
Selama bertahun-tahun mengoperasikan Kubernet dalam produksi, kami telah mengumpulkan banyak cerita menarik, karena bug di berbagai komponen sistem menyebabkan konsekuensi yang tidak menyenangkan dan / atau tidak dapat dipahami yang mempengaruhi pengoperasian wadah dan polong. Dalam artikel ini, kami telah memilih beberapa yang paling sering atau menarik. Bahkan jika Anda tidak pernah cukup beruntung untuk menghadapi situasi seperti itu, membaca tentang detektif sesingkat itu - terlebih lagi, secara langsung - selalu menghibur, bukankah begitu? ..
Sejarah 1. Supercronic dan pembekuan Docker
Di salah satu cluster, kami secara berkala menerima Docker "beku", yang mengganggu fungsi normal cluster. Pada saat yang sama, berikut ini diamati dalam log Docker
level=error msg="containerd: start init process" error="exit status 2: \"runtime/cgo: pthread_create failed: No space left on device SIGABRT: abort PC=0x7f31b811a428 m=0 goroutine 0 [idle]: goroutine 1 [running]: runtime.systemstack_switch() /usr/local/go/src/runtime/asm_amd64.s:252 fp=0xc420026768 sp=0xc420026760 runtime.main() /usr/local/go/src/runtime/proc.go:127 +0x6c fp=0xc4200267c0 sp=0xc420026768 runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 fp=0xc4200267c8 sp=0xc4200267c0 goroutine 17 [syscall, locked to thread]: runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 …
Dalam kesalahan ini, kami paling tertarik pada pesan:
pthread_create failed: No space left on device . Sebuah studi cepat dari
dokumentasi menjelaskan bahwa Docker tidak dapat melakukan proses percabangan, yang menyebabkannya “membeku” secara berkala.
Dalam memantau apa yang terjadi, gambar berikut ini bersesuaian:

Situasi serupa diamati pada node lain:


Pada node yang sama kita lihat:
root@kube-node-1 ~
Ternyata perilaku ini merupakan konsekuensi dari pekerjaan
pod dengan
supercronic (utilitas on Go yang kami gunakan untuk menjalankan tugas cron di pod):
\_ docker-containerd-shim 833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 /var/run/docker/libcontainerd/833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 docker-runc | \_ /usr/local/bin/supercronic -json /crontabs/cron | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true | | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true -no-pidfile | \_ [newrelic-daemon] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> …
Masalahnya adalah ini: ketika tugas dimulai dalam supercronic, proses yang dihasilkannya tidak
dapat diselesaikan dengan benar , berubah menjadi
zombie .
Catatan : Untuk lebih tepatnya, proses dihasilkan oleh tugas cron, namun, supercronic bukanlah sistem init dan tidak dapat "mengadopsi" proses yang ditimbulkan oleh anak-anaknya. Ketika sinyal SIGHUP atau SIGTERM terjadi, mereka tidak ditransmisikan ke proses melahirkan, sebagai akibatnya proses anak tidak berakhir, tetap dalam status zombie. Anda dapat membaca lebih lanjut tentang semua ini, misalnya, dalam artikel seperti itu .Ada beberapa cara untuk menyelesaikan masalah:
- Sebagai solusi sementara - tingkatkan jumlah PID dalam sistem pada satu titik waktu:
/proc/sys/kernel/pid_max (since Linux 2.5.34) This file specifies the value at which PIDs wrap around (ie, the value in this file is one greater than the maximum PID). PIDs greater than this value are not allo‐ cated; thus, the value in this file also acts as a system-wide limit on the total number of processes and threads. The default value for this file, 32768, results in the same range of PIDs as on earlier kernels
- Atau, melakukan peluncuran tugas dalam supercronic tidak secara langsung, tetapi dengan bantuan tini yang sama, yang mampu menghentikan proses dengan benar dan tidak menghasilkan zombie.
Riwayat 2. "Zombies" saat menghapus cgroup
Kubelet mulai mengkonsumsi banyak CPU:
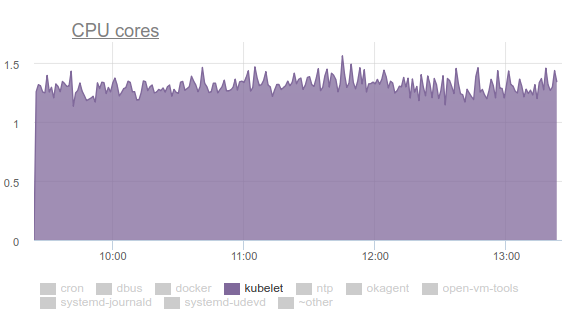
Tidak ada yang suka ini, jadi kami mempersenjatai diri dengan
perf dan mulai menangani masalahnya. Hasil investigasi adalah sebagai berikut:
- Kubelet menghabiskan lebih dari sepertiga waktu CPU untuk menarik data memori dari semua grup:

