
Penanda adalah hal yang baik. Berguna dalam jumlah yang wajar. Ketika jumlah mereka terlalu banyak, manfaatnya akan hilang. Apa yang harus dilakukan jika Anda ingin menandai hasil pencarian di peta, di mana puluhan ribu objek? Dalam artikel ini saya akan memberi tahu Anda bagaimana kami memecahkan masalah ini pada kartu WebGL tanpa mengorbankan penampilan dan kinerjanya.
Latar belakang
Pada tahun 2016, 2GIS meluncurkan proyek WebGL pertamanya, Lantai: denah bangunan 3D.
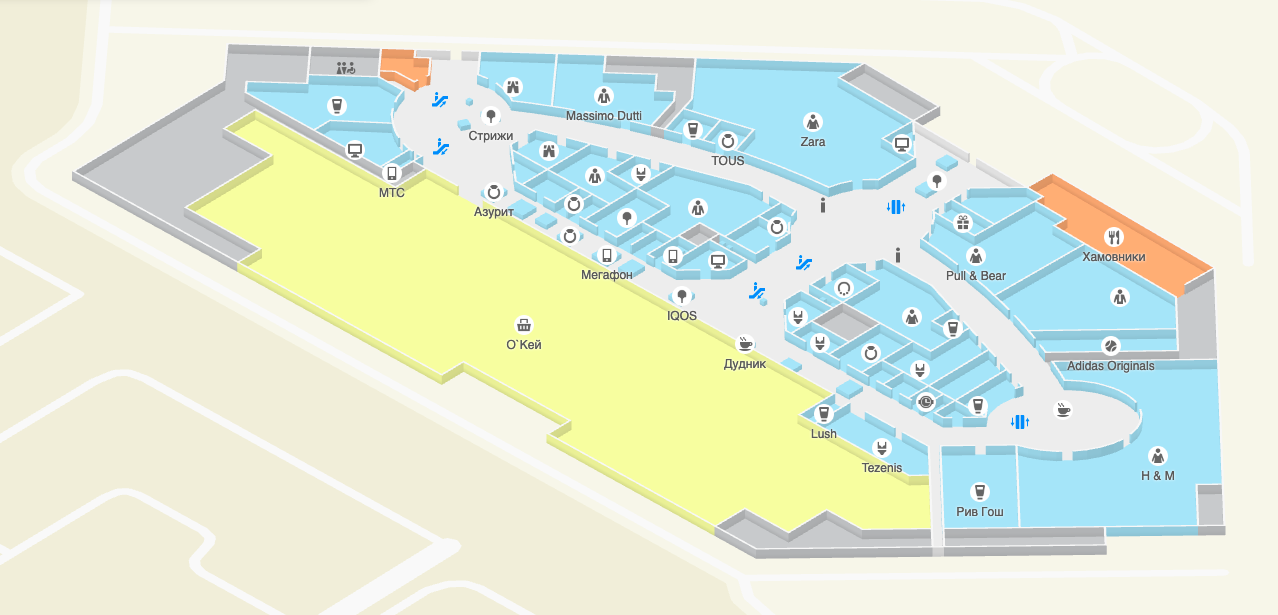
Lantai pusat perbelanjaan Novosibirsk Aura
Segera setelah rilis Floors, tim kami mulai mengembangkan mesin kartografi tiga dimensi penuh di WebGL. Mesin dikembangkan bersama dengan versi baru 2gis.ru dan sekarang dalam status beta publik .
Kotak merah digambar di WebGL. Rencana bangunan sekarang terintegrasi langsung ke dalam peta.
Tugas generalisasi tanda tangan
Siapa pun yang ingin menulis mesin peta mereka sendiri cepat atau lambat akan menghadapi masalah menempatkan tanda tangan di peta. Ada banyak objek di peta, dan tidak mungkin untuk menandatangani masing-masing sehingga tanda tangan tidak tumpang tindih.
