Pada tahun 1943, neuropsikolog Amerika, McCallock dan Pitts mengembangkan model komputer dari jaringan saraf, dan pada tahun 1958 jaringan single-layer
pertama yang bekerja mengenali beberapa huruf. Sekarang, jaringan saraf tidak hanya digunakan untuk apa: untuk memprediksi nilai tukar, mendiagnosis penyakit, autopilot, dan membuat grafik dalam permainan komputer. Tentang yang terakhir dan bicara.
Evgeni Tumanov bekerja sebagai insinyur Deep Learning di
NVIDIA . Berdasarkan hasil pidatonya di konferensi HighLoad ++, kami menyiapkan cerita tentang penggunaan Machine Learning dan Deep Learning dalam grafik. Pembelajaran mesin tidak berakhir dengan NLP, Visi Komputer, sistem rekomendasi, dan tugas pencarian. Bahkan jika Anda tidak terlalu mengenal bidang ini, Anda dapat menerapkan praktik terbaik dari artikel di bidang atau industri Anda.
Kisah itu akan terdiri dari tiga bagian. Kami akan meninjau tugas-tugas dalam grafik yang diselesaikan dengan bantuan pembelajaran mesin, mendapatkan ide utama, dan menggambarkan kasus penerapan ide ini dalam tugas tertentu, dan khususnya dalam
rendering awan .
DL / ML yang diawasi dalam grafik, atau pelatihan guru dalam grafik
Mari kita menganalisis dua kelompok tugas. Untuk memulainya, kami secara singkat menunjukkannya.
Dunia Nyata atau render engine :
- Pembuatan animasi yang dapat dipercaya: penggerak, animasi wajah.
- Gambar yang diberikan setelah pemrosesan: supersampling, anti-aliasing.
- Slowmotion: interpolasi bingkai.
- Generasi material.
Kelompok tugas kedua sekarang secara konvensional disebut "
Algoritma berat ". Kami menyertakan tugas-tugas seperti rendering objek kompleks, seperti awan, dan
simulasi fisik : air, asap.
Tujuan kami adalah untuk memahami perbedaan mendasar antara kedua kelompok. Mari kita bahas tugas-tugasnya lebih detail.
Pembuatan animasi yang dapat dipercaya: penggerak, animasi wajah
Dalam beberapa tahun terakhir, banyak
artikel telah muncul , di mana para peneliti menawarkan cara-cara baru untuk menghasilkan animasi yang indah. Menggunakan karya seniman itu mahal, dan menggantinya dengan algoritma akan sangat bermanfaat bagi semua orang. Setahun yang lalu, di NVIDIA, kami mengerjakan sebuah proyek di mana kami terlibat dalam animasi wajah karakter dalam game: menyinkronkan wajah pahlawan dengan trek audio pidato. Kami mencoba untuk "menghidupkan kembali" wajah sehingga setiap titik di atasnya bergerak, dan di atas semua bibir, karena ini adalah momen paling sulit dalam animasi. Secara manual seorang seniman melakukan ini secara mahal dan untuk waktu yang lama. Apa saja pilihan untuk mengatasi masalah ini dan membuat
dataset untuknya?
Pilihan pertama adalah
mengidentifikasi vokal: mulut terbuka pada vokal, vokal di mulut . Ini adalah algoritma yang sederhana, tetapi terlalu sederhana. Dalam permainan, kami menginginkan lebih banyak kualitas. Pilihan kedua adalah
membuat orang membaca teks yang berbeda dan menuliskan wajah mereka, dan kemudian membandingkan huruf yang mereka ucapkan dengan ekspresi wajah. Ini adalah ide yang bagus, dan kami melakukannya dalam
proyek bersama dengan Remedy Entertainment. Satu-satunya perbedaan adalah bahwa dalam permainan kami tidak menampilkan video, tetapi model 3D titik. Untuk merakit dataset, Anda perlu memahami bagaimana titik-titik spesifik pada gerakan wajah. Kami mengambil aktor, diminta untuk membaca teks dengan intonasi yang berbeda, memotret pada kamera yang sangat bagus dari sudut yang berbeda, setelah itu kami mengembalikan model wajah 3D pada setiap frame, dan memperkirakan posisi titik pada wajah dengan suara.
Render Image Post-Processing: supersampling, anti-aliasing
Pertimbangkan kasus dari permainan tertentu: kami memiliki mesin yang menghasilkan gambar dalam resolusi yang berbeda. Kami ingin membuat gambar dalam resolusi 1000 × 500 piksel, dan menunjukkan kepada pemain 2000 × 1000 - ini akan lebih cantik. Bagaimana cara menyusun dataset untuk tugas ini?
Pertama-tama render gambar dalam resolusi tinggi, kemudian turunkan kualitasnya, dan kemudian coba latih sistem untuk mengubah gambar dari resolusi rendah ke resolusi tinggi.
Slowmotion: interpolasi bingkai
Kami memiliki video, dan kami ingin jaringan menambahkan frame di tengah - untuk menginterpolasi frame. Idenya jelas - untuk merekam video nyata dengan sejumlah besar bingkai, menghapus yang menengah dan mencoba memprediksi apa yang dihapus oleh jaringan.
Generasi Material
Kami tidak akan terlalu memikirkan generasi bahan. Esensinya adalah bahwa kita mengambil, misalnya, sepotong kayu di beberapa sudut pencahayaan, dan menyisipkan pandangan dari sudut lain.
Kami memeriksa kelompok masalah pertama. Yang kedua berbeda secara mendasar. Kita akan berbicara tentang rendering objek kompleks, seperti awan, nanti, tetapi sekarang kita akan berurusan dengan simulasi fisik.
Simulasi fisik air dan asap
Bayangkan sebuah kolam di mana benda padat bergerak berada. Kami ingin memprediksi pergerakan partikel cairan. Ada partikel di kolam pada waktu
t , dan pada waktu
t + wet kami ingin mendapatkan posisi mereka. Untuk setiap partikel, kami memanggil jaringan saraf dan mendapatkan jawaban di mana itu akan berada di frame berikutnya.
Untuk mengatasi masalah,
kami menggunakan
persamaan Navier-Stokes , yang menggambarkan gerakan fluida. Untuk simulasi air yang masuk akal dan benar secara fisik, kita harus menyelesaikan persamaan atau perkiraannya. Ini dapat dilakukan dengan cara komputasi, yang telah banyak ditemukan selama 50 tahun terakhir: algoritma SPH, FLIP, atau Position Based Fluid.
Perbedaan antara kelompok tugas pertama dari yang kedua
Pada kelompok pertama, guru untuk algoritme adalah sesuatu di atas: rekaman dari kehidupan nyata, seperti dalam kasus individu, atau sesuatu dari mesin, misalnya, rendering gambar. Dalam kelompok masalah kedua, kami menggunakan metode matematika komputasi. Dari pembagian tematik ini, sebuah ide tumbuh.
Ide utama
Kami memiliki tugas komputasi yang kompleks yang panjang, sulit dan sulit untuk diselesaikan dengan metode universitas komputasi klasik. Untuk mengatasinya dan mempercepat, bahkan mungkin kehilangan sedikit kualitas, kita perlu:
- menemukan tempat yang paling memakan waktu dalam tugas di mana kode bertahan paling lama;
- lihat apa yang dihasilkan garis ini;
- cobalah untuk memprediksi hasil garis menggunakan jaringan saraf atau algoritma pembelajaran mesin lainnya.
Ini adalah metodologi umum dan ide utamanya adalah resep tentang cara menemukan aplikasi untuk pembelajaran mesin. Apa yang harus Anda lakukan agar ide ini bermanfaat? Tidak ada jawaban yang pasti - gunakan kreativitas, lihat pekerjaan Anda dan temukan. Saya membuat grafik, dan saya tidak begitu akrab dengan bidang lain, tetapi saya bisa membayangkan bahwa di lingkungan akademik - dalam fisika, kimia, robotika - Anda pasti dapat menemukan aplikasi. Jika Anda memecahkan persamaan fisik yang kompleks di tempat kerja Anda, maka Anda juga dapat menemukan aplikasi untuk ide ini. Untuk kejelasan, pertimbangkan kasus tertentu.
Tugas rendering cloud
Kami terlibat dalam proyek ini di NVIDIA enam bulan lalu: tugasnya adalah menggambar awan yang benar secara fisik, yang direpresentasikan sebagai kepadatan tetesan cairan di ruang angkasa.