- Di milis pengembang kernel Anda dapat menemukan diskusi tentang masalah tersebut . Singkatnya, intinya adalah bahwa file tmpfs yang berbeda dan hal-hal serupa lainnya tidak sepenuhnya dihapus dari sistem ketika cgroup dihapus - zombie yang disebut memcg tetap ada. Cepat atau lambat, mereka tetap akan dihapus dari cache halaman, namun, memori di server besar dan kernel tidak melihat titik membuang-buang waktu menghapusnya. Karena itu, mereka terus menumpuk. Mengapa ini bahkan terjadi? Ini adalah server dengan pekerjaan cron yang terus-menerus menciptakan pekerjaan baru, dan dengan mereka pod baru. Dengan demikian, cgroup baru dibuat untuk wadah di dalamnya, yang akan segera dihapus.
- Mengapa cAdvisor di kubelet menghabiskan banyak waktu? Ini mudah dilihat dengan eksekusi
time cat /sys/fs/cgroup/memory/memory.stat . Jika operasi memakan waktu 0,01 detik pada mesin yang sehat, maka 1,2 detik pada cron02 yang bermasalah. Masalahnya adalah bahwa cAdvisor, yang membaca data dari sysfs dengan sangat lambat, mencoba untuk memperhitungkan memori yang digunakan dalam cgroup zombie juga. - Untuk menghapus zombie dengan paksa, kami mencoba menghapus cache, seperti yang direkomendasikan di LKML:
sync; echo 3 > /proc/sys/vm/drop_caches sync; echo 3 > /proc/sys/vm/drop_caches , tetapi kernel ternyata lebih rumit dan menggantung mesin.
Apa yang harus dilakukan Masalahnya sudah diperbaiki (
komit , dan keterangannya, lihat
pesan rilis ) dengan memperbarui kernel Linux ke versi 4.16.
Sejarah 3. Systemd dan mount-nya
Sekali lagi, kubelet mengkonsumsi terlalu banyak sumber daya pada beberapa node, tetapi kali ini sudah memori:

Ternyata ada masalah dalam systemd yang digunakan di Ubuntu 16.04, dan itu terjadi ketika mengendalikan mount yang dibuat untuk menghubungkan
subPath dari ConfigMaps atau rahasia. Setelah pod selesai,
layanan systemd dan layanan mountnya tetap berada di sistem. Seiring waktu, mereka mengumpulkan jumlah yang sangat besar. Bahkan ada masalah pada topik ini:
- kops # 5916 ;
- kubernetes # 57345 .
... yang terakhir merujuk ke PR di systemd:
# 7811 (masalah di systemd adalah
# 7798 ).
Masalahnya tidak lagi di Ubuntu 18.04, tetapi jika Anda ingin terus menggunakan Ubuntu 16.04, solusi kami tentang topik ini mungkin berguna.
Jadi, kami membuat DaemonSet berikut:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: labels: app: systemd-slices-cleaner name: systemd-slices-cleaner namespace: kube-system spec: updateStrategy: type: RollingUpdate selector: matchLabels: app: systemd-slices-cleaner template: metadata: labels: app: systemd-slices-cleaner spec: containers: - command: - /usr/local/bin/supercronic - -json - /app/crontab Image: private-registry.org/systemd-slices-cleaner/systemd-slices-cleaner:v0.1.0 imagePullPolicy: Always name: systemd-slices-cleaner resources: {} securityContext: privileged: true volumeMounts: - name: systemd mountPath: /run/systemd/private - name: docker mountPath: /run/docker.sock - name: systemd-etc mountPath: /etc/systemd - name: systemd-run mountPath: /run/systemd/system/ - name: lsb-release mountPath: /etc/lsb-release-host imagePullSecrets: - name: antiopa-registry priorityClassName: cluster-low tolerations: - operator: Exists volumes: - name: systemd hostPath: path: /run/systemd/private - name: docker hostPath: path: /run/docker.sock - name: systemd-etc hostPath: path: /etc/systemd - name: systemd-run hostPath: path: /run/systemd/system/ - name: lsb-release hostPath: path: /etc/lsb-release
... dan menggunakan skrip berikut:
... dan itu dimulai setiap 5 menit dengan supercronic yang telah disebutkan. Dockerfile-nya terlihat seperti ini:
FROM ubuntu:16.04 COPY rootfs / WORKDIR /app RUN apt-get update && \ apt-get upgrade -y && \ apt-get install -y gnupg curl apt-transport-https software-properties-common wget RUN add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable" && \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - && \ apt-get update && \ apt-get install -y docker-ce=17.03.0* RUN wget https://github.com/aptible/supercronic/releases/download/v0.1.6/supercronic-linux-amd64 -O \ /usr/local/bin/supercronic && chmod +x /usr/local/bin/supercronic ENTRYPOINT ["/bin/bash", "-c", "/usr/local/bin/supercronic -json /app/crontab"]
Sejarah 4. Persaingan dalam polong perencanaan
Tercatat bahwa: jika sebuah pod ditempatkan pada node kami dan gambarnya dipompa untuk waktu yang sangat lama, maka pod lainnya yang "masuk" ke node yang sama
tidak akan mulai menarik gambar pod baru . Sebaliknya, ia menunggu gambar pod sebelumnya ditarik. Akibatnya, pod yang telah direncanakan dan yang gambarnya dapat diunduh hanya dalam satu menit akan berakhir dalam status
containerCreating untuk waktu yang lama.
Dalam acara, akan ada sesuatu seperti ini:
Normal Pulling 8m kubelet, ip-10-241-44-128.ap-northeast-1.compute.internal pulling image "registry.example.com/infra/openvpn/openvpn:master"
Ternyata
satu gambar dari registri lambat dapat memblokir penyebaran ke node.
Sayangnya, tidak banyak jalan keluar dari situasi ini:
- Cobalah untuk menggunakan Docker Registry Anda secara langsung di cluster atau langsung dengan cluster (misalnya, GitLab Registry, Nexus, dll.);
- Gunakan utilitas seperti kraken .
Sejarah 5. Menggantung node dengan kehabisan memori
Selama pengoperasian berbagai aplikasi, kami juga menerima situasi di mana node benar-benar tidak dapat diakses: SSH tidak merespons, semua daemon pemantauan jatuh, dan kemudian tidak ada (atau hampir tidak ada) yang abnormal dalam log.
Saya akan memberi tahu Anda dalam gambar pada contoh satu simpul di mana MongoDB berfungsi.
Beginilah tampilan puncak
sebelum kecelakaan:

Jadi -
setelah kecelakaan:

Dalam pemantauan, juga, ada lompatan tajam di mana node tidak lagi dapat diakses:
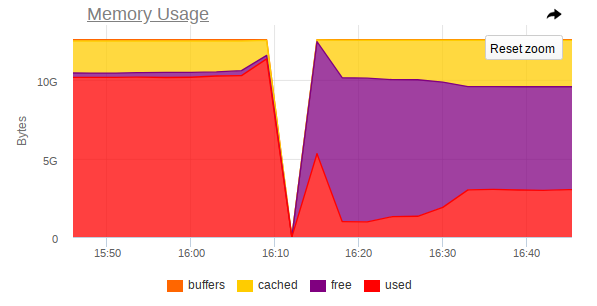
Jadi, tangkapan layar menunjukkan bahwa:
- RAM pada mesin mendekati akhir;
- Lonjakan tajam dalam konsumsi RAM diamati, setelah itu akses ke seluruh mesin dinonaktifkan secara tajam;
- Sebuah tugas besar tiba di Mongo, yang memaksa proses DBMS menggunakan lebih banyak memori dan secara aktif membaca dari disk.
Ternyata jika Linux kehabisan memori bebas (tekanan memori terjadi) dan tidak ada swap, maka
sebelum pembunuh OOM tiba, keseimbangan dapat terjadi antara membuang halaman di cache halaman dan menulisnya kembali ke disk. Ini dilakukan oleh kswapd, yang dengan berani membebaskan sebanyak mungkin halaman memori untuk distribusi nanti.
Sayangnya, dengan beban I / O yang besar, ditambah dengan sejumlah kecil memori bebas,
kswapd menjadi penghambat seluruh sistem , karena
semua kesalahan halaman dari halaman memori dalam sistem terkait dengannya. Ini dapat berlangsung untuk waktu yang sangat lama jika proses tidak ingin menggunakan memori lagi, tetapi tetap di tepi jurang pembunuh OOM.
Pertanyaan logisnya adalah: mengapa pembunuh OOM datang sangat terlambat? Dalam iterasi OOM saat ini, killer sangat bodoh: itu akan membunuh proses hanya ketika upaya untuk mengalokasikan halaman memori gagal, mis. jika kesalahan halaman gagal. Ini tidak terjadi untuk waktu yang lama, karena kswapd dengan berani membebaskan halaman memori dengan membilas cache halaman (semua disk I / O dalam sistem, pada kenyataannya) kembali ke disk. Secara lebih rinci, dengan deskripsi langkah-langkah yang diperlukan untuk menghilangkan masalah seperti itu di kernel, Anda dapat membaca di
sini .
Perilaku ini
harus ditingkatkan dengan kernel Linux 4.6+.
Story 6. Pods Pending
Dalam beberapa kelompok, di mana terdapat banyak polong, kami mulai memperhatikan bahwa kebanyakan dari mereka tergantung dalam status
Pending untuk waktu yang sangat lama, meskipun wadah Docker sendiri sudah berjalan di node dan Anda dapat secara manual bekerja dengannya.
Tidak ada yang salah dengan
describe :
Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 1m default-scheduler Successfully assigned sphinx-0 to ss-dev-kub07 Normal SuccessfulAttachVolume 1m attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "sphinx-config" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "default-token-fzcsf" Normal SuccessfulMountVolume 49s (x2 over 51s) kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx-exporter/sphinx-indexer:v1" already present on machine Normal Created 43s kubelet, ss-dev-kub07 Created container Normal Started 43s kubelet, ss-dev-kub07 Started container Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx/sphinx:v1" already present on machine Normal Created 42s kubelet, ss-dev-kub07 Created container Normal Started 42s kubelet, ss-dev-kub07 Started container
Setelah menggali sekitar, kami membuat asumsi bahwa kubelet tidak punya waktu untuk mengirim server API semua informasi tentang keadaan pod, sampel liness / readiness.
Dan setelah mempelajari bantuan, kami menemukan parameter berikut:
--kube-api-qps - QPS to use while talking with kubernetes apiserver (default 5) --kube-api-burst - Burst to use while talking with kubernetes apiserver (default 10) --event-qps - If > 0, limit event creations per second to this value. If 0, unlimited. (default 5) --event-burst - Maximum size of a bursty event records, temporarily allows event records to burst to this number, while still not exceeding event-qps. Only used if --event-qps > 0 (default 10) --registry-qps - If > 0, limit registry pull QPS to this value. --registry-burst - Maximum size of bursty pulls, temporarily allows pulls to burst to this number, while still not exceeding registry-qps. Only used if --registry-qps > 0 (default 10)
Seperti yang Anda lihat, nilai
standarnya cukup kecil , dan dalam 90% mereka memenuhi semua kebutuhan ... Namun, dalam kasus kami ini tidak cukup. Oleh karena itu, kami menetapkan nilai-nilai ini:
--event-qps=30 --event-burst=40 --kube-api-burst=40 --kube-api-qps=30 --registry-qps=30 --registry-burst=40
... dan me-restart kubelet, setelah itu mereka melihat gambar berikut pada grafik mengakses server API:

... dan ya, semuanya mulai terbang!
PS
Untuk bantuan dalam mengumpulkan bug dan menyiapkan artikel, saya mengucapkan terima kasih yang mendalam kepada banyak insinyur perusahaan kami, dan khususnya kepada Andrei Klimentyev (kolega dari tim R&D kami) (
zuzzas ).
PPS
Baca juga di blog kami: