“Dalam mode penelusuran, programmer melihat urutan eksekusi perintah dan nilai-nilai variabel pada langkah eksekusi program ini, yang membuatnya lebih mudah untuk mendeteksi kesalahan,” kata Wikipedia kepada kami. Sebagai penggemar Linux sendiri, kami secara teratur menemukan pertanyaan tentang alat spesifik mana yang terbaik untuk mengimplementasikannya. Dan kami ingin membagikan terjemahan artikel oleh programmer Hongley Lai yang merekomendasikan bpftrace. Ke depan, saya akan mengatakan bahwa artikel itu berakhir dengan ringkas: "bpftrace adalah masa depan". Jadi mengapa dia begitu mengesankan rekan Lai? Jawaban terperinci di bawah potongan.
Ada dua alat penelusuran utama di Linux:
strace memungkinkan Anda untuk melihat panggilan sistem mana yang sedang dibuat;
ltrace memungkinkan Anda melihat perpustakaan dinamis mana yang dipanggil.
Terlepas dari kegunaannya, alat-alat ini terbatas. Dan jika Anda perlu mencari tahu apa yang terjadi di dalam sistem atau panggilan perpustakaan? Dan jika Anda tidak hanya perlu menyusun daftar panggilan, tetapi juga, misalnya, mengumpulkan statistik tentang perilaku tertentu? Dan jika Anda perlu melacak beberapa proses dan membandingkan data dari beberapa sumber?
Pada tahun 2019, kami akhirnya mendapatkan jawaban yang layak untuk pertanyaan-pertanyaan ini di Linux:
bpftrace berdasarkan teknologi
eBPF . Bpftrace memungkinkan Anda menulis program kecil yang berjalan setiap kali suatu peristiwa terjadi.
Pada artikel ini saya akan menjelaskan cara menginstal bpftrace dan mengajarkan aplikasi dasarnya. Saya juga akan memberikan gambaran tentang seperti apa jejak ekosistem itu (misalnya, "apa itu eBPF?") Dan bagaimana ia telah berevolusi menjadi apa yang kita miliki sekarang.
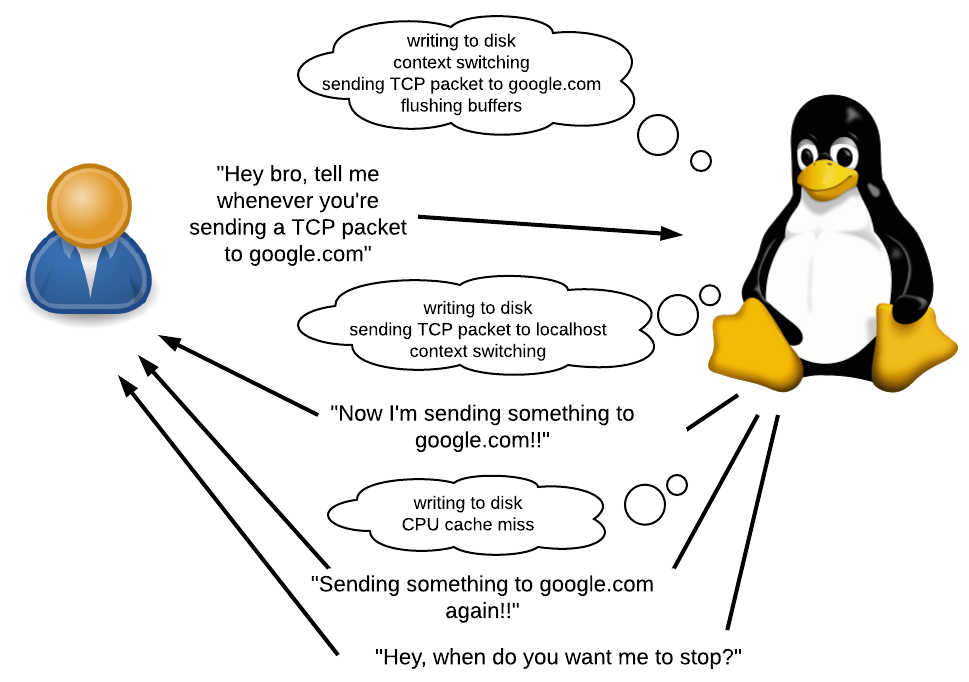
Apa itu jejak?
Seperti disebutkan sebelumnya, bpftrace memungkinkan Anda untuk menulis program kecil yang berjalan setiap kali suatu peristiwa terjadi.
