Pendahuluan
Netcracker adalah perusahaan internasional yang mengembangkan solusi IT yang kompleks, termasuk hosting dan layanan dukungan untuk peralatan klien, serta hosting sistem IT yang dibuat untuk operator telekomunikasi.
Ini terutama adalah keputusan yang berkaitan dengan organisasi kegiatan operasional dan bisnis operator telekomunikasi. Rincian lebih lanjut dapat ditemukan di
sini .
Keberlanjutan ketersediaan solusi yang sedang dikembangkan sangat penting. Jika operator telekomunikasi berhenti bekerja setidaknya selama satu jam, ini akan menyebabkan kerugian finansial dan reputasi yang besar bagi operator dan penyedia perangkat lunak. Oleh karena itu, salah satu persyaratan utama untuk solusi adalah parameter
ketersediaan , nilainya bervariasi dari 99,995% hingga 99,95% tergantung pada jenis solusi.
Solusi itu sendiri adalah seperangkat kompleks sistem TI monolitik sentral, termasuk peralatan telekomunikasi kompleks dan perangkat lunak layanan yang terletak di cloud publik, serta banyak layanan mikro yang terintegrasi dengan inti pusat.
Karena itu, sangat penting bagi tim pendukung untuk memantau semua perangkat keras dan sistem perangkat lunak yang diintegrasikan ke dalam satu solusi. Paling sering, perusahaan menggunakan pemantauan tradisional. Proses ini sudah mapan: kita bisa membangun sistem pemantauan yang sama dari awal dan kita tahu bagaimana mengatur proses respons insiden dengan benar. Namun, ada beberapa kesulitan dalam pendekatan ini yang kami hadapi dari proyek ke proyek.
- Apa yang harus dipantau
Metrik mana yang saat ini penting, dan mana yang akan penting di masa depan? Tidak ada jawaban yang pasti di sini, jadi kami mencoba memantau semuanya . Kesulitan nomor satu - jumlah metrik. Ada masalah kinerja, dashboard operasional semakin menyerupai panel kontrol pesawat ruang angkasa.
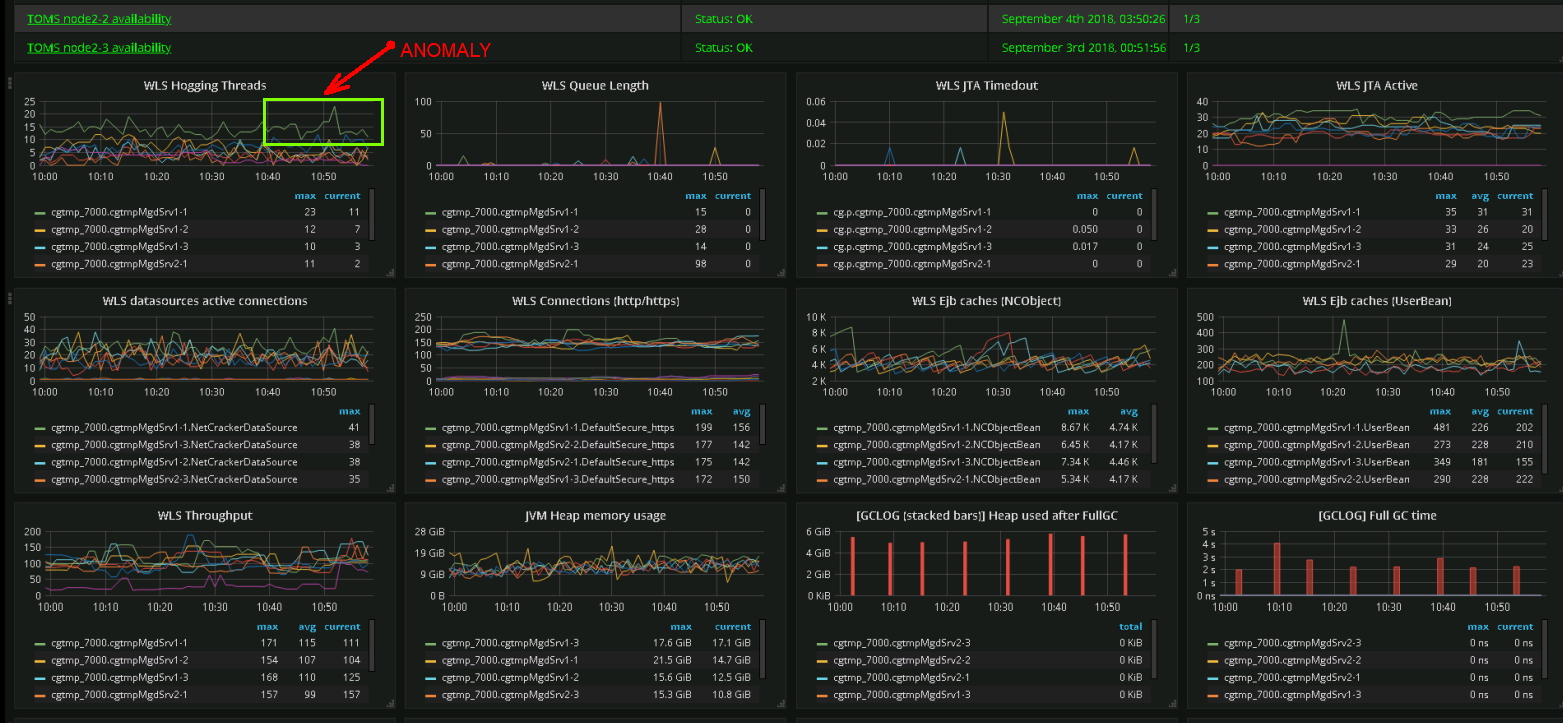
Cuplikan layar dasbor nyata. Insinyur tim pendukung dapat mengidentifikasi kelainan perilaku sistem berdasarkan representasi grafis mereka
- Peringatan / ambang batas
Terlepas dari kenyataan bahwa kami memiliki pengalaman mengoperasikan banyak sistem besar, pemantauan mereka masih merupakan tugas yang sulit karena spesifikasi peralatan yang digunakan dan versi perangkat lunak dari berbagai pemasok. Pengalaman dan aturan yang sudah jadi seringkali tidak dapat sepenuhnya ditransfer dari satu solusi ke solusi lainnya. Ada set dasar tertentu, peningkatan yang terjadi berulang, sebagai analisis insiden yang timbul dari pengoperasian solusi.
Kesulitan nomor dua adalah kurangnya aturan yang jelas untuk penyesuaian. - Interpretasi hasil
