Dalam artikel ini saya akan berbicara tentang ranjau yang diletakkan di bawah kinerja, serta deteksi mereka (lebih disukai sebelum ledakan) dan pembuangan.
Gambar untuk menarik perhatian Apa itu tambang?
Mari kita mulai dengan apa yang ada pada asal mula pengetahuan apa pun - dengan definisi. Orang dahulu mengatakan bahwa memberi nama dengan benar berarti memahami dengan benar. Saya pikir definisi tambang yang berkinerja terbaik diungkapkan dengan membandingkannya dengan kesalahan yang jelas, misalnya, ini:
String concat(String... strings) { String result = ""; for (String str : strings) { result += str; } return result; }
Bahkan pengembang pemula tahu bahwa garis tidak dapat diubah, dan menempelkannya bersama dalam satu lingkaran tidak berarti menambahkan data ke ekor garis yang ada, tetapi membuat garis baru dengan setiap lintasan. Jika Anda salah, maka jangan berkecil hati - "Ide" akan segera memperingatkan Anda tentang bahaya, dan "Sonar" pasti akan membanjiri majelis Anda.
Tetapi kode ini akan menarik lebih sedikit perhatian, dan Idea ( sebelum versi 2018.2 ) akan diam:
Long total = 0L; List<Long> totals = query.getResultList(); for (Long element : totals) { total += element == null ? 0 : element; }
Masalahnya di sini adalah sama: pembungkus untuk tipe sederhana tidak berubah, yang berarti menambahkan 5 unit ke nomor objek berarti membuat pembungkus baru dan menuliskan angka 6 ke dalamnya.
Lelucon di sini adalah kehadiran di Jawa dua representasi dari tipe data tertentu - sederhana dan objek, serta transformasi otomatis mereka melalui bahasa itu sendiri. Karena itu, banyak pengembang pemula berpikir seperti ini: "Ya, eksekusi entah bagaimana mengubah mereka di sana dengan sendirinya, itu hanya angka."
Padahal, tidak semuanya begitu sederhana. Ambil patokan dan coba tambahkan angka dengan cara yang ditentukan:
Tiba-tiba, itu keluar sangat, sangat murah (selanjutnya JDK 11, kecuali dinyatakan secara eksplisit) (size) Mode Cnt Score Error Units wrapper 10 avgt 100 23,5 ± 0,1 ns/op wrapper 100 avgt 100 352,3 ± 2,1 ns/op wrapper 1000 avgt 100 4424,5 ± 25,2 ns/op wrapper 10 avgt 100 0 ± 0 B/op wrapper 100 avgt 100 1872 ± 0 B/op wrapper 1000 avgt 100 23472 ± 0 B/op
Bandingkan dengan tipe sederhana:
primitive 10 avgt 100 6,4 ± 0,0 ns/op primitive 100 avgt 100 39,8 ± 0,1 ns/op primitive 1000 avgt 100 252,5 ± 1,3 ns/op primitive 10 avgt 100 0 ± 0 B/op primitive 100 avgt 100 0 ± 0 B/op primitive 1000 avgt 100 0 ± 0 B/op
Dari sini kami memperoleh salah satu definisi ranjau yang berkinerja - ini adalah kode yang tidak menarik perhatian, tidak terdeteksi (setidaknya pada saat Anda menemukannya) oleh analisis statis, tetapi dapat memperlambat dalam beberapa penggunaan. Dalam kasus kami, sementara jumlah tidak melebihi 127 objek diambil dari cache dan Long hanya 4 kali lebih lambat dari long . Namun, untuk ukuran array 100, kecepatannya hampir 10 kali lebih rendah.
Hal-hal kecil yang besar
Terkadang perubahan kecil, yang hampir tidak mengubah arti eksekusi, dalam beberapa keadaan menjadi rem yang kuat.
Misalkan kita memiliki kode:
Seperti apa logika metode itu?
Jangan terburu-buru untuk memata-matai, pikirkanIni adalah ConcurrentHashMap::computeIfAbsent !
