
Selama setahun terakhir, ada begitu banyak publikasi tentang layanan mikro sehingga akan membuang waktu untuk mengatakan apa itu dan mengapa, sehingga sisa diskusi akan fokus pada pertanyaan tentang bagaimana menerapkan arsitektur ini dan mengapa itu dihadapi persis dan masalah apa yang dihadapi.
Kami memiliki masalah besar di bank kecil: 3 monolit python dihubungkan oleh sejumlah besar interaksi RPC sinkron dengan volume besar warisan. Untuk setidaknya sebagian menyelesaikan semua masalah yang muncul dalam kasus ini, diputuskan untuk beralih ke arsitektur layanan-mikro. Tetapi sebelum memutuskan langkah seperti itu, Anda perlu menjawab 3 pertanyaan utama:
- Bagaimana memecah monolit menjadi layanan-layanan mikro dan kriteria apa yang harus diikuti.
- Bagaimana layanan microser berinteraksi?
- Bagaimana cara memonitor?
Sebenarnya jawaban singkat untuk pertanyaan ini akan dikhususkan untuk artikel ini.
Bagaimana memecah monolit menjadi layanan-layanan mikro dan kriteria apa yang harus diikuti.
Pertanyaan yang tampaknya sederhana ini akhirnya menentukan seluruh arsitektur masa depan.
Kami adalah bank, sehingga seluruh sistem berputar di sekitar operasi dengan keuangan dan berbagai hal tambahan. Tentu saja mungkin untuk mentransfer transaksi ACID keuangan ke sistem terdistribusi dengan sagas , tetapi dalam kasus umum itu sangat sulit. Jadi kami mengembangkan aturan berikut:
- Mematuhi S dari SOLID untuk layanan microser
- Transaksi harus sepenuhnya dilakukan dalam microservice - tidak ada transaksi terdistribusi pada kerusakan database
- Agar berfungsi, layanan mikro dalam membutuhkan informasi dari basis datanya sendiri atau dari permintaan
- Cobalah untuk memastikan kebersihan (dalam arti bahasa fungsional) untuk layanan microser
Secara alami, pada saat yang sama tidak mungkin untuk sepenuhnya memuaskan mereka, tetapi bahkan implementasi parsial sangat menyederhanakan pengembangan.
Bagaimana layanan microser berinteraksi?
Ada banyak opsi, tetapi pada akhirnya, semuanya dapat diabstraksi dengan sederhana "pesan pertukaran layanan microser," tetapi jika Anda menerapkan protokol sinkron (misalnya, RPC melalui REST), maka sebagian besar kerugian dari monolith akan tetap ada, tetapi keuntungan dari layanan microser hampir tidak akan muncul. Jadi solusi yang jelas adalah mengambil broker pesan dan memulai. Memilih antara RabbitMQ dan Kafka menentukan yang terakhir, dan inilah alasannya:
- Kafka lebih sederhana dan menyediakan model pesan tunggal - Terbitkan - berlangganan
- Relatif mudah untuk mendapatkan data dari Kafka untuk kedua kalinya. Ini sangat nyaman untuk debugging atau memperbaiki bug selama pemrosesan yang salah, serta untuk pemantauan dan pencatatan.
- Cara yang jelas dan sederhana untuk meningkatkan skala layanan: menambahkan partisi ke topik, meluncurkan lebih banyak pelanggan - sisanya akan dilakukan oleh kafka.
Selain itu saya ingin menarik perhatian pada perbandingan yang sangat berkualitas tinggi dan terperinci .
Antrian di kafka + asynchrony memungkinkan kita untuk:
- Matikan semua microservice untuk pembaruan secara singkat tanpa konsekuensi nyata untuk sisanya
- Matikan semua layanan untuk waktu yang lama dan tidak repot dengan pemulihan data. Sebagai contoh, microservice fiskalisasi baru-baru ini jatuh. Itu diperbaiki setelah 2 jam, dia mengambil akun mentah dari Kafka dan memproses semuanya. Itu tidak perlu, seperti sebelumnya, untuk mengembalikan apa yang seharusnya terjadi di sana dan secara manual melakukan log HTTP dan tabel terpisah dalam database.
- Jalankan versi uji layanan pada data saat ini dari penjualan dan bandingkan hasil pemrosesan mereka dengan versi layanan pada penjualan.
