Teman-teman, pada akhir Maret kami meluncurkan aliran baru pada kursus
"Data Scientist" . Dan sekarang, kami mulai membagikan materi yang bermanfaat di kursus dengan Anda.
PendahuluanMengingat pengalaman awal dari hasrat saya untuk pembelajaran mesin (ML), saya dapat mengatakan bahwa banyak upaya dilakukan untuk membangun model yang sangat bagus. Saya berkonsultasi dengan para ahli di bidang ini untuk memahami bagaimana meningkatkan model saya, memikirkan fungsi yang diperlukan, mencoba memastikan bahwa semua tips yang mereka usulkan dipertimbangkan. Tapi tetap saja saya mengalami masalah.
Bagaimana cara mengimplementasikan model dalam proyek nyata? Saya tidak punya ide tentang skor ini. Semua literatur yang saya pelajari sampai saat ini hanya berfokus pada peningkatan model. Saya tidak melihat langkah selanjutnya dalam perkembangan mereka.

Itu sebabnya saya menulis panduan ini sekarang. Saya ingin Anda menghadapi masalah yang saya temui pada waktu saya, tetapi saya dapat dengan cepat menyelesaikannya. Menjelang akhir artikel ini, saya akan menunjukkan kepada Anda bagaimana menerapkan model pembelajaran mesin menggunakan kerangka kerja Flask di Python.
Isi- Opsi implementasi untuk model pembelajaran mesin.
- Apa itu API?
- Menginstal lingkungan Python dan informasi dasar tentang Flask.
- Menciptakan model pembelajaran mesin.
- Model Pembelajaran Mesin Penghematan: Serialisasi dan Deserialisasi.
- Membuat API menggunakan Flask.
Opsi implementasi untuk model pembelajaran mesin.
Dalam kebanyakan kasus, penggunaan model pembelajaran mesin yang sebenarnya adalah bagian utama dari pengembangan, bahkan jika itu hanya komponen kecil dari sistem distribusi email otomatis atau chatbot. Terkadang ada saat-saat ketika hambatan implementasi tampaknya tidak dapat diatasi.
Misalnya, sebagian besar spesialis ML menggunakan R atau Python untuk penelitian ilmiah mereka. Namun, insinyur perangkat lunak yang menggunakan tumpukan teknologi yang sama sekali berbeda akan menjadi konsumen model ini. Ada dua opsi yang dapat mengatasi masalah ini:
Opsi 1: Tulis ulang semua kode dalam bahasa yang bekerja dengan insinyur pengembangan. Kedengarannya logis, tetapi butuh banyak waktu dan upaya untuk mereplikasi model yang dikembangkan. Pada akhirnya, ternyata hanya buang-buang waktu saja. Sebagian besar bahasa, seperti JavaScript, tidak memiliki perpustakaan yang nyaman untuk bekerja dengan ML. Oleh karena itu, itu akan menjadi solusi rasional untuk tidak menggunakan opsi ini.
Opsi 2: Gunakan API. API Jaringan memecahkan masalah bekerja dengan aplikasi dalam berbagai bahasa. Jika pengembang front-end perlu menggunakan model pembelajaran mesin Anda untuk membuat aplikasi web pada dasarnya, mereka hanya perlu mendapatkan URL server tujuan yang membahas API.
Apa itu API?Dengan kata sederhana, API (Application Programming Interface) adalah semacam kontrak antara dua program, yang mengatakan bahwa jika program pengguna memberikan data input dalam format tertentu, maka program pengembang (API) melewatinya sendiri dan menyediakan data output kepada pengguna.
Anda akan dapat membaca beberapa artikel sendiri, yang menggambarkan dengan baik mengapa API merupakan pilihan yang cukup populer di kalangan pengembang.
Sebagian besar penyedia layanan cloud dan perusahaan yang lebih kecil dan fokus pada pembelajaran mesin menyediakan API siap pakai. Mereka memenuhi kebutuhan pengembang yang tidak memahami pembelajaran mesin, tetapi ingin mengintegrasikan teknologi ini ke dalam solusi mereka.
Misalnya, salah satu penyedia API ini adalah Google dengan
Google Vision API-nya .
Yang perlu dilakukan pengembang hanyalah memanggil API REST (Representational State Transfer) menggunakan SDK yang disediakan oleh Google. Lihat apa yang dapat Anda lakukan dengan menggunakan
Google Vision API .
Kedengarannya bagus, bukan? Pada artikel ini, kita akan mengetahui cara membuat API Anda sendiri menggunakan Flask, kerangka kerja Python.
