Halo semuanya! Musim semi telah tiba, yang berarti bahwa kurang dari satu bulan tersisa sebelum dimulainya kursus
Pengembang Python . Untuk kursus ini publikasi kami hari ini akan dikhususkan.

 Tugas:
Tugas:- Pelajari tentang struktur internal Python;
- Memahami prinsip-prinsip membangun pohon sintaksis abstrak (AST);
- Tulis kode yang lebih efisien dalam waktu dan memori.
Rekomendasi awal:- Pemahaman dasar juru bahasa (AST, token, dll.).
- Pengetahuan tentang Python.
- Pengetahuan dasar C.
batuhan@arch-pc ~/blogs/cpython/exec_model python --version Python 3.7.0
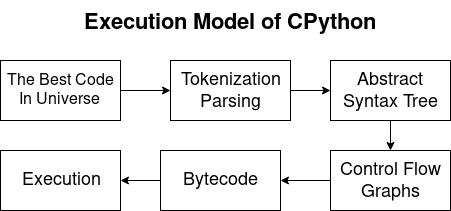
Model Eksekusi CPythonPython adalah bahasa yang dikompilasi dan ditafsirkan. Dengan demikian, kompiler Python menghasilkan bytecodes, dan interpreter mengeksekusinya. Selama artikel kami akan mempertimbangkan masalah-masalah berikut:
- Parsing dan tokenization:
- Transformasi dalam AST;
- Grafik Alir Kontrol (CFG);
- Bytecode
- Berjalan di mesin virtual CPython.
Parsing dan tokenization.
Tata bahasa.Grammar mendefinisikan semantik bahasa Python. Ini juga berguna dalam menunjukkan cara pengurai harus menafsirkan bahasa. Tata bahasa Python menggunakan sintaksis yang mirip dengan bentuk Backus-Naur yang diperluas. Ini memiliki tata bahasa sendiri untuk penerjemah dari bahasa sumber. Anda dapat menemukan file tata bahasa di direktori "cpython / Grammar / Grammar".
Berikut ini adalah contoh tata bahasa,
batuhan@arch-pc ~/cpython/Grammar master grep "simple_stmt" Grammar | head -n3 | tail -n1 simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
Ekspresi sederhana berisi ekspresi kecil dan tanda kurung, dan perintah berakhir dengan baris baru. Ekspresi kecil terlihat seperti daftar ekspresi yang mengimpor ...
Beberapa ungkapan lain :)
small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt) ... del_stmt: 'del' exprlist pass_stmt: 'pass' flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt break_stmt: 'break' continue_stmt: 'continue'
Tokenisasi (Penggabungan)Tokenisasi adalah proses memperoleh aliran data teks dan membelah menjadi token kata-kata penting (untuk penerjemah) dengan metadata tambahan (misalnya, di mana token dimulai dan berakhir, dan berapa nilai string dari token ini).
TokenToken adalah file header yang berisi definisi semua token. Ada 59 jenis token di Python (Sertakan / token.h).
Di bawah ini adalah contoh dari beberapa di antaranya,
Anda melihat mereka jika Anda memecah beberapa kode Python menjadi token.
Tokenisasi dengan CLIIni file tests.py
def greetings(name: str): print(f"Hello {name}") greetings("Batuhan")
Kemudian kita tokenize menggunakan perintah python -m tokenize dan berikut ini adalah output:
batuhan@arch-pc ~/blogs/cpython/exec_model python -m tokenize tests.py 0,0-0,0: ENCODING 'utf-8' ... 2,0-2,4: INDENT ' ' 2,4-2,9: NAME 'print' ... 4,0-4,0: DEDENT '' ... 5,0-5,0: ENDMARKER ''
Di sini angka (misalnya, 1.4-1.13) menunjukkan di mana token dimulai dan di mana berakhir. Token penyandian selalu merupakan token pertama yang kami terima. Ini memberikan informasi tentang penyandian file sumber, dan jika ada masalah dengan itu, penerjemah melempar pengecualian.
Tokenisasi dengan tokenize.tokenizeJika Anda perlu tokenize file dari kode Anda, Anda dapat menggunakan modul
tokenize dari
stdlib .
>>> with open('tests.py', 'rb') as f: ... for token in tokenize.tokenize(f.readline): ... print(token) ... TokenInfo(type=57 (ENCODING), string='utf-8', start=(0, 0), end=(0, 0), line='') ... TokenInfo(type=1 (NAME), string='greetings', start=(1, 4), end=(1, 13), line='def greetings(name: str):\n') ... TokenInfo(type=53 (OP), string=':', start=(1, 24), end=(1, 25), line='def greetings(name: str):\n') ...
