Ketika
HighLoad ++ peserta datang ke laporan
Alexander Krasheninnikov , mereka berharap untuk mendengar tentang pemrosesan 1.600.000 peristiwa per detik. Ekspektasi tidak menjadi kenyataan ... Karena selama persiapan untuk kinerja, angka ini terbang hingga
1.800.000 - jadi, di HighLoad ++, kenyataan melebihi harapan.
3 tahun yang lalu, Alexander memberi tahu bagaimana mereka membangun sistem pemrosesan acara dekat waktu nyata di Badoo. Sejak itu, ia telah berevolusi, volume telah tumbuh dalam proses, perlu untuk memecahkan masalah penskalaan dan toleransi kesalahan, dan pada saat-saat tertentu diperlukan tindakan radikal -
perubahan dalam tumpukan teknologi .

Dari dekripsi, Anda akan belajar bagaimana di Badoo Anda mengganti bundel Spark + Hadoop dengan ClickHouse,
menyimpan perangkat keras 3 kali dan menambah beban 6 kali , mengapa dan dengan cara apa mengumpulkan statistik di proyek, dan kemudian apa yang harus dilakukan dengan data ini.
Tentang pembicara: Alexander Krasheninnikov (
alexkrash ) - Kepala Teknik Data di Badoo. Dia terlibat dalam infrastruktur BI, penskalaan untuk beban kerja, dan mengelola tim yang membangun infrastruktur pemrosesan data. Dia menyukai semua yang didistribusikan: Hadoop, Spark, ClickHouse. Saya yakin bahwa sistem terdistribusi keren dapat disiapkan dari OpenSource.
Koleksi statistik
Jika kami tidak memiliki data, kami buta dan tidak dapat mengelola proyek kami. Itu sebabnya kami membutuhkan statistik - untuk
memantau kelangsungan proyek. Kami, sebagai insinyur, harus berusaha untuk meningkatkan produk kami, dan jika
Anda ingin meningkatkan, mengukurnya. Ini adalah moto saya dalam pekerjaan. Pertama-tama, tujuan kami adalah keuntungan bisnis. Statistik
memberikan jawaban untuk pertanyaan bisnis . Metrik teknis adalah metrik teknis, tetapi bisnis juga tertarik pada indikator, dan mereka juga perlu dipertimbangkan.
Statistik Siklus Hidup
Saya mendefinisikan siklus hidup statistik dengan 4 poin, yang masing-masing akan kita bahas secara terpisah.
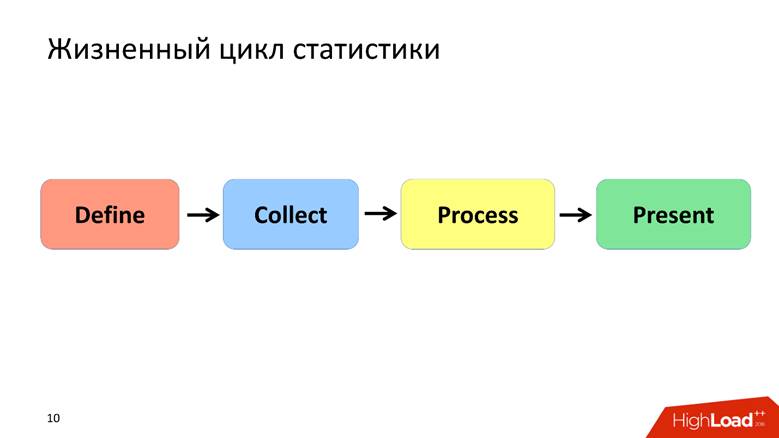
Tentukan Fase - Formalisasi
Dalam aplikasi, kami mengumpulkan beberapa metrik. Pertama-tama, ini adalah
metrik bisnis . Jika Anda memiliki layanan foto, misalnya, Anda bertanya-tanya berapa banyak foto yang diunggah per hari, per jam, per detik. Metrik berikut adalah
"semi-teknis" : responsif terhadap aplikasi atau situs seluler, kerja API, seberapa cepat pengguna berinteraksi dengan situs, instalasi aplikasi, UX.
Melacak perilaku pengguna adalah metrik penting ketiga. Ini adalah sistem seperti Google Analytics dan Yandex.Metrics. Kami memiliki sistem pelacakan keren kami sendiri, di mana kami banyak berinvestasi.
Dalam proses bekerja dengan statistik, banyak pengguna terlibat - ini adalah pengembang dan analitik bisnis. Penting bagi setiap orang untuk berbicara dalam bahasa yang sama, jadi Anda harus setuju.
Dimungkinkan untuk bernegosiasi secara verbal, tetapi jauh lebih baik bila ini terjadi secara formal - dalam struktur peristiwa yang jelas.
Formalisasi struktur acara bisnis adalah ketika pengembang mengatakan berapa banyak pendaftaran yang kami miliki, analis memahami bahwa ia diberikan informasi tidak hanya tentang jumlah total pendaftaran, tetapi juga menurut negara, jenis kelamin, dan parameter lainnya. Dan semua informasi ini diformalkan dan berada
dalam domain publik untuk semua pengguna perusahaan . Acara ini memiliki struktur yang diketik dan deskripsi formal. Misalnya, kami menyimpan informasi ini dalam format
Protokol Buffer .
