Selama 7 tahun terakhir, bersama dengan tim, saya telah mendukung dan mengembangkan inti dari produk Miro (ex-RealtimeBoard): interaksi client-server dan cluster, bekerja dengan database.
Kami memiliki Java dengan berbagai pustaka. Semuanya diluncurkan di luar wadah, melalui plugin Maven. Ini didasarkan pada platform mitra kami, yang memungkinkan kami untuk bekerja dengan basis data dan arus, mengelola interaksi klien-server, dll. DB - Redis dan PostgreSQL (kolega saya
menulis tentang bagaimana kami berpindah dari satu database ke yang lain ).
Dalam hal logika bisnis, aplikasi berisi:
- bekerja dengan papan khusus dan isinya;
- fungsionalitas untuk pendaftaran pengguna, pembuatan dan pengelolaan papan;
- generator sumber daya kustom. Misalnya, ini mengoptimalkan gambar besar yang diunggah ke aplikasi sehingga mereka tidak memperlambat klien kami;
- banyak integrasi dengan layanan pihak ketiga.
Pada 2011, ketika kami baru memulai, seluruh Miro berada di server yang sama. Semuanya ada di sana: Nginx di mana php untuk situs berubah, aplikasi Java dan database.
Produk dikembangkan, jumlah pengguna dan konten yang mereka tambahkan ke papan bertambah, sehingga beban di server juga bertambah. Karena banyaknya aplikasi di server kami, pada saat itu kami tidak dapat memahami apa yang sebenarnya memberi beban, dan karenanya, tidak dapat mengoptimalkannya. Untuk memperbaikinya, kami membagi semuanya menjadi server yang berbeda, dan kami mendapat server web, server dengan aplikasi dan server database kami.
Sayangnya, setelah beberapa waktu, masalah muncul lagi, karena beban pada aplikasi terus bertambah. Kemudian kami memikirkan bagaimana skala infrastruktur.

Selanjutnya, saya akan berbicara tentang kesulitan yang kami temui dalam mengembangkan cluster dan meningkatkan skala aplikasi dan infrastruktur Java.
Skala infrastruktur secara horizontal
Kami mulai dengan mengumpulkan metrik: penggunaan memori dan CPU, waktu yang diperlukan untuk mengeksekusi permintaan pengguna, penggunaan sumber daya sistem, dan bekerja dengan database. Dari metrik, jelas bahwa generasi sumber daya pengguna adalah proses yang tidak dapat diprediksi. Kami dapat memuat prosesor 100% dan menunggu puluhan detik hingga semuanya selesai. Permintaan pengguna untuk papan juga terkadang memberi beban yang tidak terduga. Misalnya, ketika pengguna memilih seribu widget dan mulai memindahkannya secara spontan.
Kami mulai berpikir tentang bagaimana skala bagian-bagian sistem ini dan sampai pada solusi yang jelas.
Skala bekerja dengan papan dan konten . Pengguna membuka papan seperti ini: pengguna membuka klien → menunjukkan papan mana yang ia ingin buka → terhubung ke server → aliran dibuat di server → semua pengguna papan ini terhubung ke satu aliran → setiap perubahan atau pembuatan widget terjadi dalam aliran ini. Ternyata semua pekerjaan dengan dewan dibatasi secara ketat oleh arus, yang berarti bahwa kita dapat mendistribusikan arus ini di antara server.
Skala generasi sumber daya pengguna . Kita dapat mengeluarkan server untuk menghasilkan sumber daya secara terpisah, dan ia akan menerima pesan untuk dibuat, dan kemudian menjawab bahwa semuanya dihasilkan.
Segalanya tampak sederhana. Tetapi begitu kami mulai mempelajari topik ini lebih dalam, ternyata kami perlu menyelesaikan beberapa masalah tidak langsung. Misalnya, jika pengguna kedaluwarsa berlangganan, maka kami harus memberi tahu mereka tentang hal ini, apa pun papannya. Atau, jika pengguna telah memperbarui versi sumber daya, Anda perlu memastikan bahwa cache dibilas dengan benar di semua server dan kami memberikan versi yang tepat.
Kami telah mengidentifikasi persyaratan sistem. Langkah selanjutnya adalah memahami bagaimana mempraktikkannya. Faktanya, kami membutuhkan sistem yang memungkinkan server dalam cluster untuk berkomunikasi satu sama lain dan berdasarkan itu kami akan mewujudkan semua ide kami.
Cluster pertama di luar kotak
Kami tidak memilih versi sistem yang pertama, karena sudah diterapkan sebagian di platform mitra yang kami gunakan. Di dalamnya, semua server terhubung satu sama lain melalui TCP, dan menggunakan koneksi ini kita bisa mengirim pesan RPC ke satu atau semua server sekaligus.
Sebagai contoh, kami memiliki tiga server, mereka terhubung satu sama lain melalui TCP, dan di Redis kami memiliki daftar server ini. Kami memulai server baru di gugus → menambahkan dirinya ke daftar di Redis → membaca daftar untuk mencari tahu tentang semua server di gugus → terhubung ke semua.