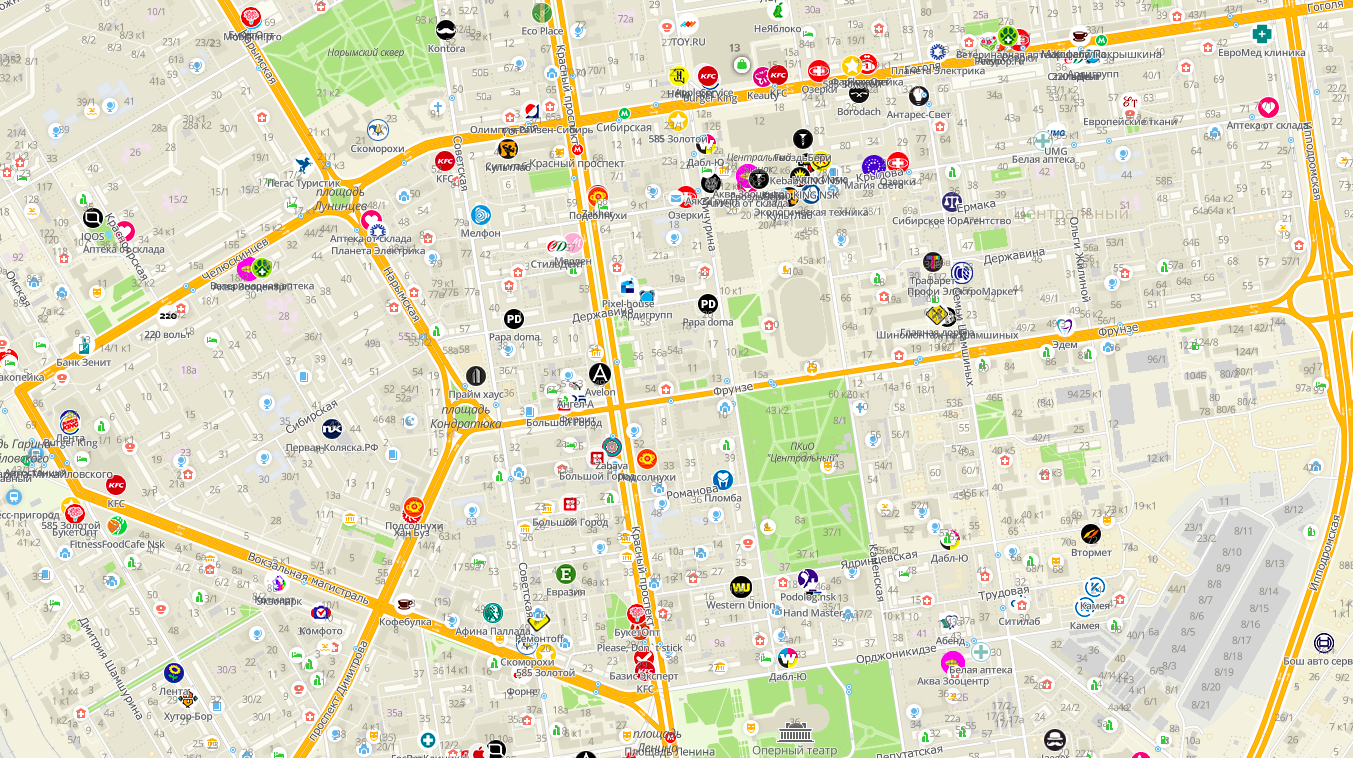
Apa yang akan terjadi jika dalam Novosibirsk semua objek ditandatangani sekaligus
Untuk mengatasi masalah ini, diperlukan generalisasi tanda tangan. Generalisasi dalam pengertian umum adalah transformasi data peta sehingga cocok untuk ditampilkan pada skala kecil. Itu dapat dilakukan dengan metode yang berbeda. Untuk tanda tangan, metode pemilihan biasanya digunakan: dari jumlah total, bagian dari tanda tangan paling prioritas yang tidak berpotongan dengan satu sama lain dipilih.
Prioritas tanda tangan ditentukan oleh jenisnya, serta skala peta saat ini. Misalnya, dalam skala kecil, tanda tangan kota dan negara diperlukan, dan dalam skala besar, tanda tangan jalan dan nomor rumah menjadi jauh lebih penting. Seringkali prioritas nama pemukiman ditentukan oleh ukuran populasi. Semakin besar, semakin penting tanda tangannya.