Jenis token adalah id di file header
token.h. String adalah nilai token. Mulai dan Akhir menunjukkan di mana token dimulai dan berakhir, masing-masing.
Dalam bahasa lain, blok ditunjukkan oleh tanda kurung atau pernyataan awal / akhir, tetapi Python menggunakan indentasi dan level yang berbeda. INDEN dan DENEN dan menunjukkan indentasi. Token ini diperlukan untuk membangun pohon parsing relasional dan / atau pohon sintaksis abstrak.
Generasi ParserGenerasi Parser - proses yang menghasilkan parser sesuai dengan tata bahasa yang diberikan. Generator Parser dikenal sebagai PGen. Cpython memiliki dua generator parser. Satu adalah asli (
Parser/pgen ) dan satu ditulis ulang dengan python (
/Lib/lib2to3/pgen2 ).
"Generator asli adalah kode pertama yang saya tulis untuk Python"
-GuidoDari kutipan di atas, menjadi jelas bahwa
pgen adalah hal yang paling penting dalam bahasa pemrograman. Ketika Anda memanggil pgen (dalam
Parser / pgen ) itu menghasilkan file header dan file-C (pengurai itu sendiri). Jika Anda melihat kode C yang dihasilkan, itu mungkin tampak tidak berguna, karena penampilannya yang bermakna adalah opsional. Ini berisi banyak data dan struktur statis. Selanjutnya, kami akan mencoba menjelaskan komponen utamanya.
DFA (Mesin Defined State)Parser mendefinisikan satu DFA untuk setiap nonterminal. Setiap DFA didefinisikan sebagai susunan status.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"}, ... {342, "yield_arg", 0, 3, states_86, "\000\040\200\000\002\000\000\000\000\040\010\000\000\000\020\002\000\300\220\050\037\000\000"}, };
Untuk setiap DFA, ada starter kit yang menunjukkan token mana yang bukan terminal bisa dimulai.
KetentuanSetiap negara ditentukan oleh array transisi / tepi (busur).
static state states_86[3] = { {2, arcs_86_0}, {1, arcs_86_1}, {1, arcs_86_2}, };
Transisi (busur)Setiap larik transisi memiliki dua angka. Nomor pertama adalah nama transisi (label busur), ini mengacu pada nomor simbol. Angka kedua adalah tujuannya.
static arc arcs_86_0[2] = { {77, 1}, {47, 2}, }; static arc arcs_86_1[1] = { {26, 2}, }; static arc arcs_86_2[1] = { {0, 2}, };
Nama (label)Ini adalah tabel khusus yang memetakan id karakter ke nama transisi.
static label labels[177] = { {0, "EMPTY"}, {256, 0}, {4, 0}, ... {1, "async"}, {1, "def"}, ... {1, "yield"}, {342, 0}, };
Angka 1 sesuai dengan semua pengidentifikasi. Dengan demikian, masing-masing mendapat nama transisi yang berbeda, bahkan jika mereka semua memiliki karakter id yang sama.
Contoh sederhana:Misalkan kita memiliki kode yang menampilkan "Hai" jika 1 - true:
if 1: print('Hi')
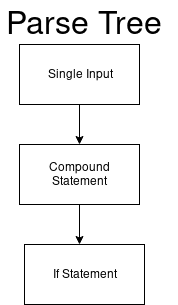
Parser menganggap kode ini sebagai single_input.
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
Kemudian pohon parsing kita mulai pada simpul akar dari input satu kali.

Dan nilai DFA kami (single_input) adalah 0.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"} ... }
Ini akan terlihat seperti ini:
static arc arcs_0_0[3] = { {2, 1}, {3, 1}, {4, 2}, }; static arc arcs_0_1[1] = { {0, 1}, }; static arc arcs_0_2[1] = { {2, 1}, }; static state states_0[3] = { {3, arcs_0_0}, {1, arcs_0_1}, {1,
arcs_0_2},
};
Di sini
arc_0_0 terdiri dari tiga elemen. Yang pertama adalah
NEWLINE , yang kedua adalah
simple_stmt , dan yang terakhir adalah
compound_stmt .
Dengan set awal
simple_stmt kita dapat menyimpulkan bahwa
simple_stmt tidak dapat dimulai dengan
if . Namun, meskipun jika bukan baris baru, maka
compound_stmt masih dapat dimulai dengan
if . Jadi, kita beralih ke
arc ({4;2}) terakhir
arc ({4;2}) dan menambahkan node
compound_stmt ke parsing tree dan beralih ke DFA baru sebelum melanjutkan ke nomor 2. Kami mendapatkan pohon parsing yang diperbarui:

DFA baru mem-parsing pernyataan majemuk.