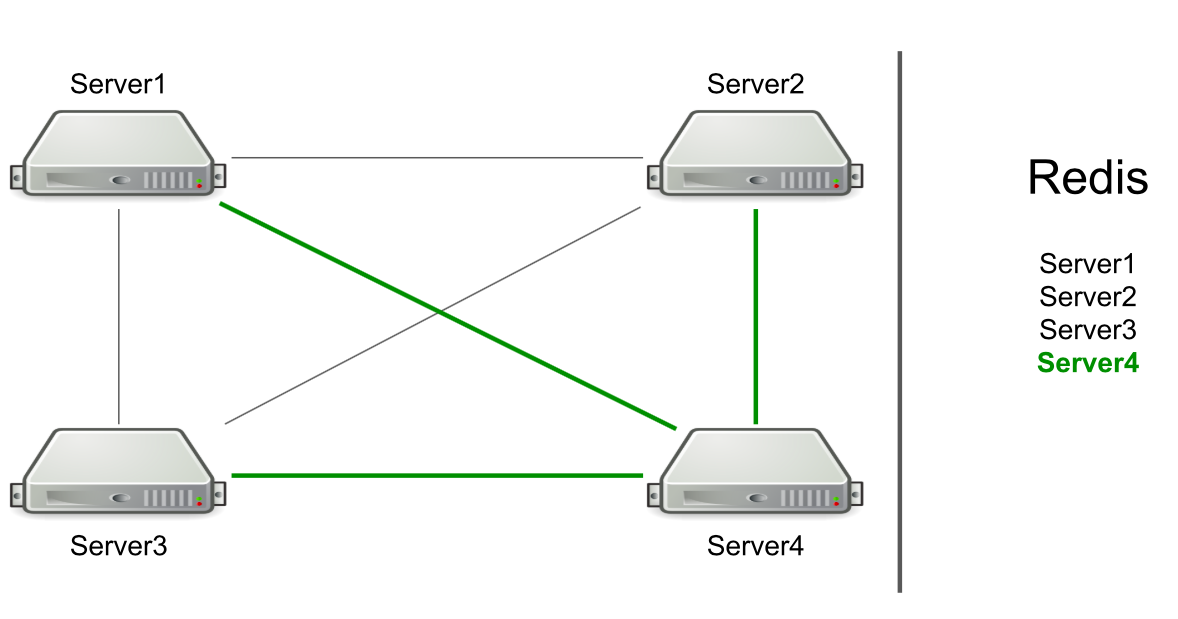
Berdasarkan RPC, dukungan untuk membilas cache dan mengarahkan pengguna ke server yang diinginkan telah dilaksanakan. Kami harus melakukan generasi sumber daya pengguna dan memberi tahu pengguna bahwa sesuatu telah terjadi (misalnya, akun telah kedaluwarsa). Untuk menghasilkan sumber daya, kami memilih server yang sewenang-wenang dan mengirimnya permintaan untuk dibuat, dan untuk pemberitahuan tentang berakhirnya langganan, kami mengirim perintah ke semua server dengan harapan pesan akan mencapai tujuan.
Server itu sendiri menentukan kepada siapa untuk mengirim pesan.
Kedengarannya seperti fitur, bukan masalah. Tetapi server hanya berfokus pada koneksi ke server lain. Jika ada koneksi, maka ada kandidat untuk mengirim pesan.
Masalahnya adalah bahwa server nomor 1 tidak tahu bahwa server nomor 4 berada di bawah beban tinggi sekarang dan tidak dapat menjawabnya dengan cukup cepat. Akibatnya, permintaan server # 1 diproses lebih lambat dari yang mereka bisa.
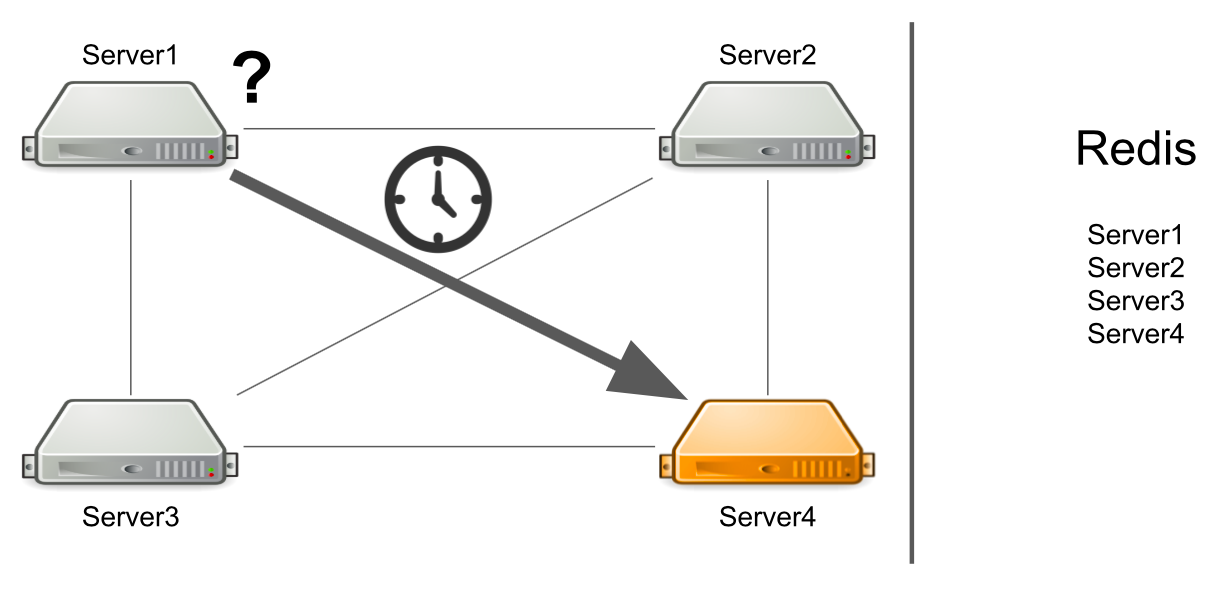
Server tidak tahu bahwa server kedua dibekukan
Tetapi bagaimana jika server tidak hanya dimuat banyak, tetapi umumnya membeku? Selain itu, hang sehingga tidak lagi hidup. Sebagai contoh, saya telah kehabisan semua memori yang tersedia.
Dalam hal ini, server # 1 tidak tahu apa masalahnya, sehingga ia terus menunggu jawaban. Server yang tersisa di gugus juga tidak tahu tentang situasi dengan server No. 4, sehingga mereka akan mengirim banyak pesan ke server No. 4 dan menunggu jawaban. Jadi akan sampai server nomor 4 mati.
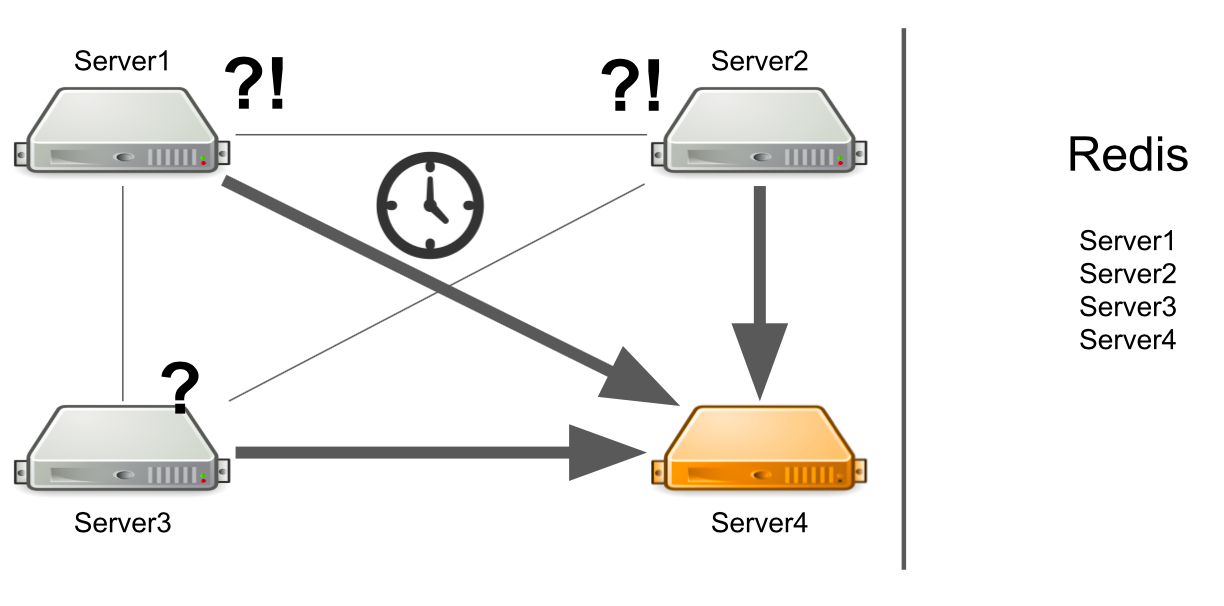
Apa yang harus dilakukan Kami dapat secara independen menambahkan pemeriksaan status server ke sistem. Atau kita dapat mengarahkan pesan dari server "sakit" ke server "sehat". Semua ini akan memakan waktu terlalu lama bagi pengembang. Pada 2012, kami memiliki sedikit pengalaman dalam bidang ini, jadi kami mulai mencari solusi yang siap pakai untuk semua masalah kami sekaligus.
Pialang pesan. Activemq
Kami memutuskan untuk pergi ke broker pesan untuk mengkonfigurasi komunikasi antara server dengan benar. Mereka memilih ActiveMQ karena kemampuan untuk mengkonfigurasi menerima pesan pada konsumen pada waktu tertentu. Benar, kami tidak pernah mengambil kesempatan ini, jadi kami bisa memilih RabbitMQ, misalnya.
Akibatnya, kami mentransfer seluruh sistem kluster kami ke ActiveMQ. Apa yang diberikannya:
- Server tidak lagi menentukan sendiri kepada siapa pesan dikirim, karena semua pesan melewati antrian.
- Toleransi kesalahan dikonfigurasi. Untuk membaca antrian, Anda dapat menjalankan tidak hanya satu, tetapi beberapa server. Bahkan jika salah satunya jatuh, sistem akan terus bekerja.
