke dalam variabel yang nilainya
0 dalam aliran
P, kita menulis
1 , dan dalam aliran
Q kita membaca variabel ini. Tidak peduli berapa banyak waktu fisik yang berlalu setelah perekaman, kami masih dapat membaca
0 .
Beginilah cara komputer bekerja dan modelnya mencerminkan hal ini.Model ini sepenuhnya abstrak dan membutuhkan visualisasi yang nyaman untuk pekerjaan yang nyaman. Untuk visualisasi dan hanya untuk itu, model dengan waktu global digunakan, dengan pemesanan yang dalam membuktikan sifat-sifat program, waktu global tidak digunakan. Dalam visualisasi, setiap peristiwa direpresentasikan sebagai interval dengan awal dan akhir.
Acara berlangsung secara paralel, seperti yang kami ketahui. Tetapi tetap saja, sistem memiliki
urutan parsial , karena ada pasangan peristiwa khusus yang memiliki urutan, dalam hal ini mereka mengatakan bahwa peristiwa ini memiliki hubungan "terjadi sebelumnya". Jika Anda pertama kali mendengar tentang hubungan "terjadi sebelum", maka mungkin mengetahui fakta bahwa hubungan semacam ini mengatur acara tidak akan banyak membantu Anda.
Mencoba menganalisis program Java
Kami menganggap beberapa minimum teoretis, mari kita lanjutkan dan pertimbangkan program multi-utas dalam bahasa tertentu - Jawa, dari dua utas dengan status umum yang bisa berubah-ubah.
Contoh klasik.
private static int x = 0, y = 0; private static int a = 0, b = 0; synchronized (this) { a = 0; b = 0; x = 0; y = 0; } Thread p = new Thread(() -> { a = 1; x = b; }); Thread q = new Thread(() -> { b = 1; y = a; }); p.start(); q.start(); p.join(); q.join(); System.out.println("x=" + x + ", y=" + y);
Kita perlu mensimulasikan pelaksanaan program ini dan mendapatkan semua hasil yang mungkin - nilai-nilai variabel x dan y. Akan ada beberapa hasil, seperti yang kita ingat dari teori, program seperti itu adalah non-deterministik.
Bagaimana kita memodelkan? Saya segera ingin menggunakan model operasi interleaving. Tetapi model “terjadi sebelumnya” memberi tahu kita bahwa peristiwa dalam satu utas sejajar dengan peristiwa dari utas lain. Oleh karena itu, model operasi bolak-balik di sini tidak sesuai jika tidak ada hubungan "terjadi sebelumnya" antara operasi.
Hasil dari eksekusi setiap utas selalu ditentukan, karena peristiwa dalam satu utas selalu dipesan, pertimbangkan bahwa mereka menerima hubungan "yang terjadi sebelumnya" secara gratis. Tetapi bagaimana peristiwa dalam aliran yang berbeda bisa mendapatkan hubungan "terjadi sebelum" tidak sepenuhnya jelas. Tentu saja, hubungan ini diformalkan dalam model, seluruh model ditulis dalam bahasa matematika. Tetapi apa yang harus dilakukan dengan ini dalam praktiknya, dalam bahasa tertentu, tidak segera dipahami.
Apa saja pilihannya?
Abaikan kendala dan simulasikan interleaving. Anda dapat mencobanya, mungkin tidak ada hal buruk yang akan terjadi.
Untuk memahami hasil seperti apa yang bisa diperoleh, kami cukup menyebutkan semua varian eksekusi yang mungkin.
Semua eksekusi program yang mungkin dapat direpresentasikan sebagai mesin keadaan terbatas.
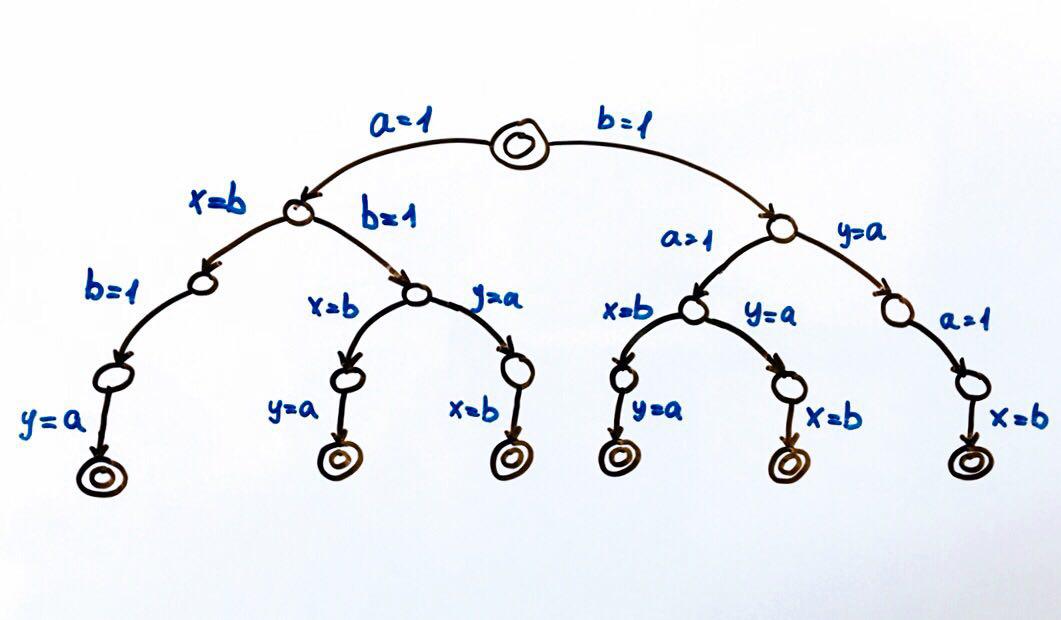
Setiap lingkaran adalah keadaan sistem, dalam kasus kami variabel
a, b, x, y . Fungsi transisi adalah tindakan pada keadaan yang menempatkan sistem dalam keadaan baru. Karena dua aliran dapat melakukan tindakan pada keadaan umum, akan ada dua transisi dari masing-masing negara. Lingkaran ganda adalah kondisi akhir dan awal sistem.
Secara total, 6 eksekusi berbeda dimungkinkan, yang menghasilkan pasangan nilai x, y:
(1, 1), (1, 0), (0, 1)
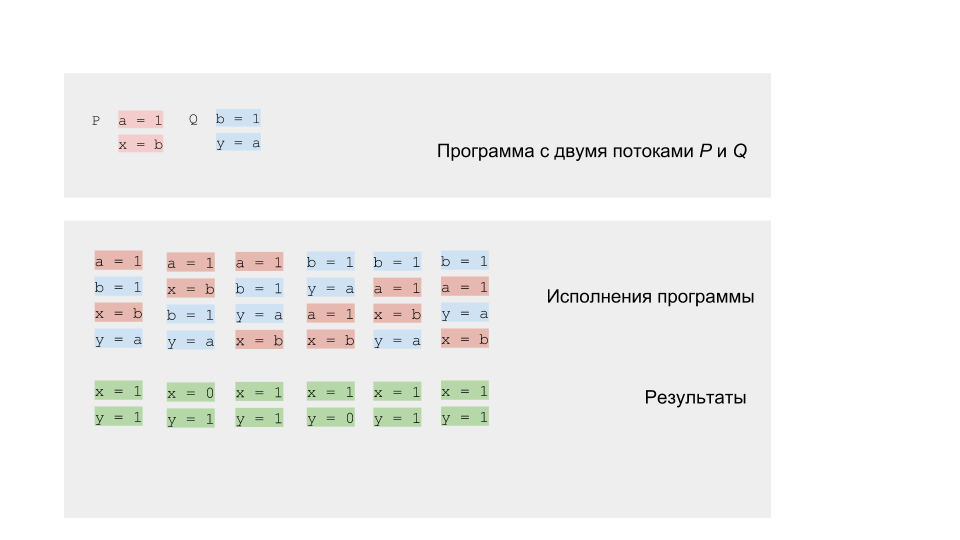
Kita dapat menjalankan program dan memeriksa hasilnya. Sebagaimana layaknya program kompetitif, ia akan memiliki hasil yang tidak deterministik.
Untuk menguji program kompetitif, lebih baik menggunakan alat khusus (
alat ,
laporan ).
Tetapi Anda dapat mencoba menjalankan program beberapa juta kali, atau bahkan lebih baik, menulis siklus yang akan melakukan ini untuk kita.
Jika kita menjalankan kode pada arsitektur single-core atau prosesor tunggal, maka kita harus mendapatkan hasil dari set yang kita harapkan. Model rotasi akan bekerja dengan baik. Pada arsitektur multi-core, misalnya x86, kita mungkin akan terkejut dengan hasilnya - kita bisa mendapatkan hasilnya (0,0), yang tidak bisa sesuai dengan pemodelan kita.
Penjelasan untuk ini dapat ditemukan di Internet dengan kata kunci -
pemesanan ulang . Sekarang penting untuk memahami bahwa
pemodelan interleaving benar-benar tidak cocok dalam situasi di mana kita tidak dapat menentukan urutan akses ke keadaan bersama .
Teori Pemrograman Kompetitif dan JMM
Saatnya untuk melihat lebih dekat pada hubungan "terjadi sebelumnya" dan bagaimana ia berteman dengan JMM. Definisi asli dari hubungan "terjadi sebelumnya" dapat ditemukan dalam Waktu, Jam, dan Pemesanan Acara dalam Sistem Terdistribusi.
Model memori bahasa membantu dalam penulisan kode kompetitif, karena menentukan operasi mana yang terkait dengan "terjadi sebelumnya". Daftar operasi tersebut disajikan dalam
spesifikasi di bagian Happens-before Order. Bahkan, bagian ini menjawab pertanyaan - dalam kondisi apa kita akan melihat hasil rekaman di aliran lain.
Ada berbagai pesanan di JMM. Alexei Shipilev dengan penuh semangat berbicara tentang peraturan di salah satu
laporannya .
Dalam model waktu global, semua operasi di utas yang sama dalam urutan. Misalnya, peristiwa menulis dan membaca variabel dapat direpresentasikan sebagai dua interval, maka model menjamin bahwa interval ini tidak akan pernah berpotongan dalam kerangka aliran tunggal. Di JMM, pesanan ini disebut Program Order (
PO ).
PO mengikat tindakan dalam utas tunggal dan tidak mengatakan apa pun tentang urutan eksekusi, ia hanya berbicara tentang urutan dalam kode sumber. Ini cukup untuk menjamin
determinisme untuk setiap aliran secara terpisah .
PO dapat dianggap sebagai data mentah.
PO selalu mudah diatur dalam suatu program - semua operasi (urutan linier) dalam kode sumber dalam satu aliran akan memiliki
PO .
Dalam contoh kita, kita mendapatkan sesuatu seperti berikut:
P: a = 1 PO x = b - menulis ke a dan membaca b memiliki urutan PO
Q: b = 1 PO y = a - tulis ke b dan baca perintah PO has
Saya memata-matai bentuk tulisan ini dengan
(a, 1) PO r (b): 0. Saya benar-benar berharap tidak ada yang mematenkannya untuk laporan. Namun, spesifikasinya memiliki bentuk serupa.
Tetapi setiap utas secara individual tidak terlalu menarik bagi kami, karena utas memiliki keadaan yang sama, kami lebih tertarik pada interaksi arus. Yang kami inginkan adalah memastikan bahwa kami akan melihat catatan variabel di utas lainnya.
Biarkan saya mengingatkan Anda bahwa ini tidak berhasil bagi kami, karena operasi penulisan dan membaca variabel dalam aliran yang berbeda tidak secara instan (ini adalah segmen yang berpotongan), masing-masing, tidak mungkin untuk menguraikan di mana awal dan akhir operasi.
Idenya sederhana - saat ini ketika kita membaca variabel a di aliran
Q , catatan variabel yang sama di aliran
P mungkin belum berakhir. Dan tidak peduli berapa banyak waktu fisik yang dibagikan oleh peristiwa ini - nanodetik atau beberapa jam.
Untuk memesan acara, kita membutuhkan hubungan "terjadi sebelum". JMM mendefinisikan hubungan ini. Spesifikasi memperbaiki urutan dalam satu utas:
Jika operasi x dan y berada di utas yang sama dan di PO x pertama kali terjadi, dan kemudian y, maka x terjadi sebelum y.
Ke depan, kita dapat mengatakan bahwa kita dapat mengganti semua
PO dengan Happens-before (
HB ):
P: w(a, 1) HB r(b) Q: w(b, 1) HB r(a)
Tetapi sekali lagi kita kembali dalam kerangka satu aliran.
HB dimungkinkan antara operasi yang terjadi di utas yang berbeda, untuk menangani kasus ini kami akan berkenalan dengan pesanan lain.
