Hai Habr.
Setelah publikasi peringkat artikel untuk
2017 dan
2018 , ide selanjutnya jelas - untuk mengumpulkan peringkat umum untuk semua tahun. Tetapi mengumpulkan tautan saja akan basi (meskipun juga bermanfaat), sehingga diputuskan untuk memperluas pemrosesan data dan mengumpulkan beberapa informasi yang lebih berguna.

Peringkat, statistik, dan sedikit kode sumber dengan Python di bawah kucing.
Pemrosesan data
Mereka yang langsung tertarik dengan hasil dapat melewati bab ini. Sementara itu, kami akan mencari tahu cara kerjanya.
Sebagai sumber data, ada file csv dari tipe berikut:
datetime,link,title,votes,up,down,bookmarks,views,comments 2006-07-13T14:23Z,https://habr.com/ru/post/1/,"Wiki-FAQ ",votes:1,votesplus:1,votesmin:0,bookmarks:8,views:28300,comments:56 2006-07-13T20:45Z,https://habr.com/ru/post/2/," … !",votes:1,votesplus:1,votesmin:0,bookmarks:1,views:14600,comments:37 ... 2019-01-25T03:47Z,https://habr.com/ru/post/435118/,"Save File Me — ",votes:5,votesplus:5,votesmin:0,bookmarks:26,views:1800,comments:6 2019-01-08T03:09Z,https://habr.com/ru/post/435120/,"Lambda- SQL… ",votes:9,votesplus:13,votesmin:4,bookmarks:63,views:5700,comments:30
Indeks semua artikel dalam formulir ini membutuhkan 42 MB, dan untuk mengumpulkannya dibutuhkan sekitar 10 hari untuk menjalankan skrip pada Raspberry Pi (unduhan berjalan dalam satu aliran dengan jeda agar tidak membebani server). Sekarang mari kita lihat data apa yang dapat diekstraksi dari semua ini.
Pemirsa Situs
Mari kita mulai dengan yang relatif sederhana - kami akan mengevaluasi pemirsa situs selama bertahun-tahun. Untuk perkiraan kasar, Anda dapat menggunakan jumlah komentar pada artikel. Unduh data dan tampilkan grafik jumlah komentar.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv(log_path, sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') def to_int(s):
Data terlihat seperti ini:

Hasilnya menarik - ternyata sejak 2009 pemirsa aktif situs (mereka yang meninggalkan komentar pada artikel) praktis tidak tumbuh. Meskipun mungkin semua karyawan IT ada di sini?
Karena kita berbicara tentang audiens, menarik untuk mengingat inovasi terbaru Habr - penambahan versi bahasa Inggris dari situs. Daftar artikel dengan "/ en /" di dalam tautan.
df = df[df['link'].str.contains("/en/")]
Hasilnya juga menarik (skala vertikal dibiarkan sama):

Lonjakan jumlah publikasi dimulai pada 15 Januari 2019, ketika pengumuman
Hello world! Atau Habr dalam bahasa Inggris , namun, beberapa bulan sebelum 3 artikel ini telah diterbitkan:
1 ,
2, dan
3 . Itu mungkin pengujian beta?
Pengidentifikasi
Poin menarik berikutnya, yang tidak kami sentuh pada bagian sebelumnya, adalah perbandingan pengidentifikasi artikel dan tanggal publikasi. Setiap artikel memiliki tautan tipe
habr.com/en/post/N , penomoran artikel bersifat end-to-end, artikel pertama memiliki pengidentifikasi 1, dan yang Anda baca adalah 441740. Tampaknya semuanya sederhana. Tapi tidak juga. Periksa korespondensi tanggal dan pengidentifikasi.
Unggah file ke Bingkai Data Pandas, pilih tanggal dan id, dan plotkan:
df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments']) dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%M:%S.%f') dates += datetime.timedelta(hours=3) df['datetime'] = dates def link2id(link):
Hasilnya mengejutkan - pengidentifikasi tidak selalu diambil berturut-turut, seperti yang diasumsikan semula, ada "pencilan" yang nyata.