Deskripsi acara "Registrasi":
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 userid =1; required Gender usergender = 2; required int32 time =3; required int32 countryid =4; }
Acara pendaftaran berisi informasi tentang
pengguna, bidang, waktu acara, dan
negara pendaftaran pengguna. Informasi ini tersedia untuk analis, dan, di masa depan, bisnis memahami apa yang kami kumpulkan.
Mengapa saya perlu deskripsi formal?
Deskripsi formal adalah
keseragaman untuk pengembang, analis, dan departemen produk. Maka informasi ini menembus uraian logika bisnis aplikasi. Sebagai contoh, kami memiliki sistem internal untuk menggambarkan proses bisnis dan di dalamnya ada layar yang kami miliki fitur baru.
Dalam
dokumen persyaratan produk terdapat bagian dengan instruksi bahwa ketika pengguna berinteraksi dengan aplikasi dengan cara ini, kita harus mengirim acara dengan parameter yang persis sama. Selanjutnya, kami akan dapat memvalidasi seberapa baik fitur kami bekerja, dan kami mengukurnya dengan benar. Deskripsi formal memungkinkan kami untuk lebih memahami cara menyimpan data ini dalam database: NoSQL, SQL, atau lainnya. Kami memiliki
skema data , dan itu keren.
Dalam beberapa sistem analitik yang disediakan sebagai layanan, hanya ada 10-15 peristiwa dalam penyimpanan rahasia. Di negara kami, jumlah ini telah bertambah lebih dari 1000 dan tidak akan berhenti -
tidak mungkin untuk hidup tanpa satu registri .
Tentukan Ringkasan Fase
Kami memutuskan bahwa
statistik - ini penting dan
menggambarkan bidang subjek tertentu - ini bagus, Anda dapat hidup terus.
Kumpulkan fase - pengumpulan data
Kami memutuskan untuk membangun sistem sehingga ketika peristiwa bisnis terjadi - pendaftaran, mengirim pesan, seperti - pada saat yang sama dengan menyimpan informasi ini, kami secara terpisah mengirim peristiwa statistik tertentu.
Dalam kode, statistik dikirim bersamaan dengan acara bisnis.
Ini diproses sepenuhnya secara independen dari penyimpanan data di mana aplikasi berjalan, karena
aliran data melewati pipa pemrosesan yang terpisah.Deskripsi melalui EDL:
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 user_id =1; required Gender user_gender = 2; required int32 time =3; required int32 country_id =4; }
Kami memiliki deskripsi acara pendaftaran. API dihasilkan secara otomatis, dapat diakses oleh pengembang dari kode, yang dalam 4 baris memungkinkan Anda mengirim statistik.
API berbasis EDL:
\EDL\Event\Regist ration::create() ->setUserId(100500) ->setGender(Gender: :MALE) ->setTime(time()) ->send();
Pengiriman Acara
Ini adalah sistem eksternal kita. Kami melakukan ini karena kami memiliki layanan luar biasa yang menyediakan API untuk bekerja dengan data foto, tentang hal lain. Mereka semua menyimpan data dalam database bermodel baru yang keren, seperti Aerospike dan CockroachDB.
Ketika Anda perlu membuat semacam pelaporan, Anda tidak perlu pergi dan bertarung: "Kawan, berapa banyak yang Anda miliki dan berapa banyak?" - Semua data dikirim dalam aliran terpisah. Memproses conveyor - sistem eksternal. Dari konteks aplikasi, kami membuka semua data dari repositori logika bisnis, dan mengirimkannya lebih jauh ke saluran pipa terpisah.
Fase Kumpulkan mengasumsikan ketersediaan server aplikasi. Kami punya PHP ini.
Transportasi
Ini adalah subsistem yang memungkinkan kami mengirim ke saluran lain apa yang kami lakukan dari konteks aplikasi. Transportasi dipilih semata-mata dari kebutuhan Anda, tergantung pada situasi di proyek.
Transportasi memiliki karakteristik, dan yang pertama adalah
jaminan pengiriman. Karakteristik transportasi: setidaknya-sekali, tepat-sekali, Anda memilih statistik untuk tugas Anda, berdasarkan seberapa penting data ini. Misalnya, untuk sistem penagihan tidak dapat diterima bahwa statistik menunjukkan lebih banyak transaksi daripada yang ada - ini adalah uang, itu tidak mungkin.
Parameter kedua adalah
binding untuk bahasa pemrograman. Kita harus entah bagaimana berinteraksi dengan transportasi, jadi itu dipilih sesuai dengan bahasa di mana proyek ditulis.
Parameter ketiga adalah
skalabilitas. Karena kita berbicara tentang jutaan peristiwa per detik, alangkah baiknya mengingat skalabilitas di masa depan.
Ada banyak opsi transportasi: aplikasi RDBMS, Flume, Kafka atau LSD. Kami menggunakan
LSD - ini adalah cara khusus kami.
