Para penulis adalah John Hennessey dan David Patterson, pemenang Turing Award 2017 "untuk pendekatan inovatif yang sistematis dan terukur untuk desain dan verifikasi arsitektur komputer yang telah memiliki dampak abadi pada seluruh industri mikroprosesor." Artikel yang diterbitkan dalam Komunikasi ACM, Februari 2019, Volume 62, No. 2, hlm. 48-60, doi: 10.1145 / 3282307 ”Mereka yang tidak ingat masa lalu akan ditakdirkan untuk mengulanginya”
”Mereka yang tidak ingat masa lalu akan ditakdirkan untuk mengulanginya” - George Santayana, 1905
Kami memulai
kuliah Turing kami pada 4 Juni 2018 dengan ulasan arsitektur komputer mulai tahun 60-an. Selain dia, kami menyoroti masalah saat ini dan mencoba mengidentifikasi peluang masa depan yang menjanjikan zaman keemasan baru di bidang arsitektur komputer dalam dekade berikutnya. Sama seperti pada 1980-an, ketika kami melakukan penelitian kami pada peningkatan biaya, efisiensi energi, keamanan dan kinerja prosesor, yang kami menerima penghargaan terhormat ini.
Ide-ide kunci
- Kemajuan Perangkat Lunak Dapat Mendorong Inovasi Arsitektur
- Meningkatkan level antarmuka perangkat lunak dan perangkat keras menciptakan peluang bagi inovasi arsitektur
- Pasar pada akhirnya menentukan pemenang dalam sengketa arsitektur
Perangkat lunak "berbicara" ke peralatan melalui kamus yang disebut "arsitektur set instruksi" (ISA). Pada awal 1960-an, IBM memiliki empat seri komputer yang tidak kompatibel, masing-masing dengan ISA sendiri, tumpukan perangkat lunak, sistem I / O dan ceruk pasar - masing-masing berorientasi pada bisnis kecil, bisnis besar, aplikasi ilmiah, dan sistem real-time. Insinyur IBM, termasuk pemenang Turing Prize Frederick Brooks Jr., memutuskan untuk membuat satu ISA yang secara efektif menyatukan keempatnya.
Mereka membutuhkan solusi teknis tentang cara menyediakan ISA yang sama cepatnya untuk komputer dengan bus 8-bit dan 64-bit. Dalam arti tertentu, bus adalah "otot" komputer: mereka melakukan pekerjaan, tetapi relatif mudah untuk "mengompres" dan "memperluas". Dahulu dan sekarang tantangan terbesar bagi para perancang adalah "otak" dari peralatan pengontrol prosesor. Terinspirasi oleh pemrograman, pelopor ilmu komputer dan penerima hadiah Turing Maurice Wilkes mengusulkan opsi untuk menyederhanakan sistem ini. Kontrol disajikan sebagai array dua dimensi, yang disebutnya sebagai "toko kontrol" (toko kontrol).
Setiap kolom array berhubungan dengan satu garis kontrol, setiap baris adalah instruksi mikro, dan catatan instruksi mikro disebut pemrograman mikro . Memori kontrol berisi interpreter ISA yang ditulis oleh instruksi mikro, sehingga pelaksanaan instruksi normal membutuhkan beberapa instruksi mikro. Memori kontrol diimplementasikan, pada kenyataannya, dalam memori, dan itu jauh lebih murah daripada elemen logika.
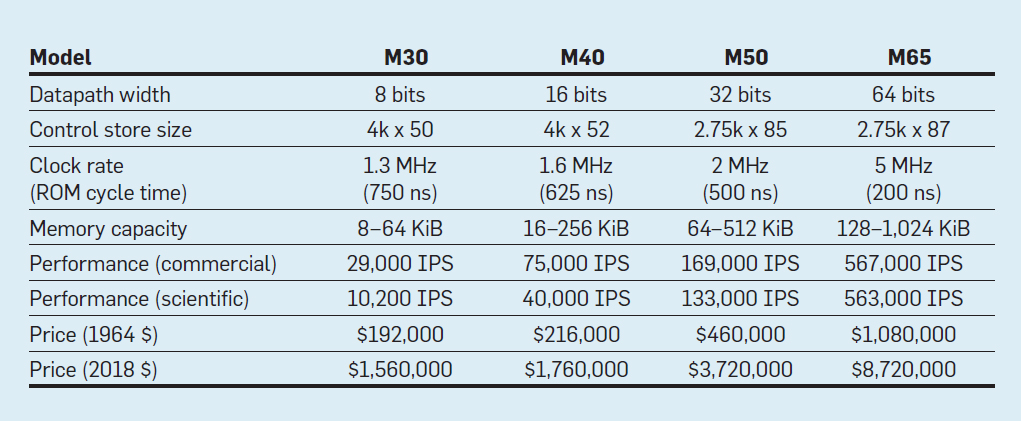 Fitur dari empat model keluarga IBM System / 360; IPS berarti operasi per detik
Fitur dari empat model keluarga IBM System / 360; IPS berarti operasi per detikTabel menunjukkan empat model ISA baru di System / 360 dari IBM, diperkenalkan 7 April 1964. Bus berbeda dengan 8 kali, kapasitas memori 16, kecepatan clock hampir 4, kinerja 50, dan biaya hampir 6. Komputer paling mahal memiliki memori kontrol paling luas, karena bus data yang lebih kompleks menggunakan jalur kontrol lebih banyak . Komputer termurah memiliki memori kontrol yang lebih sedikit karena perangkat keras yang lebih sederhana, tetapi mereka membutuhkan lebih banyak instruksi mikro, karena mereka membutuhkan lebih banyak siklus clock untuk menjalankan instruksi Sistem / 360.
Berkat pemrograman mikro, IBM bertaruh bahwa ISA baru akan merevolusi industri komputasi - dan memenangkan taruhan. IBM mendominasi pasarnya, dan keturunan mainframe IBM berusia 55 tahun masih menghasilkan pendapatan $ 10 miliar per tahun.
Seperti yang telah berulang kali dicatat, meskipun pasar adalah wasit yang tidak sempurna sebagai sebuah teknologi, tetapi mengingat keterkaitan yang erat antara arsitektur dan komputer komersial, pada akhirnya menentukan keberhasilan inovasi arsitektur, yang seringkali membutuhkan investasi teknik yang signifikan.
Sirkuit Terpadu, CISC, 432, 8086, IBM PC
Ketika komputer beralih ke sirkuit terintegrasi, hukum Moore berarti bahwa memori kontrol bisa menjadi jauh lebih besar. Pada gilirannya, ini memungkinkan ISA yang jauh lebih kompleks. Misalnya, memori kontrol VAX-11/780 dari Digital Equipment Corp. pada tahun 1977, itu adalah 5120 kata dalam 96 bit, sedangkan pendahulunya hanya menggunakan 256 kata dalam 56 bit.
Beberapa produsen telah mengaktifkan firmware untuk pelanggan tertentu yang mungkin telah menambahkan fitur khusus. Ini disebut toko kontrol yang dapat ditulis (WCS). Komputer WCS yang paling terkenal adalah
Alto , yang diciptakan oleh pemenang Turing Prize Chuck Tucker dan Butler Lampson dan rekannya untuk Pusat Penelitian Xerox Palo Alto pada tahun 1973. Itu benar-benar komputer pribadi pertama: di sini adalah tampilan pertama dengan pencitraan elemen-demi-elemen dan jaringan Ethernet lokal pertama. Pengontrol untuk tampilan inovatif dan kartu jaringan adalah mikroprogram yang disimpan di WCS dengan kapasitas 4.096 kata dalam 32 bit.
Pada 70-an, prosesor masih tetap 8-bit (misalnya, Intel 8080) dan diprogram terutama di assembler. Pesaing menambahkan instruksi baru untuk mengungguli satu sama lain, menunjukkan prestasi mereka dengan contoh assembler.
Gordon Moore percaya bahwa ISA Intel berikutnya akan bertahan selamanya untuk perusahaan, jadi ia mempekerjakan banyak dokter pintar dalam ilmu komputer dan mengirim mereka ke fasilitas baru di Portland untuk menciptakan ISA hebat berikutnya. Prosesor 8800, sebagaimana Intel awalnya menyebutnya, telah menjadi proyek arsitektur komputer yang benar-benar ambisius untuk setiap zaman, tentu saja, itu adalah proyek paling agresif di tahun 80-an. Ini termasuk pengalamatan berbasis kemampuan 32-bit, arsitektur berorientasi objek, instruksi panjang variabel, dan sistem operasinya sendiri dalam bahasa pemrograman Ada yang baru.
Sayangnya, proyek ambisius ini membutuhkan beberapa tahun pengembangan, yang memaksa Intel untuk meluncurkan proyek cadangan darurat di Santa Clara untuk dengan cepat merilis prosesor 16-bit pada tahun 1979. Intel memberi tim baru 52 minggu untuk mengembangkan ISA baru "8086", mendesain dan membangun chip. Dengan jadwal yang ketat, desain ISA hanya membutuhkan waktu 10 orang-minggu selama tiga minggu kalender reguler, terutama karena perluasan register 8-bit dan satu set instruksi 8080 menjadi 16 bit. Tim menyelesaikan 8086 sesuai jadwal, tetapi prosesor buatan ini diumumkan tanpa banyak keriuhan.
Intel sangat beruntung bahwa IBM sedang mengembangkan komputer pribadi untuk bersaing dengan Apple II dan membutuhkan mikroprosesor 16-bit. IBM mengincar Motorola 68000 dengan ISA yang mirip dengan IBM 360, tetapi itu berada di belakang jadwal agresif IBM. Sebaliknya, IBM beralih ke versi 8-bit bus 8086. Ketika IBM mengumumkan PC pada 12 Agustus 1981, ia berharap untuk menjual 250.000 komputer pada tahun 1986. Sebagai gantinya, perusahaan menjual 100 juta di seluruh dunia, menghadirkan masa depan yang sangat menjanjikan untuk ISA darurat Intel.
Proyek Intel 8800 asli diganti namanya menjadi iAPX-432. Akhirnya, diumumkan pada tahun 1981, tetapi membutuhkan beberapa chip dan memiliki masalah kinerja yang serius. Itu selesai pada tahun 1986, setahun setelah Intel memperluas 16-bit ISA 8086 menjadi 80386, meningkatkan register dari 16 bit menjadi 32 bit. Dengan demikian, prediksi Moore mengenai ISA ternyata benar, tetapi pasar memilih 8086 yang dibuat menjadi setengah, daripada iAPX-432 yang diurapi. Ketika arsitek dari prosesor Motorola 68000 dan iAPX-432 menyadari, pasar jarang mampu menunjukkan kesabaran.
Dari set instruksi kompleks ke disingkat
Pada awal 1980-an, beberapa penelitian komputer dengan seperangkat instruksi kompleks (CISC) dilakukan: mereka memiliki mikroprogram besar dalam memori kontrol besar. Ketika Unix menunjukkan bahwa bahkan sistem operasi dapat ditulis dalam bahasa tingkat tinggi, pertanyaan utamanya adalah: "Instruksi apa yang akan dihasilkan oleh kompiler?" bukannya mantan "Assembler apa yang akan digunakan programmer?" Peningkatan signifikan dalam tingkat antarmuka perangkat keras-perangkat lunak telah menciptakan peluang untuk inovasi dalam arsitektur.