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt
Dan kami mendapatkan yang berikut:
static arc arcs_39_0[9] = { {91, 1}, {92, 1}, {93, 1}, {94, 1}, {95, 1}, {19, 1}, {18, 1}, {17, 1}, {96, 1}, }; static arc arcs_39_1[1] = { {0, 1}, }; static state states_39[2] = { {9, arcs_39_0}, {1, arcs_39_1}, };
Hanya lompatan pertama yang bisa dimulai dengan
if . Kami mendapatkan pohon parsing yang diperbarui.
Kemudian kita kembali mengubah DFA dan ifs DFA berikutnya.
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]
Akibatnya, kami mendapatkan satu-satunya transisi dengan penunjukan 97. Ini bertepatan dengan token
if .
static arc arcs_41_0[1] = { {97, 1}, }; static arc arcs_41_1[1] = { {26, 2}, }; static arc arcs_41_2[1] = { {27, 3}, }; static arc arcs_41_3[1] = { {28, 4}, }; static arc arcs_41_4[3] = { {98, 1}, {99, 5}, {0, 4}, }; static arc arcs_41_5[1] = { {27, 6}, }; static arc arcs_41_6[1] = { {28, 7}, }; ...
Saat kami beralih ke status berikutnya, tetap dalam DFA yang sama, arcs_41_1 berikutnya juga hanya memiliki satu transisi. Ini berlaku untuk terminal uji. Itu harus dimulai dengan angka (misalnya, 1).
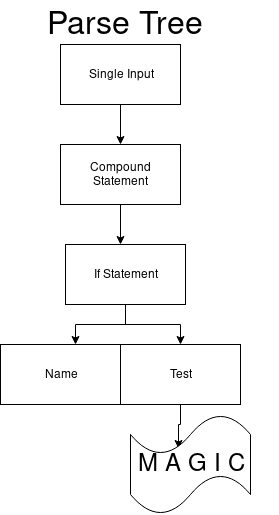
Hanya ada satu transisi di arc_41_2 yang mendapat token titik dua (:).

Jadi kita mendapatkan satu set yang bisa dimulai dengan nilai cetak. Akhirnya, buka arcs_41_4. Transisi pertama dalam set adalah ekspresi elif, yang kedua adalah yang lain, dan yang ketiga adalah untuk keadaan terakhir. Dan kita mendapatkan tampilan akhir dari pohon parsing.
 Antarmuka Python untuk parser.
Antarmuka Python untuk parser.
Python memungkinkan Anda untuk mengedit pohon parsing untuk ekspresi menggunakan modul yang disebut parser.
>>> import parser >>> code = "if 1: print('Hi')"
Anda dapat menghasilkan pohon sintaksis tertentu (Sintaksis Beton Pohon, CST) menggunakan parser.suite.
>>> parser.suite(code).tolist() [257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '1']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, "'Hi'"]]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]
Nilai output akan menjadi daftar bersarang. Setiap daftar dalam struktur memiliki 2 elemen. Yang pertama adalah id karakter (0-256 - terminal, 256+ - non-terminal) dan yang kedua adalah string token untuk terminal.
Pohon sintaksis abstrakBahkan, pohon sintaksis abstrak (AST) adalah representasi struktural dari kode sumber dalam bentuk pohon, di mana setiap simpul menunjukkan berbagai jenis konstruksi bahasa (ekspresi, variabel, operator, dll.)
Apa itu pohon?Pohon adalah struktur data yang memiliki simpul akar sebagai titik awal. Simpul akar diturunkan oleh cabang (transisi) ke simpul lain. Setiap simpul, kecuali root, memiliki satu simpul induk unik.
Ada perbedaan tertentu antara pohon sintaksis abstrak dan pohon parsing.
