
Apa yang paling membuat Anda marah ketika Anda mencoba mengatur log yang dapat dibaca di aplikasi NodeJS Anda? Secara pribadi, saya sangat kesal dengan kurangnya standar matang waras untuk membuat jejak ID. Dalam artikel ini, kita akan berbicara tentang opsi untuk membuat ID jejak, mari kita lihat bagaimana penyimpanan lokal-kelanjutan atau CLS bekerja pada jari kita dan memanggil kekuatan Proxy untuk mendapatkan semuanya dengan logger apa pun.
Mengapa ada masalah di NodeJS dengan membuat ID jejak untuk setiap permintaan?
Di masa lalu, dulu, dulu, ketika mammoth masih hidup di bumi, semua-semua-server semuanya multi-threaded dan membuat utas baru untuk permintaan. Dalam kerangka paradigma ini, membuat jejak ID adalah sepele, karena ada yang namanya penyimpanan thread-local atau TLS , yang memungkinkan Anda untuk memasukkan ke dalam memori beberapa data yang tersedia untuk fungsi apa pun dalam aliran ini. Pada awal memproses permintaan, Anda dapat menebus ID jejak acak, memasukkannya ke TLS dan kemudian membacanya di layanan apa pun dan melakukan sesuatu dengannya. Masalahnya adalah ini tidak akan berfungsi di NodeJS.
NodeJS adalah single-threaded (tidak cukup, mengingat penampilan pekerja, tetapi dalam kerangka masalah dengan jejak ID, pekerja tidak memainkan peran apa pun), sehingga Anda dapat melupakan TLS. Di sini paradigma berbeda - untuk menyulap sekelompok panggilan balik yang berbeda dalam utas yang sama, dan segera setelah fungsi ingin melakukan sesuatu yang tidak sinkron, kirim permintaan asinkron ini, dan berikan waktu prosesor ke fungsi lain dalam antrian (jika Anda tertarik pada bagaimana hal ini, dengan bangga disebut Perulangan Acara bekerja) di bawah tenda, saya sarankan membaca seri artikel ini ). Jika Anda berpikir tentang bagaimana NodeJS memahami panggilan balik yang akan dipanggil saat itu, Anda dapat berasumsi bahwa masing-masing dari mereka harus sesuai dengan beberapa ID. Selain itu, NodeJS bahkan memiliki API yang menyediakan akses ke ID ini. Kami akan menggunakannya.
Pada zaman kuno, ketika mamut menjadi punah, tetapi orang-orang masih tidak tahu manfaat dari pembuangan limbah pusat, (NodeJS v0.11.11) kami memiliki addAsyncListener . Berdasarkan itu, Forrest Norvell menciptakan implementasi pertama penyimpanan lokal-berkelanjutan atau CLS . Tapi kami tidak akan berbicara tentang cara kerjanya, karena API ini (saya sedang berbicara tentang addAsyncLustener) memesan umur yang panjang. Dia sudah mati di NodeJS v0.12.
Sebelum NodeJS 8, tidak ada cara resmi untuk melacak antrian acara asinkron. Dan akhirnya, di versi 8, pengembang NodeJS memulihkan keadilan dan memberi kami async_hooks API . Jika Anda ingin mempelajari lebih lanjut tentang async_hooks, saya sarankan Anda membaca artikel ini . Berdasarkan async_hooks, refactoring dari implementasi CLS sebelumnya telah dilakukan. Perpustakaan disebut cls-doyan .
CLS di bawah tenda
Secara umum, skema operasi CLS dapat direpresentasikan sebagai berikut:
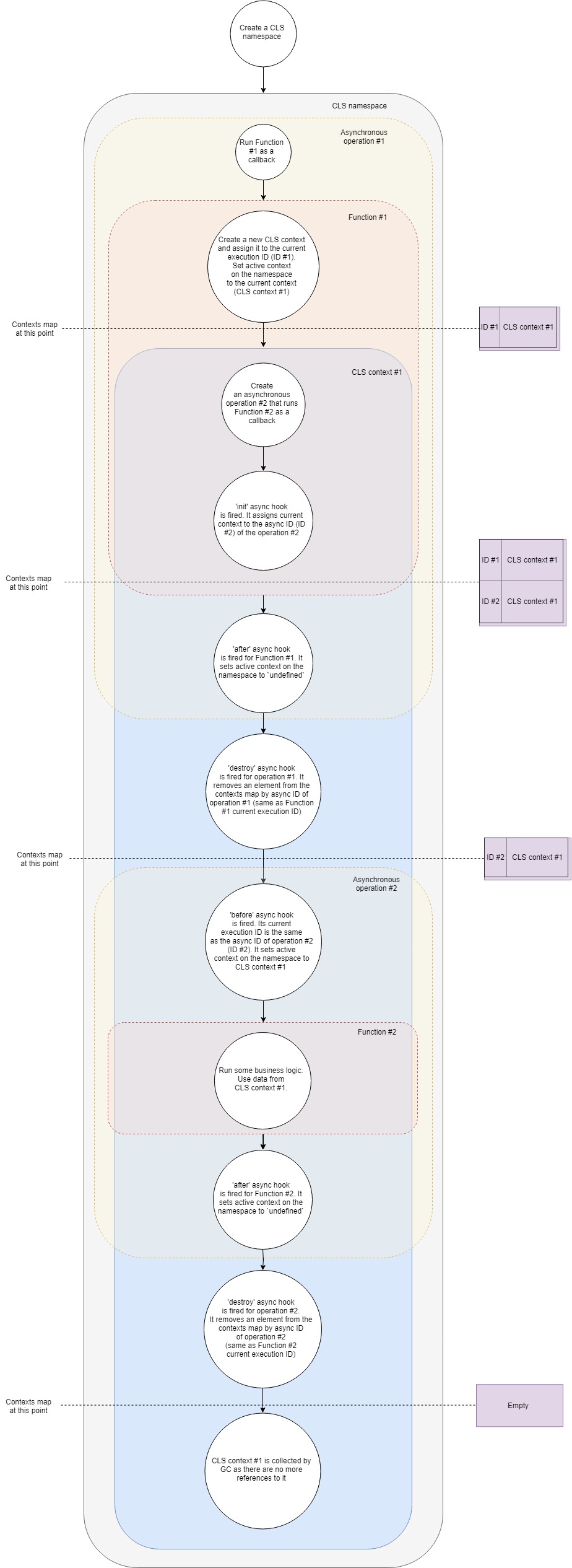
Mari kita sedikit lebih detail:
- Misalkan kita memiliki server web Express yang khas. Pertama, buat namespace CLS baru. Sekali dan untuk seumur hidup aplikasi.
- Kedua, kami akan membuat middleware, yang akan membuat konteks CLS kami sendiri untuk setiap permintaan.
- Ketika permintaan baru tiba, middleware ini (Fungsi # 1) dipanggil.
- Dalam fungsi ini, buat konteks CLS baru (sebagai satu opsi, Anda dapat menggunakan Namespace.run ). Di Namespace.run kita melewati fungsi yang akan dieksekusi dalam lingkup konteks kita.
- CLS menambahkan konteks yang baru dibuat ke Peta dengan konteks dengan kunci ID eksekusi saat ini .
- Setiap namespace CLS memiliki properti
active . CLS memberikan properti ini referensi untuk konteks kami. - Dalam lingkup konteks, kami membuat beberapa jenis permintaan asinkron, misalnya, ke database. Kami meneruskan panggilan balik ke driver database, yang akan dipanggil ketika permintaan selesai.
- Init hook asinkron menyala . Ini menambahkan konteks saat ini ke Peta dengan konteks oleh ID async (ID dari operasi asinkron baru).
- Karena fungsi kami tidak lagi memiliki instruksi tambahan, ia menyelesaikan eksekusi.
- Asinkron setelah kait berfungsi untuknya. Ini memberikan properti
active ke namespace undefined (pada kenyataannya, tidak selalu, karena kita dapat memiliki beberapa konteks bersarang, tetapi untuk kasus yang paling sederhana). - Menghancurkan kait asinkron yang menyala untuk operasi asinkron pertama kami. Ini menghapus konteks dari Peta dengan konteks dengan ID async dari operasi ini (sama dengan ID eksekusi saat ini dari panggilan balik pertama).
- Permintaan dalam database selesai dan panggilan balik kedua disebut.
- Kait asinkron sebelumnya . ID eksekusi saat ini sama dengan ID async dari operasi kedua (permintaan basis data). Properti
active namespace diberikan konteks yang ditemukan di Peta dengan konteks dengan ID eksekusi saat ini. Ini adalah konteks yang kami buat sebelumnya. - Sekarang panggilan balik kedua dijalankan. Semacam logika bisnis berhasil, setan menari, vodka mengalir. Di dalam ini, kita bisa mendapatkan nilai apa pun dari konteks dengan kunci . CLS akan mencoba menemukan kunci yang diberikan dalam konteks saat ini atau mengembalikan yang
undefined . - Hook setelah asinkron untuk panggilan balik ini dipicu saat selesai. Ini mengatur properti
active namespace menjadi undefined . - Hancurkan kait asinkron yang menyala untuk operasi ini. Ini menghapus konteks dari Peta dengan konteks dengan ID async dari operasi ini (sama dengan ID eksekusi saat ini dari callback kedua).
