
Saya akan berbagi cerita tentang proyek kecil: cara menemukan jawaban penulis di komentar tanpa mengetahui siapa penulis pos tersebut.
Saya memulai proyek saya dengan sedikit pengetahuan tentang pembelajaran mesin dan saya pikir tidak akan ada yang baru untuk spesialis di sini. Materi ini, dalam arti tertentu, adalah kompilasi artikel yang berbeda, di dalamnya saya akan memberi tahu Anda bagaimana mendekati tugas, dalam kode Anda dapat menemukan hal-hal kecil yang berguna dan trik dengan pemrosesan bahasa alami.
Data awal saya adalah sebagai berikut: database berisi materi media 2,5 juta dan komentar 39,5 juta. Untuk posting 1M, dengan satu atau lain cara, penulis materi diketahui (informasi ini ada dalam database, atau diperoleh dengan menganalisis data dengan alasan tidak langsung). Atas dasar ini, dataset dibuat dari catatan 215 ribu yang ditandai.
Awalnya, saya menggunakan pendekatan berbasis heuristik yang dipancarkan oleh kecerdasan alami dan diterjemahkan ke dalam query sql dengan pencarian teks lengkap atau ekspresi reguler. Contoh teks paling sederhana untuk diuraikan: "terima kasih atas komentarnya" atau "terima kasih atas peringkat yang baik" ini adalah penulis dalam 99,99% kasus, dan "terima kasih atas pekerjaannya" atau "Terima kasih!" Kirim materi melalui surat. Terima kasih! " - ulasan biasa. Dengan pendekatan seperti itu, hanya kebetulan yang jelas yang dapat disaring, kecuali untuk kasus kesalahan ketik dangkal atau ketika penulis sedang berdialog dengan komentator. Oleh karena itu, diputuskan untuk menggunakan jaringan saraf, ide ini datang bukan tanpa bantuan seorang teman.
Urutan komentar yang khas, yang manakah di antara penulisnya?
Metode untuk menentukan nada suara teks diambil sebagai dasar.Tugas ini sederhana bagi kita dalam dua kelas: penulis dan bukan penulis. Untuk melatih model, saya menggunakan
layanan dari Google yang menyediakan mesin virtual dengan GPU dan antarmuka notebook Jupiter.
Contoh jaringan yang ditemukan di Internet:
embed_dim = 128 model = Sequential() model.add(Embedding(max_fatures, embed_dim,input_length = X_train.shape[1])) model.add(SpatialDropout1D(0.2)) model.add(LSTM(196, dropout=0.5, recurrent_dropout=0.2)) model.add(Dense(1,activation='softmax')) model.compile(loss = 'binary_crossentropy', optimizer='adam',metrics = ['accuracy'])
pada baris yang dihapus dari tag html dan karakter khusus, mereka memberikan akurasi sekitar 65-74%, yang tidak jauh berbeda dengan melempar koin.
Hal yang menarik adalah bahwa penyelarasan urutan input melalui
pad_sequences(x_train, maxlen=max_len, padding='pre') memberikan perbedaan yang signifikan dalam hasil. Dalam kasus saya, hasil terbaik adalah dengan padding = 'post'.
Langkah selanjutnya adalah penggunaan lemmatization, yang segera memberi peningkatan keakuratan hingga 80% dan ini bisa dikerjakan lebih lanjut. Sekarang masalah utama adalah pembersihan teks yang benar. Misalnya, kesalahan ketik pada kata "terima kasih" dikonversi (kesalahan ketik dipilih berdasarkan frekuensi penggunaan) menjadi ekspresi reguler (ekspresi seperti itu telah terakumulasi setengah hingga dua lusin).
re16 = re.compile(ur"(?:\b:(?:1|c(?:|)|(?:|)|(?:(?:|(?:(?:(?:|(?:)?|))?|(?:)?))|)|(?:(?:(?:|)|)||||(?:(?:||(?:|)|(?:|(?:(?:(?:||(?:(?:||(?:[]|)|[]))?|[і]))?|||1)||)|)|||[]|(?:|)|(?:(?:(?:[]|)|?|(?:(?:(?:|(?:)?))?|)|(?:|)))?)||)|(?:|x))\b)", re.UNICODE)
Di sini, saya ingin mengucapkan terima kasih khusus kepada orang-orang yang terlalu sopan yang menganggap perlu menambahkan kata ini ke setiap kalimat mereka.
Mengurangi proporsi kesalahan ketik itu perlu, karena di pintu keluar dari lemmatizer mereka memberikan kata-kata aneh dan kami kehilangan informasi yang bermanfaat.
Tapi ada hikmahnya, kami sudah bosan berurusan dengan kesalahan ketik, berurusan dengan pembersihan teks yang kompleks, saya menggunakan representasi vektor kata - word2vec. Metode ini memungkinkan untuk menerjemahkan semua kesalahan ketik, kesalahan ketik, dan sinonim ke dalam vektor yang berjarak dekat.