Apa itu acara? Ini bisa berupa panggilan sistem, panggilan fungsi, atau bahkan sesuatu yang terjadi di dalam permintaan tersebut. Ini juga bisa berupa penghitung waktu atau peristiwa perangkat keras, misalnya, "50 ms telah berlalu sejak peristiwa yang sama", "kegagalan halaman terjadi", "terjadi perubahan konteks" atau "prosesor kehilangan uang terjadi".
Apa yang bisa dilakukan sebagai respons terhadap suatu peristiwa? Anda dapat berjanji sesuatu, mengumpulkan statistik dan menjalankan perintah shell sewenang-wenang. Anda akan memiliki akses ke berbagai informasi kontekstual, seperti PID saat ini, jejak stack, waktu, argumen panggilan, nilai balik, dll.
Kapan menggunakannya? Dalam banyak. Anda dapat mengetahui mengapa aplikasi ini lambat dengan menyusun daftar panggilan paling lambat. Anda dapat menentukan apakah ada kebocoran memori dalam aplikasi, dan jika demikian, di mana. Saya menggunakannya untuk memahami mengapa Ruby menggunakan begitu banyak memori.
Nilai tambah besar dari bpftrace adalah Anda tidak perlu mengkompilasi ulang aplikasi. Tidak perlu menulis panggilan cetak secara manual atau kode debug lain dalam kode sumber aplikasi yang sedang dipelajari. Bahkan tidak perlu me-restart aplikasi. Dan semua ini dengan overhead yang sangat rendah. Ini membuat bpftrace sangat berguna untuk sistem debugging langsung pada prod atau dalam situasi lain di mana ada kesulitan dengan kompilasi.
DTrace: bapak jejak
Untuk waktu yang lama, alat penelusuran terbaik adalah
DTrace , kerangka penelusuran dinamis lengkap yang awalnya dikembangkan oleh Sun Microsystems (pembuat Java). Seperti bpftrace, DTrace memungkinkan Anda untuk menulis program kecil yang berjalan sebagai respons terhadap peristiwa. Faktanya, banyak elemen kunci ekosistem sebagian besar dikembangkan oleh
Brendan Gregg , pakar DTrace terkenal yang saat ini bekerja di Netflix. Yang menjelaskan persamaan antara DTrace dan bpftrace.
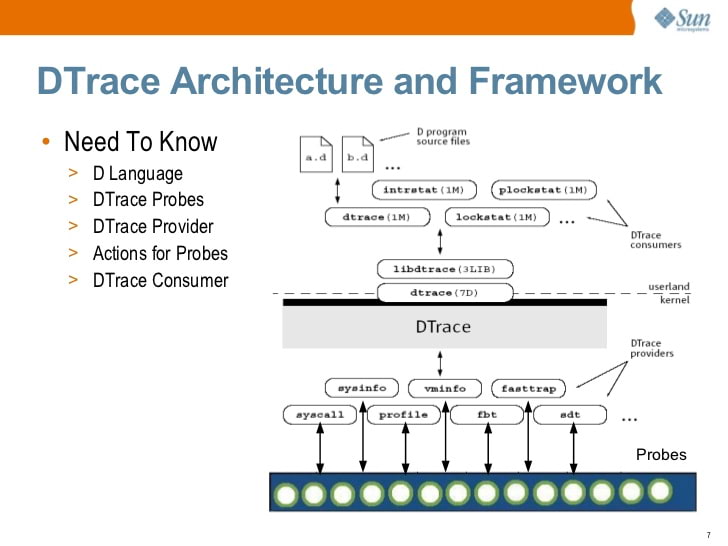 Pengenalan Solaris DTrace (2009) oleh S. Tripathi, Sun Microsystems
Pengenalan Solaris DTrace (2009) oleh S. Tripathi, Sun MicrosystemsPada titik tertentu, Sun membuka sumber untuk DTrace. Saat ini, DTrace tersedia di Solaris, FreeBSD, dan macOS (walaupun versi macOS umumnya tidak dapat dioperasikan karena System Integrity Protection, SIP, telah melanggar banyak prinsip yang dijalankan oleh DTrace).
Ya, Anda memperhatikan dengan benar ... Linux tidak ada dalam daftar ini. Ini bukan masalah teknik, ini masalah lisensi. DTrace dibuka di bawah CDDL, bukan GPL.
