Dodo IS adalah sistem global yang membantu Anda mengelola bisnis Anda secara efektif di Dodo Pizza. Itu menutup masalah pemesanan pizza, membantu pewaralaba melacak bisnis, meningkatkan efisiensi karyawan, dan kadang-kadang jatuh. Yang terakhir adalah yang terburuk bagi kita. Setiap menit dari kejatuhan seperti itu menyebabkan hilangnya keuntungan, ketidakpuasan pengguna, dan malam pengembang yang tidak bisa tidur.
Tapi sekarang kita tidur lebih nyenyak. Kami belajar mengenali skenario kiamat sistemik dan memprosesnya. Di bawah ini saya akan memberi tahu Anda bagaimana kami memberikan stabilitas sistem.

Serangkaian artikel tentang runtuhnya sistem Dodo IS * :
1. Hari ketika Dodo berhenti. Script sinkron.
2. Hari ketika Dodo berhenti. Skrip asinkron.
* Materi ditulis berdasarkan kinerja saya di DotNext 2018 di Moskow .
Dodo adalah
Sistem ini merupakan keunggulan kompetitif waralaba kami, karena franchisee mendapatkan model bisnis yang sudah jadi. Ini adalah ERP, HRM dan CRM, semuanya dalam satu.
Sistem muncul beberapa bulan setelah pembukaan restoran pizza pertama. Ini digunakan oleh manajer, pelanggan, kasir, juru masak, pembeli misteri, karyawan pusat panggilan - itu saja. Secara konvensional, Dodo IS dibagi menjadi dua bagian. Yang pertama adalah untuk pelanggan. Ini termasuk situs web, aplikasi seluler, pusat kontak. Yang kedua untuk mitra franchisee, ini membantu mengelola pizzeria. Melalui sistem, faktur dari pemasok, manajemen personalia, karyawan yang mengambil giliran kerja, akunting penggajian otomatis, pelatihan online untuk personel, sertifikasi manajer, sistem kontrol kualitas, dan pembeli misterius melewati sistem.
Kinerja sistem
Kinerja Sistem Dodo IS = Keandalan = Toleransi / Pemulihan Kesalahan. Mari kita bahas masing-masing poin.
Keandalan
Kami tidak memiliki perhitungan matematis yang besar: kami perlu melayani sejumlah pesanan, ada zona pengiriman tertentu. Jumlah pelanggan tidak terlalu bervariasi. Tentu saja, kita akan bahagia ketika itu tumbuh, tetapi ini jarang terjadi dalam ledakan besar. Bagi kami, kinerja bermuara pada beberapa kegagalan yang terjadi, hingga keandalan sistem.
Toleransi kesalahan
Satu komponen mungkin tergantung pada komponen lain. Jika kesalahan terjadi dalam satu sistem, subsistem lainnya tidak boleh jatuh.
Ketangguhan
Kegagalan komponen individu terjadi setiap hari. Ini normal. Penting seberapa cepat kita pulih dari kegagalan.
Skenario Kegagalan Sistem Sinkron
Apa ini
Naluri bisnis besar adalah melayani banyak pelanggan secara bersamaan. Seperti halnya mustahil untuk bekerja di restoran pizza dapur yang bekerja untuk pengiriman dengan cara yang sama seperti ibu rumah tangga di dapur di rumah, kode yang dirancang untuk eksekusi sinkron tidak dapat bekerja dengan sukses untuk layanan pelanggan massal di server.
Ada perbedaan mendasar antara mengeksekusi algoritma dalam satu instance, dan mengeksekusi algoritma yang sama sebagai server dalam kerangka layanan massal.