Kami memiliki "delapan" dan kami dapat dengan dingin meningkatkan kode: ganti 6 baris dengan satu, membuat kode lebih pendek dan lebih mudah dimengerti. Omong-omong, para pecinta multithreading mungkin akan menunjukkan peningkatan lain yang dibawa ConcurrentHashMap::computeIfAbsent , tetapi sedikit lebih lambat;)
Mari kita membuat pemikiran yang hebat menjadi kenyataan:
Berkumpul, mulai, menangisUntuk melihat ukuran penuh, klik kanan pada gambar dan pilih "Buka Gambar di Tab Baru"
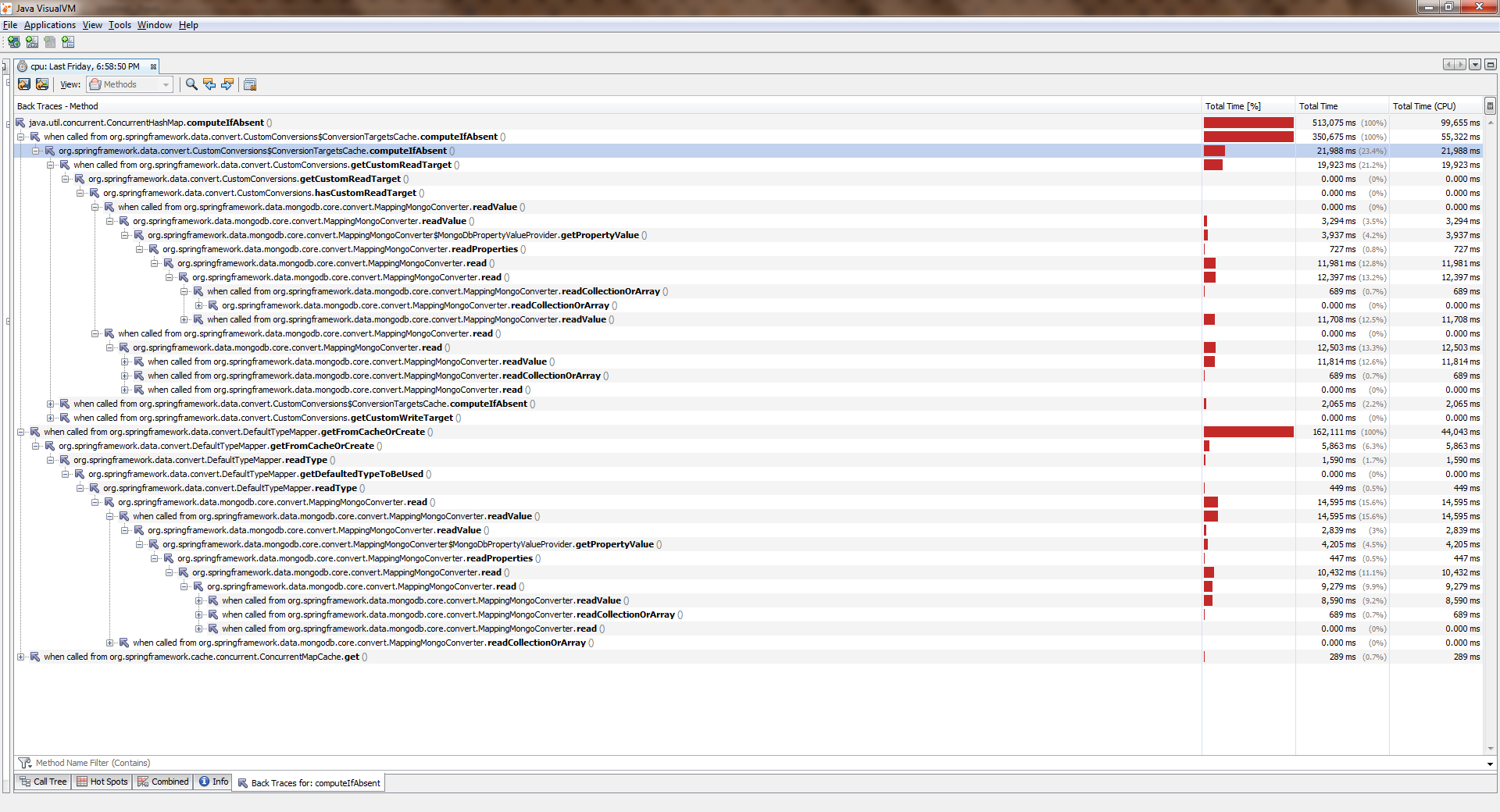
Sementara aplikasi bekerja dengan satu utas, semuanya kurang lebih baik. Aliran menjadi lebih dan menjadi lebih buruk secara signifikan. ConcurrentHashMap::computeIfAbsent diblokir, bahkan jika kunci telah ditambahkan ke kamus . Dan ini menjadi alasan bug di Spring Date Mongo.