Perintah Sinkronisasi (
SO ) - menautkan Tindakan Sinkronisasi (
SA ), daftar lengkap
SA diberikan dalam spesifikasi, di bagian 17.4.2. Tindakan Inilah beberapa di antaranya:
- Membaca variabel yang tidak stabil
- Menulis variabel yang tidak stabil
- Kunci monitor
- Buka kunci monitor
SO menarik bagi kami, karena memiliki properti yang semua bacaan dalam urutan
SO melihat entri terakhir di
SO . Dan saya mengingatkan Anda, kami hanya mencapai ini.
Di tempat ini, saya akan mengulangi apa yang kita perjuangkan. Kami memiliki program multithreaded, kami ingin mensimulasikan semua eksekusi yang mungkin dan mendapatkan semua hasil yang bisa diberikan. Ada model yang memungkinkan ini dilakukan dengan cukup sederhana. Tetapi mereka mengharuskan semua tindakan pada negara bersama dipesan.
Menurut properti
SO - jika semua tindakan dalam program ini adalah
SA maka kami akan mencapai tujuan kami. Yaitu kita dapat mengatur
pengubah volatil untuk semua variabel dan kita dapat menggunakan model pergantian. Jika intuisi memberi tahu Anda bahwa ini tidak sepadan, maka Anda benar sekali. Dengan tindakan ini, kami hanya melarang mengoptimalkan kode, tentu saja, kadang-kadang ini merupakan pilihan yang baik, tetapi ini jelas bukan kasus umum.
Pertimbangkan Synchronize-With Order (
SW ) lain - SO order untuk membuka kunci / kunci tertentu, menulis / membaca pasangan yang mudah menguap. Tidak masalah apa aliran tindakan ini, yang utama adalah bahwa mereka berada di monitor yang sama, variabel volatil.
SW menyediakan jembatan antara utas.
Dan sekarang kita sampai pada urutan yang paling menarik - Terjadi sebelum (
HB ).
HB adalah penutupan transitif dari persatuan
SW dan
PO .
PO memberikan urutan linier dalam aliran, dan
SW menyediakan jembatan antara aliran.
HB bersifat transitif, mis. jika
x HB y y HB z, x HB z
Spesifikasi memiliki daftar hubungan
HB , Anda dapat membiasakan diri dengan lebih detail, berikut adalah beberapa daftar:
Dalam satu utas, operasi apa pun terjadi sebelum operasi apa pun yang mengikutinya dalam kode sumber.
Keluar dari blok / metode yang disinkronkan terjadi sebelum memasukkan blok / metode yang disinkronkan pada monitor yang sama.
Menulis bidang
volatil terjadi sebelum membaca bidang
volatil yang sama.
Mari kita kembali ke contoh kita:
P: a = 1 PO x = b Q: b = 1 PO y = a
Mari kita kembali ke contoh kita dan mencoba menganalisis program, dengan mempertimbangkan pesanan.
Analisis program menggunakan JMM didasarkan pada mengedepankan hipotesis dan mengkonfirmasi atau membantahnya.
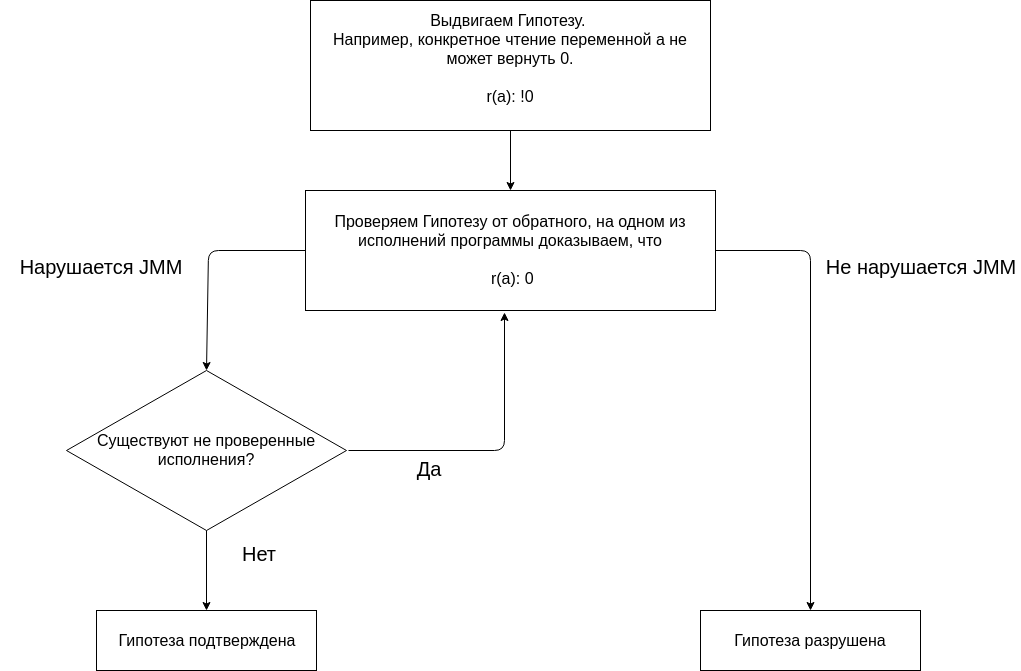
Kami memulai analisis kami dengan hipotesis bahwa tidak satu pun eksekusi program yang memberikan hasil (0, 0). Tidak adanya hasil (0, 0) pada semua eksekusi adalah properti yang seharusnya dari program.