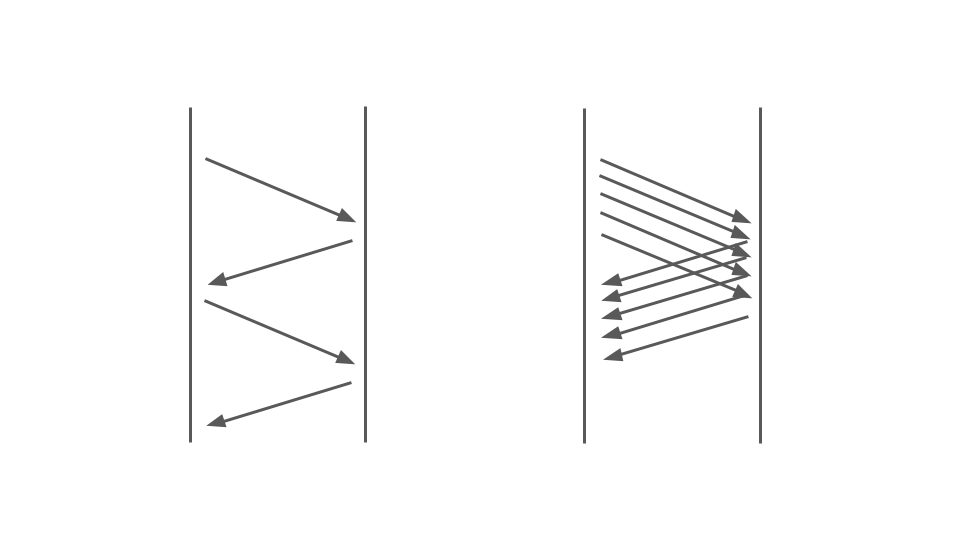
Lihatlah gambar di bawah ini. Di sebelah kiri, kita melihat bagaimana permintaan terjadi antara dua layanan. Ini adalah panggilan RPC. Permintaan berikutnya berakhir setelah yang sebelumnya. Jelas, pendekatan ini tidak skala - pesanan tambahan berbaris.
Untuk melayani banyak pesanan, kami membutuhkan opsi yang tepat:
Pengoperasian kode pemblokiran dalam aplikasi sinkron sangat dipengaruhi oleh model multithreading yang digunakan, yaitu preemptive multitasking. Itu saja dapat menyebabkan kegagalan.
Multitasking sederhana dan preemptive dapat diilustrasikan sebagai berikut:

Blok warna adalah pekerjaan nyata yang dilakukan CPU, dan kami melihat bahwa pekerjaan bermanfaat yang ditunjukkan oleh warna hijau dalam diagram cukup kecil terhadap latar belakang umum. Kita perlu membangkitkan arus, menidurkannya, dan ini di atas kepala. Tidur / bangun seperti itu terjadi selama sinkronisasi pada primitif sinkronisasi apa pun.
Jelas, kinerja CPU akan menurun jika Anda mencairkan pekerjaan yang bermanfaat dengan sejumlah besar sinkronisasi. Seberapa kuat multitasking dapat mempengaruhi kinerja?
Pertimbangkan hasil tes sintetis:
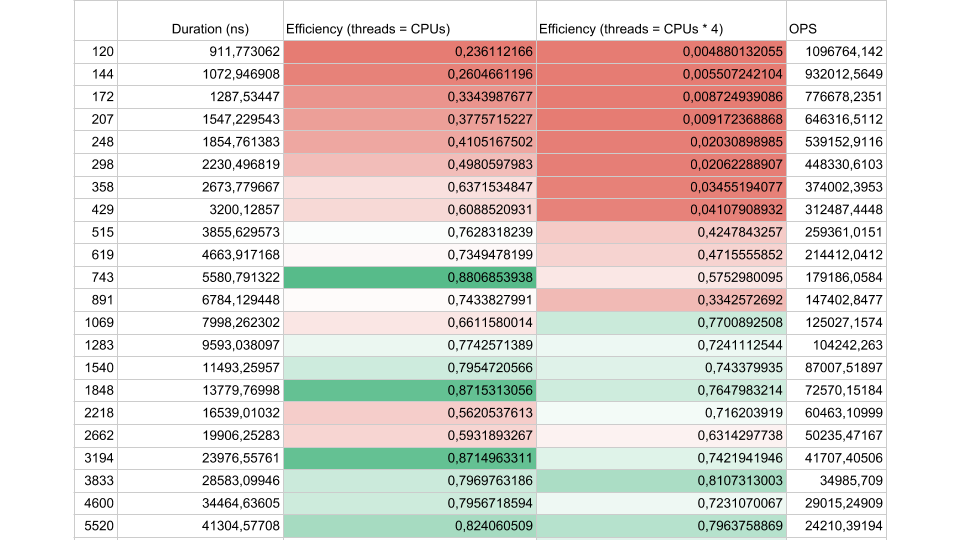
Jika interval aliran antara sinkronisasi sekitar 1000 nanodetik, efisiensinya cukup kecil, bahkan jika jumlah utas sama dengan jumlah inti. Dalam hal ini, efisiensinya sekitar 25%. Jika jumlah Thread 4 kali lebih besar, efisiensi turun drastis, menjadi 0,5%.
