Mengetahui hanya satu pendekatan untuk pengikisan web memecahkan masalah dalam jangka pendek, tetapi semua metode memiliki kekuatan dan kelemahannya. Kesadaran akan hal ini menghemat waktu dan membantu menyelesaikan masalah dengan lebih efisien.

Banyak sumber berbicara tentang satu-satunya metode yang benar untuk mengambil data dari halaman web. Tetapi kenyataannya adalah bahwa untuk ini Anda dapat menggunakan beberapa solusi dan alat.
- Apa sajakah opsi untuk mengambil data dari suatu halaman web secara terprogram?
- Pro dan kontra dari setiap pendekatan?
- Bagaimana cara menggunakan sumber daya cloud untuk meningkatkan tingkat otomatisasi?
Artikel ini akan membantu mendapatkan jawaban atas pertanyaan-pertanyaan ini.
Saya berasumsi bahwa Anda sudah tahu apa permintaan
HTTP ,
DOM (Document Object Model),
HTML ,
pemilih CSS dan
JavaScript Async .
Jika tidak, saya menyarankan Anda untuk mempelajari teorinya, dan kemudian kembali ke artikel.
Konten statis
Sumber HTMLMari kita mulai dengan pendekatan yang paling sederhana.
Jika Anda berencana untuk memo halaman web, ini adalah hal pertama yang dimulai. Ini akan membutuhkan daya komputer yang kecil dan waktu minimum.
Namun, ini hanya berfungsi jika kode sumber HTML berisi data yang Anda targetkan. Untuk mengujinya di Chrome, klik kanan pada halaman dan pilih Lihat Halaman Kode. Anda sekarang harus melihat kode sumber HTML.
Setelah Anda menemukan datanya, tulis
pemilih CSS yang termasuk dalam elemen pembungkus sehingga Anda memiliki tautan nanti.
Untuk implementasi, Anda dapat mengirim permintaan GET HTTP ke URL halaman dan mendapatkan kode sumber HTML kembali.
Di
Node, Anda bisa menggunakan alat
CheerioJS untuk
mem -
parsing HTML mentah dan mengambil data menggunakan pemilih. Kode akan terlihat seperti ini:
const fetch = require('node-fetch'); const cheerio = require('cheerio'); const url = 'https://example.com/'; const selector = '.example'; fetch(url) .then(res => res.text()) .then(html => { const $ = cheerio.load(html); const data = $(selector); console.log(data.text()); });
Konten dinamis
Dalam banyak kasus, Anda tidak dapat mengakses informasi dari kode HTML mentah karena DOM dikendalikan oleh JavaScript yang berjalan di latar belakang. Contoh khas dari ini adalah SPA (aplikasi satu halaman), di mana dokumen HTML berisi informasi minimal dan JavaScript mengisinya saat run time.
Dalam situasi ini, solusinya adalah membuat DOM dan menjalankan skrip yang terletak di kode sumber HTML, seperti browser. Setelah itu, data dapat diekstraksi dari objek ini menggunakan penyeleksi.
Browser Tanpa KepalaBrowser tanpa kepala sama dengan browser biasa, hanya tanpa antarmuka pengguna. Ini berjalan di latar belakang, dan Anda dapat mengontrolnya secara terprogram alih-alih mengklik dan mengetik dari keyboard.
Dalang adalah salah satu browser tanpa kepala paling populer. Ini adalah Node library yang mudah digunakan yang menyediakan API tingkat tinggi untuk mengelola Chrome offline. Dapat dikonfigurasi untuk berjalan tanpa header, yang sangat nyaman selama pengembangan. Kode berikut melakukan hal yang sama seperti sebelumnya, tetapi akan berfungsi dengan halaman dinamis:
const puppeteer = require('puppeteer'); async function getData(url, selector){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); const data = await page.evaluate(selector => { return document.querySelector(selector).innerText; }, selector); await browser.close(); return data; } const url = 'https://example.com'; const selector = '.example'; getData(url,selector) .then(result => console.log(result));
Tentu saja, Anda dapat melakukan lebih banyak hal menarik dengan Puppeteer, jadi periksalah
dokumentasinya . Berikut cuplikan kode yang menavigasi URL, mengambil tangkapan layar, dan menyimpannya:
const puppeteer = require('puppeteer'); async function takeScreenshot(url,path){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); await page.screenshot({path: path}); await browser.close(); } const url = 'https://example.com'; const path = 'example.png'; takeScreenshot(url, path);
Browser membutuhkan daya komputasi yang lebih besar daripada mengirimkan permintaan GET sederhana dan menganalisis respons. Karena itu, pelaksanaannya relatif lambat. Tidak hanya itu, tetapi juga menambahkan peramban sebagai ketergantungan membuat paket ini luar biasa.
Di sisi lain, metode ini sangat fleksibel. Anda dapat menggunakannya untuk menavigasi halaman, mensimulasikan klik, gerakan mouse dan menggunakan keyboard, mengisi formulir, membuat screenshot atau membuat halaman PDF, menjalankan perintah di konsol, memilih item untuk mengekstraksi konten teks. Pada dasarnya, semua itu bisa dilakukan secara manual di browser.