Pemenang Hadiah Turing John Kokk dan rekannya telah mengembangkan ISA dan kompiler komputer mini yang lebih sederhana. Sebagai percobaan, mereka mereorientasi kompiler penelitian mereka untuk menggunakan IBM 360 ISA hanya menggunakan operasi sederhana antara register dan memuat dengan memori, menghindari instruksi yang lebih kompleks. Mereka memperhatikan bahwa program berjalan tiga kali lebih cepat jika mereka menggunakan subset sederhana. Emer dan Clark
menemukan bahwa 20% dari instruksi VAX mengambil 60% dari mikrokode dan hanya mengambil 0,2% dari waktu eksekusi. Salah satu penulis artikel ini (Patterson) menghabiskan liburan kreatif di DEC, membantu mengurangi kesalahan dalam mikrokode VAX. Jika produsen mikroprosesor akan mengikuti desain ISA dengan serangkaian perintah CISC yang kompleks di komputer besar, mereka mengharapkan sejumlah besar kesalahan mikrokode dan ingin menemukan cara untuk memperbaikinya. Dia menulis
artikel seperti itu , tetapi majalah
Komputer menolaknya. Para pengulas berpendapat bahwa ide buruk untuk membangun mikroprosesor dengan ISA sangat kompleks sehingga mereka perlu diperbaiki di lapangan. Kegagalan ini meragukan nilai CISC untuk mikroprosesor. Ironisnya, mikroprosesor CISC modern memang memasukkan mekanisme pemulihan mikrokode, tetapi penolakan untuk menerbitkan artikel mengilhami penulis untuk mengembangkan ISA yang kurang rumit untuk mikroprosesor - komputer dengan set instruksi yang direduksi (RISC).
Komentar-komentar ini dan transisi ke bahasa tingkat tinggi memungkinkan transisi dari CISC ke RISC. Pertama, instruksi RISC disederhanakan, jadi tidak perlu juru bahasa. Instruksi RISC biasanya sederhana seperti instruksi mikro dan dapat dieksekusi langsung oleh perangkat keras. Kedua, memori cepat yang sebelumnya digunakan untuk interpreter mikrokode CISC dirancang ulang menjadi cache instruksi RISC (cache adalah memori kecil, cepat yang mendukung instruksi yang baru-baru ini dijalankan, karena instruksi seperti itu kemungkinan akan digunakan kembali dalam waktu dekat). Ketiga,
register pengalokasi berdasarkan skema pewarnaan grafik oleh Gregory Chaitin sangat memudahkan penggunaan register yang efisien untuk kompiler, yang diuntungkan dari SPA ini dengan operasi register-register. Akhirnya, hukum Moore mengarah pada fakta bahwa pada 1980-an ada cukup transistor pada sebuah chip untuk mengakomodasi bus 32-bit penuh pada satu chip, bersama dengan cache untuk instruksi dan data.
Sebagai contoh, dalam gbr. Gambar 1 menunjukkan mikroprosesor
RISC-I dan
MIPS yang dikembangkan di Universitas California di Berkeley dan Universitas Stanford pada tahun 1982 dan 1983, yang menunjukkan manfaat RISC. Akibatnya, pada tahun 1984 prosesor ini dipresentasikan pada konferensi terkemuka tentang desain sirkuit, Konferensi Sirkuit Solid-State IEEE International (
1 ,
2 ). Itu adalah momen yang luar biasa ketika beberapa mahasiswa pascasarjana di Berkeley dan Stanford menciptakan mikroprosesor yang melebihi kemampuan industri pada zaman itu.
 Fig. 1. Prosesor RISC-I dari University of California di Berkeley dan MIPS dari Stanford University
Fig. 1. Prosesor RISC-I dari University of California di Berkeley dan MIPS dari Stanford UniversityChip akademik tersebut menginspirasi banyak perusahaan untuk membuat mikroprosesor RISC, yang merupakan yang tercepat selama 15 tahun ke depan. Penjelasan terkait dengan rumus kinerja prosesor berikut:
Waktu / Program = (Instruksi / Program) × (tindakan / instruksi) × (waktu / tindakan)Para insinyur DEC kemudian
menunjukkan bahwa untuk satu program, CISC yang lebih kompleks membutuhkan 75% dari jumlah instruksi RISC (istilah pertama dalam rumus), tetapi dalam teknologi yang sama (istilah ketiga) setiap instruksi CISC membutuhkan 5-6 siklus lebih banyak (istilah kedua), yang membuat mikroprosesor RISC sekitar 4 kali lebih cepat.
Tidak ada formula seperti itu dalam literatur komputer tahun 80-an, yang membuat kami menulis buku
Computer Architecture: A Quantitective Approach pada tahun 1989. Subtitle menjelaskan tema buku ini: untuk menggunakan pengukuran dan tolok ukur untuk mengukur trade-off, daripada mengandalkan intuisi dan pengalaman desainer, seperti di masa lalu. Pendekatan kuantitatif kami juga terinspirasi oleh apa yang dilakukan buku
Turing Laureate Donald Knuth untuk algoritma.
VLIW, EPIC, Itanium
ISA inovatif berikutnya seharusnya melampaui keberhasilan RISC dan CISC.
Arsitektur instruksi mesin yang sangat panjang,
VLIW dan sepupunya EPIC (Komputasi dengan paralelisme eksplisit dari instruksi mesin) dari Intel dan Hewlett-Packard menggunakan instruksi panjang, yang masing-masing terdiri dari beberapa operasi independen yang dihubungkan bersama. Pendukung VLIW dan EPIC pada waktu itu percaya bahwa jika satu instruksi dapat mengindikasikan, katakanlah, enam operasi independen - dua transfer data, dua operasi integer dan dua operasi floating point - dan teknologi kompiler dapat secara efisien menetapkan operasi ke enam slot instruksi, maka peralatan bisa disederhanakan. Mirip dengan pendekatan RISC, VLIW dan EPIC memindahkan pekerjaan dari perangkat keras ke kompiler.
Bersama-sama, Intel dan Hewlett-Packard telah mengembangkan prosesor berbasis EPIC 64-bit untuk menggantikan arsitektur x86 32-bit. Harapan besar disematkan pada prosesor EPIC pertama yang disebut Itanium, tetapi kenyataannya tidak sesuai dengan pernyataan awal para pengembang. Meskipun pendekatan EPIC bekerja dengan baik untuk program floating point yang sangat terstruktur, itu tidak dapat mencapai kinerja tinggi untuk program integer dengan percabangan dan cache cache yang kurang dapat diprediksi. Seperti yang kemudian Donald Knuth
catat : "Itanium seharusnya menjadi ... luar biasa - sampai ternyata kompiler yang diinginkan pada dasarnya tidak mungkin untuk ditulis." Para kritikus mencatat keterlambatan dalam rilis Itanium dan menjulukinya Itanik untuk menghormati kapal penumpang Titanic yang bernasib buruk. Pasar kembali gagal menunjukkan kesabaran dan mengadopsi versi 64-bit x86, dan bukan Itanium, sebagai penerusnya.
Berita baiknya adalah bahwa VLIW masih cocok untuk aplikasi yang lebih khusus yang menjalankan program kecil dengan cabang yang lebih sederhana tanpa kehilangan cache, termasuk pemrosesan sinyal digital.
RISC vs CISC di era PC dan Post-PC
AMD dan Intel membutuhkan 500 tim desain dan teknologi semikonduktor yang unggul untuk menjembatani kesenjangan kinerja antara x86 dan RISC. Sekali lagi, demi kinerja yang dicapai melalui pipelining, decoder instruksi on-the-fly menerjemahkan instruksi x86 yang kompleks menjadi instruksi mikro internal seperti RISC. AMD dan Intel kemudian membangun saluran pipa untuk implementasinya. Setiap ide yang digunakan oleh perancang RISC untuk meningkatkan kinerja - memisahkan instruksi dan cache data, cache level kedua pada chip, saluran pipa yang dalam, dan penerimaan simultan dan pelaksanaan beberapa instruksi - kemudian dimasukkan dalam x86. Pada puncak era komputer pribadi pada tahun 2011, AMD dan Intel mengirimkan sekitar 350 juta mikroprosesor x86 setiap tahunnya. Volume tinggi dan margin industri yang rendah juga berarti harga yang lebih rendah daripada komputer RISC.
Dengan ratusan juta komputer terjual setiap tahun, perangkat lunak telah menjadi pasar yang sangat besar. Sementara vendor perangkat lunak Unix harus merilis versi perangkat lunak yang berbeda untuk arsitektur RISC yang berbeda - Alpha, HP-PA, MIPS, Power, dan SPARC - komputer pribadi memiliki satu ISA, sehingga pengembang merilis perangkat lunak "menyusut" yang biner hanya kompatibel dengan arsitektur. x86. Karena basis perangkat lunaknya yang jauh lebih besar, kinerja yang serupa dan harga yang lebih rendah, pada tahun 2000 arsitektur x86 mendominasi pasar desktop dan server kecil.
Apple membantu mengantar era pasca-PC dengan iPhone pada 2007. Alih-alih membeli mikroprosesor, perusahaan smartphone membuat sistem mereka sendiri pada chip (SoC) menggunakan perkembangan orang lain, termasuk prosesor RISC dari ARM. Di sini, desainer tidak hanya penting kinerja, tetapi juga konsumsi daya dan area chip, yang menempatkan pada kerugian arsitektur CISC. Selain itu, Internet of Things telah secara signifikan meningkatkan jumlah prosesor dan tradeoff yang diperlukan dalam ukuran chip, daya, biaya dan kinerja. Tren ini telah meningkatkan pentingnya waktu dan biaya desain, semakin memperburuk posisi prosesor CISC. Di era pasca-PC hari ini, pengiriman x86 tahunan telah turun hampir 10% sejak puncak 2011, sementara chip RISC telah meroket hingga 20 miliar. Saat ini, 99% dari prosesor 32-dan 64-bit di dunia adalah RISC.
Sebagai penutup tinjauan historis ini, kita dapat mengatakan bahwa pasar telah menyelesaikan perselisihan antara RISC dan CISC. Meskipun CISC memenangkan tahap akhir era PC, RISC menang sekarang karena era pasca-PC telah tiba. Tidak ada SPA baru di CISC selama beberapa dekade. Yang mengejutkan kami, konsensus umum tentang prinsip-prinsip ISA terbaik untuk prosesor tujuan umum hari ini masih mendukung RISC, 35 tahun setelah penemuannya.
Tantangan modern untuk arsitektur prosesor
"Jika masalah tidak memiliki solusi, mungkin ini bukan masalah, tetapi fakta yang harus Anda pelajari untuk hidup" - Shimon Peres
Meskipun bagian sebelumnya berfokus pada pengembangan arsitektur set instruksi (ISA), sebagian besar desainer di industri tidak mengembangkan ISA baru, tetapi mengintegrasikan ISA yang ada ke dalam teknologi manufaktur yang ada.
