Halo, Habr! Saya membawa kepada Anda terjemahan dari artikel oleh Rudy Gilman dan Katherine Wang Intuitive RL: Intro to Advantage-Actor-Critic (A2C) .

Reinforced Learning Specialists (RL) telah menghasilkan banyak tutorial yang luar biasa. Namun, sebagian besar menggambarkan RL dalam hal persamaan matematika dan diagram abstrak. Kami suka berpikir tentang subjek dari perspektif yang berbeda. RL sendiri terinspirasi oleh bagaimana hewan belajar, jadi mengapa tidak menerjemahkan mekanisme RL yang mendasarinya kembali ke fenomena alam yang dimaksudkan untuk disimulasikan? Orang belajar dengan baik melalui cerita.
Ini adalah kisah model Actor Advantage Critic (A2C). Model subjek-kritik adalah bentuk populer dari model Gradient Kebijakan, yang dengan sendirinya adalah algoritma RL tradisional. Jika Anda memahami A2C, Anda memahami RL dalam.
Setelah Anda mendapatkan pemahaman A2C yang intuitif, periksa:
Ilustrasi @embermarke
Dalam RL, agen, rubah Klyukovka, bergerak melalui negara-negara yang dikelilingi oleh tindakan, mencoba untuk memaksimalkan hadiah selama perjalanan.
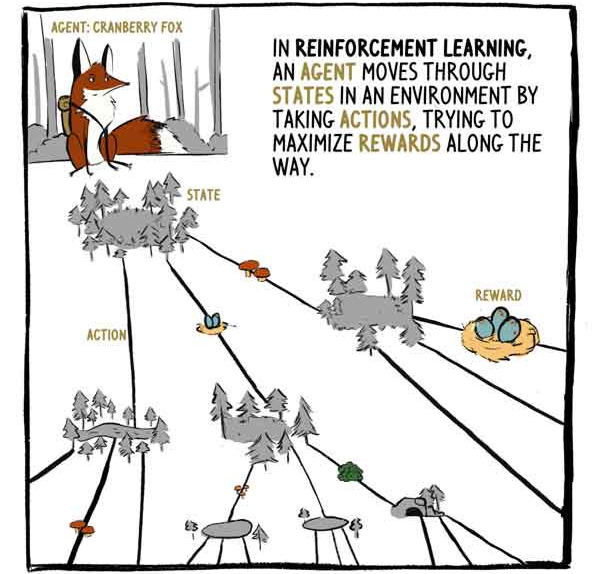
A2C menerima input status - input sensor dalam kasus Klukovka - dan menghasilkan dua output:
1) Penilaian terhadap berapa banyak remunerasi yang akan diterima, mulai dari saat keadaan saat ini, dengan pengecualian dari remunerasi saat ini (yang ada).
2) Rekomendasi tentang tindakan apa yang harus diambil (kebijakan).
Critic: wow, lembah yang luar biasa! Ini akan menjadi hari yang bermanfaat untuk mencari makan! Saya bertaruh hari ini saya akan mengumpulkan 20 poin sebelum matahari terbenam.
"Subjek": bunga-bunga ini terlihat indah, saya merasakan keinginan untuk "A".

Model Deep RL adalah mesin pemetaan input-output, seperti model klasifikasi atau regresi lainnya. Alih-alih mengkategorikan gambar atau teks, model RL yang mendalam membawa status ke tindakan dan / atau menyatakan ke nilai-nilai status. A2C melakukan keduanya.


Himpunan tindakan negara ini merupakan satu pengamatan. Dia akan menulis baris data ini ke jurnalnya, tetapi dia belum akan memikirkannya. Dia akan mengisinya ketika dia berhenti berpikir.
Beberapa penulis mengasosiasikan hadiah 1 dengan langkah waktu 1, yang lain mengaitkannya dengan langkah 2, tetapi semua memiliki konsep yang sama: hadiah dikaitkan dengan negara, dan tindakan segera mendahuluinya.

Hooking mengulangi proses itu lagi. Pertama, dia melihat sekelilingnya dan mengembangkan fungsi V (S) dan rekomendasi untuk tindakan.
Critic: Lembah ini terlihat sangat standar. V (S) = 19.
Subjek: Opsi untuk tindakan terlihat sangat mirip. Saya pikir saya hanya akan pergi ke jalur "C".
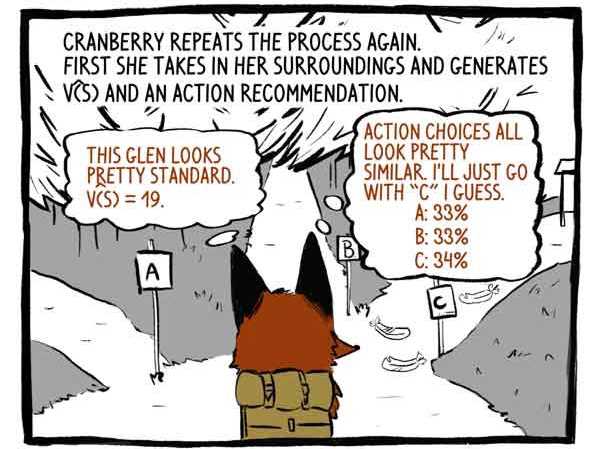
Maka itu bertindak.