Membangun DOMAnda akan berpikir bahwa tidak perlu mensimulasikan keseluruhan browser hanya untuk membuat DOM. Sebenarnya, ini benar, setidaknya dalam keadaan tertentu.
Jsdom adalah perpustakaan Node yang mem-parsing HTML yang sedang dikirim, sama seperti browser. Namun, ini bukan browser, tetapi
alat untuk membangun DOM dari kode sumber HTML yang diberikan , serta untuk mengeksekusi kode JavaScript dalam HTML ini.
Berkat abstraksi ini, Jsdom dapat berjalan lebih cepat daripada browser tanpa kepala. Jika lebih cepat, mengapa tidak menggunakannya daripada browser tanpa kepala sepanjang waktu?
Kutipan dari dokumentasi :
Orang sering mengalami masalah dengan memuat skrip asinkron saat menggunakan jsdom. Banyak halaman memuat skrip secara tidak sinkron, tetapi tidak mungkin untuk menentukan kapan ini terjadi, dan karenanya kapan harus menjalankan kode dan memeriksa struktur DOM yang dihasilkan. Ini adalah batasan mendasar.
Solusi ini ditunjukkan dalam contoh. Setiap 100 ms, diperiksa apakah elemen telah muncul atau timeout telah terjadi (setelah 2 detik).
Itu juga sering memberikan pesan kesalahan ketika Jsdom tidak mengimplementasikan beberapa fitur browser pada halaman, seperti: "
Kesalahan: Tidak diterapkan: window.alert ..." atau "Kesalahan: Tidak diterapkan: window.scrollTo ... ". Masalah ini juga dapat diselesaikan dengan beberapa solusi (
konsol virtual ).
Ini biasanya API tingkat lebih rendah dari Puppeteer, jadi Anda perlu mengimplementasikan beberapa hal sendiri.
Ini mempersulit penggunaannya, seperti yang bisa dilihat dari contoh.
Jsdom menawarkan solusi cepat untuk pekerjaan yang sama.
Mari kita lihat contoh yang sama, tetapi menggunakan
Jsdom :
const jsdom = require("jsdom"); const { JSDOM } = jsdom; async function getData(url,selector,timeout) { const virtualConsole = new jsdom.VirtualConsole(); virtualConsole.sendTo(console, { omitJSDOMErrors: true }); const dom = await JSDOM.fromURL(url, { runScripts: "dangerously", resources: "usable", virtualConsole }); const data = await new Promise((res,rej)=>{ const started = Date.now(); const timer = setInterval(() => { const element = dom.window.document.querySelector(selector) if (element) { res(element.textContent); clearInterval(timer); } else if(Date.now()-started > timeout){ rej("Timed out"); clearInterval(timer); } }, 100); }); dom.window.close(); return data; } const url = "https://example.com/"; const selector = ".example"; getData(url,selector,2000).then(result => console.log(result));
Rekayasa terbalikJsdom adalah solusi cepat dan mudah, tetapi Anda bisa membuatnya lebih sederhana.
Apakah kita perlu memodelkan DOM?
Halaman web yang ingin Anda memo terdiri dari HTML dan JavaScript yang sama, teknologi yang sama yang sudah Anda ketahui. Jadi,
jika Anda menemukan sepotong kode dari mana data target diperoleh, Anda dapat mengulangi operasi yang sama untuk mendapatkan hasil yang sama .
Untuk mempermudah, data yang Anda cari bisa berupa:
- bagian dari kode sumber HTML (seperti yang dapat dilihat dari bagian pertama artikel),
- bagian dari file statis yang dirujuk dalam dokumen HTML (misalnya, baris dalam file javascript),
- menanggapi permintaan jaringan (misalnya, beberapa kode JavaScript mengirim permintaan AJAX ke server yang merespons dengan string JSON).
Sumber data ini dapat diakses menggunakan kueri jaringan . Tidak masalah jika halaman web menggunakan HTTP, WebSockets, atau protokol komunikasi lainnya, karena semuanya direproduksi secara teori.
Setelah Anda menemukan sumber daya yang berisi data, Anda dapat mengirim permintaan jaringan yang sama ke server yang sama dengan halaman asli. Akibatnya, Anda akan mendapatkan jawaban yang berisi data target, yang dapat dengan mudah diekstraksi menggunakan ekspresi reguler, metode string, JSON.parse, dll.
Dengan kata sederhana, Anda dapat mengambil sumber daya tempat data berada, alih-alih memproses dan memuat semua materi. Dengan demikian, masalah yang ditunjukkan pada contoh sebelumnya dapat diselesaikan dengan permintaan HTTP tunggal alih-alih mengendalikan browser atau objek JavaScript yang kompleks.
Secara teori, solusi ini tampaknya sederhana, tetapi dalam banyak kasus ini dapat memakan waktu dan membutuhkan pengalaman dengan halaman web dan server.