Sejak akhir 70-an, teknologi yang berlaku telah terintegrasi sirkuit pada struktur MOS (MOS), tipe-n pertama (nMOS), dan kemudian saling melengkapi (CMOS). Laju peningkatan yang menakjubkan dalam teknologi MOS - ditangkap oleh prediksi Gordon Moore - adalah kekuatan pendorong yang memungkinkan desainer untuk mengembangkan metode yang lebih agresif untuk mencapai kinerja untuk ISA yang diberikan. Prediksi awal Moore pada tahun 1965 memberikan peningkatan kepadatan transistor dua kali lipat per tahun; pada tahun 1975, dia merevisinya , memprediksi penggandaan setiap dua tahun. Pada akhirnya, ramalan ini mulai disebut hukum Moore. Karena kepadatan transistor tumbuh secara kuadratik, dan kecepatan tumbuh secara linear, menggunakan lebih banyak transistor dapat meningkatkan produktivitas.Akhir dari hukum Moore dan hukum skala Dennard
Meskipun hukum Moore telah berlaku selama beberapa dekade (lihat Gambar 2), di suatu tempat sekitar tahun 2000, ia mulai melambat, dan pada tahun 2018, kesenjangan antara prediksi Moore dan kemampuan saat ini telah tumbuh hingga 15 kali lipat. Pada tahun 2003, Moore menyarankan bahwa ini tidak bisa dihindari . Saat ini diharapkan bahwa kesenjangan akan terus melebar karena teknologi CMOS mendekati batas fundamental.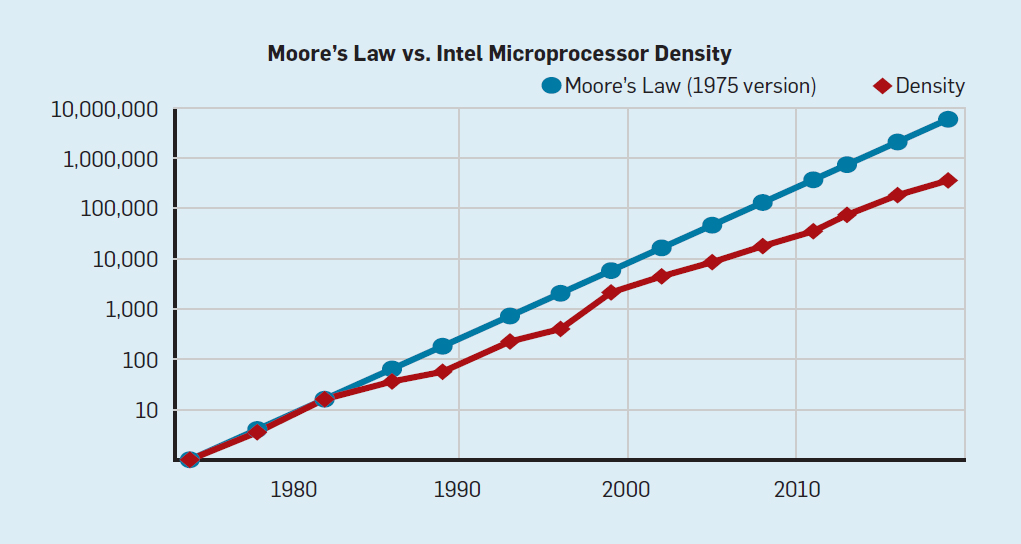 Fig. 2. Jumlah transistor pada chip Intel dibandingkan denganHukum Moore. Hukum Moore disertai dengan proyeksi yang dibuat oleh Robert Dennard yang disebut "Dennard Scaling"bahwa dengan meningkatnya kepadatan transistor, konsumsi energi dari transistor akan turun, sehingga konsumsi per mm² silikon akan hampir konstan. Seiring kekuatan komputasi milimeter silikon tumbuh dengan setiap generasi teknologi baru, komputer menjadi lebih hemat energi. Skala Dennard mulai melambat secara signifikan pada tahun 2007, dan pada tahun 2012 praktis tidak ada gunanya (lihat Gambar 3).
Fig. 2. Jumlah transistor pada chip Intel dibandingkan denganHukum Moore. Hukum Moore disertai dengan proyeksi yang dibuat oleh Robert Dennard yang disebut "Dennard Scaling"bahwa dengan meningkatnya kepadatan transistor, konsumsi energi dari transistor akan turun, sehingga konsumsi per mm² silikon akan hampir konstan. Seiring kekuatan komputasi milimeter silikon tumbuh dengan setiap generasi teknologi baru, komputer menjadi lebih hemat energi. Skala Dennard mulai melambat secara signifikan pada tahun 2007, dan pada tahun 2012 praktis tidak ada gunanya (lihat Gambar 3).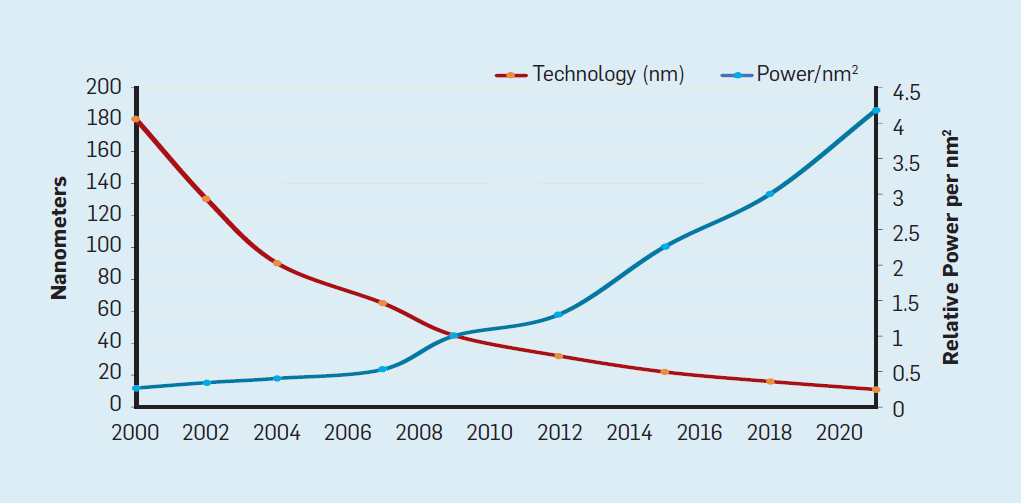 Fig. 3. Jumlah transistor per chip dan konsumsi energi per mm²Dari 1986 hingga 2002, instruksi level concurrency (ILP) adalah metode arsitektur utama untuk meningkatkan produktivitas. Seiring dengan peningkatan kecepatan transistor, ini memberikan peningkatan produktivitas tahunan sekitar 50%. Akhir dari penskalaan Dennard berarti bahwa arsitek harus menemukan cara yang lebih baik untuk menggunakan konkurensi.Untuk memahami mengapa peningkatan ILP mengurangi efisiensi, pertimbangkan inti dari prosesor ARM, Intel, dan AMD modern. Misalkan dia memiliki saluran pipa 15-tahap dan empat instruksi per jam. Dengan demikian, setiap saat pada konveyor terdapat hingga 60 instruksi, termasuk sekitar 15 cabang, karena mereka membentuk sekitar 25% dari instruksi yang dieksekusi. Untuk mengisi pipa, cabang diprediksi, dan kode ditempatkan secara spekulatif dalam pipa untuk dieksekusi. Peramalan spekulatif adalah sumber kinerja dan inefisiensi ILP. Ketika prediksi cabang ideal, spekulasi meningkatkan kinerja dan hanya sedikit meningkatkan konsumsi daya - dan bahkan dapat menghemat energi - tetapi ketika cabang tidak diprediksi dengan benar, prosesor harus membuang perhitungan yang salah.dan semua pekerjaan dan energi terbuang sia-sia. Keadaan internal prosesor juga harus dikembalikan ke keadaan yang ada sebelum cabang yang disalahpahami, dengan mengorbankan waktu dan energi tambahan.Untuk memahami betapa rumitnya desain seperti itu, bayangkan kesulitan memprediksi dengan benar hasil dari 15 cabang. Jika konstruktor prosesor menetapkan batas kerugian 10%, prosesor harus memprediksi dengan benar setiap cabang dengan akurasi 99,3%. Tidak banyak program cabang tujuan umum yang dapat diprediksi secara akurat.Untuk mengevaluasi terdiri dari apa pekerjaan yang sia-sia ini, pertimbangkan data pada Gambar. 4, menunjukkan proporsi instruksi yang dieksekusi secara efisien tetapi terbuang sia-sia karena prosesor memperkirakan percabangan yang salah. Dalam tes SPEC pada Intel Core i7, rata-rata 19% instruksi terbuang sia-sia. Namun, jumlah energi yang dihabiskan lebih besar, karena prosesor harus menggunakan energi tambahan untuk memulihkan keadaan ketika diprediksi secara keliru.
