
Ketika saya memperkenalkan diri dan mengatakan apa yang dilakukan startup kami, lawan bicaranya segera mengajukan pertanyaan: apakah Anda bekerja di Facebook sebelumnya, atau apakah perkembangan Anda dibuat di bawah pengaruh Facebook? Banyak yang menyadari upaya Facebook untuk mempertahankan grafik sosialnya, karena perusahaan telah menerbitkan
beberapa artikel tentang infrastruktur grafik ini, yang telah dibangun dengan cermat.
Google berbicara tentang
grafik pengetahuannya , tetapi tidak tentang infrastruktur internal. Namun, perusahaan juga memiliki subsistem khusus untuk itu. Faktanya, banyak perhatian diberikan pada grafik pengetahuan. Secara pribadi, saya menempatkan setidaknya dua promosi saya pada kuda ini - dan mulai mengerjakan grafik baru pada tahun 2010.
Google perlu membangun infrastruktur tidak hanya untuk melayani hubungan yang kompleks dalam Grafik Pengetahuan, tetapi juga untuk mendukung semua blok tematik
OneBox dalam hasil pencarian yang memiliki akses ke data terstruktur. Infrastruktur diperlukan untuk 1) pengelakan fakta yang berkualitas dengan 2) throughput yang cukup tinggi dan 3) penundaan yang cukup rendah untuk mengelola masuk ke bagian yang baik dari permintaan pencarian di web. Ternyata tidak satu pun sistem atau basis data yang tersedia dapat melakukan ketiga tindakan.
Sekarang saya telah menjelaskan mengapa infrastruktur diperlukan, di bagian selanjutnya dari artikel ini saya akan berbicara tentang pengalaman saya membangun sistem seperti itu, termasuk untuk
Grafik Pengetahuan dan
OneBox .
Bagaimana saya tahu itu?
Saya akan memperkenalkan diri secara singkat. Saya bekerja di Google dari 2006 hingga 2013. Pertama sebagai magang, kemudian sebagai insinyur perangkat lunak dalam infrastruktur pencarian web. Google
mengakuisisi Metaweb pada 2010, dan tim saya baru saja meluncurkan
Kafein . Saya ingin melakukan sesuatu yang lain - dan mulai bekerja dengan orang-orang dari Metaweb (di San Francisco), menghabiskan waktu bepergian antara San Francisco dan Mountain View. Saya ingin mengetahui cara menggunakan grafik pengetahuan untuk meningkatkan pencarian web saya.
Ada proyek semacam itu di Google sebelum saya. Perlu dicatat bahwa proyek bernama
Squared dibuat di kantor New York, dan ada beberapa pembicaraan tentang Kartu Pengetahuan. Kemudian ada upaya sporadis oleh individu / tim kecil, tetapi pada saat itu tidak ada rantai tim yang mapan, yang akhirnya memaksa saya untuk meninggalkan Google. Tapi kita akan kembali ke ini nanti ...
Sejarah Metaweb
Seperti yang telah disebutkan, Google mengakuisisi Metaweb pada 2010. Metaweb membangun grafik pengetahuan berkualitas tinggi menggunakan beberapa metode, termasuk merangkak dan parsing Wikipedia, serta sistem editing gaya wiki crowdsourcing menggunakan
Freebase . Semua ini bekerja berdasarkan basis data grafik Graphd sendiri - daemon grafik (sekarang
diterbitkan di GitHub).
Graphd memiliki beberapa properti yang cukup tipikal. Sebagai daemon, ini berfungsi pada satu server, menyimpan semua data dalam memori dan dapat mengeluarkan seluruh situs Freebase. Setelah pembelian, Google menetapkan salah satu tugas untuk terus bekerja dengan Freebase.
Google membangun kerajaan pada perangkat keras standar dan perangkat lunak terdistribusi. Satu DBMS sisi server tidak akan pernah bisa melayani hasil perayapan, pengindeksan, dan pencarian. Pertama-tama dibuat SSTable, kemudian Bigtable, yang menskala secara horizontal ke ratusan atau ribuan mesin yang berbagi petabyte data. Mesin dialokasikan oleh Borg (
K8 berasal dari sini), mereka berkomunikasi melalui Stubby (gRPC datang dari sini) dengan menyelesaikan alamat IP melalui layanan nama Borg (BNC di dalam K8) dan menyimpan data dalam Sistem File Google (
GFS , Anda dapat mengatakan Hadoop FS).