Port Linux DTrace telah tersedia sejak 2011, tetapi belum pernah didukung oleh pengembang Linux utama. Pada awal 2018,
Oracle membuka kembali DTrace di bawah GPL , tetapi pada saat itu sudah terlambat.
Linux Tracing Ecosystem
Tidak diragukan lagi pelacakan sangat berguna, dan komunitas Linux telah berusaha mengembangkan solusi sendiri untuk topik ini. Tetapi, tidak seperti Solaris, Linux tidak diatur oleh satu vendor tertentu, dan oleh karena itu tidak ada upaya yang disengaja untuk mengembangkan pengganti DTrace yang berfungsi penuh. Ekosistem jejak Linux telah berevolusi secara perlahan dan alami, memecahkan masalah yang muncul. Dan baru-baru ini saja ekosistem ini tumbuh cukup untuk bersaing secara serius dengan DTrace.
Karena pertumbuhan alami, ekosistem ini mungkin tampak sedikit kacau, terdiri dari banyak komponen berbeda. Untungnya, Julia Evans
menulis tinjauan ekosistem ini (perhatian, tanggal publikasi - 2017, sebelum munculnya bpftrace).
 Ekosistem jejak Linux dijelaskan oleh Julia Evans
Ekosistem jejak Linux dijelaskan oleh Julia EvansTidak semua elemen sama pentingnya. Biarkan saya meringkas secara singkat elemen mana yang saya anggap paling penting.
Sumber acaraData acara dapat berasal dari kernel atau ruang pengguna (aplikasi dan perpustakaan). Beberapa dari mereka tersedia secara otomatis, tanpa upaya pengembang tambahan, sementara yang lain memerlukan pengumuman manual.
 Tinjauan tentang sumber paling penting dari peristiwa yang dilacak di Linux
Tinjauan tentang sumber paling penting dari peristiwa yang dilacak di LinuxDi sisi kernel, ada kprobes (
dari "kernel probes", "sensor kernel", sekitar Per. ) - sebuah mekanisme yang memungkinkan Anda untuk melacak setiap panggilan fungsi di dalam kernel. Dengannya, Anda tidak hanya dapat melacak panggilan sistem, tetapi juga apa yang terjadi di dalamnya (karena titik masuk panggilan sistem memanggil fungsi internal lainnya). Anda juga dapat menggunakan kprobes untuk melacak peristiwa kernel yang bukan panggilan sistem, misalnya, "data buffer sedang ditulis ke disk", "paket TCP dikirim melalui jaringan" atau "pengalihan konteks sedang berlangsung".
Kernel tracepoints memungkinkan penelusuran peristiwa non-standar yang ditentukan oleh pengembang kernel. Peristiwa ini tidak pada tingkat panggilan fungsi. Untuk membuat poin seperti itu, pengembang kernel secara manual menempatkan makro TRACE_EVENT dalam kode kernel.
Kedua sumber memiliki pro dan kontra. Kprobes bekerja "secara otomatis" karena tidak memerlukan pengembang kernel untuk secara manual kode kode. Tetapi acara kprobe dapat berubah secara sewenang-wenang dari satu versi kernel ke versi lain, karena fungsinya terus berubah - mereka ditambahkan, dihapus, diganti namanya.
Titik jejak kernel umumnya lebih stabil dari waktu ke waktu dan dapat memberikan informasi kontekstual yang berguna yang mungkin tidak tersedia jika kprobes digunakan. Menggunakan kprobes, Anda dapat mengakses argumen panggilan fungsi. Tetapi dengan bantuan titik jejak, Anda bisa mendapatkan informasi apa pun yang diputuskan oleh pengembang kernel untuk dijelaskan secara manual.
Di ruang pengguna ada analog dari kprobes - jubah. Ini dirancang untuk melacak panggilan fungsi di ruang pengguna.
Sensor USDT ("Jejak Ruang Pengguna Yang Didefinisikan Statis") adalah analog dari titik jejak kernel di ruang pengguna. Pengembang aplikasi harus secara manual menambahkan sensor USDT ke kode mereka.
Fakta menarik: DTrace telah lama menyediakan C API untuk mendefinisikan sendiri analog sensor USDT (menggunakan makro DTRACE_PROBE). Lacak pengembang ekosistem di Linux memutuskan untuk meninggalkan kode sumber yang kompatibel dengan API ini, sehingga makro DTRACE_PROBE apa pun secara otomatis dikonversi ke sensor USDT!