Anda dapat memverifikasi ini dengan pengukuran sederhana ("delapan"). Inilah kesimpulannya:
Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 19,405 ± 0,411 ns/op getAndPut avgt 20 4,578 ± 0,045 ns/op 2 threads computeIfAbsent avgt 20 66,492 ± 2,036 ns/op getAndPut avgt 20 4,454 ± 0,110 ns/op 4 threads computeIfAbsent avgt 20 155,975 ± 8,850 ns/op getAndPut avgt 20 5,616 ± 2,073 ns/op 6 threads computeIfAbsent avgt 20 203,188 ± 10,547 ns/op getAndPut avgt 20 7,024 ± 0,456 ns/op 8 threads computeIfAbsent avgt 20 302,036 ± 31,702 ns/op getAndPut avgt 20 7,990 ± 0,144 ns/op
Bisakah ini jelas dianggap sebagai kesalahan oleh pengembang? Menurut pendapat saya yang sederhana, tidak, tidak. Dokumentasi mengatakan:
Beberapa upaya pembaruan operasi di peta ini oleh utas lain mungkin diblokir saat perhitungan sedang berlangsung, sehingga perhitungannya harus singkat dan sederhana, dan tidak boleh mencoba memperbarui pemetaan lain dari peta ini
Dengan kata lain, ConcurrentHashMap::computeIfAbsent menutup sel yang berisi kunci dari dunia luar (tidak seperti ConcurrentHashMap::get ), yang secara umum benar, karena memungkinkan Anda untuk menghindari balapan sambil memanggil metode dari utas yang berbeda ketika kunci belum ditambahkan.
Di sisi lain, dalam mode operasi yang paling umum, perhitungan nilai dan pengikatannya dengan kunci hanya terjadi pada panggilan pertama, dan semua panggilan berikutnya hanya mengembalikan nilai yang dihitung sebelumnya. Oleh karena itu, masuk akal untuk mengubah logika sehingga kunci hanya diatur ketika berubah. Itu dibuat di sini .
Dalam edisi yang lebih baru (> 8), ConcurrentHashMap::computeIfAbsent menjadi ConcurrentHashMap::computeIfAbsent :
JDK 11 Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 6,983 ± 0,066 ns/op getAndPut avgt 20 5,291 ± 1,220 ns/op 2 threads computeIfAbsent avgt 20 7,173 ± 0,249 ns/op getAndPut avgt 20 5,118 ± 0,395 ns/op 4 threads computeIfAbsent avgt 20 7,991 ± 0,447 ns/op getAndPut avgt 20 5,270 ± 0,366 ns/op 6 threads computeIfAbsent avgt 20 11,919 ± 0,865 ns/op getAndPut avgt 20 7,249 ± 0,199 ns/op 8 threads computeIfAbsent avgt 20 14,360 ± 0,892 ns/op getAndPut avgt 20 8,511 ± 0,229 ns/op
Perhatikan bahaya dari contoh ini: konten semantik tidak banyak berubah, karena pada pandangan pertama kita hanya menggunakan sintaksis yang lebih maju. Pada saat yang sama, saat aplikasi berjalan dalam satu utas, pengguna hampir tidak merasakan perbedaan! Inilah perubahan yang tampaknya tidak berbahaya babi menambang di bawah kinerja kami.
Mengapa saya menulis 'hampir tidak berubah'ConcurrentHashMap::computeIfAbsent tidak selalu dapat dipertukarkan dengan ekspresi getAndPut , karena ConcurrentHashMap::computeIfAbsent adalah operasi atom. Dalam kode yang sama
private TypeInformation<?> getFromCacheOrCreate(Alias alias) { TypeInformation<?> info = cache.get(alias); if (info == null) { info = getAlias.apply(alias); cache.put(alias, info); } return info; }
karena kurangnya sinkronisasi eksternal , sebuah perlombaan muncul . Jika fungsi diteruskan ke ConcurrentHashMap::computeIfAbsent untuk kunci yang diberikan selalu mengembalikan nilai yang sama, maka ini adalah perlombaan "aman", yang paling sering kita hadapi adalah menghitung nilai yang sama 2 atau lebih kali. Jika tidak ada jaminan seperti itu, maka penggantian mekanis penuh dengan gangguan aplikasi. Berhati-hatilah!
