Meretas musik untuk mendemokratisasi konten yang diturunkanPenafian: Semua kekayaan intelektual, desain, dan metode yang dijelaskan dalam artikel ini diungkapkan dalam US10014002B2 dan US9842609B2.
Seandainya saya bisa kembali ke 1965, mengetuk pintu depan studio Abby Road dengan sebuah pas, masuk ke dalam - dan dengarkan suara asli Lennon dan McCartney ... Baiklah, mari kita coba. Input: Beatles kualitas rata-rata MP3
We Can Work Out . Track atas adalah campuran input, track bawah adalah vokal terisolasi yang disorot oleh jaringan saraf kita.
Secara formal, masalah ini dikenal sebagai
pemisahan sumber suara atau
pemisahan sinyal (pemisahan sumber audio). Ini terdiri dalam pemulihan atau rekonstruksi satu atau lebih dari sinyal asli, yang dicampur dengan sinyal lain sebagai hasil dari proses
linier atau konvolusional . Bidang penelitian ini memiliki banyak aplikasi praktis, termasuk meningkatkan kualitas suara (ucapan) dan menghilangkan kebisingan, remix musik, distribusi spasial suara, remastering, dll. Insinyur suara kadang-kadang menyebut teknik ini demixing. Ada banyak sumber daya pada topik ini, dari pemisahan sinyal buta dengan analisis komponen independen (ICA) ke faktorisasi semi-terkontrol dari matriks non-negatif dan diakhiri dengan pendekatan selanjutnya berdasarkan jaringan saraf. Anda dapat menemukan informasi yang bagus tentang dua poin pertama dalam
panduan mini dari CCRMA ini, yang pada satu waktu sangat berguna bagi saya.
Tapi sebelum terjun ke pengembangan ... sedikit filosofi pembelajaran mesin yang diterapkan ...Saya terlibat dalam pemrosesan sinyal dan gambar bahkan sebelum slogan "pembelajaran mendalam memecahkan segalanya" telah menyebar, jadi saya dapat memberikan Anda solusi sebagai perjalanan
rekayasa fitur dan menunjukkan
mengapa jaringan saraf adalah pendekatan terbaik untuk masalah khusus ini . Mengapa Sangat sering, saya melihat orang menulis sesuatu seperti ini:
“Dengan pembelajaran yang mendalam, Anda tidak perlu lagi khawatir memilih fitur; itu akan melakukannya untuk Anda. "atau lebih buruk ...
"Perbedaan antara pembelajaran mesin dan pembelajaran mendalam [hei ... pembelajaran mendalam masih pembelajaran mesin!] Apakah
itu di ML Anda sendiri mengekstrak atribut, dan dalam pembelajaran mendalam ini terjadi secara otomatis dalam jaringan."Generalisasi ini mungkin berasal dari kenyataan bahwa DNN bisa sangat efektif dalam mengeksplorasi ruang tersembunyi yang baik. Tapi jadi tidak mungkin untuk menggeneralisasi. Saya sangat sedih ketika lulusan dan praktisi baru-baru ini menyerah pada kesalahpahaman di atas dan mengadopsi pendekatan "belajar-dalam-itu-semua". Seperti, itu sudah cukup untuk membuang banyak data mentah (bahkan setelah sedikit proses awal) - dan semuanya akan berfungsi sebagaimana mestinya. Di dunia nyata, Anda harus mengurus hal-hal seperti kinerja, eksekusi waktu nyata, dan sebagainya. Karena kesalahpahaman seperti itu, Anda akan terjebak dalam mode percobaan untuk waktu yang sangat lama ...
Fitur Teknik tetap menjadi disiplin yang sangat penting dalam desain jaringan saraf tiruan. Seperti dalam teknik ML lainnya, dalam banyak kasus, itu yang membedakan solusi efektif dari tingkat produksi dari percobaan yang gagal atau tidak efektif. Pemahaman yang mendalam tentang data Anda dan sifatnya masih sangat berarti ...A hingga Z
Ok, saya selesai khotbah. Sekarang mari kita lihat mengapa kita ada di sini! Seperti halnya masalah pemrosesan data, pertama mari kita lihat seperti apa bentuknya. Lihatlah bagian vokal berikutnya dari rekaman studio asli.
Studio vokal 'Satu Kali Terakhir', Ariana GrandeTidak terlalu menarik, bukan? Nah, ini karena kami memvisualisasikan sinyal
tepat waktu . Di sini kita hanya melihat perubahan amplitudo dari waktu ke waktu. Tetapi Anda dapat mengekstraksi segala macam hal lain, seperti amplop amplop (amplop), nilai rata-rata akar (RMS), laju perubahan dari nilai positif amplitudo menjadi negatif (laju penyilangan nol), dll., Tetapi
tanda -
tanda ini terlalu
primitif dan tidak cukup khas, untuk membantu dalam masalah kita. Jika kita ingin mengekstraksi vokal dari sinyal audio, pertama-tama kita perlu menentukan struktur bicara manusia. Untungnya, Window
Fourier Transform (STFT) hadir untuk menyelamatkan.
Spektrum amplitudo STFT - ukuran jendela = 2048, tumpang tindih = 75%, skala frekuensi logaritmik [Sonic Visualizer]Meskipun saya suka pemrosesan pidato dan pasti suka bermain dengan
simulasi filter input, cepstrum, sottotami, LPC, MFCC dan sebagainya
, kami akan melewati semua omong kosong ini dan fokus pada elemen utama yang terkait dengan masalah kami sehingga artikel tersebut dapat dipahami oleh sebanyak mungkin orang, bukan hanya spesialis pemrosesan sinyal.
Jadi apa yang dikatakan oleh struktur bicara manusia kepada kita?
