Alexander Rubin bekerja di Percona dan telah tampil di
HighLoad ++ lebih dari sekali, akrab bagi peserta sebagai ahli dalam MySQL. Adalah logis untuk berasumsi bahwa hari ini kita akan berbicara tentang sesuatu yang berkaitan dengan MySQL. Ini benar, tetapi hanya sebagian, karena kita juga akan berbicara tentang
Internet . Kisahnya akan setengah menghibur, terutama bagian pertama, di mana kita melihat perangkat yang diciptakan Alexander untuk memanen buah aprikot. Begitulah sifat seorang insinyur sejati - jika Anda ingin buah, Anda harus membayar biaya.

Latar belakang
Semuanya dimulai dengan keinginan sederhana untuk menanam pohon buah-buahan di daerahnya. Tampaknya sangat sederhana untuk melakukan ini - Anda datang ke toko dan membeli bibit. Namun di Amerika, penjual pertanyaan pertama bertanya adalah berapa banyak sinar matahari yang akan diterima pohon. Bagi Alexander, ini ternyata merupakan misteri raksasa - sama sekali tidak diketahui seberapa banyak sinar matahari di situs tersebut.
Untuk mengetahuinya, seorang siswa dapat pergi ke halaman setiap hari, melihat seberapa banyak sinar matahari, dan menulisnya di buku catatan. Tapi ini tidak terjadi - perlu untuk melengkapi semuanya dan mengotomatiskannya.
Selama presentasi, banyak contoh dijalankan dan dimainkan secara langsung. Ingin gambar yang lebih lengkap daripada di teks, beralih ke menonton video.Jadi, agar tidak merekam pengamatan cuaca di notebook, ada sejumlah besar perangkat untuk hal-hal Internet - Raspberry Pi, Raspberry Pi baru, Arduino - ribuan platform berbeda. Tapi saya memilih perangkat yang disebut
Particle Photon untuk proyek ini. Sangat mudah digunakan, biaya $ 19 di situs web resmi.
Hal yang baik tentang Partikel Photon adalah:
- Solusi cloud 100%;
- Setiap sensor cocok, misalnya, untuk Arduino. Semuanya berharga kurang dari satu dolar.
Saya membuat alat seperti itu dan meletakkannya di rumput di situs. Ini memiliki Cloud Perangkat Partikel dan konsol. Perangkat ini terhubung melalui hotspot Wi-Fi dan mengirimkan data: cahaya, suhu, dan kelembaban. Penguji berlangsung 24 jam dengan baterai kecil, yang cukup bagus.
Selanjutnya, saya tidak hanya perlu mengukur iluminasi dan sebagainya dan mentransfernya ke telepon (yang benar-benar bagus - saya dapat melihat secara real time iluminasi apa yang saya miliki), tetapi juga
untuk menyimpan data . Untuk ini, tentu saja, sebagai veteran MySQL, saya memilih MySQL.
Bagaimana cara kita menulis data di MySQL
Saya memilih skema yang agak rumit:
- Saya mendapatkan data dari konsol Partikel;
- Saya menggunakan Node.js untuk menulisnya ke MySQL.
Saya menggunakan API JS Partikel, yang dapat diunduh dari situs web Partikel. Saya membangun koneksi dengan MySQL dan menulis, yaitu, saya hanya melakukan nilai INSERT INTO. Pipa seperti itu.
Dengan demikian, perangkat terletak di halaman, terhubung melalui Wi-Fi ke router rumah dan menggunakan protokol MQTT mentransfer data ke Partikel. Kemudian skema yang sangat: program di Node.js berjalan di mesin virtual, yang menerima data dari Particle dan menulisnya ke MySQL.
Sebagai permulaan, saya membuat grafik dari data mentah dalam R. Grafik menunjukkan bahwa suhu dan pencahayaan naik pada siang hari, turun pada malam hari, dan kelembaban meningkat - ini alami. Tetapi ada juga noise pada grafik, yang tipikal untuk perangkat Internet of Things. Misalnya, ketika bug merangkak ke perangkat dan menutupnya, sensor dapat mengirimkan data yang sama sekali tidak relevan. Ini akan menjadi penting untuk dipertimbangkan lebih lanjut.