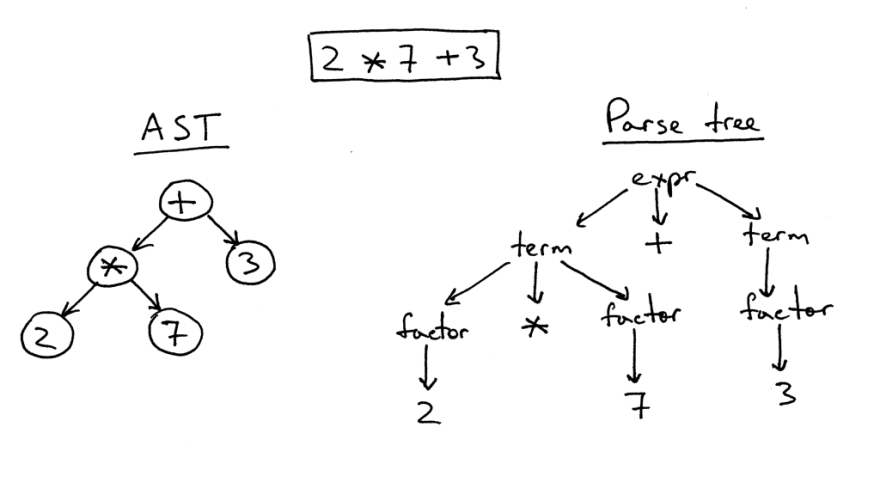
Di sebelah kanan adalah pohon penguraian untuk ekspresi 2 * 7 + 3. Ini secara harfiah adalah gambar satu-ke-satu dari kode sumber dalam bentuk pohon. Semua ekspresi, istilah, dan nilai terlihat di sana. Namun, gambar seperti itu terlalu rumit untuk sepotong kode sederhana, jadi kita bisa menghapus semua ekspresi sintaksis yang harus kita tentukan dalam kode untuk perhitungan.
Pohon yang disederhanakan seperti itu disebut pohon sintaksis abstrak (AST). Di sebelah kiri pada gambar ditampilkan persis untuk kode yang sama. Semua ekspresi sintaksis telah dibuang untuk memudahkan pemahaman, tetapi ingat bahwa informasi tertentu telah hilang.
Contoh
Python menawarkan modul AST bawaan untuk bekerja dengan AST. Untuk menghasilkan kode dari pohon AST, Anda dapat menggunakan modul pihak ketiga, misalnya
Astor .
Misalnya, pertimbangkan kode yang sama seperti sebelumnya.
>>> import ast >>> code = "if 1: print('Hi')"
Untuk mendapatkan AST, kami menggunakan metode ast.parse.
>>> tree = ast.parse(code) >>> tree <_ast.Module object at 0x7f37651d76d8>
Coba gunakan metode
ast.dump untuk mendapatkan pohon sintaksis abstrak yang lebih mudah dibaca.
>>> ast.dump(tree) "Module(body=[If(test=Num(n=1), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hi')], keywords=[]))], orelse=[])])"
AST umumnya dianggap lebih visual dan mudah dipahami daripada pohon parsing.
Control Flow Graf (CFG)Grafik aliran kendali adalah grafik arah yang memodelkan aliran suatu program menggunakan blok-blok dasar yang berisi representasi perantara.
Biasanya, CFG adalah langkah sebelumnya sebelum mendapatkan nilai kode output. Kode dihasilkan langsung dari blok dasar menggunakan pencarian kedalaman mundur di CFG, mulai dari atas.
BytecodeBytecode Python adalah seperangkat instruksi antara yang bekerja di mesin virtual Python. Ketika Anda menjalankan kode sumber, Python membuat direktori bernama __pycache__. Ini menyimpan kode yang dikompilasi untuk menghemat waktu jika memulai kembali kompilasi.
Pertimbangkan fungsi Python sederhana di func.py.
def say_hello(name: str): print("Hello", name) print(f"How are you {name}?")
>>> from func import say_hello >>> say_hello("Batuhan") Hello Batuhan How are you Batuhan?
say_hello objek
say_hello adalah fungsi.
>>> type(say_hello) <class 'function'>
Ini memiliki atribut
__code__ .
>>> say_hello.__code__ <code object say_hello at 0x7f13777d9150, file "/home/batuhan/blogs/cpython/exec_model/func.py", line 1>
Objek KodeObjek kode adalah struktur data yang tidak dapat diubah yang berisi instruksi atau metadata yang diperlukan untuk menjalankan kode. Sederhananya, ini adalah representasi dari kode Python. Anda juga bisa mendapatkan objek kode dengan mengkompilasi pohon sintaksis abstrak menggunakan metode
kompilasi .
>>> import ast >>> code = """ ... def say_hello(name: str): ... print("Hello", name) ... print(f"How are you {name}?") ... say_hello("Batuhan") ... """ >>> tree = ast.parse(code, mode='exec') >>> code = compile(tree, '<string>', mode='exec') >>> type(code) <class 'code'>
Setiap objek kode memiliki atribut yang berisi informasi tertentu (diawali dengan co_). Di sini kami hanya menyebutkan beberapa saja.
co_nameUntuk memulai - sebuah nama. Jika suatu fungsi ada, maka itu harus memiliki nama, masing-masing, nama ini akan menjadi nama fungsi, situasi yang mirip dengan kelas. Dalam contoh AST, kami menggunakan modul, dan kami dapat memberi tahu kompiler apa yang ingin kami beri nama. Biarkan mereka menjadi
module .
