Hai, nama saya Vladislav, dan saya anggota tim pengembangan
Tarantool . Tarantool adalah DBMS dan server aplikasi sekaligus. Hari ini saya akan menceritakan tentang bagaimana kami menerapkan penskalaan horizontal di Tarantool dengan menggunakan modul
VShard .
Beberapa pengetahuan dasar dulu.
Ada dua jenis penskalaan: horisontal dan vertikal. Dan ada dua jenis penskalaan horizontal: replikasi dan sharding. Replikasi memastikan penskalaan komputasi sedangkan sharding digunakan untuk penskalaan data.
Sharding juga dibagi menjadi dua jenis: sharding berbasis rentang dan sharding berbasis hash.
Sharding berbasis rentang menyiratkan bahwa beberapa kunci shard dihitung untuk setiap catatan cluster. Kunci beling diproyeksikan ke garis lurus yang dipisahkan ke dalam rentang dan dialokasikan ke node fisik yang berbeda.
Sharding berbasis hash kurang rumit: fungsi hash dihitung untuk setiap catatan dalam sebuah cluster; catatan dengan fungsi hash yang sama dialokasikan ke simpul fisik yang sama.
Saya akan fokus pada penskalaan horizontal menggunakan sharding berbasis hash.
Implementasi yang lebih lama
Tarantool Shard adalah modul asli kami untuk penskalaan horizontal. Ini menggunakan sharding berbasis hash sederhana dan kunci shard dihitung dengan kunci primer untuk semua catatan dalam sebuah cluster.
function shard_function(primary_key) return guava(crc32(primary_key), shard_count) end
Namun akhirnya Tarantool Shard menjadi tidak mampu menangani tugas-tugas baru.
Pertama, salah satu persyaratan akhirnya kami menjadi jaminan
lokalitas data terkait secara logis . Dengan kata lain, ketika kami memiliki data yang terkait secara logis, kami selalu ingin menyimpannya pada satu simpul fisik, terlepas dari topologi klaster dan perubahan penyeimbang. Tarantool Shard tidak dapat menjamin hal itu. Ini dihitung hash hanya dengan kunci primer, dan dengan demikian penyeimbangan kembali dapat menyebabkan pemisahan sementara catatan dengan hash yang sama karena perubahan tidak dilakukan secara atom.
Kurangnya lokalitas data adalah masalah utama bagi kami. Berikut ini sebuah contoh. Katakanlah ada bank tempat pelanggan membuka rekening. Informasi tentang akun dan pelanggan harus disimpan secara fisik bersama sehingga dapat diambil dalam satu permintaan atau diubah dalam satu transaksi tunggal, misalnya selama transfer uang. Jika kita menggunakan sharding tradisional Tarantool Shard, akan ada nilai fungsi hash yang berbeda untuk akun dan pelanggan. Data dapat berakhir pada node fisik yang terpisah. Ini benar-benar menyulitkan membaca dan bertransaksi dengan data pelanggan.
format = {{'id', 'unsigned'}, {'email', 'string'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}} box.schema.create_space('account', {format = format})
Pada contoh di atas, bidang id akun dan pelanggan bisa tidak konsisten. Mereka terhubung oleh bidang customer_id akun dan bidang id pelanggan. Bidang id yang sama akan melanggar batasan keunikan kunci utama akun. Dan Shard tidak dapat melakukan sharding dengan cara lain apa pun.
Masalah lain adalah
lambatnya pemasangan kembali , yang merupakan masalah mendasar dari semua pecahan hash. Intinya adalah bahwa ketika mengubah komponen cluster, fungsi beling berubah karena biasanya tergantung pada jumlah node. Jadi, ketika fungsi berubah, perlu untuk memeriksa semua catatan di cluster dan menghitung ulang fungsi. Mungkin juga diperlukan untuk mentransfer beberapa catatan. Dan selama transfer data, kita bahkan tidak tahu apakah catatan yang diperlukan? Dalam permintaan data telah ditransfer atau sedang ditransfer saat ini. Jadi, selama pengerasan ulang, perlu untuk membuat permintaan baca dengan fungsi shard lama dan baru. Permintaan ditangani dua kali lebih lambat, dan ini tidak dapat diterima.
Namun masalah lain dengan Tarantool Shard adalah ketersediaan rendah bacaan dalam kasus kegagalan simpul dalam set replika.
Solusi baru
Kami menciptakan
Tarantool VShard untuk menyelesaikan tiga masalah yang disebutkan di atas. Perbedaan utamanya adalah bahwa tingkat penyimpanan datanya divirtualisasi, yaitu penyimpanan fisik host penyimpanan virtual, dan catatan data dialokasikan di atas yang virtual. Penyimpanan ini disebut
ember . Pengguna tidak perlu khawatir tentang apa yang terletak pada node fisik yang diberikan. Ember adalah unit data atom tak terpisahkan, seperti tuple dalam pecahan tradisional. VShard selalu menyimpan seluruh bucket pada satu simpul fisik, dan selama pengulangan, ia memigrasikan semua data dari satu bucket secara atom. Metode ini memastikan lokalitas data. Kami hanya memasukkan data ke dalam satu ember, dan kami selalu dapat memastikan bahwa itu tidak akan dipisahkan selama perubahan cluster.

Bagaimana kita memasukkan data ke dalam satu ember? Mari tambahkan bidang id ember baru ke tabel untuk pelanggan bank kami. Jika nilai bidang ini sama untuk data terkait, semua catatan akan berada dalam satu ember. Keuntungannya adalah kita dapat menyimpan catatan dengan id ember yang sama di ruang yang berbeda, dan bahkan di mesin yang berbeda. Lokalitas data berdasarkan id ember dijamin terlepas dari metode penyimpanan.
format = {{'id', 'unsigned'}, {'email', 'string'}, {'bucket_id', 'unsigned'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}, {'bucket_id', 'unsigned'}} box.schema.create_space('account', {format = format})
Mengapa ini sangat penting? Saat menggunakan sharding tradisional, data akan diperluas ke berbagai penyimpanan fisik yang ada. Untuk contoh bank kami, kami harus menghubungi setiap node ketika meminta semua akun untuk pelanggan tertentu. Jadi kita mendapatkan kompleksitas baca O (N), di mana N adalah jumlah penyimpanan fisik. Sangat lambat.
Menggunakan bucket dan lokalitas oleh bucket memungkinkan untuk membaca data yang diperlukan dari satu node menggunakan satu permintaan - terlepas dari ukuran cluster.

Di VShard, Anda menghitung id ember Anda dan menetapkannya. Bagi sebagian orang, ini merupakan keuntungan, sementara yang lain menganggapnya sebagai kerugian. Saya percaya bahwa kemampuan untuk memilih fungsi Anda sendiri untuk perhitungan id ember adalah keuntungan.
Apa perbedaan utama antara pecahan tradisional dan pecahan virtual dengan ember?
Dalam kasus sebelumnya, ketika kita mengubah komponen cluster, kita memiliki dua status: yang sekarang (lama) dan yang baru untuk diimplementasikan. Dalam proses transisi, perlu tidak hanya untuk memigrasikan data, tetapi juga untuk menghitung ulang fungsi hash untuk setiap catatan. Ini sangat tidak nyaman karena setiap saat kita tidak tahu apakah data yang diperlukan sudah dimigrasi atau tidak. Lebih lanjut, metode ini tidak dapat diandalkan, dan perubahannya tidak bersifat atomik, karena migrasi atom dari sekumpulan catatan dengan nilai fungsi hash yang sama akan membutuhkan penyimpanan terus-menerus dari status migrasi jika diperlukan pemulihan. Akibatnya, ada konflik dan kesalahan, dan operasi harus dimulai ulang beberapa kali.
