Java 11 tidak memperkenalkan fitur inovatif apa pun, tetapi berisi beberapa permata yang mungkin belum pernah Anda dengar. Sudah melihat yang terbaru di String , Optional , Collection , dan workhorses lainnya? Jika tidak, maka Anda telah datang ke alamat: hari ini kita akan melihat 11 permata tersembunyi dari Jawa 11!
Ketik inferensi untuk parameter lambda
Saat menulis ekspresi lambda, Anda dapat memilih di antara jenis yang secara eksplisit menentukan dan melewatkannya:
Function<String, String> append = string -> string + " "; Function<String, String> append = (String s) -> s + " ";
Java 10 memperkenalkan var , tetapi tidak bisa digunakan dalam lambdas:
Di Jawa 11 sudah dimungkinkan. Tapi mengapa? Sepertinya var memberikan lebih dari sekadar pass type. Meskipun demikian, penggunaan var memiliki dua keuntungan kecil:
- membuat penggunaan
var lebih universal dengan menghapus pengecualian pada aturan - memungkinkan Anda untuk menambahkan anotasi ke tipe parameter tanpa menggunakan nama lengkapnya
Ini adalah contoh dari kasus kedua:
List<EnterpriseGradeType<With, Generics>> types = ; types .stream()
Meskipun mencampur tipe turunan, eksplisit dan implisit dalam ekspresi lambda dari bentuk (var type, String option, index) -> ... dapat diimplementasikan, tetapi ( dalam kerangka JEP-323 ) pekerjaan ini tidak dilakukan. Oleh karena itu, perlu untuk memilih salah satu dari tiga pendekatan dan mematuhinya untuk semua parameter ekspresi lambda. Kebutuhan untuk menentukan var untuk semua parameter untuk menambahkan anotasi untuk salah satunya dapat sedikit mengganggu, tetapi secara umum dapat ditoleransi.
Aliran pemrosesan string dengan 'String::lines'
Punya string multi-line? Ingin melakukan sesuatu dengan setiap barisnya? Maka String::lines adalah pilihan yang tepat:
var multiline = "\r\n\r\n\r\n"; multiline .lines()
Perhatikan bahwa baris asli menggunakan pembatas sekrup \r\n dan meskipun saya di Linux, lines() masih mematahkannya. Hal ini disebabkan oleh fakta bahwa, terlepas dari OS saat ini, metode ini mengartikan \r , \n , dan \r\n sebagai jeda baris - bahkan jika mereka dicampur pada baris yang sama.
Aliran garis tidak pernah mengandung pemisah garis itu sendiri. Baris dapat kosong ( "\n\n \n\n" , yang berisi 5 baris), tetapi baris terakhir dari baris asli diabaikan jika kosong ( "\n\n" ; 2 baris). (Catatan oleh penerjemah: lebih mudah bagi mereka untuk memiliki line , tetapi untuk memiliki string , dan kami memiliki keduanya.)
Tidak seperti split("\R") , lines() malas dan, saya kutip , "memberikan kinerja yang lebih baik [...] dengan lebih cepat mencari jeda baris baru". (Jika seseorang ingin mengajukan tolok ukur pada JMH untuk verifikasi, beri tahu saya). Ini juga lebih baik mencerminkan algoritma pemrosesan dan menggunakan struktur data yang lebih nyaman (stream bukan array).
Menghapus spasi dengan 'String::strip' , dll.
Awalnya, String memiliki metode trim untuk menghapus spasi, yang dianggap semuanya dengan kode hingga U+0020 . Ya, BACKSPACE ( U+0008) adalah ruang putih seperti BELL ( U+0007 ), tetapi LINE SEPARATOR ( U+2028 ) tidak lagi dianggap seperti itu.
