Artikel pertama menjelaskan
mesin pengindeksan PostgreSQL , yang kedua berhubungan dengan
antarmuka metode akses , dan sekarang kami siap untuk membahas jenis indeks tertentu. Mari kita mulai dengan indeks hash.
Hash
Struktur
Teori umum
Banyak bahasa pemrograman modern menyertakan tabel hash sebagai tipe data dasar. Di luar, tabel hash terlihat seperti array biasa yang diindeks dengan tipe data apa pun (misalnya, string) daripada dengan angka integer. Indeks hash di PostgreSQL disusun dengan cara yang serupa. Bagaimana cara kerjanya?
Sebagai aturan, tipe data memiliki rentang yang sangat besar dari nilai yang diizinkan: berapa banyak string yang berbeda yang dapat kita bayangkan dalam kolom tipe "teks"? Pada saat yang sama, berapa banyak nilai yang berbeda sebenarnya disimpan dalam kolom teks dari beberapa tabel? Biasanya tidak begitu banyak.
Gagasan hashing adalah untuk mengasosiasikan sejumlah kecil (dari 0 hingga
N −1, nilai total
N ) dengan nilai tipe data apa pun. Asosiasi seperti ini disebut
fungsi hash . Angka yang diperoleh dapat digunakan sebagai indeks dari array reguler di mana referensi ke baris tabel (TIDs) akan disimpan. Elemen dari array ini disebut
bucket tabel hash - satu ember dapat menyimpan beberapa TID jika nilai indeks yang sama muncul di baris yang berbeda.
Semakin banyak fungsi hash mendistribusikan nilai sumber dengan bucket, semakin baik. Tetapi bahkan fungsi hash yang baik kadang-kadang akan menghasilkan hasil yang sama untuk nilai sumber yang berbeda - ini disebut
collision . Jadi, satu ember dapat menyimpan TIDs yang sesuai dengan kunci yang berbeda, dan oleh karena itu, TIDs yang diperoleh dari indeks perlu diperiksa ulang.
Sebagai contoh: fungsi hash untuk string apa yang bisa kita pikirkan? Biarkan jumlah ember menjadi 256. Kemudian misalnya nomor ember, kita dapat mengambil kode karakter pertama (dengan asumsi pengkodean karakter bita tunggal). Apakah ini fungsi hash yang baik? Jelas, tidak: jika semua string dimulai dengan karakter yang sama, semuanya akan masuk ke dalam satu ember, sehingga keseragaman keluar dari pertanyaan, semua nilai perlu diperiksa ulang, dan hashing tidak akan masuk akal. Bagaimana jika kita meringkas kode semua karakter modulo 256? Ini akan jauh lebih baik, tetapi jauh dari ideal. Jika Anda tertarik dengan internal fungsi hash di PostgreSQL, lihat definisi hash_any () di
hashfunc.c .
Struktur indeks
Mari kita kembali ke indeks hash. Untuk nilai beberapa tipe data (kunci indeks), tugas kami adalah menemukan TID yang cocok dengan cepat.
Saat memasukkan ke dalam indeks, mari kita hitung fungsi hash untuk kunci tersebut. Fungsi hash dalam PostgreSQL selalu mengembalikan tipe "integer", yang berada dalam kisaran 2
32 ≈ 4 miliar nilai. Jumlah bucket awalnya sama dengan dua dan meningkat secara dinamis untuk menyesuaikan dengan ukuran data. Nomor bucket dapat dihitung dari kode hash menggunakan bit aritmatika. Dan ini adalah ember tempat kita akan meletakkan TID kita.
Tapi ini tidak cukup karena TIDs yang cocok dengan kunci yang berbeda dapat dimasukkan ke dalam ember yang sama. Apa yang harus kita lakukan? Dimungkinkan untuk menyimpan nilai sumber kunci dalam ember, selain TID, tetapi ini akan secara signifikan meningkatkan ukuran indeks. Untuk menghemat ruang, alih-alih kunci, ember menyimpan kode hash kunci.
Saat mencari melalui indeks, kami menghitung fungsi hash untuk kunci dan mendapatkan nomor ember. Sekarang tinggal memeriksa isi ember dan mengembalikan hanya TUT yang cocok dengan kode hash yang sesuai. Ini dilakukan secara efisien karena pasangan "hash code - TID" yang disimpan telah dipesan.
Namun, dua kunci yang berbeda dapat terjadi tidak hanya untuk masuk ke satu ember, tetapi juga memiliki kode hash empat byte yang sama - tidak ada yang menghilangkan tabrakan. Oleh karena itu, metode akses meminta mesin pengindeksan umum untuk memverifikasi setiap TID dengan memeriksa kembali kondisi di baris tabel (mesin dapat melakukan ini bersama dengan pemeriksaan visibilitas).
Memetakan struktur data ke halaman
Jika kita melihat indeks yang dilihat oleh manajer cache buffer alih-alih dari perspektif perencanaan dan eksekusi permintaan, ternyata semua informasi dan semua baris indeks harus dimasukkan ke dalam halaman. Halaman indeks tersebut disimpan dalam cache buffer dan diusir dari sana dengan cara yang sama persis seperti halaman tabel.
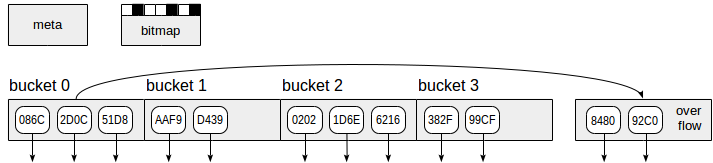
Indeks hash, seperti yang ditunjukkan pada gambar, menggunakan empat jenis halaman (persegi panjang abu-abu):
- Halaman meta - nomor halaman nol, yang berisi informasi tentang apa yang ada di dalam indeks.
- Halaman bucket - halaman utama indeks, yang menyimpan data sebagai pasangan "kode hash - TID".
- Halaman meluap - terstruktur dengan cara yang sama dengan halaman ember dan digunakan saat satu halaman tidak cukup untuk satu ember.
- Halaman Bitmap - yang melacak halaman overflow yang saat ini jelas dan dapat digunakan kembali untuk bucket lain.
Panah bawah mulai dari elemen halaman indeks mewakili TIDs, yaitu, referensi ke baris tabel.
Setiap kali indeks meningkat, PostgreSQL secara instan membuat dua kali lebih banyak bucket (dan karenanya, halaman) seperti yang terakhir dibuat. Untuk menghindari alokasi jumlah halaman yang berpotensi besar ini sekaligus, versi 10 membuat ukurannya bertambah lebih lancar. Adapun halaman overflow, mereka dialokasikan tepat ketika kebutuhan muncul dan dilacak dalam halaman bitmap, yang juga dialokasikan ketika kebutuhan muncul.
Perhatikan bahwa indeks hash tidak dapat mengurangi ukurannya. Jika kami menghapus beberapa baris yang diindeks, halaman yang dialokasikan tidak akan dikembalikan ke sistem operasi, tetapi hanya akan digunakan kembali untuk data baru setelah VACUUMING. Satu-satunya pilihan untuk mengurangi ukuran indeks adalah membangunnya kembali dari awal menggunakan perintah REINDEX atau VACUUM FULL.
Contoh
Mari kita lihat bagaimana indeks hash dibuat. Untuk menghindari menyusun tabel kami sendiri, mulai sekarang kami akan menggunakan
database demo transportasi udara, dan kali ini kami akan mempertimbangkan tabel penerbangan.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN ---------------------------------------------------- Bitmap Heap Scan on flights Recheck Cond: (flight_no = 'PG0001'::bpchar) -> Bitmap Index Scan on flights_flight_no_idx Index Cond: (flight_no = 'PG0001'::bpchar) (4 rows)
Apa yang tidak nyaman tentang implementasi indeks hash saat ini adalah bahwa operasi dengan indeks tidak dicatat dalam log tulis-depan (yang diperingatkan PostgreSQL ketika indeks dibuat). Karena itu, indeks hash tidak dapat dipulihkan setelah kegagalan dan tidak berpartisipasi dalam replikasi. Selain itu, indeks hash jauh di bawah "B-tree" dalam fleksibilitas, dan efisiensinya juga dipertanyakan. Jadi sekarang tidak praktis untuk menggunakan indeks tersebut.
Namun, ini akan berubah sejak musim gugur ini (2017) setelah PostgreSQL versi 10 dirilis. Dalam versi ini, indeks hash akhirnya mendapat dukungan untuk log write-ahead; selain itu alokasi memori dioptimalkan dan pekerjaan bersamaan dibuat lebih efisien.
Itu benar. Karena indeks hash PostgreSQL 10 telah mendapat dukungan penuh dan dapat digunakan tanpa batasan. Peringatan tidak ditampilkan lagi.
Hantaman semantik
Tetapi mengapa indeks hash bertahan hampir sejak kelahiran PostgreSQL menjadi 9,6 tidak dapat digunakan? Masalahnya adalah bahwa DBMS menggunakan ekstensif algoritma hashing (khususnya, untuk hash joins dan pengelompokan), dan sistem harus menyadari fungsi hash mana yang berlaku untuk tipe data mana. Tetapi korespondensi ini tidak statis, dan tidak dapat ditetapkan sekali dan untuk semua karena PostgreSQL mengizinkan tipe data baru untuk ditambahkan dengan cepat. Dan ini adalah metode akses oleh hash, di mana korespondensi ini disimpan, direpresentasikan sebagai asosiasi fungsi tambahan dengan keluarga operator.
demo=# select opf.opfname as opfamily_name, amproc.amproc::regproc AS opfamily_procedure from pg_am am, pg_opfamily opf, pg_amproc amproc where opf.opfmethod = am.oid and amproc.amprocfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_procedure;
opfamily_name | opfamily_procedure --------------------+-------------------- abstime_ops | hashint4 aclitem_ops | hash_aclitem array_ops | hash_array bool_ops | hashchar ...
Meskipun fungsi-fungsi ini tidak didokumentasikan, mereka dapat digunakan untuk menghitung kode hash untuk nilai tipe data yang sesuai. Misalnya, fungsi "hashtext" jika digunakan untuk keluarga operator "text_ops":
demo=# select hashtext('one');
hashtext ----------- 127722028 (1 row)
demo=# select hashtext('two');
hashtext ----------- 345620034 (1 row)
Properti
Mari kita lihat properti indeks hash, di mana metode akses ini memberikan sistem informasi tentang dirinya sendiri. Kami memberikan pertanyaan
terakhir kali . Sekarang kita tidak akan melampaui hasil:
name | pg_indexam_has_property ---------------+------------------------- can_order | f can_unique | f can_multi_col | f can_exclude | t name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t bitmap_scan | t backward_scan | t name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
Fungsi hash tidak mempertahankan relasi urutan: jika nilai fungsi hash untuk satu kunci lebih kecil dari untuk kunci lainnya, tidak mungkin untuk membuat kesimpulan bagaimana kunci itu sendiri dipesan. Oleh karena itu, secara umum indeks hash dapat mendukung satu-satunya operasi "sama dengan":
demo=# select opf.opfname AS opfamily_name, amop.amopopr::regoperator AS opfamily_operator from pg_am am, pg_opfamily opf, pg_amop amop where opf.opfmethod = am.oid and amop.amopfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_operator;
opfamily_name | opfamily_operator ---------------+---------------------- abstime_ops | =(abstime,abstime) aclitem_ops | =(aclitem,aclitem) array_ops | =(anyarray,anyarray) bool_ops | =(boolean,boolean) ...
Akibatnya, indeks hash tidak dapat mengembalikan data yang dipesan ("can_order", "orderable"). Indeks hash tidak memanipulasi NULL untuk alasan yang sama: operasi "sama dengan" tidak masuk akal untuk NULL ("search_nulls").
Karena indeks hash tidak menyimpan kunci (tetapi hanya kode hash mereka), maka indeks hash tidak dapat digunakan untuk akses hanya indeks ("dapat dikembalikan").
Metode akses ini tidak mendukung indeks multi-kolom ("can_multi_col").
Internal
Dimulai dengan versi 10, dimungkinkan untuk melihat internal indeks hash melalui ekstensi "
pageinspect ". Ini akan terlihat seperti:
demo=# create extension pageinspect;
Halaman meta (kami mendapatkan jumlah baris dalam indeks dan jumlah bucket maksimum yang digunakan):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type ---------------- metapage (1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket ---------+----------- 33121 | 127 (1 row)
Halaman ember (kami mendapatkan jumlah tupel hidup dan tupel mati, yaitu yang bisa disedot):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type ---------------- bucket (1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items ------------+------------ 407 | 0 (1 row)
Dan sebagainya. Tetapi hampir tidak mungkin untuk mencari tahu arti dari semua bidang yang tersedia tanpa memeriksa kode sumber. Jika Anda ingin melakukannya, Anda harus mulai dengan
README .
Baca terus .