Fig. 3. Jumlah transistor per chip dan konsumsi energi per mm²Dari 1986 hingga 2002, instruksi level concurrency (ILP) adalah metode arsitektur utama untuk meningkatkan produktivitas. Seiring dengan peningkatan kecepatan transistor, ini memberikan peningkatan produktivitas tahunan sekitar 50%. Akhir dari penskalaan Dennard berarti bahwa arsitek harus menemukan cara yang lebih baik untuk menggunakan konkurensi.Untuk memahami mengapa peningkatan ILP mengurangi efisiensi, pertimbangkan inti dari prosesor ARM, Intel, dan AMD modern. Misalkan dia memiliki saluran pipa 15-tahap dan empat instruksi per jam. Dengan demikian, setiap saat pada konveyor terdapat hingga 60 instruksi, termasuk sekitar 15 cabang, karena mereka membentuk sekitar 25% dari instruksi yang dieksekusi. Untuk mengisi pipa, cabang diprediksi, dan kode ditempatkan secara spekulatif dalam pipa untuk dieksekusi. Peramalan spekulatif adalah sumber kinerja dan inefisiensi ILP. Ketika prediksi cabang ideal, spekulasi meningkatkan kinerja dan hanya sedikit meningkatkan konsumsi daya - dan bahkan dapat menghemat energi - tetapi ketika cabang tidak diprediksi dengan benar, prosesor harus membuang perhitungan yang salah.dan semua pekerjaan dan energi terbuang sia-sia. Keadaan internal prosesor juga harus dikembalikan ke keadaan yang ada sebelum cabang yang disalahpahami, dengan mengorbankan waktu dan energi tambahan.Untuk memahami betapa rumitnya desain seperti itu, bayangkan kesulitan memprediksi dengan benar hasil dari 15 cabang. Jika konstruktor prosesor menetapkan batas kerugian 10%, prosesor harus memprediksi dengan benar setiap cabang dengan akurasi 99,3%. Tidak banyak program cabang tujuan umum yang dapat diprediksi secara akurat.Untuk mengevaluasi terdiri dari apa pekerjaan yang sia-sia ini, pertimbangkan data pada Gambar. 4, menunjukkan proporsi instruksi yang dieksekusi secara efisien tetapi terbuang sia-sia karena prosesor memperkirakan percabangan yang salah. Dalam tes SPEC pada Intel Core i7, rata-rata 19% instruksi terbuang sia-sia. Namun, jumlah energi yang dihabiskan lebih besar, karena prosesor harus menggunakan energi tambahan untuk memulihkan keadaan ketika diprediksi secara keliru.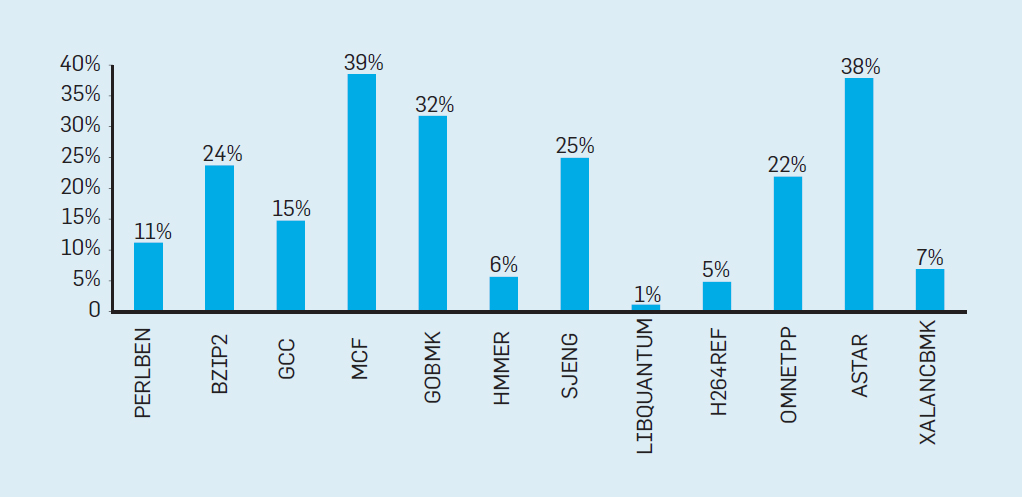 Fig. 4. Instruksi yang terbuang sebagai persentase dari semua instruksi yang dijalankan pada Intel Core i7 untuk berbagai tes SPEC integer.Pengukuran tersebutmembawa banyak kesimpulan bahwa pendekatan yang berbeda harus dicari untuk mencapai kinerja yang lebih baik. Jadi era multicore lahir.Dalam konsep ini, tanggung jawab untuk mengidentifikasi konkurensi dan memutuskan cara menggunakannya dialihkan ke programmer dan sistem bahasa. Multicore tidak menyelesaikan masalah komputasi hemat energi, yang diperburuk dengan berakhirnya skala Dennard. Setiap inti aktif mengkonsumsi energi, terlepas dari apakah itu terlibat dalam perhitungan yang efisien. Kendala utama adalah pengamatan lama yang disebut hukum Amdahl. Dikatakan bahwa manfaat komputasi paralel dibatasi oleh fraksi komputasi sekuensial. Untuk menilai pentingnya pengamatan ini, pertimbangkan Gambar 5. Ini menunjukkan seberapa cepat aplikasi bekerja dengan 64 core dibandingkan dengan satu core, dengan asumsi proporsi perhitungan sekuensial yang berbeda ketika hanya satu prosesor yang aktif. Sebagai contohjika 1% dari waktu perhitungan dilakukan secara berurutan, maka keuntungan dari konfigurasi 64-prosesor hanya 35%. Sayangnya, konsumsi daya sebanding dengan 64 prosesor, sehingga sekitar 45% energi terbuang.
Fig. 4. Instruksi yang terbuang sebagai persentase dari semua instruksi yang dijalankan pada Intel Core i7 untuk berbagai tes SPEC integer.Pengukuran tersebutmembawa banyak kesimpulan bahwa pendekatan yang berbeda harus dicari untuk mencapai kinerja yang lebih baik. Jadi era multicore lahir.Dalam konsep ini, tanggung jawab untuk mengidentifikasi konkurensi dan memutuskan cara menggunakannya dialihkan ke programmer dan sistem bahasa. Multicore tidak menyelesaikan masalah komputasi hemat energi, yang diperburuk dengan berakhirnya skala Dennard. Setiap inti aktif mengkonsumsi energi, terlepas dari apakah itu terlibat dalam perhitungan yang efisien. Kendala utama adalah pengamatan lama yang disebut hukum Amdahl. Dikatakan bahwa manfaat komputasi paralel dibatasi oleh fraksi komputasi sekuensial. Untuk menilai pentingnya pengamatan ini, pertimbangkan Gambar 5. Ini menunjukkan seberapa cepat aplikasi bekerja dengan 64 core dibandingkan dengan satu core, dengan asumsi proporsi perhitungan sekuensial yang berbeda ketika hanya satu prosesor yang aktif. Sebagai contohjika 1% dari waktu perhitungan dilakukan secara berurutan, maka keuntungan dari konfigurasi 64-prosesor hanya 35%. Sayangnya, konsumsi daya sebanding dengan 64 prosesor, sehingga sekitar 45% energi terbuang.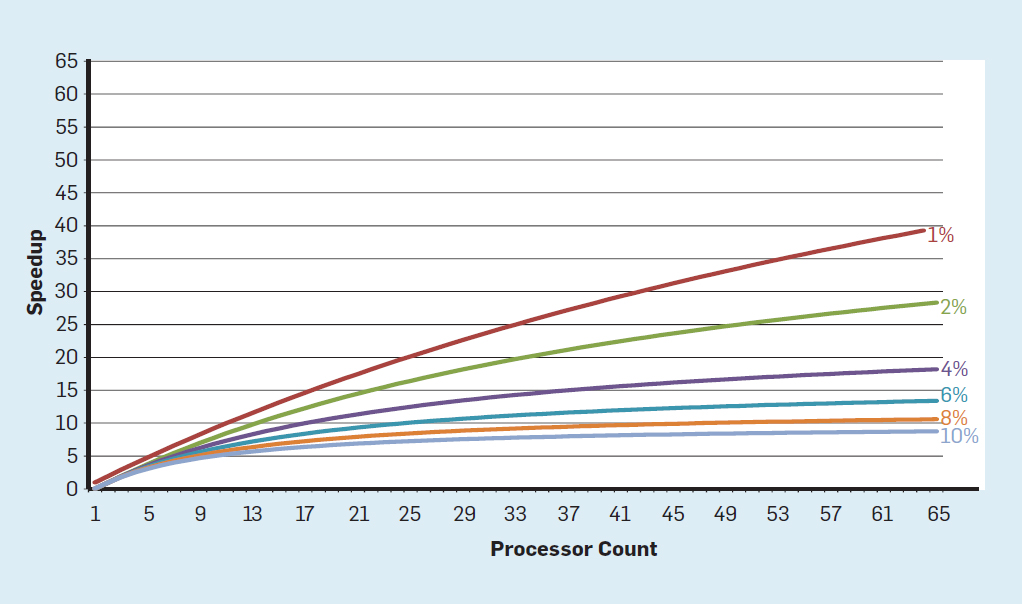 Fig. 5. Pengaruh hukum Amdahl pada peningkatan kecepatan, dengan mempertimbangkan proporsi langkah-langkah dalam mode berurutan.Tentusaja, program nyata memiliki struktur yang lebih kompleks. Ada fragmen yang memungkinkan Anda untuk menggunakan jumlah prosesor yang berbeda pada waktu tertentu. Namun, kebutuhan untuk berinteraksi dan menyinkronkannya secara berkala berarti bahwa sebagian besar aplikasi memiliki beberapa bagian yang hanya dapat menggunakan bagian prosesor secara efisien. Meskipun hukum Amdahl telah berusia lebih dari 50 tahun, itu tetap menjadi kendala yang sulit.Dengan berakhirnya skala Dennard, peningkatan jumlah core pada chip berarti bahwa daya juga meningkat pada tingkat yang hampir sama. Sayangnya, tegangan yang dipasok ke prosesor kemudian harus dilepas sebagai panas. Dengan demikian, prosesor multi-inti dibatasi oleh daya keluaran termal (TDP) atau jumlah daya rata-rata yang dapat dilepas oleh sasis dan sistem pendingin. Meskipun beberapa pusat data kelas atas menggunakan teknologi pendinginan yang lebih canggih, tidak ada pengguna yang ingin meletakkan penukar panas kecil di atas meja atau membawa radiator di punggungnya untuk mendinginkan ponsel. Batas TDP mengarah ke era silikon yang gelap, ketika prosesor memperlambat kecepatan jam dan mematikan core idle untuk mencegah overheating. Cara lain untuk mempertimbangkan pendekatan ini adalah denganbahwa beberapa sirkuit mikro dapat mendistribusikan kembali kekuatan berharga mereka dari inti yang tidak aktif ke yang aktif.Era tanpa skala Dennard, bersama dengan pengurangan hukum Moore dan hukum Amdahl, berarti bahwa inefisiensi membatasi peningkatan produktivitas hanya beberapa persen per tahun (lihat Gambar 6).