Proses dapat mati, mesin dapat rusak, tetapi sistem secara keseluruhan tidak dapat dihancurkan dan akan terus bersenandung.Graphd masuk ke lingkungan seperti itu. Gagasan tentang database yang melayani seluruh situs web pada satu server adalah asing bagi Google (termasuk saya). Secara khusus, Graphd membutuhkan 64 GB atau lebih banyak memori untuk dijalankan. Jika menurut Anda ini sedikit, ingat: ini 2010. Sebagian besar server Google dilengkapi dengan maksimum 32 GB. Faktanya, Google harus membeli mesin khusus dengan RAM yang cukup untuk melayani Graphd dalam bentuknya saat ini.
Penggantian Graphd
Brainstorming dimulai tentang cara memindahkan data Graphd atau menulis ulang sistem untuk bekerja secara terdistribusi. Tapi, Anda lihat, grafiknya rumit. Ini bukan basis data nilai kunci untuk Anda, di mana Anda bisa mengambil sepotong data, memindahkannya ke server lain dan mengeluarkannya saat Anda meminta kunci. Grafik melakukan gabungan dan penyelesaian yang efisien yang memerlukan perangkat lunak untuk bekerja dengan cara tertentu.
Satu ide adalah menggunakan proyek yang disebut MindMeld (IIRC). Diasumsikan bahwa memori dari server lain akan tersedia jauh lebih cepat melalui peralatan jaringan. Seharusnya lebih cepat daripada RPC biasa, cukup cepat untuk mereplikasi semu akses memori langsung yang diperlukan oleh database dalam memori. Tapi idenya tidak terlalu jauh.
Gagasan lain yang benar-benar menjadi proyek adalah untuk menciptakan sistem layanan grafik yang benar-benar terdistribusi. Sesuatu yang tidak hanya dapat menggantikan Graphd untuk Freebase, tetapi juga benar-benar berfungsi dalam produksi.
Dia disebut Dgraph - grafik terdistribusi, terbalik dari Graphd (graph-daemon).Jika Anda tertarik, maka ya. Startup saya, Dgraph Labs, perusahaan, dan proyek open source Dgraph diberi nama setelah proyek itu di Google (catatan: Dgraph adalah merek dagang dari Dgraph Labs; Sejauh yang saya tahu, Google tidak merilis proyek dengan nama yang cocok dengan yang internal).
Di hampir semua sisa teks, ketika saya menyebutkan Dgraph, maksud saya proyek internal Google, dan bukan proyek open source yang kami buat. Tetapi lebih lanjut tentang
itu nanti.
Kisah Cerebro: mesin pengetahuan
Membuat infrastruktur untuk grafik secara tidak sengajaMeskipun saya umumnya tahu tentang Dgraph yang mencoba mengganti Graphd, tujuan saya adalah menciptakan sesuatu untuk meningkatkan pencarian web. Di Metaweb, saya bertemu dengan seorang insinyur penelitian DH yang menciptakan
Cubed .
Seperti yang saya sebutkan, sekelompok insinyur beragam dari divisi New York mengembangkan Google
Squared . Tetapi sistem DH
jauh lebih baik. Saya mulai berpikir bagaimana menerapkannya di Google. Google memiliki potongan puzzle yang dapat saya gunakan dengan mudah.
Bagian pertama dari teka-teki adalah mesin pencari. Ini adalah cara untuk secara akurat menentukan kata-kata yang terkait satu sama lain. Misalnya, ketika Anda melihat frasa seperti [film tom hanks], itu mungkin memberi tahu Anda bahwa [tom] dan [hanks] terkait. Demikian pula, dari [san francisco weather] kita melihat hubungan antara [san] dan [francisco]. Ini adalah hal yang jelas bagi orang-orang, tetapi tidak begitu jelas untuk mobil.
Bagian kedua dari teka-teki adalah memahami tata bahasa. Ketika dalam permintaan [buku oleh penulis Perancis], mesin dapat menafsirkan ini sebagai [buku] dari [penulis Perancis], yaitu, buku-buku dari penulis yang berasal dari Perancis. Tapi dia juga bisa menafsirkan ini sebagai [buku Prancis] dari [penulis], yaitu buku dalam bahasa Prancis oleh penulis mana pun. Saya menggunakan
tag-part-of-speech (POS) dari Stanford University untuk mengurai tata bahasa dengan lebih baik dan membangun pohon.