Sekarang mari kita bicara tentang MySQL dan JSON, yang telah berubah saat bekerja dengan JSON dari MySQL 5.7 ke MySQL 8. Lalu saya akan menunjukkan demo yang saya gunakan MySQL 8 (pada saat laporan versi ini belum siap untuk produksi, rilis stabil telah dirilis).
Penyimpanan data MySQL
Ketika kami mencoba menyimpan data yang diterima dari sensor, pemikiran pertama kami adalah
membuat tabel di MySQL :
CREATE TABLE 'sensor_wide' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'light' int (11) DEFAULT NULL, 'temp' double DEFAULT NULL, 'humidity' double DEFAULT NULL, PRIMARY KEY ('id') ) ENGINE=InnoDB
Di sini untuk setiap sensor dan untuk setiap tipe data ada kolom: cahaya, suhu, kelembaban.
Ini cukup logis, tetapi
ada masalah - tidak fleksibel . Misalkan kita ingin menambahkan sensor lain dan mengukur sesuatu yang lain. Misalnya, beberapa orang mengukur bir yang tersisa dalam tong. Apa yang harus dilakukan dalam kasus ini?
alter table sensor_wide add water level double ...;
Bagaimana cara memutarbalikkan untuk menambahkan sesuatu ke meja? Anda perlu membuat tabel perubahan, tetapi jika Anda melakukan tabel perubahan di MySQL, maka Anda tahu apa yang saya bicarakan - ini benar-benar sulit. Tabel perubahan di MySQL 8 dan MariaDB jauh lebih sederhana, tetapi secara historis ini adalah masalah besar. Jadi jika kita perlu menambahkan kolom, misalnya, dengan nama bir, maka itu tidak akan sesederhana itu.
Sekali lagi, sensor muncul, menghilang, apa yang harus kita lakukan dengan data lama? Misalnya, kami berhenti menerima informasi tentang pencahayaan. Atau apakah kita membuat kolom baru - bagaimana cara menyimpan apa yang tidak ada sebelumnya? Pendekatan standar adalah nol, tetapi untuk analisis tidak akan terlalu nyaman.
Pilihan lain adalah penyimpanan kunci / nilai.
Penyimpanan data MySQL: key / value
Ini akan
lebih fleksibel : pada kunci / nilai akan ada nama, misalnya, suhu dan, karenanya, data.
CREATE TABLE 'cloud_data' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' text DEFAULT NULL, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB
Dalam hal ini,
masalah lain muncul
- tidak ada tipe . Kami tidak tahu apa yang kami simpan di bidang 'data'. Kami harus mendeklarasikannya sebagai bidang teks. Ketika saya membuat perangkat Internet saya, saya tahu jenis sensor apa yang ada dan jenisnya, tetapi jika Anda perlu menyimpan data orang lain dalam tabel yang sama, saya tidak akan tahu data apa yang sedang dikumpulkan.
Anda dapat menyimpan banyak tabel, tetapi membuat satu tabel baru untuk setiap sensor tidak terlalu baik.
Apa yang bisa dilakukan? - Gunakan JSON.
Penyimpanan data MySQL: JSON
Berita baiknya adalah di MySQL 5.7 Anda dapat menyimpan JSON sebagai bidang.
CREATE TABLE 'cloud_data_json' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' JSON, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB;
Sebelum MySQL 5.7 muncul, orang-orang juga menyimpan JSON, tetapi sebagai bidang teks. Bidang JSON di MySQL memungkinkan Anda untuk menyimpan JSON itu sendiri dengan paling efisien. Selain itu, berdasarkan JSON, Anda dapat membuat kolom virtual dan indeks berdasarkan mereka.
Satu-satunya masalah kecil adalah
bahwa ukuran meja akan bertambah selama penyimpanan . Tapi kemudian kami mendapatkan lebih banyak fleksibilitas.
Bidang JSON lebih baik untuk menyimpan JSON daripada bidang teks karena:
- Memberikan validasi dokumen otomatis . Artinya, jika kita mencoba menulis sesuatu yang tidak valid di sana, akan terjadi kesalahan.
- Ini adalah format penyimpanan yang dioptimalkan . JSON disimpan dalam format biner, yang memungkinkan Anda untuk beralih dari satu dokumen JSON ke yang lain - apa yang disebut skip.
