Artikel ini adalah terjemahan resmi dari pos asli . Terjemahan dibuat dengan bantuan orang-orang dari PVS-Studio. Terima kasih kawan!Apa yang mendorong saya untuk menulis artikel ini adalah sejumlah besar bahan analisis statis, yang akhir-akhir ini semakin banyak muncul. Pertama, ini adalah
blog PVS-Studio , yang secara aktif mempromosikan dirinya di Habr memposting ulasan kesalahan, ditemukan oleh alat mereka dalam proyek-proyek open source. PVS-Studio baru-baru ini mengimplementasikan
dukungan Java , dan, tentu saja, pengembang dari IntelliJ IDEA, yang penganalisa bawaannya mungkin yang paling canggih untuk Jawa saat ini,
tidak bisa menjauh .
Saat membaca ulasan ini, saya merasa bahwa kita sedang berbicara tentang ramuan ajaib: klik tombolnya, dan ini dia - daftar cacat tepat di depan mata Anda. Tampaknya seiring dengan semakin canggihnya analisis, semakin banyak bug akan ditemukan, dan produk, yang dipindai oleh robot ini, akan menjadi lebih baik dan lebih baik tanpa upaya dari pihak kami.
Yah, tapi tidak ada ramuan ajaib. Saya ingin berbicara tentang apa yang biasanya tidak diucapkan dalam tulisan seperti "di sini adalah hal-hal yang dapat ditemukan robot kami": apa yang tidak dapat dilakukan oleh penganalisa, apa bagian dan tempat mereka yang sebenarnya dalam proses pengiriman perangkat lunak, dan bagaimana menerapkan analisis dengan benar.
 Ratchet (sumber: Wikipedia ).
Ratchet (sumber: Wikipedia ).Apa Analisis Statis Tidak Akan Pernah Dapat Dilakukan
Apa analisis kode sumber dari sudut pandang praktis? Kami mengambil file sumber dan mendapatkan beberapa informasi tentang kualitas sistem dalam waktu singkat (jauh lebih pendek daripada tes dijalankan). Keterbatasan pokok dan matematis yang tidak dapat diatasi adalah bahwa dengan cara ini kita dapat menjawab hanya sebagian kecil pertanyaan tentang sistem yang dianalisis.
Contoh tugas yang paling terkenal, tidak dapat dipecahkan dengan menggunakan analisis statis adalah
masalah terputus -
putus : ini adalah teorema, yang membuktikan bahwa seseorang tidak dapat mengerjakan algoritma umum, yang akan menentukan apakah suatu program dengan kode sumber yang diberikan diulang selamanya atau diselesaikan untuk waktu terakhir. Perpanjangan teorema ini adalah teorema
Rice , yang menyatakan bahwa untuk properti non-sepele dari fungsi yang dapat dihitung, pertanyaan penentuan apakah program yang diberikan menghitung fungsi dengan properti ini adalah tugas algoritmik yang tidak dapat dipecahkan. Misalnya, Anda tidak dapat menulis analisa, yang menentukan berdasarkan kode sumber jika program yang dianalisis adalah implementasi dari algoritma tertentu, katakanlah, yang menghitung kuadrat angka integer.
Dengan demikian, fungsi analisis statis memiliki keterbatasan yang tidak dapat diatasi. Analis statis tidak akan pernah bisa mendeteksi semua kasus, misalnya, bug "null pointer exception" dalam bahasa tanpa
keamanan batal . Atau mendeteksi semua kemunculan "atribut tidak ditemukan" dalam bahasa yang diketik secara dinamis. Semua yang dapat dilakukan penganalisa statis paling sempurna adalah menangkap kasus-kasus tertentu. Jumlah mereka di antara semua kemungkinan masalah dengan kode sumber Anda, tanpa berlebihan, adalah setetes di lautan.
Analisis Statis Bukan Pencarian untuk Bug
Berikut ini adalah kesimpulan yang mengikuti dari di atas: analisis statis bukan cara untuk mengurangi jumlah cacat dalam suatu program. Saya berani mengklaim sebagai berikut: pertama kali diterapkan pada proyek Anda, ia akan menemukan tempat "lucu" dalam kode, tetapi kemungkinan besar tidak akan menemukan cacat yang memengaruhi kualitas program Anda.
Contoh cacat yang ditemukan secara otomatis oleh analis sangat mengesankan, tetapi kita tidak boleh lupa bahwa contoh-contoh ini ditemukan dengan memindai sekumpulan basis kode yang besar terhadap sekumpulan aturan yang relatif sederhana. Dengan cara yang sama peretas, yang memiliki kesempatan untuk mencoba beberapa kata sandi sederhana pada sejumlah besar akun, akhirnya menemukan akun dengan kata sandi sederhana.
Apakah ini berarti bahwa analisis statis tidak perlu dilakukan? Tentu tidak! Itu harus diterapkan untuk alasan yang sama Anda mungkin ingin memverifikasi setiap kata sandi baru dalam daftar berhenti kata sandi yang tidak aman.
Analisis Statis Lebih Daripada Mencari Bug
Bahkan, tugas-tugas yang dapat diselesaikan dengan analisis dalam praktiknya jauh lebih luas. Karena secara umum, analisis statis mewakili setiap pemeriksaan kode sumber, yang dilakukan sebelum menjalankannya. Berikut beberapa hal yang dapat Anda lakukan:
- Pemeriksaan gaya pengkodean dalam arti luas dari kata ini. Ini mencakup pemeriksaan pemformatan dan pencarian penggunaan tanda kurung kosong / tidak perlu, pengaturan nilai ambang batas untuk metrik seperti sejumlah baris / kompleksitas siklomatik suatu metode dan sebagainya - semua hal yang menyulitkan keterbacaan dan pemeliharaan kode. Di Jawa, Checkstyle mewakili alat dengan fungsi seperti itu, dalam Python -
flake8 . Program semacam itu biasanya disebut "linter". - Tidak hanya kode yang dapat dieksekusi yang dapat dianalisis. Sumber daya seperti file JSON, YAML, XML, dan
.properties dapat (dan harus!) Diperiksa secara otomatis untuk validitasnya. Alasannya adalah bahwa lebih baik untuk mengetahui fakta bahwa, katakanlah, struktur JSON rusak karena kutipan tidak berpasangan pada tahap awal pemeriksaan otomatis permintaan tarik daripada selama pelaksanaan tes atau dalam waktu berjalan, tidak itu Ada beberapa alat yang relevan, misalnya, YAMLlint , JSONLint dan xmllint . - Kompilasi (atau parsing untuk bahasa pemrograman dinamis) juga merupakan semacam analisis statis. Biasanya, kompiler dapat mengeluarkan peringatan yang memberi sinyal tentang masalah dengan kualitas kode sumber, dan mereka tidak boleh diabaikan.
- Terkadang kompilasi diterapkan tidak hanya pada kode yang dapat dieksekusi. Misalnya, jika Anda memiliki dokumentasi dalam format AsciiDoctor , maka dalam proses kompilasi ke dalam HTML / PDF, AsciiDoctor ( plugin Maven ) dapat mengeluarkan peringatan, misalnya, pada tautan internal yang terputus. Ini adalah alasan penting untuk tidak menerima permintaan penarikan dengan perubahan dokumentasi.
- Pemeriksaan ejaan juga semacam analisis statis. Utilitas aspell mampu memeriksa ejaan tidak hanya dalam dokumentasi, tetapi juga dalam kode sumber program (komentar dan literal) dalam berbagai bahasa pemrograman termasuk C / C ++, Java dan Python. Kesalahan pengejaan di antarmuka pengguna atau dokumentasi juga cacat!
- Tes konfigurasi sebenarnya mewakili bentuk analisis statis, karena mereka tidak mengeksekusi kode sumber selama proses pelaksanaannya, meskipun tes konfigurasi dijalankan sebagai tes unit
pytest .
Seperti yang bisa kita lihat, pencarian bug memiliki peran paling tidak penting dalam daftar ini dan semua yang lain tersedia saat menggunakan alat open source gratis.
Manakah dari jenis analisis statis ini yang harus digunakan dalam proyek Anda? Tentu, semakin banyak semakin baik! Yang penting di sini adalah implementasi yang tepat, yang akan dibahas lebih lanjut.
Jalur Pengiriman Sebagai Filter Multistage dan Analisis Statis Sebagai Tahap Pertama
Pipa dengan aliran perubahan (mulai dari perubahan kode sumber hingga pengiriman dalam produksi) adalah metafora klasik integrasi berkelanjutan. Urutan standar tahapan pipa ini terlihat sebagai berikut:
- analisis statis
- kompilasi
- tes unit
- tes integrasi
- Tes UI
- verifikasi manual
Perubahan yang ditolak pada tahap ke-N dari pipeline tidak diteruskan pada tahap N +1.
Kenapa begitu dan tidak sebaliknya? Di bagian jalur pipa, yang berkaitan dengan pengujian, penguji mengenali piramida uji yang terkenal:
 Tes piramida. Sumber: artikel oleh Martin Fowler.
Tes piramida. Sumber: artikel oleh Martin Fowler.Di bagian bawah piramida ini ada tes yang lebih mudah untuk ditulis, yang dieksekusi lebih cepat dan tidak cenderung menghasilkan positif palsu. Oleh karena itu, harus ada lebih banyak dari mereka, mereka harus mencakup sebagian besar kode dan harus dieksekusi terlebih dahulu. Di puncak piramida situasinya sangat berlawanan, sehingga jumlah tes integrasi dan UI harus dikurangi seminimal mungkin. Orang-orang dalam rantai ini adalah sumber daya yang paling mahal, lambat, dan tidak dapat diandalkan, sehingga mereka berada di bagian paling akhir dan melakukan pekerjaan hanya jika langkah sebelumnya tidak mendeteksi adanya cacat. Di bagian yang tidak terkait dengan pengujian, pipa dibangun dengan prinsip yang sama!
Saya ingin menyarankan analogi dalam bentuk sistem penyaringan air bertingkat. Air kotor (perubahan dengan cacat) disediakan dalam input, dan sebagai output kita perlu mendapatkan air bersih, yang tidak akan mengandung semua kontaminasi yang tidak diinginkan.
 Filter multi-tahap. Sumber: Wikimedia Commons
Filter multi-tahap. Sumber: Wikimedia CommonsSeperti yang Anda ketahui, filter pemurnian dirancang sedemikian rupa sehingga setiap tahap selanjutnya mampu menghilangkan partikel kontaminan berukuran lebih kecil. Tahap input pemurnian kasar memiliki throughput lebih besar dan biaya lebih rendah. Dalam analogi kami, itu berarti bahwa gerbang kualitas input memiliki kinerja yang lebih besar, membutuhkan lebih sedikit upaya untuk meluncurkan dan memiliki lebih sedikit biaya operasi. Peran analisis statis, yang (seperti yang sekarang kita pahami) mampu menyingkirkan hanya cacat yang paling serius adalah peran sump filter sebagai tahap pertama dari pembersih multi-tahap.
Analisis statis tidak meningkatkan kualitas produk akhir dengan sendirinya, sama seperti "bah" tidak membuat air minum. Namun dalam hubungannya dengan elemen pipa lainnya, kepentingannya jelas. Meskipun dalam filter multistage, tahap output berpotensi menghapus semua yang dapat input - kami sadar akan konsekuensi yang akan terjadi ketika mencoba bertahan hanya dengan tahap pemurnian halus, tanpa tahap input.
Tujuan dari "bah" adalah untuk membongkar tahap selanjutnya dari penangkapan cacat yang sangat kasar. Misalnya, seseorang yang melakukan tinjauan kode tidak boleh terganggu oleh kode yang salah diformat dan pelanggaran standar kode (seperti tanda kurung yang berlebihan atau bercabang yang bersarang terlalu dalam). Bug seperti NPE harus ditangkap oleh unit test, tetapi jika sebelum itu penganalisa menunjukkan bahwa bug akan muncul tak terhindarkan - ini akan secara signifikan mempercepat perbaikannya.
Saya kira sekarang sudah jelas mengapa analisis statis tidak meningkatkan kualitas produk ketika diterapkan sesekali, dan harus diterapkan terus menerus untuk menyaring perubahan dengan cacat serius. Pertanyaan apakah aplikasi penganalisis statis meningkatkan kualitas produk Anda kira-kira setara dengan pertanyaan "jika kita mengambil air dari kolam yang kotor, apakah kualitas minumnya akan meningkat ketika kita melewati saringan?"
Pengantar dalam Proyek Warisan
Masalah praktis penting: bagaimana menerapkan analisis statis dalam proses integrasi berkelanjutan, sebagai "gerbang kualitas"? Dalam hal tes otomatis semuanya jelas: ada serangkaian tes, kegagalan salah satunya adalah alasan yang cukup untuk percaya bahwa build belum melewati gerbang kualitas. Upaya untuk mengatur gerbang dengan cara yang sama dengan hasil analisis statis gagal: ada terlalu banyak peringatan analisis pada kode warisan, Anda tidak ingin mengabaikan semuanya, di sisi lain tidak mungkin untuk menghentikan pengiriman produk hanya karena ada peringatan penganalisa di dalamnya.
Untuk setiap proyek, penganalisa mengeluarkan sejumlah besar peringatan yang diterapkan pada saat pertama. Mayoritas peringatan tidak ada hubungannya dengan berfungsinya produk. Tidak mungkin untuk memperbaiki mereka semua dan banyak dari mereka tidak harus diperbaiki sama sekali. Pada akhirnya, kita tahu bahwa produk kita benar-benar berfungsi bahkan sebelum diperkenalkannya analisis statis!
Akibatnya, banyak pengembang membatasi diri dengan penggunaan analisis statis sesekali atau menggunakannya hanya dalam mode informatif yang melibatkan mendapatkan laporan analisis ketika membangun proyek. Ini setara dengan tidak adanya analisis, karena jika kita sudah memiliki banyak peringatan, kemunculan yang lain (betapapun seriusnya) tetap tidak diperhatikan ketika mengubah kode.
Berikut adalah cara yang dikenal untuk pengenalan gerbang berkualitas:
- Menetapkan batas jumlah total peringatan atau jumlah peringatan, dibagi dengan jumlah baris kode. Ini bekerja dengan buruk, karena gerbang seperti itu memungkinkan perubahan dengan cacat baru sampai batas mereka terlampaui.
- Menandai semua peringatan lama dalam kode sebagai diabaikan pada saat tertentu dan membangun kegagalan saat peringatan baru muncul. Fungsionalitas tersebut dapat disediakan oleh PVS-Studio dan beberapa alat lain, misalnya, Codacy. Saya belum pernah bekerja dengan PVS-Studio. Adapun pengalaman saya dengan Codacy, masalah utama mereka adalah bahwa perbedaan kesalahan lama dan baru adalah algoritma yang rumit dan tidak selalu bekerja, terutama jika file berubah secara signifikan atau diganti namanya. Sepengetahuan saya, Codacy bisa mengabaikan peringatan baru dalam permintaan tarikan dan pada saat yang sama menghalangi permintaan tarikan karena peringatan, tidak terkait dengan perubahan dalam kode PR ini.
- Menurut pendapat saya, solusi paling efektif adalah metode "ratcheting" yang dijelaskan dalam buku " Pengiriman Berkelanjutan ". Gagasan dasarnya adalah bahwa jumlah peringatan analisis statis adalah properti dari setiap rilis dan hanya perubahan yang diizinkan, yang tidak menambah jumlah total peringatan.
Ratchet
Ini bekerja dengan cara berikut:
- Pada fase awal, entri tentang sejumlah peringatan yang ditemukan oleh penganalisa kode ditambahkan dalam metadata rilis. Dengan demikian, ketika membangun cabang utama tidak hanya "rilis 7.0.2" ditulis di manajer repositori Anda, tetapi "rilis 7.0.2, yang berisi 100500 Checkstyle-peringatan". Jika Anda menggunakan manajer repositori tingkat lanjut (seperti Artifactory), mudah menyimpan metadata tersebut tentang rilis Anda.
- Saat membangun, setiap permintaan tarik membandingkan jumlah peringatan yang dihasilkan dengan jumlah mereka dalam rilis saat ini. Jika seorang PR mengarah ke pertumbuhan angka ini, kode tidak melewati gerbang kualitas pada analisis statis. Jika jumlah peringatan dikurangi atau tidak diubah - maka itu berlalu.
- Selama rilis berikutnya nomor yang dihitung ulang akan ditulis dalam metadata lagi.
Jadi perlahan tapi pasti, jumlah peringatan akan menjadi nol. Tentu saja, sistem bisa dibodohi dengan memperkenalkan peringatan baru dan mengoreksi kesalahan orang lain. Ini normal, karena dalam jangka panjang memberikan hasil: peringatan diperbaiki, biasanya tidak satu per satu, tetapi oleh kelompok-kelompok dari jenis tertentu, dan semua peringatan yang mudah diselesaikan diselesaikan dengan cukup cepat.
Grafik ini menunjukkan jumlah total peringatan Checkstyle selama enam bulan dari "ratchet" pada
salah satu proyek OpenSource kami . Jumlah peringatan telah berkurang secara signifikan, dan itu terjadi secara alami, sejalan dengan pengembangan produk!
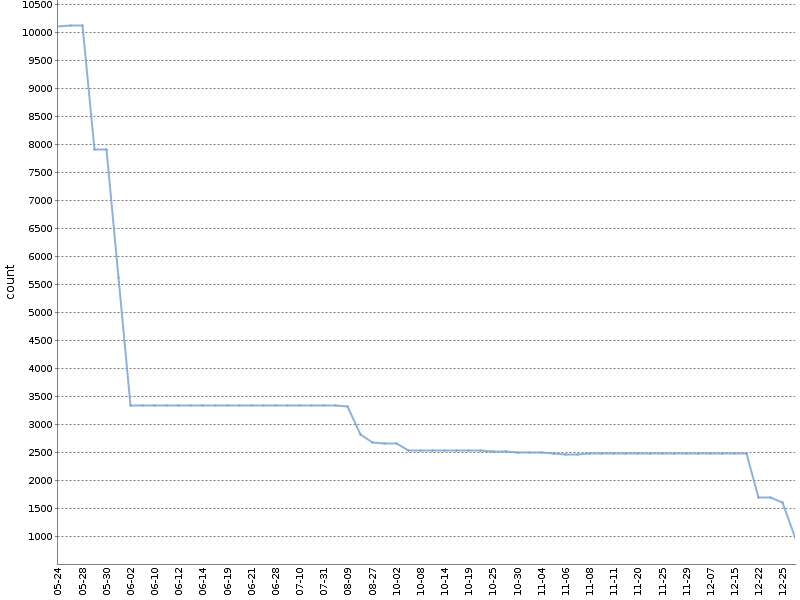
Saya menerapkan versi modifikasi dari metode ini. Saya menghitung peringatan secara terpisah untuk berbagai modul proyek dan alat analisis. File YAML dengan metadata tentang build, yang dibentuk untuk melakukannya, tampak sebagai berikut:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0
Dalam sistem CI canggih "ratchet" dapat diimplementasikan untuk alat analisis statis apa pun, tanpa bergantung pada plugin dan alat pihak ketiga. Setiap analis mengeluarkan laporannya dalam bentuk teks atau XML sederhana, yang akan dengan mudah dianalisis. Satu-satunya hal yang harus dilakukan setelahnya, adalah menulis logika yang diperlukan dalam sebuah skrip-CI. Anda dapat mengintip dan melihat di
sini atau di
sini bagaimana penerapannya dalam proyek sumber kami berdasarkan Jenkins dan Artifactory. Kedua contoh bergantung pada pustaka
ratchetlib : metode
countWarnings() dengan cara yang biasa menghitung tag xml dalam file yang dihasilkan oleh Checkstyle dan Spotbugs, dan
compareWarningMaps() mengimplementasikan ratchet yang sangat, melempar kesalahan dalam kasus, jika jumlah peringatan di salah satu kategori meningkat.
Cara yang menarik untuk penerapan "ratchet" dimungkinkan untuk menganalisis ejaan komentar, literal teks, dan dokumentasi menggunakan aspell. Seperti yang Anda ketahui, saat memeriksa ejaan, tidak semua kata yang tidak dikenal ke kamus standar salah, mereka dapat ditambahkan ke kamus khusus. Jika Anda menjadikan kamus khusus sebagai bagian dari proyek kode sumber, maka gerbang kualitas untuk ejaan dapat dirumuskan sebagai berikut: menjalankan aspell dengan kamus standar dan kustom
tidak akan menemukan kesalahan ejaan apa pun.
Pentingnya Memperbaiki Versi Analyzer
Kesimpulannya, perlu untuk mencatat hal berikut: cara apa pun yang Anda pilih untuk memperkenalkan analisis dalam pipa pengiriman Anda, versi penganalisis harus diperbaiki. Jika Anda membiarkan penganalisis memperbarui dirinya sendiri secara spontan, maka ketika membuat permintaan tarikan lain cacat baru dapat muncul, yang tidak terkait dengan kode yang diubah, tetapi dengan fakta bahwa penganalisa baru hanya mampu mendeteksi lebih banyak cacat. Ini akan merusak proses verifikasi permintaan tarik Anda. Pembaruan penganalisis harus merupakan tindakan sadar. Bagaimanapun, fiksasi versi yang kaku dari setiap komponen build adalah persyaratan umum dan subjek untuk topik lain.
Kesimpulan
- Analisis statis tidak akan menemukan bug dan tidak akan meningkatkan kualitas produk Anda sebagai hasil dari sekali berjalan. Hanya terus berjalan dalam proses pengiriman akan menghasilkan efek positif.
- Bug hunt bukan tujuan analisis utama sama sekali. Sebagian besar fitur yang berguna tersedia di perangkat opensource.
- Memperkenalkan gerbang kualitas dengan hasil analisis statis pada tahap pertama dari pipa pengiriman, menggunakan "ratchet" untuk kode lawas.
Referensi
- Pengiriman terus menerus
- Alexey Kudryavtsev: Analisis program: apakah Anda pengembang yang baik? Laporkan metode analisis kode yang berbeda, bukan hanya statis!
Kutipan dari pembahasan artikel asli
Evgeniy RyzhkovIvan, terima kasih atas artikelnya dan telah membantu kami melakukan pekerjaan kami, yaitu mempopulerkan teknologi analisis kode statis. Anda benar bahwa artikel-artikel dari blog PVS-Studio, dalam kasus dengan pikiran yang tidak matang, dapat memengaruhi mereka dan mengarah pada kesimpulan seperti "Saya akan memeriksa kode sekali saja, memperbaiki kesalahan dan itu akan dilakukan." Ini adalah rasa sakit pribadi saya, yang saya tidak tahu bagaimana mengatasinya selama beberapa tahun. Faktanya adalah bahwa artikel tentang pemeriksaan proyek:
- Menyebabkan efek wow pada orang. Orang suka membaca bagaimana pengembang perusahaan seperti Google, Epic Games, Microsoft, dan perusahaan lain terkadang gagal. Orang suka berpikir bahwa siapa pun bisa salah, bahkan para pemimpin industri melakukan kesalahan. Orang suka membaca artikel seperti itu.
- Selain itu, penulis dapat menulis artikel tentang arus, tanpa harus berpikir keras. Tentu saja, saya tidak ingin menyinggung perasaan orang-orang kami yang menulis artikel ini. Tetapi datang setiap kali dengan artikel baru jauh lebih sulit daripada menulis artikel tentang cek proyek (selusin bug, beberapa lelucon, campur dengan gambar unicorn).
Anda menulis artikel yang sangat bagus. Saya juga punya beberapa artikel tentang topik ini. Begitu juga kolega lainnya. Selain itu, saya mengunjungi berbagai perusahaan dengan laporan tentang tema "Filsafat analisis kode statis", di mana saya berbicara tentang proses itu sendiri, tetapi bukan tentang bug tertentu.
Tetapi tidak mungkin menulis 10 artikel tentang prosesnya. Nah, untuk mempromosikan produk kita, kita perlu banyak menulis secara teratur. Saya ingin mengomentari beberapa poin lagi dari artikel dengan komentar terpisah untuk membawa diskusi lebih nyaman.
Artikel singkat
ini adalah tentang "Filsafat analisis kode statis", yang merupakan topik saya ketika mengunjungi berbagai perusahaan.
Ivan PonomarevEvgeniy, terima kasih banyak atas ulasan informatif pada artikelnya! Ya, Anda mendapat perhatian saya di posting tentang dampak pada "pikiran yang belum matang" benar-benar benar!
Tidak ada yang bisa disalahkan di sini, karena penulis artikel / laporan
analisis tidak bertujuan membuat artikel / laporan
analisis . Tetapi setelah beberapa posting terbaru oleh
Andrey2008 dan
lany , saya memutuskan bahwa saya tidak bisa diam lagi.
Evgeniy RyzhkovIvan, seperti yang ditulis di atas, saya akan mengomentari tiga poin dari artikel ini. Itu berarti bahwa saya setuju dengan yang, bahwa saya tidak berkomentar.
1.
Urutan standar tahapan pipa ini terlihat sebagai berikut ...Saya tidak setuju bahwa langkah pertama adalah analisis statis, dan hanya yang kedua adalah kompilasi. Saya percaya bahwa, rata-rata, pengecekan kompilasi lebih cepat dan lebih logis daripada langsung menjalankan analisis statis "lebih berat". Kami dapat mendiskusikan jika Anda berpikir sebaliknya.
2.
Saya belum pernah bekerja dengan PVS-Studio. Adapun pengalaman saya dengan Codacy, masalah utama mereka adalah bahwa perbedaan kesalahan lama dan baru adalah algoritma yang rumit dan tidak selalu bekerja, terutama jika file berubah secara signifikan atau diganti namanya.Dalam PVS-Studio hal ini dilakukan dengan sangat baik. Ini adalah salah satu fitur pembunuh dari produk, yang, sayangnya, sulit untuk dijelaskan dalam artikel, itu sebabnya orang tidak terlalu mengenalnya. Kami mengumpulkan informasi tentang kesalahan yang ada di basis. Dan tidak hanya "nama file dan baris", tetapi juga informasi tambahan (tanda hash dari tiga baris - saat ini, sebelumnya, berikutnya), sehingga dalam hal menggeser fragmen kode, kita masih bisa menemukannya. Karena itu, ketika memiliki modifikasi kecil, kami masih mengerti bahwa ini adalah kesalahan lama. Dan penganalisa tidak mengeluh tentang hal itu. Sekarang seseorang mungkin berkata: "Nah, bagaimana jika kodenya telah banyak berubah, maka ini tidak akan berhasil, dan Anda mengeluh tentang hal itu seolah-olah itu adalah yang baru ditulis?" Ya Kami mengeluh. Tetapi sebenarnya ini adalah kode baru. Jika kode telah banyak berubah, ini sekarang adalah kode baru, bukan yang lama.
Berkat fitur ini, kami secara pribadi berpartisipasi dalam implementasi proyek dengan 10 juta baris kode C ++, yang setiap hari "disentuh" oleh sekelompok pengembang. Semuanya berjalan tanpa masalah. Jadi kami merekomendasikan penggunaan fitur PVS-Studio ini kepada siapa saja yang memperkenalkan analisis statis dalam prosesnya. Opsi dengan memperbaiki jumlah peringatan menurut rilis tampaknya kurang disukai bagi saya.
3.
Cara apa pun yang Anda pilih untuk memperkenalkan analisis pipa pengiriman Anda, versi analisa harus diperbaikiSaya tidak bisa setuju dengan ini. Musuh yang pasti dari pendekatan semacam itu. Saya merekomendasikan memperbarui analisa dalam mode otomatis. Saat kami menambahkan diagnostik baru dan meningkatkan yang lama. Mengapa Pertama, Anda akan mendapatkan peringatan untuk kesalahan nyata yang baru. Kedua, beberapa positif palsu lama mungkin hilang jika kita mengatasinya.
Tidak memperbarui penganalisis sama dengan tidak memperbarui basis data anti-virus ("bagaimana jika mereka mulai memberi tahu tentang virus"). Kami tidak akan membahas di sini manfaat sebenarnya dari perangkat lunak antivirus secara keseluruhan.
Jika setelah memutakhirkan versi penganalisa Anda memiliki banyak peringatan baru, kemudian tekan mereka, seperti yang saya tulis di atas, melalui fungsi itu. Tetapi tidak untuk memperbarui versi ... Sebagai aturan, klien seperti itu (tentu ada beberapa) tidak memperbarui versi penganalisa selama bertahun-tahun. Tidak ada waktu untuk itu. Mereka MEMBAYAR untuk perpanjangan lisensi, tetapi tidak menggunakan versi baru. Mengapa Karena begitu mereka memutuskan untuk memperbaiki suatu versi. Produk hari ini dan tiga tahun yang lalu adalah siang dan malam. Ternyata seperti "Saya akan membeli tiket, tetapi tidak akan datang".
Ivan Ponomarev1. Di sini Anda benar. Saya siap untuk setuju dengan kompiler / pengurai di awal dan ini bahkan harus diubah di artikel! Misalnya,
spotbugs terkenal tidak dapat bertindak dengan cara yang berbeda sama sekali, karena menganalisis dikompilasi bytecode. Ada kasus-kasus eksotis, misalnya, dalam pipa untuk buku pedoman Ansible, analisis statis lebih baik ditetapkan sebelum parsing karena lebih ringan di sana. Tapi ini eksotis itu sendiri)
2.
Opsi dengan memperbaiki jumlah peringatan menurut rilis tampaknya kurang disukai bagi saya ... - yah, ya, kurang disukai, kurang teknis tetapi sangat praktis :-) Hal utama adalah bahwa itu adalah metode umum, dimana saya dapat secara efektif menerapkan analisis statis di mana saja, bahkan dalam proyek paling menakutkan, memiliki basis kode dan penganalisa apa pun (tidak harus milik Anda), menggunakan Groovy atau skrip bash pada CI. Ngomong-ngomong, sekarang kita menghitung peringatan secara terpisah untuk modul dan alat proyek yang berbeda, tetapi jika kita membaginya dengan cara yang lebih terperinci (untuk file), itu akan jauh lebih dekat dengan metode membandingkan yang baru / lama. Tapi kami merasa seperti itu dan saya suka ratcheting karena itu merangsang pengembang memantau jumlah total peringatan dan perlahan-lahan mengurangi jumlah ini. Jika kita memiliki metode yang lama / baru, apakah itu akan memotivasi pengembang untuk memantau kurva angka peringatan? - mungkin, ya, mungkin, tidak.
Adapun poin 3, inilah contoh nyata dari pengalaman saya. Lihatlah
komit ini . Dari mana asalnya? Kami mengatur linter dalam skrip TravisCI. Mereka bekerja di sana sebagai gerbang berkualitas. Tapi tiba-tiba, ketika versi baru dari Ansible-lint yang menemukan lebih banyak peringatan, beberapa build permintaan tarik mulai gagal karena peringatan dalam kode, yang tidak mereka ubah !!! Pada akhirnya, prosesnya rusak dan permintaan tarikan yang mendesak digabung tanpa melewati gerbang kualitas.
Tidak ada yang mengatakan bahwa tidak perlu memperbarui analisis. Tentu saja! Seperti semua komponen build lainnya. Tetapi itu harus merupakan proses yang disadari, tercermin dalam kode sumber. Dan setiap kali tindakan akan tergantung pada keadaan (apakah kita memperbaiki peringatan yang terdeteksi lagi atau hanya mereset "ratchet")
Evgeniy RyzhkovKetika saya ditanya: "Apakah ada kemampuan untuk memeriksa setiap komit di PVS-Studio?", Saya menjawab, bahwa ya, ada. Dan kemudian menambahkan: "Hanya demi Tuhan jangan gagal membangun jika PVS-Studio menemukan sesuatu!" Karena kalau tidak, cepat atau lambat, PVS-Studio akan dianggap sebagai hal yang mengganggu. Dan ada situasi ketika ITU PERLU untuk melakukan dengan cepat, daripada berkelahi dengan alat, yang tidak membiarkan komit berlalu.
Pendapat saya buruk untuk gagal membangun dalam kasus ini. Ada baiknya mengirim pesan ke pembuat kode masalah.
Ivan PonomarevPendapat saya adalah bahwa tidak ada yang namanya "kita harus cepat berkomitmen." Ini semua hanyalah proses yang buruk. Proses yang baik menghasilkan kecepatan bukan karena kita memecah gerbang proses / kualitas, ketika kita perlu "melakukannya dengan cepat".
Ini tidak bertentangan dengan fakta yang dapat kita lakukan tanpa gagal membangun beberapa kelas temuan analisis statis. Ini hanya berarti bahwa gerbang diatur sedemikian rupa sehingga jenis-jenis temuan tertentu diabaikan dan untuk temuan lain kami memiliki Toleransi Nol.
Commstrip favorit saya pada topik "cepat".Evgeniy RyzhkovSaya adalah musuh yang pasti dari pendekatan untuk menggunakan versi analisa lama. Bagaimana jika pengguna menemukan bug di versi itu? Dia menulis ke pengembang alat dan pengembang alat bahkan akan memperbaikinya. Namun dalam versi baru. Tidak ada yang akan mendukung versi lama untuk beberapa klien. Jika kita tidak berbicara tentang kontrak bernilai jutaan dolar.
Ivan PonomarevEvgeniy, kita tidak membicarakan ini sama sekali. Tidak ada yang mengatakan kita harus menjaga mereka tetap tua. Ini tentang memperbaiki versi dependensi komponen build untuk pembaruan terkontrol mereka - ini adalah disiplin umum, ini berlaku untuk semuanya, termasuk perpustakaan dan alat.
Evgeniy RyzhkovSaya mengerti bagaimana "itu harus dilakukan secara teori". Tetapi saya melihat hanya dua pilihan yang dibuat oleh klien. Baik tetap pada yang baru atau yang lama. Jadi kami hampir tidak memiliki situasi seperti itu ketika "kami memiliki disiplin dan kami tertinggal dari versi saat ini pada dua rilis". Tidak penting bagi saya untuk mengatakan sekarang apakah itu baik atau buruk. Saya hanya mengatakan apa yang saya lihat.
Ivan PonomarevSaya mengerti. Bagaimanapun, itu semua sangat tergantung pada alat / proses apa yang dimiliki klien Anda dan bagaimana mereka menggunakannya. Sebagai contoh, saya tidak tahu apa-apa tentang cara kerjanya di dunia C ++.