Mulailah dengan memonitor lalu lintas jaringan. Alat hebat untuk ini adalah tab
Jaringan di Chrome DevTools . Anda akan melihat semua permintaan keluar dengan jawaban (termasuk file statis, permintaan AJAX, dll.) Untuk mengulanginya dan mencari data.
Jika jawabannya diubah oleh kode apa pun sebelum ditampilkan di layar, prosesnya akan lebih lambat. Dalam hal ini, Anda harus menemukan bagian kode ini dan memahami apa yang sedang terjadi.
Seperti yang Anda lihat, metode seperti itu mungkin membutuhkan lebih banyak pekerjaan daripada metode yang dijelaskan di atas. Di sisi lain, ini memberikan kinerja terbaik.
Diagram menunjukkan runtime dan ukuran paket yang diperlukan dibandingkan dengan Jsdom dan Puppeteer:
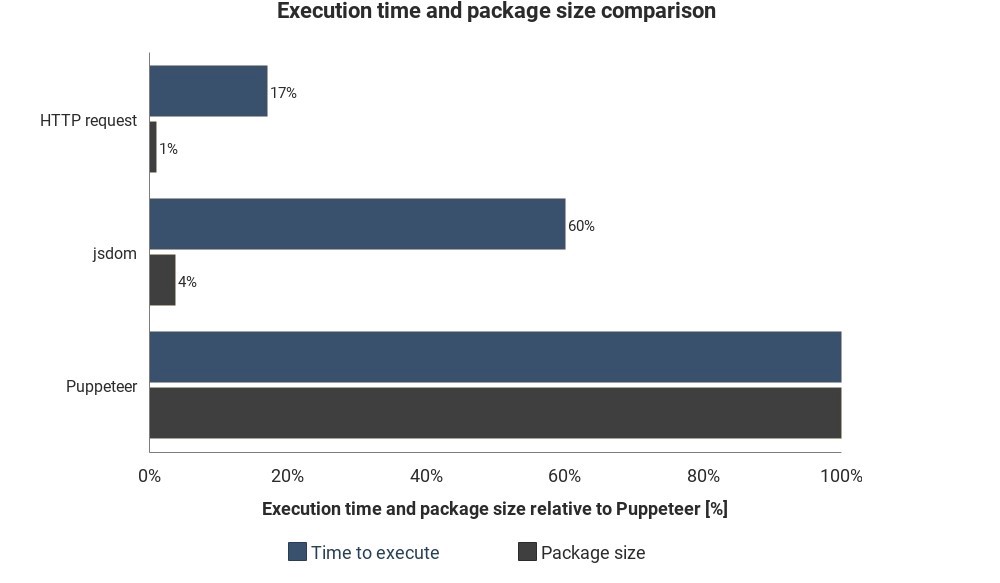
Hasilnya tidak didasarkan pada pengukuran yang akurat dan dapat bervariasi, tetapi menunjukkan perbedaan perkiraan yang baik antara metode ini.
Integrasi layanan cloud
Misalkan Anda telah menerapkan salah satu solusi ini. Salah satu cara untuk menjalankan skrip adalah dengan menyalakan komputer, buka terminal dan mulai secara manual.
Tapi itu akan menjadi menjengkelkan dan tidak efisien, jadi akan lebih baik jika Anda bisa mengunggah skrip ke server dan itu akan mengeksekusi kode secara teratur tergantung pada pengaturan.
Ini dapat dilakukan dengan memulai server yang sebenarnya dan menetapkan aturan kapan harus menjalankan skrip. Dalam kasus lain, fungsi cloud adalah cara yang lebih mudah.
Fungsi cloud adalah penyimpanan yang dirancang untuk mengeksekusi kode yang diunduh ketika suatu peristiwa terjadi. Ini berarti Anda tidak perlu mengelola server, ini dilakukan secara otomatis oleh penyedia cloud Anda.
Pemicu dapat berupa jadwal, permintaan jaringan, dan banyak acara lainnya. Anda dapat menyimpan data yang dikumpulkan dalam database, menulisnya ke
lembar Google atau mengirimnya melalui
email . Itu semua tergantung pada imajinasi Anda.
Penyedia cloud populer -
Amazon Web Services (AWS),
Google Cloud Platform (GCP) dan
Microsoft Azure :
Anda dapat menggunakan layanan ini secara gratis, tetapi tidak lama.
Jika Anda menggunakan Puppeteer,
fitur Google Cloud adalah solusi termudah. Ukuran paket dalam format Chrome Tanpa Kepala (~ 130 MB) melebihi ukuran arsip maksimum yang diizinkan dalam AWS Lambda (50 MB). Ada beberapa metode untuk membuatnya berfungsi dengan Lambda, tetapi fungsi GCP secara default
mendukung Chrome tanpa header , Anda hanya perlu memasukkan Puppeteer sebagai ketergantungan dalam
package.json .
Jika Anda ingin mempelajari lebih lanjut tentang fitur cloud secara umum, lihat informasi arsitektur tanpa server. Banyak tutorial yang baik telah ditulis tentang topik ini, dan sebagian besar penyedia memiliki dokumentasi yang mudah dipahami.