
Alat tradisional di bidang Ilmu Data adalah bahasa seperti sintaksis R dan Python -santai dan sejumlah besar pustaka untuk pembelajaran mesin dan pemrosesan data memungkinkan Anda dengan cepat mendapatkan beberapa solusi yang berfungsi. Namun, ada situasi di mana keterbatasan alat-alat ini menjadi penghambat yang signifikan - pertama-tama, jika Anda perlu mencapai kinerja tinggi dalam hal kecepatan pemrosesan dan / atau bekerja dengan kumpulan data yang sangat besar. Dalam hal ini, spesialis harus dengan enggan beralih ke bantuan "sisi gelap" dan menghubungkan alat-alat dalam bahasa pemrograman "industri": Scala , Java dan C ++ .
Tapi apakah sisi ini sangat gelap? Selama bertahun-tahun pengembangan, alat-alat dari Ilmu Data "industri" telah datang jauh dan hari ini mereka sangat berbeda dari versi mereka sendiri 2-3 tahun yang lalu. Mari kita coba menggunakan contoh tugas SNA Hackathon 2019 untuk mencari tahu seberapa besar ekosistem Scala + Spark dapat dikaitkan dengan Python Data Science.
Dalam kerangka kerja SNA Hackathon 2019, peserta memecahkan masalah pengurutan umpan berita dari pengguna jejaring sosial dalam salah satu dari tiga "disiplin": menggunakan data dari teks, gambar, atau fitur log. Dalam publikasi ini, kita akan melihat bagaimana di Spark dimungkinkan untuk memecahkan masalah berdasarkan log tanda menggunakan alat pembelajaran mesin klasik.
Dalam menyelesaikan masalah, kami akan menggunakan cara standar yang dilalui oleh setiap spesialis analisis data saat mengembangkan model:
- Kami akan melakukan analisis data penelitian, membuat grafik.
- Kami menganalisis sifat statistik tanda-tanda dalam data, melihat perbedaannya antara set pelatihan dan tes.
- Kami akan melakukan pemilihan awal fitur berdasarkan properti statistik.
- Kami menghitung korelasi antara tanda-tanda dan variabel target, serta korelasi silang antara tanda-tanda.
- Kami akan membentuk set fitur terakhir, melatih model dan memeriksa kualitasnya.
- Mari kita menganalisis struktur internal model untuk mengidentifikasi titik pertumbuhan.
Selama "perjalanan" kita, kita akan berkenalan dengan alat-alat seperti notebook interaktif Zeppelin , perpustakaan pembelajaran mesin ML Spark dan ekstensi PravdaML , paket grafik GraphX , perpustakaan visualisasi Vegas , dan, tentu saja, Apache Spark dengan segala kemuliaan: ) Semua kode dan hasil percobaan tersedia di platform notebook kolaborasi Zepl .
Pemuatan data
Fitur dari data yang diletakkan di SNA Hackathon 2019 adalah bahwa adalah mungkin untuk memprosesnya secara langsung menggunakan Python, tetapi sulit: sumber data dikemas secara efisien berkat kemampuan format kolom Apache Parket dan ketika membaca ke dalam memori "dengan dahi" itu didekompresi menjadi beberapa puluh gigabyte. Ketika bekerja dengan Apache Spark, tidak perlu memuat data sepenuhnya ke dalam memori, arsitektur Spark dirancang untuk memproses data dalam bentuk potongan, memuat dari disk seperlunya.
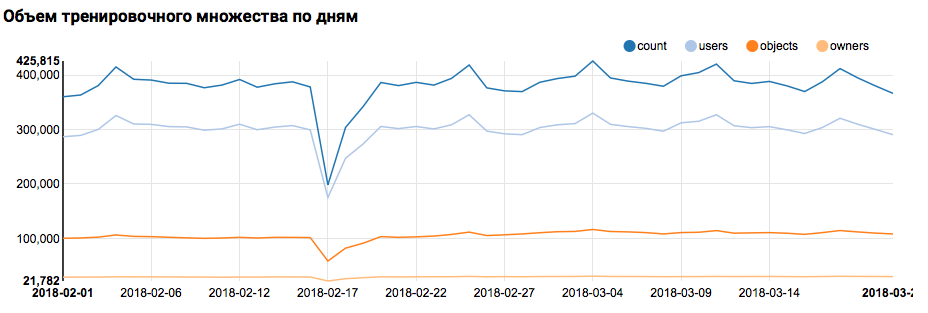
Oleh karena itu, langkah pertama - memeriksa distribusi data berdasarkan hari - mudah dilakukan oleh alat kotak:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show(train.groupBy($"date").agg( functions.count($"instanceId_userId").as("count"), functions.countDistinct($"instanceId_userId").as("users"), functions.countDistinct($"instanceId_objectId").as("objects"), functions.countDistinct($"metadata_ownerId").as("owners")) .orderBy("date"))
Apa grafik yang sesuai akan ditampilkan di Zeppelin:
Saya harus mengatakan bahwa sintaks Scala cukup fleksibel, dan kode yang sama mungkin terlihat, misalnya, seperti ini:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show( train groupBy $"date" agg( count($"instanceId_userId") as "count", countDistinct($"instanceId_userId") as "users", countDistinct($"instanceId_objectId") as "objects", countDistinct($"metadata_ownerId") as "owners") orderBy "date" )
Sebuah peringatan penting harus dibuat di sini: ketika bekerja dalam sebuah tim besar, di mana semua orang mendekati penulisan Scala-code secara eksklusif dari sudut pandang selera mereka sendiri, komunikasi jauh lebih sulit. Jadi lebih baik untuk mengembangkan konsep gaya kode terpadu.