Pikirkan tentang hal itu, di cloud Anda memesan mesin virtual dengan 72 core. Harganya uang, dan Anda menggunakan kurang dari setengah inti. Inilah yang dapat terjadi dalam aplikasi multi-utas.
Jika ada lebih sedikit tugas, tetapi durasinya lebih lama, efisiensinya meningkat. Kami melihat bahwa pada 5.000 operasi per detik, dalam kedua kasus efisiensi adalah 80-90%. Untuk sistem multiprosesor, ini sangat bagus.
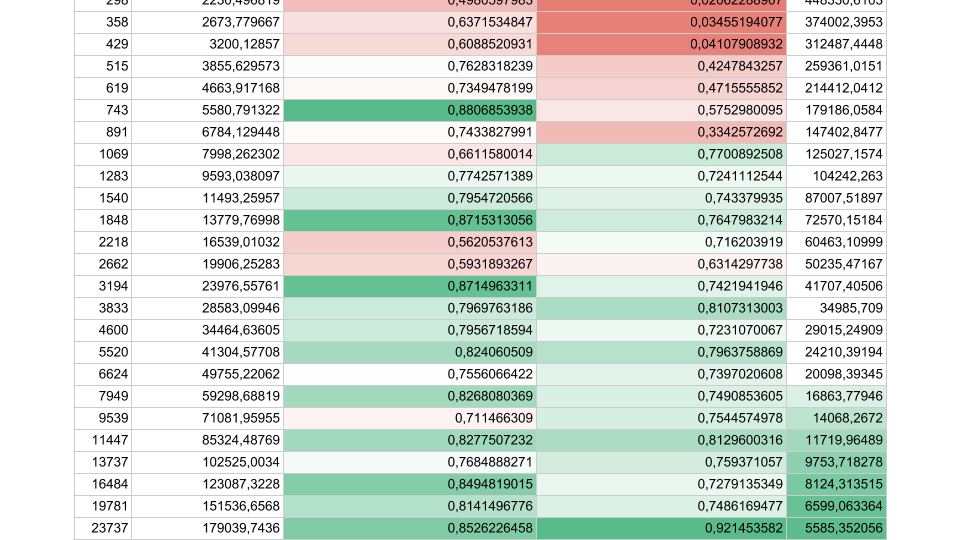
Dalam aplikasi nyata kami, durasi satu operasi antara sinkronisasi terletak di antara keduanya, sehingga masalahnya sangat mendesak.
Apa yang sedang terjadi
Perhatikan hasil stress testing. Dalam hal ini, yang disebut "pengujian ekstrusi."