Java 11 memperkenalkan metode strip , yang pendekatannya memiliki lebih banyak nuansa. Ia menggunakan metode Character::isWhitespace dari Java 5 untuk menentukan apa yang sebenarnya perlu dihapus. Dari dokumentasinya jelas bahwa ini:
SPACE SEPARATOR , LINE SEPARATOR , PARAGRAPH SEPARATOR , tetapi bukan ruang yang tidak bisa dipisahkanHORIZONTAL TABULATION ( U+0009 ), LINE FEED ( U+000A ), VERTICAL TABULATION ( U+000B ), FORM FEED ( U+000C ), CARRIAGE RETURN U+000D ( U+000D )FILE SEPARATOR ( U+001C ), GROUP SEPARATOR ( U+001D ), RECORD SEPARATOR ( U+001E ), UNIT SEPARATOR ( U+001F )
Dengan logika yang sama, ada dua metode pembersihan lagi, stripLeading dan stripTailing , yang melakukan apa yang diharapkan dari mereka.
Dan akhirnya, jika Anda hanya perlu mencari tahu apakah garis menjadi kosong setelah menghapus spasi, maka tidak perlu untuk benar-benar menghapusnya - cukup gunakan isBlank :
" ".isBlank();
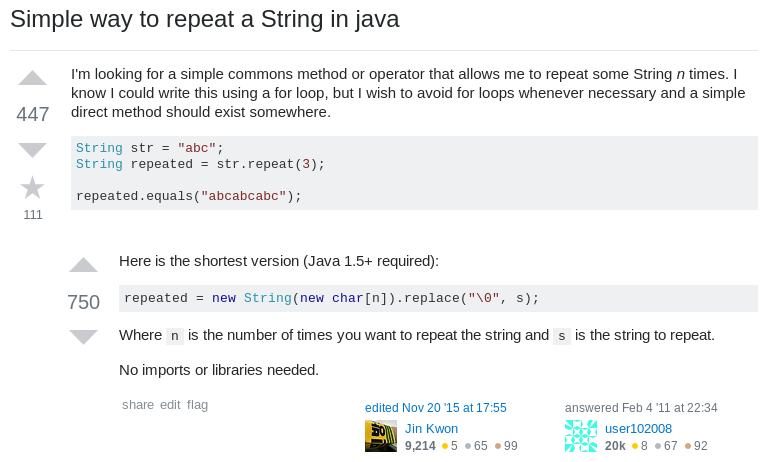
Mengulang string dengan 'String::repeat'
Tangkap idenya:
Langkah 1: Menyimpan Arloji di JDK

Langkah 2: Menemukan Pertanyaan Terkait StackOverflow
Langkah 3: Tiba dengan jawaban baru berdasarkan perubahan di masa depan

Langkah 4: ????
Langkah 4: Untung

Seperti yang dapat Anda bayangkan, String memiliki metode repeat(int) . Ia bekerja persis sesuai dengan harapan, dan ada sedikit untuk didiskusikan.
Membuat jalur dengan 'Path::of'
Saya sangat suka Path API, tetapi mengubah jalur di antara tampilan yang berbeda (seperti Path , File , URL , URI dan String ) masih mengganggu. Poin ini menjadi kurang membingungkan di Java 11 dengan menyalin dua Paths::get methods ke Path::of methods:
Path tmp = Path.of("/home/nipa", "tmp"); Path codefx = Path.of(URI.create("http://codefx.org"));
Mereka dapat dianggap kanonik, karena kedua Paths::get methods lama menggunakan opsi baru.
Membaca dan menulis file dengan 'Files::readString' dan 'Files::writeString'
Jika saya perlu membaca dari file besar, saya biasanya menggunakan Files::lines untuk mendapatkan aliran malas dari barisnya. Demikian pula, untuk menulis sejumlah besar data yang mungkin tidak disimpan dalam memori secara keseluruhan, saya menggunakan Files::write meneruskannya sebagai Iterable<String> .
Tapi bagaimana dengan kasus sederhana ketika saya ingin memproses isi file sebagai satu baris? Ini sangat tidak nyaman, karena Files::readAllBytes dan varian Files::write beroperasi pada array byte.
Dan kemudian Java 11 muncul, menambahkan readString dan writeString ke Files :
String haiku = Files.readString(Path.of("haiku.txt")); String modified = modify(haiku); Files.writeString(Path.of("haiku-mod.txt"), modified);
Jelas dan mudah digunakan. Jika perlu, Anda bisa meneruskan Charset ke readString , dan di writeString juga sebuah array OpenOptions .