Ketika sebuah insiden terjadi, sangat penting untuk segera menemukannya. Ini sebagian besar tergantung pada pengalaman tim pendukung, karena di bawah poros pesan sekunder tentang kegagalan, Anda tidak dapat melihat akar penyebab masalah dan kehilangan waktu pada tanggapan cepat. Dan ini adalah kompleksitas tiga.
Dengan bantuan proses yang terorganisir dengan baik, tim dapat mengatasi kesulitan-kesulitan di atas, namun, permintaan modern untuk perubahan keputusan reaktif - ketika waktu untuk beralih dari ide ke implementasi diukur dalam hitungan hari - secara signifikan mempersulit tugas. Pelatihan tim berkelanjutan diperlukan. Perubahan konstan mengarah pada fakta bahwa aturan-aturan tertentu dan hubungan sebab-akibat kehilangan makna dan, sebagai akibatnya, insiden itu, yang tidak dihilangkan dalam waktu, dapat berubah menjadi kecelakaan.
Bagaimana pembelajaran mesin membantu kita
Prediksi kegagalan fungsi perangkat keras dan sistem perangkat lunak menjadi fungsi yang sangat populer sebagai respons preventif atau reaktif terhadap insiden.
NEC Corporation, perusahaan induk kami, berinvestasi besar dalam mengembangkan ide pemantauan. Salah satu hasil dari investasi ini adalah
Teknologi Analisis Invarian Sistem (SIAT) yang dipatenkan.
SIAT adalah teknologi pembelajaran mesin yang, di antara kumpulan data sensor atau metrik yang disajikan sebagai deret waktu, ditemukan menggunakan algoritma ML hubungan fungsional konstan dan membangun model umum - grafik hubungan ini. Detail dapat ditemukan di
sini .
Gambar menggambarkan hubungan yang ditemukan antara sensor benda fisik
Idenya, awalnya dikembangkan untuk sistem-IT, saat ini telah menyebar hanya untuk memantau kompleks fisik, seperti pabrik, pabrik, pembangkit listrik tenaga nuklir.
Lockheed Martin , misalnya,
mengimplementasikan teknologi ini di divisi ruangnya. Pada 2018,
Netcracker, bersama dengan
NEC, memikirkan kembali ide ini dan menciptakan produk yang cocok untuk memantau sistem TI sebagai alat untuk analitik tambahan.
Penting : ini hanya tambahan untuk sistem pemantauan, tetapi bukan penggantinya.
Aplikasi SIAT untuk Sistem TI
Apa perbedaan antara kompleks fisik dan perangkat lunak? Dalam sistem perangkat lunak, metrik digunakan, dalam fisik - sensor. Metrik lebih banyak digunakan, karena sensor fisik selalu bernilai uang dan hanya ditempatkan di tempat yang masuk akal. Metrik perangkat lunak, jika diatur dengan benar, tidak dikenakan biaya. Selain itu, metrik data sistem informasi jauh lebih sulit untuk diinterpolasi dengan benar ke keadaan sistem. Lebih mudah bagi seseorang untuk memahami sensor yang terkait dengan dunia fisik, sementara nilai spesifik metrik perangkat lunak hanya masuk akal dalam kaitannya dengan perangkat keras, konfigurasi, dan beban tertentu.