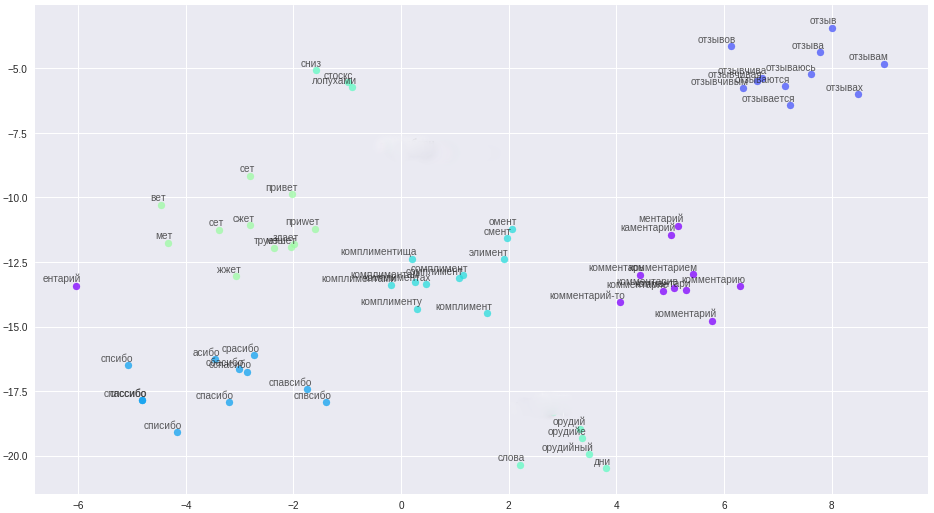
Kata-kata dan hubungannya dalam ruang vektor.
Aturan pembersihan secara signifikan disederhanakan (aha, pendongeng), semua pesan, nama pengguna, dibagi menjadi kalimat dan diunggah ke file. Poin penting: karena singkatnya komentator kami, untuk membangun vektor berkualitas tinggi, kata-kata memerlukan informasi kontekstual tambahan, misalnya, dari forum dan Wikipedia. Tiga model dilatih pada file yang dihasilkan: classic word2vec, Glove dan FastText. Setelah banyak percobaan, dia akhirnya memilih FastText, sebagai kelompok kata yang paling membedakan secara kualitatif dalam kasus saya.
Semua perubahan ini menghasilkan akurasi 84-85 persen yang stabil.
Contoh Model def model_conv_core(model_input, embd_size = 128): num_filters = 128 X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, 3, activation='relu', padding='same')(X) X = Dropout(0.3)(X) X = MaxPooling1D(2)(X) X = Conv1D(num_filters, 5, activation='relu', padding='same')(X) return X def model_conv1d(model_input, embd_size = 128, num_filters = 64, kernel_size=3): X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, kernel_size, padding='same', activation='relu', strides=1)(X)
dan 6 model lainnya dalam
kode . Beberapa model diambil dari jaringan, beberapa diciptakan secara independen.
Telah diperhatikan bahwa komentar yang berbeda menonjol pada model yang berbeda, ini mendorong gagasan untuk menggunakan ansambel model. Pertama, saya memasang ansambel secara manual, memilih pasangan model terbaik, lalu saya membuat generator. Untuk mengoptimalkan pencarian lengkap, saya mengambil kode abu-abu sebagai dasar.
def gray_code(n): def gray_code_recurse (g,n): k = len(g) if n <= 0: return else: for i in range (k-1, -1, -1): char='1' + g[i] g.append(char) for i in range (k-1, -1, -1): g[i]='0' + g[i] gray_code_recurse (g, n-1) g = ['0','1'] gray_code_recurse(g, n-1) return g def gen_list(m): out = [] g = gray_code(len(m)) for i in range (len(g)): mask_str = g[i] idx = 0 v = [] for c in list(mask_str): if c == '1': v.append(m[idx]) idx += 1 if len(v) > 1: out.append(v) return out
Dengan ansambel "hidup telah menjadi lebih menyenangkan" dan persentase ketepatan model saat ini berada pada level 86-87%, yang terutama terkait dengan klasifikasi berkualitas buruk dari beberapa penulis dalam dataset.

Masalah yang saya temui:
- Dataset tidak seimbang. Jumlah komentar dari penulis secara signifikan lebih sedikit daripada komentator lain.
- Kelas dalam sampel berjalan dalam urutan yang ketat. Intinya adalah bahwa awal, tengah dan akhir berbeda secara signifikan dalam kualitas klasifikasi. Ini terlihat jelas dalam proses pembelajaran pada jadwal ukuran f1.
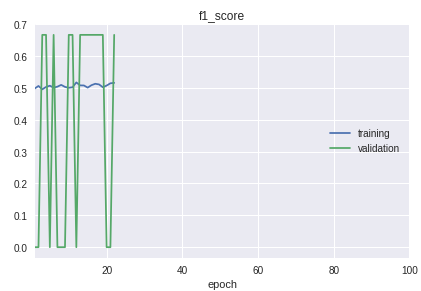
Untuk solusinya, sepeda dibuat untuk pemisahan menjadi sampel pelatihan dan validasi. Meskipun dalam prakteknya dalam banyak kasus prosedur train_test_split dari pustaka sklearn sudah cukup.
Grafik model kerja saat ini:

Akibatnya, saya mendapatkan model dengan definisi percaya diri dari penulis dari komentar singkat. Perbaikan lebih lanjut akan dikaitkan dengan pembersihan dan transfer hasil klasifikasi data nyata ke dalam dataset pelatihan.
Semua kode dengan penjelasan tambahan ada di dalam
repositori .
Sebagai catatan tambahan: jika Anda perlu mengklasifikasikan teks dalam jumlah besar, lihat model
VDCNN “Very Deep Convolutional Neural Network” (
implementasi pada keras), ini adalah analog dari ResNet untuk teks.
Bahan yang digunakan:
•
Ikhtisar kursus pembelajaran mesin•
Analisis konvolusi menggunakan konvolusi•
Jaringan konvolusional di NLP•
Metrik dalam pembelajaran mesinhttps://ld86.imtqy.com/ml-slides/unbalanced.html•
Tampilan di dalam model