Fig. 5. Pengaruh hukum Amdahl pada peningkatan kecepatan, dengan mempertimbangkan proporsi langkah-langkah dalam mode berurutan.Tentusaja, program nyata memiliki struktur yang lebih kompleks. Ada fragmen yang memungkinkan Anda untuk menggunakan jumlah prosesor yang berbeda pada waktu tertentu. Namun, kebutuhan untuk berinteraksi dan menyinkronkannya secara berkala berarti bahwa sebagian besar aplikasi memiliki beberapa bagian yang hanya dapat menggunakan bagian prosesor secara efisien. Meskipun hukum Amdahl telah berusia lebih dari 50 tahun, itu tetap menjadi kendala yang sulit.Dengan berakhirnya skala Dennard, peningkatan jumlah core pada chip berarti bahwa daya juga meningkat pada tingkat yang hampir sama. Sayangnya, tegangan yang dipasok ke prosesor kemudian harus dilepas sebagai panas. Dengan demikian, prosesor multi-inti dibatasi oleh daya keluaran termal (TDP) atau jumlah daya rata-rata yang dapat dilepas oleh sasis dan sistem pendingin. Meskipun beberapa pusat data kelas atas menggunakan teknologi pendinginan yang lebih canggih, tidak ada pengguna yang ingin meletakkan penukar panas kecil di atas meja atau membawa radiator di punggungnya untuk mendinginkan ponsel. Batas TDP mengarah ke era silikon yang gelap, ketika prosesor memperlambat kecepatan jam dan mematikan core idle untuk mencegah overheating. Cara lain untuk mempertimbangkan pendekatan ini adalah denganbahwa beberapa sirkuit mikro dapat mendistribusikan kembali kekuatan berharga mereka dari inti yang tidak aktif ke yang aktif.Era tanpa skala Dennard, bersama dengan pengurangan hukum Moore dan hukum Amdahl, berarti bahwa inefisiensi membatasi peningkatan produktivitas hanya beberapa persen per tahun (lihat Gambar 6).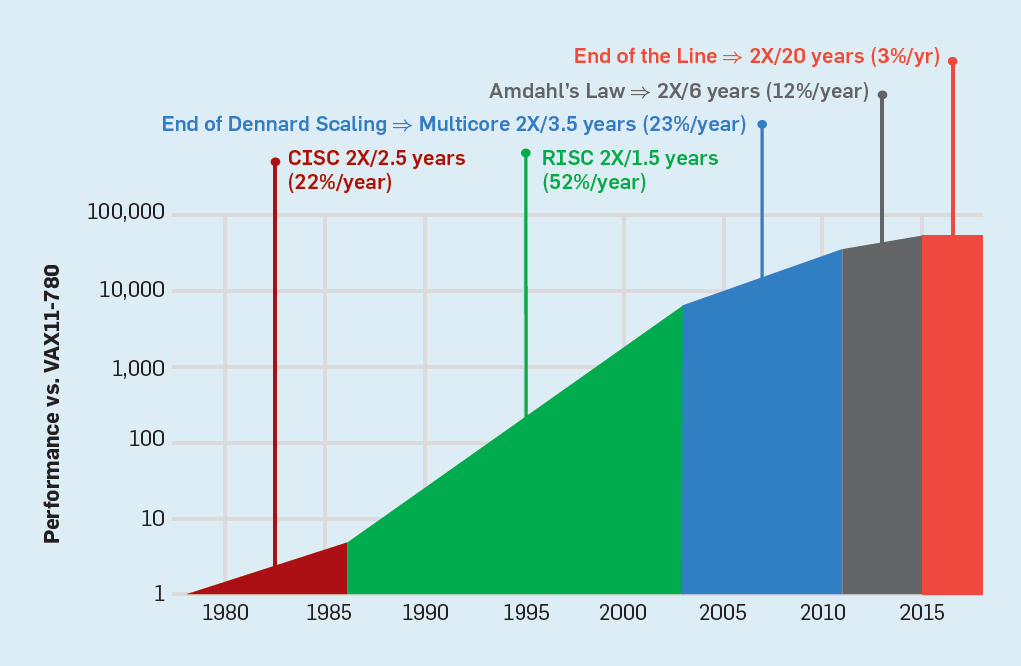 Fig. 6. Pertumbuhan kinerja komputer dengan tes integer (SPECintCPU)Mencapai tingkat peningkatan kinerja yang lebih tinggi - seperti yang dicatat pada tahun 80-an dan 90-an - membutuhkan pendekatan arsitektur baru yang memanfaatkan sirkuit terintegrasi jauh lebih efisien. Kami akan kembali ke diskusi tentang pendekatan yang berpotensi efektif, menyebutkan kelemahan serius lain dari komputer modern - keamanan.
Fig. 6. Pertumbuhan kinerja komputer dengan tes integer (SPECintCPU)Mencapai tingkat peningkatan kinerja yang lebih tinggi - seperti yang dicatat pada tahun 80-an dan 90-an - membutuhkan pendekatan arsitektur baru yang memanfaatkan sirkuit terintegrasi jauh lebih efisien. Kami akan kembali ke diskusi tentang pendekatan yang berpotensi efektif, menyebutkan kelemahan serius lain dari komputer modern - keamanan.Keamanan yang Terlupakan
Di tahun 70-an, pengembang prosesor rajin memastikan keamanan komputer dengan bantuan berbagai konsep, mulai dari cincin pelindung hingga fungsi khusus. Mereka mengerti bahwa sebagian besar bug ada pada perangkat lunak, tetapi percaya bahwa dukungan arsitektur dapat membantu. Fitur-fitur ini sebagian besar tidak digunakan oleh sistem operasi yang bekerja di lingkungan yang seharusnya aman (seperti komputer pribadi). Oleh karena itu, fungsi yang terkait dengan overhead signifikan telah dihilangkan. Dalam komunitas perangkat lunak, banyak yang percaya bahwa pengujian dan metode formal seperti menggunakan microkernel akan menyediakan mekanisme yang efektif untuk membuat perangkat lunak yang sangat aman. Sayangnya, skala sistem perangkat lunak kita yang umum dan pencapaian kinerja berarti bahwa metode seperti itu tidak dapat mengimbangi kinerja. Akibatnya, sistem perangkat lunak besar masih memiliki banyak kelemahan keamanan, dan pengaruhnya semakin besar karena semakin banyaknya informasi pribadi di Internet dan penggunaan cloud computing, di mana pengguna berbagi peralatan fisik yang sama dengan penyerang potensial.
Meskipun perancang prosesor dan lainnya mungkin tidak menyadari pentingnya keamanan yang semakin meningkat, mereka mulai menyertakan dukungan perangkat keras untuk mesin virtual dan enkripsi. Sayangnya, prediksi cabang memperkenalkan cacat keamanan yang tidak diketahui tetapi signifikan di banyak prosesor. Secara khusus,
kerentanan Meltdown dan Specter mengeksploitasi fitur arsitektur mikro, yang memungkinkan kebocoran informasi yang dilindungi . Mereka berdua menggunakan serangan yang disebut pada saluran pihak ketiga ketika informasi bocor sesuai dengan perbedaan waktu yang dihabiskan untuk tugas tersebut. Pada tahun 2018, peneliti menunjukkan
cara menggunakan salah satu opsi Spectre untuk mengekstrak informasi melalui jaringan tanpa mengunduh kode ke prosesor target . Meskipun serangan ini, yang disebut NetSpectre, mentransfer informasi secara perlahan, fakta bahwa ini memungkinkan Anda untuk menyerang mesin apa pun di jaringan lokal yang sama (atau di cluster yang sama di cloud) menciptakan banyak vektor serangan baru. Selanjutnya, dua lagi kerentanan dalam arsitektur mesin virtual dilaporkan (
1 ,
2 ). Salah satunya, yang disebut Foreshadow, memungkinkan Anda untuk menembus mekanisme keamanan Intel SGX yang dirancang untuk melindungi data yang paling berharga (seperti kunci enkripsi). Kerentanan baru ditemukan setiap bulan.
Serangan pada saluran pihak ketiga bukanlah hal baru, tetapi dalam banyak kasus bug perangkat lunak adalah kesalahan sebelumnya. Dalam Meltdown, Specter, dan serangan lainnya, ini adalah kelemahan dalam implementasi perangkat keras. Ada kesulitan mendasar dalam bagaimana arsitek prosesor menentukan apa implementasi ISA yang benar karena definisi standar tidak mengatakan apa-apa tentang efek kinerja mengeksekusi urutan instruksi, hanya keadaan eksekusi arsitektur yang terlihat dari ISA. Arsitek harus memikirkan kembali definisi mereka tentang implementasi ISA yang benar untuk mencegah kelemahan keamanan tersebut. Pada saat yang sama, mereka harus memikirkan kembali perhatian yang mereka berikan pada keamanan komputer, dan bagaimana arsitek dapat bekerja dengan pengembang perangkat lunak untuk menerapkan sistem yang lebih aman. Arsitek (dan semua orang) tidak boleh mengambil keamanan dengan cara lain selain sebagai kebutuhan utama.
Peluang masa depan dalam arsitektur komputer
”Kami memiliki peluang luar biasa yang disamarkan sebagai masalah yang tak terpecahkan.” - John Gardner, 1965
Inefisiensi inheren dari prosesor tujuan umum, baik itu teknologi ILP atau prosesor multi-inti, dikombinasikan dengan penyelesaian skala Dennard dan hukum Moore membuatnya tidak mungkin bahwa arsitek dan pengembang prosesor akan dapat mempertahankan kecepatan yang signifikan dalam meningkatkan kinerja prosesor tujuan umum. Mengingat pentingnya meningkatkan produktivitas untuk perangkat lunak, kita harus bertanya: pendekatan apa yang menjanjikan?
Ada dua kemungkinan yang jelas, serta yang ketiga dibuat dengan menggabungkan keduanya. Pertama, metode pengembangan perangkat lunak yang ada menggunakan ekstensif bahasa tingkat tinggi dengan pengetikan dinamis. Sayangnya, bahasa seperti itu biasanya ditafsirkan dan dieksekusi dengan sangat tidak efisien. Untuk menggambarkan inefisiensi ini, Leiserson dan rekannya
memberikan contoh kecil: penggandaan matriks .
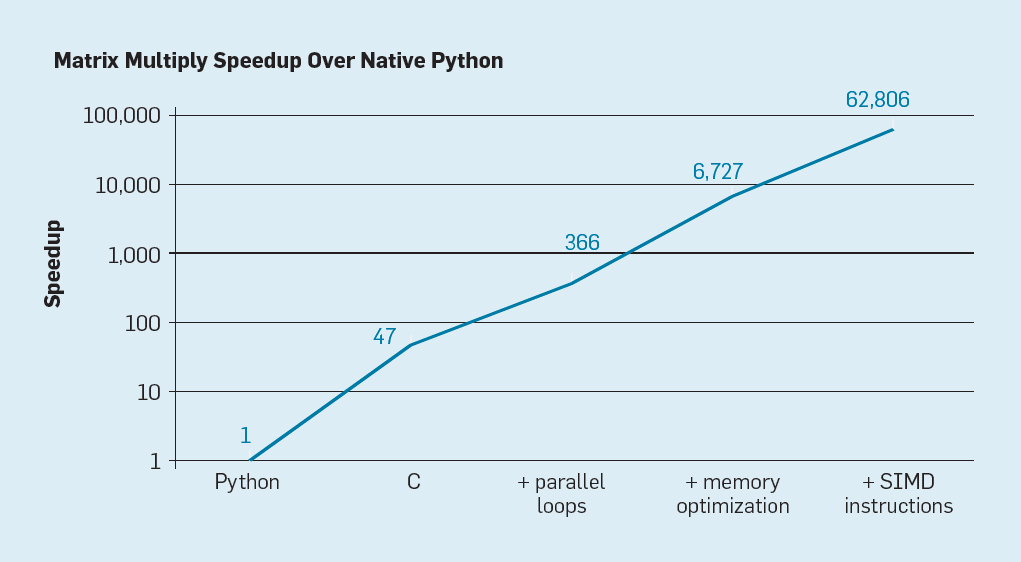 Fig. 7. Potensi percepatan perkalian matriks Python setelah empat optimisasi
Fig. 7. Potensi percepatan perkalian matriks Python setelah empat optimisasiSeperti yang ditunjukkan pada gambar. 7, cukup menulis ulang kode dari Python ke C meningkatkan kinerja sebanyak 47 kali. Menggunakan loop paralel pada banyak core memberikan faktor tambahan sekitar 7. Mengoptimalkan struktur memori untuk menggunakan cache memberikan faktor 20, dan faktor 9 terakhir berasal dari penggunaan ekstensi perangkat keras untuk melakukan operasi SIMD paralel yang mampu melakukan 16 instruksi 32-bit. Setelah itu, versi final, yang sangat dioptimalkan berjalan pada prosesor multi-core Intel 62.806 kali lebih cepat daripada versi Python asli. Ini, tentu saja, adalah contoh kecil. Dapat diasumsikan bahwa programmer akan menggunakan perpustakaan yang dioptimalkan. Meskipun kesenjangan kinerja berlebihan, mungkin ada banyak program yang dapat dioptimalkan 100-1000 kali.