Oleh karena itu, secara teori, strace dapat diimplementasikan menggunakan kprobes, dan ltrace dapat diimplementasikan menggunakan uprobe. Saya tidak yakin apakah ini sudah dipraktikkan atau belum.
AntarmukaAntarmuka adalah aplikasi yang memungkinkan pengguna untuk dengan mudah menggunakan sumber acara.
Mari kita lihat bagaimana sumber acara bekerja. Alur kerjanya adalah sebagai berikut:
- Kernel merepresentasikan mekanisme - biasanya file / proc atau / sys yang terbuka untuk ditulis - yang merekam niat untuk melacak acara dan apa yang harus mengikuti acara tersebut.
- Setelah terdaftar, kernel melokalisasi kernel / fungsi dalam memori di ruang pengguna / melacak titik / sensor USDT dan mengubah kode mereka sehingga sesuatu yang lain terjadi.
- Hasil dari "sesuatu yang lain" ini dapat dikumpulkan kemudian menggunakan beberapa mekanisme.
Saya tidak ingin melakukan semua ini secara manual! Oleh karena itu, antarmuka datang untuk menyelamatkan: mereka melakukan semua ini untuk Anda.
Ada antarmuka untuk setiap selera dan warna. Di bidang
antarmuka berbasis eBPF, ada yang tingkat rendah yang membutuhkan pemahaman mendalam tentang bagaimana berinteraksi dengan sumber acara dan bagaimana bytecode eBPF bekerja. Dan ada tingkat tinggi dan mudah dioperasikan, meskipun selama keberadaannya mereka tidak menunjukkan fleksibilitas yang besar.
Itu sebabnya bpftrace - antarmuka terbaru - adalah favorit saya. Ini ramah pengguna dan fleksibel seperti DTrace. Tetapi ini cukup baru dan membutuhkan pemolesan.
eBPF
eBPF adalah
bintang jejak Linux baru yang menjadi basis bpftrace. Ketika Anda melacak suatu peristiwa, Anda ingin sesuatu terjadi di kernel. Bagaimana cara fleksibel untuk menentukan apa ini "sesuatu"? Tentu saja, menggunakan bahasa pemrograman (atau menggunakan kode mesin).
eBPF (versi yang disempurnakan dari Berkeley Packet Filter). Ini adalah mesin virtual kinerja tinggi yang berjalan di kernel dan memiliki properti / batasan berikut:
- Semua interaksi ruang pengguna terjadi melalui "kartu" eBPF, yang merupakan penyimpanan data bernilai kunci.
- Tidak ada siklus sehingga setiap program eBPF berakhir pada waktu tertentu.
- Tunggu, kami katakan Batch Filter? Anda benar: mereka awalnya dirancang untuk menyaring paket jaringan. Ini adalah tugas yang serupa: ketika meneruskan paket (terjadinya suatu peristiwa) Anda perlu melakukan beberapa tindakan administratif (menerima, membuang, jurnal atau mengarahkan paket, dll.) Mesin virtual diciptakan untuk mempercepat tindakan seperti itu (dengan kemampuan JIT) kompilasi). Versi "extended" dianggap karena fakta bahwa, dibandingkan dengan versi asli dari Berkeley Packet Filter, eBPF dapat digunakan di luar konteks jaringan.
Itu dia. Dengan bpftrace, Anda dapat menentukan acara mana yang harus dilacak dan apa yang harus terjadi sebagai respons. Bpftrace mengkompilasi program bpftrace tingkat tinggi Anda menjadi bytecode eBPF, melacak peristiwa, dan memuat bytecode ke dalam kernel.
Hari-hari gelap sebelum eBPF
Sebelum eBPF, opsi solusinya, secara sederhana, canggung.
SystemTap adalah sedikit pendahulu "paling serius" untuk bpftrace dalam keluarga Linux. Skrip SystemTap diterjemahkan ke dalam bahasa C dan dimuat ke dalam kernel sebagai modul. Modul kernel yang dihasilkan kemudian dimuat.
Pendekatan ini sangat rapuh dan kurang didukung di luar Red Hat Enterprise Linux. Bagi saya, itu tidak pernah bekerja dengan baik di Ubuntu, yang cenderung merusak SystemTap pada setiap pembaruan kernel karena perubahan dalam struktur data kernel. Dikatakan juga bahwa pada masa awal keberadaannya, SystemTap
dengan mudah menyebabkan panik kernel .
Instalasi Bpftrace
Saatnya menyingsingkan lengan baju Anda! Dalam panduan ini, kita akan melihat menginstal bpftrace di Ubuntu 18.04. Versi distribusi yang lebih baru tidak diinginkan, karena selama instalasi, kita akan membutuhkan paket yang belum dikompilasi untuk mereka.
Instalasi KetergantunganPertama, instal Clang 5.0, lbclang 5.0, dan LLVM 5.0, termasuk semua file header. Kami akan menggunakan paket yang disediakan oleh llvm.org, karena yang ada di repositori Ubuntu
bermasalah .
wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | sudo apt-key add - cat <<EOF | sudo tee -a /etc/apt/sources.list deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main EOF sudo apt update sudo apt install clang-5.0 libclang-5.0-dev llvm-5.0 llvm-5.0-dev
Selanjutnya:
sudo apt install bison cmake flex g++ git libelf-dev zlib1g-dev libfl-dev
Dan akhirnya, instal libbfcc-dev dari hulu, bukan dari repositori Ubuntu. Tidak
ada file header dalam paket yang ada di Ubuntu. Dan masalah ini tidak terpecahkan bahkan pada pukul 18.10.
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list sudo apt update sudo apt install bcc-tools libbcc-examples linux-headers-$(uname -r)
Instalasi utama BpftraceSaatnya untuk menginstal bpftrace sendiri dari sumber! Mari kita mengkloningnya, merakitnya dan menginstalnya di / usr / local:
git clone https://github.com/iovisor/bpftrace cd bpftrace mkdir build && cd build cmake -DCMAKE_BUILD_TYPE=DEBUG .. make -j4 sudo make install
Dan kamu selesai! Eksekusi akan diinstal di / usr / local / bin / bpftrace. Anda dapat mengubah tujuan menggunakan argumen cmake, yang terlihat seperti ini secara default:
DCMAKE_INSTALL_PREFIX=/usr/local.
Contoh satu barisMari kita jalankan beberapa bpftrace single-liners untuk memahami kemampuan kita. Saya mengambil ini dari panduan
Brendan Gregg , yang memiliki deskripsi rinci tentang masing-masing.
# 1. Tampilkan daftar sensor
bpftrace -l 'tracepoint:syscalls:sys_enter_*'
# 2. Salam
bpftrace -e 'BEGIN { printf("hello world\n"); }'
# 3. Membuka file
bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
# 4. Jumlah panggilan sistem per proses
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
# 5. Distribusi panggilan read () dengan jumlah byte
bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid == 18644/ { @bytes = hist(args->retval); }'
# 6. Pelacakan dinamis konten read ()
bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }'
# 7. Waktu yang dihabiskan untuk panggilan read ()
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
# 8. Menghitung acara tingkat proses
bpftrace -e 'tracepoint:sched:sched* { @[name] = count(); } interval:s:5 { exit(); }'
# 9. Membuat profil tumpukan kerja kernel
bpftrace -e 'profile:hz:99 { @[stack] = count(); }'
# 10. Lacak perencana
bpftrace -e 'tracepoint:sched:sched_switch { @[stack] = count(); }'
# 11. Melacak pemblokiran I / O
bpftrace -e 'tracepoint:block:block_rq_complete { @ = hist(args->nr_sector * 512); }'
Lihatlah situs web Brendan Gregg untuk mengetahui
output apa yang dapat dihasilkan oleh tim-tim di atas .
Sintaksis Script dan Contoh Timing I / OString yang melewati saklar '-e' adalah isi skrip bpftrace. Sintaks dalam kasus ini adalah, kondisional, seperangkat konstruksi:
<event source> /<optional filter>/ { <program body> }
Mari kita lihat contoh ketujuh, tentang timing operasi sistem baca file:
kprobe:vfs_read { @start[tid] = nsecs; } <- 1 -><-- 2 -> <---------- 3 --------->
Kami melacak acara dari mekanisme
kprobe , yaitu, kami melacak awal dari fungsi kernel.
Fungsi kernel untuk tracing adalah
vfs_read , fungsi ini dipanggil ketika kernel melakukan operasi baca dari sistem file (VFS dari "Virtual FileSystem", abstraksi dari sistem file di dalam kernel).