Tapi kembali ke tugas kita. Analisis sederhana pada siang hari menunjukkan adanya titik-titik abnormal pada 17 dan 18 Februari; mungkin hari ini data yang tidak lengkap telah dikumpulkan, dan distribusi sifat mungkin bias. Ini harus diperhitungkan dalam analisis lebih lanjut. Selain itu, sangat mengejutkan bahwa jumlah pengguna unik sangat dekat dengan jumlah objek, sehingga masuk akal untuk mempelajari distribusi pengguna dengan jumlah objek yang berbeda:
z.show(filteredTrain .groupBy($"instanceId_userId").count .groupBy("count").agg(functions.log(functions.count("count")).as("withCount")) .orderBy($"withCount".desc) .limit(100) .orderBy($"count"))
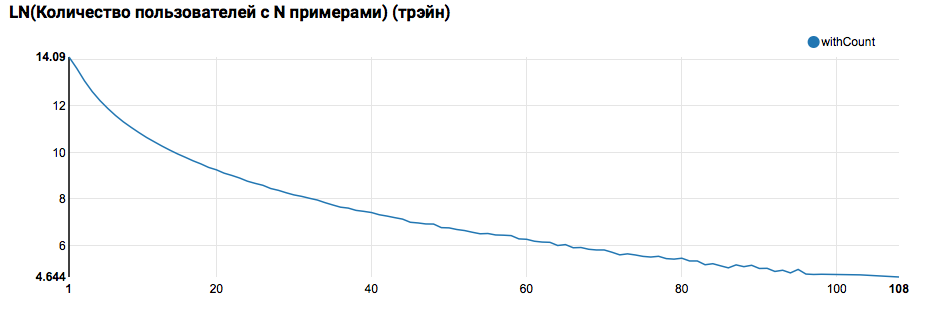
Diharapkan melihat distribusi yang dekat dengan eksponensial, dengan ekor yang sangat panjang. Dalam tugas-tugas seperti itu, sebagai suatu peraturan, adalah mungkin untuk mencapai peningkatan dalam kualitas pekerjaan dengan mensegmentasi model untuk pengguna dengan berbagai tingkat aktivitas. Untuk memeriksa apakah perlu melakukan ini, bandingkan distribusi jumlah objek oleh pengguna di set tes:
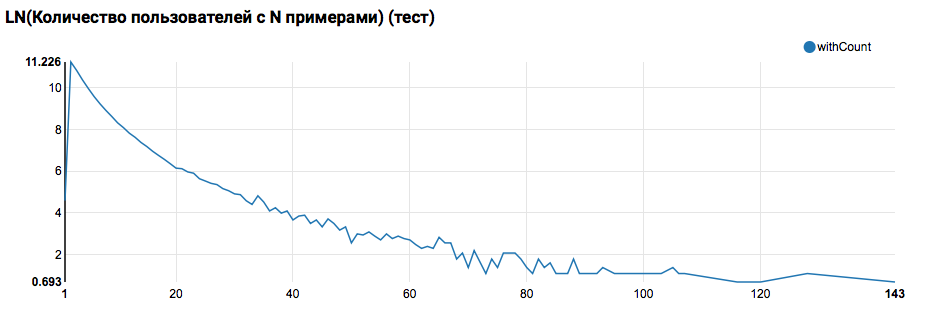
Perbandingan dengan tes menunjukkan bahwa pengguna tes memiliki setidaknya dua objek dalam log (karena masalah peringkat diselesaikan pada hackathon, ini adalah kondisi yang diperlukan untuk menilai kualitas). Di masa mendatang, saya sarankan untuk melihat lebih dekat pengguna di set pelatihan, yang kami nyatakan Fungsi Buatan Pengguna dengan filter:
Sebuah komentar penting juga harus dibuat di sini: dari sudut pandang mendefinisikan UDF bahwa penggunaan Spark dari bawah Scala / Java dan dari bawah Python sangat berbeda. Sementara kode PySpark menggunakan fungsionalitas dasar, semuanya bekerja hampir sama cepatnya, tetapi ketika fungsi yang ditimpa muncul, kinerja PySpark menurun berdasarkan urutan besarnya.