Sebagai sistem serialisasi data, kami memilih AVRO, mengapa - dijelaskan dalam artikel terpisah .
Tetapi terlepas dari metode serialisasi yang dipilih, penting untuk memahami bagaimana protokol akan diperbarui. Meskipun AVRO mendukung Resolusi Skema, kami tidak menggunakan ini dan memutuskan secara administratif:
- Data dalam topik ditulis dan dibaca hanya melalui AVRO, nama topik sesuai dengan nama skema (dan Confluent memiliki pendekatan yang berbeda - mereka menulis skema ID AVRO dari registri dalam byte pesan yang tinggi, sehingga mereka dapat memiliki berbagai jenis pesan dalam satu topik
- Jika Anda perlu menambah atau mengubah data, skema baru dibuat dengan topik baru di kafka, setelah itu semua produsen beralih ke topik baru, dan diikuti oleh pelanggan
Kami menyimpan sendiri sirkuit AVRO dalam submit git dan terhubung ke semua proyek kafka. Mereka memutuskan untuk tidak menerapkan daftar skema yang terpusat.
PS: Kolega membuat opsi opensource tetapi hanya dengan skema JSON bukan AVRO .
Beberapa kehalusan
Setiap pelanggan menerima semua pesan dari topik
Ini adalah kekhususan model interaksi Terbitkan - berlangganan - saat berlangganan suatu topik, pelanggan akan menerima semuanya. Akibatnya, jika layanan hanya membutuhkan beberapa pesan, ia harus menyaringnya. Jika ini menjadi masalah, dimungkinkan untuk membuat router layanan terpisah yang akan menjabarkan pesan dalam beberapa topik yang berbeda, sehingga mengimplementasikan bagian dari fungsi RabbitMQ yang tidak ada dalam kafka. Sekarang kami memiliki satu pelanggan pada python dalam satu proses thread sekitar 7-5 ribu pesan per detik, tetapi jika Anda menjalankan dari melalui PyPy, maka kecepatannya tumbuh menjadi 11-15 ribu / detik.