Bidang penelitian yang menarik adalah pertanyaan apakah mungkin untuk menjembatani beberapa kesenjangan kinerja dengan teknologi kompiler baru, mungkin dengan perbaikan arsitektur. Meskipun sulit untuk menerjemahkan dan mengkompilasi bahasa skrip tingkat tinggi secara efisien seperti Python, potensi hasilnya sangat besar. Bahkan optimasi kecil dapat mengarah pada kenyataan bahwa program Python akan berjalan puluhan hingga ratusan kali lebih cepat. Contoh sederhana ini menunjukkan seberapa lebar jarak antara bahasa modern yang berfokus pada kinerja programmer dan pendekatan tradisional yang menekankan kinerja.
Arsitektur Khusus
Pendekatan yang lebih berorientasi pada perangkat keras adalah desain arsitektur yang disesuaikan dengan bidang subjek tertentu, di mana mereka menunjukkan efisiensi yang signifikan. Ini adalah arsitektur khusus domain (arsitektur khusus domain, DSA). Ini biasanya diprogram dan prosesor turing-lengkap, tetapi dengan mempertimbangkan kelas tugas tertentu. Dalam hal ini, mereka berbeda dari sirkuit terintegrasi spesifik aplikasi (ASIC), yang sering digunakan untuk fungsi yang sama dengan kode yang jarang berubah. DSA sering disebut akselerator, karena mempercepat beberapa aplikasi dibandingkan menjalankan seluruh aplikasi pada CPU tujuan umum. Selain itu, DSA dapat memberikan kinerja yang lebih baik karena mereka lebih tepat disesuaikan dengan kebutuhan aplikasi. Contoh DSA termasuk prosesor grafis (GPU), prosesor jaringan saraf yang digunakan untuk pembelajaran yang mendalam, dan prosesor untuk jaringan yang ditentukan perangkat lunak (SDN). DSA mencapai kinerja yang lebih tinggi dan efisiensi energi yang lebih besar karena empat alasan utama.
Pertama, DSA menggunakan bentuk konkurensi yang lebih efisien untuk area subjek tertentu. Sebagai contoh, SIMD (aliran instruksi tunggal, banyak aliran data)
lebih efisien daripada MIMD (aliran beberapa instruksi, banyak aliran data). Meskipun SIMD kurang fleksibel, namun cocok untuk banyak DSA. Prosesor khusus juga dapat menggunakan pendekatan ILP VLIW alih-alih mekanisme spekulatif yang buruk. Seperti disebutkan sebelumnya,
prosesor VLIW kurang cocok untuk kode tujuan umum , tetapi untuk daerah sempit mereka jauh lebih efisien karena mekanisme kontrol lebih sederhana. Secara khusus, prosesor tujuan umum paling top-multi adalah multi-pipelined, yang membutuhkan logika kontrol yang kompleks untuk memulai dan menyelesaikan instruksi. Sebaliknya, VLIW melakukan analisis dan perencanaan yang diperlukan pada waktu kompilasi, yang dapat bekerja dengan baik untuk program paralel yang jelas.
Kedua, layanan DSA memanfaatkan hierarki memori dengan lebih baik. Akses ke memori menjadi jauh lebih mahal daripada perhitungan aritmatika,
seperti dicatat Horowitz . Misalnya, mengakses blok dalam cache 32-KB membutuhkan sekitar 200 kali lebih banyak energi daripada menambahkan bilangan bulat 32-bit. Perbedaan yang begitu besar membuat pengaksesan akses memori sangat penting untuk mencapai efisiensi energi yang tinggi. Prosesor tujuan umum mengeksekusi kode di mana memori mengakses biasanya menunjukkan lokalitas spasial dan temporal, tetapi sebaliknya tidak terlalu dapat diprediksi pada waktu kompilasi. Oleh karena itu, untuk meningkatkan throughput, CPU menggunakan cache multi-level dan menyembunyikan keterlambatan dalam DRAM yang relatif lambat di luar chip. Tembolok multi-level ini sering menghabiskan sekitar setengah energi prosesor, tetapi mereka mencegah hampir semua panggilan ke DRAM, yang membutuhkan sekitar 10 kali lebih banyak energi daripada mengakses cache level terakhir.
Cache memiliki dua kelemahan penting.
Ketika set data sangat besar . Tembolok tidak berfungsi dengan baik ketika kumpulan data sangat besar, memiliki temporal atau spasialitas yang rendah.
Saat cache bekerja dengan baik . Ketika cache berfungsi dengan baik, lokalitasnya sangat tinggi, yaitu, menurut definisi, sebagian besar cache hampir tidak digunakan.
Dalam aplikasi di mana pola akses memori didefinisikan dengan baik dan dapat dipahami pada waktu kompilasi, yang berlaku untuk bahasa khas domain (DSL), programmer dan kompiler dapat mengoptimalkan penggunaan memori lebih baik daripada cache yang dialokasikan secara dinamis. Jadi, DSA biasanya menggunakan hierarki memori bergerak yang secara eksplisit dikontrol oleh perangkat lunak, mirip dengan cara kerja prosesor vektor. Dalam aplikasi yang sesuai, kontrol memori pengguna "manual" memungkinkan Anda menghabiskan energi jauh lebih sedikit daripada cache standar.
Ketiga, DSA dapat mengurangi akurasi perhitungan jika akurasi tinggi tidak diperlukan. CPU tujuan umum biasanya mendukung perhitungan bilangan bulat 32-bit dan 64-bit, serta data floating point (FP). Untuk banyak pembelajaran mesin dan aplikasi grafik, ini adalah akurasi yang berlebihan. Misalnya, dalam jaringan saraf yang dalam, perhitungan sering menggunakan angka 4-, 8-, atau 16-bit, meningkatkan throughput data dan kekuatan pemrosesan. Demikian pula, perhitungan floating-point berguna untuk melatih jaringan saraf, tetapi 32 bit, dan seringkali 16 bit, sudah cukup.
Akhirnya, manfaat DSA dari program yang ditulis dalam bahasa khusus domain yang memungkinkan lebih banyak konkurensi, meningkatkan struktur, penyajian akses memori, dan menyederhanakan overlay aplikasi yang efisien pada prosesor khusus.
Bahasa Berorientasi Subjek
DSA mensyaratkan operasi tingkat tinggi disesuaikan dengan arsitektur prosesor, tetapi sangat sulit dilakukan dalam bahasa tujuan umum seperti Python, Java, C, atau Fortran. Bahasa khusus domain (DSL) membantu dengan ini dan memungkinkan Anda untuk memprogram DSA secara efektif. Sebagai contoh, DSL dapat membuat vektor eksplisit, matriks padat, dan operasi matriks sparse eksplisit, memungkinkan kompiler DSL memetakan operasi secara efisien ke prosesor. Di antara bahasa khusus domain adalah Matlab, bahasa untuk bekerja dengan matriks, TensorFlow untuk pemrograman jaringan saraf, P4 untuk pemrograman jaringan yang ditentukan perangkat lunak, dan Halide untuk memproses gambar dengan transformasi tingkat tinggi.
Masalah DSL adalah bagaimana menjaga independensi arsitektur yang cukup sehingga perangkat lunak di atasnya dapat porting ke berbagai arsitektur, sambil mencapai efisiensi tinggi ketika membandingkan perangkat lunak dengan DSA dasar. Misalnya,
sistem XLA menerjemahkan kode
Tensorflow ke sistem heterogen dengan GPU Nvidia atau prosesor tensor (TPU). Menyeimbangkan portabilitas antara DSA sambil mempertahankan efisiensi adalah tugas penelitian yang menarik bagi pengembang bahasa, kompiler, dan DSA sendiri.
Contoh DSA: TPU v1
Sebagai contoh DSA, pertimbangkan Google TPU v1, yang dirancang untuk mempercepat pengoperasian jaringan saraf (
1 ,
2 ). TPU ini telah diproduksi sejak 2015, dan banyak aplikasi telah berjalan di atasnya: dari permintaan pencarian untuk terjemahan teks dan pengenalan gambar di AlphaGo dan AlphaZero, program DeepMind untuk bermain go dan catur. Tujuannya adalah untuk meningkatkan produktivitas dan efisiensi energi dari jaringan saraf dalam sebanyak 10 kali.