Tangan-tangan ini tidak mengubah apa pun
Itu juga terjadi bahwa kode tidak berubah sama sekali, tetapi tiba-tiba mulai melambat.
Bayangkan bahwa kita dihadapkan dengan tugas menggeser elemen-elemen array menjadi koleksi. Yang paling logis adalah dengan menggunakan Collection::addAll , tapi inilah nasib buruknya - ia menerima koleksi:
public interface Collection<E> extends Iterable<E> { boolean addAll(Collection<? extends E> c); }
Cara termudah adalah dengan membungkus array di Arrays::asList . Ini akan menghasilkan sesuatu seperti
boolean addItems(Collection<T> collection) { T[] items = getArray(); return collection.addAll(Arrays.asList(items)); }
Selama pengoreksian, rekan kerja yang sadar kinerja mungkin akan memberi tahu kami bahwa ada dua masalah dalam kode ini sekaligus:
- membungkus array dalam daftar (objek tambahan)
- membuat iterator (objek tambahan lain) dan melewatinya
Bahkan, dalam implementasi referensi Collection::addAll kita akan melihat ini:
public abstract class AbstractCollection<E> implements Collection<E> { public boolean addAll(Collection<? extends E> c) { boolean modified = false; for (E e : c) { if (add(e)) modified = true; } return modified; } }
Jadi iterator dibuat di sini dan elemen diurutkan menggunakannya. Karena itu, kawan yang berpengalaman menawarkan solusi mereka:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
Di dalam kode, sepertinya memang lebih produktif:
public static <T> boolean addAll(Collection<? super T> c, T... elements) { boolean result = false; for (T element : elements) result |= c.add(element); return result; }
Pertama, iterator tidak dibuat. Kedua, lintasan berjalan dalam siklus penghitungan yang biasa, di samping itu, array cocok di cache, elemen-elemennya terletak di memori secara berurutan (yang berarti akan ada beberapa cache yang hilang), dan akses ke mereka dengan indeks sangat cepat. Daftar pembungkus juga tidak dibuat. Kedengarannya bagus dan terdengar.
Akhirnya, rekan mengutip rasio ultima regum: dokumentasi. Dan di sana, abu-abu putih (atau hijau hitam) mengatakan:
@SafeVarargs public static <T> boolean addAll(Collection<? super T> c, T... elements) {
Artinya, pengembang itu sendiri (dan siapa yang harus mereka percayai, jika bukan mereka?) Tulis bahwa untuk sebagian besar implementasi metode utilitas bekerja lebih cepat. Dan dia sangat cepat. Terkadang.
Benchmark , yang akan kami luncurkan untuk HashSet di G8, akan membantu HashSet :
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 155,2 ± 2,8 ns/op addAll HashSet 100 avgt 100 1884,4 ± 37,4 ns/op addAll HashSet 1000 avgt 100 17917,3 ± 298,8 ns/op collectionsAddAll HashSet 10 avgt 100 136,1 ± 0,8 ns/op collectionsAddAll HashSet 100 avgt 100 1538,3 ± 31,4 ns/op collectionsAddAll HashSet 1000 avgt 100 15168,6 ± 289,4 ns/op
Tampaknya kawan yang lebih berpengalaman benar. Hampir.