Batasi masa pakai pointer dalam suatu topik
Dalam pengaturan kafka ada parameter yang membatasi waktu kafka "mengingat" di mana pembaca berhenti - defaultnya adalah 2 hari. Akan menyenangkan untuk menaikkannya menjadi seminggu, sehingga jika masalah muncul pada hari libur dan 2 hari tidak terselesaikan, maka ini tidak akan menyebabkan hilangnya posisi dalam topik.
Baca Batas Waktu Konfirmasi
Jika pembaca Kafka tidak mengkonfirmasi pembacaan dalam 30 detik (parameter yang dapat dikonfigurasi), maka broker percaya bahwa ada kesalahan dan terjadi kesalahan ketika mencoba mengkonfirmasi pembacaan. Untuk menghindari hal ini, saat memproses pesan untuk waktu yang lama, kami mengirim konfirmasi baca tanpa memindahkan pointer.
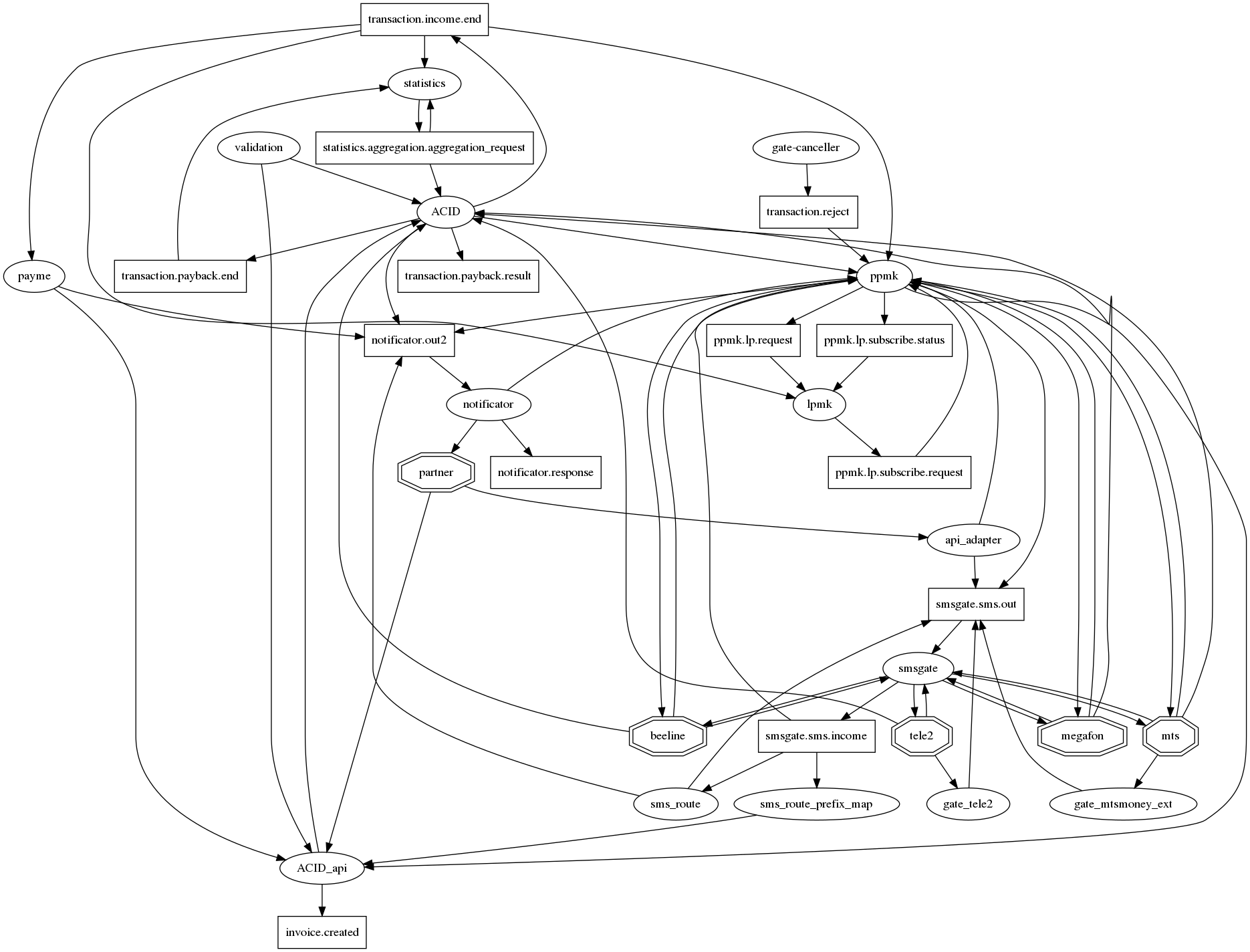
Grafik koneksi sulit dipahami.
Jika Anda benar-benar menggambar semua hubungan dalam graphviz, maka ada landak dari kiamat tradisional untuk layanan microser dengan puluhan koneksi dalam satu node. Setidaknya agar entah bagaimana membuatnya (grafik koneksi) dapat dibaca, kami menyetujui notasi berikut: microservices - oval, topik kafka - persegi panjang. Jadi, pada satu grafik, dimungkinkan untuk menampilkan fakta interaksi dan tipenya. Namun, sayangnya, ini tidak menjadi jauh lebih baik. Jadi pertanyaan ini masih terbuka.
Bagaimana cara memonitor?
Bahkan sebagai bagian dari monolith, kami memiliki log dalam file dan Sentry. Tetapi ketika kami beralih ke interaksi melalui Kafka dan disebarkan ke k8, log dipindahkan ke ElasticSearch dan, oleh karena itu, kami pertama-tama memantau membaca log pelanggan di Elastic. Tanpa log - tidak ada pekerjaan.
Setelah itu, mereka mulai menggunakan Prometheus dan pengekspor kafka sedikit mengubah dasbornya : https://github.com/kkirsanov/articles/blob/master/2019-habr-kafka/dashboard.json
Hasilnya, kami mendapatkan gambar-gambar ini:
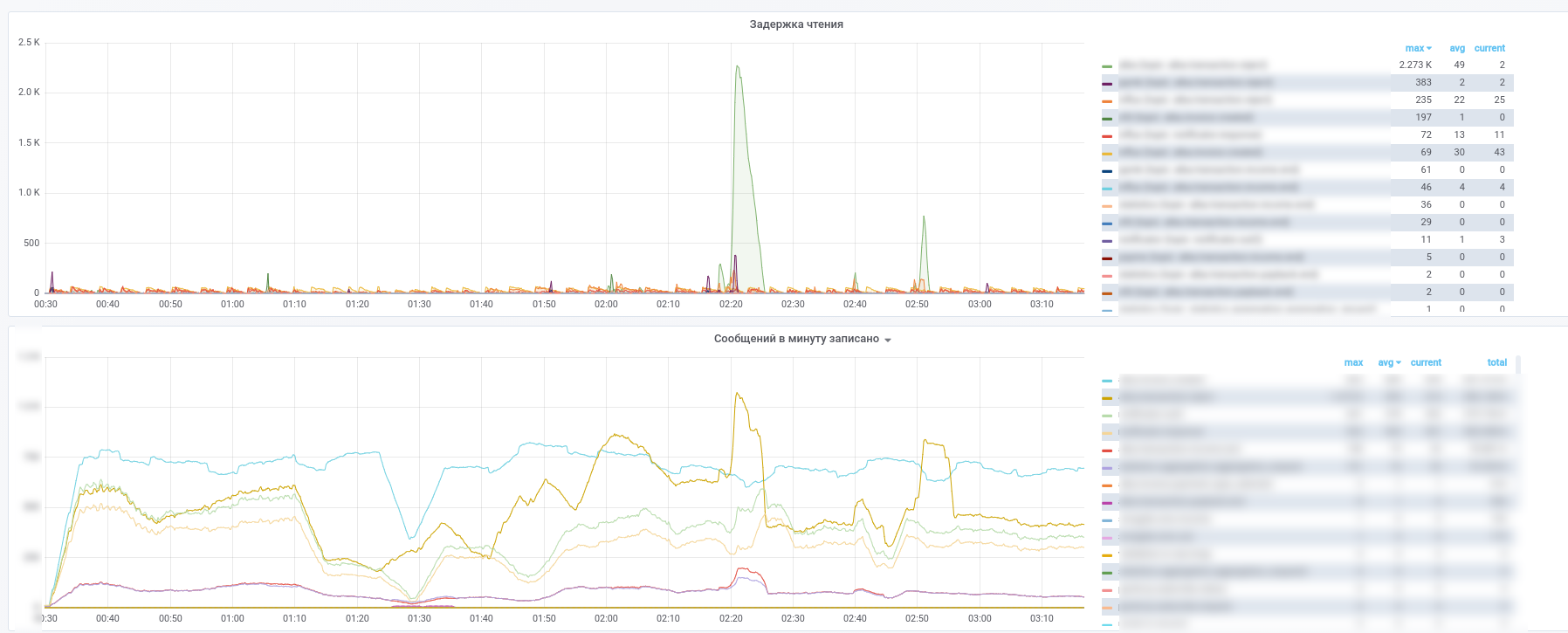
Anda dapat melihat layanan mana yang berhenti memproses pesan mana.
Selain itu, semua pesan dari topik utama (transaksi pembayaran, pemberitahuan dari mitra, dll.) Disalin ke InfluxDB, yang diatur dalam grafana yang sama. Jadi, kita tidak hanya bisa merekam fakta lewat pesan, tetapi juga membuat berbagai sampel sesuai konten. Jadi, jawaban untuk pertanyaan seperti "berapa waktu tunda rata-rata untuk respons dari layanan" atau "Apakah arus transaksi sangat berbeda hari ini dari kemarin di toko ini" selalu ada.
Juga, untuk menyederhanakan analisis insiden, kami menggunakan pendekatan berikut: setiap layanan, saat memproses pesan, menambahkannya dengan informasi meta yang berisi UUID yang dikeluarkan ketika sistem menampilkan serangkaian catatan jenis:
- nama layanan
- UUID dari proses pemrosesan dalam microservice ini
- proses mulai cap waktu
- waktu proses
- set tag
Akibatnya, saat pesan melewati grafik komputasi, pesan diperkaya dengan informasi tentang jalur yang ditempuh pada grafik. Ternyata analog zipkin / opentracing untuk MQ, yang memungkinkan menerima pesan untuk dengan mudah mengembalikan jalurnya pada grafik. Ini mendapatkan nilai khusus dalam kasus-kasus ketika siklus muncul pada grafik. Ingat contoh layanan kecil, bagian pembayarannya hanya 0,0001%. Dengan menganalisis meta-informasi dalam pesan, ia dapat menentukan apakah mereka adalah pemrakarsa pembayaran, tanpa menghubungi database untuk verifikasi.