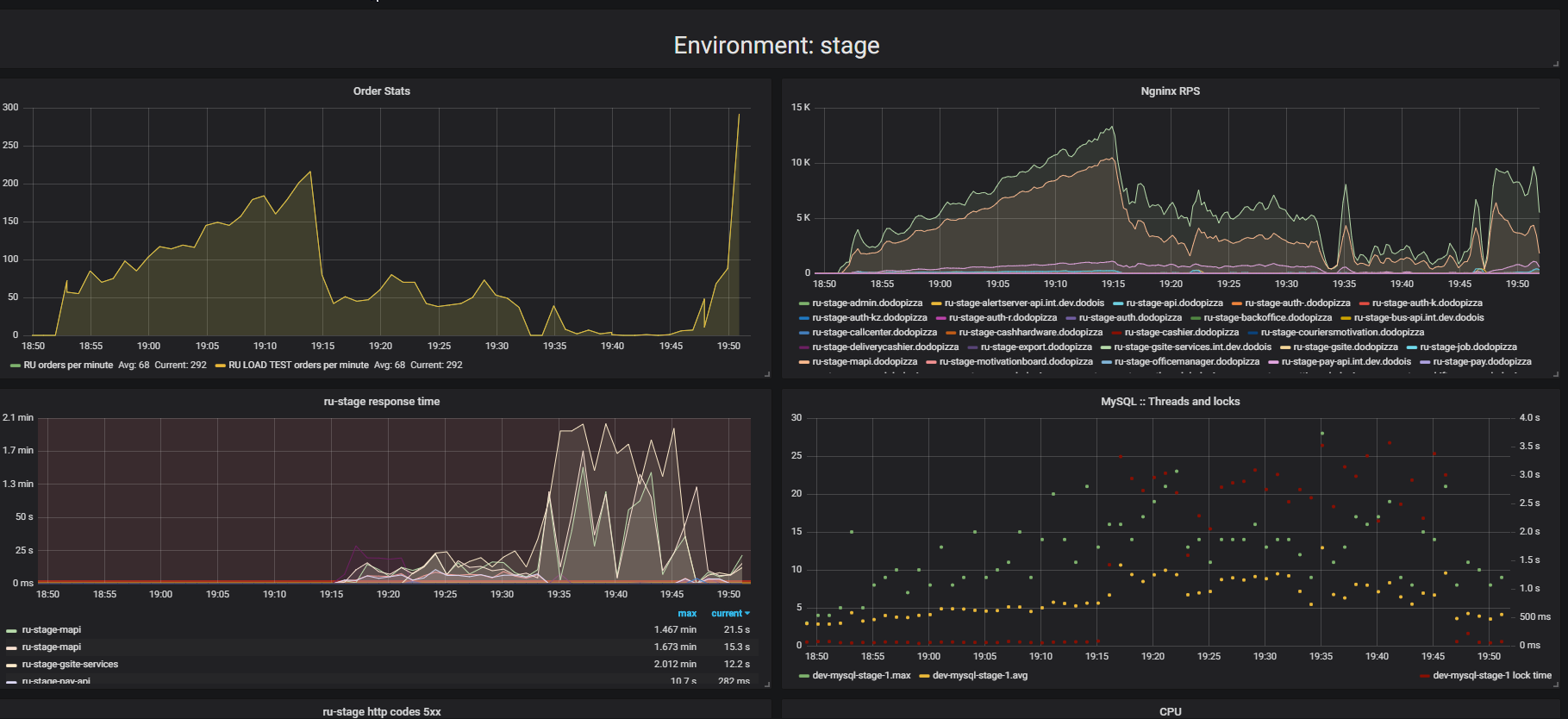
Inti dari pengujian ini adalah bahwa dengan menggunakan dudukan beban, kami mengirimkan semakin banyak permintaan buatan ke sistem, mencoba menempatkan sebanyak mungkin pesanan per menit. Kami mencoba menemukan batas setelah mana aplikasi akan menolak untuk melayani permintaan di luar kemampuannya. Secara intuitif, kami mengharapkan sistem berjalan hingga batasnya, mengabaikan permintaan tambahan. Inilah yang akan terjadi dalam kehidupan nyata, misalnya - ketika melayani di restoran yang penuh dengan pelanggan. Tetapi sesuatu yang lain terjadi. Pelanggan membuat lebih banyak pesanan, dan sistem mulai melayani lebih sedikit. Sistem mulai melayani pesanan sangat sedikit sehingga dapat dianggap sebagai kegagalan total, kerusakan. Ini terjadi dengan banyak aplikasi, tetapi haruskah itu terjadi?
Pada grafik kedua, waktu untuk memproses permintaan bertambah, selama interval ini lebih sedikit permintaan yang dilayani. Permintaan yang tiba lebih awal dilayani jauh kemudian.
