Beberapa bulan yang lalu, kolega kami dari Google
mengadakan kontes di Kaggle untuk membuat classifier untuk gambar yang diterima di
game terkenal "Quick, Draw!". Tim, di mana pengembang Yandex Roman Vlasov berpartisipasi, mengambil tempat keempat dalam kompetisi. Pada sesi pelatihan mesin Januari, Roman berbagi ide timnya, implementasi akhir dari classifier, dan praktik menarik dari para pesaing.
- Halo semuanya! Nama saya Roma Vlasov, hari ini saya akan ceritakan tentang Cepat, Draw! Tantangan Pengakuan Doodle.

Ada lima orang di tim kami. Saya bergabung dengannya tepat di depan tenggat waktu penggabungan. Kami tidak beruntung, kami sedikit terguncang, tetapi kami dinaungi oleh uang, dan mereka dari posisi emas. Dan kami mengambil tempat keempat terhormat.
(Selama kompetisi, tim mengamati diri mereka di peringkat, yang dibentuk sesuai dengan hasil yang ditunjukkan pada satu bagian dari kumpulan data yang diusulkan. Peringkat akhir, pada gilirannya, dibentuk pada bagian lain dari dataset. Hal ini dilakukan agar para peserta kompetisi tidak menyesuaikan algoritma mereka dengan data tertentu. Oleh karena itu, di final, ketika beralih di antara peringkat, posisi "goyang" sedikit (dari goyang Inggris - mengocok): pada data lain dan hasilnya mungkin berbeda. Tim Roman pertama di tiga besar. AU troika - adalah uang, peringkat uang zona, karena hanya tiga lokasi pertama mengandalkan hadiah Setelah " 'tim shake APA sudah berada di tempat keempat dengan cara yang sama tim lain kehilangan kemenangan, posisi emas -... Ed) ..
Kompetisi ini juga penting karena Yevgeny Babakhnin menerima grandmaster untuknya, Ivan Sosin - master, Roman Solovyov tetap menjadi grandmaster, Alex Parinov menerima master, saya menjadi ahli, dan sekarang saya sudah menjadi master.
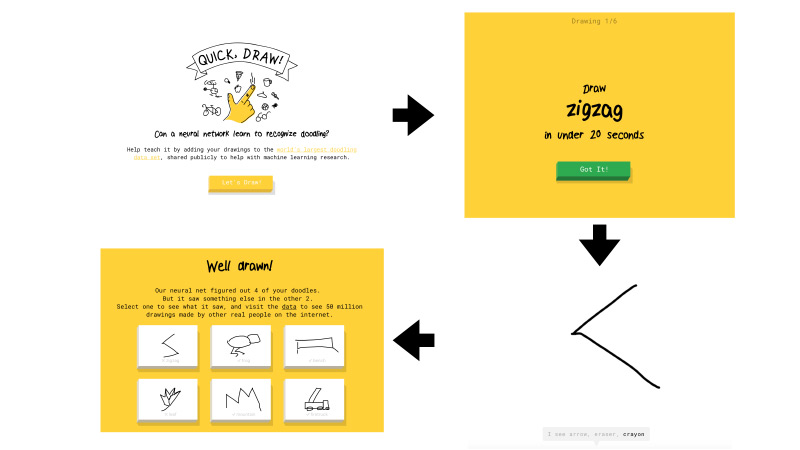
Apa ini Cepat, Draw? Ini adalah layanan dari Google. Google bertujuan untuk mempopulerkan AI dan dengan layanan ini ingin menunjukkan cara kerja jaringan saraf. Anda pergi ke sana, klik Ayo menggambar, dan halaman baru muncul di mana Anda diberitahu: menggambar zigzag, Anda memiliki 20 detik untuk melakukan ini. Anda mencoba menggambar zig-zag dalam 20 detik, seperti di sini, misalnya. Jika semuanya berhasil untuk Anda, jaringan mengatakan itu zig-zag dan Anda melanjutkan. Hanya ada enam gambar seperti itu.
Jika jaringan dari Google tidak dapat mengenali apa yang Anda gambar, tanda silang ditempatkan pada tugas tersebut. Nanti saya akan memberi tahu Anda apa yang akan berarti di masa depan apakah gambar itu diakui oleh jaringan atau tidak.
Layanan ini mengumpulkan sejumlah besar pengguna, dan semua gambar yang digambar pengguna dicatat.