Daemon streaming langsung
LSD tidak ada hubungannya dengan zat terlarang. Ini adalah
daemon streaming yang hidup dan sangat cepat yang tidak menyediakan agen apa pun untuk menulisnya. Kita dapat menyetelnya, kami memiliki
integrasi dengan sistem lain : HDFS, Kafka - kami dapat mengatur ulang data yang dikirim. LSD tidak memiliki panggilan jaringan pada INSERT, dan Anda dapat mengontrol topologi jaringan di dalamnya.
Yang paling penting, ini adalah
OpenSource Badoo - tidak ada alasan untuk tidak mempercayai perangkat lunak ini.
Jika itu adalah iblis yang sempurna, maka alih-alih Kafka kita akan membahas LSD di setiap konferensi, tetapi setiap LSD memiliki lalat di salep. Kami memiliki batasan kami sendiri yang membuat kami nyaman: kami
tidak memiliki dukungan replikasi di LSD dan memiliki
setidaknya satu kali jaminan pengiriman. Juga, untuk transaksi uang, ini bukan transportasi yang paling cocok, tetapi Anda umumnya perlu berkomunikasi dengan uang secara eksklusif melalui database "asam" - mendukung
ACID .
Kumpulkan Ringkasan Fase
Berdasarkan hasil dari seri sebelumnya, kami menerima
deskripsi formal dari data, menghasilkan
API yang sangat baik dan nyaman
untuk pengirim acara dari mereka, dan menemukan cara
untuk mentransfer data ini
dari konteks aplikasi ke pipa yang terpisah . Sudah tidak buruk, dan kami sedang mendekati fase berikutnya.
Proses Fase - Pemrosesan Data
Kami mengumpulkan data dari pendaftaran, foto yang diunggah, jajak pendapat - apa yang harus dilakukan dengan semua ini? Dari data ini kami ingin mendapatkan
bagan dengan riwayat panjang dan
data mentah . Grafik memahami segalanya - Anda tidak perlu menjadi pengembang untuk memahami dari kurva bahwa pendapatan perusahaan tumbuh. Kami menggunakan data mentah untuk pelaporan online dan ad-hoc. Untuk kasus yang lebih kompleks, analis kami ingin melakukan kueri analitik pada data ini. Baik itu maupun fungsionalitas itu penting bagi kita.
Grafik
Grafik tersedia dalam berbagai bentuk.
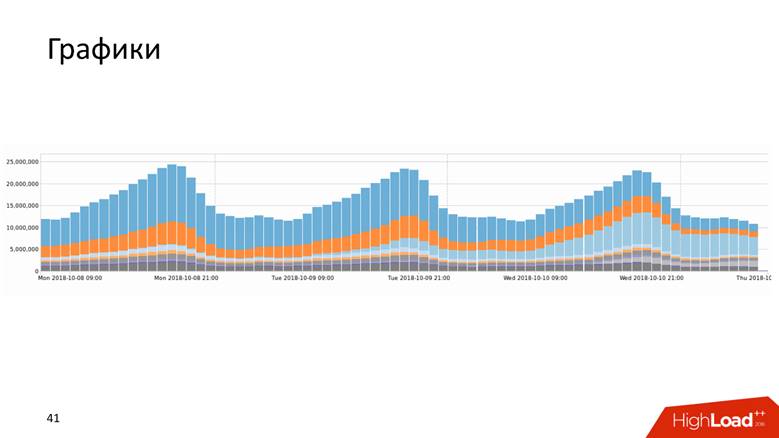
Atau, misalnya, grafik dengan riwayat yang menunjukkan data selama 10 tahun.
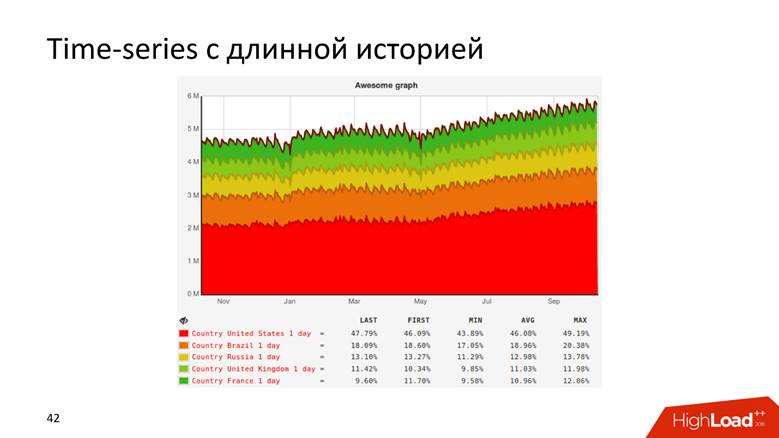
Grafik bahkan seperti itu.