Pipa ML pertama
Pada langkah berikutnya, kami akan mencoba menghitung statistik dasar tentang tindakan dan atribut. Tetapi untuk ini kita membutuhkan kemampuan SparkML, jadi pertama-tama kita akan melihat arsitektur umumnya:

SparkML dibangun berdasarkan konsep berikut:
- Transformer - mengambil set data sebagai input dan mengembalikan set yang dimodifikasi (transform). Sebagai aturan, ini digunakan untuk mengimplementasikan algoritma sebelum dan sesudah pemrosesan, ekstraksi fitur, dan juga dapat mewakili model-ML yang dihasilkan.
- Estimator - mengambil set data sebagai input, dan mengembalikan Transformer (cocok). Secara alami, Pengukur dapat mewakili algoritma ML.
- Pipeline adalah kasus khusus Estimator, yang terdiri dari rantai transformer dan estimator. Ketika metode ini disebut, fit melewati rantai, dan jika ia melihat sebuah transformator, ia menerapkannya pada data, dan jika ia melihat suatu estimator, ia melatih transformator dengannya, menerapkannya pada data dan melangkah lebih jauh.
- PipelineModel - hasil Pipeline juga mengandung rantai di dalamnya, tetapi hanya terdiri dari transformer. Dengan demikian, PipelineModel sendiri juga merupakan transformator.
Pendekatan seperti pembentukan algoritma ML membantu untuk mencapai struktur modular yang jelas dan reproduktifitas yang baik - baik model dan saluran pipa dapat disimpan.
Untuk memulainya, kami akan membangun jalur pipa sederhana yang dengannya kami menghitung statistik distribusi tindakan (bidang umpan balik) dari pengguna dalam rangkaian pelatihan:
val feedbackAggregator = new Pipeline().setStages(Array(
Dalam pipa ini, fungsionalitas PravdaML digunakan secara aktif - perpustakaan dengan blok berguna yang diperluas untuk SparkML, yaitu:
- MultinominalExtractor digunakan untuk menyandikan karakter tipe "array of strings" ke dalam vektor sesuai dengan prinsip one-hot. Ini adalah satu-satunya penaksir dalam pipeline (untuk membangun encoding, Anda harus mengumpulkan garis unik dari dataset).
- VectorStatCollector digunakan untuk menghitung statistik vektor.
- VectorExplode digunakan untuk mengubah hasilnya menjadi format yang nyaman untuk visualisasi.
Hasil karya akan berupa grafik yang menunjukkan bahwa kelas dalam dataset tidak seimbang, namun, ketidakseimbangan untuk target Kelas yang disukai tidak ekstrem:

Analisis distribusi serupa di antara pengguna yang mirip dengan yang diuji (memiliki "positif" dan "negatif" dalam log) menunjukkan bahwa itu bias terhadap kelas positif:
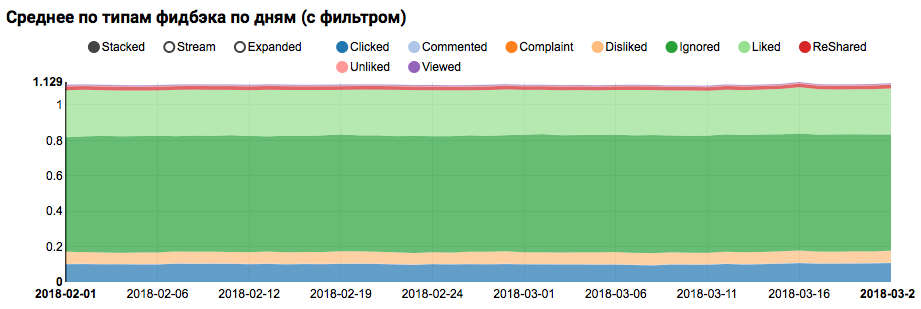
Analisis statistik tanda-tanda
Pada tahap selanjutnya, kami akan melakukan analisis terperinci tentang sifat statistik atribut. Kali ini kami membutuhkan conveyor yang lebih besar:
val statsAggregator = new Pipeline().setStages(Array( new NullToDefaultReplacer(),
Karena sekarang kita perlu bekerja bukan dengan bidang terpisah, tetapi dengan semua atribut sekaligus, kita akan menggunakan dua utilitas PravdaML yang lebih berguna:
- NullToDefaultReplacer memungkinkan Anda untuk mengganti elemen yang hilang dalam data dengan nilai defaultnya (0 untuk angka, false untuk variabel logis, dll.). Jika Anda tidak melakukan konversi ini, maka nilai NaN akan muncul di vektor yang dihasilkan, yang fatal bagi banyak algoritma (meskipun, misalnya, XGBoost dapat bertahan hidup ini). Alternatif untuk mengganti dengan nol dapat diganti dengan rata-rata, ini diterapkan di NaNToMeanReplacerEstimator.