Kami menguji hipotesis dengan membangun berbagai eksekusi.
Saya melihat nomenklatur di
sini (kadang-kadang muncul alih-alih
… kata
race dengan panah, Alexey sendiri menggunakan panah dan kata ras dalam laporannya, tetapi memperingatkan bahwa urutan ini bukan di JMM dan menggunakan notasi ini untuk kejelasan).
Kami melakukan reservasi kecil.
Karena semua tindakan pada variabel umum penting bagi kami, dan dalam contoh, variabel umum adalah
a, b, x, y . Kemudian, misalnya, operasi x = b harus dianggap sebagai r (b) dan w (x, b), dan
r(b) HB w(x,b) (berdasarkan
PO ). Tetapi karena variabel x tidak dibaca di mana pun di utas (membaca di cetak di akhir kode tidak menarik, karena setelah operasi gabungan di utas kita akan melihat nilai x), kita tidak dapat mempertimbangkan tindakan w (x, b).
Periksa kinerja pertama.
w(a, 1) HB r(b): 0 … w(b, 1) HB r(a): 0
Dalam aliran
Q, kita membaca variabel a, menulis ke variabel ini di aliran
P. Tidak ada urutan antara menulis dan membaca
(PO, SW, HB) .
Jika variabel ditulis dalam satu utas dan bacaan ada di utas lainnya dan tidak ada hubungan
HB antara operasi, maka mereka mengatakan bahwa variabel tersebut dibaca di bawah ras. Dan di bawah perlombaan menurut JMM kita dapat membaca nilai tercatat terakhir dalam
HB , atau nilai lainnya.
Performa seperti itu dimungkinkan. Eksekusi
tidak melanggar JMM . Saat membaca variabel a, Anda dapat melihat nilai apa pun, karena membaca terjadi di bawah perlombaan dan tidak ada jaminan bahwa kami akan melihat tindakan w (a, 1). Ini tidak berarti bahwa program bekerja dengan benar, itu hanya berarti bahwa hasil seperti itu diharapkan.
Tidak masuk akal untuk mempertimbangkan sisa eksekusi, karena
hipotesis sudah dihancurkan .
JMM mengatakan bahwa jika program tidak memiliki balapan data, maka semua eksekusi dapat dianggap sebagai berurutan. Mari kita singkirkan ras, untuk ini kita perlu merampingkan operasi baca dan tulis di utas yang berbeda. Penting untuk dipahami bahwa program multithreaded, berbeda dengan yang berurutan, memiliki beberapa eksekusi. Dan untuk mengatakan bahwa suatu program memiliki properti apa pun, diharuskan untuk membuktikan bahwa program tersebut memiliki properti ini bukan pada salah satu eksekusi, tetapi pada semua eksekusi.
Untuk membuktikan bahwa program ini non-balap, Anda harus melakukan ini untuk semua pertunjukan. Mari kita coba membuat
SA dan tandai variabel a dengan
pengubah volatil . Variabel
volatil akan diawali dengan v.