Bagian ketiga dari teka-teki adalah memahami entitas. [Perancis] bisa sangat berarti. Ini mungkin sebuah negara (wilayah), kebangsaan (terkait dengan orang Prancis), masakan (terkait dengan makanan) atau bahasa. Kemudian saya menerapkan sistem lain untuk mendapatkan daftar entitas yang dapat disesuaikan dengan kata atau frasa.
Bagian keempat dari teka-teki adalah untuk memahami hubungan antara entitas. Ketika diketahui bagaimana menghubungkan kata-kata ke dalam frasa, dalam urutan frasa apa yang harus dilakukan, yaitu, tata bahasa mereka, dan entitas mana yang dapat mereka padukan, Anda perlu menemukan hubungan antara entitas-entitas ini untuk membuat interpretasi mesin. Misalnya, kami menjalankan kueri [buku oleh penulis Prancis], dan POS mengatakan itu adalah [buku] dari [penulis Prancis]. Kami memiliki beberapa entitas untuk [Perancis] dan beberapa untuk [penulis]: algoritma harus menentukan bagaimana mereka terkait. Misalnya, mereka mungkin terkait dengan tempat kelahiran, yaitu, penulis yang lahir di Prancis (walaupun mereka dapat menulis dalam bahasa Inggris). Atau bisa juga penulis yang merupakan warga negara Prancis. Entah penulis yang bisa berbicara atau menulis bahasa Prancis (tetapi mungkin tidak terkait dengan Prancis sebagai negara), atau penulis yang hanya menyukai masakan Prancis.
Indeks Sistem Pencarian Indeks
Untuk menentukan apakah ada koneksi antara objek dan bagaimana mereka terhubung, Anda memerlukan sistem grafik. Graphd tidak akan pernah naik ke tingkat Google, tetapi Anda dapat menggunakan pencarian itu sendiri. Data Grafik Pengetahuan disimpan dalam format tiga kali lipat, yaitu, setiap fakta diwakili oleh tiga bagian: subjek (entitas), predikat (relasi) dan objek (entitas lain). Permintaan seperti
[SP] → [O] atau
[PO] → [S] , dan kadang-kadang
[SO] → [P] .
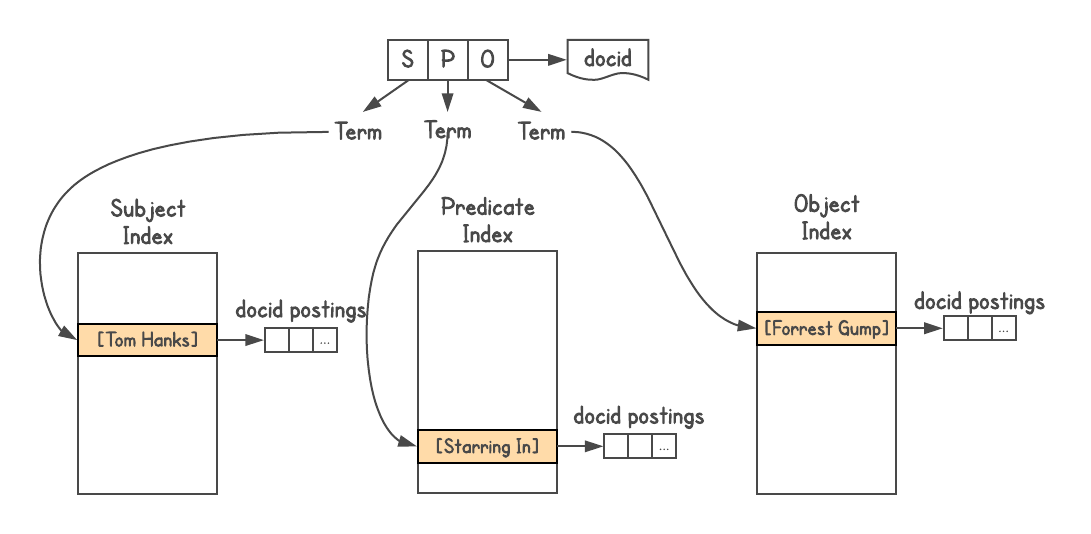 Saya menggunakan indeks pencarian Google
Saya menggunakan indeks pencarian Google , menetapkan sebuah dokumen untuk setiap tiga, dan membangun tiga indeks, satu untuk S, P, dan O. Selain itu, indeks ini bersarang, jadi saya menambahkan informasi tentang jenis setiap entitas (yaitu, aktor, buku, orang, dan dll.)