Awan adalah objek yang kompleks secara fisik, suspensi tetesan cairan yang tidak dapat dimodelkan sebagai objek padat.
Tidak akan mungkin untuk memaksakan tekstur dan render di awan, karena tetesan air sulit secara geometris terletak di ruang 3d dan rumit dalam dirinya sendiri: mereka praktis tidak menyerap warna, tetapi memantulkannya, secara anisotropis - ke segala arah dengan cara yang berbeda.
Jika Anda melihat setetes air, yang disinari matahari, dan vektor-vektor dari mata dan matahari yang jatuh itu sejajar, maka puncak besar dalam intensitas cahaya akan diamati. Ini menjelaskan fenomena fisik yang dilihat semua orang: dalam cuaca cerah, salah satu batas awan sangat cerah, hampir putih. Kami melihat perbatasan awan, dan garis pandang dan vektor dari perbatasan ke matahari ini hampir paralel.

Cloud adalah objek yang kompleks secara fisik dan renderingnya oleh algoritma klasik membutuhkan banyak waktu. Kami akan berbicara tentang algoritma klasik sedikit kemudian. Bergantung pada parameternya, prosesnya bisa memakan waktu berjam-jam atau bahkan berhari-hari. Bayangkan bahwa Anda seorang seniman dan menggambar film dengan efek khusus. Anda memiliki pemandangan yang rumit dengan pencahayaan berbeda yang ingin Anda mainkan. Kami membuat satu topologi cloud - saya tidak menyukainya, dan Anda ingin menggambar ulang dan mendapatkan jawaban di sana. Penting untuk mendapatkan jawaban dari satu perubahan parameter secepat mungkin. Ini masalah. Karena itu, mari kita coba mempercepat proses ini.
Solusi klasik
Untuk menyelesaikan masalah, Anda harus menyelesaikan persamaan rumit ini.

Persamaannya keras, tetapi mari kita pahami makna fisiknya. Pertimbangkan balok yang tertembus awan yang menembus awan. Bagaimana cahaya masuk ke kamera ke arah ini? Pertama, cahaya dapat mencapai titik keluarnya sinar dari awan, dan kemudian merambat sepanjang sinar ini di dalam awan.
Untuk metode kedua "perambatan cahaya sepanjang arah" adalah istilah integral dari persamaan. Arti fisiknya adalah sebagai berikut.
Pertimbangkan segmen di dalam cloud pada ray - dari titik masuk ke titik keluar. Integrasi dilakukan tepat di atas segmen ini, dan untuk setiap titik di atasnya kami mempertimbangkan apa yang disebut
energi cahaya tidak langsung L (x, ω) - arti integral I
1 - pencahayaan tidak langsung pada titik tersebut. Tampaknya karena fakta bahwa tetes dengan cara yang berbeda memantulkan sinar matahari. Oleh karena itu, sejumlah besar sinar yang dimediasi dari tetesan sekitarnya sampai pada intinya. I
1 adalah integral dari bola yang mengelilingi titik pada sinar. Dalam algoritma klasik, dihitung menggunakan metode
Monte Carlo .
Algoritma klasik.
- Render gambar dari piksel, dan hasilkan sinar yang bergerak dari tengah kamera ke piksel lalu lebih jauh.
- Kami menyeberangi sinar dengan awan, kami menemukan titik masuk dan keluar.
- Kami mempertimbangkan istilah terakhir dari persamaan: untuk menyeberang, terhubung dengan matahari.
- Memulai sampling kepentingan
Bagaimana mempertimbangkan perkiraan Monte Carlo I
1 kita tidak akan menganalisis, karena itu sulit dan tidak begitu penting. Cukuplah untuk mengatakan bahwa ini adalah bagian terpanjang dan paling sulit dalam keseluruhan algoritma.
Kami menghubungkan jaringan saraf
Dari ide utama dan deskripsi algoritma klasik, berikut adalah resep tentang cara menerapkan jaringan saraf untuk tugas ini. Yang paling sulit adalah menghitung skor Monte Carlo. Ini memberikan angka yang berarti pencahayaan tidak langsung pada suatu titik, dan inilah yang ingin kita prediksi.

