
Ketika mendiagnosis masalah dalam kluster Kubernetes, kita sering memperhatikan bahwa kadang-kadang salah satu dari node cluster gerimis * dan, tentu saja, ini jarang dan aneh. Jadi kami sampai pada kebutuhan akan alat yang akan melakukan
ping dari setiap node ke setiap node dan menyajikan hasil kerjanya dalam bentuk
metrik Prometheus . Kami hanya perlu menggambar grafik di Grafana dan dengan cepat melokalkan simpul yang gagal (dan, jika perlu, menghapus semua pod dari itu, dan kemudian melakukan pekerjaan yang sesuai **) ...
* Dengan "gerimis" Saya mengerti bahwa node dapat masuk ke status NotReady dan tiba-tiba kembali bekerja. Atau, misalnya, bagian dari lalu lintas di pod mungkin tidak mencapai pod di node tetangga.** Mengapa situasi seperti itu muncul? Salah satu penyebab umum mungkin masalah jaringan pada sakelar di pusat data. Sebagai contoh, sekali di Hetzner kami mengkonfigurasi vswitch, tetapi pada saat yang luar biasa salah satu node tidak lagi dapat diakses pada port vswitch ini: karena ini, ternyata node tersebut benar-benar tidak dapat diakses di jaringan lokal.Selain itu, kami ingin
meluncurkan layanan seperti itu secara langsung di Kubernetes , sehingga seluruh penyebaran dapat dilakukan dengan menggunakan pemasangan Helm-chart. (Mengantisipasi pertanyaan - jika menggunakan Ansible yang sama, kami harus menulis peran untuk berbagai lingkungan: AWS, GCE, bare metal ...) Setelah sedikit mencari di Internet untuk alat yang siap pakai untuk tugas tersebut, kami tidak menemukan sesuatu yang cocok. Karena itu, mereka membuat sendiri.
Script dan konfigurasi
Jadi, komponen utama dari solusi kami adalah
skrip yang memantau perubahan pada setiap node di bidang
.status.addresses dan, jika bidang telah berubah untuk beberapa simpul (mis. Simpul baru telah ditambahkan), mengirimkan nilai Helm ke bagan menggunakan daftar node ini dalam bentuk ConfigMap:
--- apiVersion: v1 kind: ConfigMap metadata: name: node-ping-config namespace: kube-prometheus data: nodes.json: > {{ .Values.nodePing.nodes | toJson }}
Skrip python itu sendiri: Ini
berjalan pada setiap node dan mengirimkan paket ICMP ke semua instance cluster Kubernetes lainnya 2 kali per detik, dan hasilnya ditulis ke file teks.
Script termasuk dalam
gambar Docker :
FROM python:3.6-alpine3.8 COPY rootfs / WORKDIR /app RUN pip3 install --upgrade pip && pip3 install -r requirements.txt && apk add --no-cache fping ENTRYPOINT ["python3", "/app/node-ping.py"]
Selain itu,
ServiceAccount telah dibuat dan peran untuk itu, yang memungkinkan hanya daftar node yang akan diterima (untuk mengetahui alamat mereka):
--- apiVersion: v1 kind: ServiceAccount metadata: name: node-ping namespace: kube-prometheus --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kube-prometheus:node-ping rules: - apiGroups: [""] resources: ["nodes"] verbs: ["list"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kube-prometheus:kube-node-ping subjects: - kind: ServiceAccount name: node-ping namespace: kube-prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-prometheus:node-ping
Akhirnya, Anda memerlukan
DaemonSet , yang berjalan di semua instance dari cluster:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: node-ping namespace: kube-prometheus labels: tier: monitoring app: node-ping version: v1 spec: updateStrategy: type: RollingUpdate template: metadata: labels: name: node-ping spec: terminationGracePeriodSeconds: 0 tolerations: - operator: "Exists" serviceAccountName: node-ping priorityClassName: cluster-low containers: - resources: requests: cpu: 0.10 image: private-registry.flant.com/node-ping/node-ping-exporter:v1 imagePullPolicy: Always name: node-ping env: - name: MY_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName - name: PROMETHEUS_TEXTFILE_DIR value: /node-exporter-textfile/ - name: PROMETHEUS_TEXTFILE_PREFIX value: node-ping_ volumeMounts: - name: textfile mountPath: /node-exporter-textfile - name: config mountPath: /config volumes: - name: textfile hostPath: path: /var/run/node-exporter-textfile - name: config configMap: name: node-ping-config imagePullSecrets: - name: antiopa-registry
Ringkasan stroke dalam kata-kata:
- Hasil skrip Python - yaitu file teks ditempatkan pada mesin host di direktori
/var/run/node-exporter-textfile textfile masuk ke DaemonSet simpul-eksportir. Argumen untuk menjalankannya menunjukkan --collector.textfile.directory /host/textfile , di mana /host/textfile adalah hostPath di /var/run/node-exporter-textfile . (Anda dapat membaca tentang pengoleksi file teks di simpul-eksportir di sini .) - Akibatnya, simpul-eksportir membaca file-file ini, dan Prometheus mengumpulkan semua data dari simpul-eksportir.