- AutoAssembler adalah utilitas yang sangat kuat yang menganalisis tata letak tabel dan untuk setiap kolom memilih skema vektorisasi yang cocok dengan jenis kolom.
Dengan menggunakan pipa yang dihasilkan, kami menghitung statistik untuk tiga set (pelatihan, pelatihan dengan filter dan pengujian pengguna) dan menyimpan dalam file terpisah:
Setelah menerima tiga dataset dengan statistik atribut, kami menganalisis hal-hal berikut:
- Apakah kita memiliki tanda-tanda yang memiliki emisi besar.
- Tanda-tanda tersebut harus dibatasi, atau catatan pencilan harus disaring. - Apakah kita memiliki tanda-tanda dengan bias rata-rata relatif terhadap median.
- Pergeseran demikian sering terjadi di hadapan distribusi daya, masuk akal untuk logaritma tanda-tanda ini. - Apakah ada pergeseran dalam distribusi rata-rata antara pelatihan dan set tes.
- Seberapa rapatnya matriks fitur kami.
Untuk memperjelas aspek-aspek ini, permintaan semacam itu akan membantu kami:
def compareWithTest(data: DataFrame) : DataFrame = { data.where("date = 'All'") .select( $"features",
Pada tahap ini, muncul pertanyaan visualisasi: sulit untuk segera menampilkan semua aspek menggunakan alat Zeppelin biasa, dan notebook dengan sejumlah besar grafik mulai terasa melambat karena DOM yang membengkak. Perpustakaan Vegas - DSL di Scala untuk membangun spesifikasi vega-lite dapat mengatasi masalah ini. Vegas tidak hanya menyediakan kemampuan visualisasi yang lebih kaya (sebanding dengan matplotlib), tetapi juga menggambarnya di atas Kanvas tanpa menggembungkan DOM :).
Spesifikasi bagan yang kami minati akan terlihat seperti ini:
vegas.Vegas(width = 1024, height = 648)
Grafik di bawah ini seharusnya berbunyi seperti ini:
- Sumbu X menunjukkan pergeseran pusat distribusi antara set tes dan pelatihan (semakin dekat ke 0, semakin stabil tandanya).
- Persentase elemen bukan nol diplot sepanjang sumbu Y (semakin tinggi, semakin banyak data yang ada untuk semakin banyak poin berdasarkan atribut).
- Ukurannya menunjukkan pergeseran rata-rata relatif terhadap median (semakin besar titik, semakin besar kemungkinan distribusi hukum kekuasaan untuk itu).
- Warna menunjukkan emisi (semakin merah, semakin banyak emisi).
- Nah, formulir dibedakan oleh mode perbandingan: dengan filter pengguna di set pelatihan atau tanpa filter.
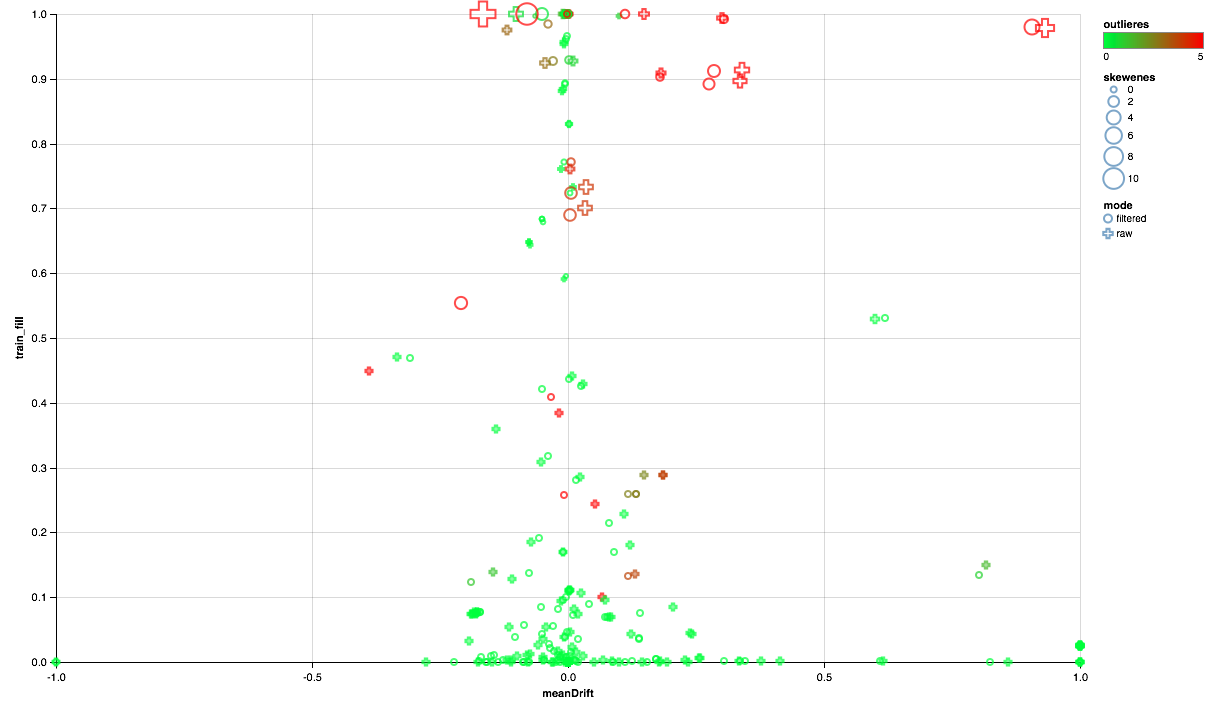
Jadi, kita bisa menarik kesimpulan berikut:
- Beberapa tanda memerlukan filter emisi - kami akan membatasi nilai maksimum untuk persentil ke-90.