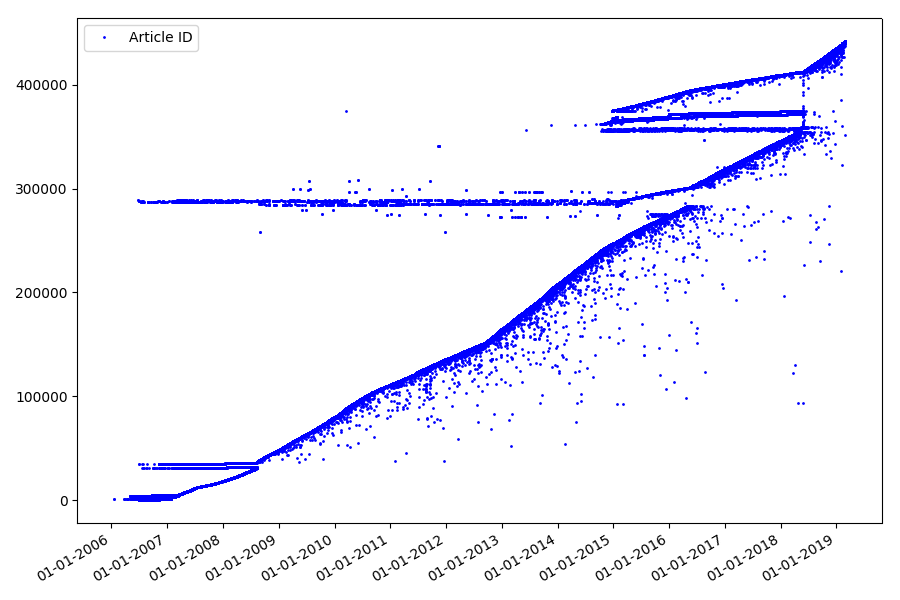
Sebagian karena mereka, hadirin memiliki pertanyaan tentang peringkat untuk 2017 dan 2018 - artikel seperti itu dengan ID yang "salah" tidak diperhitungkan oleh pengurai. Kenapa sulit dikatakan, dan tidak begitu penting.
Apa yang bisa menarik tentang pengidentifikasi? Ada hipotesis yang tidak bisa saya buktikan secara formal, tetapi yang tampak jelas. Identifier diberikan pada saat penulisan draft artikel, dan tanggal publikasi jelas datang kemudian. Seseorang memposting artikel pada hari yang sama, seseorang menerbitkan materi nanti. Kenapa semua ini? Mari kita tempatkan pengidentifikasi pada sumbu X, dan tanggal secara vertikal, dan lihat fragmen grafik secara lebih rinci:
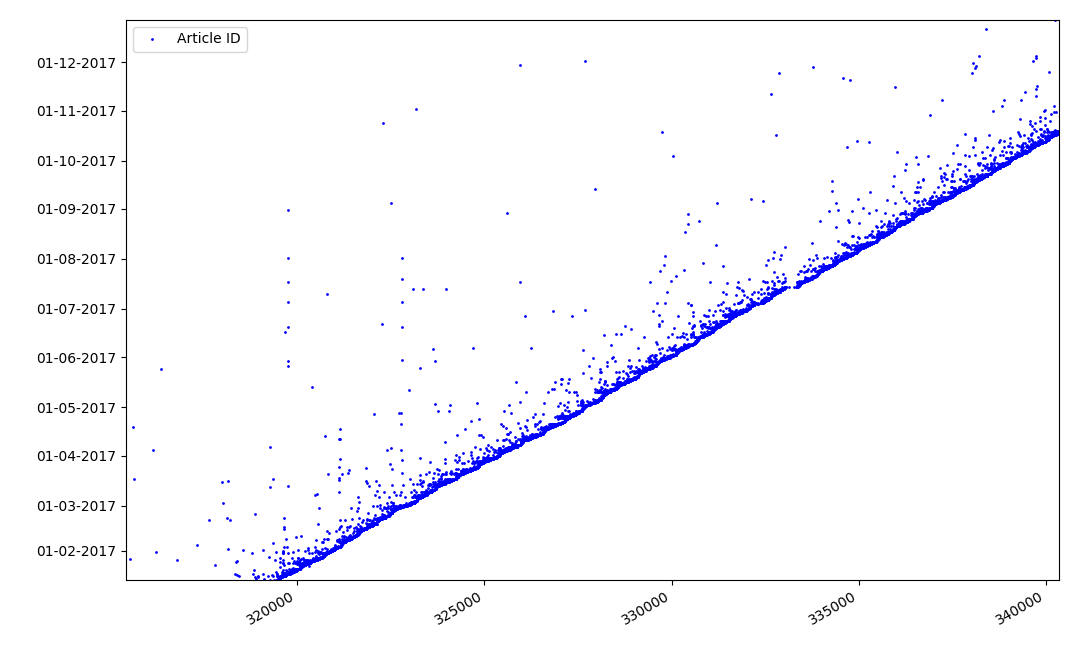
Hasil - kita melihat awan titik-titik di atas garis padat, yang menunjukkan kepada kita distribusi waktu selama
pembuatan artikel . Seperti yang Anda lihat, maksimum jatuh pada interval hingga 1-2 minggu. Hampir seluruh massa artikel dibuat dalam waktu tidak lebih dari sebulan, walaupun beberapa artikel diterbitkan beberapa bulan setelah pembuatan draft (tentu saja, ini tidak menjamin kami bahwa penulis mengerjakan artikel selama beberapa bulan setiap hari, tetapi hasilnya masih cukup menarik).