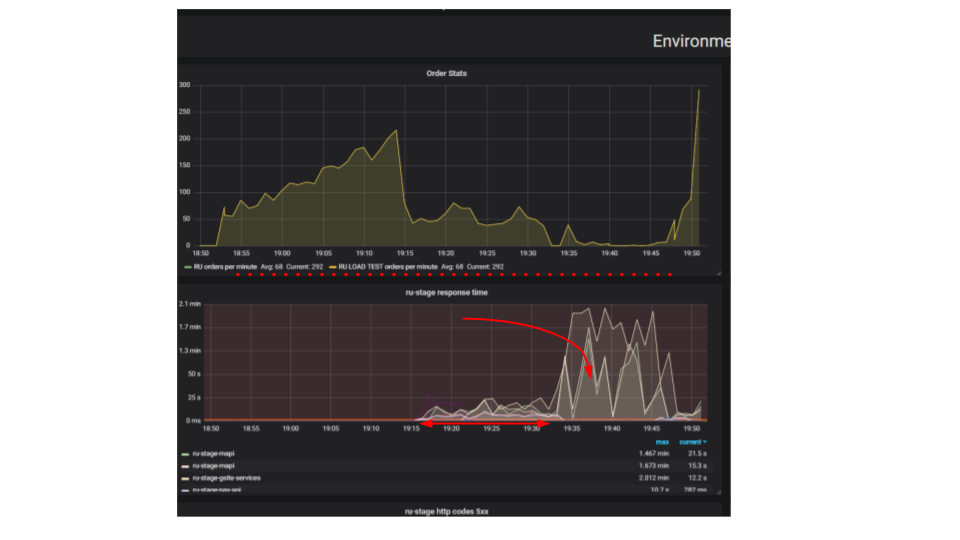
Mengapa aplikasi berhenti? Ada algoritma, itu berhasil. Kami memulainya dari mesin lokal kami, ini bekerja sangat cepat. Kami berpikir bahwa jika kami mengambil mesin seratus kali lebih kuat dan menjalankan seratus permintaan yang sama, maka itu harus dijalankan dalam waktu yang bersamaan. Ternyata permintaan dari klien yang berbeda bertabrakan. Di antara mereka, Pertentangan muncul dan ini merupakan masalah mendasar dalam aplikasi terdistribusi. Permintaan terpisah memperebutkan sumber daya.
Cara menemukan masalah
Jika server tidak berfungsi, pertama-tama kami akan mencoba mencari dan memperbaiki masalah sepele dari kunci di dalam aplikasi, dalam database dan selama file I / O. Masih ada seluruh kelas masalah dalam jaringan, tetapi sejauh ini kami akan membatasi diri pada ketiga hal ini, ini cukup untuk belajar bagaimana mengenali masalah yang sama, dan kami terutama tertarik pada masalah yang menyebabkan Pertentangan - perjuangan untuk sumber daya.
Kunci dalam proses
Berikut adalah permintaan khas dalam aplikasi pemblokiran.
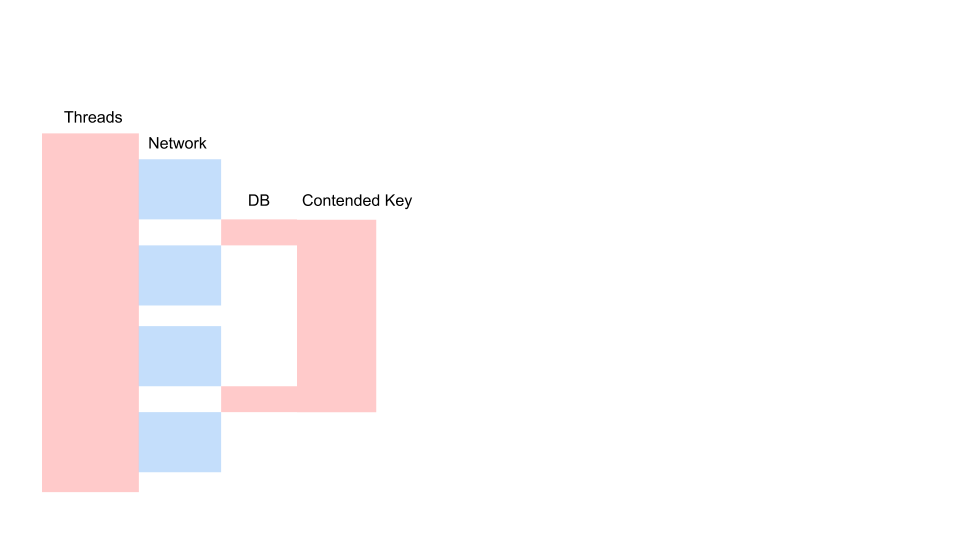
Ini adalah variasi dari Sequence Diagram yang menggambarkan algoritma untuk interaksi kode aplikasi dan database sebagai hasil dari beberapa operasi bersyarat. Kami melihat bahwa panggilan jaringan sedang dibuat, kemudian sesuatu terjadi dalam database - database sedikit digunakan. Kemudian permintaan lain dibuat. Untuk seluruh periode, transaksi dalam database dan kunci umum untuk semua permintaan digunakan. Itu bisa dua pelanggan yang berbeda atau dua pesanan yang berbeda, tetapi satu dan objek menu restoran yang sama, disimpan dalam database yang sama dengan pesanan pelanggan. Kami bekerja menggunakan transaksi untuk konsistensi, dua kueri memiliki Contention pada kunci dari objek umum.