Dalam edisi selanjutnya (misalnya, dalam 11) kecemerlangan metode utilitas akan agak memudar:
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 143,1 ± 0,6 ns/op addAll HashSet 100 avgt 100 1738,4 ± 7,3 ns/op addAll HashSet 1000 avgt 100 16853,9 ± 101,0 ns/op collectionsAddAll HashSet 10 avgt 100 132,1 ± 1,1 ns/op collectionsAddAll HashSet 100 avgt 100 1661,1 ± 7,1 ns/op collectionsAddAll HashSet 1000 avgt 100 15450,9 ± 93,9 ns/op
Dapat dilihat bahwa kita tidak berbicara tentang yang "lebih cepat". Dan jika kita mengulangi percobaan untuk ArrayList -a, maka ternyata metode utilitas mulai kehilangan banyak (semakin jauh semakin kuat):
Benchmark (collection) (size) Mode Cnt Score Error Units JDK 8 addAll ArrayList 10 avgt 100 38,5 ± 0,5 ns/op addAll ArrayList 100 avgt 100 188,4 ± 7,0 ns/op addAll ArrayList 1000 avgt 100 1278,8 ± 42,9 ns/op collectionsAddAll ArrayList 10 avgt 100 62,7 ± 0,7 ns/op collectionsAddAll ArrayList 100 avgt 100 495,1 ± 2,0 ns/op collectionsAddAll ArrayList 1000 avgt 100 4892,5 ± 48,0 ns/op JDK 11 addAll ArrayList 10 avgt 100 26,1 ± 0,0 ns/op addAll ArrayList 100 avgt 100 161,1 ± 0,4 ns/op addAll ArrayList 1000 avgt 100 1276,7 ± 3,7 ns/op collectionsAddAll ArrayList 10 avgt 100 41,6 ± 0,0 ns/op collectionsAddAll ArrayList 100 avgt 100 492,6 ± 1,5 ns/op collectionsAddAll ArrayList 1000 avgt 100 6792,7 ± 165,5 ns/op
Tidak ada yang tak terduga di sini, ArrayList dibangun di sekitar array, sehingga pengembang telah mendefinisikan kembali metode Collection::addAll :
public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); modCount++; int numNew = a.length; if (numNew == 0) return false; Object[] elementData; final int s; if (numNew > (elementData = this.elementData).length - (s = size)) elementData = grow(s + numNew); System.arraycopy(a, 0, elementData, s, numNew); <--- size = s + numNew; return true; }
Sekarang kembali ke tambang kita. Misalkan kita tetap menerima solusi yang diusulkan pada proofreading dan meninggalkan kode ini:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
Untuk saat ini, semuanya baik-baik saja, tetapi setelah menambahkan fungsionalitas baru, metode ini terkadang menjadi panas dan mulai melambat. Kami membuka kode sumber - kode itu tidak berubah. Jumlah datanya sama. Dan kinerja banyak tenggelam. Ini adalah jenis tambang saya yang lain.
Temukan debugger dan temukan yang cantik:

Harap perhatikan: kami tidak mengubah algoritme, jumlah data yang diproses tidak berubah, tetapi sifatnya berubah dan masalah kinerja dimulai pada kode kami:
Java 8 Java 11 addAll 10 56,9 25,2 ns/op collectionsAddAll 10 352,2 142,9 ns/op addAll 100 159,9 84,3 ns/op collectionsAddAll 100 4607,1 3964,3 ns/op addAll 1000 1244,2 760,2 ns/op collectionsAddAll 1000 355796,9 364677,0 ns/op
Pada array besar, perbedaan antara Collections::addAll dan Collection::addAll adalah 500 kali sederhana. Faktanya adalah bahwa COWList tidak hanya memperluas array yang ada, tetapi juga membuat yang baru setiap elemen ditambahkan:
public boolean add(E e) { synchronized (lock) { Object[] es = getArray(); int len = es.length; es = Arrays.copyOf(es, len + 1); <---- es[len] = e; setArray(es); return true; } }
Siapa yang harus disalahkan?
Masalah utama di sini adalah bahwa metode Collections::addAll menerima antarmuka, sedangkan metode addAll tidak addAll isi. Tidak ada badan - tidak ada bisnis, oleh karena itu, dokumentasi ditulis berdasarkan implementasi yang ada di AbstractCollection::addAll , yang merupakan algoritma umum yang berlaku untuk semua koleksi. Ini berarti bahwa implementasi struktur data yang lebih spesifik yang berada pada level abstraksi yang lebih rendah dapat mengubah perilaku ini.
Sekarang secara manusiawi Collection::addAll – AbstractCollection::addAll – <--- ArrayList::addAll HashSet::addAll – <--- COWList::addAll
Lebih lanjut tentang abstraksi
Karena kita berbicara tentang tingkat abstraksi, saya akan memberi tahu Anda tentang satu contoh dari kehidupan.
