
Apache Spark saat ini mungkin merupakan platform paling populer untuk menganalisis data volume besar. Kontribusi yang cukup besar terhadap popularitasnya dibuat oleh kemungkinan menggunakannya dari bawah Python. Pada saat yang sama, semua orang setuju bahwa, dalam kerangka API standar, kinerja kode Python dan Scala / Java dapat dibandingkan, tetapi tidak ada sudut pandang tunggal mengenai fungsi yang ditentukan pengguna (User Defined Function, UDF). Mari kita coba mencari tahu bagaimana biaya overhead meningkat dalam kasus ini, menggunakan contoh tugas memeriksa solusi SNA Hackathon 2019 .
Sebagai bagian dari kompetisi, peserta memecahkan masalah pengurutan feed berita dari jejaring sosial dan mengunggah solusi dalam bentuk serangkaian daftar yang diurutkan. Untuk memeriksa kualitas solusi yang diperoleh, pertama, untuk masing-masing daftar yang dimuat, ROC AUC dihitung, dan kemudian nilai rata-rata ditampilkan. Harap dicatat bahwa Anda perlu menghitung bukan satu ROC AUC yang umum, tetapi yang pribadi untuk setiap pengguna - tidak ada desain yang siap pakai untuk menyelesaikan masalah ini, jadi Anda harus menulis fungsi khusus. Alasan yang baik untuk membandingkan kedua pendekatan tersebut dalam praktik.
Sebagai platform perbandingan, kami akan menggunakan wadah cloud dengan empat core dan Spark diluncurkan dalam mode lokal, dan kami akan bekerja dengannya melalui Apache Zeppelin . Untuk membandingkan fungsinya, kita akan meniru kode yang sama di PySpark dan Scala Spark. [di sini] Mari kita mulai dengan memuat data.
data = sqlContext.read.csv("sna2019/modelCappedSubmit") trueData = sqlContext.read.csv("sna2019/collabGt") toValidate = data.withColumnRenamed("_c1", "submit") \ .join(trueData.withColumnRenamed("_c1", "real"), "_c0") \ .withColumnRenamed("_c0", "user") \ .repartition(4).cache() toValidate.count()
val data = sqlContext.read.csv("sna2019/modelCappedSubmit") val trueData = sqlContext.read.csv("sna2019/collabGt") val toValidate = data.withColumnRenamed("_c1", "submit") .join(trueData.withColumnRenamed("_c1", "real"), "_c0") .withColumnRenamed("_c0", "user") .repartition(4).cache() toValidate.count()
Saat menggunakan API standar, identitas kode yang hampir lengkap perlu diperhatikan, hingga kata kunci val . Waktu operasi tidak berbeda secara signifikan. Sekarang mari kita coba menentukan UDF yang kita butuhkan.
parse = sqlContext.udf.register("parse", lambda x: [int(s.strip()) for s in x[1:-1].split(",")], ArrayType(IntegerType())) def auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores)) auc_udf = sqlContext.udf.register("auc", auc, DoubleType())
val parse = sqlContext.udf.register("parse", (x : String) => x.slice(1,x.size - 1).split(",").map(_.trim.toInt)) case class AucAccumulator(height: Int, area: Int, negatives: Int) val auc_udf = sqlContext.udf.register("auc", (byScore: Seq[Int], gt: Seq[Int]) => { val byLabel = gt.toSet val accumulator = byScore.foldLeft(AucAccumulator(0, 0, 0))((accumulated, current) => { if (byLabel.contains(current)) { accumulated.copy(height = accumulated.height + 1) } else { accumulated.copy(area = accumulated.area + accumulated.height, negatives = accumulated.negatives + 1) } }) (accumulator.area).toDouble / (accumulator.negatives * accumulator.height) })
Ketika mengimplementasikan fungsi tertentu, jelas bahwa Python lebih ringkas, terutama karena kemampuan untuk menggunakan fungsi scikit-learn bawaan . Namun, ada saat-saat yang tidak menyenangkan - Anda harus secara eksplisit menentukan jenis nilai pengembalian, sedangkan di Scala ditentukan secara otomatis. Mari kita lakukan operasi:
toValidate.select(auc_udf(parse("submit"), parse("real"))).groupBy().avg().show()
toValidate.select(auc_udf(parse($"submit"), parse($"real"))).groupBy().avg().show()
Kode ini terlihat hampir identik, tetapi hasilnya mengecewakan.

Implementasi di PySpark berhasil satu setengah menit, bukan dua detik pada Scala, yaitu, Python ternyata 45 kali lebih lambat . Saat berjalan, top menunjukkan 4 proses Python aktif yang berjalan dengan kecepatan penuh, dan ini menunjukkan bahwa Global Interpreter Lock tidak menciptakan masalah di sini. Tapi! Mungkin masalahnya ada pada implementasi internal scikit-learn - mari kita coba mereproduksi kode Python secara harfiah, tanpa menggunakan perpustakaan standar.
def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) auc_udf_modified = sqlContext.udf.register("auc_modified", auc, DoubleType()) toValidate.select(auc_udf_modified(parse("submit"), parse("real"))).groupBy().avg().show()

Eksperimen menunjukkan hasil yang menarik. Di satu sisi, dengan pendekatan ini, produktivitas diratakan, tetapi di sisi lain, laconicism menghilang. Hasil yang diperoleh dapat menunjukkan bahwa ketika bekerja di Python menggunakan modul C ++ tambahan, overhead signifikan muncul untuk beralih antar konteks. Tentu saja, ada overhead serupa ketika menggunakan JNI di Java / Scala, namun, saya tidak harus berurusan dengan contoh degradasi 45 kali saat menggunakannya.
Untuk analisis yang lebih rinci, kami akan melakukan dua percobaan tambahan: menggunakan Python murni tanpa Spark untuk mengukur kontribusi dari paket doa, dan dengan peningkatan ukuran data di Spark untuk mengamortisasi overhead dan mendapatkan perbandingan yang lebih akurat.
def parse(x): return [int(s.strip()) for s in x[1:-1].split(",")] def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) def sklearn_auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores))
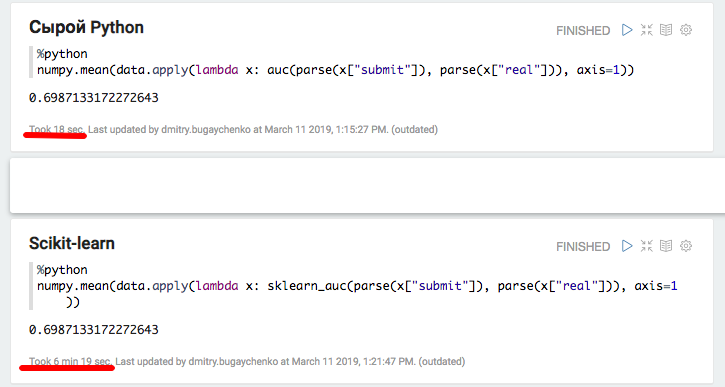
Eksperimen dengan Python dan Pandas lokal mengkonfirmasi asumsi overhead yang signifikan ketika menggunakan paket tambahan - ketika menggunakan scikit-learn, kecepatan berkurang lebih dari 20 kali. Namun, 20 bukan 45 - mari kita coba "mengembang" data dan membandingkan kinerja Spark lagi.
k4 = toValidate.union(toValidate) k8 = k4.union(k4) m1 = k8.union(k8) m2 = m1.union(m1) m4 = m2.union(m2).repartition(4).cache() m4.count()

Perbandingan baru menunjukkan keunggulan kecepatan implementasi Scala atas Python oleh 7-8 kali - 7 detik versus 55. Akhirnya, mari kita coba "tercepat yang ada di Python" - numpy untuk menghitung jumlah array:
import numpy numpy_sum = sqlContext.udf.register("numpy_sum", lambda x: float(numpy.sum(x)), DoubleType())
val my_sum = sqlContext.udf.register("my_sum", (x: Seq[Int]) => x.map(_.toDouble).sum)
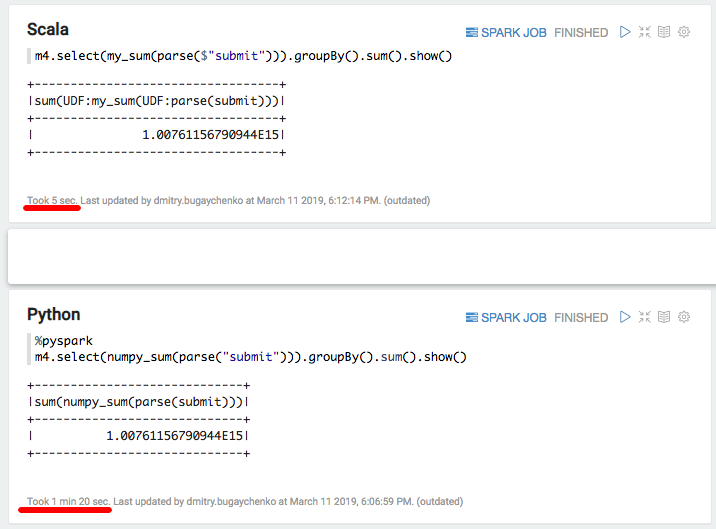
Lagi-lagi pelambatan signifikan - 5 detik Scala versus 80 detik Python. Kesimpulannya, kita bisa menarik kesimpulan berikut:
- Sementara PySpark beroperasi dalam kerangka API standar, ini benar-benar dapat dibandingkan dalam kecepatan dengan Scala.
- Ketika logika spesifik muncul dalam bentuk Fungsi yang Ditentukan Pengguna, kinerja PySpark menurun secara nyata. Dengan informasi yang cukup, ketika waktu pemrosesan blok data melebihi beberapa detik, implementasi Python 5-10 lebih lambat karena kebutuhan untuk memindahkan data antara proses dan sumber daya limbah pada menafsirkan Python.
- Jika penggunaan fungsi tambahan yang diterapkan dalam modul C ++ muncul, maka biaya panggilan tambahan muncul, dan perbedaan antara Python dan Scala meningkat hingga 10-50 kali.
Akibatnya, terlepas dari semua pesona Python, penggunaannya bersama dengan Spark tidak selalu terlihat benar. Jika tidak ada begitu banyak data untuk membuat overhead Python signifikan, maka Anda harus berpikir tentang apakah Spark diperlukan di sini? Jika ada banyak data, tetapi pemrosesan terjadi dalam kerangka standar SQL API Spark, maka apakah Python diperlukan di sini?
Jika ada banyak data dan sering harus berurusan dengan tugas-tugas yang melampaui batas SQL API, maka untuk melakukan jumlah pekerjaan yang sama ketika menggunakan PySpark, Anda harus menambah kluster di kali. Misalnya, untuk Odnoklassniki, biaya pengeluaran modal untuk cluster Spark akan meningkat ratusan juta rubel. Dan jika Anda mencoba untuk mengambil keuntungan dari kemampuan canggih dari pustaka ekosistem Python, yaitu, risiko melambat tidak hanya pada waktu, tetapi urutan besarnya.
Beberapa akselerasi dapat diperoleh dengan menggunakan fungsi vektorisasi yang relatif baru. Dalam hal ini, tidak satu baris pun dimasukkan ke input UDF, tetapi paket beberapa baris dalam bentuk Bingkai Data Pandas. Namun, pengembangan fungsi ini belum selesai , dan bahkan dalam kasus ini perbedaannya akan signifikan .
Alternatifnya adalah dengan mempertahankan tim insinyur data yang luas, dapat dengan cepat mengatasi kebutuhan ilmuwan data dengan fungsi tambahan. Atau untuk membenamkan diri di dunia Scala, karena tidak begitu sulit: banyak alat yang diperlukan sudah ada , program pelatihan muncul yang melampaui PySpark.