Sharding virtual jauh lebih sederhana. Kami tidak memiliki dua status gugus yang berbeda; kami hanya memiliki kondisi bucket. Cluster ini lebih fleksibel, dengan lancar bergerak dari satu kondisi ke kondisi lainnya. Ada lebih dari dua negara sekarang? (tidak jelas). Dengan transisi yang mulus, dimungkinkan untuk mengubah keseimbangan dengan cepat atau untuk menghapus penyimpanan yang baru ditambahkan. Artinya, kontrol penyeimbang telah sangat meningkat dan menjadi lebih granular.
Penggunaan
Katakanlah kita telah memilih fungsi untuk id ember kami dan telah mengunggah begitu banyak data ke dalam cluster sehingga tidak ada ruang yang tersisa. Sekarang kami ingin menambahkan beberapa node dan secara otomatis memindahkan data ke mereka. Begitulah cara kami melakukannya di VShard: pertama, kami memulai node baru dan menjalankan Tarantool di sana, lalu kami memperbarui konfigurasi VShard kami. Ini berisi informasi tentang setiap komponen cluster, setiap replika, set replika, master, URI yang ditugaskan dan banyak lagi. Sekarang kami menambahkan node baru kami ke file konfigurasi, dan menerapkannya ke semua node cluster menggunakan VShard.storage.cfg.
function create_user(email) local customer_id = next_id() local bucket_id = crc32(customer_id) box.space.customer:insert(customer_id, email, bucket_id) end function add_account(customer_id) local id = next_id() local bucket_id = crc32(customer_id) box.space.account:insert(id, customer_id, 0, bucket_id) end
Seperti yang Anda ingat, ketika mengubah jumlah node dalam sharding tradisional, fungsi shard itu sendiri juga berubah. Ini tidak terjadi di VShard. Di sini kami memiliki sejumlah penyimpanan virtual, atau ember. Ini adalah konstanta yang Anda pilih saat memulai cluster. Mungkin kelihatannya skalabilitas dibatasi, tetapi sebenarnya tidak. Anda dapat menentukan sejumlah besar ember, puluhan dan ratusan ribu. Hal penting yang perlu diketahui adalah bahwa setidaknya harus ada dua urutan besarnya lebih banyak ember daripada jumlah maksimum set replika yang pernah Anda miliki di cluster.