- Server muncul peran, yang memungkinkan untuk membagi server berdasarkan jenis beban. Sebagai contoh, generator sumber daya hanya dapat terhubung ke antrian untuk membaca pesan untuk menghasilkan sumber daya, dan server dengan papan dapat terhubung ke antrian untuk membuka papan.
- Apakah komunikasi RPC, mis. setiap server memiliki antrian pribadi sendiri, di mana server lain mengirim acara ke sana.
- Anda dapat mengirim pesan ke semua server melalui Topik, yang kami gunakan untuk mengatur ulang langganan.
Skema ini terlihat sederhana: semua server terhubung ke broker, dan mengelola komunikasi di antara mereka. Semuanya berfungsi, pesan dikirim dan diterima, sumber daya dibuat. Tetapi ada masalah baru.
Apa yang harus dilakukan ketika semua server yang diperlukan berbohong?
Katakanlah server # 3 ingin mengirim pesan untuk menghasilkan sumber daya dalam antrian. Dia berharap pesannya diproses. Tetapi dia tidak tahu bahwa karena suatu alasan tidak ada satu pun penerima pesan. Misalnya, penerima macet karena kesalahan.
Untuk semua waktu tunggu, server mengirim banyak pesan dengan permintaan, itulah sebabnya antrian pesan muncul. Oleh karena itu, ketika server yang berfungsi muncul, mereka dipaksa untuk terlebih dahulu memproses akumulasi antrian, yang membutuhkan waktu. Di sisi pengguna, ini mengarah pada fakta bahwa gambar yang mereka unggah tidak segera muncul. Dia tidak siap untuk menunggu, jadi dia meninggalkan papan tulis.
Akibatnya, kami menghabiskan kapasitas server untuk menghasilkan sumber daya, dan tidak ada yang membutuhkan hasilnya.
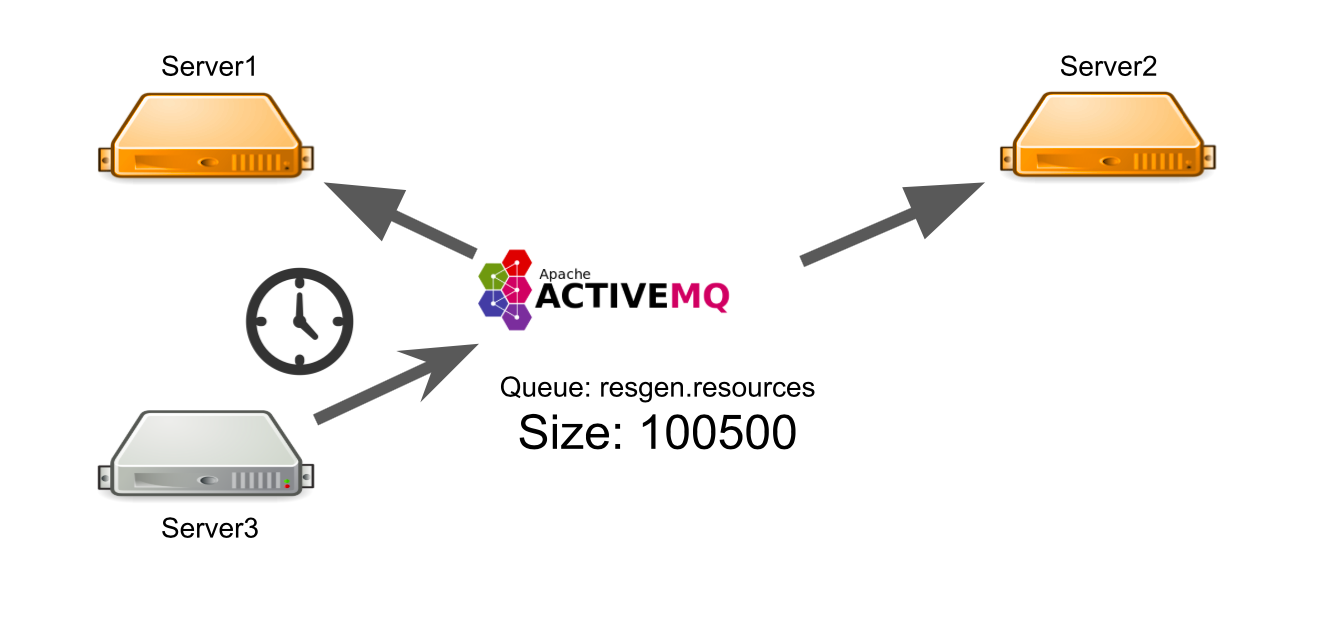
Bagaimana saya bisa menyelesaikan masalah? Kami dapat mengatur pemantauan, yang akan memberi tahu Anda tentang apa yang terjadi. Tetapi dari saat pemantauan melaporkan sesuatu, sampai saat kita memahami bahwa server kita buruk, waktu akan berlalu. Ini tidak cocok untuk kita.
Pilihan lain adalah menjalankan Service Discovery, atau registri layanan yang akan mengetahui server mana yang menjalankan peran. Dalam hal ini, kami akan segera menerima pesan kesalahan jika tidak ada server gratis.