Kami mengajukan
hipotesis baru . Jika variabel a dibuat tidak
stabil , maka tidak ada eksekusi program yang akan memberikan hasil (0, 0).
w(va, 1) HB r(b): 0 … w(b, 1) HB r(va): 0
Eksekusi
tidak melanggar JMM . Membaca dan terjadi dalam lomba. Setiap ras menghancurkan transitivitas HB.
Kami mengajukan
hipotesis lain . Jika variabel b dibuat tidak
stabil , maka tidak ada eksekusi program yang akan memberikan hasil (0, 0).
w(a, 1) HB r(vb): 0 … w(vb, 1) HB r(a): 0
Eksekusi tidak melanggar JMM. Membaca terjadi di bawah perlombaan.
Mari kita
menguji hipotesis bahwa jika variabel a dan b
volatil , maka tidak ada eksekusi program yang akan memberikan hasil (0, 0).
Periksa kinerja pertama.
w(va, 1) SO r(vb): 0 SO w(vb, 1) SO r(va): 0
Karena semua tindakan dalam program
SA (khusus membaca atau menulis variabel
volatil ), kami mendapatkan urutan
SO lengkap antara semua tindakan. Ini berarti bahwa r (va) harus melihat w (va, 1).
Eksekusi ini
melanggar JMM .
Diperlukan untuk melanjutkan ke eksekusi berikutnya untuk mengkonfirmasi hipotesis. Tetapi karena akan ada
SO untuk eksekusi apa pun, Anda dapat menyimpang dari formalisme - jelas bahwa hasilnya (0, 0) melanggar JMM untuk eksekusi apa pun.
Untuk menggunakan model rotasi, Anda perlu menambahkan
volatile untuk variabel a dan b. Program seperti itu akan memberikan hasil (1,1), (1,0) atau (0,1).
Pada akhirnya, kita dapat mengatakan bahwa program yang sangat sederhana cukup mudah untuk dianalisis.
Tetapi program kompleks dengan sejumlah besar eksekusi dan data bersama sulit dianalisis, karena Anda perlu memeriksa semua eksekusi.
Model eksekusi kompetitif lainnya
Mengapa mempertimbangkan model pemrograman kompetitif lainnya?
Menggunakan utas dan sinkronisasi primitif dapat menyelesaikan semua masalah. Ini semua benar, tetapi masalahnya adalah bahwa kita memeriksa contoh dari selusin baris kode, di mana 4 baris kode melakukan pekerjaan yang bermanfaat.
Dan di sana kami menjumpai banyak pertanyaan, sampai pada titik bahwa tanpa spesifikasi kami bahkan tidak dapat dengan benar menghitung semua hasil yang mungkin. Utas dan sinkronisasi primitif adalah hal yang sangat sulit, penggunaannya tentu dibenarkan dalam beberapa kasus. Pada dasarnya, kasus-kasus ini terkait dengan kinerja.
Maaf, saya banyak merujuk ke Elizarov, tetapi apa yang bisa saya lakukan jika seseorang benar-benar memiliki pengalaman di bidang ini. Jadi, ia memiliki
laporan indah lainnya
, "Jutaan kutipan per detik di Jawa murni," di mana ia mengatakan bahwa keadaan abadi adalah baik, tetapi saya tidak akan menyalin jutaan kutipan saya ke setiap aliran, maaf. Tetapi tidak semua memiliki jutaan kutipan, banyak tentu saja memiliki tugas yang lebih sederhana. Apakah ada model pemrograman kompetitif yang membuat Anda melupakan JMM dan masih menulis kode yang aman dan kompetitif?
Jika Anda benar-benar tertarik dengan pertanyaan ini, saya sangat merekomendasikan buku Paul Butcher, “Seven Models of Competition in Seven Weeks. Kami mengungkapkan rahasia arus. " Sayangnya, tidak mungkin menemukan informasi yang cukup tentang pengarangnya, tetapi buku itu harus membuka mata Anda terhadap paradigma baru. Sayangnya, saya tidak memiliki pengalaman dengan banyak model kompetisi lain, jadi saya mendapat ulasan dari buku ini.
Menjawab pertanyaan di atas. Sejauh yang saya mengerti, ada model pemrograman kompetitif yang setidaknya dapat sangat mengurangi kebutuhan akan pengetahuan tentang nuansa JMM. Namun, jika ada keadaan dan aliran yang dapat berubah, maka jangan mengacaukan abstraksi atas mereka, masih akan ada tempat di mana aliran ini harus menyinkronkan akses ke negara. Pertanyaan lain adalah Anda mungkin tidak perlu menyinkronkan akses sendiri, misalnya kerangka kerja dapat menjawabnya. Tetapi seperti yang telah kami katakan, cepat atau lambat, abstraksi dapat terjadi.