Itu mungkin untuk mengumpulkan hampir 50 juta gambar. Dari sini, kereta dan tanggal ujian untuk kompetisi kami dibentuk. Omong-omong, jumlah data dalam tes dan jumlah kelas tidak sia-sia. Saya akan membicarakannya nanti.
Format data adalah sebagai berikut. Ini bukan hanya gambar RGB, tetapi, secara umum, log dari semua yang dilakukan pengguna. Word adalah target kami, kode negara adalah tempat asal orat-oret, timestamp adalah waktu. Label yang dikenali hanya menunjukkan apakah jaringan dari Google mengenali gambar atau tidak. Dan menggambar itu sendiri adalah suatu urutan, perkiraan dari kurva yang digambar pengguna dengan titik-titik. Dan timing. Ini adalah waktu dari awal menggambar gambar.
Data disajikan dalam dua format. Ini adalah format pertama, dan yang kedua disederhanakan. Mereka melihat penentuan waktu dari sana dan mendekati set poin ini dengan set poin yang lebih kecil. Untuk melakukan ini, mereka menggunakan
algoritma Douglas-Pecker . Anda memiliki satu set besar poin yang hanya mendekati garis lurus, tetapi Anda sebenarnya dapat memperkirakan garis ini hanya dengan dua poin. Ini adalah gagasan algoritma.
Data didistribusikan sebagai berikut. Semuanya seragam, tetapi ada beberapa outlier. Ketika kami memecahkan masalah, kami tidak melihatnya. Yang utama adalah bahwa tidak ada kelas yang benar-benar sedikit, kami tidak perlu melakukan sampler tertimbang dan oversampling data.

Seperti apa gambarnya? Ini adalah kelas pesawat dan contoh darinya diberi label diakui dan tidak dikenali. Rasio mereka di suatu tempat 1 hingga 9. Seperti yang Anda lihat, datanya cukup berisik. Saya akan menyarankan bahwa ini adalah pesawat. Jika Anda melihat tidak dikenali, dalam banyak kasus itu hanya noise. Seseorang bahkan mencoba menulis "pesawat terbang", tetapi ternyata dalam bahasa Prancis.
Sebagian besar peserta hanya mengambil kisi-kisi, memberikan data dari urutan garis ini sebagai gambar RGB, dan melemparkannya ke jaringan. Saya melukis dengan cara yang sama: saya mengambil palet warna, saya melukis garis pertama dengan satu warna, yang berada di awal palet ini, yang terakhir, dengan yang lain, yang berada di ujung palet, dan di antara mereka di mana-mana diinterpolasi di palet ini. Omong-omong, ini memberikan hasil yang lebih baik daripada jika Anda menggambar seperti pada slide pertama - hanya hitam.
Anggota tim lainnya, seperti Ivan Sosin, mencoba pendekatan menggambar yang sedikit berbeda. Dengan satu saluran, ia hanya menggambar gambar abu-abu, dengan saluran lain, ia menggambar setiap stroke dengan gradien dari awal hingga akhir, dari 32 hingga 255, dan saluran ketiga menggambar gradien dalam semua stroke dari 32 hingga 255.
Hal lain yang menarik adalah bahwa Alex Parinov melemparkan informasi ke jaringan melalui kode negara.
