Dalam
artikel terakhir, kami memeriksa batasan dan hambatan yang muncul saat Anda perlu mengukur data secara horizontal dan memiliki jaminan properti transaksi ACID. Pada artikel ini, kita berbicara tentang teknologi FoundationDB dan memahami bagaimana ini membantu untuk mengatasi keterbatasan ini ketika mengembangkan aplikasi mission-critical.
FoundationDB adalah database NoSQL terdistribusi dengan transaksi ACID Serializable yang menyimpan pasangan toko nilai kunci yang diurutkan. Kunci dan nilai dapat berupa urutan byte yang sewenang-wenang. Itu tidak memiliki satu titik kejadian - semua mesin cluster sama. Itu sendiri mendistribusikan data di antara server cluster dan skala on the fly: ketika Anda perlu menambahkan sumber daya ke cluster, Anda cukup menambahkan alamat mesin baru pada server konfigurasi dan database mengambilnya sendiri.
Di FoundationDB, transaksi tidak pernah memblokir satu sama lain. Membaca diimplementasikan melalui
kontrol versi multiversion (MVCC), dan membaca diimplementasikan melalui
kontrol concurrency optimis (OCC). Pengembang mengklaim bahwa ketika semua mesin di cluster berada di pusat data yang sama, latensi tulis adalah 2-3 ms, dan latensi baca kurang dari satu milidetik. Dokumentasi berisi perkiraan 10-15 ms, yang mungkin lebih dekat dengan hasil dalam kondisi nyata.
 * Tidak mendukung properti ACID pada banyak pecahan.
* Tidak mendukung properti ACID pada banyak pecahan.FoundationDB memiliki keunggulan unik - pengerjaan ulang otomatis. DBMS itu sendiri memastikan bahkan memuat mesin di cluster: ketika satu server penuh, itu mendistribusikan kembali data ke yang tetangga di latar belakang. Pada saat yang sama, jaminan tingkat Serializable untuk semua transaksi dipertahankan, dan satu-satunya efek yang terlihat bagi pelanggan adalah sedikit peningkatan latensi tanggapan. Basis data memastikan bahwa jumlah data pada server cluster paling banyak dan paling sedikit berbeda tidak lebih dari 5%.
Arsitektur
Secara logis, cluster FoundationDB adalah serangkaian proses dengan tipe yang sama pada mesin fisik yang berbeda. Proses tidak memiliki file konfigurasi sendiri, sehingga dapat dipertukarkan. Beberapa proses tetap memiliki peran khusus - Koordinator, dan setiap proses cluster pada saat startup mengetahui alamat mereka. Penting bahwa crash Koordinator adalah independen mungkin, sehingga mereka terbaik ditempatkan pada mesin fisik yang berbeda atau bahkan di pusat data yang berbeda.
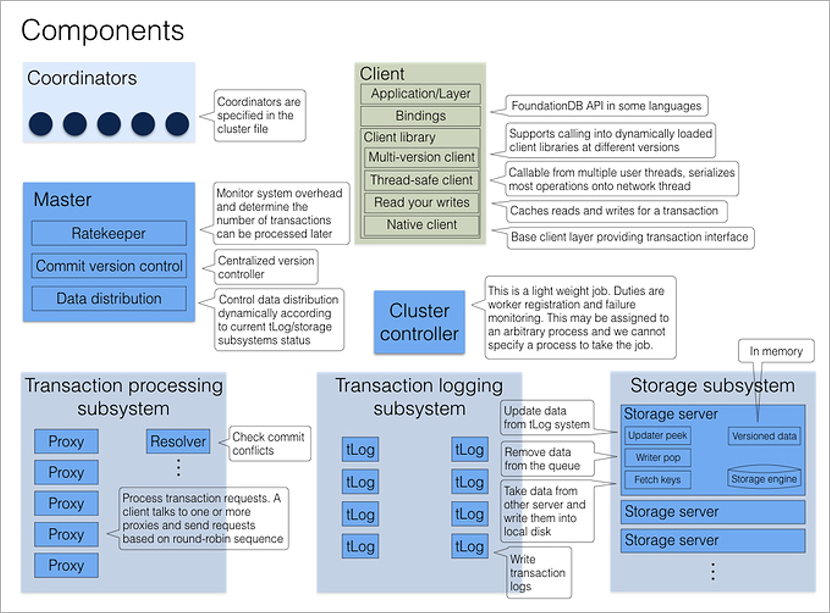
Koordinator sepakat di antara mereka sendiri melalui algoritma konsensus
Paxos . Mereka memilih proses Pengontrol Cluster, yang kemudian menetapkan peran ke seluruh proses cluster. Cluster Controller terus-menerus memberi tahu semua Koordinator bahwa dia masih hidup. Jika sebagian besar Koordinator berpikir dia sudah mati, mereka hanya memilih yang baru. Baik Pengontrol Cluster maupun Koordinator tidak terlibat dalam pemrosesan transaksi, tugas utama mereka adalah untuk menghilangkan situasi
otak yang terpecah .