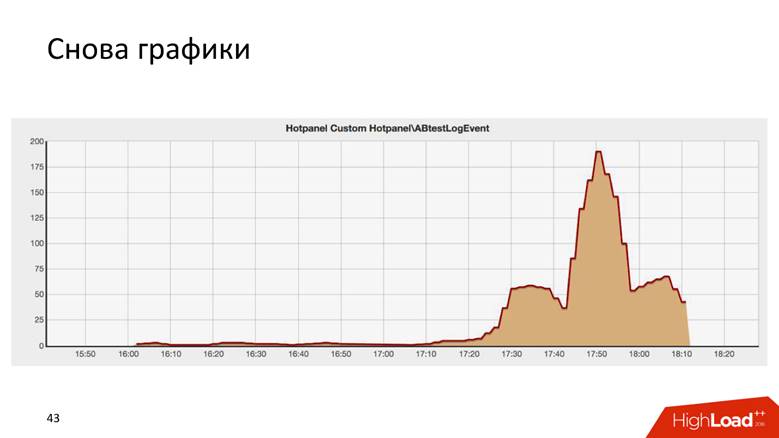
Ini adalah hasil dari beberapa tes AB, dan secara mengejutkan mirip dengan gedung Chrysler di New York.
Ada dua cara untuk menggambar grafik:
kueri untuk data mentah dan
seri waktu . Kedua pendekatan memiliki kekurangan dan kelebihan, yang tidak akan kita bahas secara terperinci. Kami menggunakan
pendekatan hibrid : kami menjaga ekor pendek dari data mentah untuk pelaporan operasional, dan seri waktu untuk penyimpanan jangka panjang. Yang kedua dihitung dari yang pertama.
Bagaimana kami telah berkembang menjadi 1,8 juta acara per detik
Ceritanya panjang - jutaan RPS tidak terjadi dalam sehari. Badoo adalah perusahaan dengan sejarah sepuluh tahun, dan kita dapat mengatakan bahwa sistem pemrosesan data tumbuh bersama perusahaan.
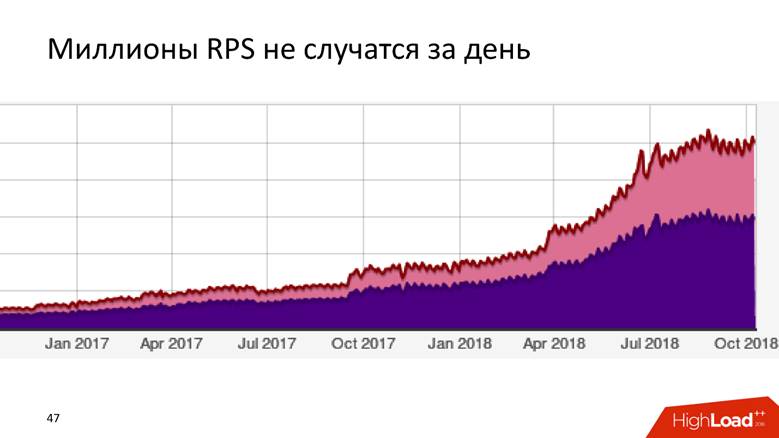
Awalnya kami tidak punya apa-apa. Kami mulai mengumpulkan data - ternyata
5.000 acara per detik. Satu host MySQL dan tidak ada yang lain! Setiap DBMS relasional akan mengatasi tugas ini, dan akan nyaman dengan itu: Anda akan memiliki transaksionalitas - memasukkan data, menerima permintaan padanya - semuanya bekerja dengan baik dan baik. Jadi kami hidup sebentar.
Di beberapa titik, terjadi sharding fungsional: data pendaftaran - di sini, dan tentang foto - di sana. Jadi kami hidup hingga
200.000 peristiwa per detik dan mulai menggunakan berbagai pendekatan gabungan: untuk menyimpan bukan data mentah, tetapi
dikumpulkan , tetapi sejauh ini dalam database relasional. Kami menyimpan penghitung, tetapi esensi dari sebagian besar basis data relasional adalah sedemikian rupa sehingga tidak mungkin untuk menjalankan
kueri DISTINCT pada data ini - model aljabar penghitung tidak memungkinkan menghitung DISTINCT.
Kami di Badoo memiliki motto
"Kekuatan tak terbendung" . Kami tidak akan berhenti dan tumbuh lebih jauh. Pada saat kami melewati ambang
200.000 peristiwa per detik , kami memutuskan untuk membuat deskripsi formal, yang saya bicarakan di atas. Sebelum itu, ada beberapa kekacauan, dan sekarang kami telah mendapatkan daftar acara yang terstruktur: kami mulai mengukur sistem,
menghubungkan Hadoop , semua data masuk ke
tabel Hive.Hadoop adalah paket perangkat lunak besar, sistem file. Untuk komputasi terdistribusi, Hadoop mengatakan, "Letakkan data di sini, saya akan membiarkan Anda melakukan pertanyaan analitik pada mereka." Jadi kami melakukan - menulis
perhitungan teratur untuk semua grafik - ternyata baik-baik saja. Tetapi bagan sangat berharga ketika mereka diperbarui dengan cepat - sekali sehari, menonton pembaruan bagan tidak begitu menyenangkan. Jika kami meluncurkan sesuatu yang mengarah ke kesalahan fatal pada produksi, kami ingin melihat grafik langsung turun, dan tidak setiap hari. Oleh karena itu, seluruh sistem mulai menurun setelah beberapa waktu. Namun, kami menyadari bahwa pada tahap ini Anda dapat menempel pada tumpukan teknologi yang dipilih.
Bagi kami, Jawa itu baru, kami menyukainya, dan kami mengerti apa yang bisa dilakukan secara berbeda.
Pada tahap dari 400.000 hingga
800.000 acara per detik , kami mengganti Hadoop dalam bentuk yang paling murni dan Hive, sebagai pelaksana kueri analitis, dengan
Spark Streaming , menulis
peta umum / pengurangan dan penghitungan metrik tambahan. 3 tahun yang lalu saya
memberi tahu bagaimana kami melakukannya. Kemudian tampak bagi kami bahwa Spark akan hidup selamanya, tetapi hidup menentukan sebaliknya - kami bertemu dengan keterbatasan Hadoop. Mungkin jika kami memiliki kondisi lain, kami akan terus hidup dengan Hadoop.
Masalah lain, selain menghitung grafik pada Hadoop, adalah pertanyaan SQL empat lantai yang luar biasa yang didorong oleh analis, dan grafik tidak diperbarui dengan cepat. Faktanya adalah bahwa ada pekerjaan yang agak rumit dengan pemrosesan data operasional, sehingga real-time, cepat dan keren.
Badoo dilayani oleh dua pusat data yang terletak di dua sisi Samudra Atlantik - di Eropa dan Amerika Utara. Untuk membuat laporan terpadu, Anda harus mengirim data dari Amerika ke Eropa. Di pusat data Eropa kami menyimpan semua statistik statistik, karena ada lebih banyak kekuatan komputasi.
Bolak -balik antara pusat data sekitar
200 ms - jaringannya cukup rumit - membuat permintaan ke DC lain tidak sama dengan pergi ke rak berikutnya.
Ketika kami mulai meresmikan acara dan pengembang, dan manajer produk terlibat, semua orang menyukai segalanya - hanya ada
ledakan pertumbuhan yang pesat . Saat ini, sudah waktunya untuk membeli besi di kluster, tetapi kami tidak benar-benar ingin melakukan ini.
Ketika kami melewati puncak
800.000 acara per detik , kami menemukan apa yang Yandex unggah ke OpenSource
ClickHouse , dan memutuskan untuk mencobanya.
Mereka mengisi kerucut kerucut ketika mereka mencoba melakukan sesuatu, dan sebagai hasilnya, ketika semuanya bekerja, mereka membuat resepsi prasmanan kecil tentang sejuta acara pertama. Mungkin, ClickHouse bisa menyelesaikan laporan.
Ambil saja ClickHouse dan jalani saja.
Tapi ini tidak menarik, jadi kami akan terus berbicara tentang pemrosesan data.
Clickhouse
ClickHouse adalah hype dari dua tahun terakhir dan tidak perlu diperkenalkan: hanya di HighLoad ++ pada tahun 2018 saya ingat
tentang lima laporan tentang hal itu, serta seminar dan pertemuan.
Alat ini dirancang untuk menyelesaikan tugas-tugas yang kita tentukan sendiri. Ada
pembaruan dan chip waktu nyata yang kami terima pada satu waktu dari Hadoop: replikasi, sharding. Tidak ada alasan untuk tidak mencoba ClickHouse, karena mereka mengerti bahwa dengan implementasi pada Hadoop kami telah melanggar bagian bawah. Alatnya keren, dan dokumentasinya pada umumnya menyala - saya menulis di sana sendiri, saya sangat suka semuanya, dan semuanya hebat. Tetapi kami harus menyelesaikan sejumlah masalah.
Bagaimana cara mengubah seluruh aliran acara di ClickHouse? Bagaimana cara menggabungkan data dari dua pusat data? Dari kenyataan bahwa kami datang ke admin dan berkata: "Guys, mari kita instal ClickHouse", mereka tidak akan membuat jaringan dua kali lebih tebal, dan penundaannya setengahnya. Tidak, jaringan masih setipis dan sekecil gaji pertama.
Bagaimana cara menyimpan hasilnya ? Di Hadoop, kami mengerti cara menggambar grafik - tetapi bagaimana melakukannya di ClickHouse ajaib? Tongkat sihir tidak termasuk.
Bagaimana cara mengirimkan hasil ke penyimpanan seri waktu?
Seperti yang dikatakan dosen saya di institut, pertimbangkan 3 skema data: strategis, logis, dan fisik.
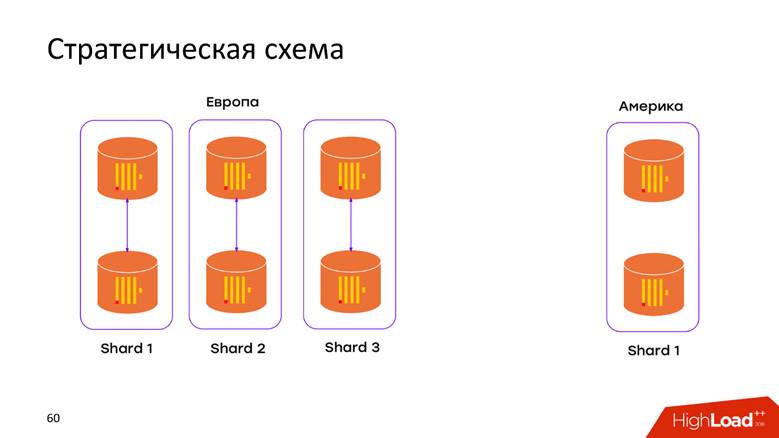
Skema penyimpanan strategis
Kami memiliki
2 pusat data . Kami mengetahui bahwa ClickHouse tidak tahu apa-apa tentang DC, dan kami baru saja membuka gugus di setiap DC. Sekarang
data tidak bergerak melalui kabel lintas-Atlantik - semua data yang terjadi di DC disimpan secara lokal di cluster-nya. Ketika kami ingin mengajukan permintaan atas data gabungan, misalnya, untuk mengetahui berapa banyak pendaftaran di kedua DC, ClickHouse memberi kami kesempatan ini. Latensi dan ketersediaan rendah untuk permintaan - hanya sebuah mahakarya!