Saya membuat sistem seperti itu, meskipun saya melihat masalah dengan kedalaman gabungan (yang dijelaskan di bawah) dan tidak cocok untuk pertanyaan kompleks. Sebenarnya, ketika seseorang dari tim Metaweb meminta saya untuk menerbitkan sistem untuk kolega, saya menolak.Untuk menentukan hubungan, Anda dapat melihat berapa banyak hasil yang diberikan setiap kueri. Misalnya, berapa banyak hasil yang [Perancis] dan [penulis] berikan? Kami mengambil hasil ini dan melihat bagaimana mereka terkait dengan [buku], dll. Dengan demikian, banyak interpretasi mesin dari kueri muncul. Misalnya, kueri [film tom hanks] menghasilkan beragam interpretasi, seperti [film yang disutradarai oleh tom hanks], [film yang dibintangi tom hanks], [film yang diproduksi oleh tom hanks], tetapi secara otomatis menolak interpretasi seperti [film bernama tom hanks].
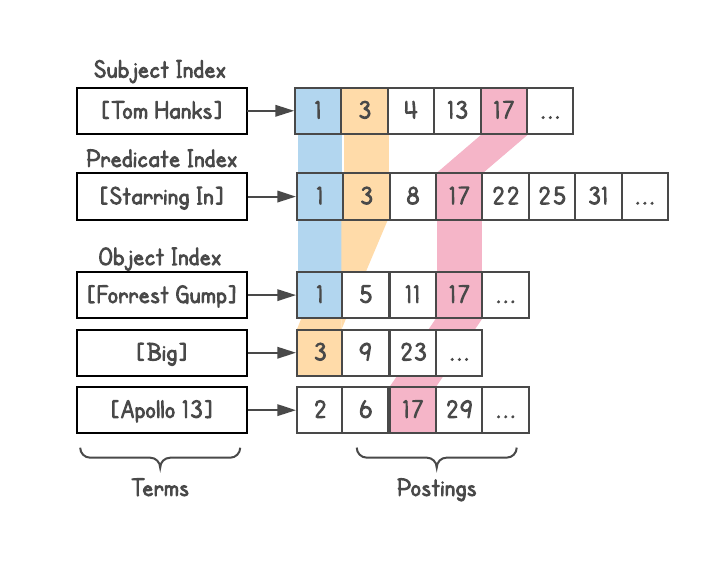
Setiap interpretasi menghasilkan daftar hasil - entitas yang valid pada grafik - dan juga mengembalikan tipenya (ada dalam lampiran). Ini terbukti menjadi fungsi yang sangat kuat karena memahami jenis hasil membuka kemungkinan seperti penyaringan, penyortiran, atau ekspansi lebih lanjut. Anda dapat memilah film dengan tahun rilis, panjang film (pendek, panjang), bahasa, penghargaan yang diterima, dll.
Proyek ini tampak sangat cerdas sehingga kami (DH juga sebagian terlibat sebagai ahli pada grafik pengetahuan) menamakannya Cerebro, untuk menghormati perangkat dengan nama yang sama dari film
"X-Men" .
Cerebro sering mengungkapkan fakta yang
sangat menarik yang awalnya tidak ada dalam permintaan pencarian. Misalnya, atas permintaan [presiden AS], Cerebro akan menyadari bahwa presiden adalah orang, dan orang memiliki pertumbuhan. Ini memungkinkan kita untuk memilah presiden berdasarkan pertumbuhan dan menunjukkan bahwa Abraham Lincoln adalah presiden tertinggi Amerika Serikat. Selain itu, orang dapat disaring berdasarkan kebangsaan. Dalam hal ini, Amerika dan Inggris muncul dalam daftar, karena Amerika Serikat memiliki satu presiden Inggris, yaitu George Washington. (Penafian: hasilnya didasarkan pada keadaan grafik pengetahuan pada saat percobaan; saya tidak dapat menjamin kebenarannya).
Tautan biru versus pengetahuan
Cerebro mampu benar-benar memahami permintaan pengguna. Setelah menerima data untuk seluruh grafik, kami dapat menghasilkan interpretasi mesin dari kueri, menghasilkan daftar hasil, dan memahami banyak dari hasil ini untuk studi lebih lanjut dari grafik. Dijelaskan di atas: begitu sistem memahami bahwa ia berurusan dengan film, orang atau buku, dll., Filter dan jenis tertentu dapat diaktifkan. Anda bahkan dapat berkeliling node dan menunjukkan informasi terkait: dari [presiden AS] ke [sekolah mereka pergi] atau [anak-anak mereka ayah]. Berikut adalah beberapa pertanyaan lain yang dihasilkan oleh sistem itu sendiri: [politisi perempuan Afrika Amerika], [aktor bollywood menikah dengan politisi], [anak-anak kita presiden], [film yang dibintangi tom hanks dirilis pada 90-an]
DH menunjukkan kesempatan ini untuk berpindah dari satu daftar ke daftar lainnya dalam proyek lain yang disebut
Parallax .
Cerebro menunjukkan hasil yang sangat mengesankan, dan manajemen Metaweb mendukungnya. Bahkan dalam hal infrastruktur, ternyata menjadi efisien dan fungsional. Saya menyebutnya
mesin pengetahuan (seperti mesin pencari). Tetapi di Google, tidak ada yang secara khusus membahas topik ini. Dia tidak terlalu tertarik pada manajer saya, mereka menyarankan saya untuk berbicara dengan satu orang, kemudian dengan orang lain, dan sebagai hasilnya saya mendapat kesempatan untuk mendemonstrasikan sistem tersebut kepada seorang manajer pencarian yang sangat tinggi.
Jawabannya bukan yang saya harapkan . Untuk menunjukkan hasil dari mesin pengetahuan untuk [buku karya penulis Perancis], ia meluncurkan pencarian Google, menunjukkan sepuluh baris dengan tautan biru dan mengatakan bahwa Google dapat melakukan hal yang sama. Selain itu, mereka tidak ingin mengambil traffic dari situs, karena mereka marah.
Jika Anda berpikir dia benar, pikirkan ini: ketika Google melakukan pencarian di Internet, itu benar-benar tidak mengerti permintaan. Sistem mencari kata-kata yang tepat di posisi yang tepat, dengan mempertimbangkan berat halaman dan seterusnya. Ini adalah sistem yang sangat kompleks, tetapi tidak memahami kueri atau hasil. Pengguna sendiri melakukan semua pekerjaan: membaca, menganalisis, mengekstraksi informasi yang diperlukan dari hasil dan pencarian lebih lanjut, menambahkan bersama daftar hasil lengkap, dll.
Misalnya, untuk [buku karya penulis Prancis] seseorang pertama-tama akan mencoba menemukan daftar lengkap, meskipun satu halaman dengan daftar seperti itu mungkin tidak ditemukan. Kemudian urutkan buku-buku ini berdasarkan tahun penerbitan atau filter oleh penerbit dan sebagainya - semua ini membutuhkan seseorang untuk memproses sejumlah besar informasi, banyak pencarian dan proses hasilnya. Cerebro mampu mengurangi upaya ini dan membuat interaksi pengguna menjadi sederhana dan sempurna.
Tapi kemudian tidak ada pemahaman penuh tentang pentingnya grafik pengetahuan. Manual tidak yakin kegunaannya atau bagaimana menghubungkannya dengan pencarian.
Pendekatan baru terhadap pengetahuan ini tidak mudah bagi organisasi yang telah mencapai kesuksesan signifikan dengan menyediakan tautan ke halaman web kepada pengguna.Sepanjang tahun itu, saya berjuang dengan kesalahpahaman para manajer, dan akhirnya menyerah. Seorang manajer dari kantor Shanghai menoleh ke saya, dan saya menyerahkan proyek kepadanya pada Juni 2011. Dia menempatkannya sebuah tim yang terdiri dari 15 insinyur. Saya menghabiskan waktu satu minggu di Shanghai, menyampaikan kepada para insinyur segala yang saya buat dan pelajari. DH juga terlibat dalam bisnis ini, dan dia memimpin tim untuk waktu yang lama.
Gabung masalah mendalam
Dalam sistem grafik Cerebro, ada masalah dengan kedalaman serikat. Gabung dilakukan ketika hasil permintaan awal diperlukan untuk menyelesaikan yang berikutnya. Gabungan umum mencakup beberapa
SELECT , yaitu filter dalam hasil tertentu dari kumpulan data universal, dan kemudian hasil ini digunakan untuk memfilter oleh bagian lain dari kumpulan data. Saya akan jelaskan dengan sebuah contoh.
Katakan Anda ingin tahu [orang-orang di SF yang makan sushi]. Semua orang diberikan beberapa data, termasuk siapa yang tinggal di kota mana dan jenis makanan apa yang mereka makan.