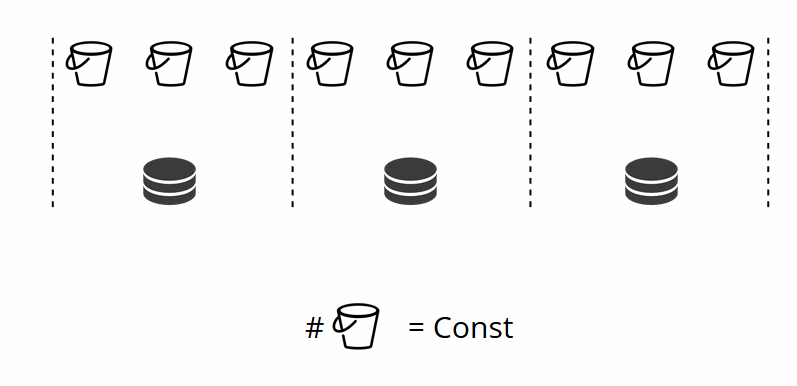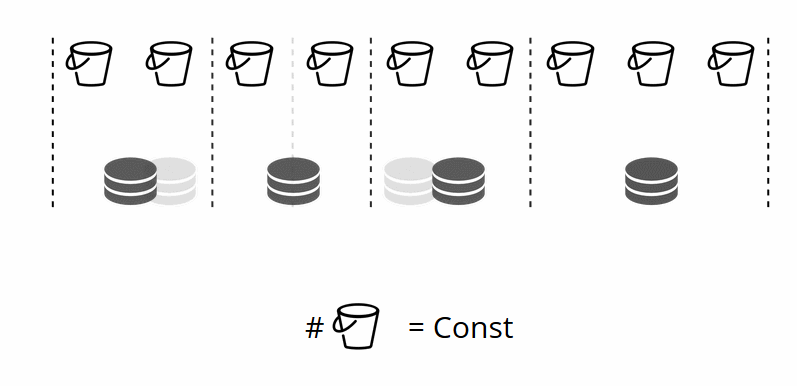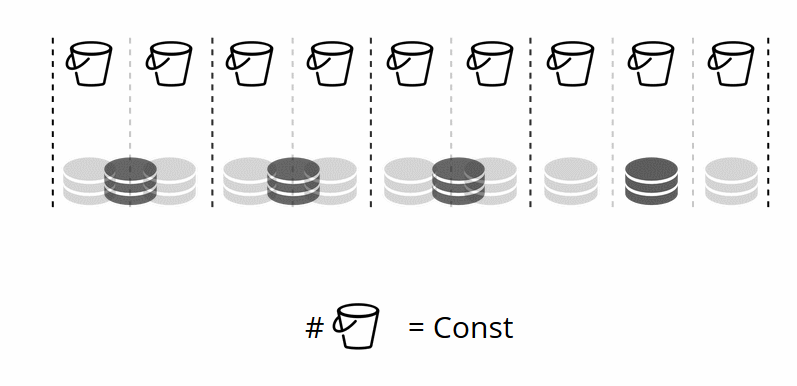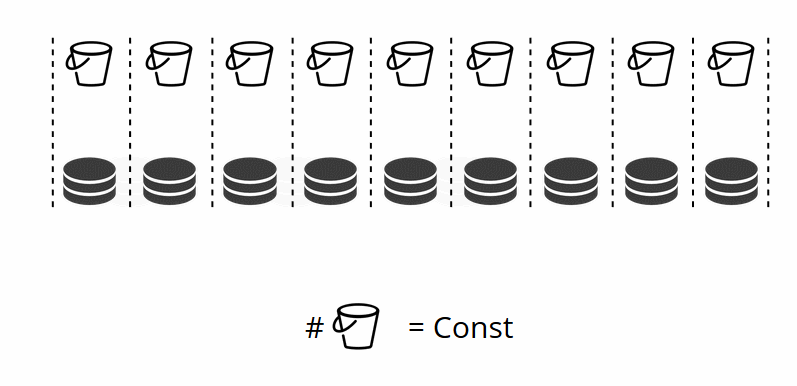
Karena jumlah penyimpanan virtual tidak berubah, dan fungsi beling hanya bergantung pada nilai ini, kami dapat menambahkan sebanyak mungkin penyimpanan fisik yang kami inginkan tanpa menghitung ulang fungsi beling.
Jadi bagaimana ember dialokasikan untuk penyimpanan fisik? Jika VShard.storage.cfg disebut, proses penyeimbangan kembali terbangun di salah satu node. Ini adalah proses analitik yang menghitung keseimbangan sempurna untuk cluster. Proses berjalan ke setiap simpul fisik dan mengambil jumlah embernya, dan kemudian membangun rute gerakan mereka untuk menyeimbangkan alokasi. Kemudian penyeimbang mengirimkan rute ke penyimpanan yang kelebihan beban, yang pada gilirannya mulai mengirim ember. Agak kemudian, gugus itu seimbang.
Dalam proyek dunia nyata, keseimbangan sempurna mungkin tidak dapat dicapai dengan mudah. Misalnya, satu set replika dapat berisi lebih sedikit data daripada yang lain karena memiliki kapasitas penyimpanan yang lebih sedikit. Dalam hal ini, VShard mungkin berpikir bahwa semuanya seimbang tetapi sebenarnya penyimpanan pertama akan kelebihan beban. Untuk mengatasi hal ini, kami telah menyediakan mekanisme untuk mengoreksi aturan keseimbangan melalui bobot. Bobot dapat diberikan ke set atau penyimpanan replika apa pun. Ketika penyeimbang memutuskan berapa banyak ember yang harus dikirim dan ke mana, ia mempertimbangkan
hubungan semua pasangan berat.
Misalnya, jika satu penyimpanan berbobot 100 dan yang lainnya 200, penyimpanan yang kedua akan menyimpan dua kali lebih banyak ember dibandingkan yang pertama. Harap dicatat bahwa saya secara khusus berbicara tentang
hubungan berat badan. Nilai absolut tidak memiliki pengaruh apa pun. Anda memilih bobot berdasarkan distribusi 100% dalam satu cluster: jadi 30% untuk satu penyimpanan akan menghasilkan 70% untuk yang lainnya. Anda dapat menggunakan kapasitas penyimpanan dalam gigabytes sebagai dasar, atau Anda dapat mengukur berat dalam jumlah ember. Yang paling penting adalah menjaga rasio yang diperlukan.

Metode ini memiliki efek samping yang menarik: jika penyimpanan ditetapkan nol berat, penyeimbang akan membuat penyimpanan ini mendistribusikan kembali semua embernya. Setelah itu, Anda dapat menghapus seluruh set replika dari konfigurasi.
Migrasi ember atom
Kami punya ember; ia menerima beberapa membaca dan menulis, dan pada saat tertentu, penyeimbang meminta migrasi ke penyimpanan lain. Ember berhenti menerima permintaan tulis, jika tidak akan diperbarui selama migrasi, lalu diperbarui lagi selama migrasi pembaruan, maka pembaruan akan diperbarui, dan seterusnya. Oleh karena itu, permintaan tulis diblokir, tetapi membaca dari ember masih dimungkinkan. Data sekarang sedang dimigrasikan ke lokasi baru. Ketika migrasi selesai, ember mulai menerima permintaan lagi. Masih ada di lokasi lama, tetapi ditandai sebagai sampah, dan kemudian pengumpul sampah menghapusnya sepotong demi sepotong.
Ada beberapa metadata yang tersimpan secara fisik di disk yang dikaitkan dengan setiap ember. Semua langkah yang dijelaskan di atas disimpan pada disk, dan apa pun yang terjadi pada penyimpanan, keadaan bucket akan secara otomatis dipulihkan.
Anda mungkin memiliki beberapa pertanyaan berikut:
- Apa yang terjadi pada permintaan yang bekerja dengan ember saat migrasi dimulai?
Ada dua jenis referensi dalam metadata masing-masing ember: RO dan RW. Ketika pengguna membuat permintaan ke ember, ia menunjukkan apakah pekerjaan itu harus dalam mode baca-saja atau dalam mode baca-tulis. Untuk setiap permintaan, penghitung referensi terkait ditingkatkan.
Mengapa kita perlu penghitung referensi untuk permintaan tulis? Katakanlah sebuah ember sedang dimigrasi, dan tiba-tiba pengumpul sampah ingin menghapusnya. Pengumpul sampah mengakui bahwa penghitung referensi di atas nol sehingga ember tidak akan dihapus. Ketika semua permintaan selesai, pemulung dapat melakukan tugasnya.
Penghitung referensi untuk penulisan juga memastikan bahwa migrasi bucket tidak akan dimulai jika setidaknya ada satu permintaan penulisan dalam proses. Tetapi sekali lagi, permintaan tulis bisa datang satu demi satu, dan ember tidak akan pernah dimigrasi. Jadi jika penyeimbang ingin memindahkan bucket, maka sistem memblokir permintaan penulisan baru sambil menunggu permintaan saat ini diselesaikan selama periode waktu habis tertentu. Jika permintaan tidak selesai dalam batas waktu yang ditentukan, sistem akan mulai menerima permintaan penulisan baru lagi sambil menunda migrasi bucket. Dengan cara ini, penyeimbang akan mencoba untuk memigrasi ember hingga migrasi berhasil.
VShard memiliki API bucket_ref tingkat rendah jika Anda membutuhkan lebih dari sekadar kemampuan tingkat tinggi. Jika Anda benar-benar ingin melakukan sesuatu sendiri, silakan merujuk ke API ini. - Apakah mungkin untuk membiarkan catatan tidak terblokir?
Tidak. Jika bucket berisi data penting dan membutuhkan akses tulis permanen, maka Anda harus memblokir migrasi sepenuhnya. Kami memiliki fungsi bucket_pin untuk melakukan hal itu. Ini pin ember ke set replika saat ini sehingga penyeimbang tidak dapat bermigrasi ember. Dalam hal ini, bucket yang berdekatan akan dapat bergerak tanpa kendala.

Kunci set replika adalah alat yang bahkan lebih kuat dari bucket_pin. Ini tidak lagi dilakukan dalam kode melainkan dalam konfigurasi. Kunci set replika menonaktifkan migrasi setiap ember masuk / keluar dari set replika. Jadi semua data akan tersedia secara permanen untuk penulisan.

VShard.router
VShard terdiri dari dua submodul: VShard.storage dan VShard.router. Kami dapat membuat dan skala ini secara mandiri dalam satu contoh. Saat meminta cluster, kami tidak tahu di mana ember yang diberikan berada, dan VShard.router akan mencarinya dengan id ember untuk kami.
Mari kita lihat kembali contoh kita, kelompok bank dengan rekening pelanggan. Saya ingin bisa mendapatkan semua akun pelanggan tertentu dari cluster. Ini membutuhkan fungsi standar untuk pencarian lokal:

Itu mencari semua akun pelanggan dengan id-nya. Sekarang saya harus memutuskan di mana saya harus menjalankan fungsinya. Untuk tujuan ini, saya menghitung id ember dengan pengidentifikasi pelanggan dalam permintaan saya, dan meminta VShard.router untuk memanggil fungsi dalam penyimpanan di mana ember dengan id ember target berada. Submodule memiliki tabel perutean yang menggambarkan lokasi ember di set replika. VShard.router mengalihkan permintaan saya.
Mungkin saja terjadi bahwa sharding dimulai pada saat yang tepat ini, dan ember mulai bergerak. Router di latar belakang secara bertahap memperbarui tabel dalam potongan besar dengan meminta tabel bucket saat ini dari penyimpanan.
Kami bahkan dapat meminta ember yang baru saja dimigrasi, di mana router belum memperbarui tabel peruteannya. Dalam hal ini, ia akan meminta penyimpanan lama, yang akan mengarahkan router ke penyimpanan lain, atau hanya akan menjawab bahwa ia tidak memiliki data yang diperlukan. Kemudian router akan pergi melalui setiap penyimpanan untuk mencari ember yang diperlukan. Dan kita bahkan tidak akan melihat kesalahan dalam tabel routing.
Baca failover
Mari kita ingat masalah awal kita:
- Tidak ada lokalitas data. Dipecahkan dengan ember.
- Proses resharding macet dan menahan semuanya. Kami menerapkan transfer data atom dengan menggunakan ember dan menyingkirkan perhitungan fungsi beling.
- Baca failover.
Masalah terakhir diatasi oleh VShard.router, didukung oleh subsistem baca failover otomatis.
Dari waktu ke waktu, router ping penyimpanan yang ditentukan dalam konfigurasi. Katakan misalnya, router tidak dapat melakukan ping salah satunya. Router memiliki koneksi cadangan panas untuk setiap replika, jadi jika replika saat ini tidak merespons, ia hanya beralih ke yang lain. Permintaan baca akan diproses secara normal karena kita dapat membaca replika (tetapi tidak menulis). Dan kita dapat menentukan prioritas untuk replika sebagai faktor bagi router untuk memilih failover untuk dibaca. Ini dilakukan dengan zonasi.

Kami menetapkan nomor zona untuk setiap replika dan setiap router dan menentukan tabel di mana kami menunjukkan jarak antara setiap pasangan zona. Ketika router memutuskan di mana ia harus mengirim permintaan baca, itu memilih replika di zona terdekat.