Mari kita lihat bagaimana skala.
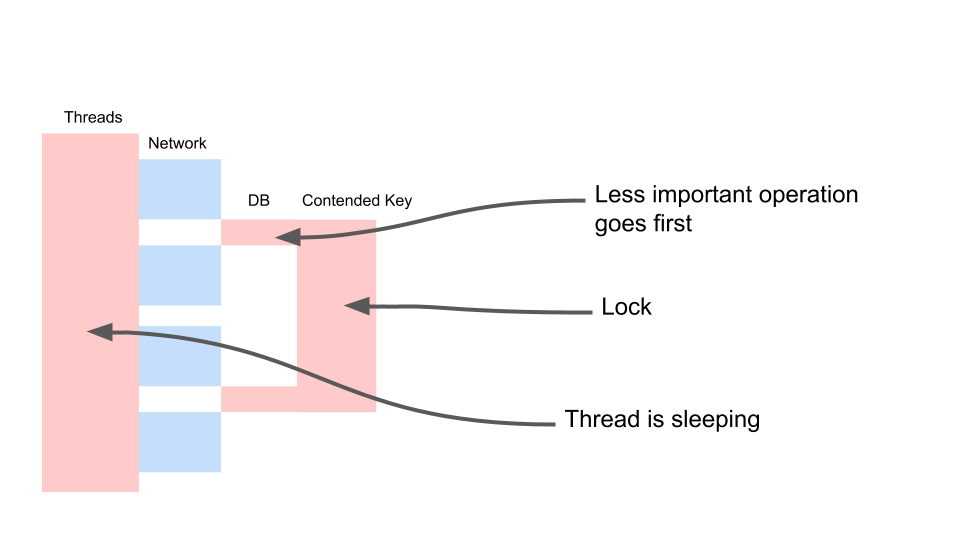
Utas tidur sebagian besar waktu. Dia, pada kenyataannya, tidak melakukan apa pun. Kami memiliki kunci yang mengganggu proses lainnya. Yang paling menjengkelkan adalah bahwa operasi yang paling tidak berguna dalam transaksi yang mengunci kunci terjadi di awal. Ini memperpanjang ruang lingkup transaksi dalam waktu.
Kami akan bertarung dengan cara ini.
var fallback = FallbackPolicy<OptionalData> .Handle<OperationCancelledException>() .FallbackAsync<OptionalData>(OptionalData.Default); var optionalDataTask = fallback .ExecuteAsync(async () => await CalculateOptionalDataAsync());
Ini adalah Konsistensi Akhirnya. Kami berasumsi bahwa beberapa data kami mungkin kurang terkini. Untuk melakukan ini, kita perlu bekerja dengan kode secara berbeda. Kami harus menerima bahwa data memiliki kualitas yang berbeda. Kami tidak akan melihat apa yang terjadi sebelumnya - manajer mengubah sesuatu di menu atau klien mengklik tombol "checkout". Bagi kami, tidak ada bedanya siapa di antara mereka yang menekan tombol dua detik sebelumnya. Dan untuk bisnis tidak ada perbedaan.
Tidak ada perbedaan, kita bisa melakukan hal seperti itu. Menyebutnya dengan syarat opsional Data. Yaitu, beberapa nilai yang bisa kita lakukan tanpanya. Kami memiliki fallback - nilai yang kami ambil dari cache atau meneruskan beberapa nilai default. Dan untuk operasi yang paling penting (variabel yang diperlukan) kami akan menunggu. Kami akan menunggunya dengan tegas, dan hanya setelah itu kami akan menunggu jawaban atas permintaan untuk data opsional. Ini akan memungkinkan kami untuk mempercepat pekerjaan. Ada poin penting lainnya - operasi ini mungkin tidak dilakukan sama sekali karena beberapa alasan. Misalkan kode untuk operasi ini tidak optimal, dan saat ini ada bug. Jika operasi gagal, lakukan fallback. Dan kemudian kita bekerja dengan ini seperti dengan makna yang biasa.
DB Locks
Kami mendapatkan kira-kira tata letak yang sama ketika kami menulis ulang di async dan mengubah model konsistensi.
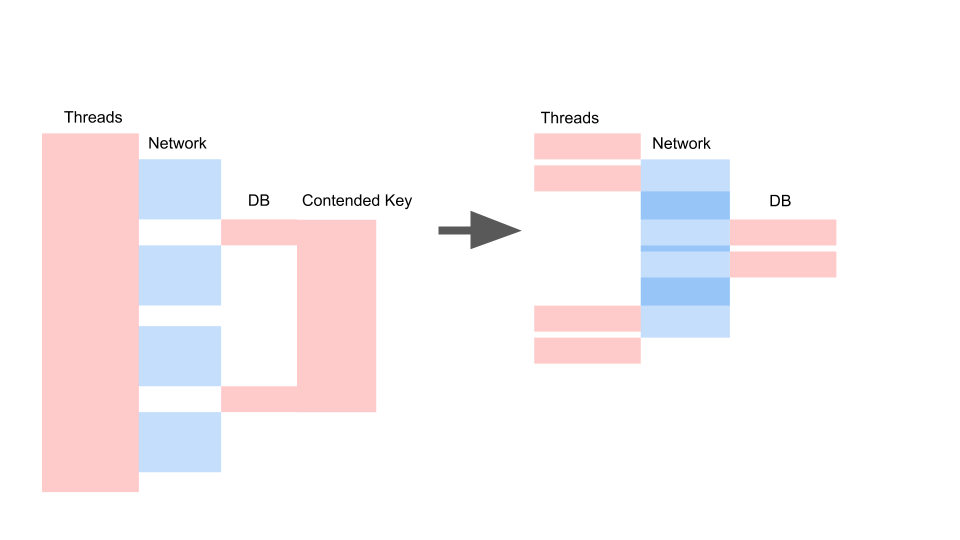
Yang penting di sini bukanlah permintaannya menjadi lebih cepat. Yang penting adalah kita tidak memiliki Pertengkaran. Jika kami menambahkan permintaan, maka hanya sisi kiri gambar yang jenuh dengan kami.
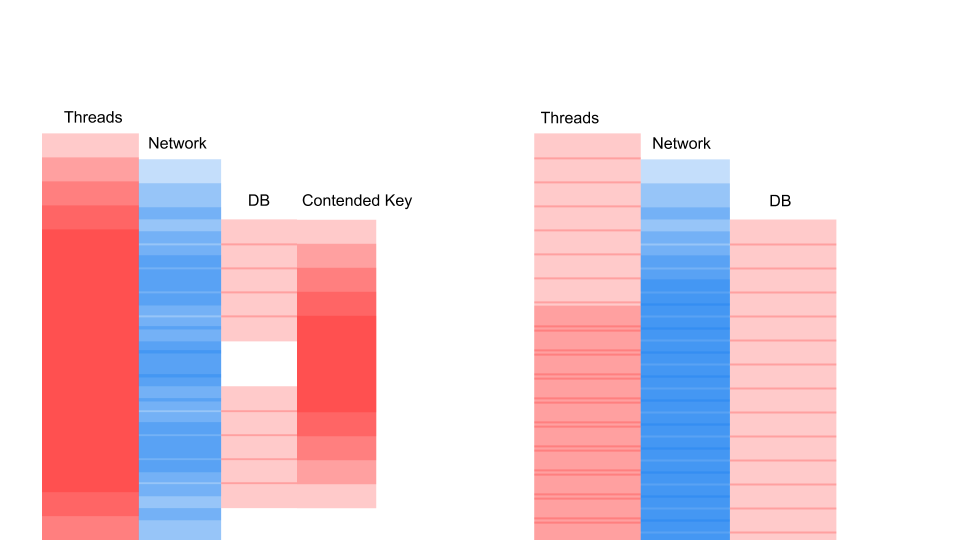
Ini permintaan pemblokiran. Di sini Thread tumpang tindih dan tombol-tombol tempat Contention terjadi. Di sebelah kanan, kami sama sekali tidak memiliki transaksi dalam basis data dan mereka dieksekusi dengan diam-diam. Kasing yang tepat dapat bekerja dalam mode ini tanpa batas. Kiri akan menyebabkan server mogok.