Kami memutuskan pada pintu keluar, sekarang kami akan memahami pintu masuk - dari informasi apa akan jelas berapa besar cahaya tidak langsung pada titik tersebut. Ini adalah cahaya yang dipantulkan dari banyak tetesan air yang mengelilingi titik. Topologi cahaya sangat dipengaruhi oleh topologi kerapatan di sekitar titik, arah ke sumber dan arah ke kamera.
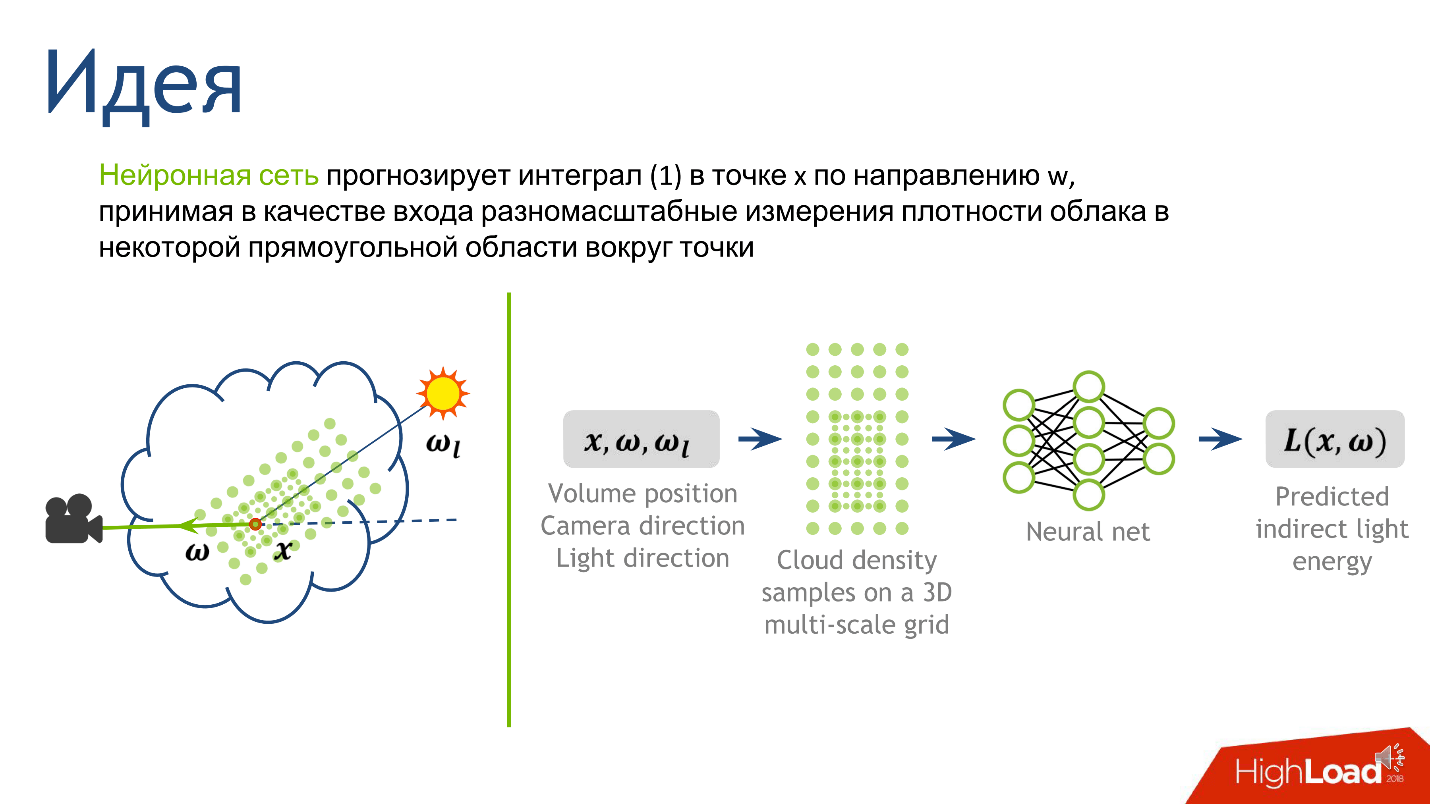
Untuk membangun pintu masuk ke jaringan saraf, kami menggambarkan kepadatan lokal. Ada banyak cara untuk melakukan ini, tetapi kami fokus pada artikel
Deep Scattering: Rendering Awan Atmospheric dengan Radiance Predicting Neural Networks, Kallwcit et al. 2017 dan banyak ide datang dari sana.
