Apakah mungkin untuk menentukan dengan kutipan mana politisi mana yang menjadi penulisnya? LSM Ukraina
Vox Ukraina membuat proyek
VoxCheck , dalam kerangka yang memverifikasi pernyataan para politisi berperingkat tertinggi. Baru-baru ini, mereka memposting seluruh
database dari kutipan yang diverifikasi . Saya hanya mendengarkan kursus NLP dan memutuskan untuk memeriksa seberapa akurat penulis dapat diidentifikasi oleh teks kutipan.
Penafian . Artikel ini ditulis karena minat pada topik dan keinginan untuk mencoba materi yang dipelajari dalam praktek, tanpa mengklaim analisis yang paling akurat dan terperinci.
Untuk analisis, python digunakan, kode ini tersedia di
github .
Data
Basis data sekarang berisi 1.952 kutipan dengan distribusi menurut kebijakan berikut:
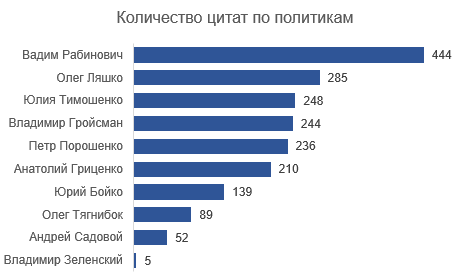
Untuk keperluan analisis, saya memilih orang dengan> 200 kutipan. Karenanya, Yuri Boyko, Oleg Tyagnibok, Andrey Sadovoy dan Vladimir Zelensky tidak cocok dengan analisis. Ada 1.667 kutipan yang tersisa dalam array. Dari enam pembicara yang tersisa, empat (kecuali Groysman dan Rabinovich) adalah kandidat terdaftar untuk pemilihan presiden berikutnya.
Kutipan bervariasi dari pendek, sekitar 30 karakter (
"Saya sudah mengirimkan 112 tagihan." ) Untuk yang panjang, sekitar 1.200 karakter. Panjang rata-rata kutipan adalah sekitar 200 karakter (misalnya,
"Sebentar lagi kita harus memberi sapi sedikit lebih sedikit untuk museum dan dinosaurus untuk anak-anak dalam ilmu alam - untuk hasil politik politik, agar yak melakukan kunjungan pemula. Ternak kurang dari 2 bulan . " )
TF-IDF
Pertama, mari kita lihat kata-kata mana yang lebih berkarakter dari penutur tertentu. Inilah 10 kata teratas dengan TF-IDF tertinggi untuk setiap kandidat:

Secara singkat tentang TF-IDFTF-IDF (istilah frekuensi - frekuensi dokumen terbalik) adalah indikator yang mengevaluasi pentingnya kata dalam konteks dokumen. Kata-kata TF-IDF sebanding dengan frekuensi penggunaan kata ini dalam dokumen dan berbanding terbalik dengan frekuensi penggunaan kata dalam semua dokumen koleksi. Dalam konteks data kami, TF-IDF tinggi berarti bahwa seorang politisi sering menggunakan kata ini, sementara politisi lain menggunakannya relatif lebih sedikit.
Untuk menghitung TF-IDF, stemming digunakan - membawa kata ke pangkalan.
Kata-kata yang ingin saya komentari untuk setiap pembicara untuk memberikan sedikit konteks disorot dengan warna hijau.
Oleg Lyashko:- Polandia: Lyashko sering menyebut Polandia sehubungan dengan migrasi kerja Ukraina di sana, dan juga membandingkan pendapatan di Polandia dan Ukraina
- Sereal: Lyashko mengatakan bahwa Ukraina mengekspor biji-bijian dan kehilangannya, karena mungkin lebih mahal untuk mengekspor tepung
- Onkologi, obat-obatan: Lyashko adalah penentang kuat reformasi medis saat ini dan sering mengatakan bahwa biaya onkologi hampir tidak ditanggung oleh negara.
Poroshenko dan
Gritsenko berbicara banyak tentang konflik militer, yang cukup logis: Poroshenko adalah presiden dan, karenanya, panglima tertinggi, dan Gritsenko adalah militer dan menteri pertahanan.
Groisman adalah perdana menteri, dan terutama berbicara tentang ekonomi, termasuk hutang publik.
Kutipan
Vadim Rabinovich tidak menunjukkan topik tertentu, mungkin karena ia banyak berbicara (444 dari tahun 1952, semua yang lain memiliki kurang dari 300 kutipan).
Yulia Tymoshenko berbicara banyak tentang sistem transmisi gas Ukraina, tentang likuidasi bank, serta tentang indikator ekonomi negara yang rendah.
Klasifikasi kutipan
Jadi, kami mendapat 6 kelas (pembicara). Untuk klasifikasi, saya menggunakan classifier Bayesian yang naif. Kata-kata berhenti dari bahasa Rusia dan Ukraina dikecualikan dari teks (menggunakan paket stopwords). N-gram hingga 2 disertakan (opsi dengan panjang hingga 3 juga diuji, tetapi menunjukkan overfitting). Sampel uji diambil dalam proporsi 20% dari total.
Keakuratan total model (proporsi kutipan yang diklasifikasikan dengan benar) dalam sampel pelatihan adalah
74,8% , dalam sampel uji -
75,7%Hasil silang oleh penulis:

Akurasi tertinggi untuk Vadim Rabinovich (97%) - kemungkinan besar karena ia adalah satu-satunya penutur bahasa Rusia dari enam. Keakuratan klasifikasi Groisman dan Lyashko yang tinggi (78% dan 77%).
Sedikit lebih tinggi dari 60% adalah indikator akurasi untuk mengutip Poroshenko dan Tymoshenko. Model lebih sering mendefinisikan keduanya sebagai Groysman. Groysman, sebagai perdana menteri, sering berbicara tentang ekonomi dalam bentuk "laporan kemajuan," dan kutipan yang salah diklasifikasikan dari Poroshenko dan Tymoshenko juga tentang hal ini (hanya Poroshenko sebagai wakil pemerintah yang positif, tetapi Tymoshenko memiliki kebalikannya).
Misalnya, berikut adalah kutipan dari Poroshenko yang ditentukan oleh model sebagai kutipan dari Groisman:
5 milyar USD, (tobto) 4 milyar UAH dari batu itu 'dan 1 milyar UAH dari seluruh batu secara langsung untuk obat-obatanDan juga kutipan dari Tymoshenko, didefinisikan sebagai kutipan dari Groisman:
Dalam anggaran ofensif untuk pemanfaatan penjara, mereka melihat lebih dari uang, kurang untuk sains, seperti bekerja di Akademi Ilmu Pengetahuan Ukraina.Akurasi terendah (57%) dalam kutipan dari Anatoly Gritsenko. Modelnya sering didefinisikan sebagai Poroshenko (yang logis, mengingat topik militer dari kutipan mereka), serta Lyashko. Dalam kasus Lyashko, klasifikasi yang salah adalah kutipan yang mengkritik pihak berwenang, termasuk, misalnya, tentang migrasi:
Saya tidak berpikir tentang mereka yang merupakan anggota yang sama dengan pesanan Anda, Volodimira Borisovich, pan Klimkin mengatakan bahwa mereka akan meninggalkan negara itu.Secara umum, bagi saya tampaknya hasilnya tidak buruk untuk kutipan singkat seperti format yang sama (pernyataan lisan oleh politisi) dan topik (politik Ukraina). Ngomong-ngomong, pada data yang sama saya mencoba membuat model yang mendefinisikan kategori kutipan (true / false / manipulation), tetapi akurasinya sangat rendah. Yang, pada prinsipnya, adalah logis: melihat kutipan seperti "Begitu banyak uang yang dihabiskan untuk ini, tetapi di negara seperti itu mereka menghabiskan begitu banyak" sulit untuk menentukan kebenaran data yang terkandung di dalamnya :)