Catatan : Flask bukan satu-satunya kerangka kerja jaringan untuk tujuan ini. Ada juga Django, Falcon, Hug dan banyak lainnya yang tidak disebutkan dalam artikel ini. Misalnya, untuk R ada paket yang disebut
tukang ledengMenginstal lingkungan Python dan informasi dasar tentang Flask.1) Menciptakan lingkungan virtual menggunakan Anaconda. Jika Anda perlu membuat lingkungan virtual Anda sendiri untuk Python dan mempertahankan status dependensi yang diperlukan, Anaconda menawarkan solusi yang bagus untuk ini. Selanjutnya akan bekerja dengan baris perintah.
- Di sini Anda akan menemukan installer miniconda untuk Python;
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.shbash Miniconda3-latest-Linux-x86_64.sh- Ikuti urutan pertanyaan.
source .bashrc- Jika Anda mengetik:
conda , Anda dapat melihat daftar perintah dan bantuan yang tersedia. - Untuk membuat lingkungan baru, ketik:
conda create --name <environment-name> python=3.6 - Ikuti langkah-langkah yang akan Anda lakukan dan pada akhirnya masukkan:
source activate <environment-name> - Instal paket Python yang diperlukan. Yang paling penting adalah labu dan gunicorn.
2) Kami akan mencoba membuat aplikasi Labu “Hello world” sederhana kami menggunakan gunicorn .- Buka editor teks favorit Anda dan buat file
hello-world.py di folder tersebut - Tulis kode berikut:
"""Filename: hello-world.py """ from flask import Flask app = Flask(__name__) @app.route('/users/<string:username>') def hello_world(username=None): return("Hello {}!".format(username))
- Simpan file dan kembali ke terminal.
- Untuk meluncurkan API, jalankan di terminal:
gunicorn --bind 0.0.0.0:8000 hello-world:app - Jika Anda mendapatkan yang berikut ini, maka Anda berada di jalur yang benar:

- Di browser, masukkan yang berikut ini:
https://localhost:8000/users/any-name

Hore! Anda menulis program Flask pertama Anda! Karena Anda sudah memiliki pengalaman dengan langkah-langkah sederhana ini, kami dapat membuat titik akhir jaringan yang dapat diakses secara lokal.
Dengan menggunakan Flask, kita dapat membungkus model kita dan menggunakannya sebagai API Web. Jika kita ingin membuat aplikasi jaringan yang lebih kompleks (misalnya, dalam JavaScript), maka kita perlu menambahkan beberapa perubahan.
Menciptakan model pembelajaran mesin.- Untuk memulai, mari kita lihat kompetisi pembelajaran mesin Prediksi Pinjaman . Tujuan utama adalah untuk menyiapkan pipa pra-pemrosesan dan membuat model ML untuk memfasilitasi tugas prediksi selama penyebaran.
import os import json import numpy as np import pandas as pd from sklearn.externals import joblib from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.base import BaseEstimator, TransformerMixin from sklearn.ensemble import RandomForestClassifier from sklearn.pipeline import make_pipeline import warnings warnings.filterwarnings("ignore")
- Simpan dataset dalam folder:
!ls /home/pratos/Side-Project/av_articles/flask_api/data/
test.csv training.csv
data = pd.read_csv('../data/training.csv')
list(data.columns)
['Loan_ID', 'Gender', 'Married', 'Dependents', 'Education', 'Self_Employed', 'ApplicantIncome', 'CoapplicantIncome', 'LoanAmount', 'Loan_Amount_Term', 'Credit_History', 'Property_Area', 'Loan_Status']
data.shape
(614, 13)
ul>
Temukan nilai null / Nan di kolom:
for _ in data.columns: print("The number of null values in:{} == {}".format(_, data[_].isnull().sum()))
The number of null values in:Loan_ID == 0 The number of null values in:Gender == 13 The number of null values in:Married == 3 The number of null values in:Dependents == 15 The number of null values in:Education == 0 The number of null values in:Self_Employed == 32 The number of null values in:ApplicantIncome == 0 The number of null values in:CoapplicantIncome == 0 The number of null values in:LoanAmount == 22 The number of null values in:Loan_Amount_Term == 14 The number of null values in:Credit_History == 50 The number of null values in:Property_Area == 0 The number of null values in:Loan_Status == 0
- Langkah selanjutnya adalah membuat kumpulan data untuk pelatihan dan pengujian:
red_var = ['Gender','Married','Dependents','Education','Self_Employed','ApplicantIncome','CoapplicantIncome',\ 'LoanAmount','Loan_Amount_Term','Credit_History','Property_Area'] X_train, X_test, y_train, y_test = train_test_split(data[pred_var], data['Loan_Status'], \ test_size=0.25, random_state=42)
- Untuk memastikan bahwa semua langkah pra-pemrosesan selesai dengan benar bahkan setelah kami bereksperimen, dan kami tidak melewatkan apa pun selama prediksi, kami akan membuat evaluator Scikit-learning kami sendiri untuk pra-pemrosesan (pra-pemrosesan penduga belajar-Scikit) .