Secara singkat, metode representasi lokal kepadatan di sekitar titik terlihat seperti ini.
- Perbaiki konstanta yang cukup kecil . Biarkan itu menjadi jalan bebas rata-rata di awan.
- Gambarkan titik di segmen kami dengan kotak persegi panjang volumetrik dengan ukuran tetap , misalnya 5 * 5 * 9. Di tengah kubus ini akan menjadi poin kami. Spasi kisi adalah konstanta tetap kecil. Pada node grid kita akan mengukur kepadatan awan.
- Mari kita tingkatkan konstanta sebanyak 2 kali , gambar grid yang lebih besar, dan lakukan hal yang sama - mengukur kerapatan pada node grid.
- Ulangi langkah sebelumnya beberapa kali . Kami melakukan ini 10 kali, dan setelah prosedur kami mendapatkan 10 grid - 10 tensor, masing-masing menyimpan kepadatan awan, dan masing-masing tensor mencakup lingkungan yang semakin besar di sekitar titik.
Pendekatan ini memberi kita deskripsi paling rinci tentang area kecil - semakin dekat ke titik, semakin detail deskripsi. Memutuskan output dan input jaringan, masih harus mengerti bagaimana melatihnya.
Pelatihan
Kami akan menghasilkan 100 cloud yang berbeda dengan topologi yang berbeda. Kami hanya akan membuat mereka menggunakan algoritma klasik, menuliskan apa yang diterima algoritma di baris di mana ia melakukan integrasi Monte Carlo, dan menuliskan properti yang sesuai dengan titik. Jadi kami mendapatkan dataset untuk dipelajari.

Apa yang diajarkan, atau arsitektur jaringan
Arsitektur jaringan untuk tugas ini bukanlah kuncinya, dan jika Anda tidak mengerti apa-apa, jangan khawatir - ini bukan hal terpenting yang ingin saya sampaikan. Kami menggunakan arsitektur berikut: untuk setiap titik ada 10 tensor, yang masing-masing dihitung pada grid skala yang semakin besar. Masing-masing tensor ini jatuh ke blok yang sesuai.
- Pertama ke dalam layer reguler yang terhubung penuh .
- Setelah keluar dari lapisan pertama yang terhubung sepenuhnya, pada lapisan kedua yang terhubung penuh, yang tidak memiliki aktivasi.
Lapisan yang sepenuhnya terhubung tanpa aktivasi hanyalah perkalian dengan sebuah matriks. Untuk hasil mengalikan dengan matriks kami menambahkan output dari
blok-residual sebelumnya, dan hanya kemudian menerapkan aktivasi.