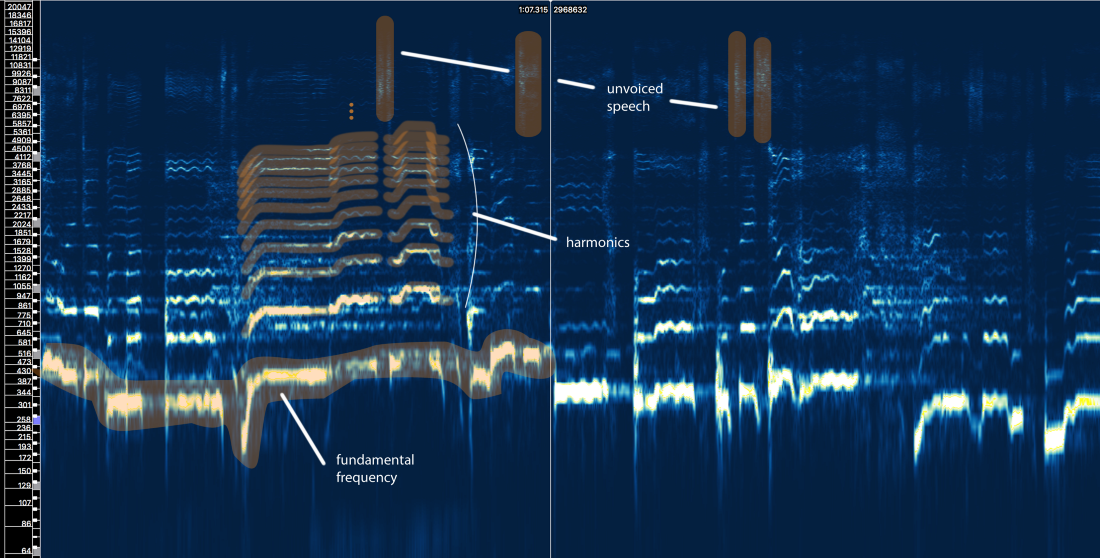
Kita dapat mendefinisikan tiga elemen utama di sini:
- Frekuensi mendasar (f0), yang ditentukan oleh frekuensi getaran pita suara kita. Dalam hal ini, Ariana bernyanyi di kisaran 300-500 Hz.
- Serangkaian harmonik di atas f0 yang mengikuti bentuk atau pola yang serupa. Harmonik ini muncul pada frekuensi yang merupakan kelipatan dari f0.
- Pidato tanpa suara, yang mencakup konsonan seperti 't', 'p', 'k', 's' (yang tidak dihasilkan oleh getaran pita suara), pernapasan, dll. Semua ini memanifestasikan dirinya dalam bentuk ledakan singkat di wilayah frekuensi tinggi.
Percobaan Pertama dengan Aturan
Mari kita lupakan sejenak apa yang disebut pembelajaran mesin. Bisakah metode ekstraksi vokal dikembangkan berdasarkan pengetahuan kita tentang sinyal? Biarkan saya mencoba ...
Isolasi vokal naif V1.0:- Identifikasi area dengan vokal. Ada banyak hal dalam sinyal aslinya. Kami ingin fokus pada area-area yang benar-benar berisi konten vokal, dan mengabaikan yang lainnya.
- Bedakan antara ucapan yang disuarakan dan yang tidak disuarakan. Seperti yang telah kita lihat, mereka sangat berbeda. Mereka mungkin perlu ditangani secara berbeda.
- Nilai perubahan frekuensi dasar dari waktu ke waktu.
- Berdasarkan pin 3, aplikasikan semacam topeng untuk menangkap harmonik.
- Lakukan sesuatu dengan fragmen pidato yang tidak disuarakan ...

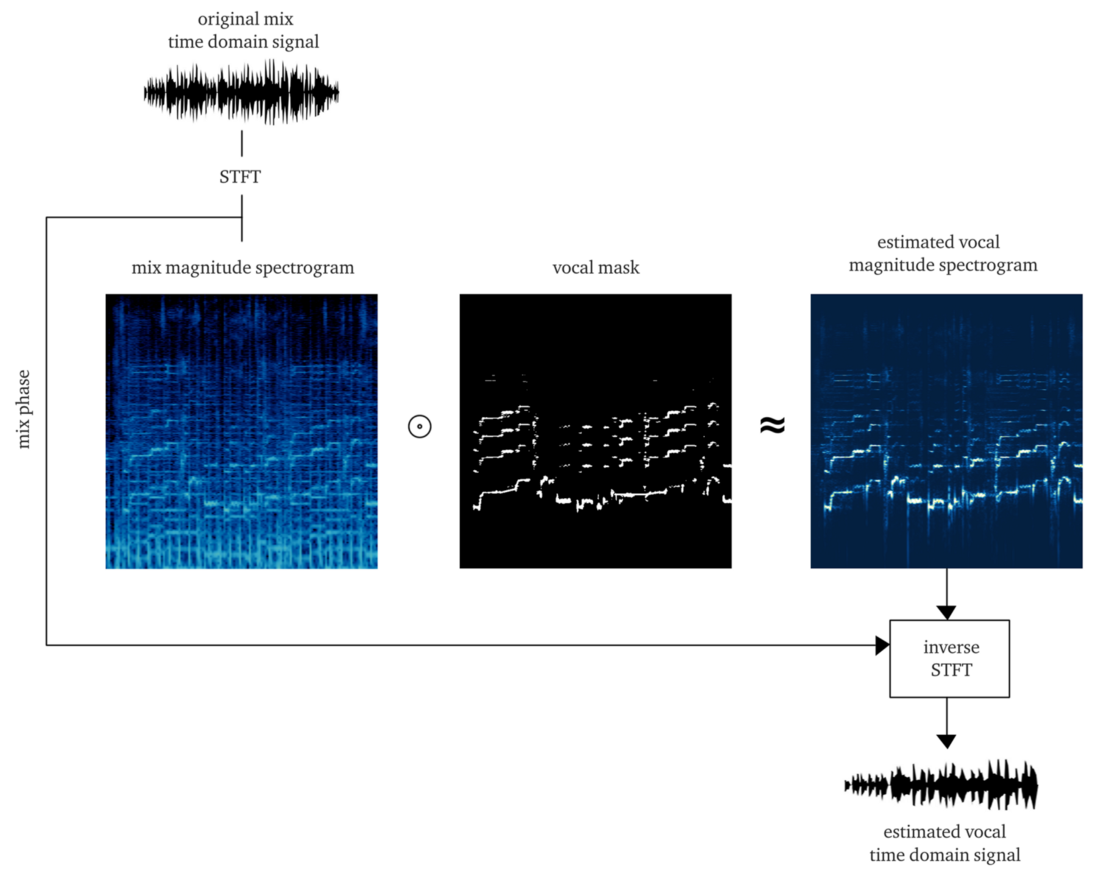
Jika kita bekerja dengan layak, hasilnya akan menjadi
lunak atau
bitmask , aplikasi yang untuk amplitudo STFT (penggandaan elemen) memberikan perkiraan rekonstruksi amplitudo vokal STFT. Kemudian kami menggabungkan STFT vokal ini dengan informasi tentang fase sinyal asli, menghitung STFT terbalik, dan mendapatkan sinyal waktu vokal yang direkonstruksi.