Ketika
vfs_read mulai
dijalankan (mis. Sebelum fungsi melakukan pekerjaan yang bermanfaat), program bpftrace dimulai. Menghemat cap waktu saat ini (dalam nanodetik) ke array asosiatif global yang disebut
st art . Kuncinya adalah
tid , referensi ke id utas saat ini.
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); } <-- 1 --> <-- 2 -> <---- 3 ----> <----------------------------- 4 ----------------------------->
1. Kami melacak acara dari mekanisme
kretprobe , yang mirip dengan
kprobe , kecuali bahwa itu dipanggil ketika fungsi mengembalikan hasil eksekusi.
2. Fungsi kernel untuk tracing adalah
vfs_read .
3. Ini adalah filter opsional. Ia memeriksa apakah waktu mulai telah direkam sebelumnya. Tanpa filter ini, program dapat dimulai saat membaca dan hanya menangkap akhir, menghasilkan
perkiraan waktu
nsecs - 0 , bukannya
nsecs - mulai .
4. Badan program.
nsecs - st art [tid] menghitung berapa banyak waktu yang telah berlalu sejak awal fungsi vfs_read.
@ns [comm] = hist (...) menambahkan data yang ditentukan ke histogram dua dimensi yang disimpan dalam
@ns . Kunci
comm mengacu pada nama aplikasi saat ini. Jadi kita akan memiliki perintah histogram dengan perintah.
delete (...) menghapus waktu mulai dari array asosiatif, karena kita tidak lagi membutuhkannya.
Ini adalah kesimpulan terakhir. Harap dicatat bahwa semua histogram ditampilkan secara otomatis. Penggunaan eksplisit perintah histogram cetak tidak diperlukan.
@ns bukan variabel khusus, jadi histogram tidak ditampilkan karena itu.
@ns[snmp-pass]: [0, 1] 0 | | [2, 4) 0 | | [4, 8) 0 | | [8, 16) 0 | | [16, 32) 0 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 0 | | [256, 512) 27 |@@@@@@@@@ | [512, 1k) 125 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [1k, 2k) 22 |@@@@@@@ | [2k, 4k) 1 | | [4k, 8k) 10 |@@@ | [8k, 16k) 1 | | [16k, 32k) 3 |@ | [32k, 64k) 144 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [64k, 128k) 7 |@@ | [128k, 256k) 28 |@@@@@@@@@@ | [256k, 512k) 2 | | [512k, 1M) 3 |@ | [1M, 2M) 1 | |
Contoh Sensor USDTMari kita ambil kode C ini dan simpan dalam file
tracetest.c :
#include <sys/sdt.h> #include <sys/time.h> #include <unistd.h> #include <stdio.h> static long myclock() { struct timeval tv; gettimeofday(&tv, NULL); DTRACE_PROBE1(tracetest, testprobe, tv.tv_sec); return tv.tv_sec; } int main(int argc, char **argv) { while (1) { myclock(); sleep(1); } return 0; }
Program ini berjalan tanpa henti dengan menelepon
myclock () sekali per detik.
myclock () menanyakan waktu saat ini dan mengembalikan jumlah detik sejak awal era.
Panggilan ke
DTRACE_PROBE1 di sini mendefinisikan titik jejak USDT statis.
- Makro DTRACE_PROBE1 diambil dari sys / sdt.h. Makro resmi USDT, yang melakukan hal yang sama, disebut STAP_PROBE1 (STAP dari SystemTap, yang merupakan mekanisme Linux pertama yang didukung dalam USDT). Tetapi karena USDT kompatibel dengan sensor ruang pengguna DTrace, DTRACE_PROBE1 hanyalah referensi ke STAP_PROBE1 .
- Parameter pertama adalah nama penyedia. Saya percaya ini adalah sisa dari DTrace, karena bpftrace sepertinya tidak melakukan sesuatu yang berguna dengannya. Namun, ada nuansa ( yang saya temukan ketika men-debug masalah pada permintaan 328 ): nama penyedia harus identik dengan nama file aplikasi biner, jika tidak bpftrace tidak akan dapat menemukan titik jejak.
- Parameter kedua adalah nama titik jejak.
- Setiap parameter tambahan adalah konteks yang disediakan oleh pengembang. Angka 1 di DTRACE_PROBE1 berarti bahwa kami ingin memberikan satu parameter tambahan.