Beberapa layanan tidak dapat diskalakan secara horizontal
Ini adalah masalah kode awal kami, bukan ActiveMQ. Izinkan saya menunjukkan kepada Anda sebuah contoh:
Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER);
Kami memiliki layanan untuk bekerja dengan hak pengguna di papan tulis: pengguna dapat menjadi pemilik papan atau editornya. Hanya ada satu pemilik di dewan. Misalkan kita memiliki skenario di mana kita ingin mentransfer kepemilikan papan dari satu pengguna ke pengguna lain. Pada baris pertama kita mendapatkan pemilik papan saat ini, pada baris kedua - kita mengambil pengguna yang merupakan editor, dan sekarang menjadi pemilik. Selanjutnya, pemilik saat ini kami menempatkan peran EDITOR, dan mantan editor - peran PEMILIK.
Mari kita lihat bagaimana ini akan bekerja di lingkungan multi-threaded. Ketika utas pertama menetapkan peran EDITOR, dan utas kedua mencoba untuk mengambil PEMILIK saat ini, mungkin saja PEMILIK itu tidak ada, tetapi ada dua EDITOR.
Alasannya adalah kurangnya sinkronisasi. Kami dapat memecahkan masalah dengan menambahkan blok sinkronisasi di papan tulis.
synchronized (board) { Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER); }
Solusi ini tidak akan berfungsi di cluster. Basis data SQL dapat membantu kami dalam hal ini dengan bantuan transaksi. Tapi kami punya Redis.
Solusi lain adalah menambahkan kunci terdistribusi ke cluster sehingga sinkronisasi ada di dalam seluruh cluster, dan bukan hanya satu server.
Satu titik kegagalan saat memasuki papan tulis
Model interaksi antara klien dan server stateful. Jadi kita harus menyimpan status board di server. Oleh karena itu, kami membuat peran terpisah untuk server - BoardServer, yang menangani permintaan pengguna terkait dengan papan.
Bayangkan kita memiliki tiga BoardServer, salah satunya adalah yang utama. Pengguna mengiriminya permintaan "Buka saya papan dengan id = 123" → server melihat dalam database-nya apakah papan terbuka dan di server mana itu. Dalam contoh ini, papan terbuka.
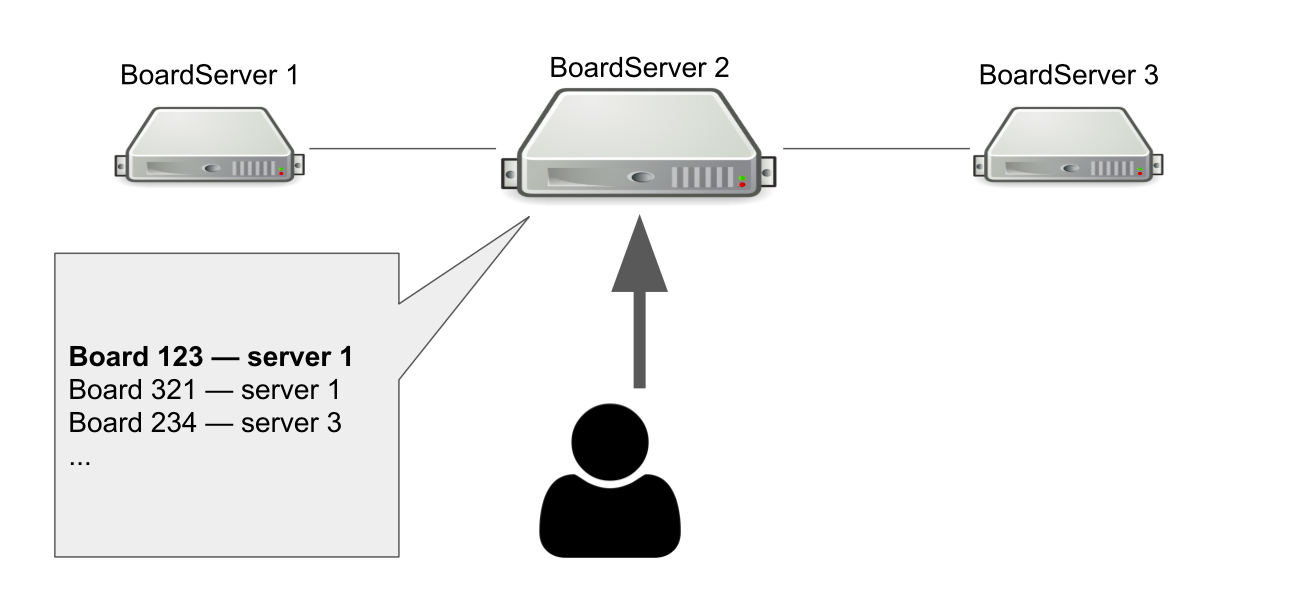
Server utama menjawab bahwa Anda harus terhubung ke server No. 1 → pengguna terhubung. Jelas, jika server utama mati, maka pengguna tidak akan lagi dapat mengakses papan baru.
Lalu mengapa kita membutuhkan server yang tahu di mana papan terbuka? Sehingga kita memiliki satu titik keputusan. Jika terjadi sesuatu pada server, kita perlu memahami apakah papan itu sebenarnya tersedia untuk menghapus papan dari registri atau membuka kembali di tempat lain. Mungkin untuk mengatur ini dengan bantuan kuorum, ketika beberapa server memecahkan masalah yang sama, tetapi pada saat itu kami tidak memiliki pengetahuan untuk mengimplementasikan kuorum secara independen.
