
Sampai saat ini, setiap siswa yang telah mengambil kursus di jaringan saraf dapat membuat pengenalan karakter Korea. Berikan dia sampel dan komputer dengan kartu video, dan setelah beberapa saat dia akan membawakan Anda jaringan yang akan mengenali karakter Korea dengan hampir tanpa kesalahan.
Tetapi solusi semacam itu akan memiliki beberapa kelemahan:
Pertama , sejumlah besar perhitungan yang diperlukan, yang memengaruhi waktu operasi atau energi yang diperlukan (yang sangat penting untuk perangkat seluler). Memang, jika kita ingin mengenali setidaknya 3000 karakter, maka ini akan menjadi ukuran lapisan terakhir jaringan. Dan jika input dari lapisan ini setidaknya 512, maka kita mendapatkan 512 * 3000 perkalian. Terlalu banyak
Kedua , ukurannya. Lapisan terakhir yang sama dari contoh sebelumnya akan menimbang 512 * 3001 * 4 byte, mis. Sekitar 6 megabyte. Ini hanya satu lapisan, seluruh jaringan akan menimbang puluhan megabyte. Jelas bahwa ini bukan masalah besar untuk komputer desktop, tetapi tidak semua orang akan siap untuk menyimpan begitu banyak data pada smartphone untuk mengenali satu bahasa.
Ketiga , jaringan semacam itu akan memberikan hasil yang tidak terduga pada gambar yang bukan karakter Korea, tetapi tetap digunakan dalam teks Korea. Dalam kondisi laboratorium, ini tidak sulit, tetapi untuk aplikasi praktis teknologi, masalah ini harus dipecahkan.
Dan keempat , masalahnya adalah jumlah karakter: 3.000 kemungkinan besar cukup untuk, misalnya, membedakan steak dari teripang goreng di menu restoran, tetapi kadang-kadang ada teks yang lebih kompleks. Akan sulit untuk melatih jaringan untuk jumlah karakter yang lebih besar: itu tidak hanya akan lebih lambat, tetapi juga akan ada masalah dengan pengumpulan sampel pelatihan, karena frekuensi karakter menurun kira-kira secara eksponensial. Tentu saja, Anda bisa mendapatkan gambar dari font dan memperbesarnya, tetapi ini tidak cukup untuk melatih jaringan yang baik.
Dan hari ini saya akan memberi tahu Anda bagaimana kami berhasil menyelesaikan masalah ini.
Bagaimana cara kerja penulisan Korea?
Tulisan Korea, Hangul, adalah persilangan antara tulisan Cina dan Eropa. Secara lahiriah, ini adalah karakter persegi menyerupai hieroglif, dan pada satu halaman teks Anda dapat menghitung lebih dari seratus yang unik. Di sisi lain, itu adalah penulisan fonetik, yaitu, berdasarkan rekaman suara. Ada alfabet yang berisi 24 huruf (ditambah Anda juga bisa menghitung diffraphs dan diftong). Tetapi, tidak seperti alfabet Latin atau Sirilik, suara tidak ditulis dalam satu baris, tetapi digabungkan dalam beberapa blok. Misalnya, jika kita menulis dengan cara yang sama, maka frasa "Halo, Habr" dapat ditulis dalam tiga blok seperti ini:
Setiap blok dapat terdiri dari dua, tiga, atau empat huruf. Dalam hal ini, konsonan selalu didahulukan, kemudian satu atau dua vokal, dan pada akhirnya bisa ada konsonan lain. Ada beberapa cara berbeda untuk menggabungkan huruf menjadi blok, yaitu, di blok yang berbeda huruf kedua, misalnya, akan berdiri di tempat yang berbeda.
Gambar di bawah ini menunjukkan dua blok yang bersama-sama membentuk kata "Hangul". Huruf pertama dari setiap blok ditandai dengan warna merah, vokal disorot dengan warna biru, dan konsonan terakhir disorot dengan warna hijau.
Sumber gambar: Wikipedia.Ubah blok Hangul
Yaitu, ternyata satu blok Hangul dapat dijelaskan dengan rumus: Ci V [V] [Cf], di mana Ci adalah konsonan awal (mungkin ganda), V adalah vokal, dan Cf adalah konsonan akhir (juga bisa ganda). Representasi seperti itu tidak nyaman untuk pengakuan, jadi kami mengubahnya.
Pertama, gabungkan kedua vokal. Kami mendapatkan rumus Ci V '[Cf], di mana V' - semua opsi yang memungkinkan untuk menggabungkan huruf, mengingat tidak adanya huruf kedua. Karena ada 10 vokal dalam bahasa tersebut, orang akan berharap bahwa sebagai hasilnya kita mendapatkan 10 * (10 + 1) pilihan, tetapi dalam praktiknya tidak semuanya mungkin, hanya 21 yang diperoleh.