Melakukannya dari awal sudah merupakan pekerjaan besar. Namun demi demonstrasi, penerapan
algoritma pYIN dapat diterapkan . Meskipun ini dimaksudkan untuk menyelesaikan langkah 3, tetapi dengan pengaturan yang benar, ia melakukan langkah 1 dan 2 dengan baik, melacak basis vokal bahkan di hadapan musik. Contoh di bawah ini berisi output setelah memproses algoritma ini, tanpa memproses ucapan yang tidak disuarakan.
Dan apa ...? Dia tampaknya telah melakukan semua pekerjaan, tetapi tidak ada kualitas yang baik dan dekat. Mungkin dengan menghabiskan lebih banyak waktu, energi, dan uang, kami akan meningkatkan metode ini ...
Tapi saya ingin bertanya ...
Apa yang terjadi jika
beberapa suara muncul di trek, namun sering ditemukan di setidaknya 50% trek profesional modern?
Apa yang terjadi jika vokal diproses oleh
reverb, penundaan dan efek lainnya? Mari kita lihat paduan suara terakhir Ariana Grande dari lagu ini.
Apakah Anda sudah merasakan sakit ...? Saya
Metode seperti itu pada aturan ketat sangat cepat berubah menjadi rumah kartu. Masalahnya terlalu rumit. Terlalu banyak aturan, terlalu banyak pengecualian, dan terlalu banyak kondisi berbeda (efek dan pengaturan campuran). Pendekatan multi-langkah juga menyiratkan bahwa kesalahan dalam satu langkah memperluas masalah ke langkah berikutnya. Memperbaiki setiap langkah akan menjadi sangat mahal: akan membutuhkan banyak iterasi untuk memperbaikinya. Dan yang terakhir, namun tidak kalah pentingnya, kemungkinan besar pada akhirnya kita akan mendapatkan konveyor yang sangat intensif sumber daya, yang dengan sendirinya dapat meniadakan semua upaya.
Dalam situasi seperti itu, sekarang saatnya untuk mulai berpikir tentang pendekatan yang lebih komprehensif dan biarkan ML mengetahui bagian dari proses dasar dan operasi yang diperlukan untuk menyelesaikan masalah. Tapi kami masih harus menunjukkan keahlian kami dan terlibat dalam rekayasa fitur, dan Anda akan tahu sebabnya.Hipotesis: gunakan jaringan saraf sebagai fungsi transfer yang menerjemahkan campuran menjadi vokal
Melihat pencapaian jaringan saraf convolutional dalam pemrosesan foto, mengapa tidak menerapkan pendekatan yang sama di sini?
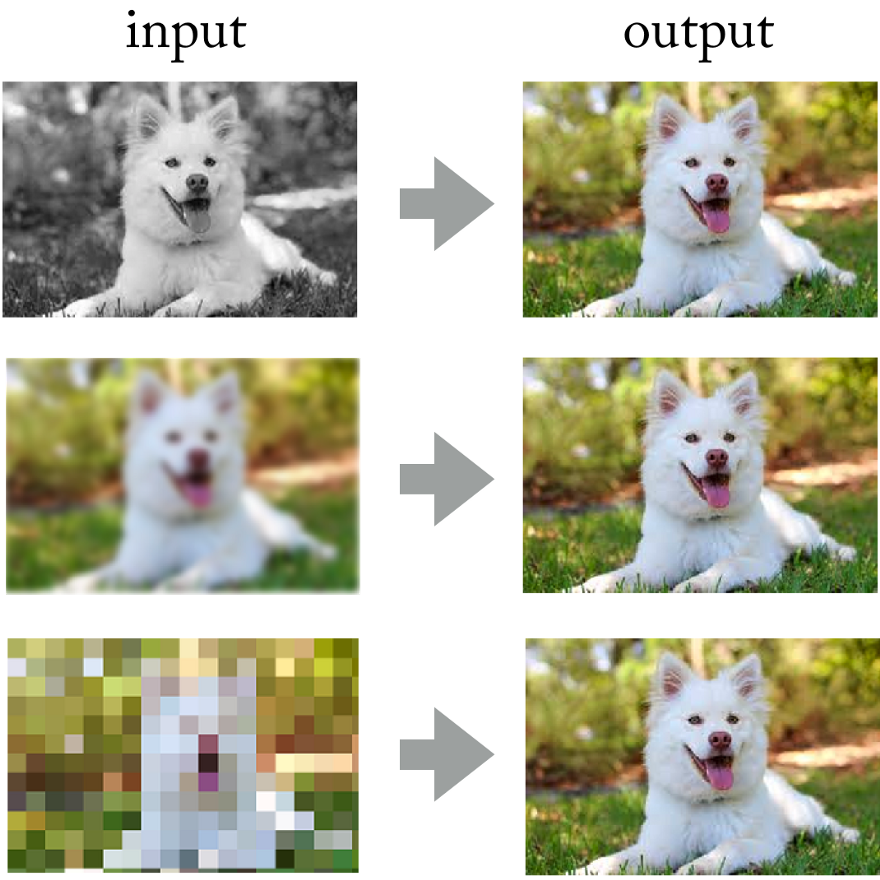 Jaringan saraf berhasil memecahkan masalah seperti pewarnaan gambar, penajaman dan resolusi.
Jaringan saraf berhasil memecahkan masalah seperti pewarnaan gambar, penajaman dan resolusi.Pada akhirnya, Anda bisa membayangkan sinyal suara "sebagai gambar" menggunakan transformasi Fourier jangka pendek, bukan? Meskipun
gambar suara ini tidak sesuai dengan distribusi statistik gambar alami, mereka masih memiliki pola spasial (dalam ruang waktu dan frekuensi) yang digunakan untuk melatih jaringan.
 Kiri: drum beat dan baseline di bawah, beberapa suara synthesizer di tengah, semua dicampur dengan vokal. Kanan: hanya vokal
Kiri: drum beat dan baseline di bawah, beberapa suara synthesizer di tengah, semua dicampur dengan vokal. Kanan: hanya vokalMelakukan eksperimen semacam itu akan menjadi pekerjaan yang mahal karena sulit untuk mendapatkan atau menghasilkan data pelatihan yang diperlukan. Tetapi dalam penelitian terapan, saya selalu mencoba menggunakan pendekatan ini: pertama,
untuk mengidentifikasi masalah yang lebih sederhana yang menegaskan prinsip yang sama , tetapi tidak memerlukan banyak pekerjaan. Ini memungkinkan Anda untuk mengevaluasi hipotesis, beralih lebih cepat dan memperbaiki model dengan kerugian minimal jika tidak berfungsi sebagaimana mestinya.