Beralih ke Hazelcast
Dengan satu atau lain cara, kami mengatasi masalah yang muncul, tetapi itu mungkin bukan cara yang paling indah. Sekarang kami perlu memahami bagaimana menyelesaikannya dengan benar, jadi kami merumuskan daftar persyaratan untuk solusi cluster baru:
- Kami membutuhkan sesuatu yang akan memantau status semua server dan peran mereka. Sebut saja Service Discovery.
- Kami membutuhkan kunci kluster yang akan membantu memastikan konsistensi saat menjalankan kueri berbahaya.
- Kami membutuhkan struktur data terdistribusi yang akan memastikan bahwa papan ada di server tertentu dan menginformasikan jika ada kesalahan.
Itu adalah tahun 2015. Kami memilih Hazelcast - In-Memory Data Grid, sistem cluster untuk menyimpan informasi dalam RAM. Kemudian kami berpikir bahwa kami telah menemukan solusi ajaib, grail suci dunia interaksi cluster, kerangka kerja keajaiban yang dapat melakukan segalanya dan menggabungkan struktur data terdistribusi, kunci, pesan RPC dan antrian.
Seperti dengan ActiveMQ, kami mentransfer hampir semuanya ke Hazelcast:
- generasi sumber daya pengguna melalui ExecutorService;
- kunci didistribusikan ketika hak diubah;
- peran dan atribut server (Penemuan Layanan);
- satu registri papan terbuka, dll.
Topologi Hazelcast
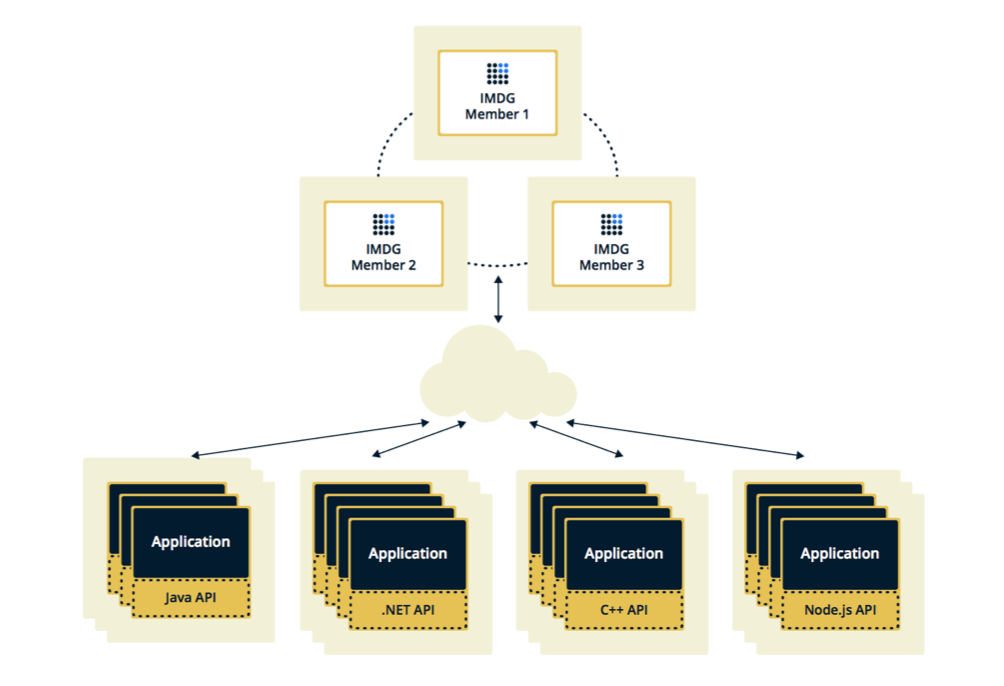
Hazelcast dapat dikonfigurasi dalam dua topologi. Opsi pertama adalah Client-Server, ketika anggota berada secara terpisah dari aplikasi utama, mereka sendiri membentuk sebuah cluster, dan semua aplikasi terhubung ke mereka sebagai database.
Topologi kedua adalah Tertanam, ketika anggota Hazelcast tertanam dalam aplikasi itu sendiri. Dalam hal ini, kita dapat menggunakan contoh lebih sedikit, akses ke data lebih cepat, karena data dan logika bisnis itu sendiri berada di tempat yang sama.