Ini seperti apa dalam konfigurasi:

Secara umum Anda dapat meminta replika apa pun, tetapi jika cluster besar, kompleks, dan sangat terdistribusi, maka zonasi dapat sangat berguna. Rak server yang berbeda dapat dipilih sebagai zona sehingga jaringan tidak kelebihan beban oleh lalu lintas. Atau, titik-titik yang terisolasi secara geografis dapat dipilih.
Zonasi juga membantu ketika replika menunjukkan perilaku yang berbeda. Misalnya, setiap set replika memiliki satu replika cadangan yang tidak boleh menerima permintaan tetapi hanya menyimpan salinan data. Dalam hal ini, kami menempatkannya di zona yang jauh dari semua router di tabel sehingga router tidak akan membahas replika ini kecuali jika benar-benar diperlukan.
Tulis kegagalan
Kita sudah bicara tentang read failover. Bagaimana dengan write failover saat mengganti master? Di VShard, gambarnya tidak semerah dulu: pemilihan master tidak diterapkan sehingga kita harus melakukannya sendiri. Ketika kita telah entah bagaimana menunjuk master, instance yang ditunjuk sekarang harus mengambil alih sebagai master. Kemudian kami memperbarui konfigurasi dengan menetapkan master = false untuk master lama, dan master = true untuk yang baru, menerapkan konfigurasi dengan menggunakan VShard.storage.cfg dan membaginya dengan setiap penyimpanan. Segala sesuatu yang lain dilakukan secara otomatis. Master lama berhenti menerima permintaan tulis dan mulai menyinkronkan dengan yang baru, karena mungkin ada data yang telah diterapkan pada master lama tetapi tidak pada yang baru. Setelah itu, master baru bertanggung jawab dan mulai menerima permintaan, dan master lama adalah replika. Beginilah cara menulis failover bekerja di VShard.
replicas = new_cfg.sharding[uud].replicas replicas[old_master_uuid].master = false replicas[new_master_uuid].master = true vshard.storage.cfg(new_cfg)
Bagaimana cara melacak berbagai acara ini?
VShard.storage.info dan VShard.router.info sudah cukup.
VShard.storage.info menampilkan informasi dalam beberapa bagian.
vshard.storage.info() --- - replicasets: <replicaset_2>: uuid: <replicaset_2> master: uri: storage@127.0.0.1:3303 <replicaset_1>: uuid: <replicaset_1> master: missing bucket: receiving: 0 active: 0 total: 0 garbage: 0 pinned: 0 sending: 0 status: 2 replication: status: slave Alerts: - ['MISSING_MASTER', 'Master is not configured for ''replicaset <replicaset_1>']
Bagian pertama adalah untuk replikasi. Di sini Anda dapat melihat status set replika tempat fungsi dipanggil: lag replikasinya, koneksi yang tersedia dan tidak tersedia, konfigurasi masternya, dll.
Di bagian ember, Anda dapat melihat secara real time jumlah ember yang dimigrasi ke / dari set replika saat ini, jumlah ember yang bekerja dalam mode biasa, jumlah ember yang ditandai sebagai sampah, dan jumlah ember yang disematkan.
Bagian Alerts menampilkan masalah yang VShard dapat menentukan sendiri: "master tidak dikonfigurasi," "ada tingkat redundansi tidak cukup," "master ada di sana, tetapi semua replika gagal," dll.
Dan bagian terakhir (q: apakah ini "status"?) Apakah lampu menyala merah ketika semuanya salah. Ini adalah angka dari nol hingga tiga, di mana angka yang lebih tinggi lebih buruk.