Kondisi tersirat adalah bahwa
jaringan saraf harus memahami struktur bicara manusia . Masalah yang lebih sederhana mungkin adalah ini:
dapatkah jaringan syaraf menentukan keberadaan ucapan pada fragmen rekaman suara yang berubah-ubah . Kita berbicara tentang
pendeteksi aktivitas suara (VAD) yang andal, diimplementasikan dalam bentuk classifier biner.
Kami merancang ruang tanda
Kita tahu bahwa sinyal suara, seperti musik dan ucapan manusia, didasarkan pada ketergantungan waktu. Sederhananya, tidak ada yang terjadi dalam isolasi pada titik waktu tertentu. Jika saya ingin tahu apakah ada suara pada rekaman suara tertentu, maka saya perlu melihat daerah tetangga.
Konteks waktu seperti
itu memberikan informasi yang baik tentang apa yang terjadi di bidang yang diminati. Pada saat yang sama, diinginkan untuk melakukan klasifikasi dengan penambahan waktu yang sangat kecil untuk mengenali suara manusia dengan resolusi waktu setinggi mungkin.

Mari kita hitung sedikit ...
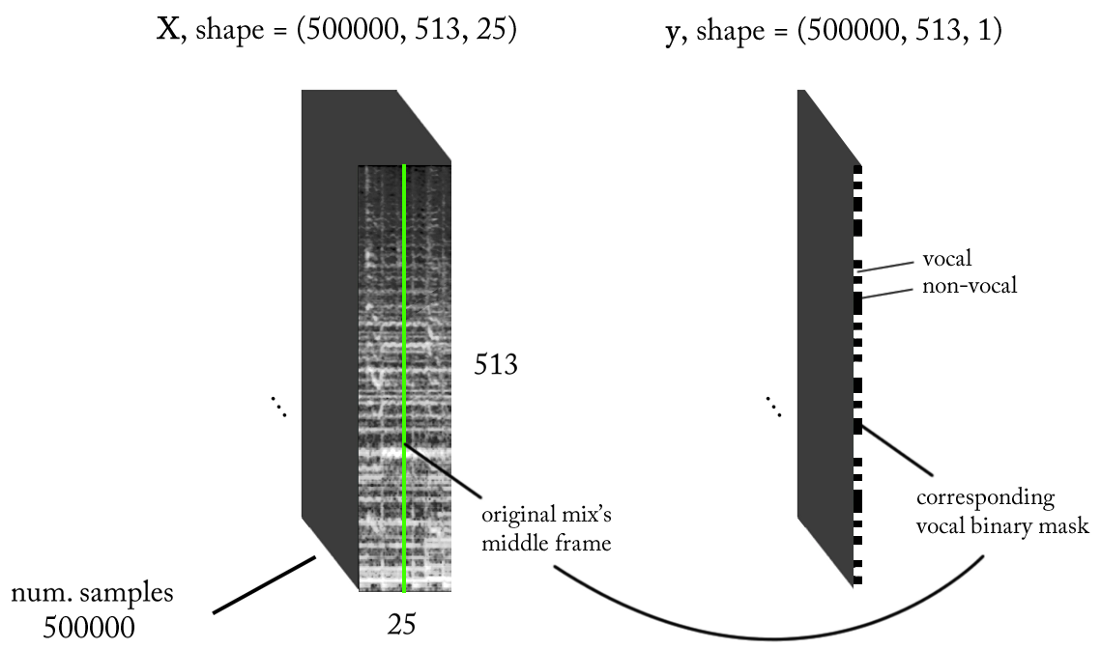
- Frekuensi pengambilan sampel (fs): 22050 Hz (kami menurunkan sampel dari 44100 menjadi 22050)
- Desain STFT: ukuran jendela = 1024, ukuran hop = 256, interpolasi skala kapur untuk filter pembobotan, dengan mempertimbangkan persepsi akun. Karena input kami adalah nyata , Anda dapat bekerja dengan setengah STFT (penjelasan di luar ruang lingkup artikel ini ...) sambil mempertahankan komponen DC (opsional), yang memberi kami 513 tempat frekuensi.
- Resolusi klasifikasi target: satu frame STFT (~ 11,6 ms = 256/22050)
- Konteks waktu target: ~ 300 milidetik = 25 frame STFT.
- Jumlah target contoh pelatihan: 500 ribu.
- Dengan asumsi kami menggunakan jendela geser dengan penambahan 1 kerangka waktu STFT untuk menghasilkan data pelatihan, kami membutuhkan sekitar 1,6 jam suara yang ditandai untuk menghasilkan 500 ribu sampel data
Dengan persyaratan di atas, input dan output dari classifier biner kami adalah sebagai berikut:
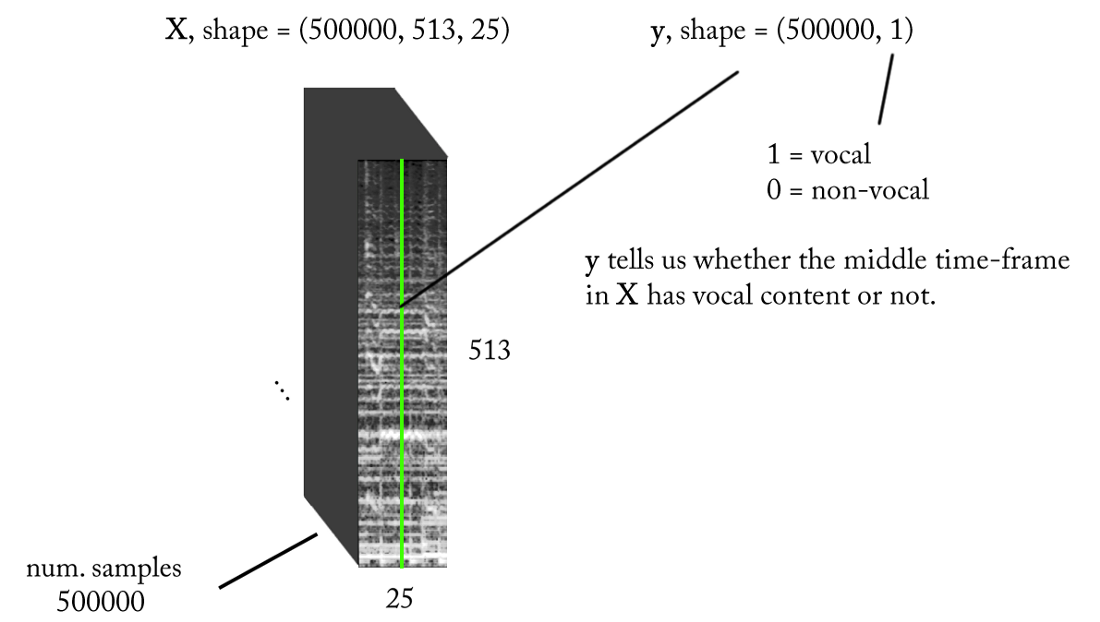
Model
Menggunakan Keras, kami akan membangun model kecil dari jaringan saraf untuk menguji hipotesis kami.