Kosong I / O dengan 'Reader::nullReader' , dll.
Perlu OutputStream yang tidak menulis di mana pun? Atau InputStream kosong? Bagaimana dengan Reader dan Writer yang tidak melakukan apa-apa? Java 11 memiliki semuanya:
InputStream input = InputStream.nullInputStream(); OutputStream output = OutputStream.nullOutputStream(); Reader reader = Reader.nullReader(); Writer writer = Writer.nullWriter();
(Catatan Penerjemah: di commons-io kelas-kelas ini telah ada sejak sekitar 2014).
Namun, saya terkejut - apakah null benar-benar awalan terbaik? Saya tidak suka bagaimana ini berarti "ketidakhadiran disengaja" ... Mungkin lebih baik menggunakan noOp ? (Catatan Penerjemah: kemungkinan besar awalan ini dipilih karena penggunaan umum /dev/null .)
{ } ~> [ ] dengan 'Collection::toArray'
Bagaimana Anda mengonversi koleksi ke array?
Opsi pertama, objects , kehilangan semua informasi tentang jenis, sehingga sedang dalam penerbangan. Bagaimana dengan yang lainnya? Keduanya tebal, tetapi yang pertama lebih pendek. Yang terakhir menciptakan array ukuran yang diperlukan, sehingga terlihat lebih produktif (yaitu, "tampaknya lebih produktif", lihat kredibilitas ). Tetapi apakah ini benar-benar lebih produktif? Tidak, sebaliknya, itu lebih lambat (saat ini).
Tetapi mengapa saya harus peduli tentang ini? Apakah tidak ada cara yang lebih baik untuk melakukan ini? Di Jawa 11 ada:
String[] strings_fun = list.toArray(String[]::new);
Varian baru Collection::toArray , yang menerima IntFunction<T[]> , yaitu. fungsi yang menerima ukuran array dan mengembalikan array ukuran yang diperlukan. Ini dapat secara singkat dinyatakan sebagai referensi ke konstruktor dari bentuk T[]::new (untuk T terkenal).
Fakta menarik, implementasi default Collection#toArray(IntFunction<T[]>) selalu melewati 0 ke generator array. Pada awalnya, saya memutuskan bahwa solusi ini didasarkan pada kinerja terbaik untuk array dengan panjang nol, tetapi sekarang saya berpikir bahwa alasannya mungkin karena beberapa koleksi, menghitung ukuran bisa menjadi operasi yang sangat mahal dan Anda tidak boleh menggunakan pendekatan ini dalam implementasi default Collection . Namun, implementasi koleksi tertentu, seperti ArrayList , dapat mengubah pendekatan ini, tetapi mereka tidak berubah di Java 11. Tidak layak, kurasa.
Tidak ada pemeriksaan dengan 'Optional::isEmpty'
Dengan banyaknya penggunaan Optional , terutama dalam proyek-proyek besar, di mana Anda sering menghadapi pendekatan non- Optional , Anda sering harus memeriksa apakah itu memiliki nilai. Ada metode Optional::isPresent untuk ini. Tetapi sama sering Anda perlu tahu sebaliknya - bahwa Optional kosong. Tidak masalah, cukup gunakan !opt.isPresent() , kan?
Tentu saja, itu mungkin, tetapi hampir selalu lebih mudah untuk memahami logika if kondisinya tidak terbalik. Dan kadang-kadang Optional muncul di akhir rantai panjang panggilan dan jika Anda perlu memeriksanya secara gratis, maka Anda harus bertaruh ! di awal:
public boolean needsToCompleteAddress(User user) { return !getAddressRepository() .findAddressFor(user) .map(this::canonicalize) .filter(Address::isComplete) .isPresent(); }
Kalau begitu, lewati saja ! sangat mudah. Mulai dengan Java 11 ada opsi yang lebih baik:
public boolean needsToCompleteAddress(User user) { return getAddressRepository() .findAddressFor(user) .map(this::canonicalize) .filter(Address::isComplete) .isEmpty(); }
Menolak predikat dengan 'Predicate::not'
Berbicara tentang pembalikan ... Antarmuka Predicate memiliki negate instance negate : mengembalikan predikat baru yang melakukan pemeriksaan yang sama, tetapi membalikkan hasilnya. Sayangnya, saya jarang berhasil menggunakannya ...