Mari kita pastikan sys / sdt.h tersedia untuk kita, dan menyusun program:
sudo apt install systemtap-sdt-dev gcc tracetest.c -o tracetest -Wall -g
Kami menginstruksikan bpftrace untuk mengeluarkan PID dan "waktu adalah [angka]" setiap kali
testprobe tercapai:
sudo bpftrace -e 'usdt:/full-path-to/tracetest:testprobe { printf("%d: time is %d\n", pid, arg0); }'
Bpftrace terus bekerja sementara kami menekan Ctrl-C. Oleh karena itu, buka terminal baru dan jalankan
tracetest di sana:
# Di terminal baru
./tracetest
Kembali ke terminal pertama dengan bpftrace, di sana Anda akan melihat sesuatu seperti:
Attaching 1 probe... 30909: time is 1549023215 30909: time is 1549023216 30909: time is 1549023217 ... ^C
Contoh alokasi memori menggunakan glibc ptmallocSaya menggunakan bpftrace untuk memahami mengapa Ruby menggunakan begitu banyak memori. Dan sebagai bagian dari penelitian saya, saya perlu pemahaman tentang bagaimana pengalokasi memori glibc menggunakan
daerah memori .
Untuk mengoptimalkan kinerja multi-core, pengalokasi memori glibc mengalokasikan beberapa "area" dari OS. Ketika aplikasi meminta alokasi memori, pengalokasi memilih area yang tidak digunakan, dan menandai bagian dari area ini sebagai "bekas". Karena utas menggunakan area yang berbeda, jumlah kunci berkurang, yang mengarah pada peningkatan kinerja multi-utas.
Tetapi pendekatan ini menghasilkan banyak sampah, dan tampaknya konsumsi memori yang begitu tinggi di Ruby justru karena itu. Untuk lebih memahami sifat sampah ini, saya bertanya-tanya: apa artinya “memilih area yang tidak digunakan”? Ini bisa berarti salah satu dari:
- Setiap kali malloc () dipanggil, pengalokasi akan beralih ke semua area dan menemukan area yang saat ini tidak dikunci. Dan hanya jika mereka semua diblokir, dia akan mencoba membuat yang baru.
- Malloc pertama kali () dipanggil pada utas tertentu (atau ketika utas dimulai), pengalokasi akan memilih salah satu yang saat ini tidak diblokir. Dan jika mereka semua diblokir, ia akan mencoba membuat yang baru.
- Malloc pertama kali () dipanggil pada utas tertentu (atau ketika utas dimulai), pengalokasi akan mencoba membuat wilayah baru, terlepas dari apakah ada daerah yang tidak dikunci. Hanya jika area baru tidak dapat dibuat (misalnya, ketika batasnya habis), itu akan menggunakan kembali yang sudah ada.
- Mungkin ada lebih banyak opsi yang belum saya pertimbangkan.
Tidak ada jawaban khusus dalam dokumentasi, yang mana dari fitur-fitur ini memungkinkan Anda untuk memilih area yang tidak digunakan. Saya mempelajari kode sumber untuk glibc, yang menyarankan opsi 3 bisa melakukan ini. Tapi saya ingin secara eksperimental memverifikasi bahwa saya menafsirkan kode sumber dengan benar, tanpa perlu kode debugging di glibc.
Berikut adalah fungsi pengalokasi memori glibc yang menciptakan area baru. Tetapi Anda dapat memanggilnya hanya setelah memeriksa batas.
static mstate _int_new_arena(size_t size) { mstate arena; size = calculate_how_much_memory_to_ask_from_os(size); arena = do_some_stuff_to_allocate_memory_from_os(); LIBC_PROBE(memory_arena_new, 2, arena, size); do_more_stuff(); return arena; }
Bisakah saya menggunakan
uprobes untuk melacak fungsi
_int_new_arena ? Sayangnya tidak. Untuk beberapa alasan simbol ini tidak tersedia di glibc Ubuntu 18.04. Bahkan setelah menginstal simbol debugging.
Untungnya, ada sensor USDT dalam fungsi ini.
LIBC_PROBE adalah alias makro untuk
STAP_PROBE .
Nama penyedia adalah libc.
Nama sensor adalah memory_arena_new.
Angka 2 berarti ada 2 argumen tambahan yang ditentukan oleh pengembang.
arena adalah alamat area yang diekstrak dari OS, dan ukurannya adalah ukurannya.