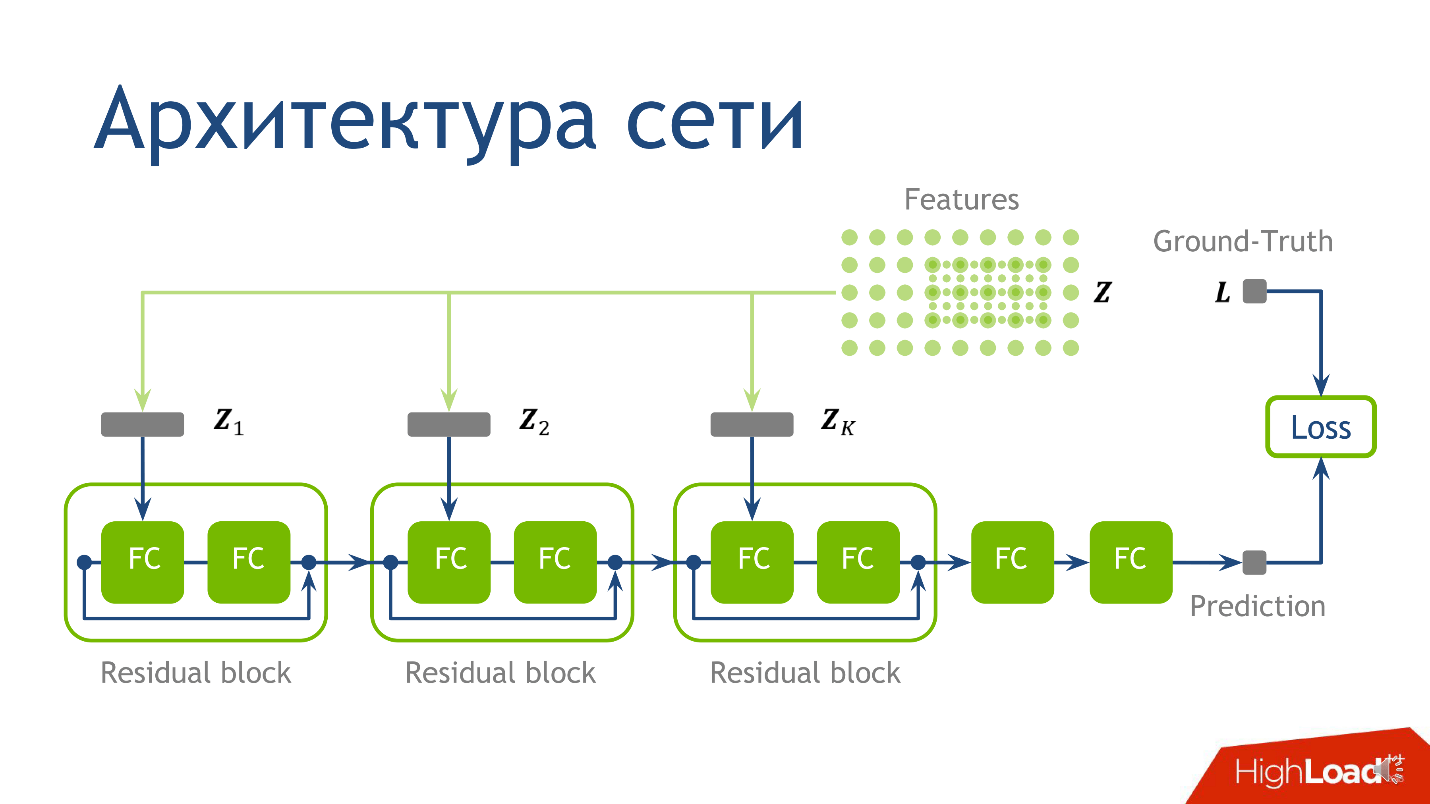
Kami mengambil titik, menghitung nilai pada masing-masing grid, meletakkan tensor yang diperoleh di blok residu yang sesuai - dan Anda dapat melakukan
inferensi jaringan saraf - mode produksi jaringan. Kami melakukan ini dan memastikan bahwa kami mendapatkan gambar awan.
Hasil
Pengamatan pertama - kami mendapatkan apa yang kami inginkan: panggilan jaringan saraf, dibandingkan dengan estimasi Monte Carlo, bekerja lebih cepat, yang sudah baik.
Tetapi ada pengamatan lain pada hasil pelatihan - ini adalah konvergensi dalam jumlah sampel. Apa yang kamu bicarakan

Saat merender gambar, mari kita potong menjadi ubin kecil - kuadrat piksel, katakan 16 * 16. Pertimbangkan satu ubin gambar tanpa kehilangan keumuman. Ketika kami membuat ubin ini, untuk setiap piksel dari kamera kami melepaskan banyak sinar yang sesuai dengan satu piksel, dan menambahkan sedikit noise ke sinar sehingga mereka sedikit berbeda. Sinar ini disebut
anti-aliasing dan diciptakan untuk mengurangi noise pada gambar akhir.
- Kami merilis beberapa sinar anti-aliasing untuk setiap piksel.
- Di bagian dalam sinar dari kamera, di awan, di segmen, kami menghitung n sampel titik di mana kami ingin melakukan penilaian Monte Carlo, atau memanggil jaringan untuk mereka.