Skema penyimpanan fisik
Sekali lagi, pertanyaan: bagaimana data kita akan jatuh ke dalam model relasional ClickHouse, apa yang harus dilakukan agar tidak kehilangan replikasi dan sharding? Semuanya dijelaskan secara luas dalam
dokumentasi ClickHouse , dan jika Anda memiliki lebih dari satu server, Anda akan menemukan artikel ini. Oleh karena itu, kami tidak akan menyelidiki apa yang ada di manual: replikasi, sharding, dan pertanyaan untuk semua data pada pecahan.
Logika penyimpanan
Diagram logika adalah yang paling menarik. Dalam satu jalur pipa kami memproses acara yang heterogen. Ini berarti bahwa kami memiliki
aliran acara yang heterogen : pendaftaran, suara, unggah foto, metrik teknis, pelacakan perilaku pengguna - semua acara ini memiliki
atribut yang sangat berbeda . Misalnya, saya melihat layar pada ponsel - saya perlu id layar, saya memilih seseorang - Anda perlu memahami apakah suara itu mendukung atau tidak. Semua peristiwa ini memiliki atribut yang berbeda, grafik yang berbeda digambar di atasnya, tetapi semua ini harus diproses dalam satu saluran pipa. Bagaimana cara memasukkannya ke dalam model ClickHouse?
Pendekatan No. 1 - per tabel acara. Pendekatan pertama ini, kami memperkirakan dari pengalaman yang diperoleh dengan MySQL - kami menciptakan
tablet untuk setiap acara di ClickHouse. Kedengarannya cukup logis, tetapi kami menemukan sejumlah kesulitan.
Kami tidak memiliki batasan bahwa acara tersebut akan mengubah strukturnya ketika build hari ini dirilis. Tambalan ini dapat dilakukan oleh pengembang mana pun. Skema ini umumnya bisa berubah ke segala arah. Satu-satunya
bidang yang diperlukan adalah
acara cap waktu dan apa acara itu. Segala sesuatu yang lain berubah dengan cepat, dan, karenanya, pelat-pelat ini perlu dimodifikasi. ClickHouse memiliki kemampuan untuk melakukan
ALTER pada sebuah cluster , tetapi ini adalah prosedur rumit yang sulit untuk diotomatisasi untuk membuatnya bekerja dengan lancar. Karena itu, ini adalah minus.
Kami memiliki lebih dari seribu peristiwa berbeda, yang memberi kami
tingkat INSERT tinggi per mesin - kami terus-menerus merekam semua data dalam seribu tabel. Untuk ClickHouse, ini adalah anti-pola. Jika Pepsi memiliki slogan - "Live in big teguk", maka ClickHouse -
"Live in big batch .
" Jika ini tidak dilakukan, maka replikasi tersendat, ClickHouse menolak untuk menerima sisipan baru - skema yang tidak menyenangkan.
Pendekatan No. 2 - tabel lebar . Orang-orang Siberia mencoba menyelipkan gergaji ke atas rel dan menerapkan model data yang berbeda. Kami membuat tabel dengan
seribu kolom , di mana setiap acara memiliki kolom yang disediakan untuk datanya. Kami mendapatkan
meja yang sangat kecil - untungnya, ini tidak melampaui lingkungan pengembangan, karena dari sisipan pertama menjadi jelas bahwa skema ini benar-benar buruk, dan kami tidak akan melakukannya.
Tapi saya masih ingin menggunakan produk perangkat lunak yang keren, sedikit lebih banyak untuk menyelesaikan - dan itu akan menjadi apa yang Anda butuhkan.
Pendekatan No. 3 - tabel umum. Kami memiliki satu tabel besar di mana kami menyimpan data dalam array, karena ClickHouse mendukung
tipe data non-skalar . Yaitu, kita mulai kolom di mana nama atribut disimpan, dan kolom terpisah dengan array di mana nilai atribut disimpan.