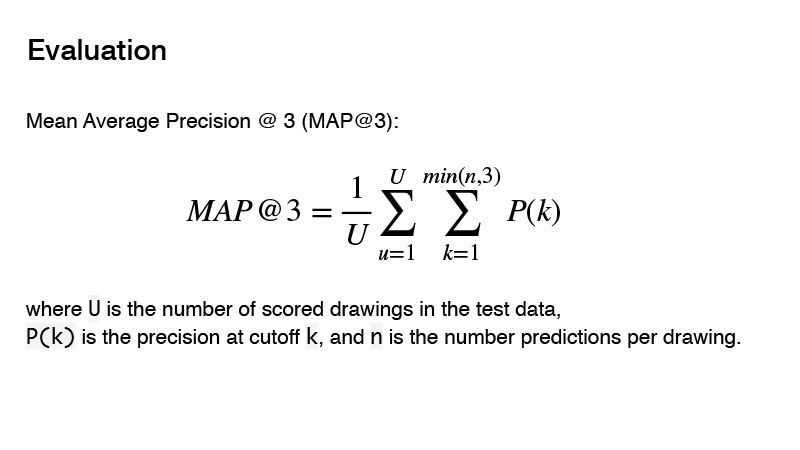
Metrik yang digunakan dalam kompetisi adalah Mean Average Precision. Apa inti dari metrik ini untuk kompetisi? Anda dapat memberikan tiga prediktor, dan jika ketiga prediktor ini tidak benar, maka Anda mendapatkan 0. Jika ada yang benar, maka urutannya diperhitungkan. Dan hasil untuk target akan dianggap sebagai 1, dibagi dengan urutan prediksi Anda. Misalnya, Anda membuat tiga prediksi, dan yang pertama adalah yang benar, maka Anda membagi 1 dengan 1 dan mendapatkan 1. Jika prediktor itu benar dan urutannya 2, maka 1 dibagi dengan 2, Anda mendapatkan 0,5. Baik, dll

Dengan preprocessing data - cara menggambar dan sebagainya - kami memutuskan sedikit. Arsitektur apa yang kami gunakan? Kami mencoba menggunakan arsitektur yang berani seperti PNASNet, SENet, dan sudah arsitektur klasik seperti SE-Res-NeXt, mereka semakin memasuki kompetisi baru. Ada juga ResNet dan DenseNet.



Bagaimana kami mengajarkan ini? Semua model yang kami ambil, kami ambil sendiri pra-dilatih di imagenet. Meskipun ada banyak data, 50 juta gambar, tetapi tetap saja, jika Anda mengambil jaringan yang sudah terlatih pada imagenet, itu menunjukkan hasil yang lebih baik daripada jika Anda hanya melatihnya dari awal.
Teknik pelatihan apa yang kami gunakan? Ini adalah Cosing Annealing dengan Warm Restarts, saya akan membicarakannya nanti. Ini adalah teknik yang saya gunakan di hampir semua kompetisi terakhir saya, dan dengan mereka ternyata cukup baik untuk melatih jaring, untuk mencapai minimum yang baik.

Selanjutnya Kurangi Tingkat Belajar di Dataran Tinggi. Anda mulai melatih jaringan, menetapkan tingkat pembelajaran tertentu, lalu mempelajarinya, kemudian kerugian Anda secara bertahap menyatu ke beberapa nilai tertentu. Anda memeriksa ini, misalnya, lebih dari sepuluh era, kerugian belum berubah. Anda mengurangi tingkat belajar Anda dengan beberapa nilai dan terus belajar. Sekali lagi turun sedikit, konvergen pada minimum tertentu, dan lagi Anda menurunkan tingkat belajar, dan sebagainya, sampai jaringan Anda akhirnya konvergen.
Teknik menarik lebih lanjut: Jangan membusuk tingkat belajar, menambah ukuran batch. Ada artikel dengan nama yang sama. Saat Anda melatih jaringan, Anda tidak perlu mengurangi tingkat pembelajaran, Anda bisa menambah ukuran bets.
Teknik ini, omong-omong, digunakan oleh Alex Parinov. Dia mulai dengan batch yang sama dengan 408, dan ketika jaringan datang ke dataran tinggi, dia hanya menggandakan ukuran batch, dll.
Sebenarnya, saya tidak ingat berapa nilai ukuran bets yang dicapai, tetapi yang menarik, ada tim di Kaggle yang menggunakan teknik yang sama, ukuran bets mereka sekitar 10.000. Omong-omong, kerangka kerja modern untuk pembelajaran mendalam, seperti PyTorch, misalnya, memungkinkan Anda melakukan ini dengan sangat sederhana. Anda menghasilkan batch Anda dan mengirimkannya ke jaringan tidak seperti itu, secara keseluruhan, tetapi membaginya menjadi potongan-potongan sehingga sesuai dengan kartu video Anda, menghitung gradien, dan setelah menghitung gradien untuk seluruh batch, Anda memperbarui skala.
Omong-omong, ukuran bets besar masih masuk dalam kompetisi ini, karena datanya cukup berisik, dan ukuran bets besar membantu Anda untuk lebih akurat memperkirakan gradien.
Pseudo-dabbing juga digunakan, sebagian besar digunakan oleh Roman Soloviev. Dia mengambil sampel di suatu tempat di setengah data dari tes, dan pada batch tersebut dia melatih grid.