Anda dapat mengecualikan status yang dapat berubah sama sekali. Dalam dunia pemrograman fungsional, ini adalah praktik normal. Jika tidak ada struktur yang bisa berubah, maka mungkin tidak akan ada masalah dengan memori bersama menurut definisi. Ada perwakilan bahasa fungsional di JVM, seperti Clojure. Clojure adalah bahasa fungsional hibrid, karena masih memungkinkan Anda untuk mengubah struktur data, tetapi menyediakan alat yang lebih efisien dan lebih aman untuk ini.
Bahasa fungsional adalah alat yang hebat untuk bekerja dengan kode kompetitif. Secara pribadi, saya tidak menggunakannya, karena bidang kegiatan saya adalah pengembangan seluler, dan di sana itu tidak umum. Meskipun pendekatan tertentu dapat diadopsi.
Cara lain untuk bekerja dengan data yang bisa berubah adalah untuk mencegah berbagi data. Aktor adalah model pemrograman seperti itu. Aktor menyederhanakan pemrograman dengan tidak mengizinkan akses simultan ke data. Ini dicapai oleh fakta bahwa fungsi yang melakukan pekerjaan pada satu saat dalam waktu dapat bekerja hanya dalam satu utas.
Namun, seorang aktor dapat mengubah keadaan internal. Mengingat bahwa pada saat berikutnya, aktor yang sama dapat dieksekusi di utas lain, ini bisa menjadi masalah. Masalahnya dapat diselesaikan dengan berbagai cara, dalam bahasa pemrograman seperti Erlang atau Elixir, di mana model aktor merupakan bagian integral dari bahasa, Anda dapat menggunakan rekursi untuk memanggil aktor dengan status baru.
Di Jawa, rekursi bisa terlalu mahal. Namun, di Jawa ada kerangka kerja untuk pekerjaan yang mudah dengan model ini, mungkin yang paling populer adalah Akka. Pengembang Akka telah mengurus semuanya, Anda dapat pergi ke bagian dokumentasi
Akka dan Java Memory Model dan membaca tentang dua kasus ketika akses ke keadaan bersama dapat terjadi dari utas yang berbeda. Tetapi yang lebih penting, dokumentasi mengatakan acara mana yang berhubungan dengan "terjadi sebelumnya." Yaitu ini berarti bahwa kita dapat mengubah keadaan aktor sebanyak yang kita suka, tetapi ketika kita menerima pesan berikutnya dan mungkin memprosesnya di utas lain, kita dijamin melihat semua perubahan yang dibuat di utas lain.
Mengapa model threading begitu populer?
Kami memeriksa dua model pemrograman kompetitif, bahkan ada lebih dari mereka yang membuat pemrograman kompetitif lebih mudah dan lebih aman.
Tetapi mengapa kemudian benang dan kunci masih begitu populer?
Saya pikir alasannya adalah kesederhanaan dari pendekatan, tentu saja, di satu sisi, mudah untuk membuat banyak kesalahan yang tidak terlihat dengan stream, menembak diri sendiri di kaki, dll. Tetapi di sisi lain
, tidak ada yang rumit dalam arus, terutama jika Anda tidak memikirkan konsekuensinya .
Pada satu titik waktu, kernel dapat menjalankan satu instruksi (sebenarnya tidak, concurrency ada di level instruksi, tetapi sekarang tidak masalah), tetapi karena multitasking, bahkan pada mesin single-core, beberapa program dapat dieksekusi secara bersamaan (tentu saja semu secara bersamaan).
Agar multitasking dapat berfungsi, Anda membutuhkan kompetisi. Seperti yang telah kita ketahui, persaingan tidak mungkin terjadi tanpa beberapa aliran manajemen.
Menurut Anda, berapa utas program yang berjalan pada prosesor ponsel quad-core harus secepat dan seresponif mungkin?
Mungkin ada beberapa lusin. Sekarang pertanyaannya adalah, mengapa kita membutuhkan begitu banyak utas untuk program yang berjalan pada perangkat keras yang memungkinkan Anda untuk mengeksekusi hanya 2-4 utas sekaligus?
Untuk mencoba menjawab pertanyaan ini, anggaplah hanya program kami yang berjalan di perangkat dan tidak ada yang lain. Bagaimana kita mengelola sumber daya yang disediakan untuk kita?
Anda dapat memberikan satu inti untuk antarmuka pengguna, sisanya dari kernel untuk tugas-tugas lain.
Jika salah satu utas diblokir, misalnya, utas dapat mengakses pengontrol memori dan menunggu jawaban, maka kita akan mendapatkan kernel yang diblokir.Teknologi apa yang ada untuk menyelesaikan masalah?Ada utas di Jawa, kita dapat membuat banyak utas, dan kemudian utas lain akan dapat melakukan operasi sementara beberapa utas diblokir. Dengan alat seperti utas, kita dapat menyederhanakan hidup kita.Pendekatan dengan utas tidak gratis, membuat utas biasanya membutuhkan waktu (ditentukan oleh kumpulan utas), memori dialokasikan untuknya, beralih di antara utas adalah operasi yang mahal. Tetapi relatif mudah diprogram dengan mereka, jadi ini adalah teknologi besar yang begitu banyak digunakan dalam bahasa umum, seperti Jawa.Java umumnya menyukai stream, tidak perlu membuat untuk setiap aksi stream, ada hal-hal tingkat yang lebih tinggi, seperti Pelaksana, yang memungkinkan Anda untuk bekerja dengan kumpulan dan menulis kode yang lebih skalabel dan fleksibel. Streaming sangat nyaman, Anda dapat membuat permintaan pemblokiran ke jaringan dan menulis hasil pemrosesan pada baris berikutnya. Bahkan jika kita menunggu hasilnya selama beberapa detik, kita masih dapat melakukan tugas-tugas lain, karena sistem operasi akan mengatur distribusi waktu prosesor antar thread.Streaming populer tidak hanya dalam pengembangan backend, dalam pengembangan seluler dianggap cukup normal untuk membuat puluhan streaming sehingga Anda dapat memblokir streaming selama beberapa detik, menunggu data diunduh melalui jaringan atau data dari soket.Bahasa seperti Erlang atau Clojure masih niche, dan karena itu model pemrograman kompetitif yang mereka gunakan tidak begitu populer. Namun, perkiraan untuk mereka adalah yang paling optimis.Kesimpulan
Jika Anda mengembangkan pada platform JVM, maka Anda harus menerima aturan permainan yang ditunjukkan oleh platform. Ini adalah satu-satunya cara untuk menulis kode multithread normal. Sangat diinginkan untuk memahami konteks dari segala sesuatu yang terjadi, sehingga akan lebih mudah untuk menerima aturan permainan. Bahkan lebih baik untuk melihat-lihat dan berkenalan dengan paradigma lain, meskipun Anda tidak bisa mendapatkan apa pun dari kapal selam, tetapi Anda dapat menemukan pendekatan dan alat baru.Bahan tambahan
Saya mencoba untuk menempatkan teks pada tautan artikel ke sumber dari mana saya mendapatkan informasi.Secara umum, materi JMM mudah ditemukan di Internet. Di sini saya akan memposting tautan ke beberapa materi tambahan yang terkait dengan JMM dan mungkin tidak langsung menarik perhatian saya.Membaca- Blog Alexey Shipilev - Saya tahu apa yang jelas, tapi itu dosa
- Blog Cheremin Ruslan - dia belum menulis secara aktif akhir-akhir ini, Anda perlu mencari entri lamanya di blog, percayalah itu sepadan - ada sumber
- Habr Gleb Smirnov - ada artikel bagus tentang multithreading dan model memori
- Blog Roman Elizarov ditinggalkan, tetapi penggalian arkeologis perlu dilakukan. Secara umum, Roman melakukan banyak hal untuk mendidik orang-orang dalam teori pemrograman multithreaded, mencarinya di media.
Masalah Podcast yang menurut saya sangat menarik. Mereka bukan tentang JMM, mereka tentang Neraka, yang terjadi di kelenjar. Tapi setelah mendengarkan mereka, saya ingin mencium pencipta JMM, yang telah melindungi kita dari semua ini.VideoSelain pidato dari orang-orang yang disebutkan di atas, perhatikan juga video akademiknya.