Generalisasi diperlukan tidak hanya untuk tanda tangan, tetapi juga untuk penanda yang menandai hasil pencarian di peta. Misalnya, ketika mencari "toko" di Moskow, ada lebih dari 15.000 hasil. Menandai semuanya di peta sekaligus jelas merupakan ide yang buruk.
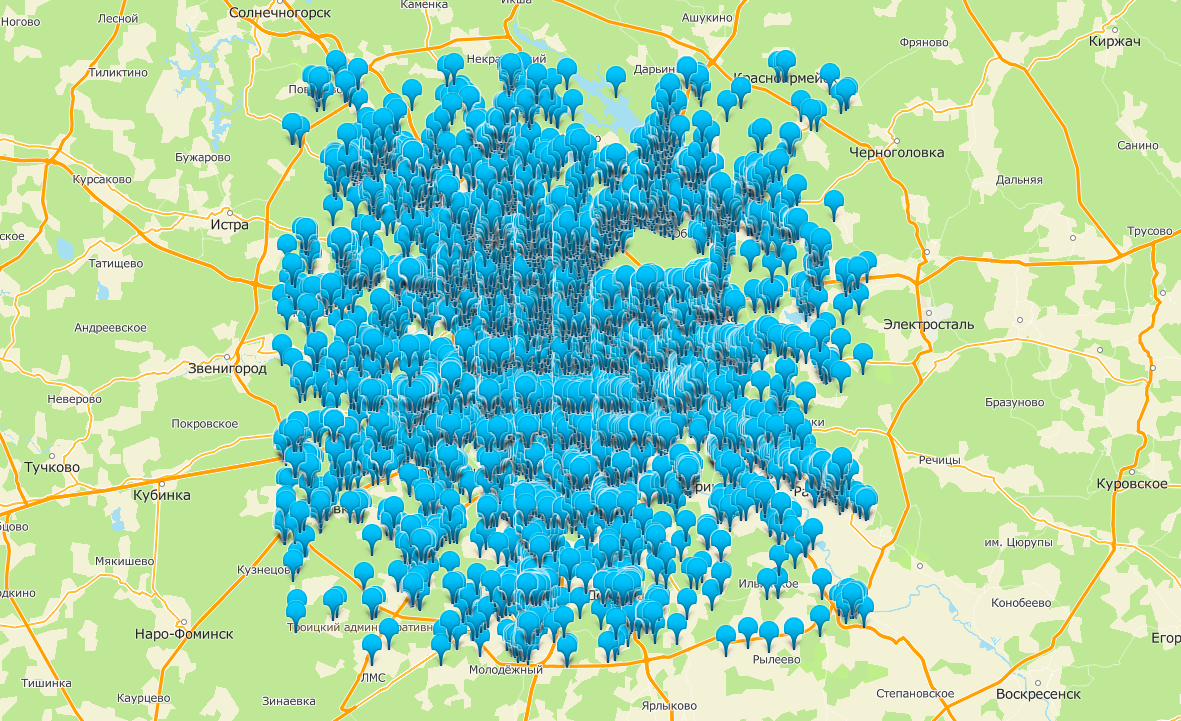
Semua toko Moskow di peta. Tidak ada cara untuk melakukannya tanpa generalisasi
Setiap interaksi pengguna dengan peta (memindahkan, memperbesar, memutar dan memiringkan) mengarah ke perubahan posisi penanda pada layar, sehingga Anda harus dapat menghitung ulang generalisasi dengan cepat. Karena itu, harus cepat.
Dalam artikel ini, menggunakan contoh generalisasi marker, saya akan menunjukkan berbagai cara untuk menyelesaikan masalah ini, yang digunakan pada waktu yang berbeda dalam proyek kami.
Pendekatan umum untuk generalisasi
- Proyeksikan setiap penanda pada bidang layar dan hitung untuknya sebuah batas - area persegi panjang yang ditempati layar.
- Urutkan penanda berdasarkan prioritas.
- Secara berurutan periksa setiap marker dan letakkan di layar jika tidak berpotongan dengan marker lain yang diletakkan di depannya.