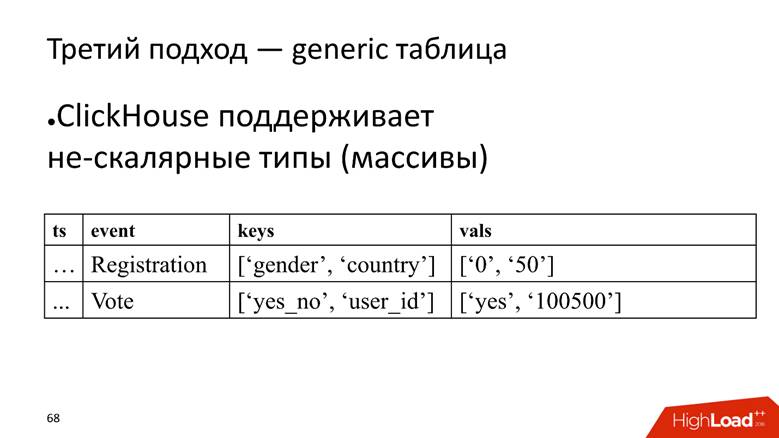
ClickHouse di sini melakukan tugasnya dengan sangat baik. Jika kita hanya perlu memasukkan data, kita mungkin akan memeras 10 kali lebih banyak dalam instalasi saat ini.
Namun, lalat di salep adalah bahwa itu juga merupakan anti-pola untuk ClickHouse -
untuk menyimpan array string . Ini buruk karena array baris
membutuhkan lebih banyak ruang disk - mereka menyusut lebih buruk daripada kolom sederhana dan lebih
sulit untuk diproses . Tetapi untuk tugas kita, kita menutup mata kita terhadap hal ini, karena kelebihannya lebih besar.
Bagaimana cara membuat SELECT dari tabel seperti itu? Tugas kami adalah menghitung pendaftaran yang dikelompokkan berdasarkan gender. Pertama, Anda perlu menemukan dalam satu array yang posisinya sesuai dengan kolom gender, lalu naik ke kolom lain dengan indeks ini dan dapatkan datanya.
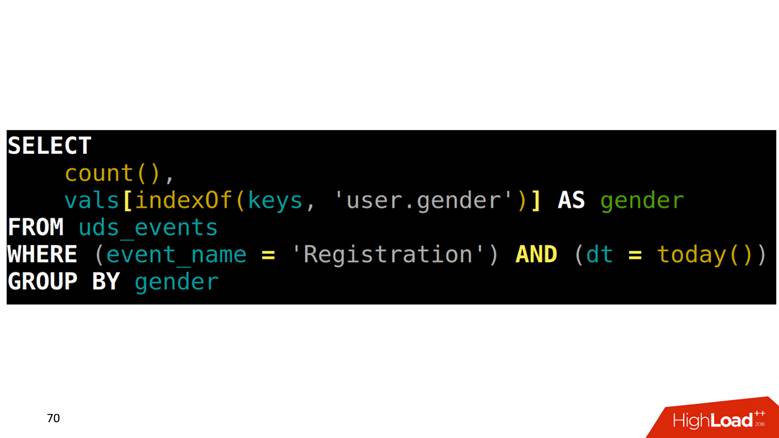
Cara menggambar grafik pada data ini
Karena semua peristiwa dijelaskan, mereka memiliki struktur yang ketat, kami membentuk kueri SQL empat lantai untuk setiap jenis acara, jalankan dan simpan hasilnya ke tabel lain.
Masalahnya adalah bahwa untuk menggambar dua titik yang berdekatan pada grafik, Anda perlu
memindai seluruh tabel . Contoh: kita melihat registrasi per hari. Acara ini dari baris atas ke yang kedua dari belakang. Dipindai satu kali - sangat baik. Setelah 5 menit, kami ingin menggambar titik baru pada bagan - lagi, kami memindai rentang data yang bersinggungan dengan pemindaian sebelumnya, dan seterusnya untuk setiap peristiwa. Kedengarannya masuk akal, tetapi tidak terlihat bagus.
Selain itu, ketika kita mengambil beberapa baris, kita juga perlu
membaca hasil di bawah agregasi . Sebagai contoh, ada fakta bahwa hamba Tuhan terdaftar di Skandinavia dan seorang laki-laki, dan kita perlu menghitung statistik ringkasan: berapa banyak pendaftaran, berapa banyak pria, berapa banyak dari mereka adalah manusia, dan berapa banyak dari Norwegia. Ini disebut dalam hal basis data analitis
ROLLUP, CUBE, dan
GROUPING SETS -
ubah satu baris menjadi beberapa.
Bagaimana cara mengobati
Untungnya, ClickHouse memiliki alat untuk memecahkan masalah ini, yaitu,
keadaan agregat fungsi serial . Ini berarti Anda dapat memindai sepotong data satu kali dan menyimpan hasil ini. Ini adalah
fitur pembunuh . 3 tahun yang lalu kami melakukan ini pada Spark dan Hadoop, dan itu keren bahwa secara paralel dengan kami, pikiran Yandex terbaik mengimplementasikan analog di ClickHouse.
Permintaan lambat
Kami memiliki permintaan lambat - untuk menghitung pengguna unik untuk hari ini dan kemarin.
SELECT uniq(user_id) FROM table WHERE dt IN (today(), yesterday())
Dalam bidang fisik, kita dapat membuat SELECT untuk state untuk kemarin, mendapatkan representasi binernya, menyimpannya di suatu tempat.