Untuk memahami bagaimana kami membuatnya, baca yang
berikut ini .
from sklearn.base import BaseEstimator, TransformerMixin class PreProcessing(BaseEstimator, TransformerMixin): """Custom Pre-Processing estimator for our use-case """ def __init__(self): pass def transform(self, df): """Regular transform() that is a help for training, validation & testing datasets (NOTE: The operations performed here are the ones that we did prior to this cell) """ pred_var = ['Gender','Married','Dependents','Education','Self_Employed','ApplicantIncome',\ 'CoapplicantIncome','LoanAmount','Loan_Amount_Term','Credit_History','Property_Area'] df = df[pred_var] df['Dependents'] = df['Dependents'].fillna(0) df['Self_Employed'] = df['Self_Employed'].fillna('No') df['Loan_Amount_Term'] = df['Loan_Amount_Term'].fillna(self.term_mean_) df['Credit_History'] = df['Credit_History'].fillna(1) df['Married'] = df['Married'].fillna('No') df['Gender'] = df['Gender'].fillna('Male') df['LoanAmount'] = df['LoanAmount'].fillna(self.amt_mean_) gender_values = {'Female' : 0, 'Male' : 1} married_values = {'No' : 0, 'Yes' : 1} education_values = {'Graduate' : 0, 'Not Graduate' : 1} employed_values = {'No' : 0, 'Yes' : 1} property_values = {'Rural' : 0, 'Urban' : 1, 'Semiurban' : 2} dependent_values = {'3+': 3, '0': 0, '2': 2, '1': 1} df.replace({'Gender': gender_values, 'Married': married_values, 'Education': education_values, \ 'Self_Employed': employed_values, 'Property_Area': property_values, \ 'Dependents': dependent_values}, inplace=True) return df.as_matrix() def fit(self, df, y=None, **fit_params): """Fitting the Training dataset & calculating the required values from train eg: We will need the mean of X_train['Loan_Amount_Term'] that will be used in transformation of X_test """ self.term_mean_ = df['Loan_Amount_Term'].mean() self.amt_mean_ = df['LoanAmount'].mean() return self
- Konversi
y_train dan y_test ke np.array :
y_train = y_train.replace({'Y':1, 'N':0}).as_matrix() y_test = y_test.replace({'Y':1, 'N':0}).as_matrix()
Mari kita buat pipeline untuk memastikan bahwa semua langkah preprocessing yang kita lakukan adalah pekerjaan evaluator scikit-learn.
pipe = make_pipeline(PreProcessing(), RandomForestClassifier())
pipe
Pipeline(memory=None, steps=[('preprocessing', PreProcessing()), ('randomforestclassifier', RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False))])
Untuk mencari parameter hiper yang sesuai (derajat untuk objek polinomial dan alfa untuk tepi), kami akan melakukan pencarian kisi (Pencarian Grid):
param_grid = {"randomforestclassifier__n_estimators" : [10, 20, 30], "randomforestclassifier__max_depth" : [None, 6, 8, 10], "randomforestclassifier__max_leaf_nodes": [None, 5, 10, 20], "randomforestclassifier__min_impurity_split": [0.1, 0.2, 0.3]}
grid = GridSearchCV(pipe, param_grid=param_grid, cv=3)
- Kami menyesuaikan data pelatihan untuk penaksir pipa:
grid.fit(X_train, y_train)
GridSearchCV(cv=3, error_score='raise', estimator=Pipeline(memory=None, steps=[('preprocessing', PreProcessing()), ('randomforestclassifier', RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impu..._jobs=1, oob_score=False, random_state=None, verbose=0, warm_start=False))]), fit_params=None, iid=True, n_jobs=1, param_grid={'randomforestclassifier__n_estimators': [10, 20, 30], 'randomforestclassifier__max_leaf_nodes': [None, 5, 10, 20], 'randomforestclassifier__min_impurity_split': [0.1, 0.2, 0.3], 'randomforestclassifier__max_depth': [None, 6, 8, 10]}, pre_dispatch='2*n_jobs', refit=True, return_train_score=True, scoring=None, verbose=0)
- Mari kita lihat parameter mana yang dipilih oleh pencarian di grid:
print("Best parameters: {}".format(grid.best_params_))
Best parameters: {'randomforestclassifier__n_estimators': 30, 'randomforestclassifier__max_leaf_nodes': 20, 'randomforestclassifier__min_impurity_split': 0.2, 'randomforestclassifier__max_depth': 8}
print("Validation set score: {:.2f}".format(grid.score(X_test, y_test)))
Validation set score: 0.79
test_df = pd.read_csv('../data/test.csv', encoding="utf-8-sig") test_df = test_df.head()
grid.predict(test_df)
array([1, 1, 1, 1, 1])
Pipa kami terlihat cukup baik untuk beralih ke langkah penting berikutnya: Menerialisasi model pembelajaran mesin.