Masih ada sampel yang sesuai dengan koneksi dengan sumber cahaya. Mereka muncul ketika kita menghubungkan suatu titik dengan sumber cahaya, misalnya, dengan matahari. Ini mudah dilakukan, karena matahari adalah sinar yang jatuh di bumi yang sejajar satu sama lain. Sebagai contoh, langit, sebagai sumber cahaya, jauh lebih rumit, karena muncul sebagai bola yang sangat jauh, yang memiliki fungsi warna dalam arah. Jika vektor terlihat lurus secara vertikal ke langit, maka warnanya biru. Semakin rendah terang. Di bagian bawah bola biasanya warna netral meniru bumi: hijau, coklat.
Ketika kita menghubungkan suatu titik dengan langit untuk memahami seberapa banyak cahaya yang masuk ke dalamnya, kita selalu melepaskan beberapa sinar untuk mendapatkan jawaban yang menyatu dengan kebenaran. Kami melepaskan lebih dari satu sinar untuk mendapatkan nilai yang lebih baik. Oleh karena itu, seluruh
render pipa membutuhkan begitu banyak sampel.
Ketika kami melatih jaringan saraf, kami memperhatikan bahwa itu mempelajari solusi yang jauh lebih rata-rata. Jika kami memperbaiki jumlah sampel, kami melihat bahwa algoritma klasik konvergen ke baris kiri kolom gambar, dan jaringan belajar ke kanan. Ini tidak berarti bahwa metode asli buruk - kami hanya bertemu lebih cepat. Ketika kita menambah jumlah sampel, metode asli akan semakin dekat dengan apa yang kita dapatkan.
Hasil utama kami yang ingin kami dapatkan adalah peningkatan kecepatan rendering. Untuk cloud tertentu dalam resolusi spesifik dengan parameter sampel, kami melihat bahwa gambar yang diperoleh oleh jaringan dan metode klasik hampir identik, tetapi kami mendapatkan gambar yang tepat 800 kali lebih cepat.

Implementasi
Ada program Open Source untuk pemodelan 3D -
Blender , yang mengimplementasikan algoritma klasik. Kami sendiri tidak menulis algoritme, tetapi menggunakan program ini: kami melatih Blender, menuliskan semua yang kami butuhkan di balik algoritme. Produksi juga dilakukan dalam program: kami melatih jaringan di
TensorFlow , mentransfernya ke C ++ menggunakan TensorRT, dan kami sudah mengintegrasikan jaringan TensorRT ke dalam Blender, karena kodenya terbuka.
Karena kami melakukan segalanya untuk Blender, solusi kami memiliki semua fitur dari program ini: kami dapat membuat semua jenis pemandangan dan banyak awan. Awan dalam solusi kami ditetapkan dengan membuat kubus, di dalamnya kami menentukan fungsi kepadatan dengan cara tertentu untuk program 3D. Kami mengoptimalkan proses ini - kepadatan cache. Jika pengguna ingin menggambar cloud yang sama pada tumpukan pengaturan adegan yang berbeda: di bawah kondisi pencahayaan yang berbeda, dengan objek yang berbeda di atas panggung, maka ia tidak perlu terus-menerus menghitung ulang kepadatan awan. Apa yang terjadi, Anda dapat menonton
videonya .
Sebagai kesimpulan, saya ulangi sekali lagi ide utama yang ingin saya sampaikan:
jika dalam pekerjaan Anda untuk waktu yang lama dan sulit Anda menganggap sesuatu sebagai beberapa algoritma komputasi tertentu, dan ini tidak cocok untuk Anda - temukan tempat tersulit dalam kode, ganti dengan jaringan saraf, dan mungkin ini akan membantu Anda.Jaringan saraf dan kecerdasan buatan adalah salah satu topik baru yang akan kita bahas di Saint HighLoad ++ 2019 pada bulan April. Kami telah menerima beberapa aplikasi tentang topik ini, dan jika Anda memiliki pengalaman yang keren, tidak harus di jaringan saraf, kirimkan aplikasi untuk laporan sebelum 1 Maret . Kami akan senang melihat Anda di antara pembicara kami.
Untuk mengikuti perkembangan program dan laporan apa yang diterima, berlangganan buletin . Di dalamnya, kami hanya menerbitkan koleksi tematik laporan, artikel, dan video baru.