Dengan poin 1, semuanya jelas - itu hanya perhitungan. Dengan item 2, kami juga beruntung: daftar marker yang datang kepada kami dari backend sudah diurutkan berdasarkan prioritas oleh algoritma pencarian. Hasil paling relevan yang paling mungkin menarik bagi pengguna berada di bagian atas hasil.
Masalah utama adalah pada paragraf 3: waktu penghitungan generalisasi dapat sangat bergantung pada bagaimana penerapannya.
Untuk mencari persimpangan antara penanda, kita memerlukan beberapa struktur data yang:
- Menyimpan batas penanda yang ditambahkan ke layar.
- Memiliki metode
insert(marker) untuk menambahkan penanda ke layar. - Ini memiliki metode
collides(marker) untuk memeriksa penanda untuk persimpangan dengan yang sudah ditambahkan ke layar.
Pertimbangkan beberapa implementasi dari struktur ini. Semua contoh lebih lanjut akan ditulis dalam TypeScript, yang kami gunakan di sebagian besar proyek kami. Dalam semua contoh, spidol akan diwakili oleh objek dari bentuk berikut:
interface Marker { minX: number; maxX: number; minY: number; maxY: number; }
Semua pendekatan yang dipertimbangkan akan menjadi implementasi dari antarmuka berikut:
interface CollisionDetector { insert(item: Marker): void; collides(item: Marker): boolean; }
Untuk membandingkan kinerja, waktu eksekusi kode berikut akan diukur:
for (const marker of markers) { if (!impl.collides(marker)) { impl.insert(marker); } }
Array markers akan berisi 100.000 elemen 30x50 yang ditempatkan secara acak pada bidang berukuran 1920x1080.
Kinerja akan diukur pada Macbook Air 2012.
Contoh pengujian dan kode yang disediakan dalam artikel juga diposting di GitHub .
Implementasi naif
Untuk memulai, pertimbangkan opsi paling sederhana, ketika marker diperiksa untuk persimpangan dengan yang lain dalam siklus sederhana.
class NaiveImpl implements CollisionDetector { private markers: Marker[]; constructor() { this.markers = []; } insert(marker: Marker): void { this.markers.push(marker); } collides(candidate: Marker): boolean { for (marker of this.markers) { if ( candidate.minX <= marker.maxX && candidate.minY <= marker.maxY && candidate.maxX >= marker.minX && candidate.maxY >= marker.minY ) { return true; } } return false; } }
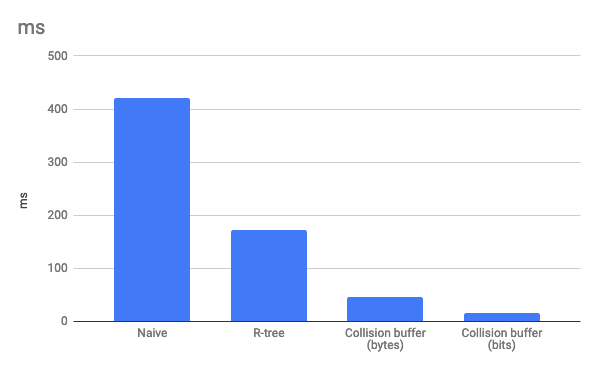
Waktu perhitungan generalisasi untuk 100.000 penanda: 420 ms . Terlalu banyak Bahkan jika perhitungan generalisasi dilakukan pada pekerja web dan tidak memblokir utas utama, penundaan seperti itu akan terlihat oleh mata, terutama karena operasi ini harus dilakukan setelah setiap gerakan kartu. Terlebih lagi, pada perangkat seluler dengan prosesor yang lemah, penundaannya bisa lebih besar.
Implementasi R-tree
Karena dalam implementasi yang naif setiap penanda diperiksa untuk persimpangan dengan semua yang sebelumnya, dalam kasus terburuk, kompleksitas algoritma ini kuadratik. Anda dapat memperbaikinya dengan menerapkan struktur data R-tree. Sebagai implementasi dari R-tree, ambil perpustakaan RBush :
import * as rbush from 'rbush'; export class RTreeImpl implements CollisionDetector { private tree: rbush.RBush<Marker>; constructor() { this.tree = rbush(); } insert(marker: Marker): void { this.tree.insert(marker); } collides(candidate: Marker): boolean { return this.tree.collides(candidate); } }
Waktu perhitungan generalisasi untuk 100.000 penanda: 173 ms . Secara signifikan lebih baik. Kami menggunakan pendekatan ini di Lantai (ini disebutkan dalam artikel saya sebelumnya ).