Interkoneksi
fungsional dalam model juga menunjukkan bahwa jika kita mengganti versi perangkat keras atau perangkat lunak (misalnya, tambalan OS) dan semua operasi menjadi lebih cepat atau lebih lambat, ini tidak akan menyebabkan pesan palsu tentang kecelakaan karena fakta bahwa kami tidak mengubah
ambang batas . Jika metrik berhenti berkorelasi satu sama lain, ini berarti penyimpangan dari norma dalam perilaku sistem. Selain itu, teknologi
SIAT memungkinkan bahkan penyimpangan perilaku kecil secara real time untuk dideteksi, termasuk apa yang disebut
kegagalan diam -
kegagalan fungsi yang tidak disertai dengan pesan kesalahan. Dan jika penyimpangan ini hanya pertanda kegagalan yang lebih besar, kita punya waktu untuk bereaksi dengan benar.
Kami memverifikasi pernyataan ini dengan mensimulasikan Server Web Apache kecil di bawah beban, meniru kesalahan internal menggunakan mekanisme
Injeksi Kesalahan di Linux .
Hasilnya disajikan dalam bentuk
Angka Anomali metrik numerik, yang nilainya dikaitkan dengan model ini. Semakin besar nilainya, semakin serius kegagalannya: semakin banyak metrik berperilaku abnormal. Nilai batasnya adalah 100% dari metrik tidak normal, sistem tidak berfungsi. Selain itu, hasilnya menunjukkan metrik yang perilakunya saat ini dapat dianggap abnormal. Ini sangat mempercepat analisis penyebab dan identifikasi subsistem yang saat ini gagal dalam model perilaku saat ini.
Secara umum,
SIAT memungkinkan
Anda untuk merespons bahkan perubahan kecil dalam perilaku yang hampir tidak terdeteksi menggunakan pemantauan tradisional atau baseline.
Gambar menggambarkan gangguan dalam hubungan antara sensor
Keuntungan tambahan
SIAT adalah algoritma untuk membangun model perilaku yang tidak memerlukan indikasi rasa bisnis dari metrik. Algoritme secara otomatis memilih semua metrik yang perilakunya saling berhubungan satu sama lain, dan hubungan ini konstan. Metrik terisolasi yang tersisa adalah salah satu subsistem titik yang tidak memengaruhi solusi TI, atau metrik yang tidak penting untuk kondisi solusi saat ini. Jika masuk akal, pemantauan metrik tersebut diimplementasikan dalam kerangka pendekatan tradisional berdasarkan
peringatan ambang batas .
Sangat penting bahwa pembuatan model memerlukan data yang terkait dengan fungsi normal sistem, yang
jauh lebih sederhana daripada saat mendekati dengan pelatihan kecelakaan.
Model selanjutnya disempurnakan dan dibangun kembali jika perilaku telah berubah atau kami telah menambahkan metrik baru ke dalamnya.
Karena perilaku normal sistem adalah karakteristik variabel, tergantung pada waktu hari dan kondisi bisnis lainnya, untuk respons yang lebih akurat masuk akal untuk membuat beberapa model yang menggambarkan perilaku sistem dalam kondisi tertentu.
Seperti apa prosesnya
Proses organisasi pemantauan adalah sebagai berikut.
- Kami memulai pemantauan tradisional. Pilihan nama metrik yang tepat sangat penting. Faktanya adalah bahwa hasilnya termasuk nama-nama metrik yang perilakunya abnormal, yang berarti bahwa semakin akurat metrik menggambarkan tempat dan makna, semakin cepat hasilnya akan diperoleh. Misalnya, metrik bernama ncp. erp_netcracker _com.apps.erp. clust4.wls .jdbc. LMSDataSource . ActiveConnectionsCurrentCount menunjukkan bahwa dalam sistem Netcracker ERP , metrik bernama ActiveConnectionsCurrentCount gagal pada gugus Weblogic keempat untuk LMSDataSource . Bagi ahli, informasi semacam itu lebih dari cukup untuk melokalisasi anomali secara akurat.
- Selanjutnya, kami mengintegrasikan dengan sistem penyimpanan data metrik - dalam kasus kami, ClickHouse - dan mendapatkan data dari semua metrik untuk periode tertentu dari perilaku normal solusi: model terbaik dibangun berdasarkan hasil pemantauan 30 hari. Untuk mendapatkan model yang lebih akurat, kami menggunakan data metrik per menit tanpa agregasi.