Menerima hadiah +20! Dan mencatat pengamatannya.

Dia mengulangi proses itu lagi.

Setelah mengumpulkan tiga pengamatan, Klyukovka berhenti untuk berpikir.
Keluarga model lain menunggu sampai akhir hari (Monte Carlo), sementara yang lain berpikir setelah setiap langkah (satu langkah).
Sebelum dapat mengatur kritik internalnya, Klukovka perlu menghitung berapa banyak poin yang akan ia terima di setiap negara bagian.
Tapi pertama!
Mari kita lihat bagaimana sepupu Klukovka, Lis Monte Carlo, menghitung arti sebenarnya dari masing-masing negara.
Model Monte Carlo tidak mencerminkan pengalaman mereka sampai akhir permainan, dan karena nilai kondisi terakhir adalah nol, sangat mudah untuk menemukan nilai sebenarnya dari kondisi sebelumnya sebagai jumlah hadiah yang diterima setelah momen ini.
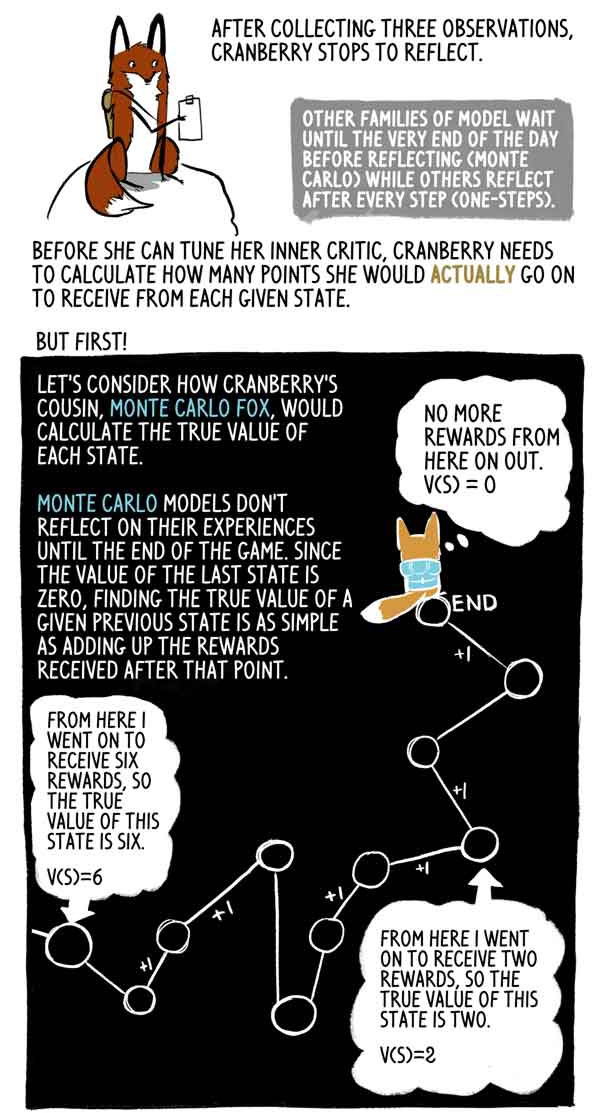
Bahkan, ini hanya sampel dispersi tinggi V (S). Agen dapat dengan mudah mengikuti lintasan yang berbeda dari negara yang sama, sehingga menerima hadiah agregat yang berbeda.
Tapi Klyukovka pergi, berhenti dan berefleksi berkali-kali sampai hari berakhir. Dia ingin tahu berapa banyak poin yang akan dia dapatkan dari setiap negara bagian hingga akhir pertandingan, karena ada beberapa jam tersisa hingga akhir pertandingan.
Di situlah dia melakukan sesuatu yang sangat cerdas - rubah Klyukovka memperkirakan berapa banyak poin yang akan dia terima untuk keadaan terakhir dalam set ini. Untungnya, ia memiliki penilaian yang benar tentang kondisinya - kritiknya.
Dengan penilaian ini, Klyukovka dapat menghitung nilai "benar" dari negara-negara sebelumnya persis seperti yang dilakukan rubah Monte Carlo.
Lis Monte Carlo mengevaluasi tanda target, membuat penyebaran lintasan dan menambahkan hadiah ke depan dari masing-masing negara. A2C memotong lintasan ini dan menggantinya dengan penilaian kritiknya. Beban awal ini mengurangi varian skor dan memungkinkan A2C berjalan terus menerus, meskipun dengan memperkenalkan bias kecil.

Hadiah sering dikurangi untuk mencerminkan fakta bahwa remunerasi sekarang lebih baik daripada di masa depan. Untuk mempermudah, Klukovka tidak mengurangi imbalannya.

Klukovka sekarang dapat melalui setiap baris data dan membandingkan perkiraan nilai-nilai negara dengan nilai-nilai aktualnya. Dia menggunakan perbedaan antara angka-angka ini untuk menyempurnakan keterampilan prediksinya. Setiap tiga langkah sepanjang hari, Klyukovka mengumpulkan pengalaman berharga yang patut dipertimbangkan.
“Saya memberi nilai buruk pada peringkat 1 dan 2. Apa yang saya lakukan salah? Ya! Lain kali saya melihat bulu seperti ini, saya akan meningkatkan V (S).
Tampaknya gila bahwa Klukovka dapat menggunakan peringkat V (S) sebagai dasar untuk membandingkannya dengan perkiraan lainnya. Tetapi hewan (termasuk kita) melakukan ini setiap saat! Jika Anda merasa segalanya berjalan baik, Anda tidak perlu melatih kembali tindakan yang membawa Anda ke keadaan ini.

Dengan memangkas output yang dihitung dan menggantinya dengan estimasi beban awal, kami mengganti varians Monte Carlo yang besar dengan bias yang kecil. Model RL biasanya menderita dispersi tinggi (mewakili semua jalur yang mungkin), dan penggantian seperti itu biasanya sepadan.
Klukovka mengulangi proses ini sepanjang hari, mengumpulkan tiga pengamatan tentang tindakan-tindakan-negara dan merefleksikannya.
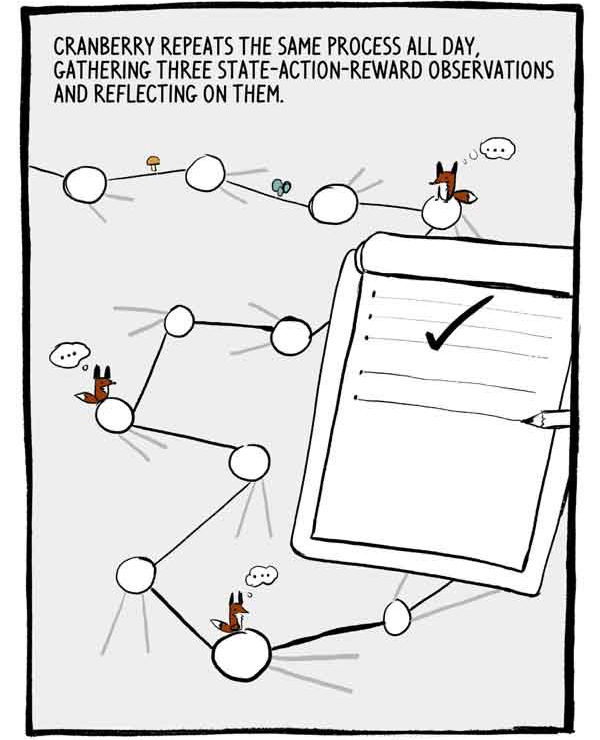
Setiap rangkaian dari tiga pengamatan adalah serangkaian kecil data pelatihan berlabel yang terkait secara otokorelasi. Untuk mengurangi autokorelasi ini, banyak A2C melatih banyak agen secara paralel, menambahkan pengalaman mereka bersama sebelum mengirimnya ke jaringan saraf umum.

Hari akhirnya akan berakhir. Tinggal dua langkah lagi.
Seperti yang kami katakan sebelumnya, rekomendasi tindakan Klukovka dinyatakan dalam persentase keyakinan tentang kemampuannya. Alih-alih hanya memilih pilihan yang paling dapat diandalkan, Klukovka memilih dari distribusi tindakan ini. Ini memastikan bahwa dia tidak selalu setuju dengan tindakan yang aman, tetapi berpotensi tindakan biasa-biasa saja.
Saya bisa menyesalinya, tapi ... Kadang-kadang, menjelajahi hal-hal yang tidak diketahui, Anda bisa datang ke penemuan baru yang menarik ...

Untuk lebih mendorong penelitian, nilai yang disebut entropi dikurangi dari fungsi kerugian. Entropi berarti "ruang lingkup" dari distribusi tindakan.
- Tampaknya permainan telah terbayar!

Atau tidak?
Terkadang agen berada dalam kondisi di mana semua tindakan mengarah pada hasil negatif. Namun, A2C dapat mengatasi situasi buruk dengan baik.


Ketika matahari terbenam, Klyukovka merenungkan serangkaian solusi terakhir.

Kami berbicara tentang bagaimana Klyukovka mengatur kritik batinnya. Tetapi bagaimana ia menyempurnakan “subjek” batinnya? Bagaimana dia belajar membuat pilihan yang begitu indah?
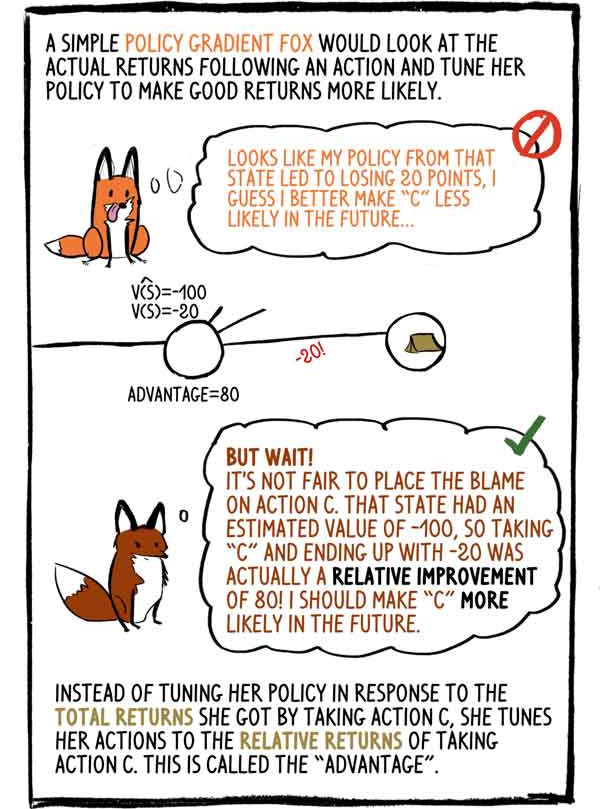
Kebijakan Gradien rubah yang berpikiran sederhana akan melihat pendapatan yang sebenarnya setelah tindakan dan menyesuaikan kebijakannya untuk membuat pendapatan yang baik lebih mungkin: - Tampaknya kebijakan saya di negara ini menyebabkan hilangnya 20 poin, saya pikir di masa depan lebih baik melakukan "C" kecil kemungkinannya.
- Tapi tunggu! Tidak adil untuk menyalahkan tindakan "C". Status ini memiliki nilai estimasi -100, jadi memilih "C" dan diakhiri dengan -20 sebenarnya merupakan peningkatan relatif 80! Saya harus membuat "C" lebih mungkin di masa depan.
Alih-alih menyesuaikan kebijakannya dalam menanggapi total pendapatan yang diterima dengan memilih tindakan C, ia menyesuaikan tindakannya dengan pendapatan relatif dari tindakan C. Ini disebut “keuntungan”.
Apa yang kami sebut keuntungan hanyalah kesalahan. Sebagai keuntungan, Klukovka menggunakannya untuk membuat kegiatan yang ternyata bagus, lebih mungkin. Sebagai kesalahan, dia menggunakan jumlah yang sama untuk mendorong kritik internalnya untuk meningkatkan penilaiannya terhadap nilai status.
Subjek mengambil keuntungan dari:
- "Wow, itu bekerja lebih baik daripada yang saya kira, tindakan C pasti ide yang bagus."
Pengkritik menggunakan kesalahan:
“Tapi mengapa aku terkejut? Saya mungkin seharusnya tidak mengevaluasi kondisi ini secara negatif. "
Sekarang kami dapat menunjukkan bagaimana total kerugian dihitung - kami meminimalkan fungsi ini untuk meningkatkan model kami.
“Total kerugian = kehilangan tindakan + kehilangan nilai - entropi”
Harap perhatikan bahwa untuk menghitung gradien dari tiga jenis yang berbeda secara kualitatif, kami mengambil nilai “hingga satu”. Ini efektif, tetapi dapat membuat konvergensi lebih sulit.

Seperti semua hewan, seiring bertambahnya usia Klyukovka, ia akan mengasah kemampuannya untuk memprediksi nilai-nilai negara, mendapatkan lebih banyak kepercayaan pada tindakannya, dan lebih jarang terkejut dengan penghargaan.
Agen RL, seperti Klukovka, tidak hanya menghasilkan semua data yang diperlukan, hanya berinteraksi dengan lingkungan, tetapi juga mengevaluasi label target sendiri. Itu benar, model RL memperbarui nilai sebelumnya untuk lebih cocok dengan nilai baru dan lebih baik.
David Silver, kepala kelompok RL di Google Deepmind mengatakan: AI = DL + RL. Ketika seorang agen seperti Klyukovka dapat mengatur kecerdasannya sendiri, kemungkinannya tidak terbatas ...