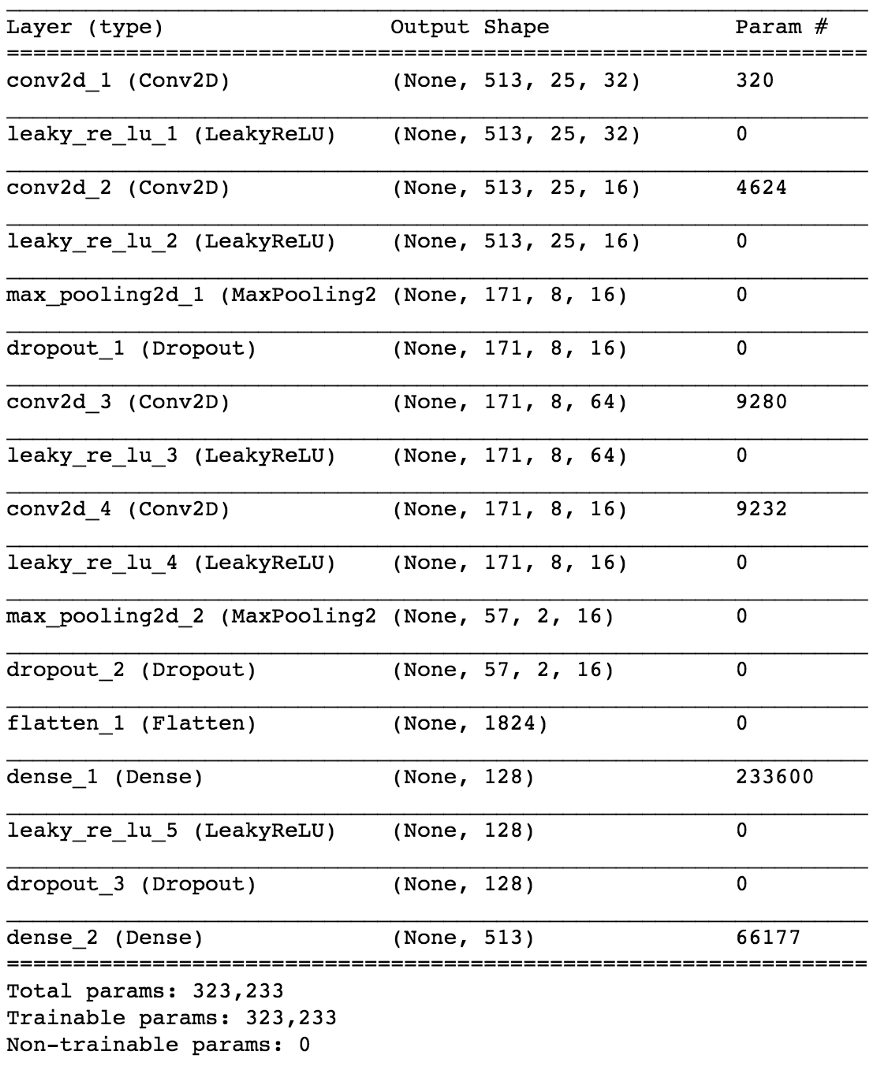
import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D from keras.optimizers import SGD from keras.layers.advanced_activations import LeakyReLU model = Sequential() model.add(Conv2D(16, (3,3), padding='same', input_shape=(513, 25, 1))) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(Conv2D(16, (3,3), padding='same')) model.add(LeakyReLU()) model.add(MaxPooling2D(pool_size=(3,3))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(64)) model.add(LeakyReLU()) model.add(Dropout(0.5)) model.add(Dense(1, activation='sigmoid')) sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True) model.compile(loss=keras.losses.binary_crossentropy, optimizer=sgd, metrics=['accuracy'])
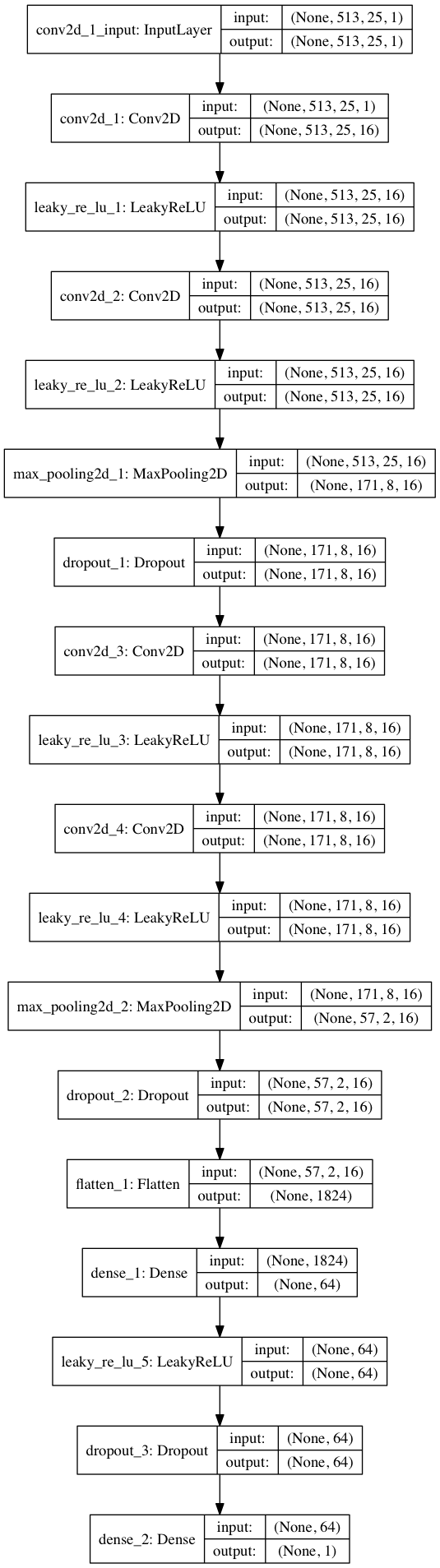
Dengan membagi 80/20 data ke dalam pelatihan dan pengujian setelah ~ 50 zaman, kita mendapatkan
akurasi saat menguji ~ 97% . Ini adalah bukti yang cukup bahwa model kami dapat membedakan antara vokal dalam fragmen suara musik (dan fragmen tanpa vokal). Jika kita memeriksa beberapa peta fitur dari lapisan konvolusional ke-4, kita dapat menyimpulkan bahwa jaringan saraf tampaknya telah mengoptimalkan kernel untuk melakukan dua tugas: menyaring musik dan menyaring vokal ...
