
Setiap proses yang terkait dengan database, cepat atau lambat akan menghadapi masalah dengan kinerja permintaan ke database ini.
Gudang data Rostelecom dibangun di atas Greenplum, sebagian besar perhitungan (transformasi) dilakukan oleh kueri sql, yang memulai (atau menghasilkan dan memulai) mekanisme ETL. DBMS memiliki nuansa tersendiri yang secara signifikan mempengaruhi kinerja. Artikel ini adalah upaya untuk menyoroti aspek paling kritis dari bekerja dengan Greenplum dalam hal kinerja dan berbagi pengalaman.
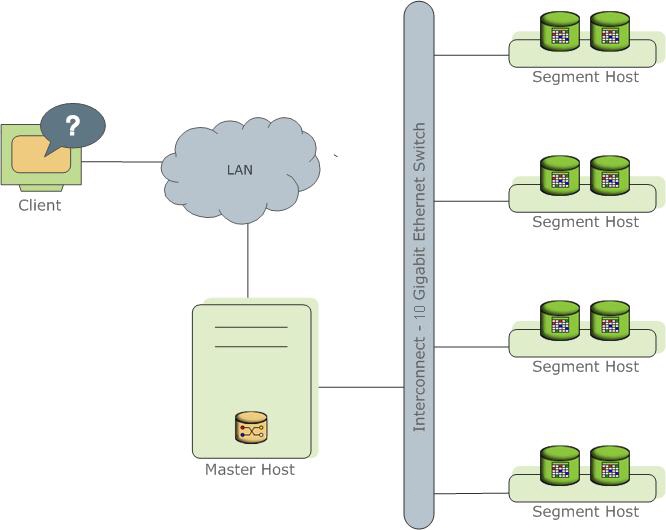
Singkatnya tentang GreenplumGreenplum - server basis data
MPP , yang intinya dibangun di PostgreSql.
Merupakan beberapa contoh berbeda dari proses PostgreSql (contoh). Salah satunya adalah titik masuk untuk klien dan disebut master instance (master), yang lainnya disebut instance Segment (segmen, instance Independen, masing-masing memiliki bagian data sendiri). Setiap server (host segmen) dapat berjalan dari satu ke beberapa layanan (segmen). Hal ini dilakukan untuk memanfaatkan sumber daya server dan prosesor secara lebih baik. Wisaya menyimpan metadata, bertanggung jawab untuk berkomunikasi dengan klien dengan data, dan juga mendistribusikan pekerjaan antar segmen.
Baca lebih lanjut di
dokumentasi resmi .
Selanjutnya dalam artikel ini akan ada banyak referensi untuk rencana permintaan. Informasi untuk Greenplum tersedia di
sini .
Cara menulis pertanyaan yang bagus di Greenplum (baik, atau setidaknya tidak cukup sedih)
Karena kita berurusan dengan database terdistribusi, penting bukan hanya bagaimana kueri sql ditulis, tetapi juga bagaimana data disimpan.
1. Distribusi
Data disimpan secara fisik di segmen yang berbeda. Anda bisa memisahkan data berdasarkan segmen secara acak atau dengan nilai fungsi hash suatu bidang atau satu set bidang.
Sintaks (saat membuat tabel):
DISTRIBUTED BY (some_field)
Atau lebih:
DISTRIBUTED RANDOMLY
Bidang distribusi harus memiliki selektivitas yang baik dan tidak memiliki nilai nol (atau memiliki nilai minimum), karena catatan dengan bidang tersebut akan didistribusikan pada satu segmen, yang dapat menyebabkan distorsi data.
Jenis bidang lebih disukai bilangan bulat. Bidang ini digunakan untuk bergabung dengan tabel. Hash join adalah salah satu cara terbaik untuk bergabung dengan tabel (dalam hal eksekusi permintaan), berfungsi paling baik dengan tipe data ini.
Untuk distribusi, disarankan untuk memilih tidak lebih dari dua bidang, dan, tentu saja, satu lebih baik dari dua. Bidang tambahan dalam kunci distribusi, pertama, memerlukan waktu tambahan untuk hashing, dan kedua, (dalam banyak kasus) akan memerlukan transfer data antar segmen saat menjalankan penggabungan.
Anda dapat menggunakan distribusi acak jika Anda tidak dapat memilih satu atau dua bidang yang sesuai, serta untuk label kecil. Tetapi kita harus memperhitungkan bahwa distribusi seperti itu paling baik untuk penyisipan data massal, dan bukan untuk satu catatan. GreenPlum mendistribusikan data sesuai dengan algoritma
siklik , dan memulai siklus baru untuk setiap operasi penyisipan, mulai dari segmen pertama, yang, dengan sisipan kecil yang sering, mengarah ke kemiringan (kemiringan data).
Dengan bidang distribusi yang dipilih dengan baik, semua perhitungan akan dilakukan pada segmen tersebut, tanpa mengirim data ke segmen lain. Juga, untuk penggabungan tabel yang optimal (gabung), nilai yang sama harus ditempatkan pada segmen yang sama.
Distribusi dalam gambarKunci distribusi yang baik: Kunci distribusi yang buruk:
Kunci distribusi yang buruk: Distribusi acak:
Distribusi acak:
Jenis bidang yang digunakan dalam gabungan harus sama di semua tabel.
Penting: jangan gunakan sebagai bidang distribusi yang digunakan untuk memfilter kueri di mana, karena dalam kasus ini beban selama kueri juga tidak akan didistribusikan secara merata.
2. Partisi
Partisi memungkinkan Anda untuk membagi tabel besar, seperti
fakta , menjadi bagian-bagian yang secara logis terpisah. Greenplum secara fisik membagi meja Anda ke dalam tabel yang terpisah, yang masing-masing dibagi menjadi beberapa segmen berdasarkan pengaturan dari hal.
Tabel harus dibagi menjadi beberapa bagian secara logis, untuk tujuan ini, pilih bidang yang sering digunakan di blok mana. Bahkan tabel ini akan menjadi periode. Dengan demikian, dengan akses yang tepat ke tabel dalam kueri, Anda hanya akan bekerja dengan sebagian dari seluruh tabel besar.
Secara umum, partisi adalah topik yang cukup terkenal, dan saya ingin menekankan bahwa Anda tidak harus memilih bidang yang sama untuk partisi dan distribusi. Ini akan mengarah pada fakta bahwa permintaan akan dieksekusi sepenuhnya pada satu segmen.
Sudah waktunya untuk pergi, pada kenyataannya, ke permintaan. Permintaan akan dieksekusi pada segmen sesuai dengan
rencana tertentu:
3. Pengoptimal
Greenplum memiliki dua pengoptimal, pengoptimal bawaan bawaan dan pengoptimal Orca pihak ketiga: GPORCA - Orca - Pengoptimal Permintaan Pivotal.
Aktifkan GPORCA berdasarkan permintaan:
set optimizer = on;
Sebagai aturan , pengoptimal GPORCA lebih baik daripada built-in. Ini bekerja lebih memadai dengan subqueries dan
CTE (lebih detail di
sini ).
Melakukan panggilan ke tabel besar dalam CTE dengan pemfilteran data maksimum (jangan lupa tentang pemangkasan partisi) dan daftar bidang yang ditentukan secara eksplisit - itu berfungsi dengan sangat baik.
Ini sedikit memodifikasi rencana permintaan, misalnya, jika tidak menampilkan partisi yang dipindai:
Pengoptimal Standar: Orca:
Orca:
GPORCA juga memungkinkan memperbarui bidang partisi / distribusi. Meskipun ada situasi ketika pengoptimal bawaan berkinerja lebih baik. Pengoptimal pihak ketiga sangat menuntut statistik, penting untuk tidak lupa
menganalisis .
Tidak peduli seberapa bagus pengoptimalnya, kueri yang ditulis dengan buruk bahkan tidak akan memperpanjang Orca:
4. Manipulasi dengan bidang di mana blok atau kondisi bergabung
Penting untuk diingat bahwa fungsi yang diterapkan ke bidang filter atau kondisi gabungan diterapkan ke
setiap rekaman.
Dalam kasus bidang partisi (misalnya, date_trunc ke bidang partisi - tanggal), bahkan GPORCA tidak dapat bekerja dengan benar dalam kasus ini,
kliping partisi tidak akan berfungsi.
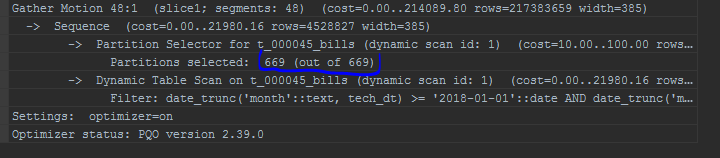
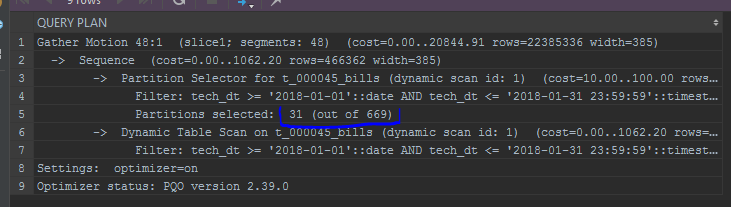 Saya juga menarik perhatian pada tampilan partisi. Pengoptimal bawaan akan menampilkan partisi dalam daftar:
Saya juga menarik perhatian pada tampilan partisi. Pengoptimal bawaan akan menampilkan partisi dalam daftar:
Terapkan fungsi dengan hati-hati ke konstanta dalam filter partisi yang sama. Contohnya adalah date_trunc yang sama:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))

GPORCA akan sepenuhnya mengatasi tipuan semacam itu dan akan bekerja dengan benar, pengoptimal standar tidak akan lagi mengatasinya. Namun, dengan membuat konversi tipe eksplisit, Anda dapat membuatnya berfungsi:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))::timestamp without time zone

Dan jika semuanya dilakukan dengan salah?
5. Gerakan
Jenis operasi lain yang dapat diamati dalam
rencana kueri adalah gerakan. Jadi ditandai pergerakan data antar segmen:
- Kumpulkan gerak - akan ditampilkan di hampir setiap rencana, berarti menggabungkan hasil eksekusi kueri dari semua segmen ke dalam satu aliran (biasanya ke master).
Dua tabel, didistribusikan oleh satu kunci, yang digunakan untuk bergabung, melakukan semua operasi pada segmen, tanpa memindahkan data. Sebaliknya, gerakan Siaran atau gerakan Redistribusi terjadi: - Gerakan siaran - setiap segmen mengirimkan salinan datanya ke segmen lain. Dalam situasi yang ideal, Siaran hanya terjadi untuk tabel kecil.
- Gerakan redistribusi - untuk bergabung dengan tabel besar yang didistribusikan melalui kunci yang berbeda, redistribusi dilakukan untuk membuat koneksi secara lokal. Untuk meja besar, ini bisa menjadi operasi yang cukup mahal.
Siaran dan Redistribusi adalah operasi yang sangat tidak menguntungkan. Mereka dieksekusi setiap kali permintaan dijalankan. Disarankan untuk menghindarinya. Setelah melihat poin seperti itu dalam rencana kueri, perlu memperhatikan kunci distribusi. Operasi yang berbeda dan serikat juga menyebabkan gerakan.
Daftar ini tidak lengkap dan didasarkan terutama pada pengalaman penulis. Tidak berhasil menemukan semuanya langsung di Internet pada satu waktu. Di sini saya mencoba mengidentifikasi faktor-faktor paling kritis yang mempengaruhi kinerja permintaan, dan untuk memahami mengapa dan mengapa ini terjadi.
Artikel ini disiapkan oleh tim manajemen data Rostelecom