Sinkronkan io
Terkadang kita membutuhkan file log. Anehnya, sistem logging dapat memberikan kegagalan yang tidak menyenangkan. Latensi pada disk di Azure - 5 milidetik. Jika kita menulis file secara berurutan, itu hanya 200 permintaan per detik. Itu dia, aplikasi sudah berhenti.

Hanya saja rambut Anda berdiri ketika Anda melihat ini - lebih dari 2000 Thread telah berkembang biak dalam aplikasi. 78% dari semua Utas adalah tumpukan panggilan yang sama. Mereka berhenti di tempat yang sama dan mencoba memasuki monitor. Monitor ini membatasi akses ke file tempat kita semua masuk. Tentu saja, ini harus dipotong.

Inilah yang perlu Anda lakukan di NLog untuk mengkonfigurasinya. Kami membuat target yang tidak sinkron dan menulisnya. Dan target asinkron menulis ke file nyata. Tentu saja, kita dapat kehilangan sejumlah pesan dalam log, tetapi apa yang lebih penting untuk bisnis? Ketika sistem jatuh selama 10 menit, kami kehilangan sejuta rubel. Mungkin lebih baik kehilangan beberapa pesan di log layanan, yang mengalami kegagalan dan reboot.
Semuanya sangat buruk
Kontensi adalah masalah besar dalam aplikasi multi-utas, yang tidak memungkinkan Anda untuk hanya skala aplikasi utas tunggal. Sumber Contention perlu dapat mengidentifikasi dan menghilangkan. Sejumlah besar Utas merupakan bencana bagi aplikasi, dan pemblokiran panggilan harus ditulis ulang menjadi async.
Saya harus menulis ulang banyak warisan dari pemblokiran panggilan di async, saya sendiri sering memulai upgrade semacam itu. Cukup sering, seseorang datang dan bertanya: "Dengar, kami sudah menulis ulang selama dua minggu sekarang, hampir semuanya async. Dan seberapa banyak itu akan bekerja lebih cepat? " Kawan, saya akan mengecewakan Anda - itu tidak akan bekerja lebih cepat. Itu akan menjadi lebih lambat. Bagaimanapun, TPL adalah salah satu model kompetitif di atas yang lain - multitasking kooperatif atas multitasking preemptive, dan ini overhead. Di salah satu proyek kami - sekitar + 5% untuk penggunaan CPU dan memuat di GC.
Ada satu lagi berita buruk - aplikasi dapat bekerja jauh lebih buruk setelah hanya menulis ulang di async, tanpa menyadari fitur-fitur model kompetitif. Saya akan berbicara tentang fitur-fitur ini dengan sangat rinci di artikel selanjutnya.
Ini menimbulkan pertanyaan - apakah perlu menulis ulang?
Kode sinkron ditulis ulang pada async untuk melepaskan ikatan model pelaksanaan kompetitif proses (Model Mata Uang), dan untuk menyingkirkan model Preemptive Multitasking. Kami melihat bahwa jumlah Thread dapat mempengaruhi kinerja, sehingga Anda harus membebaskan diri dari kebutuhan untuk menambah jumlah Thread untuk meningkatkan Concurrency. Meskipun kami memiliki Legacy, dan kami tidak ingin menulis ulang kode ini - ini adalah alasan utama untuk menulis ulang kode ini.
Kabar baiknya pada akhirnya adalah bahwa kita sekarang tahu sesuatu tentang cara menyingkirkan masalah sepele dari Contention of blocking code. Jika Anda menemukan masalah seperti itu di aplikasi pemblokiran Anda, maka sudah waktunya untuk menyingkirkannya sebelum menulis ulang ke async, karena di sana mereka tidak akan hilang dengan sendirinya.