Mari kita bandingkan dua cara ini untuk menyimpan jumlah entitas ke-n dalam database:
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } } @Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
Sepintas, kinerja kedua metode ini seharusnya tidak jauh berbeda, karena
- dalam kedua kasus jumlah entitas yang sama akan disimpan dalam database
- jika kunci diambil dari urutan, maka jumlah panggilan akan sama
- jumlah data yang ditransfer adalah sama
SimpleJpaRepository::saveAndFlush ke metode SimpleJpaRepository::saveAndFlush :
@Transactional public <S extends T> S save(S entity) { if (entityInformation.isNew(entity)) { em.persist(entity); return entity; } else { return em.merge(entity); } } @Transactional public <S extends T> S saveAndFlush(S entity) { S result = save(entity); flush(); return result; } @Transactional public void flush() { em.flush(); }
Titik gelap di sini adalah metode flush() . Kenapa bodoh? Sepertinya saya bahwa pengungkapannya dalam antarmuka JpaRepository adalah kesalahan pengembang. Saya akan mencoba membenarkan pemikiran saya. Biasanya, metode ini sama sekali tidak digunakan oleh pengembang, karena panggilan ke EntityManager::flush terkait dengan penyelesaian transaksi yang dikendalikan oleh Spring:
Harap dicatat: EntityManager adalah bagian dari spesifikasi JPA diterapkan di Hibernate sebagai sesi (antarmuka Sesi dan kelas SessionImpl, masing-masing). Spring Date adalah kerangka kerja yang berjalan di atas ORM, dalam hal ini, di atas Hibernate. Ternyata JpaRepository::saveAndFlush memberi kita akses ke tingkat API yang lebih rendah, meskipun tugas kerangka kerja adalah menyembunyikan detail level rendah (situasinya agak mirip dengan kisah Tidak Aman di JDK).
Dalam kasus kami, saat menggunakan JpaRepository::saveAndFlush kami masuk ke lapisan aplikasi yang lebih rendah, sehingga merusak sesuatu.
Luangkan waktu untuk mengintip, pikirkan sendiriKemampuan Hibernate untuk mengirim data dalam batch rusak, kelipatan dari pengaturan jdbc.batch_size , yang ditentukan dalam application.yml :
spring: jpa: properties: hibernate: jdbc.batch_size: 500
Pekerjaan Hibernate dibangun di atas acara, jadi ketika Anda menyimpan 1000 entitas seperti ini
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } }
memanggil repository.save(e) tidak langsung menyimpan. Sebagai gantinya, sebuah acara dibuat yang di-antri. Setelah penyelesaian transaksi, data digabungkan menggunakan EntityManager::flush , yang membagi sisipan / pembaruan ke dalam beberapa paket dari jdbc.batch_size dan membuat permintaan dari mereka. Dalam kasus kami, jdbc.batch_size: 500 , jadi menyimpan 1000 entitas pada kenyataannya berarti hanya 2 permintaan.
Tetapi dengan sesi manual pada setiap lintasan siklus
@Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
antrian dihapus dan menyimpan 1000 entitas berarti 1000 permintaan.
Dengan demikian, mengganggu lapisan bawah aplikasi dapat dengan mudah menjadi tambang, dan bukan hanya tambang produktivitas (lihat Tidak Aman dan penggunaannya yang tidak terkontrol).
Berapa lambatnya? Ambil kasus terbaik (bagi kami) - database berada di host yang sama dengan aplikasi. Pengukuran saya menunjukkan gambar berikut:
(entityCount) Mode Cnt Score Error Units bulkSave 10 ss 500 16,613 ± 1,714 ms/op bulkSave 100 ss 500 31,371 ± 1,453 ms/op bulkSave 1000 ss 500 35,687 ± 1,973 ms/op bulkSaveUsingFlush 10 ss 500 32,653 ± 2,166 ms/op bulkSaveUsingFlush 100 ss 500 61,983 ± 6,304 ms/op bulkSaveUsingFlush 1000 ss 500 184,814 ± 6,976 ms/op
Tentunya, jika basis data terletak pada host jarak jauh, maka biaya transfer data akan semakin menurunkan kinerja seiring dengan pertumbuhan volume data.
Dengan demikian, bekerja pada level abstraksi yang salah dapat dengan mudah membuat bom waktu. Ngomong-ngomong, di salah satu artikel saya sebelumnya saya berbicara tentang upaya penasaran untuk meningkatkan StringBuilder -a: di sana saya tidak berhasil ketika mencoba masuk ke tingkat kode yang lebih abstrak.