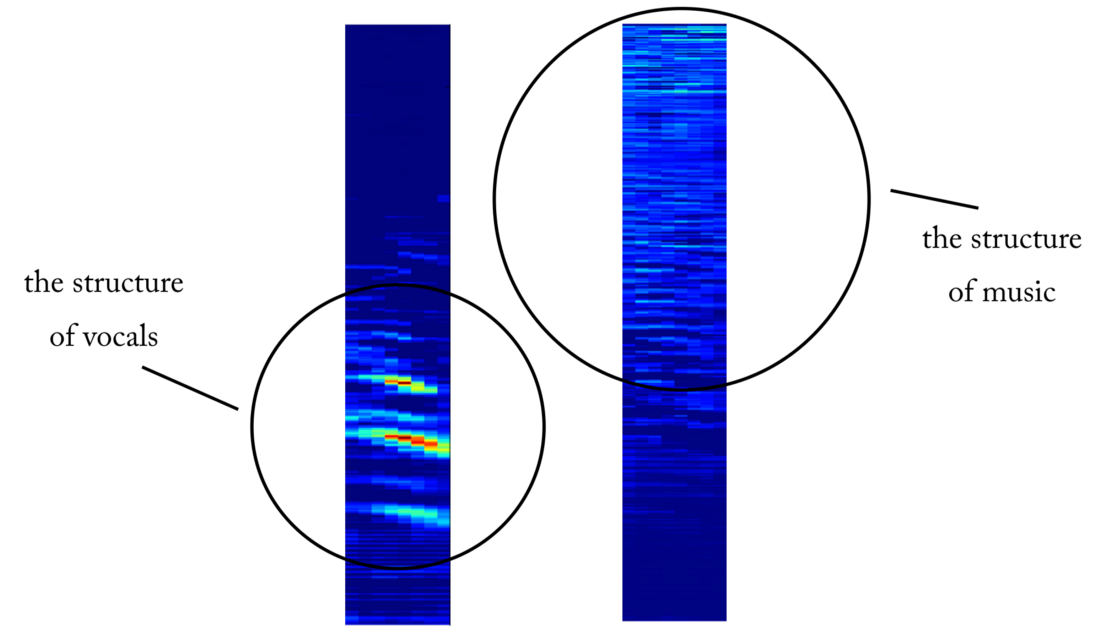 Contoh peta benda di pintu keluar lapisan konvolusional ke-4. Tampaknya, output di sebelah kiri adalah hasil dari operasi kernel dalam upaya untuk mempertahankan konten vokal sambil mengabaikan musik. Nilai-nilai tinggi menyerupai struktur harmonis ucapan manusia. Peta objek di sebelah kanan tampaknya merupakan hasil dari tugas yang berlawanan.
Contoh peta benda di pintu keluar lapisan konvolusional ke-4. Tampaknya, output di sebelah kiri adalah hasil dari operasi kernel dalam upaya untuk mempertahankan konten vokal sambil mengabaikan musik. Nilai-nilai tinggi menyerupai struktur harmonis ucapan manusia. Peta objek di sebelah kanan tampaknya merupakan hasil dari tugas yang berlawanan.Dari detektor suara ke pemutusan sinyal
Setelah memecahkan masalah klasifikasi yang lebih sederhana, bagaimana kita bisa beralih ke pemisahan vokal yang sebenarnya dari musik? Nah, melihat metode
naif pertama, kami masih ingin entah bagaimana mendapatkan spektrogram amplitudo untuk vokal. Sekarang ini menjadi tugas regresi. Yang ingin kami lakukan adalah menghitung spektrum amplitudo yang sesuai untuk vokal dalam kerangka waktu ini dari STFT dari sinyal asli, yaitu dari campuran (dengan konteks waktu yang cukup).
Bagaimana dengan dataset pelatihan? (Anda dapat bertanya kepada saya saat ini)Sial ... kenapa begitu. Saya akan mempertimbangkan ini di akhir artikel agar tidak teralihkan dari topik!
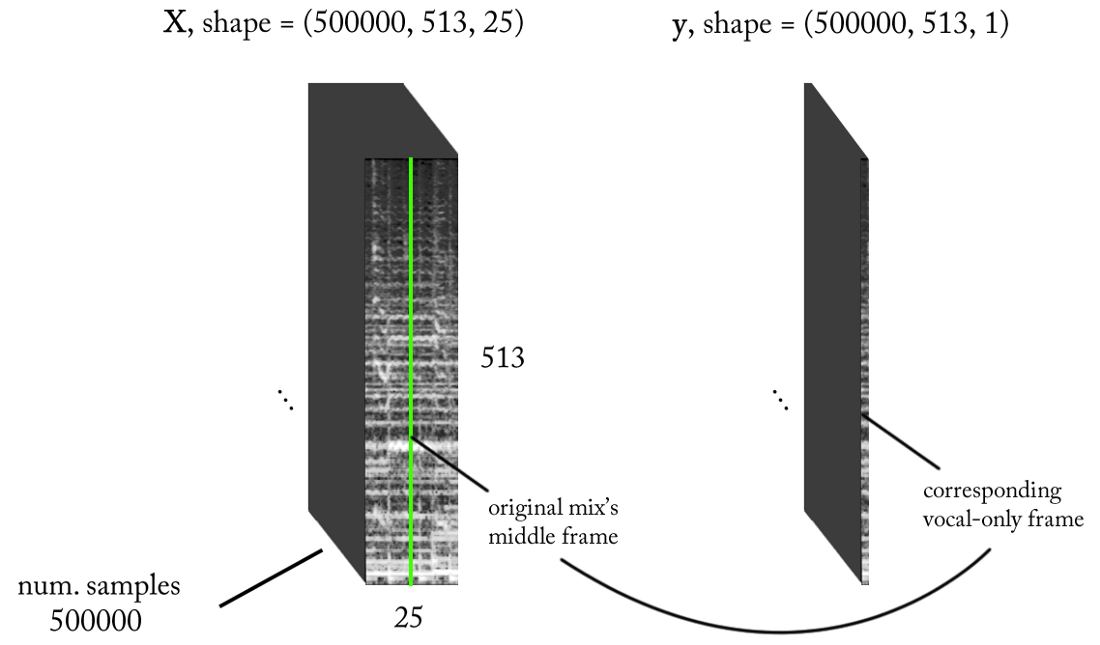
Jika model kami terlatih dengan baik, maka untuk kesimpulan logis Anda hanya perlu menerapkan jendela geser sederhana ke campuran STFT. Setelah setiap perkiraan, gerakkan jendela ke kanan sebanyak 1 jangka waktu, prediksi bingkai berikutnya dengan vokal dan kaitkan dengan prediksi sebelumnya. Adapun model, mari kita ambil model yang sama yang digunakan untuk detektor suara dan membuat perubahan kecil: gelombang output sekarang (513.1), aktivasi linier pada output, MSE sebagai fungsi kerugian. Sekarang kita mulai pelatihan.