Untuk menyimpan data dalam JSON, kita cukup menggunakan SQL: buat INSERT, letakkan 'data' di sana dan dapatkan data dari perangkat.
… stream.on('event', function(data) { var query = connection.query( 'INSERT INTO cloud_data_json (client_name, data) VALUES (?, ?)', ['particle', JSON.stringify(data)] ) … (demo)
Demo
Untuk mendemonstrasikan (di
sini dimulai dalam video) contoh menggunakan mesin virtual di mana ada SQL.

Di bawah ini adalah bagian dari program.
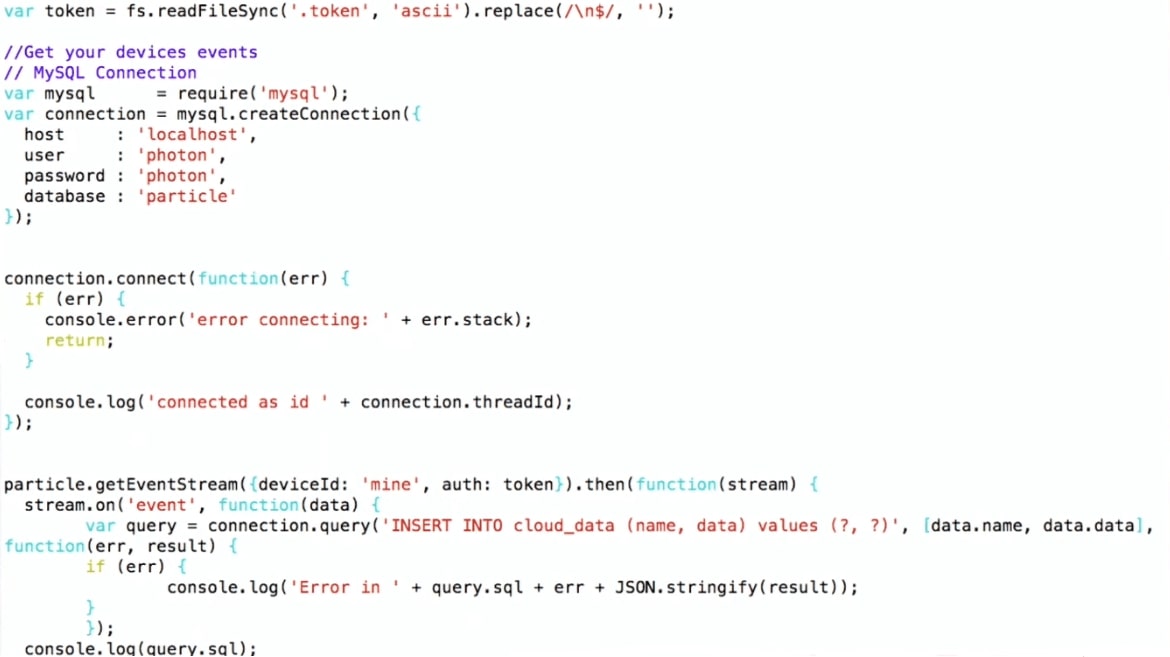
Saya melakukan
INSERT INTO cloud_data (name, data) , saya sudah mendapatkan datanya dalam format JSON, dan saya bisa langsung menuliskannya ke MySQL apa adanya, tanpa memikirkan apa yang ada di dalamnya.
Ternyata, menggunakan cloud ini, Anda tidak hanya dapat mengakses data perangkat saya, tetapi umumnya
semua data yang digunakan oleh Partikel ini. Tampaknya bekerja sejauh ini. Orang-orang yang menggunakan Partikel Photon di seluruh dunia mengirimkan beberapa data: pintu ke garasi terbuka, atau sisa birnya adalah ini dan itu, atau sesuatu yang lain. Tidak diketahui di mana perangkat ini berada, tetapi data tersebut dapat diperoleh. Satu-satunya perbedaan adalah ketika saya mendapatkan data saya, saya menulis sesuatu seperti:
deviceId: 'mine' .
Saat kami menjalankan kode, kami mendapatkan aliran beberapa data dari perangkat orang lain yang melakukan sesuatu.
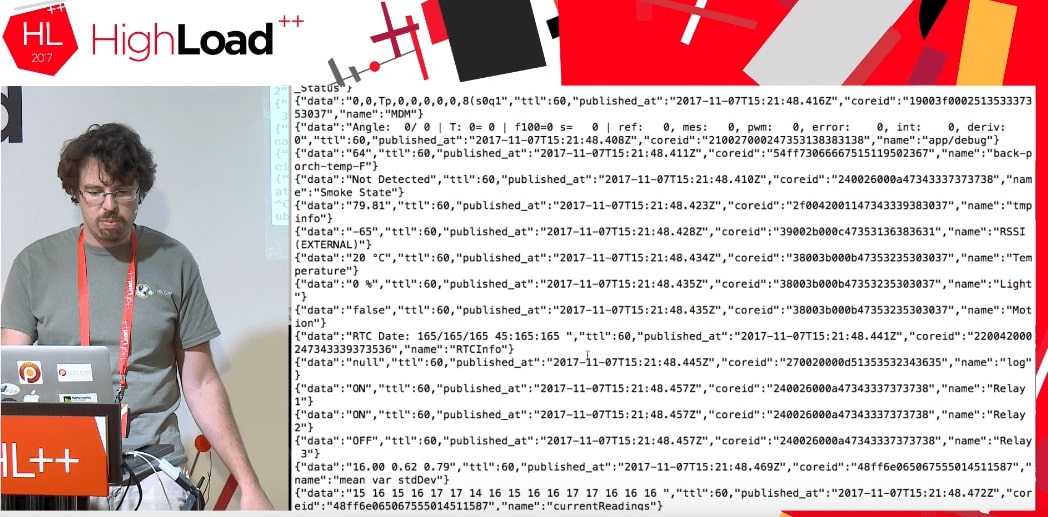
Kami benar-benar tidak tahu apa data ini: TTL, publish_at, coreid, status pintu (pintu terbuka), nyalakan.
Ini adalah contoh yang bagus. Misalkan saya mencoba meletakkan ini di MySQL dalam struktur data normal. Saya harus tahu apa pintu itu, mengapa terbuka, dan apa parameter umum yang bisa diambil. Jika saya memiliki JSON, maka saya menulisnya langsung ke MySQL sebagai bidang JSON.
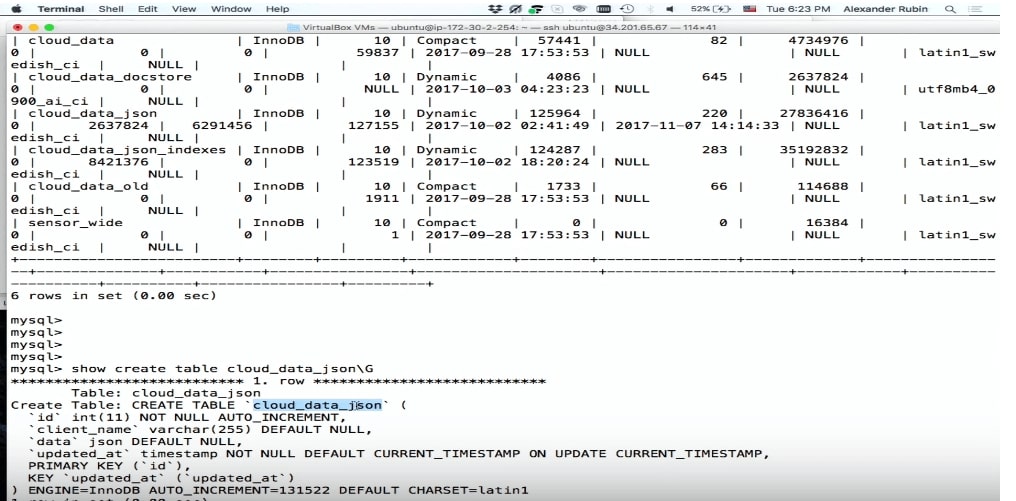
Tolong, semuanya sudah direkam.
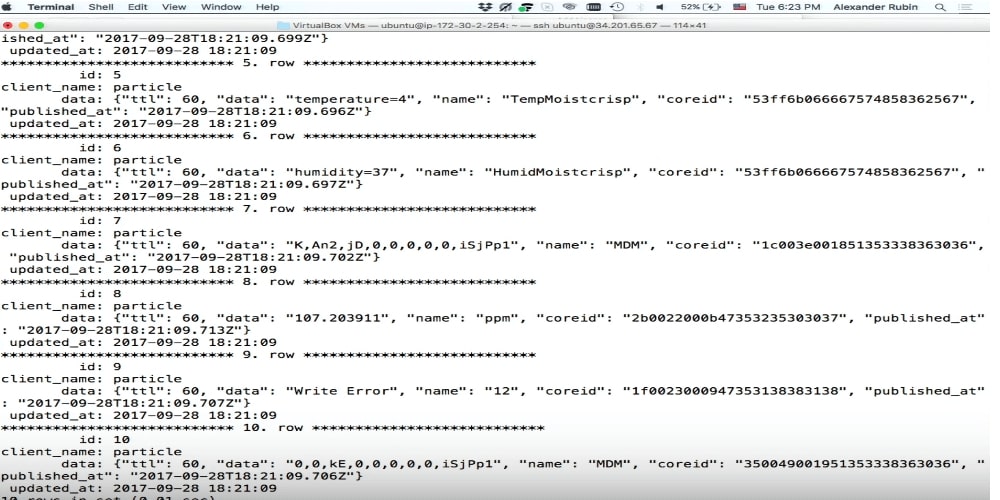
Toko dokumen
Penyimpanan dokumen adalah upaya di MySQL untuk membuat penyimpanan untuk JSON. Saya sangat suka SQL, saya kenal baik, saya bisa membuat query SQL, dll. Tetapi banyak yang tidak suka SQL karena berbagai alasan, dan Document store dapat menjadi solusi bagi mereka, karena dengan itu Anda dapat abstrak dari SQL, terhubung ke MySQL dan menulis JSON langsung di sana.

Ada kemungkinan lain yang muncul di MySQL 5.7: gunakan protokol yang berbeda, port yang berbeda, dan driver lain juga diperlukan. Untuk Node.js (sebenarnya, untuk bahasa pemrograman apa pun - PHP, Java, dll.), Kami terhubung ke MySQL menggunakan protokol yang berbeda dan dapat mentransfer data dalam format JSON. Sekali lagi, saya tidak tahu apa yang saya miliki di JSON ini - informasi tentang pintu atau sesuatu yang lain, saya hanya membuang data di MySQL, dan kemudian kita akan mengetahuinya.
const mysqlx = require('@mysql/xdevapi*); // MySQL Connection var mySession = mysqlx.gctSession({ host: 'localhost', port: 33060, dbUser: 'photon* }); … session.getSchema("particle").getCollection("cloud_data_docstore") .add( data ) .execute(function (row) { }).catch(err => { console.log(err); }) .then( -Function (notices) { console.log("Wrote to MySQL") }); ...https:
Jika Anda ingin bereksperimen dengan ini, Anda dapat mengkonfigurasi MySQL 5.7 sehingga mengerti dan mendengarkan pada port Document store atau X DevAPI yang sesuai. Saya menggunakan connector-nodejs.
Ini adalah contoh dari apa yang saya tulis di sana: bir, dll. Saya sama sekali tidak tahu apa yang ada di sana. Sekarang kita cukup menuliskannya dan menganalisisnya nanti.

Poin berikutnya dari program kami adalah bagaimana melihat apa yang ada di sana?
Penyimpanan data MySQL: indeks JSON +
Ada fitur hebat di JSON dan MySQL 5.7 yang dapat menarik bidang dari JSON. Ini adalah gula sintaksis pada fungsi JSON_EXTRACT. Saya pikir ini sangat nyaman.
Data dalam kasus kami adalah nama kolom tempat JSON disimpan, dan nama adalah bidang kami. Nama, data, publish_at - hanya ini yang bisa kita tarik dengan cara ini.
select data->>'$.name' as data_name, data->>'$.data' as data, data->>'$.published_at' as published from cloud_data_json order by data->'$.published_at' desc limit 10;
Dalam contoh ini, saya ingin melihat apa yang saya tulis ke tabel MySQL, dan 10 catatan terakhir. Saya membuat permintaan seperti itu dan mencoba untuk menjalankannya. Sayangnya,
ini akan bekerja untuk waktu yang sangat lama .
Secara logis, MySQL tidak akan menggunakan indeks apa pun dalam kasus ini. Kami mengeluarkan data dari JSON dan mencoba menerapkan beberapa jenis filter dan penyortiran. Dalam hal ini, kita menggunakan Filesort.
EXPLAIN select data->>'$.name' as data_name ... order by data->>'$.published_at' desc limit 10 select_type: SIMPLE table: cloud_data_json possible_keys: NULL key: NULL … rows: 101589 filtered: 100.00 Extra: Using filesort
Menggunakan filesort sangat buruk, ini adalah jenis eksternal.
Berita baiknya adalah Anda dapat mengambil 2 langkah untuk mempercepatnya.
Langkah 1. Buat kolom virtual
mysql> ALTER TABLE cloud_data_json -> ADD published_at DATETIME(6) -> GENERATED ALWAYS AS (STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ")) VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
Saya melakukan EXTRACT, yaitu, saya menarik data dari JSON dan berdasarkan itu saya membuat kolom virtual. Kolom virtual tidak disimpan di MySQL 5.7 dan di MySQL 8 - itu hanya kemampuan untuk membuat kolom terpisah.
Anda bertanya bagaimana ini, Anda mengatakan bahwa ALTER TABLE adalah operasi yang begitu lama. Tapi di sini tidak terlalu buruk.
Membuat kolom virtual cepat . Ada loCk di sana, tetapi sebenarnya di MySQL ada kunci pada semua operasi DDL. ALTER TABLE adalah operasi yang cukup cepat, dan itu tidak membangun kembali seluruh tabel.
Kami telah membuat kolom virtual di sini. Saya harus mengonversi tanggal, karena di JSON disimpan dalam format iso, tetapi di sini MySQL menggunakan format yang sama sekali berbeda. Untuk membuat kolom, saya menamainya, memberinya jenis dan mengatakan bahwa saya akan merekam di sana.
Untuk mengoptimalkan kueri asli, Anda harus mencabut publish_at dan nama. Published_at sudah ada, nama lebih mudah - cukup buat kolom virtual.
mysql> ALTER TABLE cloud_data_json -> ADD data_name VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.name') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
Langkah 2. Membuat indeks
Dalam kode di bawah ini, saya membuat indeks di publish_at dan menjalankan kueri:
mysql> alter table cloud_data_json add key (published_at); Query OK, 0 rows affected (0.31 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G table: cloud_data_json type: index possible_keys: NULL key: published_at key_len: 9 rows: 10 filtered: 100.00 Extra: Backward index scan
Anda dapat melihat bahwa sebenarnya MySQL menggunakan indeks. Ini adalah optimasi berdasarkan pesanan. Dalam contoh ini, data dan nama tidak diindeks. MySQL menggunakan pesanan berdasarkan data, dan karena kami memiliki indeks di publish_at, ia menggunakannya.
Selain itu, saya dapat menggunakan gula sintaks yang sama
STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ") alih-alih dipublikasikan_at secara berurutan. MySQL masih akan mengerti bahwa ada indeks pada kolom ini dan mulai menggunakannya.
Sebenarnya ada masalah kecil dengan ini. Misalkan saya ingin mengurutkan data tidak hanya dengan publish_at, tetapi juga dengan nama.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc, data_name asc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 101589 filtered: 100.00 Extra: Using filesort
Jika perangkat Anda memproses puluhan ribu peristiwa per detik, publish_at tidak akan memberikan hasil yang baik, karena akan ada duplikat. Oleh karena itu, kami menambahkan pengurutan lainnya berdasarkan data_name. Ini adalah permintaan khas tidak hanya untuk Internet hal: beri saya 10 acara terakhir, tetapi urutkan berdasarkan tanggal, lalu, misalnya, dengan nama belakang orang dalam urutan naik. Untuk melakukan ini, dalam contoh di atas, ada dua bidang dan dua tombol pengurutan ditentukan: turun dan naik.
Pertama-tama, dalam hal ini, MySQL tidak akan menggunakan indeks. Dalam kasus khusus ini, MySQL memutuskan bahwa pemindaian tabel penuh akan lebih menguntungkan daripada menggunakan indeks, dan sekali lagi operasi filesort yang sangat lambat digunakan.
Baru di MySQL 8.0
turun / naik
Di MySQL 5.7, permintaan seperti itu tidak dapat dioptimalkan, jika hanya dengan mengorbankan hal-hal lain. Di MySQL 8, ada peluang nyata untuk menentukan penyortiran untuk setiap bidang.
mysql> alter table cloud_data_json add key published_at_data_name (published_at desc, data_name asc); Query OK, 0 rows affected (0.44 sec) Records: 0 Duplicates: 0 Warnings: 0
Hal yang paling menarik adalah bahwa kunci turun / naik setelah nama indeks telah lama di SQL. Bahkan di versi pertama MySQL 3.23, Anda bisa menentukan publish_at descending atau publish_at ascending. MySQL menerima ini,
tetapi tidak melakukan apa pun , yaitu selalu disortir dalam satu arah.
Di MySQL 8, ini sudah diperbaiki dan sekarang ada fitur seperti itu. Anda bisa membuat bidang dalam urutan menurun dan dengan pengurutan default.
Mari kita kembali sejenak dan melihat contoh dari langkah 2 lagi.
Mengapa itu berhasil, kalau tidak, tidak? Ini berfungsi karena dalam indeks MySQL itu adalah B-tree, dan indeks B-tree dapat dibaca dari awal dan dari akhir. Dalam hal ini, MySQL membaca indeks dari akhir dan semuanya baik-baik saja. Tetapi jika kita turun dan naik, maka Anda tidak dapat membaca. Anda dapat membaca dalam urutan yang sama, tetapi
Anda tidak dapat menggabungkan dua jenis - Anda perlu mengurutkan ulang.
Karena kami mengoptimalkan kasus yang sangat spesifik, kami dapat membuat indeks untuknya dan menentukan jenis tertentu: di sini publish_at turun, data_name naik. MySQL menggunakan indeks ini, dan semuanya akan baik-baik saja dan cepat.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: index possible_keys: NULL key: published_at_data_name key_len: 267 ref: NULL rows: 10 filtered: 100.00 Extra: NULL
Ini adalah fitur dari MySQL 8, yang sekarang, pada saat publikasi, sudah tersedia dan siap digunakan dalam produksi.
Hasil keluaran
Ada dua hal menarik yang ingin saya perlihatkan:
1. Cetak cantik, yaitu, output data yang indah ke layar. Dengan SELECT normal, JSON tidak akan diformat.
mysql> select json_pretty(data) from cloud_data_json where data->>'$.data' like '%beer%' limit 1\G … json_pretty(data): { "ttl": 60, "data": "FvGav,tagkey=beer-store spFridge=7.00,pvFridge=7.44", "name": "LOG_DATA_DEBUG", "coreid": "3600....", "published_at": "2017-09-28T18:21:16.517Z" }
2. Kita dapat mengatakan bahwa MySQL akan menampilkan hasil dalam bentuk array JSON atau objek JSON, tentukan bidang, dan kemudian output akan diformat sebagai JSON.
Pencarian teks lengkap di dalam dokumen JSON
Jika kami menggunakan sistem penyimpanan yang fleksibel dan tidak tahu apa yang ada di dalam JSON kami, akan logis untuk menggunakan pencarian teks lengkap.
Sayangnya,
pencarian teks lengkap memiliki keterbatasan . Hal pertama yang saya coba adalah membuat kunci teks lengkap. Saya mencoba melakukan hal seperti itu:
mysql> alter table cloud_data_json_indexes add fulltext key (data); ERROR 3152 (42000): JSON column 'data' supports indexing only via generated columns on a specified ISON path.
Sayangnya ini tidak berhasil. Bahkan di MySQL 8, membuat indeks teks lengkap hanya dengan bidang JSON sayangnya tidak mungkin. Tentu saja, saya ingin memiliki fungsi seperti itu - kemampuan untuk mencari setidaknya dengan kunci JSON akan sangat berguna.
Tetapi jika ini belum memungkinkan, mari kita buat kolom virtual. Dalam kasus kami, ada bidang data, dan akan menarik bagi kami untuk melihat apa yang ada di dalamnya.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.data') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name, data_data); ERROR 3106 (HY000): 'Fulltext index on virtual generated column' is not supported for generated columns.
Sayangnya, ini juga tidak berfungsi -
Anda tidak dapat membuat indeks teks lengkap pada kolom virtual .
Jika demikian, mari kita buat kolom tersimpan. MySQL 5.7 memungkinkan Anda untuk mendeklarasikan kolom sebagai bidang yang disimpan.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_name VARCHAR(255) CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS (data->>'$.name') STORED; Query OK, 123518 rows affected (1.75 sec) Records: 123518 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name); Query OK, 0 rows affected, 1 warning (3.78 sec) Records: 0 Duplicates: 0 Warnings: 1 mysql> show warnings; +
Dalam contoh sebelumnya, kami membuat kolom virtual yang tidak disimpan, tetapi indeks dibuat dan disimpan. Dalam hal ini, saya harus memberi tahu MySQL bahwa ini adalah kolom STORED, artinya akan dibuat dan data akan disalin ke dalamnya. Setelah itu, MySQL membuat indeks teks lengkap, untuk ini kami harus membuat ulang tabel. Tetapi batasan ini sebenarnya adalah pencarian teks lengkap InnoDB dan InnoDB: Anda harus membuat ulang tabel untuk menambahkan pengidentifikasi pencarian teks lengkap khusus.
Menariknya, di MySQL 8 ada
pengkodean UTF8 MB4 baru untuk emotikon . Tentu saja, tidak cukup untuk mereka, tetapi karena di UTF8MB3 ada beberapa masalah dengan bahasa Rusia, Cina, Jepang dan lainnya.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data TEXT CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS ( CONVERT(data->>'$.data' USING UTF8MB4) ) STORED Query OK, 123518 rows affected (3.14 sec) Records: 123518 Duplicates: 0 Warnings: 0
Dengan demikian, MySQL 8 harus menyimpan data JSON di UTF8MB4. Tetapi apakah karena fakta bahwa Node.js terhubung ke Device Cloud, dan ada sesuatu yang salah ditulis di sana, atau itu adalah bug versi beta, ini tidak terjadi. Karena itu, saya harus mengonversi data sebelum menulisnya ke kolom yang disimpan.
mysql> ALTER TABLE cloud_data_json_indexes DROP KEY ft_json, ADD FULLTEXT KEY ft_json(data_name, data_data); Query OK, 0 rows affected (1.85 sec) Records: 0 Duplicates: 0 Warnings: 0
Setelah itu, saya dapat membuat pencarian teks lengkap pada dua bidang: pada nama JSON dan pada data JSON.
Bukan hanya IoT
JSON bukan hanya Internet hal. Dapat digunakan untuk hal-hal menarik lainnya:
- Bidang khusus (CMS);
- Struktur kompleks, dll.;
Beberapa hal dapat lebih mudah diimplementasikan menggunakan skema penyimpanan data yang fleksibel. Contoh yang sangat baik diberikan di Oracle OpenWorld: pemesanan bioskop. Sangat sulit untuk menerapkan ini dalam model relasional - Anda mendapatkan banyak tabel dependen, bergabung, dll. Di sisi lain, kita dapat menyimpan seluruh ruangan sebagai struktur JSON, masing-masing, menulisnya ke MySQL di tabel lain dan menggunakannya dengan cara biasa: membuat indeks berdasarkan JSON, dll.
Struktur kompleks disimpan dengan nyaman dalam format JSON.
Ini adalah pohon yang berhasil ditanam. Sayangnya, beberapa tahun kemudian, rusa memakannya, tetapi ini adalah kisah yang sama sekali berbeda.
Laporan ini adalah contoh yang sangat baik tentang bagaimana seluruh bagian tumbuh dari satu topik di konferensi besar, dan kemudian acara terpisah yang terpisah. Dalam hal Internet of Things , kami mendapatkan InoThings ++ - sebuah konferensi untuk para profesional di pasar Internet of Things, yang akan diadakan untuk kedua kalinya pada 4 April.
Acara sentral konferensi, tampaknya, akan menjadi meja bundar "Apakah kita memerlukan standar nasional di Internet of Things?", Yang mana secara organik akan dilengkapi dengan laporan terapan yang komprehensif. Datang jika sistem Anda yang memuat banyak bergerak dengan benar ke IIoT.