- Pengumpul sampah (GC) membebaskan memori yang terkait dengan objek konteks, karena dalam aplikasi kami tidak ada lagi tautan ke sana.
Ini adalah pandangan yang disederhanakan dari apa yang terjadi di bawah tenda, tetapi mencakup fase dan langkah utama. Jika Anda memiliki keinginan untuk menggali lebih dalam, saya sarankan Anda membiasakan diri dengan jenis - jenis itu . Hanya ada 500 baris kode.
Buat jejak ID
Jadi, setelah berurusan dengan CLS, kami akan mencoba menggunakan hal ini untuk kepentingan kemanusiaan. Mari kita membuat middleware, yang untuk setiap permintaan membuat konteks CLS sendiri, membuat ID jejak acak dan menambahkannya ke konteks menggunakan traceID kunci. Kemudian di dalam ofigilliard pengendali dan layanan kami, kami mendapatkan ID jejak ini.
Untuk ekspres, middleware serupa mungkin terlihat seperti ini:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsNamespace = cls.createNamespace('app') const clsMiddleware = (req, res, next) => {
Dan di pengontrol atau layanan kami, kami bisa mendapatkan traceID ini hanya dalam satu baris kode:
const controller = (req, res, next) => { const traceID = clsNamespace.get('traceID') }
Benar, tanpa menambahkan jejak ID ini ke log, itu manfaat dari itu, seperti dari peniup salju di musim panas.
Mari kita menulis formatter winston sederhana yang akan menambahkan jejak ID secara otomatis.
const { createLogger, format, transports } = require('winston') const addTraceId = printf((info) => { let message = info.message const traceID = clsNamespace.get('taceID') if (traceID) { message = `[TraceID: ${traceID}]: ${message}` } return message }) const logger = createLogger({ format: addTraceId, transports: [new transports.Console()], })
Dan jika semua penebang mendukung formatter kustom dalam bentuk fungsi (banyak dari mereka memiliki alasan untuk tidak melakukan ini), maka artikel ini mungkin tidak akan terjadi. Jadi bagaimana Anda bisa menambahkan jejak jejak ke log dari pino yang dipuja?
Kami memanggil Proxy untuk mendapatkan teman logger dan CLS APAPUN
Beberapa kata tentang Proxy sendiri: ini adalah sesuatu yang membungkus objek asli kita dan memungkinkan kita untuk mendefinisikan kembali perilakunya dalam situasi tertentu. Dalam daftar terbatas situasi yang didefinisikan secara ketat (dalam sains mereka disebut traps ). Anda dapat menemukan daftar lengkapnya di sini , kami hanya tertarik pada jebakan get . Ini memberi kita kesempatan untuk mengganti nilai kembali saat mengakses properti objek, mis. jika kita mengambil objek const a = { prop: 1 } dan membungkusnya dalam Proxy, maka dengan bantuan trap kita dapat mengembalikan semua yang kita suka ketika mengakses a.prop .
Dalam kasus pino idenya adalah ini: kita membuat ID jejak acak untuk setiap permintaan, membuat instance anak pino di mana kita melewati ID jejak ini, dan menempatkan instance anak ini di CLS. Kemudian kami membungkus logger sumber kami di Proxy, yang akan menggunakan turunan turunan yang sama ini untuk mencatat jika ada konteks aktif dan ada logger turunan di dalamnya, atau menggunakan logger asli.
Untuk kasus seperti itu, proksi akan terlihat seperti ini:
const pino = require('pino') const logger = pino() const loggerCls = new Proxy(logger, { get(target, property, receiver) {
Middleware kami akan terlihat seperti ini:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsMiddleware = (req, res, next) => {
Dan kita bisa menggunakan logger seperti ini:
const controller = (req, res, next) => { loggerCls.info('Long live rocknroll!')
Berdasarkan ide di atas, perpustakaan kecil cls-proxify telah dibuat. Dia bekerja di luar kotak dengan express , koa , dan fastify . Selain membuat jebakan untuk get , itu membuat jebakan lain untuk memberi pengembang lebih banyak kebebasan. Karena itu, kita dapat menggunakan Proxy untuk membungkus fungsi, kelas, dan banyak lagi. Ada demo langsung tentang cara mengintegrasikan pino dan fastify, pino dan express .
Saya harap Anda tidak membuang waktu dengan sia-sia, dan artikel itu setidaknya sedikit bermanfaat bagi Anda. Tolong tendang dan kritik. Kami akan belajar kode lebih baik bersama.