Kueri di atas adalah gabungan satu level. Jika aplikasi mengakses database, itu akan membuat satu permintaan untuk langkah pertama. Kemudian beberapa pertanyaan (satu permintaan untuk setiap hasil) untuk mencari tahu apa yang dimakan setiap orang, hanya memilih mereka yang makan sushi.
Langkah kedua menderita masalah fan-out. Jika langkah pertama memberikan hasil jutaan (populasi San Francisco), maka langkah kedua harus diberikan atas permintaan kepada semua orang, meminta kebiasaan makan mereka, dan kemudian menerapkan filter.

Insinyur sistem terdistribusi biasanya menyelesaikan masalah ini dengan
siaran , yaitu dengan distribusi di mana-mana. Mereka mengakumulasikan hasil yang sesuai, membuat satu permintaan ke setiap server di cluster. Ini memberikan gabungan, tetapi menyebabkan masalah dengan latensi permintaan.
Penyiaran tidak bekerja dengan baik dalam sistem terdistribusi. Masalah ini paling baik dijelaskan oleh
Jeff Dean dari Google dalam pidatonya “Mencapai respons cepat dalam layanan online besar” (
video ,
slide ). Total keterlambatan selalu lebih besar daripada keterlambatan komponen paling lambat.
Silau kecil pada masing-masing komputer menyebabkan penundaan, dan dimasukkannya banyak komputer dalam kueri secara dramatis meningkatkan kemungkinan penundaan.Pertimbangkan server dengan keterlambatan lebih dari 1 ms dalam 50% kasus, dan lebih dari 1 detik dalam 1% kasus. Jika permintaan hanya ke satu server seperti itu, hanya 1% dari respons yang melebihi satu detik. Tetapi jika permintaan masuk ke ratusan server seperti itu, maka 63% dari tanggapan melebihi satu detik.
Dengan demikian, penyiaran satu permintaan sangat meningkatkan penundaan. Sekarang pikirkan, dan jika Anda membutuhkan dua, tiga, atau lebih asosiasi? Terlalu lambat untuk dieksekusi secara real time.
Masalah penyebaran penggemar ketika permintaan siaran melekat pada sebagian besar DB grafik non-pribumi, termasuk
grafik Janus ,
Twitter FlockDB, dan
TAO Facebook .
Asosiasi yang didistribusikan adalah masalah yang kompleks. Basis data grafik asli memungkinkan menghindari masalah ini dengan menyimpan kumpulan data universal dalam satu server (database yang berdiri sendiri) dan melakukan semua gabungan tanpa mengakses server lain. Sebagai contoh,
Neo4j melakukan ini.
Dgraph: serikat pekerja dengan kedalaman sewenang-wenang
Setelah menyelesaikan pekerjaan di Cerebro dan memiliki pengalaman membangun sistem manajemen grafik, saya mengambil bagian dalam proyek Dgraph, menjadi salah satu dari tiga manajer proyek teknis. Kami menerapkan konsep inovatif yang memecahkan masalah kedalaman serikat.
Secara khusus, Dgraph memisahkan data grafik sehingga setiap sambungan dapat sepenuhnya dilakukan oleh satu mesin. Kembali ke objek
subject-predicate-object (SPO), setiap instance Dgraph berisi semua subjek dan objek yang sesuai dengan masing-masing predikat dalam instance ini. Beberapa predikat disimpan dalam sebuah instance, masing-masing disimpan sepenuhnya.
Ini memungkinkan kami untuk memenuhi permintaan dengan asosiasi yang sewenang-wenang , menghilangkan masalah penyebaran penggemar selama siaran. Misalnya, kueri [orang-orang di SF yang makan sushi] akan menghasilkan
maksimal dua panggilan jaringan dalam database terlepas dari ukuran cluster. Tantangan pertama akan menemukan semua orang yang tinggal di San Francisco. Permintaan kedua akan mengirim daftar ini untuk bersinggungan dengan semua orang yang makan sushi. Kemudian Anda dapat menambahkan batasan atau ekstensi tambahan, setiap langkah masih menyediakan tidak lebih dari satu panggilan jaringan.

Ini menciptakan masalah predikat yang sangat besar pada server yang sama, tetapi dapat dipecahkan dengan membagi lebih lanjut predikat antara dua contoh atau lebih saat ukuran bertambah. Dalam kasus terburuk, satu predikat akan dibagi di seluruh kluster. Tetapi ini hanya akan terjadi dalam situasi yang fantastis, ketika semua data hanya sesuai dengan satu predikat. Dalam kasus lain, pendekatan ini dapat secara signifikan mengurangi keterlambatan permintaan dalam sistem nyata.