SELECT uniq(user_id), 'xxx' AS ts, uniqState(user id) AS state FROM table WHERE dt IN (today(), yesterday())
Untuk hari ini, kita hanya mengubah syaratnya menjadi hari ini:
'yyy' AS ts dan
WHERE dt = today() dan timestamp kita sebut "xxx" dan "yyy". , , 2 .
SELECT uniqMerge(state) FROM ageagate_table WHERE ts IN ('xxx', 'yyy')
:
, - .
. , , , , ClickHouse, : «, ! , !»
, , .
, . . — SQL-, . , , .

, - time series. : , , , time series.
time series : , , timestamp . , , . . , , , — , . , , ClickHouse -, , .
, , ClickHouse:
— « », — .
time series 2 , 20 20-80 . . ClickHouse
GraphiteMergeTree , time series, .
8 ClickHouse , 6 - , 2 : 2 — , .
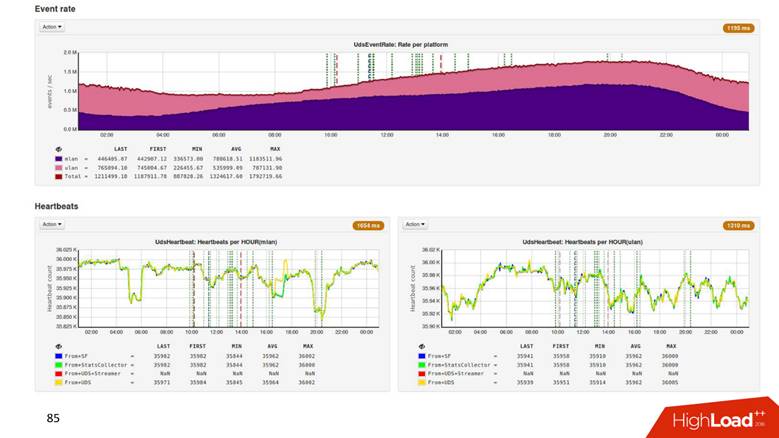
1.8 . ,
500 . , 1,8 , 500 ! .
Hadoop
2 . .
3 , CPU —
4 . , .
Process
, , , . , , ClickHouse 3 000 . , , , overkill.
, , . ClickHouse,
. , , , . , 8 3–4 . — .
Present —
, ? time series,
time series , , , .
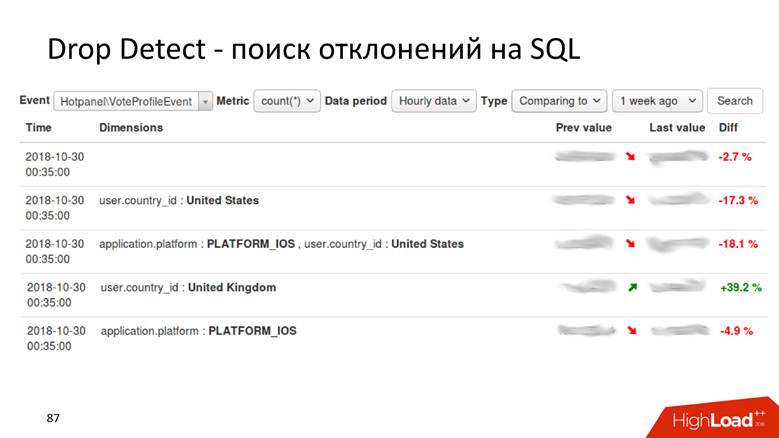
 Drop Detect — SQL
Drop Detect — SQL : SQL- , , .
 Anomaly Detection
Anomaly Detection — . , , 2% , — 40, , , , .
— , , - , Anomaly Detection.
Anomaly Detection
, time series . : , , . time series
. , , . ,
drop detection — , .
UI.
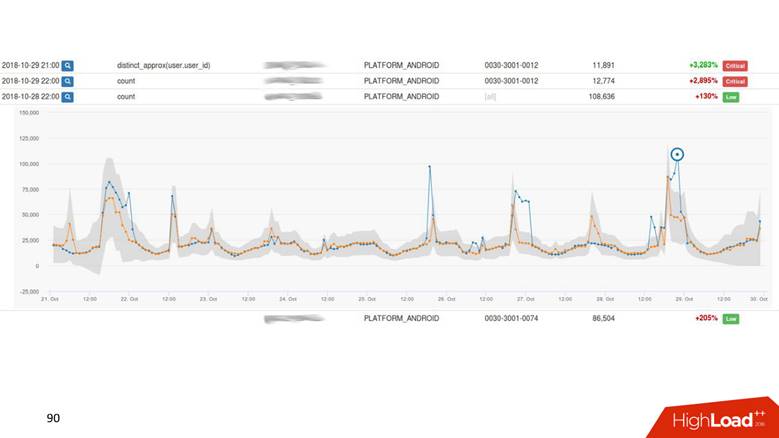
. - , — . -, .
Present
, ,
.
, : 1000 — alarm, 0 — alarm. .
Anomaly Detection , . Anomaly Detection
Exasol , ClickHouse. Anomaly Detection 2 , .
, , 4 .
,
, , . ,
, . ,
.
HighLoad++ , HighLoad++ - . , , :)
, PHP Russia , , . , , , 1,8 /, , 1 .