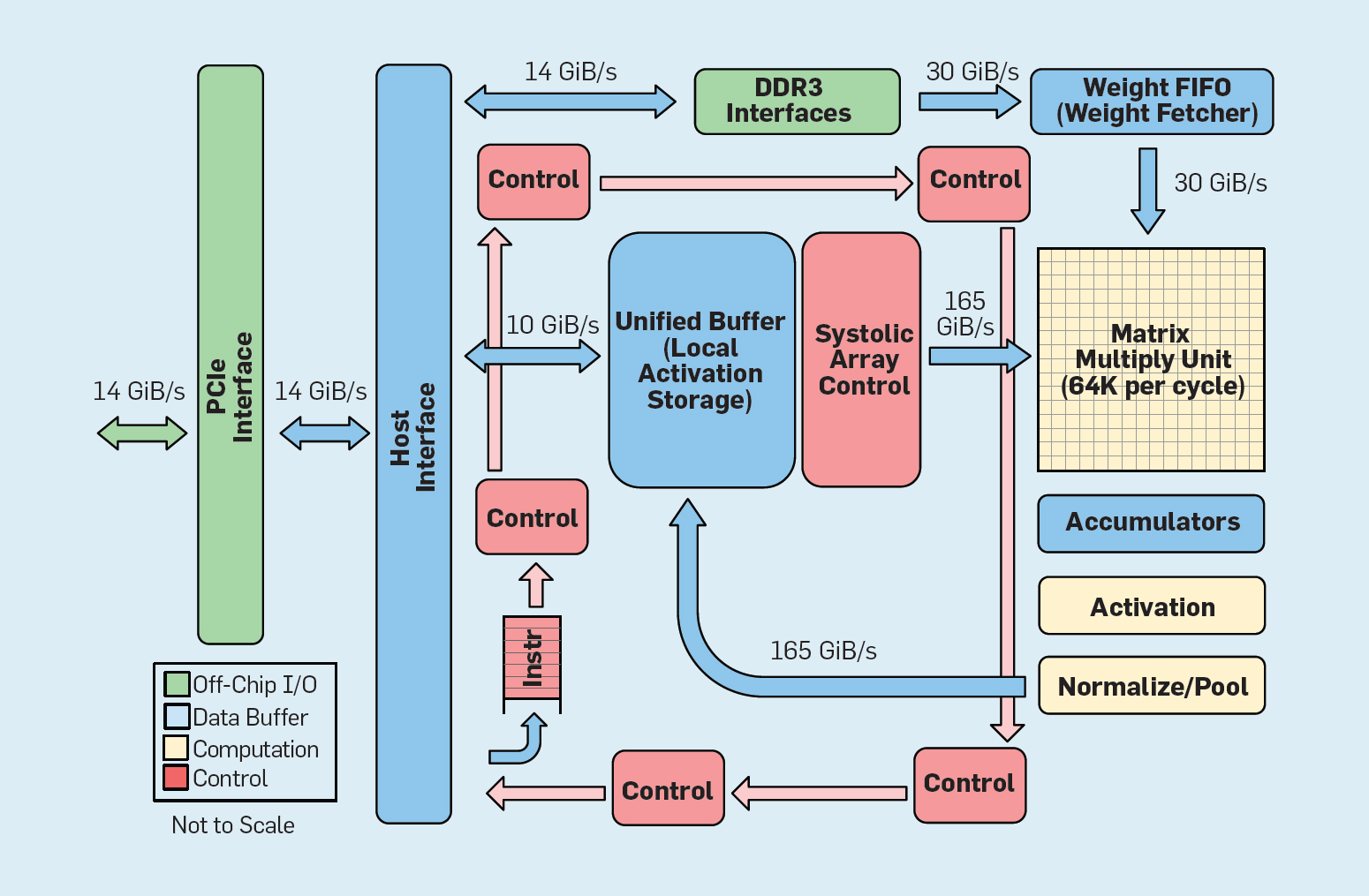 Fig. 8. Organisasi Fungsional Unit Pemrosesan Google Tensor (TPU v1)
Fig. 8. Organisasi Fungsional Unit Pemrosesan Google Tensor (TPU v1)Seperti yang ditunjukkan pada Gambar 8, organisasi TPU secara radikal berbeda dari prosesor untuk keperluan umum. Unit komputasi utama adalah unit matriks,
struktur susunan sistolik , yang setiap siklusnya menghasilkan 256 × 256 akumulasi berlipat ganda. Kombinasi dari akurasi 8-bit, struktur sistolik yang sangat efisien, kontrol SIMD dan alokasi bagian penting dari chip untuk fungsi ini membantu untuk melakukan operasi penggandaan multiplikasi sekitar 100 kali lebih banyak per siklus daripada inti CPU untuk keperluan umum. Alih-alih cache, TPU menggunakan memori lokal 24 MB, yang kira-kira dua kali lipat dari cache tujuan umum tahun 2015 dengan TDP yang sama. Akhirnya, kedua memori aktivasi neuron dan memori keseimbangan jaringan saraf (termasuk struktur FIFO yang menyimpan bobot) dihubungkan melalui saluran berkecepatan tinggi yang dikendalikan oleh pengguna. Kinerja TPU rata-rata tertimbang untuk enam masalah tipikal dari output logis dari jaringan saraf di pusat data Google adalah 29 kali lebih tinggi daripada prosesor tujuan umum. Karena TPU membutuhkan kurang dari setengah daya, efisiensi energinya untuk beban kerja ini lebih dari 80 kali lipat dari prosesor tujuan umum.
Ringkasan
Kami memeriksa dua pendekatan berbeda untuk meningkatkan kinerja program dengan meningkatkan efisiensi penggunaan teknologi perangkat keras. Pertama, dengan meningkatkan produktivitas bahasa modern tingkat tinggi yang biasanya ditafsirkan. Kedua, dengan menciptakan arsitektur untuk bidang subjek tertentu, yang secara signifikan meningkatkan kinerja dan efisiensi dibandingkan dengan prosesor tujuan umum. Bahasa khusus domain adalah contoh lain tentang cara meningkatkan antarmuka perangkat keras-lunak yang memungkinkan inovasi arsitektur seperti DSA. Untuk mencapai keberhasilan yang signifikan menggunakan pendekatan seperti itu, tim proyek yang terintegrasi secara vertikal akan diperlukan yang berpengalaman dalam aplikasi, bahasa yang berorientasi subjek dan teknologi kompilasi yang terkait, arsitektur komputer, serta teknologi implementasi dasar. Kebutuhan untuk integrasi vertikal dan membuat keputusan desain pada berbagai tingkat abstraksi adalah tipikal untuk sebagian besar pekerjaan awal di bidang teknologi komputer sebelum industri menjadi terstruktur secara horizontal. Di era baru ini, integrasi vertikal menjadi lebih penting. Keuntungan akan diberikan kepada tim yang dapat menemukan dan menerima kompromi dan optimisasi yang kompleks.
Peluang ini telah menyebabkan lonjakan inovasi arsitektur, menarik banyak filosofi arsitektur yang bersaing:
GPU GPU Nvidia
menggunakan beberapa core, masing-masing dengan file register besar, beberapa stream perangkat keras, dan cache.
TPU Google
TPUs mengandalkan susunan sistolik dua dimensi yang besar dan memori yang dapat diprogram dengan chip.
FPGA Microsoft Corporation di pusat datanya
mengimplementasikan array yang dapat diprogram pengguna (FPGA), yang digunakan dalam aplikasi jaringan saraf.
CPU Intel menawarkan prosesor dengan banyak inti, cache multi-level besar dan instruksi SIMD satu dimensi, dalam beberapa cara seperti Microsoft FPGA, dan
neuroprosesor baru lebih dekat ke TPU daripada ke CPU .
Selain para pemain utama ini,
puluhan startup menerapkan ide mereka sendiri . Untuk memenuhi permintaan yang terus meningkat, desainer menggabungkan ratusan dan ribuan chip untuk membuat superkomputer jaringan saraf.
Longsor ini arsitektur jaringan saraf menunjukkan waktu yang menarik telah datang dalam sejarah arsitektur komputer. Pada tahun 2019, sulit untuk memprediksi yang mana dari banyak area ini yang akan menang (jika ada yang menang sama sekali), tetapi pasar pasti akan menentukan hasilnya, seperti yang telah menyelesaikan debat arsitektur masa lalu.
Arsitektur terbuka
Mengikuti contoh perangkat lunak open source yang berhasil, ISA terbuka merupakan peluang alternatif dalam arsitektur komputer. Mereka diperlukan untuk membuat semacam "Linux untuk prosesor", sehingga komunitas dapat membuat kernel open source selain perusahaan individual yang memiliki kernel proprietary. Jika banyak organisasi mendesain prosesor menggunakan ISA yang sama, lebih banyak kompetisi dapat menghasilkan inovasi yang lebih cepat. Tujuannya adalah menyediakan arsitektur untuk prosesor yang biayanya mulai dari beberapa sen hingga $ 100.
Contoh pertama adalah RISC-V (RISC Five),
arsitektur RISC kelima yang dikembangkan di University of California di Berkeley . Dia didukung oleh komunitas yang dipimpin oleh
RISC-V Foundation .
Keterbukaan arsitektur memungkinkan evolusi ISA terjadi di mata publik, dengan keterlibatan para ahli sampai keputusan akhir dibuat. Keuntungan tambahan dari dana terbuka adalah bahwa ISA tidak mungkin berkembang terutama karena alasan pemasaran, karena kadang-kadang ini adalah satu-satunya penjelasan untuk perluasan set instruksi mereka sendiri.RISC-V adalah set instruksi modular. Basis instruksi kecil meluncurkan tumpukan perangkat lunak sumber terbuka penuh, diikuti oleh ekstensi standar tambahan yang dapat diaktifkan atau dinonaktifkan perancang tergantung pada kebutuhan mereka. Database ini berisi versi 32-bit dan 64-bit alamat. RISC-V hanya dapat tumbuh melalui ekstensi opsional; tumpukan perangkat lunak akan tetap berfungsi dengan baik, bahkan jika arsitek tidak menerima ekstensi baru. Arsitektur eksklusif biasanya memerlukan kompatibilitas ke atas pada tingkat biner: ini berarti bahwa jika perusahaan prosesor menambahkan fitur baru, semua prosesor masa depan juga harus memasukkannya. RISC-V tidak, di sini semua perangkat tambahan adalah opsional dan dapat dihapus jika aplikasi tidak membutuhkannya.Berikut adalah ekstensi standar saat ini, dengan huruf pertama dari nama lengkap:- M. Perkalian / pembagian bilangan bulat.
- A. Operasi memori atom.
- F / d. Operasi floating point presisi tunggal / ganda.
- C. Instruksi terkompresi.
Ciri ketiga RISC-V adalah kesederhanaan ISA. Meskipun indikator ini tidak dapat diukur, berikut adalah dua perbandingan arsitektur ARMv8, yang dikembangkan secara paralel oleh ARM:- Instruksi lebih sedikit . RISC-V memiliki instruksi yang jauh lebih sedikit. Ada 50 di dalam database, dan secara mengejutkan jumlah dan karakternya sama dengan RISC-I asli . Sisa dari ekstensi standar (M, A, F, dan D) menambahkan 53 instruksi, ditambah C menambahkan 34 lebih, sehingga jumlahnya total 137. Sebagai perbandingan, ARMv8 memiliki lebih dari 500 instruksi.
- . RISC-V : , ARMv8 14.