Apa yang terjadi
Sekarang - untuk hasil yang ditunggu-tunggu. Ketika metrik tersebut dibuat, kita dapat melihatnya dan, tentu saja, menggambar grafik visual. Ini adalah tampilannya.
Pertama, ada blok umum dengan kemampuan (menggunakan pemilih) untuk memilih daftar node
dari mana ping dilakukan dan
di mana. Ini adalah
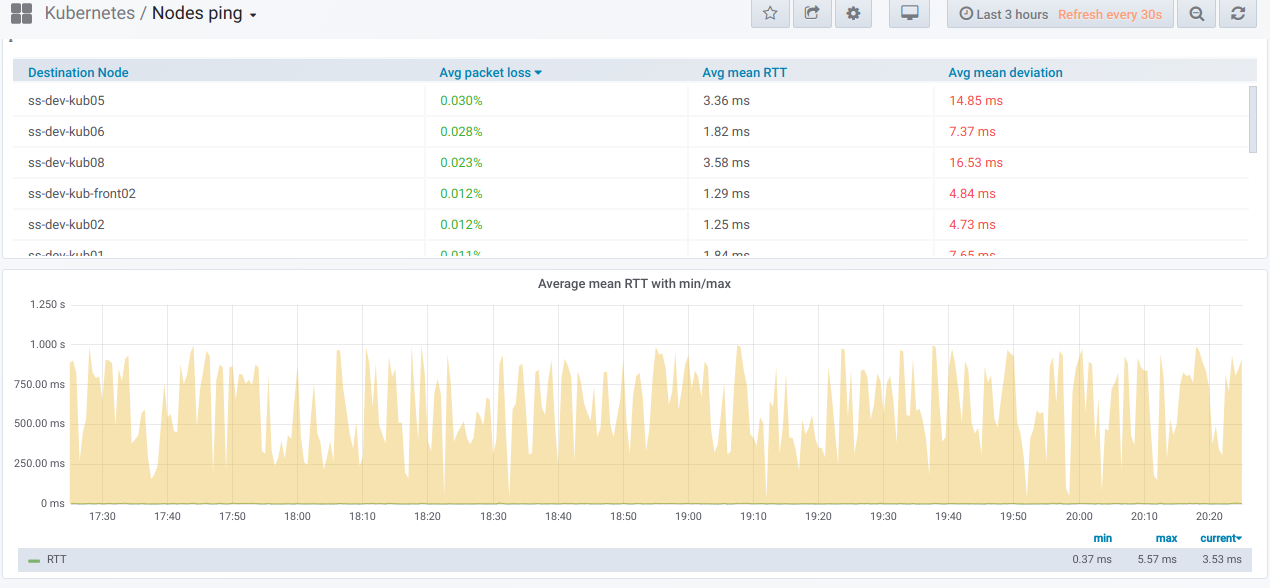
tabel ringkasan untuk melakukan ping antara node yang dipilih untuk periode yang ditentukan dalam dasbor Grafana:
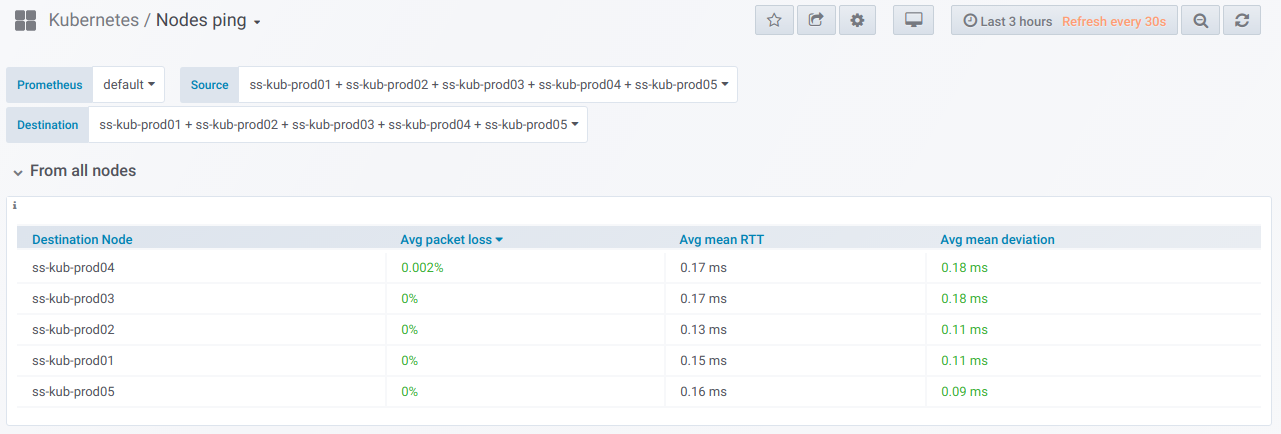
Dan di sini adalah grafik dengan informasi umum
tentang node yang dipilih :
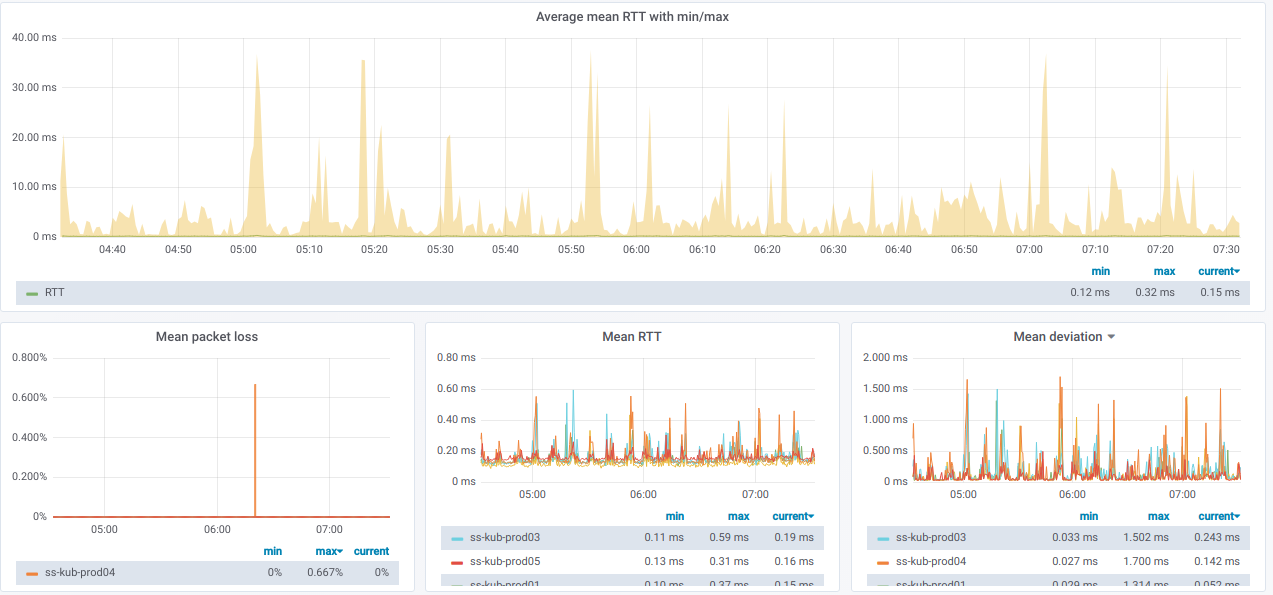
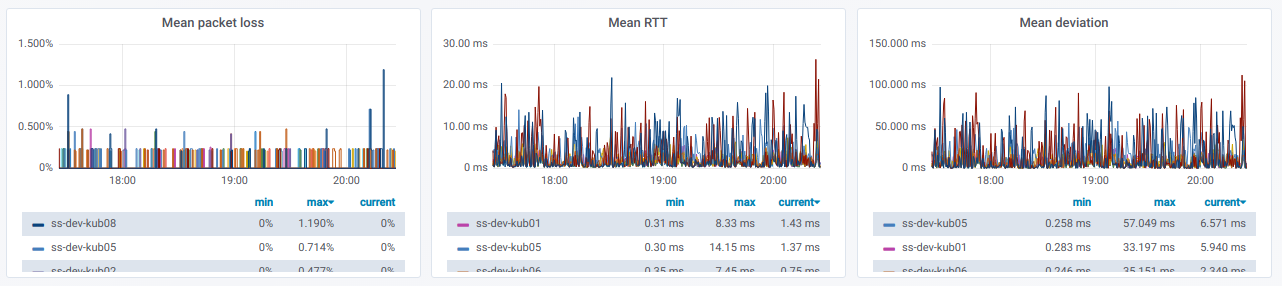
Kami juga memiliki daftar garis, yang masing-masing adalah grafik
untuk satu simpul terpisah dari pemilih
simpul Sumber :

Jika Anda memperluas garis seperti itu, Anda dapat melihat informasi tentang ping