Ketika klien ingin terhubung ke database, ia segera menghubungi semua Koordinator untuk alamat Pengontrol Cluster saat ini. Jika sebagian besar jawaban cocok, ia menerima dari Kontroler Cluster konfigurasi cluster penuh saat ini (jika tidak cocok, itu memanggil Koordinator lagi).
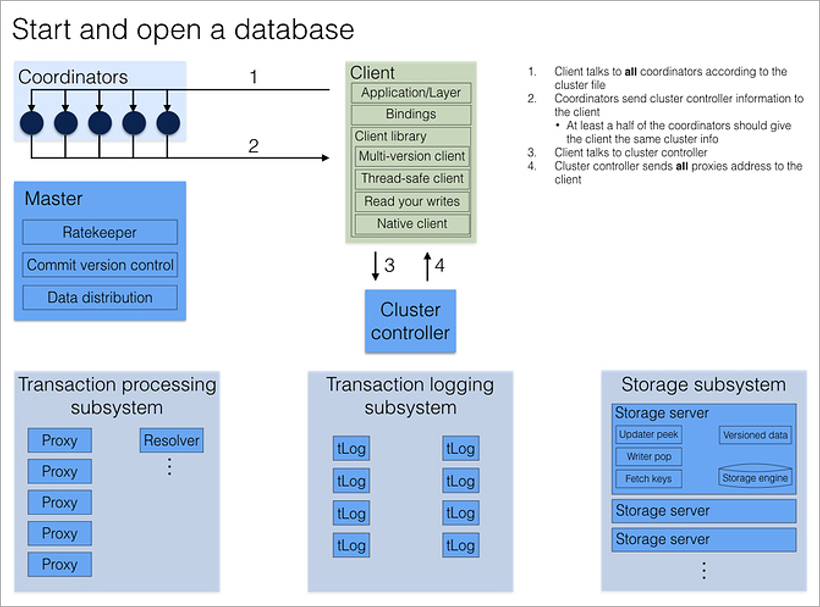
Cluster Controller tahu jumlah total proses yang tersedia dan mendistribusikan peran: 5 ini akan menjadi Proxy, 2 ini akan menjadi Resolver, yang ini akan menjadi Master. Dan jika ada di antara mereka yang mati, maka ia akan segera menemukan pengganti untuknya, menugaskan peran yang diperlukan untuk proses bebas yang sewenang-wenang. Ini semua terjadi di latar belakang, tidak terlihat oleh programmer aplikasi.
Proses Master bertanggung jawab untuk jumlah versi saat ini dari kumpulan data (meningkat dengan setiap catatan dalam database), serta untuk distribusi banyak kunci ke server penyimpanan dan pembatasan kecepatan (kinerja yang secara artifisial lebih rendah di bawah beban berat: jika kluster tahu bahwa klien akan membuat banyak permintaan kecil, dia akan menunggu, mengelompokkannya dan menjawab seluruh paket sekaligus).