Sebelum kita dapat menggunakan sensor ini, kita perlu
menyiasati masalah 328 . Kita perlu membuat tautan simbolik dengan glibc di suatu tempat dengan nama
libc , karena bpftrace mengharapkan nama pustaka (yang sebaliknya akan menjadi
libc-2.27.so ) untuk menjadi identik dengan nama penyedia
(libc) .
ln -s /lib/x86_64-linux-gnu/libc-2.27.so /tmp/libc
Sekarang kami menginstruksikan bpftrace untuk menghubungkan ke sensor USDT memory_arena_new, yang nama vendornya adalah
libc :
sudo bpftrace -e 'usdt:/tmp/libc:memory_arena_new { printf("PID %d: created new arena at %p, size %d\n", pid, arg0, arg1); }'
Di terminal lain, kita akan menjalankan Ruby, yang akan membuat tiga utas yang tidak melakukan apa pun dan berakhir dalam sedetik. Karena pemblokiran global penerjemah, Ruby
malloc () tidak boleh dipanggil secara paralel oleh utas yang berbeda.
ruby -e '3.times { Thread.new { } }; sleep 1'
Kembali ke terminal dengan bpftrace, kita akan melihat:
Attaching 1 probe... PID 431: created new arena at 0x7f40e8000020, size 576 PID 431: created new arena at 0x7f40e0000020, size 576 PID 431: created new arena at 0x7f40e4000020, size 576
Inilah jawaban untuk pertanyaan kami! Setiap kali Anda membuat utas baru di Ruby, glibc menyoroti area baru terlepas dari daya saing.
Apa titik jejak yang tersedia? Apa yang harus saya lacak?Anda dapat membuat daftar semua perangkat keras, timer, kprobe, dan titik jejak kernel statis dengan menjalankan perintah:
sudo bpftrace -l
Anda dapat membuat daftar semua titik jejak uprobe (karakter fungsi) aplikasi atau perpustakaan dengan melakukan:
nm /path-to-binary
Anda dapat membuat daftar semua titik jejak aplikasi atau perpustakaan USDT dengan menjalankan perintah berikut:
/usr/share/bcc/tools/tplist -l /path-to/binary
Mengenai titik jejak mana yang digunakan: tidak ada salahnya untuk memahami kode sumber apa yang akan Anda lacak. Saya sarankan Anda mempelajari kode sumber.
Tip: format struktural untuk melacak titik di kernelBerikut ini tip bermanfaat tentang titik jejak kernel. Anda dapat memeriksa kolom argumen mana yang tersedia dengan membaca file / sys / kernel / debug / tracing / events!
Misalnya, Anda ingin melacak panggilan ke
madvise (..., MADV_DONTNEED) :
sudo bpftrace -l | grep madvise
- akan memberi tahu kami bahwa kami dapat menggunakan tracepoint: syscalls: sys_enter_madvise.
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_madvise/format
- akan memberi kami informasi berikut:
name: sys_enter_madvise ID: 569 format: field:unsigned short common_type; offset:0; size:2; signed:0; field:unsigned char common_flags; offset:2; size:1; signed:0; field:unsigned char common_preempt_count; offset:3; size:1; signed:0; field:int common_pid; offset:4; size:4; signed:1; field:int __syscall_nr; offset:8; size:4; signed:1; field:unsigned long start; offset:16; size:8; signed:0; field:size_t len_in; offset:24; size:8; signed:0; field:int behavior; offset:32; size:8; signed:0; print fmt: "start: 0x%08lx, len_in: 0x%08lx, behavior: 0x%08lx", ((unsigned long)(REC->start)), ((unsigned long)(REC->len_in)), ((unsigned long)(REC->behavior))
Madvise tanda tangan sesuai dengan manual:
(void * addr, size_t length, int advice) . Tiga bidang terakhir dari struktur ini sesuai dengan parameter ini!
Apa arti dari MADV_DONTNEED? Dinilai oleh grep MADV_DONTNEED / usr / include, itu sama dengan 4:
/usr/include/x86_64-linux-gnu/bits/mman-linux.h:80:# define MADV_DONTNEED 4 /* Don't need these pages. */
Jadi tim bpftrace kami menjadi:
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_madvise /args->behavior == 4/ { printf("madvise DONTNEED called\n"); }'
Kesimpulan
Bpftrace luar biasa! Bpftrace adalah masa depan!
Jika Anda ingin tahu lebih banyak tentang dia, maka saya sarankan Anda membiasakan diri dengan
kepemimpinannya , serta
posting pertama tahun 2019 di blog Brendan Gregg.
Debugging yang bagus!