Tanggal dan waktu publikasi
Poin yang menarik, meskipun intuitif, adalah waktu publikasi artikel.
Statistik keluaran pada hari kerja:
print("Group by hour (average, working days):") df_workdays = df[(df['day'] < 5)] g = df_workdays.groupby(['hour']) hour_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = hour_count['counts'] print(grouped[['hour', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_hours = grouped['hour'].values view_hours_avg = grouped['counts'].values fig, ax = plt.subplots() plt.bar(view_hours, view_hours_avg, align='edge', label='Publication Time (Mo-Fr)') ax.set_xticks(range(24)) ax.xaxis.set_major_formatter(FormatStrFormatter('%d:00')) plt.legend(loc='best') fig.autofmt_xdate() plt.tight_layout() plt.show()
Ketergantungan jumlah artikel pada waktu publikasi pada hari kerja:
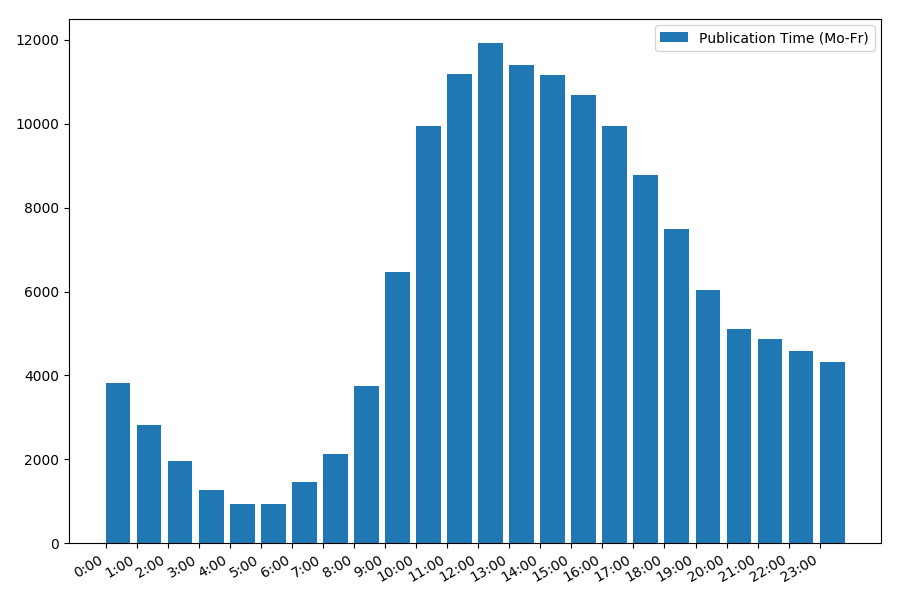
Gambarannya menarik, sebagian besar publikasi jatuh pada jam kerja. Masih menarik, karena sebagian besar penulis menulis artikel adalah pekerjaan utama, atau mereka hanya melakukannya selama jam kerja? ;) Tetapi jadwal distribusi pada akhir pekan memberikan gambaran yang berbeda:
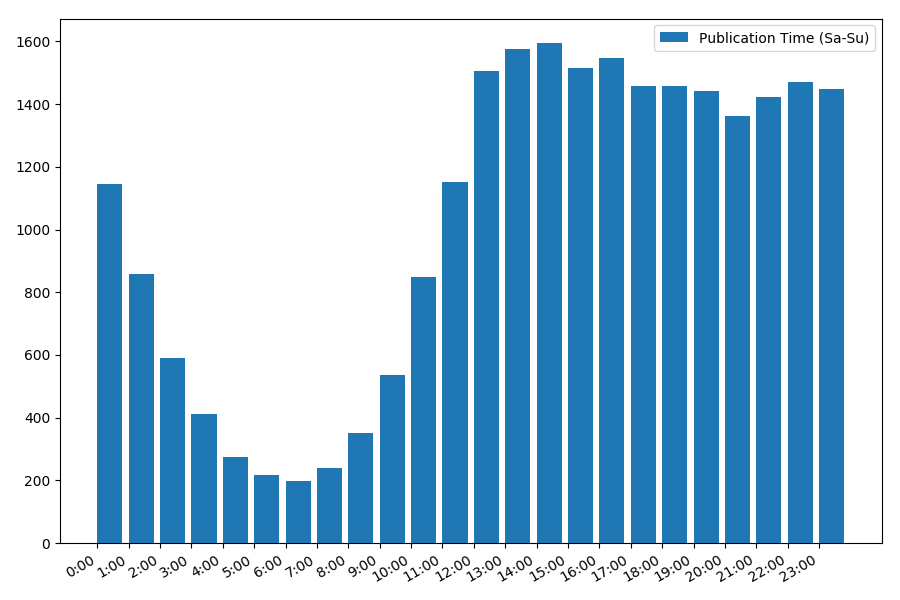