- Kami membangun model menggunakan SIAT berdasarkan data dari sistem pemantauan. Dalam kerangka model yang dibangun, kami menyaring hubungan fungsional sesuai dengan tingkat kesamaan. Singkatnya, ini adalah tingkat penyimpangan perilaku dari yang diberikan, dinyatakan sebagai persentase.
- Kami memeriksa model pada data hari-hari sebelumnya, di mana kegagalan terdeteksi menggunakan tim pemantauan dan dukungan tradisional.
- Kami memulai pemantauan online: setiap 10 menit, data semua metrik ditransfer ke model atau model. Kami mendapatkan hasil - skor anomali, dan jika hasilnya tidak nol, selain itu kami mendapatkan daftar metrik yang perilakunya saat ini tidak normal.
- Hasilnya dikirim ke sistem pemantauan umum, di mana ia menjadi bagian dari dasbor umum dan alat pemantauan tradisional lainnya.
Tes
Tidak ada implementasi tunggal terjadi tanpa verifikasi. Sebagai sistem yang diuji, kami memilih
ERP kami sendiri (monolit,
Weblogic ,
Oracle , 4500 metrik) dan sistem perutean seluruh sistem pemantauan kami, 7 juta metrik per menit, -
carbon-c-relay (1200 metrik).
Dump semua metrik digunakan sebagai input, dan hari-hari di mana kegagalan dicatat juga ditunjukkan. Untuk mengevaluasi hasilnya, kami memperkenalkan konsep-konsep berikut:
- Jumlah kesalahan jenis kedua adalah ketika sistem pemantauan tradisional atau tim pendukung menemukan kegagalan, tetapi SIAT tidak.
- Jumlah deteksi yang benar - ketika pemantauan tradisional dan SIAT mendeteksi masalah.
- Jumlah kesalahan jenis pertama - ketika SIAT mendeteksi penyimpangan perilaku, tetapi tim pendukung tidak menemukannya.
Kami tidak menemukan kesalahan jenis kedua untuk kedua sistem yang diuji. Jumlah deteksi yang benar - 85% dari total kegagalan yang ditemukan oleh
SIAT , dan dalam kasus kegagalan peralatan - array RAID pada basis data
gagal -
SIAT mendeteksi degradasi perilaku dengan indikasi yang tepat dari metrik yang terkait dengan database, tujuh jam sebelum mencapai menetapkan nilai ambang batas dalam sistem pemantauan.
15% sisanya dari kegagalan
SIAT yang ditunjukkan adalah kesalahan jenis pertama - perilaku abnormal yang tidak dapat dijelaskan oleh tim pendukung. Ini mungkin karena fakta bahwa ketika membangun model, metrik-metrik itu secara otomatis dimasukkan yang memiliki makna fungsional, tetapi tidak memiliki efek yang nyata pada perilaku umum sistem. Setelah beberapa kesalahan positif, pakar TI dapat menandai metrik ini sebagai tidak penting dan menghapusnya dari model, setelah sebelumnya menyetujui ini dengan
SME .
Hasil menunjukkan bahwa produk ini sepenuhnya mengotomatiskan proses mendeteksi kegagalan (termasuk yang tersembunyi), tepat waktu melokalisasi kejadian dan menilai skalanya.
Apa selanjutnya
Sekarang kami sedang mengumpulkan pengalaman dalam mengoperasikan produk untuk berbagai jenis perangkat keras dan sistem perangkat lunak untuk menganalisis penerapan pendekatan ini ke berbagai sistem: perangkat jaringan, perangkat
IoT , cloud microservices, dan sebagainya.
Saat ini, tugas membangun kembali model adalah hambatan. Ini membutuhkan daya komputasi yang signifikan, tetapi, untungnya, penghitungan ulang dapat dilakukan pada mesin yang terisolasi, mengekspor hasilnya sebagai model yang sudah jadi. Pemantauan waktu nyata itu sendiri tidak memerlukan sumber daya yang signifikan dan dilakukan secara paralel dengan pemantauan tradisional pada peralatan yang sama.
Kesimpulan
Kesimpulannya, saya ingin mencatat bahwa menggunakan kombinasi teknik pemantauan tradisional dan algoritma pembelajaran mesin memungkinkan Anda untuk membangun model sederhana yang membantu Anda merespons dalam waktu, mencari tahu di mana masalahnya berasal, dan juga menjaga sistem dalam kondisi kerja.
Selain teknologi
SIAT yang menjanjikan, kami menganalisis kemungkinan menggunakan teknologi
NEC lain -
Next Generation Log Analytics . Teknologi ini memungkinkan penggunaan algoritma pembelajaran mesin dan penggunaan log sistem untuk menentukan anomali terkait dengan kondisi internal produk yang tidak mempengaruhi degradasi keseluruhan sistem dalam hal kinerja.
Analitik apa yang Anda gunakan untuk memonitor sistem TI?