Sharding bukan satu-satunya inovasi dalam Dgraph. Semua objek diberi pengidentifikasi bilangan bulat, mereka diurutkan dan disimpan dalam bentuk daftar (daftar posting) untuk dengan cepat melintasi daftar tersebut nanti. Ini memungkinkan Anda untuk dengan cepat menyaring selama penggabungan, menemukan tautan umum, dll. Gagasan dari mesin pencari Google juga berguna di sini.
Menggabungkan semua blok OneBox melalui Plasma
Dgraph Google bukan database . Ini adalah salah satu subsistem, yang juga merespons pembaruan. Jadi dia perlu pengindeksan. Saya memiliki pengalaman luas bekerja dengan sistem pengindeksan inkremental real-time yang berjalan di bawah
Kafein .
Saya memulai sebuah proyek untuk menyatukan semua OneBox dalam sistem pengindeksan grafik ini, termasuk cuaca, jadwal penerbangan, acara dan sebagainya. Anda mungkin tidak tahu istilah OneBox, tetapi Anda pasti melihatnya - ini adalah jendela terpisah yang muncul ketika jenis kueri tertentu dijalankan, di mana Google mengembalikan informasi yang lebih kaya. Untuk melihat OneBox beraksi, coba [
cuaca di sf ].
Sebelumnya, masing-masing OneBox mengerjakan backend otonom dan didukung oleh berbagai kelompok pengembangan.
Ada banyak set data terstruktur, tetapi unit OneBox tidak saling bertukar data. Pertama, backend yang berbeda meningkatkan biaya tenaga kerja berkali-kali lipat. Kedua, kurangnya berbagi informasi membatasi rentang permintaan yang dapat ditanggapi oleh Google.
Misalnya, [acara di SF] dapat menampilkan acara, dan [cuaca di SF] dapat menunjukkan cuaca. Tetapi jika [acara di SF] mengerti bahwa sekarang hujan, maka Anda dapat menyaring atau mengurutkan acara berdasarkan jenis "di dalam ruangan" atau "di luar rumah" (
mungkin lebih baik pergi ke bioskop daripada sepak bola dalam hujan lebat) )
Dengan bantuan tim Metaweb, kami mulai mengubah semua data ini ke format SPO dan mengindeksnya dengan satu sistem. Saya menamainya
Plasma, mesin pengindeksan grafik waktu-nyata untuk melayani Dgraph.
Manajemen Leapfrog
Seperti Cerebro, proyek Plasma menerima sedikit sumber daya, tetapi terus mendapatkan momentum. Pada akhirnya, ketika manajemen menyadari bahwa blok OneBox adalah bagian dari proyek kami, ia segera memutuskan untuk menempatkan
"orang yang tepat" untuk mengelola sistem grafik. Pada puncak permainan politik, tiga pemimpin diganti, yang masing-masing tidak memiliki pengalaman bekerja dengan grafik.
Selama lompatan Dgraph ini, manajer proyek
Spanner menyebut Dgraph sistem yang
terlalu rumit . Sebagai referensi, Spanner adalah database SQL terdistribusi di seluruh dunia yang membutuhkan jam tangan GPS sendiri untuk memastikan konsistensi global.
Ironi dari ini masih meniup atap saya.Dgraph dibatalkan, Plasma selamat. Dan di kepala proyek mereka menempatkan tim baru dengan pemimpin baru, dengan hierarki yang jelas dan melapor kepada CEO. Tim baru - dengan pemahaman yang buruk tentang grafik dan masalah terkait - memutuskan untuk membuat subsistem infrastruktur berdasarkan indeks pencarian Google yang ada (seperti yang saya lakukan untuk Cerebro). Saya menyarankan menggunakan sistem yang sudah saya lakukan untuk Cerebro, tetapi ditolak. Saya memodifikasi Plasma untuk merayapi dan memperluas setiap simpul pengetahuan ke dalam beberapa tingkatan sehingga sistem dapat melihatnya sebagai dokumen web. Mereka menyebut sistem ini TS (
singkatan ).
Ini berarti bahwa subsistem baru tidak akan dapat melakukan asosiasi yang mendalam. Sekali lagi, ini adalah kutukan yang saya lihat di banyak perusahaan karena insinyur memulai dengan gagasan yang salah bahwa "grafik adalah masalah sederhana yang dapat diselesaikan dengan hanya membangun lapisan di atas sistem lain."