VShard.router.info memiliki bagian yang sama, tetapi artinya agak berbeda.
vshard.router.info() --- - replicasets: <replicaset_2>: replica: &0 status: available uri: storage@127.0.0.1:3303 uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7 bucket: available_rw: 500 uuid: <replicaset_2> master: *0 <replicaset_1>: replica: &1 status: available uri: storage@127.0.0.1:3301 uuid: 8a274925-a26d-47fc-9e1b-af88ce939412 bucket: available_rw: 400 uuid: <replicaset_1> master: *1 bucket: unreachable: 0 available_ro: 800 unknown: 200 available_rw: 700 status: 1 alerts: - ['UNKNOWN_BUCKETS', '200 buckets are not discovered']
Bagian pertama adalah untuk replikasi, meskipun tidak mengandung informasi tentang keterlambatan replikasi, tetapi informasi tentang ketersediaan: koneksi router ke set replika; koneksi panas dan koneksi cadangan jika master gagal; master yang dipilih; dan jumlah ember RW dan ember RO yang tersedia pada setiap set replika.
Bagian bucket menampilkan jumlah total kotak baca-tulis dan baca-saja yang saat ini tersedia untuk router ini; jumlah ember dengan lokasi yang tidak diketahui; dan jumlah ember dengan lokasi yang diketahui tetapi tanpa koneksi ke set replika yang diperlukan.
Bagian peringatan terutama menjelaskan koneksi, acara failover, dan bucket yang tidak dikenal.
Akhirnya, ada juga statusnya yang sederhana? Indikator dari nol hingga tiga.
Apa yang Anda perlukan untuk menggunakan VShard?
Pertama, Anda harus memilih jumlah ember yang konstan. Mengapa tidak atur saja ke int32_max? Karena metadata disimpan bersama dengan masing-masing ember, 30 byte dalam penyimpanan dan 16 byte pada router. Semakin banyak ember yang Anda miliki, semakin banyak ruang yang akan diambil oleh metadata. Tetapi pada saat yang sama, ukuran bucket akan lebih kecil, yang berarti granularity cluster yang lebih tinggi dan kecepatan migrasi per ember yang lebih tinggi. Jadi, Anda harus memilih apa yang lebih penting bagi Anda dan tingkat skalabilitas yang diperlukan.
Kedua, Anda harus memilih fungsi beling untuk menghitung id ember. Aturannya sama seperti ketika memilih fungsi beling dalam sharding tradisional, karena ember di sini sama dengan jumlah penyimpanan tetap dalam sharding tradisional. Fungsi harus mendistribusikan nilai output secara merata, jika tidak, pertumbuhan ukuran bucket tidak akan seimbang, dan VShard hanya beroperasi dengan jumlah bucket. Jika Anda tidak menyeimbangkan fungsi beling, maka Anda harus memindahkan data dari satu ember ke ember lainnya, dan mengubah fungsi beling. Jadi, Anda harus memilih dengan cermat.
Ringkasan
VShard memastikan:
- lokalitas data
- pengulangan atom
- fleksibilitas cluster yang lebih tinggi
- baca otomatis failover
- beberapa pengendali bucket.
VShard sedang dalam pengembangan aktif. Beberapa tugas yang direncanakan sudah dilaksanakan. Tugas pertama adalah
penyeimbangan beban router . Jika ada permintaan baca yang berat, tidak selalu disarankan untuk mengalaminya ke master. Router harus menyeimbangkan permintaan untuk replika baca yang berbeda dengan sendirinya.
Tugas kedua adalah
migrasi bucket tanpa kunci . Algoritme telah diterapkan yang membantu menjaga agar blokir tidak terblokir bahkan selama migrasi. Ember akan diblokir hanya di akhir untuk mendokumentasikan migrasi itu sendiri.
Tugas ketiga adalah
aplikasi atom konfigurasi . Tidak mudah atau atomik untuk menerapkan konfigurasi secara terpisah karena beberapa penyimpanan mungkin tidak tersedia, dan jika konfigurasi tidak diterapkan, apa yang akan kita lakukan selanjutnya? Itu sebabnya kami sedang mengerjakan mekanisme untuk transfer konfigurasi otomatis.