Menyimpan Model Pembelajaran Mesin: Serialisasi dan Deserialisasi."Dalam ilmu komputer, dalam konteks penyimpanan data, serialisasi adalah proses menerjemahkan struktur data atau status objek ke dalam format yang tersimpan (misalnya, file atau buffer memori) dan kemudian merekonstruksi dalam lingkungan komputer yang sama atau yang lain."
Dalam Python, pengawetan adalah cara standar untuk menyimpan objek dan mengambilnya nanti dalam keadaan aslinya. Untuk membuatnya lebih jelas, saya akan memberikan contoh sederhana:
list_to_pickle = [1, 'here', 123, 'walker']
list_pickle
b'\x80\x03]q\x00(K\x01X\x04\x00\x00\x00hereq\x01K{X\x06\x00\x00\x00walkerq\x02e.'
Lalu kami membongkar objek kaleng lagi:
loaded_pickle = pickle.loads(list_pickle)
loaded_pickle
[1, 'here', 123, 'walker']
Kita dapat menyimpan objek kalengan ke file dan menggunakannya. Metode ini mirip dengan membuat file
.rda , seperti dalam pemrograman R, misalnya.
Catatan: Beberapa mungkin tidak menyukai metode pelestarian ini untuk serialisasi. Alternatifnya bisa
h5py .
Kami memiliki kelas khusus (Kelas) yang perlu kami impor saat pelatihan sedang berlangsung, jadi kami akan menggunakan modul
dill untuk mengemas evaluator kelas dengan objek kisi.
Dianjurkan untuk membuat file
training.py terpisah yang berisi semua kode untuk melatih model. (Contohnya bisa dilihat di
sini ).
!pip install dill
Requirement already satisfied: dill in /home/pratos/miniconda3/envs/ordermanagement/lib/python3.5/site-packages
import dill as pickle filename = 'model_v1.pk'
with open('../flask_api/models/'+filename, 'wb') as file: pickle.dump(grid, file)
Model akan disimpan di direktori yang dipilih di atas. Setelah model kapur barus, itu dapat dibungkus dengan pembungkus Flask. Namun, sebelum ini, Anda perlu memastikan bahwa file kalengan berfungsi. Mari kita muat kembali dan membuat prediksi:
with open('../flask_api/models/'+filename ,'rb') as f: loaded_model = pickle.load(f)
loaded_model.predict(test_df)
array([1, 1, 1, 1, 1])
Karena kami mengikuti langkah-langkah pra-pemrosesan sehingga data yang baru tiba adalah bagian dari pipa, kami hanya perlu menjalankan prediksikan (). Menggunakan perpustakaan scikit-learn, cukup mudah untuk bekerja dengan saluran pipa. Penilai dan jaringan pipa menjaga waktu dan saraf Anda, bahkan jika implementasi awal tampak liar.
Membuat API menggunakan FlaskMari kita menjaga struktur folder sesederhana mungkin:
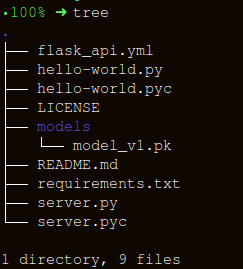
Ada tiga bagian penting untuk membuat wrapper untuk fungsi
apicall() :
- Menerima data
request (yang akan dibuat ramalannya); - Memuat penilai kalengan;
- Menerjemahkan perkiraan kami dalam format JSON dan menerima
status code: 200 respons status code: 200 ;
Pesan HTTP dibuat dari tajuk dan badan. Secara umum, konten utama tubuh ditransmisikan dalam format JSON. Kami akan mengirim (
POST url-endpoint/ ) data yang masuk sebagai paket untuk menerima perkiraan.
Catatan: Anda dapat mengirim teks biasa, XML, cvs atau gambar secara langsung untuk pertukaran format, namun lebih baik menggunakan JSON dalam kasus kami.