Jangan bersukacita lagi ...Meskipun representasi I / O ini masuk akal, setelah melatih model kami beberapa kali, dengan berbagai parameter dan normalisasi data, tidak ada hasil. Sepertinya kita terlalu banyak bertanya ...
Kami telah pindah dari klasifikasi biner ke
regresi pada vektor 513 dimensi. Meskipun jaringan mempelajari masalah sampai batas tertentu, vokal yang dipulihkan masih memiliki artefak yang jelas dan gangguan dari sumber lain. Bahkan setelah menambahkan lapisan tambahan dan meningkatkan jumlah parameter model, hasilnya tidak banyak berubah. Dan kemudian muncul pertanyaan:
bagaimana cara "menyederhanakan" tugas untuk jaringan dengan penipuan, dan pada saat yang sama mencapai hasil yang diinginkan?Bagaimana jika, alih-alih memperkirakan amplitudo vokal STFT, kami melatih jaringan untuk mendapatkan topeng biner, yang bila diterapkan pada campuran STFT memberi kami spektogram amplitudo vokal yang disederhanakan, tetapi
dapat diterima secara perseptual dari vokal?
Bereksperimen dengan berbagai heuristik, kami menghasilkan cara yang sangat sederhana (dan, tentu saja, tidak lazim dalam hal pemrosesan sinyal ...) untuk mengekstraksi vokal dari campuran menggunakan topeng biner. Tanpa merinci, esensinya adalah sebagai berikut. Bayangkan output sebagai gambar biner, di mana nilai '1' menunjukkan
keberadaan konten vokal pada frekuensi dan jangka waktu tertentu, dan nilai '0' menunjukkan keberadaan musik di tempat tertentu. Kita dapat menyebutnya
binarisasi persepsi , hanya untuk menghasilkan sebuah nama. Secara visual, itu terlihat sangat jelek, jujur, tetapi hasilnya sangat bagus.
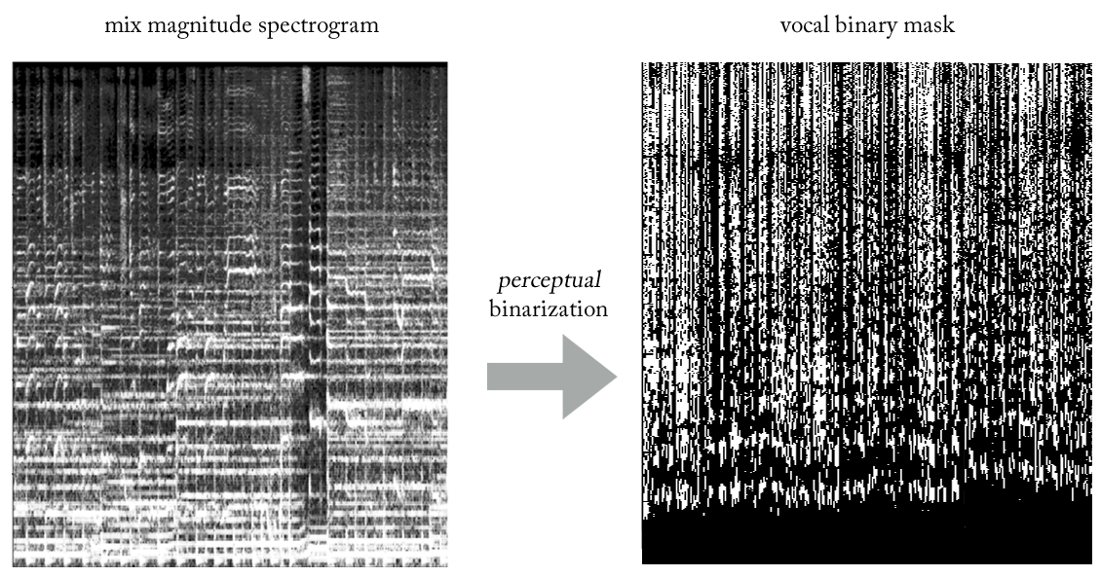
Sekarang masalah kita menjadi semacam regresi-klasifikasi hibrida (sangat kasar ...). Kami meminta model untuk "mengklasifikasikan piksel" pada output sebagai vokal atau non-vokal, meskipun secara konseptual (serta dari sudut pandang fungsi kehilangan MSE yang digunakan) tugas tetap regresif.
Meskipun perbedaan ini mungkin tampak tidak tepat untuk beberapa orang, pada kenyataannya itu sangat penting dalam kemampuan model untuk mempelajari tugas, yang kedua adalah lebih sederhana dan lebih terbatas. Pada saat yang sama, ini memungkinkan kami untuk menjaga model kami relatif kecil dalam hal jumlah parameter, mengingat kompleksitas tugas, sesuatu yang sangat diinginkan untuk bekerja secara real time, yang dalam hal ini merupakan persyaratan desain. Setelah beberapa perubahan kecil, model terakhir terlihat seperti ini.
Bagaimana cara memulihkan sinyal domain waktu?
Bahkan, seperti dalam
metode naif . Dalam hal ini, untuk setiap pass, kami memperkirakan satu jangka waktu dari topeng vokal biner. Sekali lagi, mewujudkan jendela geser sederhana dengan langkah satu kerangka waktu, kami terus mengevaluasi dan menggabungkan kerangka waktu berturut-turut, yang akhirnya membentuk seluruh topeng biner vokal.