- Beberapa tanda menunjukkan distribusi yang dekat dengan eksponensial - kami akan mengambil logaritma.
- Beberapa fitur tidak disajikan dalam tes - kami akan mengecualikan mereka dari pelatihan.
Analisis korelasi
Setelah mendapatkan gagasan umum tentang bagaimana atribut didistribusikan dan bagaimana mereka menghubungkan antara pelatihan dan set tes, mari kita coba menganalisis korelasi. Untuk melakukan ini, konfigurasikan ekstraktor fitur berdasarkan pengamatan sebelumnya:
Dari mesin-mesin baru dalam pipa ini, utilitas SQLTransformer menarik perhatian, yang memungkinkan transformasi SQL sewenang-wenang dari tabel input.
Ketika menganalisis korelasi, penting untuk menyaring kebisingan yang diciptakan oleh korelasi alami fitur satu-panas. Untuk melakukan ini, saya ingin memahami elemen vektor apa yang sesuai dengan kolom sumber mana. Tugas ini di Spark diselesaikan menggunakan metadata kolom (disimpan dengan data) dan grup atribut. Blok kode berikut digunakan untuk memfilter pasangan nama atribut yang berasal dari kolom yang sama dari tipe String:
val attributes = AttributeGroup.fromStructField(raw.schema("features")).attributes.get val originMap = filteredTrain .schema.filter(_.dataType == StringType) .flatMap(x => attributes.map(_.name.get).filter(_.startsWith(x.name + "_")).map(_ -> x.name)) .toMap
Memiliki set data dengan kolom vektor, menghitung korelasi silang menggunakan Spark cukup sederhana, tetapi hasilnya adalah sebuah matriks, untuk penyebaran yang Anda harus bermain sedikit ke dalam satu set pasangan:
val pearsonCorrelation =
Dan, tentu saja, visualisasi: kita akan membutuhkan lagi bantuan Vegas untuk menggambar peta panas:
vegas.Vegas("Pearson correlation heatmap") .withDataFrame(pearsonCorrelation .withColumn("isPositive", $"corr" > 0) .withColumn("abs_corr", functions.abs($"corr")) .where("feature1 < feature2 AND abs_corr > 0.05") .orderBy("feature1", "feature2")) .encodeX("feature1", Nom) .encodeY("feature2", Nom) .encodeColor("abs_corr", Quant, scale=Scale(rangeNominals=List("#FFFFFF", "#FF0000"))) .encodeShape("isPositive", Nom) .mark(vegas.Point) .show
Hasilnya lebih baik untuk melihat di Zepl-e . Untuk pemahaman umum:
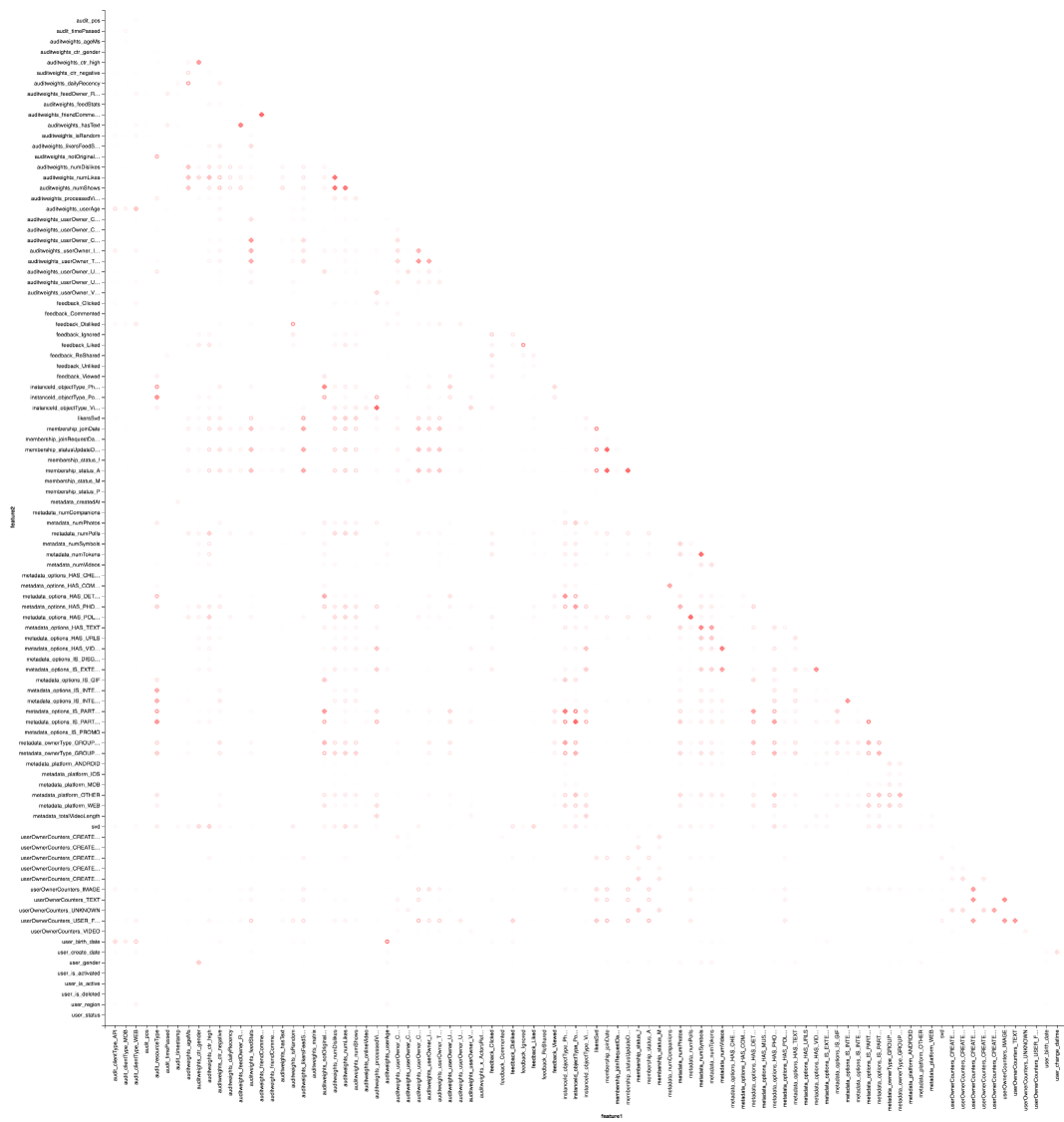
Peta panas menunjukkan bahwa beberapa korelasi jelas ada di sana. Mari kita coba untuk memilih blok-blok fitur yang paling berkorelasi kuat, untuk ini kita menggunakan perpustakaan GraphX : kita mengubah matriks korelasi menjadi grafik, menyaring tepi berdasarkan berat, setelah itu kita menemukan komponen yang terhubung dan hanya menyisakan komponen yang tidak mengalami degenerasi (dari lebih dari satu elemen). Prosedur semacam itu pada dasarnya mirip dengan penerapan algoritma DBSCAN dan adalah sebagai berikut:
Hasilnya disajikan dalam bentuk tabel:
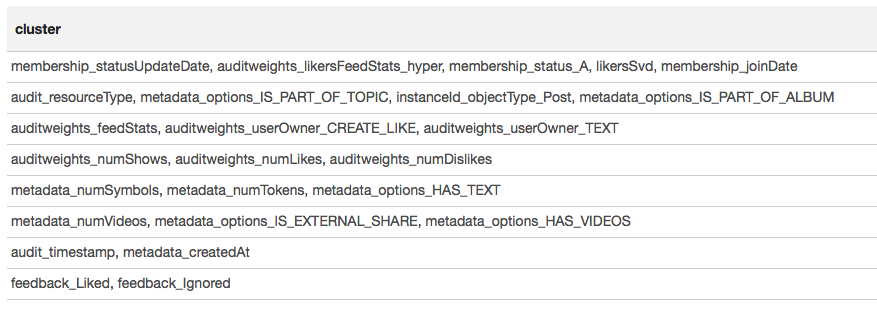
Berdasarkan hasil pengelompokan, kita dapat menyimpulkan bahwa kelompok yang paling berkorelasi terbentuk di sekitar tanda-tanda yang terkait dengan keanggotaan pengguna dalam grup (membership_status_A), serta di sekitar jenis objek (instanceId_objectType). Untuk pemodelan terbaik dari interaksi tanda, masuk akal untuk menerapkan segmentasi model - untuk melatih model yang berbeda untuk berbagai jenis objek, secara terpisah untuk kelompok di mana pengguna berada dan tidak.
Pembelajaran mesin
Kami mendekati hal yang paling menarik - pembelajaran mesin. Pipa untuk melatih model paling sederhana (regresi logistik) menggunakan ekstensi SparkML dan PravdaML adalah sebagai berikut:
new Pipeline().setStages(Array( new SQLTransformer().setStatement( """SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127)))
Di sini kita melihat tidak hanya banyak elemen yang akrab, tetapi juga beberapa yang baru:
- LogisticRegressionLBFSG adalah penduga dengan pelatihan regresi logistik terdistribusi.
- Untuk mencapai kinerja maksimum dari algoritma ML terdistribusi. data harus didistribusikan secara optimal di seluruh partisi. Utilitas UnwrappedStage.repartition akan membantu dalam hal ini, menambahkan operasi partisi ulang ke pipa sehingga hanya digunakan pada tahap pelatihan (setelah semua, ketika membangun prakiraan, tidak diperlukan lagi).
- Sehingga model linier dapat memberikan hasil yang baik. data harus diskalakan, di mana utilitas Scaler.scale bertanggung jawab. Namun, kehadiran dua transformasi linear berturut-turut (penskalaan dan perkalian dengan bobot regresi) menyebabkan biaya yang tidak perlu, dan diharapkan untuk menutup operasi ini. Saat menggunakan PravdaML, hasilnya akan menjadi model bersih dengan satu transformasi :).
- Nah, tentu saja, untuk model seperti itu, kita memerlukan anggota gratis, yang kita tambahkan menggunakan operasi Interceptor.intercept.
Pipa yang dihasilkan, diterapkan pada semua data, memberikan AUC 0,6889 per pengguna (kode validasi tersedia di Zepl ). Sekarang tetap menerapkan semua penelitian kami: memfilter data, mengubah fitur, dan model segmen. Pipa akhir akan terlihat seperti ini:
new Pipeline().setStages(Array( new SQLTransformer().setStatement(s"SELECT instanceId_userId, instanceId_objectId, ${expressions.mkString(", ")} FROM __THIS__"), new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label, concat(IF(membership_status = 'A', 'OwnGroup_', 'NonUser_'), instanceId_objectType) AS type FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label", "type","instanceId_objectType") .setOutputCol("features"), CombinedModel.perType( Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127))), numThreads = 6) ))
PravdaML — CombinedModel.perType. , numThreads = 6. .
, , per-user AUC 0.7004. ? , " " XGBoost :
new Pipeline().setStages(Array( new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), new XGBoostRegressor() .setNumRounds(100) .setMaxDepth(15) .setObjective("reg:logistic") .setNumWorkers(17) .setNthread(4) .setTrackerConf(600000L, "scala") ))
, — XGBoost Spark ! DLMC , PravdaML , ( ). XGboost " " 10 per-user AUC 0.6981.
, , , . SparkML , . PravdaML : Parquet Spark:
Parquet, PravdaML — TopKTransformer, .