Perbatasan ladang ranjau
Mari kita bermain ranjau? Temukan milikku:
Menemukannya? Periksa jawaban yang benar. "Apakah Anda bercanda?" Kata kritik itu. "Tapi apakah hanya ada dua garis pengeleman? Apa artinya ini dalam E. yang berdarah?" Biarkan saya menarik perhatian Anda pada fakta bahwa saya menyoroti tidak hanya perekatan string, tetapi juga nama kelas dan nama metode. Memang, bahaya dari menempelkan string bukan dalam menempelkannya sendiri, tetapi dalam apa yang terjadi dalam metode yang menciptakan kunci untuk cache, yaitu dalam skenario tertentu kita akan memiliki banyak akses ke metode ini, yang berarti banyak jalur sampah.
Oleh karena itu, pesan kesalahan harus dibuat hanya ketika kesalahan ini benar-benar dilemparkan:
Dengan demikian, ladang ranjau memiliki batas - ini adalah jumlah data, frekuensi akses ke metode, dll. Indikator kuantitatif, setelah mencapai dan melampaui yang sedikit kelemahan menjadi signifikan secara statistik.
Di sisi lain, ini adalah fitur sampai persimpangan yang menyulitkan kode tidak memberikan peningkatan yang signifikan (terukur).
Ini adalah kesimpulan lain bagi pengembang: dalam banyak kasus, penipuan adalah kejahatan, yang menyebabkan komplikasi kode yang tidak berarti. Dalam 99 kasus dari 100, kami tidak memenangkan apa pun.
Harus diingat bahwa selalu ada
Kasing keseratus
Ini adalah kode yang diberikan Nitzan Wakart dalam artikelnya . Kejutan baca yang mudah berubah :
@BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) @State(Scope.Thread) public class LoopyBenchmarks { @Param({ "32", "1024", "32768" }) int size; byte[] bunn; @Setup public void prepare() { bunn = new byte[size]; } @Benchmark public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) {
Ketika kami mengatur pengalaman, kami akan menemukan perbedaan yang menakjubkan antara dua cara untuk beralih ke array:
Benchmark (size) Score Score error Units goodOldLoop 32 46.630 0.097 ns/op goodOldLoop 1024 1199.338 0.705 ns/op goodOldLoop 32768 37813.600 56.081 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Di sini, pengembang yang tidak berpengalaman dapat membuat kesimpulan yang jelas dan terukur seperti itu: melewati array menggunakan sintaks baru bekerja lebih cepat daripada siklus penghitungan. Ini adalah kesimpulan yang salah, karena itu perlu sedikit mengubah metode goodOldLoop :
@Benchmark public void goodOldLoopReturns(Blackhole fox) { byte[] sunn = bunn;
dan kinerjanya sebanding dengan metode sweetLoop "lebih cepat":
Benchmark (size) Score Score error Units goodOldLoopReturns 32 19.306 0.045 ns/op goodOldLoopReturns 1024 476.493 1.190 ns/op goodOldLoopReturns 32768 14292.286 16.046 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Blackhole::consume :
, , . goodOldLoop this.bunn , for-each , (, Java Concurrency In Practice " "). .
: " ? , Blackhole::consume — JMH . , , ?"
:
byte[] bunn; public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
? ? , :
E[] bunn; public void forEach(Consumer<E> fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
Iterable::forEach ! , , , ( JDK 13):
, . , Collections.nCopies()::forEach :
@Override public void forEach(final Consumer<? super E> action) { Objects.requireNonNull(action); for (int i = 0; i < this.n; i++) { action.accept(this.element); } }
, . . this.n this.element :
private static class CopiesList<E> extends AbstractList<E> implements RandomAccess, Serializable { final int n; final E element; CopiesList(int n, E e) { assert n >= 0; this.n = n; element = e; }
, , @Stable .
: 99 100 , , 1 100, . , .
" volatile".
, :
- , ( java.lang.Integer , java.lang.Long , java.lang.Short , java.lang.Byte , java.lang.Character ). , ,
Integer intgr = Integer.valueOf(42);
.
:
Integer intgr = new Integer(42);
, , Integer::valueOf .
: . , , "" ( ). , , Integer::valueOf . " " .
. , . , . , , .