Deteksi serangan telah menjadi bagian dari keamanan informasi selama beberapa dekade. Implementasi sistem deteksi intrusi (IDS) pertama diketahui tanggal kembali ke awal 1980-an.
Saat ini, seluruh industri deteksi serangan ada. Ada sejumlah jenis produk - seperti IDS, IPS, WAF, dan solusi firewall - yang sebagian besar menawarkan deteksi serangan berbasis aturan. Gagasan untuk menggunakan semacam deteksi anomali statistik untuk mengidentifikasi serangan dalam produksi tampaknya tidak realistis seperti dulu. Tetapi apakah asumsi itu dibenarkan?
Deteksi anomali dalam Aplikasi Web
Firewall pertama yang dirancang untuk mendeteksi serangan aplikasi web muncul di pasar pada awal 1990-an. Baik teknik serangan maupun mekanisme perlindungan telah berkembang secara dramatis sejak saat itu, dengan para penyerang berlomba untuk selangkah lebih maju.
Sebagian besar firewall aplikasi web (WAFs) saat ini berupaya untuk mendeteksi serangan dengan cara yang sama, dengan mesin berbasis aturan yang tertanam dalam proxy terbalik dari beberapa jenis. Contoh yang paling menonjol adalah mod_security, modul WAF untuk server web Apache, yang dibuat pada tahun 2002. Deteksi berbasis aturan memiliki beberapa kelemahan: misalnya, gagal mendeteksi serangan baru (nol hari), meskipun serangan yang sama mungkin mudah dideteksi oleh seorang ahli manusia. Fakta ini tidak mengejutkan, karena otak manusia bekerja sangat berbeda dari serangkaian ekspresi reguler.
Dari perspektif WAF, serangan dapat dibagi menjadi yang berbasis berurutan (time series) dan serangan yang terdiri dari permintaan atau respons HTTP tunggal. Penelitian kami berfokus pada pendeteksian jenis serangan terakhir, yang meliputi:
- Injeksi SQL
- Skrip lintas situs
- Injeksi Entitas Eksternal XML
- Jalur traversal
- Memerintah OS
- Injeksi objek
Tapi pertama-tama mari kita bertanya pada diri sendiri: bagaimana manusia melakukannya?
Apa yang akan dilakukan manusia ketika melihat satu permintaan
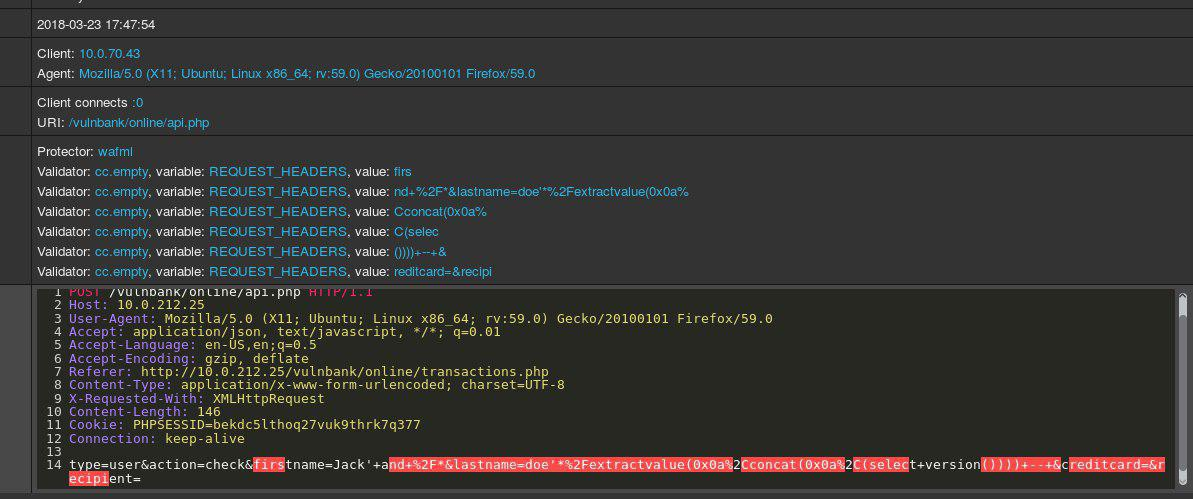
Lihatlah contoh permintaan HTTP reguler untuk beberapa aplikasi:
Jika Anda harus mendeteksi permintaan jahat yang dikirim ke suatu aplikasi, kemungkinan besar Anda ingin mengamati permintaan tidak ramah untuk sementara waktu. Setelah melihat permintaan untuk sejumlah titik akhir eksekusi aplikasi, Anda akan memiliki gagasan umum tentang bagaimana permintaan aman disusun dan apa yang dikandungnya.