Visualisasi penyimpanan poin di R-tree. Pembagian hierarkis pesawat menjadi persegi panjang memungkinkan Anda untuk dengan cepat mempersempit area pencarian dan tidak memilah-milah semua objek
Implementasi collision buffer
Menggambar peta adalah tugas yang jauh lebih rumit daripada menggambar rencana satu bangunan. Ini juga memanifestasikan dirinya dalam generalisasi. Bahkan di pusat perbelanjaan terbesar di dunia, 1.000 organisasi jarang berada di lantai yang sama. Pada saat yang sama, permintaan pencarian sederhana di kota besar dapat menghasilkan puluhan ribu hasil.
Ketika kami mulai mengembangkan peta WebGL, kami mulai berpikir: apakah masih mungkin untuk mempercepat generalisasi. Sebuah ide menarik ditawarkan kepada kami oleh stellarator yang bekerja untuk kami: alih-alih R-tree, gunakan buffer untuk menyimpan status setiap piksel layar (sibuk atau tidak sibuk). Saat memasukkan penanda di layar, "isi" tempat yang sesuai di buffer, dan saat memeriksa kemungkinan menempel, periksa nilai piksel di area yang diperlukan.
class CollisionBufferByteImpl implements CollisionDetector { private buffer: Uint8Array; private height: number; constructor(width: number, height: number) { this.buffer = new Uint8Array(width * height); this.height = height; } insert(marker: Marker): void { const { minX, minY, maxX, maxY } = marker; for (let i = minX; i < maxX; i++) { for (let j = minY; j < maxY; j++) { buffer[i * this.height + j] = 1; } } } collides(candidate: Marker): boolean { const { minX, minY, maxX, maxY } = candidate; for (let i = minX; i < maxX; i++) { for (let j = minY; j < maxY; j++) { if (buffer[i * this.height + j]) { return true; } } } return false; } }
Waktu perhitungan generalisasi untuk 100.000 penanda: 46 ms .
Kenapa begitu cepat? Pendekatan ini tampaknya naif pada pandangan pertama, dan loop bersarang di kedua metode tidak seperti kode cepat. Namun, jika Anda melihat lebih dekat pada kode, Anda akan melihat bahwa waktu eksekusi kedua metode tidak tergantung pada jumlah total penanda. Jadi, untuk ukuran tetap marker WxH, kami memperoleh kompleksitas O (W * H * n), yaitu linear!
Pendekatan Penyangga Tabrakan Dioptimalkan
Anda dapat meningkatkan pendekatan sebelumnya dalam kecepatan dan memori yang digunakan, jika Anda memastikan bahwa satu piksel direpresentasikan dalam memori bukan oleh satu byte, tetapi dengan satu bit. Kode setelah optimasi ini, bagaimanapun, terasa rumit dan ditumbuhi sedikit keajaiban bit:
Kode sumber export class CollisionBufferBitImpl implements CollisionDetector { private width: number; private height: number; private buffer: Uint8Array; constructor(width: number, height: number) { this.width = Math.ceil(width / 8) * 8; this.height = height; this.buffer = new Uint8Array(this.width * this.height / 8); } insert(marker: Marker): void { const { minX, minY, maxX, maxY } = marker; const { width, buffer } = this; for (let j = minY; j < maxY; j++) { const start = j * width + minX >> 3; const end = j * width + maxX >> 3; if (start === end) { buffer[start] = buffer[start] | (255 >> (minX & 7) & 255 << (8 - (maxX & 7))); } else { buffer[start] = buffer[start] | (255 >> (minX & 7)); for (let i = start + 1; i < end; i++) { buffer[i] = 255; } buffer[end] = buffer[end] | (255 << (8 - (maxX & 7))); } } } collides(marker: Marker): boolean { const { minX, minY, maxX, maxY } = marker; const { width, buffer } = this; for (let j = minY; j < maxY; j++) { const start = j * width + minX >> 3; const end = j * width + maxX >> 3; let sum = 0; if (start === end) { sum = buffer[start] & (255 >> (minX & 7) & 255 << (8 - (maxX & 7))); } else { sum = buffer[start] & (255 >> (minX & 7)); for (let i = start + 1; i < end; i++) { sum = buffer[i] | sum; } sum = buffer[end] & (255 << (8 - (maxX & 7))) | sum; } if (sum !== 0) { return true; } } return false; } }
Waktu perhitungan generalisasi untuk 100.000 penanda: 16 ms . Seperti yang Anda lihat, kompleksitas logika membenarkan dirinya sendiri dan memungkinkan kami untuk mempercepat perhitungan generalisasi hampir tiga kali lipat.