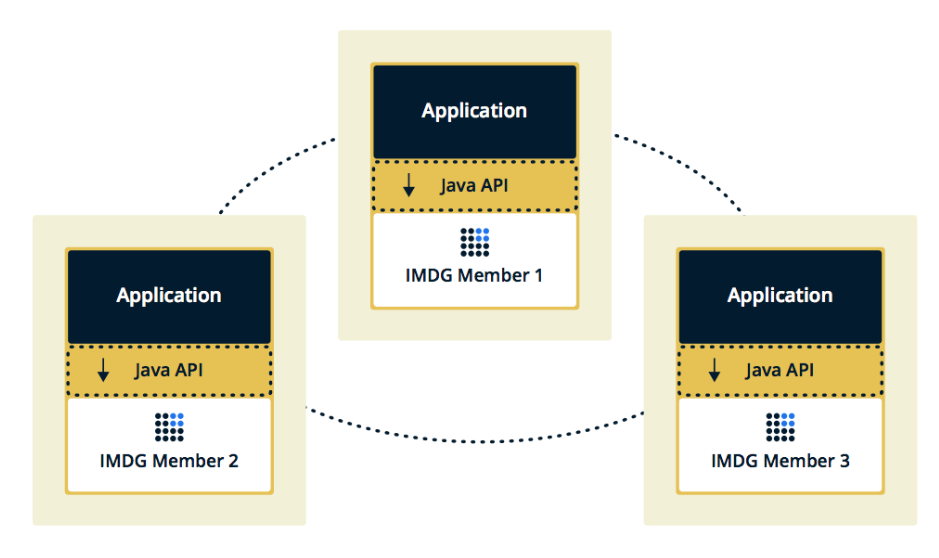
Kami memilih solusi kedua karena kami menganggapnya lebih efektif dan ekonomis untuk diterapkan. Efektif, karena kecepatan mengakses data Hazelcast akan lebih rendah, karena mungkin data ini ada di server saat ini. Ekonomis, karena kita tidak perlu mengeluarkan uang untuk contoh tambahan.
Cluster hang ketika anggota hang
Beberapa minggu setelah menyalakan Hazelcast, muncul masalah pada prod.
Pada awalnya, pemantauan kami menunjukkan bahwa salah satu server mulai secara bertahap membebani memori. Saat kami menonton server ini, seluruh server mulai memuat juga: CPU bertambah, lalu RAM, dan setelah lima menit semua server menggunakan semua memori yang tersedia.
Pada titik ini di konsol kami melihat pesan-pesan ini:
2015-07-15 15:35:51,466 [WARN] (cached18) com.hazelcast.spi.impl.operationservice.impl.Invocation: [my.host.address.com]:5701 [dev] [3.5] Asking ifoperation execution has been started: com.hazelcast.spi.impl.operationservice.impl.IsStillRunningService$InvokeIsStillRunningOperationRunnable@6d4274d7 2015-07-15 15:35:51,467 [WARN] (hz._hzInstance_1_dev.async.thread-3) com.hazelcast.spi.impl.operationservice.impl.Invocation:[my.host.address.com]:5701 [dev] [3.5] 'is-executing': true -> Invocation{ serviceName='hz:impl:executorService', op=com.hazelcast.executor.impl.operations.MemberCallableTaskOperation{serviceName='null', partitionId=-1, callId=18062, invocationTime=1436974430783, waitTimeout=-1,callTimeout=60000}, partitionId=-1, replicaIndex=0, tryCount=250, tryPauseMillis=500, invokeCount=1, callTimeout=60000,target=Address[my.host2.address.com]:5701, backupsExpected=0, backupsCompleted=0}
Di sini, Hazelcast memeriksa untuk melihat apakah operasi yang dikirim ke server "sekarat" pertama sedang berlangsung. Hazelcast mencoba mengikuti dan memeriksa status operasi beberapa kali per detik. Akibatnya, ia mem-spammed semua server lain dengan operasi ini, dan setelah beberapa menit mereka kehabisan memori, dan kami mengumpulkan beberapa GB log dari masing-masing server.
Situasi diulang beberapa kali. Ternyata ini adalah kesalahan dalam Hazelcast versi 3.5, di mana mekanisme detak jantung dilaksanakan, yang memeriksa status permintaan. Itu tidak memeriksa beberapa kasus batas yang kami temui. Saya harus mengoptimalkan aplikasi agar tidak masuk ke dalam kasus ini, dan setelah beberapa minggu Hazelcast memperbaiki kesalahan di rumah.
Sering menambahkan dan menghapus anggota dari Hazelcast
Masalah berikutnya yang kami temukan adalah menambah dan menghapus anggota dari Hazelcast.
Pertama, saya akan menjelaskan secara singkat bagaimana Hazelcast bekerja dengan partisi. Misalnya, ada empat server, dan masing-masing menyimpan sebagian data (pada gambar mereka berbeda warna). Unit adalah partisi primer, deuce adalah partisi sekunder, yaitu cadangan dari partisi utama.

Ketika server dimatikan, partisi dikirim ke server lain. Dalam hal server mati, partisi tidak ditransfer dari itu, tetapi dari server yang masih hidup dan menyimpan cadangan dari partisi ini.
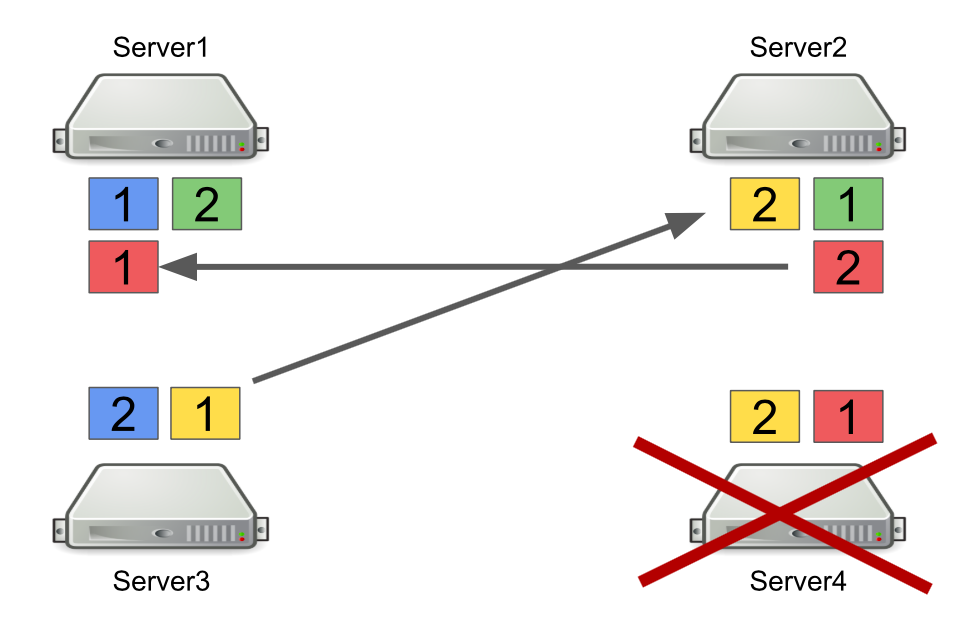
Ini adalah mekanisme yang andal. Masalahnya adalah kita sering menghidupkan dan mematikan server untuk menyeimbangkan beban, dan menyeimbangkan partisi juga membutuhkan waktu. Dan semakin banyak server berjalan dan semakin banyak data yang kami simpan di Hazelcast, semakin banyak waktu yang dibutuhkan untuk menyeimbangkan kembali partisi.
Tentu saja, kita dapat mengurangi jumlah cadangan, mis. partisi sekunder. Tapi ini tidak aman, karena sesuatu pasti akan salah.
Solusi lain adalah beralih ke topologi Client-Server sehingga menghidupkan dan mematikan server tidak mempengaruhi cluster Hazelcast inti. Kami mencoba melakukan ini, dan ternyata permintaan RPC tidak dapat dilakukan pada klien. Mari kita lihat mengapa.
Untuk melakukan ini, perhatikan contoh mengirim satu permintaan RPC ke server lain. Kami mengambil ExecutorService, yang memungkinkan Anda mengirim pesan RPC, dan mengirimkannya dengan tugas baru.
hazelcastInstance .getExecutorService(...) .submit(new Task(), ...);
Tugas itu sendiri terlihat seperti kelas Java biasa yang mengimplementasikan Callable.
public class Task implements Callable<Long> { @Override public Long call() { return 42; } }
Masalahnya adalah klien Hazelcast tidak hanya aplikasi Java, tetapi juga aplikasi C ++, .NET, dan lainnya. Secara alami, kami tidak dapat membuat dan mengkonversi kelas Java kami ke platform lain.
Salah satu opsi adalah beralih menggunakan permintaan http jika kami ingin mengirim sesuatu dari satu server ke server lain dan mendapatkan jawaban. Tetapi kemudian kita harus meninggalkan sebagian Hazelcast.
Oleh karena itu, sebagai solusi, kami memilih untuk menggunakan antrian alih-alih ExecutorService. Untuk melakukan ini, kami secara mandiri menerapkan mekanisme menunggu elemen dieksekusi dalam antrian, yang memproses kasus batas dan mengembalikan hasilnya ke server yang meminta.
Apa yang telah kita pelajari
Letakkan fleksibilitas dalam sistem. Masa depan terus berubah, jadi tidak ada solusi yang sempurna. Untuk melakukannya dengan benar, "benar" tidak berfungsi, tetapi Anda dapat mencoba menjadi fleksibel dan memasukkannya ke dalam sistem. Ini memungkinkan kami untuk menunda keputusan arsitektur yang penting sampai saat ketika tidak lagi mustahil untuk menerimanya.
Robert Martin dalam Arsitektur Bersih menulis tentang prinsip ini:
“Tujuan arsitek adalah menciptakan bentuk untuk sistem yang akan menjadikan politik elemen yang paling penting, dan detail yang tidak terkait dengan politik. Ini akan menunda dan menunda keputusan tentang perincian. "
Alat dan solusi universal tidak ada. Jika Anda merasa bahwa beberapa kerangka kerja menyelesaikan semua masalah Anda, maka kemungkinan besar tidak demikian. Karena itu, ketika menerapkan kerangka kerja apa pun, penting untuk memahami tidak hanya masalah apa yang akan dipecahkan, tetapi juga masalah apa yang akan dibawanya.
Jangan langsung menulis ulang semuanya. Jika Anda dihadapkan dengan masalah dalam arsitektur dan tampaknya satu-satunya solusi yang tepat adalah menulis semuanya dari awal, tunggu. Jika masalahnya benar-benar serius, temukan perbaikan cepat dan perhatikan bagaimana sistem akan bekerja di masa depan. Kemungkinan besar, ini bukan satu-satunya masalah dalam arsitektur, seiring waktu Anda akan menemukan lebih banyak. Dan hanya ketika Anda mengambil sejumlah masalah yang cukup Anda dapat mulai melakukan refactoring. Hanya dalam hal ini akan ada lebih banyak keuntungan darinya daripada nilainya.