Ukuran gambar berperan, tetapi faktanya Anda memiliki banyak data, Anda perlu berlatih untuk waktu yang lama, dan jika ukuran gambar Anda cukup besar, maka Anda akan berlatih untuk waktu yang sangat lama. Tapi ini tidak membawa terlalu banyak ke dalam kualitas classifier akhir Anda, jadi itu layak menggunakan trade-off. Dan mereka mencoba hanya gambar-gambar yang ukurannya tidak terlalu besar.
Bagaimana semuanya belajar? Pada awalnya, foto-foto ukuran kecil diambil, beberapa era dijalankan, mereka dengan cepat butuh waktu. Kemudian gambar besar diberikan, jaringan belajar, lalu bahkan lebih, bahkan lebih untuk tidak melatihnya dari awal dan tidak menghabiskan banyak waktu.
Tentang pengoptimal. Kami menggunakan SGD dan Adam. Dengan cara ini, dimungkinkan untuk mendapatkan model tunggal, yang memberikan kecepatan 0,941-0,956 pada papan peringkat publik, yang cukup bagus.
Jika Anda memasang model dengan beberapa cara, maka Anda mendapatkan suatu tempat 0,951. Jika Anda menerapkan teknik lain, maka Anda akan mendapatkan kecepatan terakhir di papan publik 0,954, seperti yang kami terima. Tetapi lebih lanjut tentang itu nanti. Selanjutnya, saya akan memberi tahu Anda bagaimana kami merakit model, dan bagaimana kecepatan akhir seperti itu dicapai.
Selanjutnya saya ingin berbicara tentang Cosing Annealing dengan Warm Restarts atau Stochastic Gradient Descent dengan Warm Restart. Secara kasar, pada prinsipnya, Anda dapat tetap menggunakan optimizer, tetapi intinya adalah ini: jika Anda hanya melatih satu jaringan dan secara bertahap konvergen ke minimum, maka semuanya baik-baik saja, Anda akan mendapatkan satu jaringan, ia membuat kesalahan tertentu, tetapi Anda bisa mengajarinya sedikit berbeda. Anda akan menetapkan beberapa tingkat pembelajaran awal, dan secara bertahap menurunkannya sesuai dengan rumus ini. Anda meremehkannya, jaringan Anda mencapai batas minimum tertentu, kemudian Anda menghemat bobot, dan sekali lagi menetapkan tingkat pembelajaran, yang pada awal pelatihan, dengan demikian dari minimum ini naik ke suatu tempat, dan sekali lagi meremehkan tingkat pembelajaran Anda.
Dengan demikian, Anda dapat mengunjungi beberapa posisi terendah sekaligus, di mana Anda akan mengalami kerugian plus atau minus yang sama. Tetapi kenyataannya adalah bahwa jaringan dengan bobot ini akan memberikan kesalahan berbeda pada kencan Anda. Dengan rata-rata, Anda akan mendapatkan perkiraan tertentu, dan kecepatan Anda akan lebih tinggi.
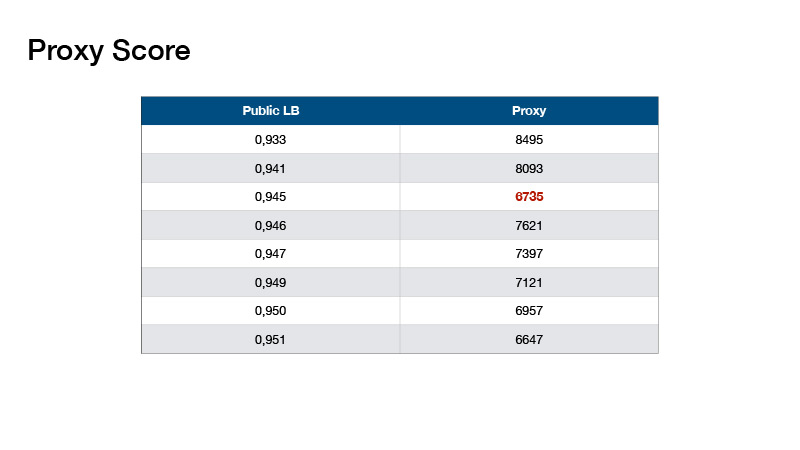
Tentang bagaimana kami merakit model kami. Di awal presentasi, saya berkata untuk memperhatikan jumlah data dalam tes dan jumlah kelas. Jika Anda menambahkan 1 ke jumlah target dalam set tes dan membaginya dengan jumlah kelas, Anda mendapatkan nomor 330, dan ada tertulis tentang ini di forum - bahwa kelas-kelas dalam tes seimbang. Ini bisa digunakan.