Selanjutnya, surat terakhir mungkin tidak. Tambahkan ke banyak surat yang diharapkan di akhir yang kosong. Kemudian kita mendapatkan formula Ci V 'Cf *. Jadi, ternyata sekarang simbol Korea selalu terdiri dari tiga "huruf". Anda dapat mempelajari kisi.
Kami membangun jaringan
Idenya adalah bahwa alih-alih mengenali seluruh karakter, kita akan mengenali masing-masing huruf di dalamnya. Jadi, alih-alih satu softmax besar di akhir, kami mendapatkan tiga yang kecil, masing-masing sekitar beberapa puluh ukuran. Mereka sesuai dengan "huruf" pertama, kedua dan ketiga dalam suku kata. Hasilnya, kami mendapatkan arsitektur berikut:
gambar yang bisa diklik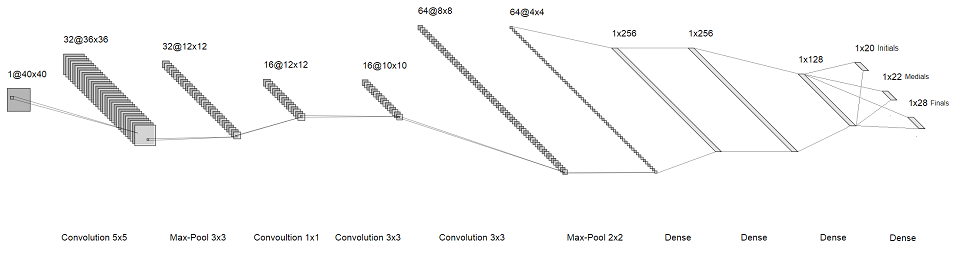
Kami berlatih, menjalankan sampel terpisah. Kualitasnya bagus, gridnya cepat, dan beratnya kecil. Mari kita coba membawanya keluar dari laboratorium ke dunia nyata.
Kami memecahkan masalah
Kami akan mendapatkan masalah pertama segera: kadang-kadang gambar yang bukan karakter Korea masuk ke input, dan jaringan di dalamnya berperilaku sangat tidak terduga. Anda dapat, tentu saja, melatih jaringan lain yang akan membedakan blok Korea dari yang lainnya, tetapi kami akan membuatnya lebih mudah.
Mari kita lakukan hal yang sama dengan yang kita lakukan dengan grup huruf ketiga: tambahkan output untuk ketiadaan huruf. Maka rumus simbol akan terlihat seperti ini: Ci * V '* Cf *. Dan di set pelatihan, kami akan menambahkan semua jenis sampah - karakter Cina, karakter yang dipotong salah, huruf Eropa, dan kami akan mengajarkan jaringan untuk menandai tiga huruf kosong di dalamnya.
Kami berlatih, tes. Ini bekerja, tetapi masalahnya tetap ada. Ternyata cukup sering, misalnya, gambar seperti itu jatuh ke dalam kisi:
Ini adalah blok bahasa Korea yang tepat di mana satu kutipan terhenti. Dan jelas bahwa pada mereka jaringan dengan sempurna menemukan ketiga huruf yang terdiri dari blok. Itu hanya gambar yang tidak benar, dan kita perlu memberi sinyal tentang itu. Adalah salah untuk mengembalikan huruf-huruf kosong di sini, karena terdapat pada gambar. Mari kita coba terapkan apa yang sudah terbukti baik: tambahkan dua output lagi untuk mengenali punctuator lengket tersebut. Masing-masing dari mereka akan memiliki satu output tambahan untuk situasi ketika tidak ada yang berlebihan dalam gambar, tetapi di samping itu perlu menambahkan satu output lagi untuk situasi "ada punctuator, tetapi tidak dikenali, mungkin sampah."
Terlatih Adalah buruk di grid seperti itu untuk mengenali punctuator: itu membedakan koma dari braket, tetapi sudah sulit dari satu titik. Anda dapat meningkatkan kompleksitas grid, tetapi tidak mau. Kami akan berurusan dengan pengakuan punctuator nanti, tetapi untuk saat ini kami hanya akan memberi tahu apakah ada sesuatu di sana atau tidak. Grid ini belajar dengan baik.
Kami menemukan punctuator terpaku, tetapi bagaimana jika, sebaliknya, bagian dari kunci hilang pada gambar? Ada kata dua karakter seperti itu, tetapi kami memotongnya menjadi karakter yang salah:
Jaringan di sini tanpa masalah menentukan huruf pusat. Ini akan menjadi kualitas yang sangat berguna jika tugas kita hanya mengenali pilihan karakter, tetapi di dunia nyata itu akan berbahaya: ketika kita salah memotong string menjadi karakter, kita harus meneruskan informasi ini di atas, karena kalau tidak, bagian yang tersisa kemudian diakui sebagai semacam tanda baca, dan dalam teks yang dihasilkan akan ada karakter tambahan.