Keterbatasan Buffer Tabrakan
Penting untuk dipahami bahwa buffer tabrakan bukanlah pengganti yang lengkap untuk R-tree. Ini memiliki fitur jauh lebih sedikit dan lebih banyak batasan:
- Anda tidak dapat memahami apa yang persis bersinggungan dengan marker. Buffer hanya menyimpan data tentang piksel mana yang sibuk dan mana yang tidak. Oleh karena itu, tidak mungkin untuk mengimplementasikan operasi yang mengembalikan daftar marker yang bersinggungan dengan yang diberikan.
- Tidak dapat menghapus penanda yang ditambahkan sebelumnya. Buffer tidak menyimpan data tentang berapa banyak marker dalam piksel yang diberikan. Oleh karena itu, tidak mungkin untuk menerapkan operasi menghapus penanda dari buffer dengan benar.
- Sensitivitas tinggi terhadap ukuran elemen. Jika Anda mencoba menambahkan penanda yang menempati seluruh layar ke buffer tabrakan, kinerja akan turun secara dramatis.
- Bekerja di area terbatas. Ukuran buffer diatur saat dibuat, dan tidak mungkin untuk menempatkan penanda di dalamnya yang melampaui ukuran ini. Oleh karena itu, ketika menggunakan pendekatan ini, perlu untuk memfilter penanda secara manual yang tidak muncul di layar.
Semua pembatasan ini tidak mengganggu solusi dari masalah generalisasi marker. Sekarang metode ini berhasil digunakan untuk spidol dalam versi beta 2gis.ru.
Namun, untuk menggeneralisasi tanda tangan utama pada peta, persyaratannya lebih kompleks. Sebagai contoh, bagi mereka perlu untuk memastikan bahwa ikon POI tidak dapat "membunuh" tanda tangannya sendiri. Karena buffer tabrakan tidak membedakan apa yang sebenarnya terjadi dengan persimpangan, itu tidak memungkinkan untuk mengimplementasikan logika tersebut. Karena itu, mereka harus meninggalkan solusi dengan RBush.
Kesimpulan
Artikel ini menunjukkan jalur yang kami gunakan dari solusi paling sederhana ke solusi yang digunakan sekarang.
Penggunaan R-tree adalah langkah penting pertama yang memungkinkan kami untuk mempercepat implementasi naif berkali-kali. Ini berfungsi dengan baik di Lantai, tetapi pada kenyataannya kami hanya menggunakan sebagian kecil dari kemampuan struktur data ini.
Setelah meninggalkan R-tree dan menggantinya dengan array dua dimensi yang sederhana, yang melakukan persis apa yang kita butuhkan, dan tidak ada yang lain, kita mendapatkan peningkatan produktivitas yang lebih besar.
Contoh ini menunjukkan kepada kita betapa pentingnya, memilih solusi untuk masalah dari beberapa pilihan, untuk memahami dan menyadari keterbatasan masing-masing. Keterbatasan itu penting dan bermanfaat, dan Anda tidak perlu takut pada mereka: dengan terampil membatasi diri Anda pada sesuatu yang tidak penting, Anda bisa mendapatkan manfaat besar sebagai imbalan di mana itu benar-benar dibutuhkan. Misalnya, untuk menyederhanakan solusi masalah, atau untuk melindungi diri Anda dari seluruh kelas masalah, atau, seperti dalam kasus kami, untuk meningkatkan produktivitas beberapa kali.