>>> code.co_name '<module>' >>> say_hello.__code__.co_name 'say_hello'
co_varnamesIni adalah tuple yang berisi semua variabel lokal, termasuk argumen.
>>> say_hello.__code__.co_varnames ('name',)
co_contsSebuah tuple yang berisi semua nilai literal dan konstan yang kami akses di tubuh fungsi. Perlu dicatat nilai Tidak Ada. Kami tidak memasukkan Tidak Ada di tubuh fungsi, bagaimanapun, Python menunjukkannya, karena jika fungsi mulai mengeksekusi dan kemudian berakhir tanpa menerima nilai kembali, itu akan mengembalikan Tidak ada.
>>> say_hello.__code__.co_consts (None, 'Hello', 'How are you ', '?')
Bytecode (co_code)Berikut ini adalah bytecode dari fungsi kami.
>>> bytecode = say_hello.__code__.co_code >>> bytecode b't\x00d\x01|\x00\x83\x02\x01\x00t\x00d\x02|\x00\x9b\x00d\x03\x9d\x03\x83\x01\x01\x00d\x00S\x00'
Ini bukan string, ini adalah objek byte, yaitu urutan byte.
>>> type(bytecode) <class 'bytes'>
Karakter pertama yang dicetak adalah "t". Jika kami meminta nilai numeriknya, kami mendapatkan yang berikut ini.
>>> ord('t') 116
116 sama dengan bytecode [0].
>>> assert bytecode[0] == ord('t')
Bagi kami, nilai 116 tidak berarti apa-apa. Untungnya, Python menyediakan perpustakaan standar yang disebut dis (from disassembly). Ini berguna saat bekerja dengan daftar opname. Ini adalah daftar semua instruksi bytecode, di mana setiap indeks adalah nama instruksi.
>>> dis.opname[ord('t')] 'LOAD_GLOBAL'
Mari kita buat fungsi lain yang lebih kompleks.
>>> def multiple_it(a: int): ... if a % 2 == 0: ... return 0 ... return a * 2 ... >>> multiple_it(6) 0 >>> multiple_it(7) 14 >>> bytecode = multiple_it.__code__.co_code
Dan kami menemukan instruksi pertama dalam bytecode.
>>> dis.opname[bytecode[0]] 'LOAD_FAST
Pernyataan LOAD_FAST terdiri dari dua elemen.
>>> dis.opname[bytecode[0]] + ' ' + dis.opname[bytecode[1]] 'LOAD_FAST <0>'
Instruksi Loadfast 0 terjadi untuk mencari nama variabel dalam sebuah tuple dan mendorong elemen dengan indeks nol ke dalam tuple dalam tumpukan eksekusi.
>>> multiple_it.__code__.co_varnames[bytecode[1]] 'a'
Kode kami dapat dibongkar menggunakan dis.dis dan mengonversi bytecode ke tampilan yang sudah dikenal. Di sini angka (2,3,4) adalah nomor baris. Setiap baris kode dalam Python diperluas sebagai seperangkat instruksi.
>>> dis.dis(multiple_it) 2 0 LOAD_FAST 0 (a) 2 LOAD_CONST 1 (2) 4 BINARY_MODULO 6 LOAD_CONST 2 (0) 8 COMPARE_OP 2 (==) 10 POP_JUMP_IF_FALSE 16 3 12 LOAD_CONST 2 (0) 14 RETURN_VALUE 4 >> 16 LOAD_FAST 0 (a) 18 LOAD_CONST 1 (2) 20 BINARY_MULTIPLY 22 RETURN_VALUE
Lead timeCPython adalah mesin virtual yang berorientasi pada tumpukan, bukan kumpulan register. Ini berarti bahwa kode Python dikompilasi untuk mesin virtual dengan arsitektur stack.
Saat memanggil fungsi, Python menggunakan dua tumpukan bersamaan. Yang pertama adalah tumpukan eksekusi, dan yang kedua adalah tumpukan blok. Sebagian besar panggilan terjadi pada tumpukan eksekusi; tumpukan blok melacak berapa banyak blok yang aktif saat ini, serta parameter lain yang terkait dengan blok dan cakupan.
Kami menantikan komentar Anda tentang materi dan mengundang Anda ke
webinar terbuka tentang topik: "Lepaskan: aspek praktis dari merilis perangkat lunak yang dapat diandalkan", yang akan dilakukan oleh guru kami, pemrogram sistem iklan di Mail.Ru,
Stanislav Stupnikov .