Masalahnya adalah saya jarang memiliki akses ke instance Predicate . Lebih sering, saya ingin mendapatkan instance seperti itu melalui tautan ke suatu metode (dan membalikkannya), tetapi agar ini berfungsi, kompiler harus tahu apa yang harus dibawa ke metode referensi - tanpa itu, ia tidak dapat melakukan apa-apa. Dan ini persis apa yang terjadi jika Anda menggunakan (String::isBlank).negate() : kompiler tidak lagi tahu apa yang harus String::isBlank pada ini dan menyerah. Kasta yang ditentukan dengan benar memperbaikinya, tetapi berapa biayanya?
Meski ada solusi sederhana. Jangan gunakan negate instance negate , tetapi gunakan metode statis baru Predicate.not(Predicate<T>) dari Java 11:
Stream .of("a", "b", "", "c")
Sudah lebih baik!
Ekspresi reguler sebagai predikat dengan 'Pattern::asMatchPredicate'
Apakah ada ekspresi reguler? Perlu memfilter data? Bagaimana dengan ini:
Pattern nonWordCharacter = Pattern.compile("\\W"); Stream .of("Metallica", "Motörhead") .filter(nonWordCharacter.asPredicate()) .forEach(System.out::println);
Saya sangat senang menemukan metode ini! Perlu ditambahkan bahwa ini adalah metode dari Java 8. Ups, saya melewatkannya saat itu. Java 11 menambahkan metode serupa lainnya: Pattern::asMatchPredicate . Apa bedanya?
asPredicate memeriksa apakah string atau bagian dari string cocok dengan pola (berfungsi seperti s -> this.matcher(s).find() )asMatchPredicate memeriksa bahwa seluruh string cocok dengan pola (berfungsi seperti s -> this.matcher(s).matches() )
Misalnya, kami memiliki ekspresi reguler yang memeriksa nomor telepon, tetapi tidak mengandung ^ dan $ untuk melacak awal dan akhir suatu baris. Maka kode berikut tidak akan berfungsi seperti yang Anda harapkan:
prospectivePhoneNumbers .stream() .filter(phoneNumberPatter.asPredicate()) .forEach(this::robocall);
Apakah Anda memperhatikan kesalahan? Baris seperti " -152 ? +1-202-456-1414" akan difilter, karena berisi nomor telepon yang valid. Di sisi lain, Pattern::asMatchPredicate tidak akan mengizinkan ini, karena seluruh string tidak lagi cocok dengan pola.
Tes diri
Berikut ini ikhtisar dari semua sebelas mutiara - apakah Anda masih ingat apa yang dilakukan setiap metode? Jika demikian, Anda telah lulus ujian.
- dalam
String :
Stream<String> lines()String strip()String stripLeading()String stripTrailing()boolean isBlank()String repeat(int)
- di
Path :
static Path of(String, String...)static Path of(URI)
- dalam
Files :
String readString(Path) throws IOExceptionPath writeString(Path, CharSequence, OpenOption...) throws IOExceptionPath writeString(Path, CharSequence, Charset, OpenOption...) throws IOException
- di
InputStream : static InputStream nullInputStream() - dalam
OutputStream : OutputStream static OutputStream nullOutputStream() - di
Reader : static Reader nullReader() - dalam
Writer : static Writer nullWriter() - dalam
Collection : T[] toArray(IntFunction<T[]>) - dalam
Optional : boolean isEmpty() - dalam
Predicate : Predicate static Predicate<T> not(Predicate<T>) - dalam
Pattern : Predicate<String> asMatchPredicate()
Bersenang-senang dengan Java 11!