Sekarang Anda disajikan dengan permintaan berikut:

Anda segera mengetahui bahwa ada sesuatu yang salah. Dibutuhkan lebih banyak waktu untuk memahami apa sebenarnya, dan segera setelah Anda menemukan bagian yang tepat dari permintaan yang anomali, Anda dapat mulai memikirkan jenis serangan apa itu. Pada dasarnya, tujuan kami adalah membuat deteksi serangan AI kami mendekati masalah dengan cara yang menyerupai pemikiran manusia ini.
Yang lebih rumit dari tugas kami adalah bahwa beberapa lalu lintas, meskipun mungkin tampak berbahaya pada pandangan pertama, sebenarnya mungkin normal untuk situs web tertentu.
Misalnya, mari kita lihat permintaan berikut:
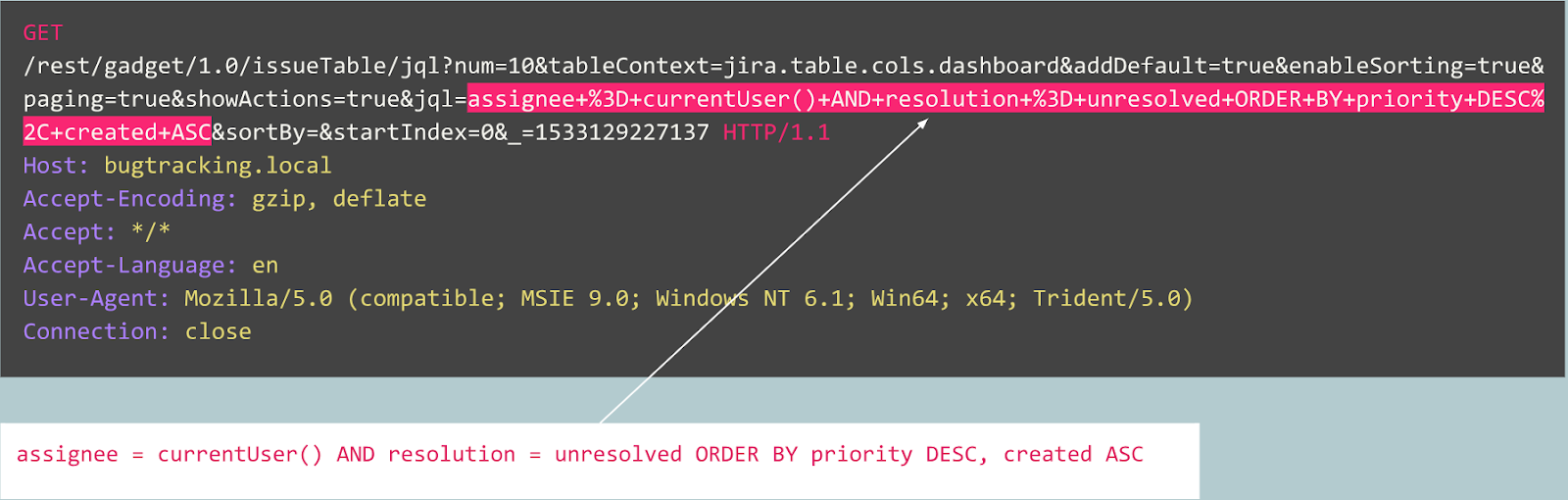
Apakah ini anomali? Sebenarnya, permintaan ini tidak berbahaya: ini adalah permintaan khas yang terkait dengan publikasi bug pada pelacak bug Jira.
Sekarang mari kita lihat kasus lain:

Pada awalnya permintaan tampak seperti pendaftaran pengguna biasa di situs web yang didukung oleh Joomla CMS. Namun, operasi yang diminta adalah "user.register" bukan "pendaftaran.register" yang normal. Opsi sebelumnya sudah usang dan mengandung kerentanan yang memungkinkan siapa pun untuk mendaftar sebagai administrator.
Eksploitasi ini dikenal sebagai “Joomla <3.6.4 Pembuatan Akun / Peningkatan Privilege” (CVE-2016-8869, CVE-2016-8870).

Bagaimana kami memulai
Kami pertama kali melihat pada penelitian sebelumnya, karena banyak upaya untuk membuat algoritma pembelajaran statistik atau mesin yang berbeda untuk mendeteksi serangan telah dilakukan selama beberapa dekade. Salah satu pendekatan yang paling sering adalah untuk menyelesaikan tugas penugasan ke kelas ("permintaan jinak," "Injeksi SQL," "XSS," "CSRF," dan sebagainya). Sementara seseorang dapat mencapai akurasi yang layak dengan klasifikasi untuk dataset yang diberikan, pendekatan ini gagal menyelesaikan beberapa masalah yang sangat penting:
- Pilihan set kelas . Bagaimana jika model Anda selama pembelajaran disajikan dengan tiga kelas ("jinak," "SQLi," "XSS") tetapi dalam produksi itu menghadapi serangan CSRF atau bahkan teknik serangan baru?
- Arti dari kelas-kelas ini . Misalkan Anda perlu melindungi 10 pelanggan, masing-masing menjalankan aplikasi web yang sangat berbeda. Untuk sebagian besar dari mereka, Anda tidak akan tahu seperti apa serangan “SQL Injection” terhadap aplikasi mereka. Ini berarti Anda harus entah bagaimana membuat set data pembelajaran Anda secara artifisial - yang merupakan ide yang buruk, karena Anda pada akhirnya akan belajar dari data dengan distribusi yang sama sekali berbeda dari data sebenarnya.
- Interpretabilitas hasil model Anda . Hebat, jadi modelnya datang dengan label "SQL Injection" - sekarang apa? Anda dan yang paling penting pelanggan Anda, yang adalah orang pertama yang melihat peringatan dan biasanya bukan ahli dalam serangan web, harus menebak bagian mana dari permintaan yang dianggap berbahaya oleh model.
Dengan mengingat hal itu, kami memutuskan untuk tetap mencoba klasifikasi.
Karena protokol HTTP berbasis teks, jelas bahwa kami harus melihat pada pengklasifikasi teks modern. Salah satu contoh yang terkenal adalah analisis sentimen dari dataset ulasan film IMDB. Beberapa solusi menggunakan jaringan saraf berulang (RNN) untuk mengklasifikasikan ulasan ini. Kami memutuskan untuk menggunakan model klasifikasi RNN yang serupa dengan beberapa perbedaan kecil. Misalnya, klasifikasi bahasa alami RNN menggunakan embeddings kata, tetapi tidak jelas kata apa yang ada dalam bahasa non-alami seperti HTTP. Itu sebabnya kami memutuskan untuk menggunakan embeddings karakter dalam model kami.
Embeddings siap pakai tidak relevan untuk menyelesaikan masalah, itulah sebabnya kami menggunakan pemetaan karakter sederhana ke kode numerik dengan beberapa penanda internal seperti
GO dan
EOS .
Setelah kami menyelesaikan pengembangan dan pengujian model, semua masalah yang diprediksi sebelumnya terjadi, tetapi setidaknya tim kami telah beralih dari bermalas-malasan ke sesuatu yang produktif.
Bagaimana kami melanjutkan
Dari sana, kami memutuskan untuk mencoba membuat hasil model kami lebih dapat ditafsirkan. Pada titik tertentu kami menemukan mekanisme "perhatian" dan mulai mengintegrasikannya ke dalam model kami. Dan itu menghasilkan beberapa hasil yang menjanjikan: akhirnya, semuanya datang bersama dan kami mendapatkan beberapa hasil yang dapat ditafsirkan oleh manusia. Sekarang model kami mulai menghasilkan tidak hanya label tetapi juga koefisien perhatian untuk setiap karakter input.
Jika itu bisa divisualisasikan, katakanlah, dalam antarmuka web, kita bisa mewarnai tempat yang tepat di mana serangan "SQL Injection" ditemukan. Itu adalah hasil yang menjanjikan, tetapi masalah lainnya masih belum terpecahkan.
Kami mulai melihat bahwa kami dapat mengambil manfaat dengan mengarahkan mekanisme perhatian, dan menjauh dari klasifikasi. Setelah membaca banyak penelitian terkait (misalnya, "Hanya perhatian yang Anda butuhkan," Word2Vec, dan enkoder - arsitektur dekoder) pada model urutan dan dengan bereksperimen dengan data kami, kami dapat membuat model pendeteksian anomali yang akan bekerja di kurang lebih sama dengan cara sebagai ahli manusia.
Autoencoder
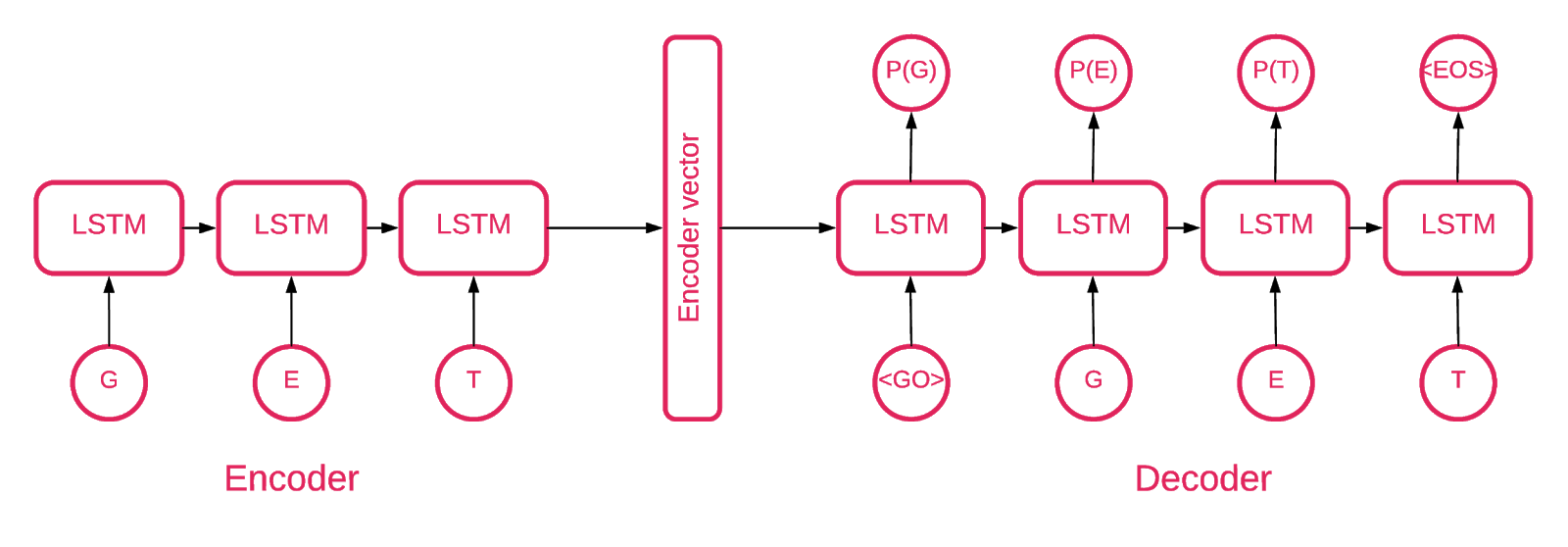
Pada titik tertentu menjadi jelas bahwa autoencoder urutan-ke-urutan paling sesuai dengan tujuan kita.
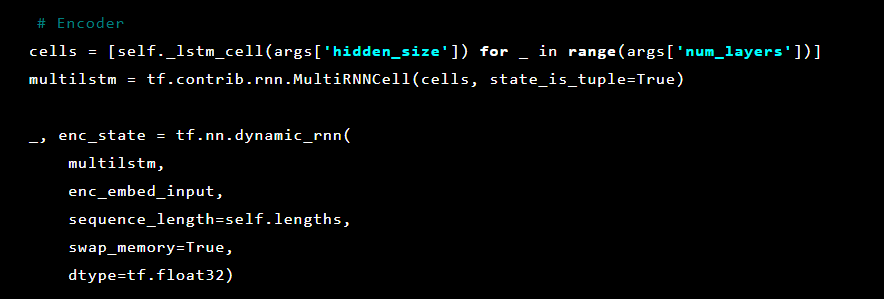
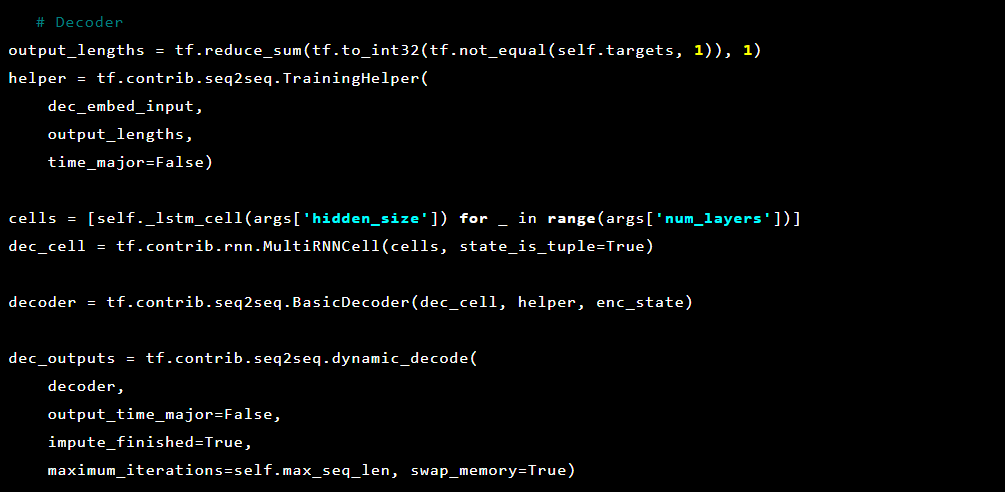
Model urutan-ke-urutan terdiri dari dua model memori jangka pendek (LSTM) berlapis ganda: sebuah enkoder dan dekoder. Encoder memetakan urutan input ke vektor dimensi tetap. Dekoder menerjemahkan vektor target menggunakan output encoder ini.
Jadi autoencoder adalah model urutan-ke-urutan yang menetapkan nilai targetnya sama dengan nilai inputnya. Idenya adalah untuk mengajarkan jaringan untuk menciptakan kembali hal-hal yang telah dilihatnya, atau, dengan kata lain, memperkirakan fungsi identitas. Jika autoencoder yang terlatih diberikan sampel anomali, kemungkinan besar akan membuatnya kembali dengan tingkat kesalahan yang tinggi karena tidak pernah melihat sampel seperti itu sebelumnya.
Kodenya
Solusi kami terdiri dari beberapa bagian: inisialisasi model, pelatihan, prediksi, dan validasi.
Sebagian besar kode yang terletak di repositori cukup jelas, kami akan fokus pada bagian-bagian penting saja.
Model ini diinisialisasi sebagai turunan dari kelas Seq2Seq, yang memiliki argumen konstruktor berikut:
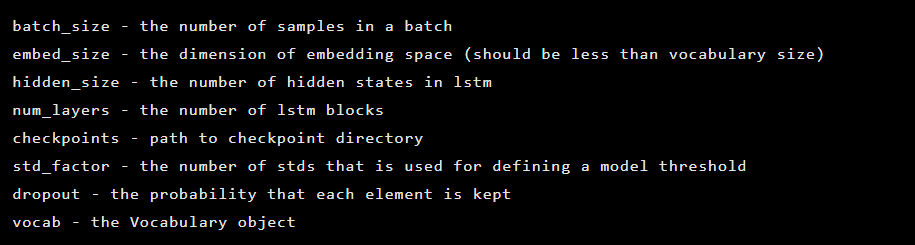
Setelah itu, layer autoencoder diinisialisasi. Pertama, pembuat enkode:
Dan kemudian dekoder:
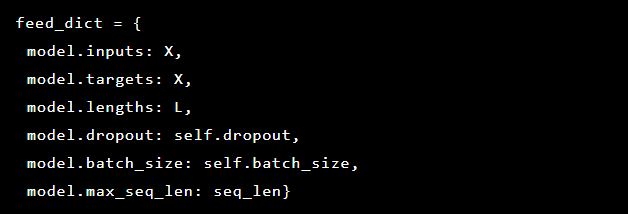
Karena kami mencoba menyelesaikan deteksi anomali, target dan inputnya sama. Jadi feed_dict kami terlihat sebagai berikut:
Setelah setiap zaman, model terbaik disimpan sebagai pos pemeriksaan, yang nantinya dapat dimuat untuk melakukan prediksi. Untuk tujuan pengujian, aplikasi web langsung dibuat dan dilindungi oleh model sehingga memungkinkan untuk menguji apakah serangan nyata berhasil atau tidak.
Terinspirasi oleh mekanisme perhatian, kami mencoba menerapkannya pada autoencoder tetapi memperhatikan bahwa probabilitas keluaran dari lapisan terakhir berfungsi lebih baik dalam menandai bagian-bagian anomali dari suatu permintaan.

Pada tahap pengujian dengan sampel kami, kami mendapat hasil yang sangat baik: presisi dan daya ingat mendekati 0,99. Dan kurva ROC sekitar 1. Pasti pemandangan yang bagus!
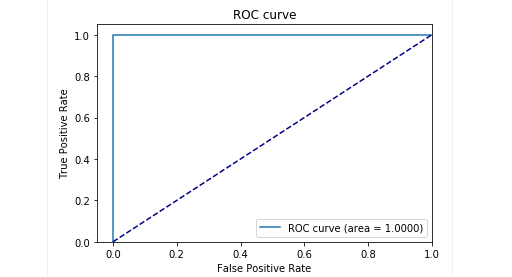
Hasilnya
Model autoencoder Seq2Seq yang dijelaskan kami terbukti mampu mendeteksi anomali dalam permintaan HTTP dengan akurasi tinggi.
Model ini bertindak seperti layaknya manusia: ia hanya mempelajari permintaan pengguna “normal” yang dikirim ke aplikasi web. Ini mendeteksi anomali dalam permintaan dan menyoroti tempat yang tepat dalam permintaan yang dianggap anomali. Kami mengevaluasi model ini terhadap serangan pada aplikasi pengujian dan hasilnya tampak menjanjikan. Misalnya, tangkapan layar sebelumnya menggambarkan bagaimana model kami mendeteksi pemisahan injeksi SQL di dua parameter formulir web. Suntikan SQL semacam itu terfragmentasi, karena muatan serangan dikirim dalam beberapa parameter HTTP. WAFs berbasis aturan klasik buruk dalam mendeteksi upaya injeksi SQL terfragmentasi karena mereka biasanya memeriksa setiap parameter sendiri.
Kode model dan data kereta / tes telah dirilis sebagai notebook Jupyter sehingga siapa pun dapat mereproduksi hasil kami dan menyarankan perbaikan.
Kesimpulan
Kami percaya tugas kami cukup sepele: untuk menemukan cara mendeteksi serangan dengan upaya minimal. Di satu sisi, kami berusaha menghindari solusi yang terlalu rumit dan menciptakan cara mendeteksi serangan yang, seolah-olah dengan sihir, belajar untuk memutuskan dengan sendirinya apa yang baik dan apa yang buruk. Pada saat yang sama, kami ingin menghindari masalah dengan faktor manusia ketika seorang ahli (yang keliru) memutuskan apa yang mengindikasikan serangan dan apa yang tidak. Dan secara keseluruhan autoencoder dengan arsitektur Seq2Seq tampaknya menyelesaikan masalah kami dalam mendeteksi anomali dengan cukup baik.
Kami juga ingin menyelesaikan masalah interpretabilitas data. Ketika menggunakan arsitektur jaringan saraf yang kompleks, sangat sulit untuk menjelaskan hasil tertentu. Ketika serangkaian transformasi diterapkan, mengidentifikasi data paling penting di balik keputusan menjadi hampir mustahil. Namun, setelah memikirkan kembali pendekatan interpretasi data oleh model, kami dapat memperoleh probabilitas untuk setiap karakter dari lapisan terakhir.
Penting untuk dicatat bahwa pendekatan ini bukan versi yang siap produksi. Kami tidak dapat mengungkapkan rincian tentang bagaimana pendekatan ini dapat diterapkan dalam produk nyata. Tetapi kami akan memperingatkan Anda bahwa tidak mungkin hanya mengambil pekerjaan ini dan "tancapkan." Kami membuat peringatan ini karena setelah menerbitkan di GitHub, kami mulai melihat beberapa pengguna yang mencoba untuk mengimplementasikan solusi kami saat ini secara grosir di proyek mereka sendiri, dengan hasil yang tidak berhasil (dan tidak mengejutkan).
Bukti konsep tersedia di
sini (github.com).
Penulis: Alexandra Murzina (
murzina_a ), Irina Stepanyuk (
GitHub ), Fedor Sakharov (
GitHub ), Arseny Reutov (
Raz0r )
Bacaan lebih lanjut
- Memahami Jaringan LSTM
- Perhatian dan Augmented Neural Networks
- Perhatian adalah yang Anda butuhkan
- Perhatian Yang Anda Butuhkan (beranotasi)
- Tutorial Terjemahan Mesin Saraf (seq2seq)
- Autoencoder
- Sequence to Sequence Learning dengan Neural Networks
- Membangun Autoencoder di Keras