"""Filename: server.py """ import os import pandas as pd from sklearn.externals import joblib from flask import Flask, jsonify, request app = Flask(__name__) @app.route('/predict', methods=['POST']) def apicall(): """API Call Pandas dataframe (sent as a payload) from API Call """ try: test_json = request.get_json() test = pd.read_json(test_json, orient='records')
Setelah eksekusi, masukkan:
gunicorn --bind 0.0.0.0:8000 server:appMari kita menghasilkan data untuk perkiraan dan antrian untuk menjalankan API secara lokal di
https:0.0.0.0:8000/predict import json import requests
"""Setting the headers to send and accept json responses """ header = {'Content-Type': 'application/json', \ 'Accept': 'application/json'} """Reading test batch """ df = pd.read_csv('../data/test.csv', encoding="utf-8-sig") df = df.head() """Converting Pandas Dataframe to json """ data = df.to_json(orient='records')
data
'[{"Loan_ID":"LP001015","Gender":"Male","Married":"Yes","Dependents":"0","Education":"Graduate","Self_Employed":"No","ApplicantIncome":5720,"CoapplicantIncome":0,"LoanAmount":110.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001022","Gender":"Male","Married":"Yes","Dependents":"1","Education":"Graduate","Self_Employed":"No","ApplicantIncome":3076,"CoapplicantIncome":1500,"LoanAmount":126.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001031","Gender":"Male","Married":"Yes","Dependents":"2","Education":"Graduate","Self_Employed":"No","ApplicantIncome":5000,"CoapplicantIncome":1800,"LoanAmount":208.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001035","Gender":"Male","Married":"Yes","Dependents":"2","Education":"Graduate","Self_Employed":"No","ApplicantIncome":2340,"CoapplicantIncome":2546,"LoanAmount":100.0,"Loan_Amount_Term":360.0,"Credit_History":null,"Property_Area":"Urban"},{"Loan_ID":"LP001051","Gender":"Male","Married":"No","Dependents":"0","Education":"Not Graduate","Self_Employed":"No","ApplicantIncome":3276,"CoapplicantIncome":0,"LoanAmount":78.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"}]'
"""POST <url>/predict """ resp = requests.post("http://0.0.0.0:8000/predict", \ data = json.dumps(data),\ headers= header)
resp.status_code
200
"""The final response we get is as follows: """ resp.json()
{'predictions': '[{"0":"LP001015","1":1},{...
KesimpulanDalam artikel ini, kami hanya setengah jalan, menciptakan API yang berfungsi yang memberikan perkiraan, dan telah menjadi satu langkah lebih dekat untuk mengintegrasikan solusi ML langsung ke aplikasi yang dikembangkan. Kami telah membuat API yang cukup sederhana yang akan membantu dalam membuat prototipe produk dan membuatnya benar-benar berfungsi, tetapi untuk mengirimkannya ke produksi, Anda perlu membuat beberapa penyesuaian yang tidak lagi di bidang pembelajaran mesin.
Ada beberapa hal yang perlu diingat saat membuat API:
- Membuat API berkualitas dari kode spageti hampir tidak mungkin, jadi gunakan pengetahuan Anda dalam pembelajaran mesin untuk membuat API yang berguna dan nyaman.
- Coba gunakan kontrol versi untuk model dan kode API. Perlu diingat bahwa Flask tidak menyediakan dukungan untuk alat kontrol versi. Menyimpan dan melacak model ML adalah tugas yang sulit, temukan cara yang nyaman bagi Anda. Ada sebuah artikel di sini yang berbicara tentang bagaimana melakukan ini.
- Karena spesifik dari model scikit-learn, Anda perlu memastikan bahwa evaluator dan kode pelatihan bersebelahan (jika Anda menggunakan evaluator khusus untuk preprocessing atau tugas serupa lainnya). Dengan demikian, model kalengan akan memiliki evaluator kelas di sebelahnya.
Langkah logis berikutnya adalah membuat mekanisme untuk menggunakan API seperti itu pada mesin virtual kecil. Ada berbagai cara untuk melakukan ini, tetapi kami akan membahasnya di artikel berikutnya.
Kode dan penjelasan untuk artikel iniSumber yang berguna:[1]
Jangan Acar data Anda.[2]
Membangun Scikit Pelajari transformer yang kompatibel .
[3]
Menggunakan jsonify dalam Flask .
[4]
Flask-QuickStart.Berikut adalah materi semacam itu. Berlangganan kepada kami jika Anda menyukai publikasi ini, dan mendaftar untuk
webinar terbuka gratis dengan topik: "Algoritma klasifikasi metrik", yang akan diadakan 12 Maret oleh pengembang dan ilmuwan data dengan pengalaman 5 tahun -
Alexander Nikitin .