Karena kita berbicara tentang tanggal dan waktu, mari kita lihat nilai rata-rata pandangan dan jumlah artikel berdasarkan hari dalam seminggu.
g = df.groupby(['day', 'dayofweek']) dayofweek_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = dayofweek_count['counts'] grouped.sort_values('day', ascending=False) print(grouped[['day', 'dayofweek', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_days = grouped['day'].values view_per_day = grouped['views'].values counts_per_day = grouped['counts'].values days_of_week = grouped['dayofweek'].values plt.bar(view_days, view_per_day, align='edge', label='Avg.Views/day') plt.bar(view_days, counts_per_day, align='edge', label='Amount/day') plt.xticks(view_days, days_of_week) plt.ylim(bottom=0, top=10000) plt.show()
Hasilnya menarik:
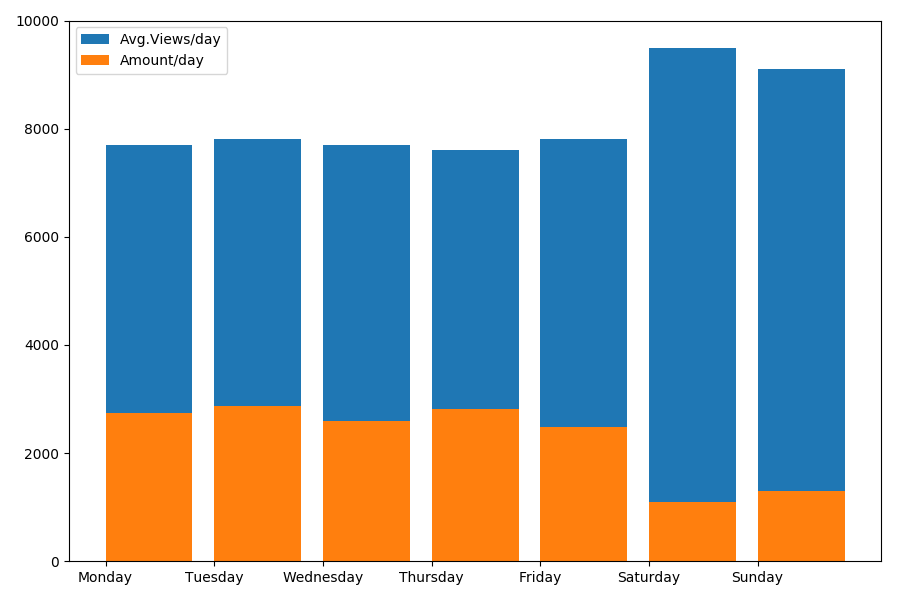
Seperti yang Anda lihat, lebih sedikit artikel yang dipublikasikan pada akhir pekan. Tetapi kemudian, setiap artikel mendapatkan lebih banyak penayangan, sehingga mempublikasikan artikel pada akhir pekan tampaknya cukup disarankan (seperti yang ditemukan di bagian
pertama , kehidupan aktif artikel tidak lebih dari 3-4 hari, sehingga beberapa hari pertama cukup kritis).
Artikelnya mungkin terlalu panjang. Berakhir di bagian
kedua .