Kesederhanaan menyederhanakan mendesain desain prosesor dan memeriksa kebenarannya. Karena RISC-V berfokus pada segala sesuatu mulai dari pusat data hingga perangkat IoT, validasi desain dapat menjadi bagian penting dari biaya pengembangan.Keempat, RISC-V adalah desain clean-sheet setelah 25 tahun, di mana arsitek belajar dari kesalahan pendahulunya. Tidak seperti arsitektur RISC generasi pertama, arsitektur mikro menghindari atau fungsi yang bergantung pada teknologi (seperti cabang yang ditangguhkan dan unduhan yang tertunda) atau inovasi (seperti register windows), yang telah digantikan oleh kemajuan kompiler.Akhirnya, RISC-V mendukung DSA, memesan ruang opcode yang luas untuk akselerator khusus.Selain RISC-V, Nvidia juga mengumumkan (pada 2017)Arsitektur yang bebas dan terbuka , ia menyebutnya Nvidia Deep Learning Accelerator (NVDLA). Ini adalah DSA yang dapat disesuaikan dan dapat disesuaikan untuk inferensi dalam pembelajaran mesin. Parameter konfigurasi termasuk tipe data (int8, int16 atau fp16) dan ukuran matriks perkalian dua dimensi. Skala substrat silikon bervariasi dari 0,5 mm² hingga 3 mm², dan konsumsi energi dari 20 mW hingga 300 mW. ISA, tumpukan perangkat lunak, dan implementasi terbuka.Arsitektur terbuka dan sederhana cocok dengan keamanan. Pertama, pakar keamanan tidak percaya pada keamanan melalui ketidakjelasan, sehingga implementasi open source menarik, dan implementasi open source membutuhkan arsitektur terbuka. Yang tak kalah penting adalah peningkatan jumlah orang dan organisasi yang dapat berinovasi di bidang arsitektur yang aman. Arsitektur eksklusif membatasi partisipasi karyawan, tetapi arsitektur terbuka memungkinkan pikiran terbaik di dunia akademis dan industri membantu keamanan. Akhirnya, kesederhanaan RISC-V menyederhanakan verifikasi implementasinya. Selain itu, arsitektur terbuka, implementasi, dan tumpukan perangkat lunak, serta fleksibilitas FPGA, berarti bahwa arsitek dapat menggunakan dan mengevaluasi solusi baru secara online dengan siklus rilis mingguan dan tahunan. Meskipun FPGA 10 kali lebih lambat dari chip khusus,tetapi kinerja mereka cukup untuk bekerja online dan memamerkan inovasi keamanan di depan penyerang nyata untuk verifikasi. Kami berharap arsitektur terbuka menjadi contoh desain perangkat keras dan perangkat lunak kolaboratif oleh arsitek dan pakar keamanan.Pengembangan perangkat keras yang fleksibel
Manifesto Pengembangan Perangkat Lunak Fleksibel (2001) Beck dkk. Merevolusi pengembangan perangkat lunak dengan menghilangkan masalah sistem air terjun tradisional berdasarkan perencanaan dan dokumentasi. Tim kecil programmer dengan cepat membuat prototipe yang berfungsi, tetapi tidak lengkap, dan menerima umpan balik pelanggan sebelum memulai iterasi berikutnya. Versi Scrum dari Agile mengumpulkan tim yang terdiri dari lima hingga sepuluh programmer yang berlari selama dua hingga empat minggu per iterasi.Setelah meminjam ide dari pengembangan perangkat lunak lagi, adalah mungkin untuk mengatur pengembangan perangkat keras yang fleksibel. Berita baiknya adalah bahwa alat bantu desain komputer elektronik (ECAD) modern telah meningkatkan tingkat abstraksi, memungkinkan pengembangan yang fleksibel. Level abstraksi yang lebih tinggi ini juga meningkatkan tingkat penggunaan kembali pekerjaan antara desain yang berbeda.Sprint empat minggu tampaknya tidak masuk akal bagi prosesor, mengingat berbulan-bulan antara saat pembuatan desain dan produksi chip. Dalam gbr. Gambar 9 menunjukkan bagaimana metode yang fleksibel dapat bekerja dengan memodifikasi prototipe pada tingkat yang sesuai .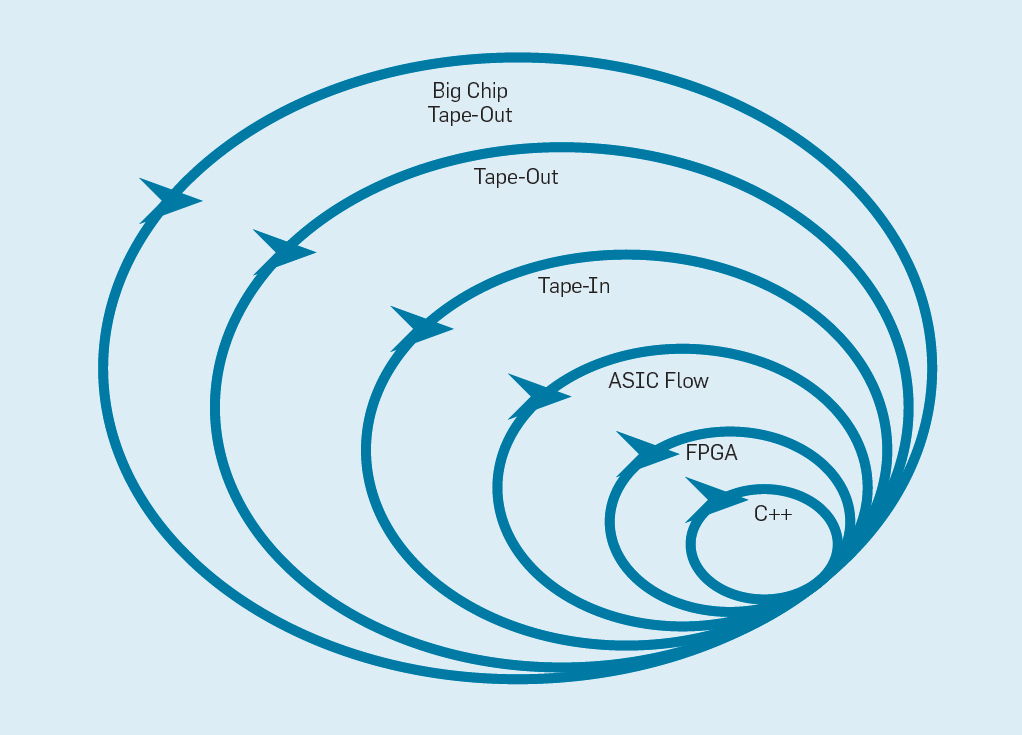 Fig. 9. Metodologi pengembangan peralatan yang fleksibelLevel terdalam adalah simulator perangkat lunak, tempat termudah dan tercepat untuk melakukan perubahan. Level selanjutnya adalah chip FPGA, yang dapat bekerja ratusan kali lebih cepat daripada simulator perangkat lunak terperinci. FPGA dapat bekerja dengan sistem operasi dan tolok ukur penuh, seperti Standard Performance Evaluation Corporation (SPEC), yang memungkinkan evaluasi prototipe yang jauh lebih akurat. Amazon Web Services menawarkan FPGA di cloud, sehingga arsitek dapat menggunakan FPGA tanpa harus membeli peralatan terlebih dahulu dan mendirikan laboratorium. Tingkat selanjutnya menggunakan alat ECAD untuk menghasilkan sirkuit chip, untuk mendokumentasikan ukuran dan konsumsi daya. Bahkan setelah alat bekerja, perlu untuk mengikuti beberapa langkah manual untuk memperbaiki hasil sebelum mengirim prosesor baru ke produksi.Pengembang prosesor menyebut ini level berikutnya.pita di . Empat level pertama ini mendukung sprint empat minggu.Untuk tujuan penelitian, kita bisa berhenti di level empat, karena perkiraan area, energi, dan kinerja sangat akurat. Tapi itu seperti pelari berlari maraton dan berhenti 5 meter sebelum finish, karena waktu finishnya sudah jelas. Meskipun persiapan yang sulit untuk maraton, ia akan kehilangan sensasi dan kesenangan untuk benar-benar melewati garis finish. Salah satu kelebihan insinyur perangkat keras daripada insinyur perangkat lunak adalah mereka menciptakan benda-benda fisik. Mendapatkan keripik dari pabrik: mengukur, menjalankan program nyata, menunjukkannya kepada teman dan keluarga adalah sukacita besar bagi perancang.Banyak peneliti percaya mereka harus berhenti karena pembuatan chip terlalu terjangkau. Tetapi jika desainnya kecil, itu mengejutkan murah. Insinyur dapat memesan 100 microchip berukuran 1 mm² hanya dengan $ 14.000. Pada 28 nm, chip 1 mm² berisi jutaan transistor: ini sudah cukup untuk prosesor RISC-V dan akselerator NVLDA. Tingkat paling eksternal mahal jika perancang berniat untuk membuat chip besar, tetapi banyak ide baru dapat ditunjukkan pada chip kecil.
Fig. 9. Metodologi pengembangan peralatan yang fleksibelLevel terdalam adalah simulator perangkat lunak, tempat termudah dan tercepat untuk melakukan perubahan. Level selanjutnya adalah chip FPGA, yang dapat bekerja ratusan kali lebih cepat daripada simulator perangkat lunak terperinci. FPGA dapat bekerja dengan sistem operasi dan tolok ukur penuh, seperti Standard Performance Evaluation Corporation (SPEC), yang memungkinkan evaluasi prototipe yang jauh lebih akurat. Amazon Web Services menawarkan FPGA di cloud, sehingga arsitek dapat menggunakan FPGA tanpa harus membeli peralatan terlebih dahulu dan mendirikan laboratorium. Tingkat selanjutnya menggunakan alat ECAD untuk menghasilkan sirkuit chip, untuk mendokumentasikan ukuran dan konsumsi daya. Bahkan setelah alat bekerja, perlu untuk mengikuti beberapa langkah manual untuk memperbaiki hasil sebelum mengirim prosesor baru ke produksi.Pengembang prosesor menyebut ini level berikutnya.pita di . Empat level pertama ini mendukung sprint empat minggu.Untuk tujuan penelitian, kita bisa berhenti di level empat, karena perkiraan area, energi, dan kinerja sangat akurat. Tapi itu seperti pelari berlari maraton dan berhenti 5 meter sebelum finish, karena waktu finishnya sudah jelas. Meskipun persiapan yang sulit untuk maraton, ia akan kehilangan sensasi dan kesenangan untuk benar-benar melewati garis finish. Salah satu kelebihan insinyur perangkat keras daripada insinyur perangkat lunak adalah mereka menciptakan benda-benda fisik. Mendapatkan keripik dari pabrik: mengukur, menjalankan program nyata, menunjukkannya kepada teman dan keluarga adalah sukacita besar bagi perancang.Banyak peneliti percaya mereka harus berhenti karena pembuatan chip terlalu terjangkau. Tetapi jika desainnya kecil, itu mengejutkan murah. Insinyur dapat memesan 100 microchip berukuran 1 mm² hanya dengan $ 14.000. Pada 28 nm, chip 1 mm² berisi jutaan transistor: ini sudah cukup untuk prosesor RISC-V dan akselerator NVLDA. Tingkat paling eksternal mahal jika perancang berniat untuk membuat chip besar, tetapi banyak ide baru dapat ditunjukkan pada chip kecil.Kesimpulan
"Jam paling gelap adalah sebelum fajar" - Thomas Fuller, 1650Untuk mengambil manfaat dari pelajaran sejarah, pencipta prosesor harus memahami bahwa banyak yang dapat diadopsi dari industri perangkat lunak, bahwa meningkatkan tingkat abstraksi antarmuka perangkat keras / perangkat lunak memberikan peluang untuk inovasi dan bahwa pasar dalam pada akhirnya menentukan pemenang. iAPX-432 dan Itanium menunjukkan bagaimana investasi dalam arsitektur tidak dapat melakukan apa-apa, sementara S / 360, 8086, dan ARM telah memberikan hasil tinggi selama beberapa dekade, tanpa akhir yang terlihat.Penyelesaian hukum Moore dan penskalaan Dennard, serta perlambatan kinerja mikroprosesor standar, bukanlah masalah yang harus dipecahkan, tetapi mengingat bahwa, seperti yang Anda ketahui, menawarkan peluang menarik. Bahasa dan arsitektur berorientasi subjek tingkat tinggi, terbebas dari rangkaian set instruksi berpemilik, bersama dengan permintaan publik akan keamanan yang meningkat, akan membuka era keemasan baru untuk arsitektur komputer. Dalam ekosistem open source, chip yang dirancang secara artifisial akan secara meyakinkan menunjukkan pencapaian dan dengan demikian mempercepat implementasi komersial. Filosofi prosesor tujuan umum dalam chip ini kemungkinan adalah RISC, yang telah teruji oleh waktu. Harapkan inovasi cepat yang sama seperti yang Anda lakukan selama masa keemasan terakhir,tapi kali ini dari segi biaya, energi dan keselamatan, bukan hanya kinerja.Pada dekade berikutnya, ledakan arsitektur komputer baru Kambria akan terjadi, yang berarti masa-masa yang menyenangkan bagi para arsitek komputer di dunia akademis dan industri.