Untuk mengatasi masalah ini, kami akan menggunakan sisa beberapa eksperimen lama beberapa tahun yang lalu. Gagasan mengenali karakter Korea melalui surat muncul sejak lama, dan upaya pertama dilakukan bahkan sebelum era jaringan saraf, tetapi mereka tidak menemukan aplikasi praktis. Namun sejak itu, hal-hal menarik tetap ada:
- Menandai di mana setiap blok memiliki surat.
- Berkualitas tinggi, meskipun cepat, memotong huruf-huruf ini dari simbol.
Setelah membersihkan debu, dengan bantuan barang ini, kami akan menghasilkan cukup banyak gambar bermasalah tanpa salah satu huruf dan kami akan secara khusus mengajarkan jaringan untuk menjawab bahwa itu adalah huruf kosong.
Itu semua, tidak ada lagi masalah dengan mengenali karakter Korea, tetapi kehidupan menempatkan tongkat ke roda lagi.
Faktanya adalah bahwa selain karakter Hangeul, teks Korea juga terdiri dari sejumlah besar karakter lain: punctuator, karakter Eropa (setidaknya angka) dan karakter Cina. Tetapi mereka secara alami lebih jarang terjadi. Kami akan membaginya menjadi dua kelompok: hieroglif dan yang lainnya, dan kami akan melatih kisi kami untuk masing-masing. Dan kami akan membuat classifier sederhana, yang menurut hasil jaringan untuk mengenali karakter Korea dan beberapa tanda lainnya (geometris, di tempat pertama) akan menjawab apakah setidaknya salah satu dari mereka perlu diluncurkan, dan jika demikian, yang mana. Anda perlu mengenali sedikit karakter Eropa, sehingga kisi-kisi akan kecil, tetapi untuk hieroglif ... Ini menyimpan bahwa mereka jarang ditemukan dalam teks, jadi mari kita putar classifier kita sehingga sangat jarang menyarankan mengenalinya.
Secara umum, dengan dua kisi-kisi ini, masalah jawaban yang memadai muncul dalam gambar yang bukan simbol yang dilatihnya, tetapi kita akan berbicara tentang cara menyelesaikan masalah ini di lain waktu.
Lakukan eksperimen
Yang pertama . Ada dua basis gambar, sebut saja mereka Nyata dan Sintetis. Nyata terdiri dari gambar nyata yang diperoleh dari dokumen yang dipindai, dan Sintetis - gambar yang diperoleh dari font. Di pangkalan pertama ada gambar untuk 2374 blok (sisanya sangat langka), dan dari font kami mendapatkan semua kemungkinan 1.172 karakter. Mari kita coba latih jaringan pada blok-blok yang ada di Real (kita akan mengambil gambar dari kedua pangkalan), dan mengujinya pada mereka yang hanya di Sintetis. Hasil:

Yaitu, dalam sekitar 60% kasus, jaringan mampu mengenali blok-blok itu, contoh-contoh yang tidak terlihat sama sekali selama pelatihan. Kualitasnya bisa lebih tinggi jika bukan karena satu masalah: di antara huruf terakhir ada yang sangat langka, dan selama pelatihan jaringan melihat sangat sedikit gambar balok di dalamnya. Ini menjelaskan kualitas rendah di kolom terakhir. Jika mungkin untuk memilih 2.374 blok yang kami pelajari, dengan cara yang berbeda, maka kualitasnya kemungkinan besar akan terasa lebih tinggi.
Yang kedua Bandingkan jaringan kami dengan jaringan "normal", yang memiliki softmax pada akhirnya. Saya ingin membuatnya dalam ukuran 11172, tetapi kami tidak dapat menemukan jumlah gambar nyata yang cukup untuk blok langka, jadi kami membatasi diri hingga 2374. Kualitas dan kecepatan jaringan ini tergantung pada ukuran lapisan yang disembunyikan. Kami hanya akan mengajar di Real, mengujinya (di bagian lain, tentu saja).

Yaitu, bahkan jika kita membatasi diri kita hanya untuk mengenali 2374 blok, jaringan kita lebih cepat dan pada tingkat kualitas yang sama.
Ketiga Misalkan kita bisa mendapatkan basis besar dari semua 1.172 blok Korea. Jika kita melatih jaringan dengan softmax di atasnya, berapa lama itu akan bekerja tepat waktu? Semua eksperimen mahal untuk dilakukan, jadi kami hanya mempertimbangkan jaringan dengan 256 ukuran lapisan tersembunyi:

Kami mendapatkan hasilnya
Tanpa mereka, tidak akan ada yang terjadi
Saya mengucapkan terima kasih kepada kolega saya Jura Chulinin, penulis asli gagasan itu. Ini
dipatenkan di Rusia, dan, di samping itu, aplikasi serupa telah
diajukan ke Kantor Paten Amerika (USPTO). Terima kasih banyak kepada pengembang Misha Zatsepin, yang mengimplementasikan semua ini dan melakukan semua percobaan.
Yuri Vatlin,
Kepala kelompok Script Kompleks