Beberapa bulan kemudian, pada Mei 2013, saya meninggalkan Google setelah mengerjakan Dgraph / Plasma selama sekitar dua tahun.
Kata penutup
- Beberapa tahun kemudian, bagian "Infrastruktur Pencarian Internet" diganti namanya menjadi "Infrastruktur Pencarian Internet dan Grafik Pengetahuan", dan pemimpin yang pernah saya tunjukkan kepada Cerebro memimpin arah "Grafik Pengetahuan" yang menceritakan tentang bagaimana mereka bermaksud untuk mengganti yang sederhana tautan Pengetahuan biru untuk menjawab pertanyaan pengguna secara langsung sesering mungkin.
- Ketika tim Shanghai yang mengerjakan Cerebro hampir memproduksinya, proyek itu diambil dari mereka dan diserahkan ke unit New York. Pada akhirnya, diluncurkan sebagai Strip Pengetahuan. Jika Anda mencari [ film tom hanks ], Anda akan melihatnya di bagian atas. Ini telah sedikit membaik sejak peluncuran pertama, tetapi masih tidak mendukung tingkat penyaringan dan pemilahan yang diletakkan di Cerebro.
- Ketiga manajer teknis yang bekerja di Dgraph (termasuk saya) akhirnya meninggalkan Google. Sejauh yang saya tahu, sisanya sekarang bekerja di Microsoft dan LinkedIn.
- Saya berhasil mendapatkan dua promosi di Google dan saya harus mendapatkan yang ketiga ketika saya meninggalkan perusahaan sebagai insinyur perangkat lunak senior (Insinyur Perangkat Lunak Senior).
- Dilihat oleh beberapa rumor terpisah, versi TS saat ini sebenarnya sangat dekat dengan desain sistem grafik Cerebro, dan setiap subjek, predikat, dan objek memiliki indeks. Karena itu, ia masih menderita masalah kedalaman penyatuan.
- Plasma sejak itu telah ditulis ulang dan diganti namanya, tetapi terus bekerja sebagai sistem pengindeksan grafik waktu nyata untuk TS. Bersama-sama, mereka terus memposting dan memproses semua data terstruktur di Google, termasuk Grafik Pengetahuan.
- Ketidakmampuan Google untuk membuat serikat pekerja yang dalam terlihat di banyak tempat. Misalnya, kami masih tidak melihat pertukaran data di antara blok-blok OneBox: [kota-kota dengan hujan terbanyak di asia] tidak memberikan daftar kota, meskipun semua data ada di kolom pengetahuan (sebagai gantinya, halaman web dikutip dalam hasil pencarian); [peristiwa di SF] tidak dapat difilter menurut cuaca; [Presiden AS] hasilnya tidak diurutkan, disaring, atau diperluas dengan fakta lain: anak-anak mereka atau sekolah tempat mereka belajar. Saya percaya ini adalah salah satu alasan untuk penghentian dukungan Freebase .
Dgraph: Phoenix Bird
Dua tahun setelah meninggalkan Google, saya memutuskan untuk
mengembangkan Dgraph . Di perusahaan lain, saya melihat keragu-raguan yang sama mengenai grafik seperti di Google. Ada banyak solusi yang belum selesai dalam ruang grafik, khususnya, banyak solusi khusus yang dengan cepat dikumpulkan di atas basis data relasional atau NoSQL, atau sebagai salah satu dari banyak fitur basis data multi-model. Jika ada solusi asli, maka itu menderita masalah skalabilitas.
Tidak ada yang saya lihat memiliki cerita yang koheren dengan desain yang produktif dan dapat diukur.
Membangun basis data grafik yang dapat diskalakan secara horizontal dengan latensi rendah dan penggabungan kedalaman sewenang-wenang adalah tugas yang sangat sulit , dan saya ingin memastikan bahwa kami membuat Dgraph dengan benar.
Tim Dgraph menghabiskan tiga tahun terakhir tidak hanya mempelajari pengalaman saya sendiri, tetapi juga menginvestasikan banyak upaya mereka sendiri dalam merancang - membuat database grafik yang tidak memiliki analog di pasar. Dengan demikian, perusahaan memiliki kesempatan untuk menggunakan solusi yang andal, scalable, dan produktif daripada solusi setengah jadi lainnya.