Pencatatan dan Penyimpanan transaksi adalah dua subsistem penyimpanan independen. Yang pertama adalah penyimpanan sementara untuk dengan cepat menulis data ke disk dalam urutan penerimaan, yang kedua adalah penyimpanan permanen, di mana data pada disk diurutkan dalam urutan kunci yang menaik. Setiap transaksi berkomitmen, setidaknya tiga proses tLog harus menyimpan data sebelum cluster melaporkan keberhasilan kepada klien. Secara paralel, data di latar belakang bergerak dari server tLog ke server Penyimpanan (penyimpanan yang juga berlebihan).
Meminta pemrosesan
Semua klien meminta proses proksi. Membuka transaksi, klien mengakses Proxy apa pun, melakukan polling semua Proxy lainnya, dan mengembalikan nomor versi saat ini dari data cluster. Semua bacaan berikutnya terjadi pada nomor versi ini. Jika klien lain menuliskan data setelah saya membuka transaksi, saya tidak akan melihat perubahannya.
Merekam transaksi sedikit lebih rumit karena Anda perlu menyelesaikan konflik. Ini termasuk proses Penyelesai, yang menyimpan dalam memori semua kunci yang dimodifikasi untuk jangka waktu tertentu. Ketika klien menyelesaikan transaksi komit, Penyelesai memeriksa untuk melihat apakah data yang dibacanya sudah kedaluwarsa. (Yaitu, apakah transaksi yang dibuka setelah saya selesai dilakukan dan mengubah kunci yang saya baca.) Jika ini terjadi, transaksi dibatalkan dan perpustakaan klien itu sendiri (!) Melakukan upaya kedua untuk melakukan. Satu-satunya hal yang harus dipikirkan pengembang adalah bahwa transaksi tersebut idempoten, yaitu penggunaan berulang harus memberikan hasil yang identik. Salah satu cara untuk mencapai ini adalah dengan menyimpan beberapa nilai unik dalam transaksi, dan pada awal transaksi untuk memeriksa keberadaannya dalam database.
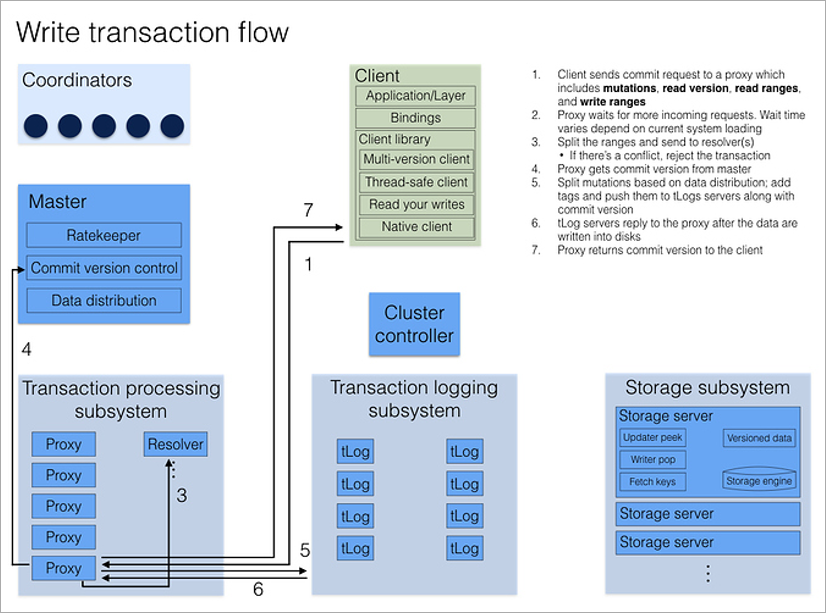
Seperti dalam sistem client-server, ada situasi ketika transaksi selesai dengan sukses, tetapi klien tidak menerima konfirmasi karena pemutusan. Pustaka klien memperlakukan mereka seperti kesalahan lain - itu hanya coba lagi. Ini berpotensi menyebabkan eksekusi ulang seluruh transaksi. Namun, jika transaksi idempoten, tidak ada masalah dengan ini - itu tidak akan mempengaruhi hasil akhir.
Scaling
Mungkin ada ribuan server dalam subsistem penyimpanan. Siapa di antara mereka yang harus dihubungi klien ketika mereka membutuhkan data pada kunci tertentu? Dari Kontroler Cluster, klien mengetahui konfigurasi penuh seluruh cluster, dan itu mencakup rentang kunci pada setiap server Storage. Oleh karena itu, ia hanya mengakses server Storage yang diinginkan secara langsung tanpa ada permintaan perantara.
Jika server penyimpanan yang diinginkan tidak tersedia, pustaka klien mengambil konfigurasi baru dari Pengontrol Cluster. Jika, sebagai akibat dari server crash, klaster memahami bahwa redundansi tidak mencukupi, ia segera mulai mengumpulkan node baru dari potongan Penyimpanan lainnya.
Misalkan Anda menyimpan satu gigabyte data dalam suatu transaksi. Bagaimana Anda bisa memberikan respons cepat? Tidak mungkin, dan karenanya, FoundationDB hanya membatasi ukuran satu transaksi hingga 10 megabita. Selain itu, ini adalah pembatasan pada semua data yang menjadi
perhatian transaksi - baca atau tulis. Setiap entri dalam database juga terbatas - kuncinya tidak dapat melebihi 10 kilobyte, nilainya 100 kilobyte. (Pada saat yang sama, untuk kinerja yang optimal, pengembang merekomendasikan kunci 32-byte dan 10 kilobyte.)
Setiap transaksi berpotensi menjadi sumber konflik, dan kemudian harus dibatalkan. Oleh karena itu, demi kecepatan, hingga perintah komit tiba, masuk akal untuk menjaga perubahan saat ini dalam RAM, dan bukan pada disk. Misalkan Anda sedang menulis data ke database dengan beban 1GB / detik. Kemudian, dalam kasus ekstrem, cluster Anda akan mengalokasikan 3GB RAM setiap detik (kami menulis transaksi pada 3 mesin). Bagaimana cara membatasi pertumbuhan memori yang digunakan seperti longsoran salju? Sangat mudah untuk membatasi waktu transaksi maksimum. Di FoundationDB, transaksi tidak dapat bertahan lebih dari 5 detik. Jika klien mencoba mengakses database 5 detik setelah transaksi dibuka, klaster akan mengabaikan semua perintahnya sampai membuka yang baru.
Indeks
Misalkan Anda menyimpan daftar orang, setiap orang memiliki pengenal unik, kami menggunakannya sebagai kunci, dan dalam nilai kami menulis semua atribut lainnya - nama, jenis kelamin, usia, dll.
| Kunci | Nilai |
| 12345 | (Ivanov Ivan Ivanovich, M, 35) |
Bagaimana cara mendapatkan daftar semua orang yang berusia 30 tahun tanpa pencarian lengkap? Biasanya, indeks dibuat dalam database untuk ini. Indeks adalah tampilan data lain yang dirancang untuk mencari atribut tambahan dengan cepat. Kami cukup menambahkan entri formulir:
Sekarang, untuk mendapatkan daftar yang Anda butuhkan, Anda hanya perlu mencari rentang tombol (30, *). Karena FoundationDB menyimpan data yang diurutkan berdasarkan kunci, permintaan seperti itu akan dijalankan dengan sangat cepat. Tentu saja, indeks membutuhkan ruang disk tambahan, tetapi sangat sedikit. Harap dicatat bahwa tidak semua atribut digandakan, tetapi hanya usia dan pengidentifikasi.
Adalah penting bahwa operasi penambahan catatan itu sendiri dan indeks untuk itu dilakukan dalam satu transaksi.
Keandalan
FoundationDB ditulis dalam C ++. Para penulis mulai mengerjakannya pada 2009, versi pertama dirilis pada 2013, dan pada Maret 2015 mereka dibeli oleh Apple. Tiga tahun kemudian, Apple secara tak terduga membuka kode sumber.
Rumor mengatakan bahwa Apple menggunakannya, antara lain, untuk menyimpan data layanan iCloud.
Pengembang berpengalaman biasanya tidak langsung memercayai solusi baru. Mungkin perlu bertahun-tahun sebelum teknologi dapat diandalkan untuk memantapkan dirinya dan akan mulai digunakan secara besar-besaran dalam produk. Untuk mengurangi waktu ini, penulis membuat ekstensi yang menarik dari bahasa C ++:
Flow . Ini memungkinkan Anda untuk meniru dengan anggun bekerja dengan komponen eksternal yang tidak dapat diandalkan dengan kemungkinan pengulangan yang lengkap dari pelaksanaan program. Setiap panggilan ke jaringan atau disk dibungkus dengan beberapa pembungkus (Aktor), dan masing-masing Aktor memiliki beberapa implementasi. Implementasi standar menulis data ke disk atau ke jaringan, sebagaimana dimaksud. Dan yang lain menulis ke disk 999 kali dari 1000, dan kehilangan 1 kali dari 1000. Implementasi jaringan alternatif dapat, misalnya, menukar byte dalam paket jaringan. Bahkan ada Aktor yang meniru pekerjaan administrator sistem yang ceroboh. Ini dapat menghapus folder data atau menukar dua folder. Pengembang
menggerakkan ribuan simulasi , mengganti Aktor yang berbeda, dan menggunakan Flow mencapai reproduksibilitas 100%: jika beberapa tes gagal, mereka dapat memulai kembali simulasi dan mendapatkan crash di tempat yang sama. Secara khusus, untuk menghilangkan ketidakpastian yang diperkenalkan oleh thread switching scheduler OS, setiap proses FoundationDB adalah single-threaded.
Ketika seorang
peneliti yang menemukan
skenario kehilangan data di hampir semua solusi NoSQL yang populer diminta untuk menguji FoundationDB, ia menolak, mencatat bahwa ia tidak mengerti maksudnya, karena penulis
melakukan pekerjaan raksasa dan
mengujinya jauh lebih dalam dan lebih teliti daripada miliknya.
Sudah menjadi kebiasaan untuk berpikir bahwa kegagalan cluster adalah acak, tetapi para devop yang berpengalaman tahu bahwa ini jauh dari kasus. Jika Anda memiliki 10 ribu disk dari pabrikan yang sama dan jumlah yang lain, maka tingkat kegagalan akan berbeda. Di FoundationDB, konfigurasi yang dikenal dengan mesin mungkin dilakukan di mana Anda bisa memberi tahu cluster mesin mana yang ada di pusat data yang sama dan proses mana yang ada di mesin yang sama. Basis data akan mempertimbangkan hal ini saat mendistribusikan beban antar mesin. Dan mesin dalam sebuah cluster biasanya memiliki karakteristik yang berbeda. FoundationDB juga memperhitungkan hal ini, melihat panjang antrian permintaan dan mendistribusikan kembali muatan secara seimbang: mesin yang lebih lemah menerima lebih sedikit permintaan.
Jadi FoundationDB menyediakan transaksi ACID dan tingkat isolasi tertinggi, Serializable, pada sekelompok ribuan mesin. Bersama dengan fleksibilitas luar biasa dan kinerja tinggi, kedengarannya seperti sulap. Tetapi Anda harus membayar semuanya, jadi ada beberapa keterbatasan teknologi.
Keterbatasan
Selain batas yang telah disebutkan pada ukuran dan panjang transaksi, penting untuk mencatat fitur-fitur berikut:
- Bahasa query bukan SQL, artinya, pengembang dengan pengalaman SQL harus mempelajari kembali.
- Pustaka klien hanya mendukung 5 bahasa tingkat tinggi (Phyton, Ruby, Java, Golang, dan C). Belum ada klien resmi untuk C #. Karena tidak ada REST API, satu-satunya cara untuk mendukung bahasa lain adalah dengan menulis pembungkus di atasnya di atas pustaka C standar.
- Tidak ada mekanisme berbagi, semua logika ini harus disediakan oleh aplikasi Anda.
- Format penyimpanan data tidak didokumentasikan (walaupun biasanya tidak didokumentasikan dalam database komersial juga). Ini adalah risiko, karena jika tiba-tiba cluster tidak berkumpul, maka tidak segera jelas apa yang harus dilakukan dan harus menyelidiki file sumber.
- Model pemrograman yang benar-benar tidak sinkron dapat terlihat rumit bagi pengembang pemula.
- Anda harus terus-menerus memikirkan idempotensi transaksi.
- Jika Anda harus membagi transaksi panjang menjadi yang kecil, maka Anda perlu menjaga integritas pada tingkat global sendiri.
Diterjemahkan dari bahasa Inggris, "Foundation" berarti "Foundation" dan penulis DBMS ini melihat perannya dengan cara ini: memberikan tingkat keandalan yang tinggi pada tingkat catatan sederhana, dan basis data lainnya dapat diimplementasikan sebagai tambahan atas fungsionalitas dasar. Jadi, di atas FoundationDB, Anda berpotensi membuat berbagai lapisan lain - dokumen, grafik, dll. Pertanyaannya tetap bagaimana lapisan ini akan skala tanpa kehilangan kinerja. Sebagai contoh, penulis CockroachDB telah mengambil jalur ini - dengan membangun lapisan SQL di atas RocksDB (penyimpanan nilai kunci lokal) dan mereka telah mendapatkan masalah kinerja yang melekat dalam gabungan relasional.
Sampai saat ini, Apple telah mengembangkan dan menerbitkan 2 lapisan di atas FoundationDB:
Lapisan Dokumen (mendukung API MongoDB) dan
Lapisan Rekaman (menyimpan catatan sebagai kumpulan bidang dalam format
Protokol Buffer , mendukung indeks, hanya tersedia di Jawa). Sangat menyenangkan dan mengejutkan bahwa perusahaan yang secara historis ditutup dari Apple hari ini mengikuti jejak Google dan Microsoft dan menerbitkan kode sumber teknologi yang digunakan di dalam.
Prospek
Ada konflik eksistensial dalam pengembangan perangkat lunak: bisnis terus-menerus menginginkan perubahan, peningkatan dari produk. Tetapi pada saat yang sama ia menginginkan perangkat lunak yang andal. Dan kedua persyaratan ini saling bertentangan, karena ketika perangkat lunak berubah, bug muncul dan bisnis menderita karenanya. Oleh karena itu, jika dalam produk Anda, Anda dapat mengandalkan beberapa teknologi yang andal, terbukti, dan menulis lebih sedikit kode sendiri, ini selalu layak dilakukan. Dalam pengertian ini, terlepas dari batasan tertentu, itu keren untuk tidak dapat memahat kruk ke database NoSQL yang berbeda, tetapi menggunakan solusi yang telah terbukti produksi dengan properti ACID.
Setahun yang lalu, kami
optimis tentang teknologi lain - CockroachDB, tetapi itu tidak memenuhi harapan kami untuk kinerja. Sejak itu, kami kehilangan selera untuk ide lapisan SQL atas toko nilai kunci terdistribusi, dan karena itu tidak melihat dengan hati-hati, misalnya,
TiDB . Kami berencana untuk mencoba FoundationDB dengan hati-hati sebagai basis data sekunder untuk kumpulan data terbesar di proyek kami. Jika Anda sudah memiliki pengalaman dalam penggunaan aktual FoundationDB atau TiDB dalam produksi, kami akan senang mendengar pendapat Anda dalam komentar.