Berdasarkan ini, Roman Solovyov menemukan metrik, kami menyebutnya Skor Proksi, yang berkorelasi cukup baik dengan leaderboard. Intinya adalah: Anda membuat prediksi, mengambil top-1 dari prediksi Anda dan menghitung jumlah objek untuk setiap kelas. Kurangi 330 dari setiap nilai dan tambahkan nilai absolut yang dihasilkan.
Nilai-nilai seperti itu ternyata. Ini membantu kami untuk tidak melakukan leaderboard pengujian, tetapi untuk memvalidasi secara lokal dan memilih koefisien untuk ansambel kami.
Dengan ansambel Anda bisa mendapatkan kecepatan seperti itu. Apa lagi yang harus dilakukan? Misalkan Anda menggunakan informasi bahwa kelas dalam tes Anda seimbang.
Perimbangannya berbeda.
Contoh salah satunya adalah penyeimbang dari orang-orang yang memenangkan tempat pertama.
Apa yang kita lakukan Penyeimbangan kami cukup sederhana, diusulkan oleh Evgeny Babakhnin. Kami pertama-tama menyortir prediksi kami berdasarkan 1 teratas dan kandidat terpilih dari mereka - sehingga jumlah kelas tidak melebihi 330. Namun untuk beberapa kelas, ternyata ada yang kurang memprediksi dari 330. Oke, mari kita urutkan berdasarkan atas-2 dan 3 teratas, dan juga memilih kandidat.
Apa perbedaan antara balancing kami dengan balancing? Mereka menggunakan pendekatan berulang, mengambil kelas yang paling populer dan mengurangi kemungkinan untuk kelas ini dengan sejumlah kecil - sampai kelas ini menjadi bukan yang paling populer. Mereka mengambil kelas paling populer berikutnya. Jadi lebih jauh dan diturunkan sampai jumlah semua kelas menjadi sama.
Semua orang menggunakan pendekatan plus atau minus untuk melatih jaringan, tetapi tidak semua orang menggunakan penyeimbangan. Menggunakan balancing, Anda bisa menjadi emas, dan jika Anda beruntung, maka dalam mani.
Bagaimana cara preprocess kencan? Semua orang melakukan pra-pemrosesan tanggal plus-minus dengan cara yang sama - melakukan fitur buatan tangan, mencoba menyandikan pewaktuan dengan goresan warna yang berbeda, dll. Ini persis seperti yang dikatakan Alexey Nozdrin-Plotnitsky, yang mengambil posisi ke-8.

Dia melakukannya secara berbeda. Dia mengatakan bahwa semua fitur buatan tangan ini tidak berfungsi, Anda tidak perlu melakukan ini, jaringan Anda harus mempelajari semua ini sendiri. Dan sebagai gantinya, dia datang dengan modul pembelajaran yang melakukan preprocessing data Anda. Dia melemparkan data sumber tanpa preprocessing - koordinat poin dan timing.
Selanjutnya, ia mengambil perbedaan dalam koordinat, dan rata-rata selama waktu. Dan dia punya matriks yang agak panjang. Dia menggunakan konvolusi 1D beberapa kali untuk mendapatkan matriks 64xn, di mana n adalah jumlah total poin, dan 64 dibuat untuk memberi makan matriks yang dihasilkan ke lapisan beberapa jaringan konvolusional yang menerima 64 saluran. ternyata menjadi matriks 64xn, maka dari ini perlu untuk menyusun tensor beberapa ukuran sehingga jumlah saluran adalah 64. Dia menormalkan semua titik X, Y dalam kisaran 0 hingga 32 untuk membuat tensor ukuran 32x32. Saya tidak tahu mengapa dia menginginkan 32x32, itu terjadi. Dan dalam koordinat ini ia meletakkan fragmen dari matriks ukuran 64xn ini. Dengan demikian, ia hanya menerima tensor 32x32x64, yang dapat dimasukkan lebih jauh ke dalam jaringan saraf convolutional Anda. Saya memiliki segalanya.