Vegas ( Zepl ):
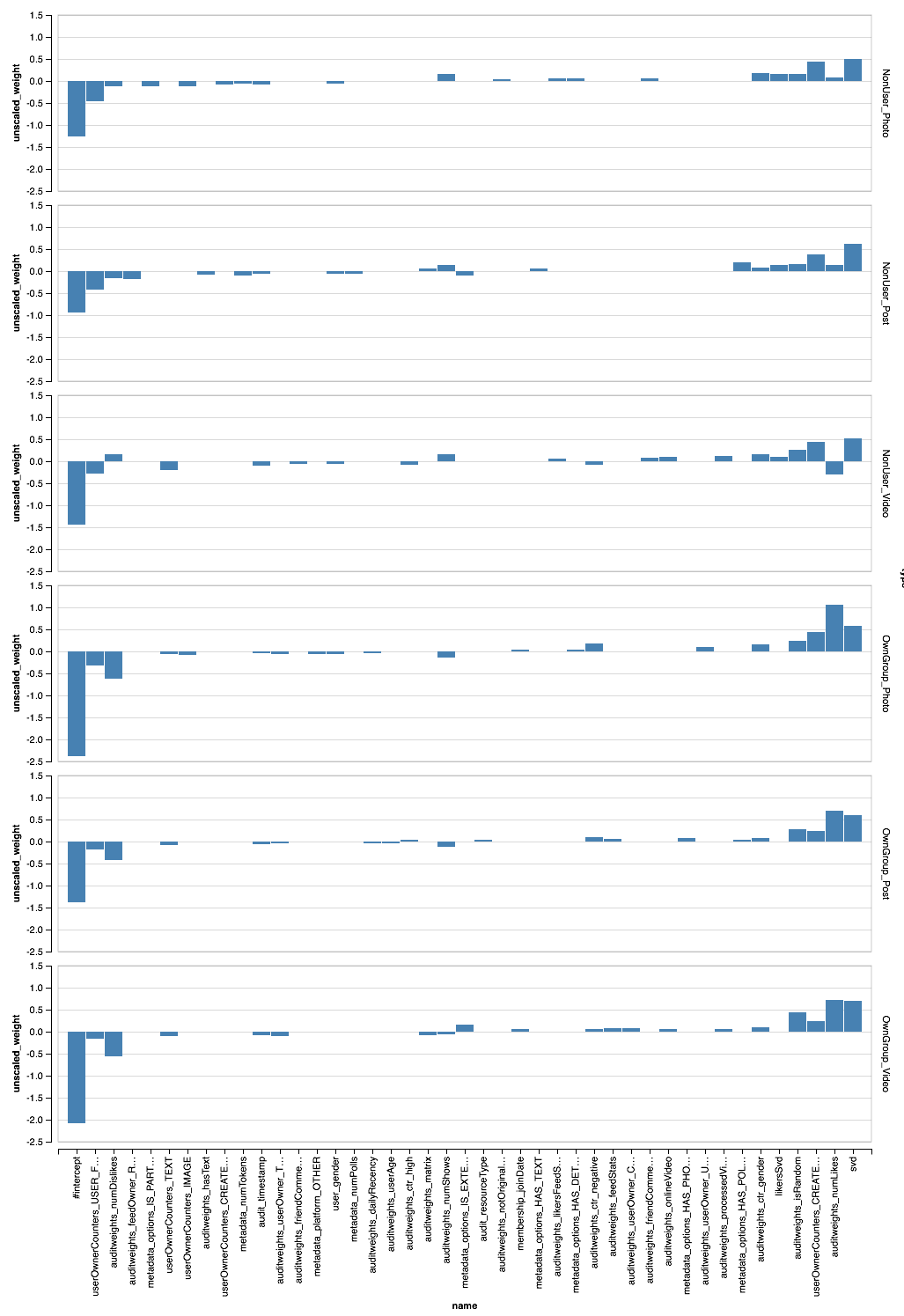
, - . XGBoost?
val significance = sqlContext.read.parquet( "sna2019/xgBoost15_100_raw/stages/*/featuresSignificance" vegas.Vegas() .withDataFrame(significance.na.drop.orderBy($"significance".desc).limit(40)) .encodeX("name", Nom, sortField = Sort("significance", AggOps.Mean)) .encodeY("significance", Quant) .mark(vegas.Bar) .show
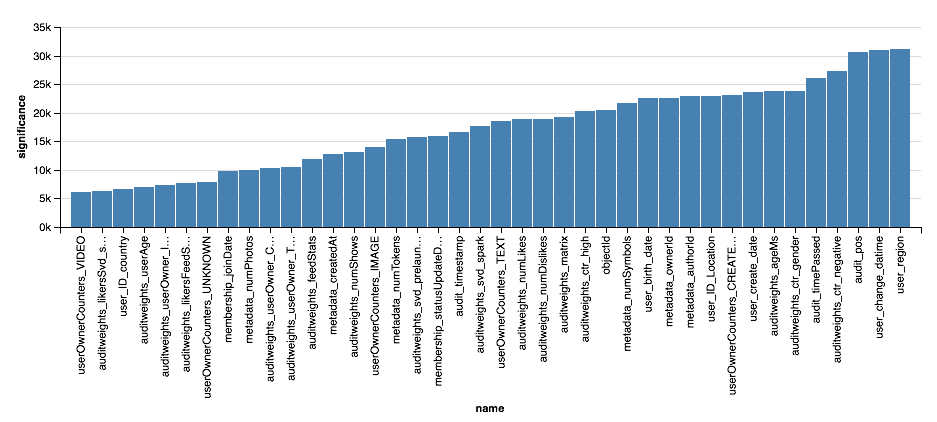
, , XGBoost, , . . , XGBoost , , .
Kesimpulan
, :). :
- , Scala Spark , , , , .
- Scala Spark Python: ETL ML, , , .
- , , , (, ) , , .
- , , . , , , -, .
, , , , -. , , " Scala " Newprolab.
, , — SNA Hackathon 2019 .