Buat satu set pelatihan
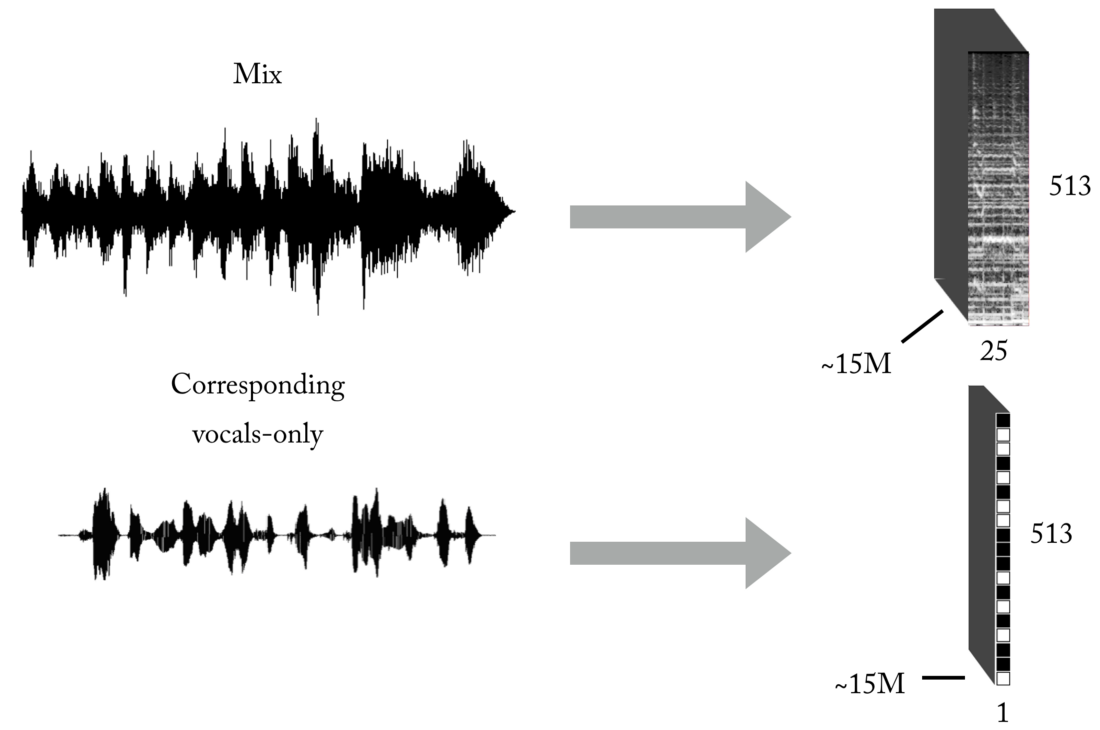
Seperti yang Anda ketahui, salah satu masalah utama ketika mengajar dengan seorang guru (tinggalkan contoh mainan ini dengan kumpulan data yang sudah jadi) adalah data yang benar (dalam jumlah dan kualitas) untuk masalah spesifik yang Anda coba selesaikan. Berdasarkan representasi input dan output yang dijelaskan, untuk melatih model kami, Anda pertama-tama akan membutuhkan sejumlah besar campuran dan trek vokal yang sesuai, selaras sempurna, dan dinormalisasi. Perangkat seperti itu dapat dibuat dalam beberapa cara, dan kami menggunakan kombinasi strategi, dari membuat pasangan [campuran <-> vokal] secara manual berdasarkan pada beberapa cappella yang ditemukan di Internet, hingga mencari bahan musik band rock dan scrapbooking Youtube. Hanya untuk memberi Anda gambaran tentang betapa melelahkan dan menyakitkannya proses ini, bagian dari proyek ini adalah pengembangan alat semacam itu untuk secara otomatis membuat pasangan [campuran <-> vokal]:

Sejumlah besar data diperlukan untuk jaringan saraf untuk mempelajari fungsi transfer untuk penyiaran campuran ke vokal. Set terakhir kami terdiri dari sekitar 15 juta sampel 300 ms campuran dan topeng biner vokal yang sesuai.
Arsitektur perpipaan
Seperti yang mungkin Anda ketahui, membuat model ML untuk tugas tertentu hanya setengah dari pertempuran. Di dunia nyata, Anda perlu memikirkan arsitektur perangkat lunak, terutama jika Anda perlu bekerja secara langsung atau dekat dengannya.
Dalam implementasi khusus ini, rekonstruksi dalam domain waktu dapat terjadi segera setelah memprediksi topeng vokal biner penuh (mode yang berdiri sendiri) atau, yang lebih menarik, dalam mode multi-berulir, tempat kami menerima dan memproses data, mengembalikan vokal dan mereproduksi suara - semua dalam segmen kecil, dekat dengan streaming dan bahkan hampir secara real time, memproses musik yang direkam dengan cepat dengan penundaan minimal. Sebenarnya, ini adalah topik yang terpisah, dan saya akan meninggalkannya untuk artikel lain
di jaringan pipa ML real-time ...
Saya kira saya sudah mengatakan cukup, jadi mengapa tidak mendengarkan beberapa contoh !?
Daft Punk - Get Lucky (rekaman studio)
Di sini Anda dapat mendengar beberapa gangguan minimal dari drum ...Adele - Set Fire to the Rain (rekaman langsung!)
Perhatikan bagaimana di awal model kami mengekstrak jeritan orang banyak sebagai konten vokal :). Dalam hal ini, ada beberapa gangguan dari sumber lain. Karena ini adalah rekaman langsung, tampaknya dapat diterima bahwa vokal yang diekstraksi memiliki kualitas yang lebih buruk daripada yang sebelumnya.Ya, dan "sesuatu yang lain" ...
Jika sistem bekerja untuk vokal, mengapa tidak menerapkannya ke instrumen lain ...?
Artikel ini sudah cukup besar, tetapi mengingat pekerjaan yang dilakukan, Anda layak mendengar demo terbaru. Dengan logika yang persis sama dengan saat mengekstraksi vokal, kita dapat mencoba membagi musik stereo menjadi komponen (drum, bass, vokal, yang lain), membuat beberapa perubahan dalam model kita dan, tentu saja, memiliki set pelatihan yang sesuai :).
Terima kasih sudah membaca. Sebagai catatan terakhir: seperti yang Anda lihat, model aktual dari jaringan saraf convolutional kami tidak begitu istimewa. Keberhasilan pekerjaan ini ditentukan oleh
Feature Engineering dan proses pengujian hipotesis yang rapi, yang akan saya tulis di artikel mendatang!