dari node tertentu ke semua yang dipilih dalam pemilih
node Destination :
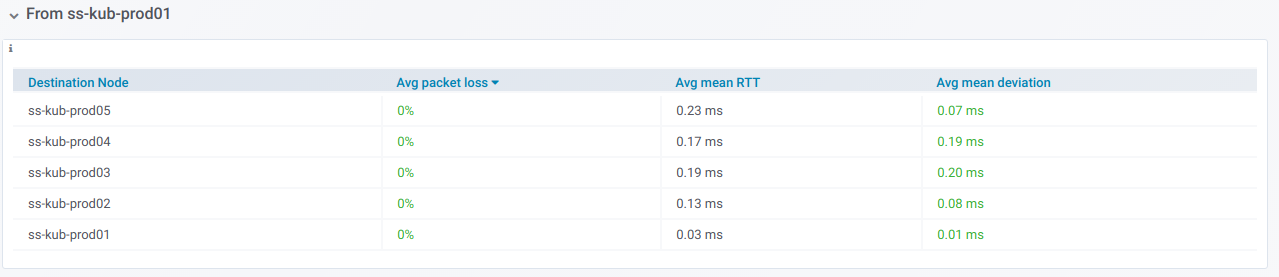
Informasi ini dalam bentuk grafik:
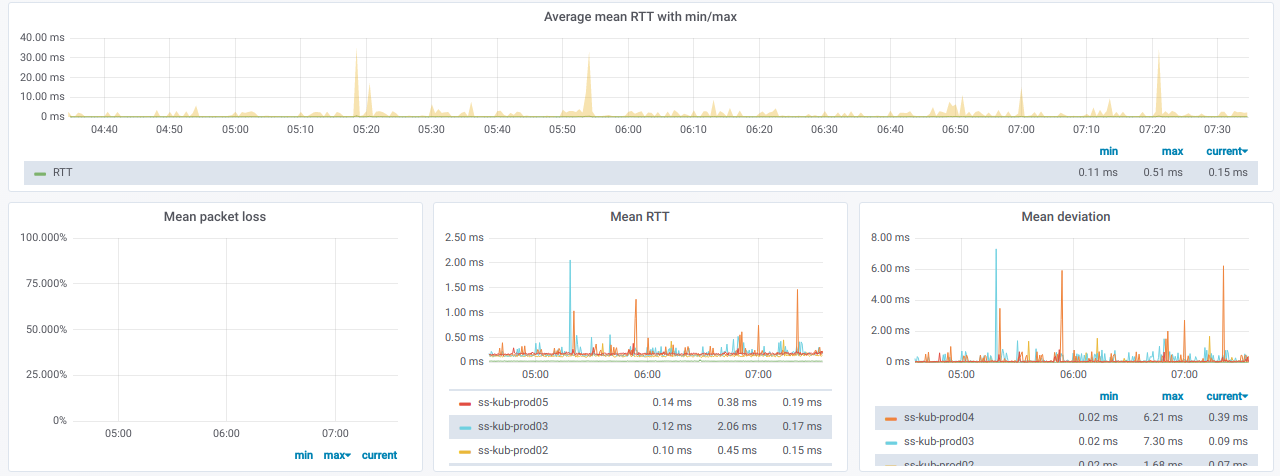
Akhirnya, seperti apa grafik yang disayangi dengan ping yang buruk di antara node?
Jika Anda mengamati ini di lingkungan nyata - inilah saatnya untuk mencari tahu alasannya.
PS
Baca juga di blog kami: